
融合多模态深度游走与偏差校准因子的推荐模型
2022-08-24 06:30武子腾宋承云
计算机应用 2022年8期
武子腾,宋承云
(重庆理工大学计算机科学与工程学院,重庆 400054)
0 引言
电商领域的流量逐渐从匮乏转为过剩,导致不可避免的信息过载问题[1]。为了让用户从大量产品中找到其感兴趣的,让产品方生产的产品得到用户的反馈,平台促成更多的交易,大多数电子商务和零售公司借助推荐系统为需求不明确的用户过滤无效产品[2]。推荐算法利用各类历史行为记录推测用户的潜在偏好,为用户提供个性化内容,使推荐系统能最大限度地吸引用户、留存用户,增加用户黏性和提高用户转化率等,实现公司长期的发展目标[3-5]。
随着电商平台业务覆盖范围逐步扩大,互联网中用户和项目的数量呈指数型增长[6],功能单一的信息筛选器已不能满足海量用户的个性化需求,电商协同过滤系统需要应对更多的挑战来留住忠诚用户[7]。国际知识发现和数据挖掘领域顶级赛事KDD(Knowledge Discovery and Data mining)CUP 2020 竞赛由阿里巴巴达摩院主办,旨在解决电商场景下的偏差(bias)问题,以对抗推荐系统中长期存在的马修效应。协同过滤推荐模型的核心是计算项目间的相似度和预测目标用户的潜在偏好,而用户倾向于与推荐页面曝光的项目交互[1],模型依据交互项目计算出与其相似的项目并推荐给用户,对用户的行为产生影响,造成曝光偏差(Exposure bias)。曝光偏差在电商协同过滤系统中迭代反馈,导致TopN预测列表偏离用户的真实兴趣,加剧曝光偏差,长此以往系统的推荐性能将越来越差,损害用户对个性化推荐的满意度[8]。
偏差问题在工业界引起了广泛关注,然而学术界与此相关的研究工作相对欠缺,针对电商推荐系统中的曝光偏差问题,本文提出一种融合多模态深度游走与偏差校准因子(Multimodal DeepWalk and Bias Calibration factor,MmDWBC)的TopN推荐模型,将更多低曝光且感兴趣的项目推荐给用户。本模型首先利用用户历史交互记录和高维多模态的项目属性信息构建多模态项目图;其次在项目图上进行改进的深度游走表示,学习得到多模态项目节点的低维嵌入表示;最后基于校准思想以修正用户兴趣倾向性计算。
本文的工作主要有以下几点:
1)针对低曝光项目交互数据稀疏性和冷启动加剧问题,将高维多模态的项目属性特征作为辅助数据,为构建多模态项目图引入更多低曝光项目信息,通过改进的深度游走表示将多模态信息融入嵌入向量,有效缓解数据稀疏和冷启动。
2)由于项目曝光度影响用户兴趣估计值,提出一种以校准策略为指导的偏差校准推荐计算新算法。
3)提出了一种TopN推荐新模型MmDW-BC,通过融合多模态深度游走(Multimodal DeepWalk,MmDW)和偏差校准因子(Bias Calibration factor,BC),有效地将不受关注且用户感兴趣的低曝光项目推荐给用户。
1 相关工作
1.1 曝光偏差
推荐系统的曝光机制由推荐器构建者制定,相关学术研究人员无权限获取和干预[9]。假设用户只能与系统曝光的项目交互,则交互次数就代表曝光次数,项目交互数越大,则项目曝光度越高,交互数与曝光度成正比。本文统计Amazon 用户交互数据中每个项目的交互次数,得到项目交互数(曝光度)分布图,项目交互数越大越受用户关注。从图1 可以看出,项目交互数(曝光度)分布不均衡,只有极少一部分项目的交互次数达到100 以上,大多数项目的交互次数集中在[0,100]。

图1 项目交互数(曝光度)分布图Fig.1 Distribution diagram of item interaction number(exposure)
由图1 可知,高曝光项目数量少,即使不推荐用户也可以通过其他新媒体平台获得;相反,低曝光项目数量庞大且不受关注,用户难以从除了推荐之外的其他途径获取到低曝光项目信息。因此与推荐高曝光项目相比,推荐低曝光项目将会带来更大的价值。推荐系统受曝光偏差影响,只向用户推荐高曝光项目忽视了滞留已久的低曝光项目,使越来越多的用户被推荐系统局限在一个相对“狭窄”的推荐列表中,用户的潜在兴趣被带有偏差的推荐结果忽略。因此,推荐低曝光且用户感兴趣的项目十分重要。
1.2 协同过滤模型
大型电子商务网站往往有庞大的用户量,可利用推荐模型捕捉用户的潜在偏好,为意图不明确的用户主动提供个性化服务。基于项目相似度的协同过滤利用用户-项目历史交互数据建模用户偏好模型,其输入数据来源广泛且语义丰富,展示给用户的预测列表解释性强,例如推荐页面向用户推送电蚊香,推荐原因是用户近期购买过蚊帐。此模型的推荐依据是用户历史偏好行为,预测结果准确率高,由于电商场景下项目及其属性信息更新较为稳定,项目相似度矩阵的更新和维护的代价相对较小。综合上述优点,基于项目相似度的协同过滤成为大规模电商网站和工业界广泛采用的推荐模型[6]。
Jaccard 相关系数(Jaccard Similarity Coefficient)和余弦相似度(Cosine Similarity)是计算项目相似度矩阵常用的方式。假设sim(i,j)表示项目i和项目j之间的相似度,N(i)表示与项目i交互过的用户集合,N(j)表示与项目j交互过的用户集合,|N(i)|表示与项目i交互过的用户数量,|N(j)|表示与项目j交互过的用户数量,|N(i) ∩N(j)|表示同时与项目i和项目j交互过的用户数量。项目i和项目j之间的Jaccard相关系数计算方式为:

项目i和项目j之间的cosine 相似度计算方式为:

得到项目相似度矩阵后,计算目标用户对历史交互项目的相似项目的兴趣倾向值:

其中:N(u)表示用户u交互的项目集合;sim(i,k)表示与项目i最相似的k个项目;ruj表示用户u对项目j的偏好程度,在隐式反馈推荐中ruj取值为1。
协同过滤机制容易过度推荐高曝光项目而放大偏差,曝光偏差使项目因曝光度不同而有不同的相似项目。一般来说,高曝光项目和其他项目间的相似程度要高于低曝光项目和其他项目间的相似度[10],这是因为频繁曝光在推荐页面的项目(高曝光项目)通常具有其他项目的共性特征,且受到系统中大多数用户的关注。由式(3)可知,两个项目间的相似程度越高对计算用户兴趣倾向值贡献越大,推送给用户的预测列表自然也是曝光度较高的项目。结合式(1)~(3)可知,协同过滤推荐模型中计算相似度矩阵和预测用户兴趣倾向值加强了高曝光项目的贡献度,削弱了低曝光项目的贡献度,模型难以避免曝光偏差对用户决策(浏览、点击、收藏、购买等)的影响,甚至加剧曝光偏差。可见,降低曝光偏差带来的影响对提高推荐精度是有效的。
1.3 图嵌入表示
图嵌入表示是利用深度学习模型的方法,将拓扑图中的邻接关系用低维度嵌入空间中的向量表示[11],即学习出一个低维稠密的向量来表示图中的节点、边和局部结构,同时包含一些附加特征,得以让预测、分类、可视化等任务更加方便地提取和利用图结构中蕴含的特征[12]。图嵌入的思想是使在原始图结构空间中彼此接近的点,映射到嵌入后的低维度空间中也相应地接近[13]。深度游走(DeepWalk)是典型的图结构数据挖掘模型[14],主要分为随机游走和生成表示向量两个部分。首先利用截断随机游走算法从图中提取一些节点序列,然后借助自然语言处理(Natural Language Processing,NLP)的思路,将生成的定点序列看作由单词组成的句子,所有的序列组成一个大的语料库,最后输入到神经语言模型中生成Embedding 向量。
随着图嵌入技术的发展,嵌入向量本身的表达能力进一步增强,而且能够将各类补充信息融入嵌入向量之中,使嵌入向量成为非常有价值的推荐系统特征[15-16]。文献[17]从理论的角度证明了基于SkipGram 模型的DeepWalk 是一种隐式的矩阵分解技术并推导出其近似的矩阵分解形式,进一步的研究发现,DeepWalk 的隐式矩阵通过低秩变换可转换为归一化的图拉普拉斯矩阵,这项工作提出了一个用于显式分解闭式矩阵的一般框架NetMF(Network embedding as Matrix Factorization)。尽管NetMF 学习到的表征向量用于后续任务时表现出较优的性能,但在学习大型图的节点表征时需要付出相当大的代价,导致性能受限。之后,文献[18]提出了基于谱传播策略的ProNE 图嵌入模型,可用于处理大规模图数据。
2 MmDW-BC推荐模型
融合多模态深度游走与偏差校准因子(MmDW-BC)的模型结构如图2 所示,其中包含三个组件:构建项目图组件、多模态深度游走MmDW 组件和偏差校准推荐BC 组件。

图2 MmDW-BC模型的结构Fig.2 Structure of MmDW-BC model
2.1 构建项目图
由1.1 节的分析可知,电商推荐系统中存在大量低曝光项目,这些项目由于推荐页面曝光次数不足而缺乏用户交互,加剧项目交互数据稀疏性和冷启动问题。项目属性提供了高维多模态的元数据,主要为项目的文本描述和图像描述,应用文献[19]中已经预训练得到的图像特征向量和文本特征向量,将高维多模态的项目属性特征引入作为辅助信息构建多模态连接边。
本文用G表示构建的项目图,图G中的节点是项目节点,其中vi∈V,|V|表示图G中的节点个数,定义了点击共现连接和属性相似连接两种连接类型,连接边分别属于实边集E={e11,e12,…,emn}和虚边集依据用户历史点击序列构建实边,如果用户先后点击过两个项目,说明两项目间存在点击共现连接关系,那么这两个项目之间就由实线连接;通过计算两个项目之间多模态属性特征相似性生成虚边,如果当前项目用户未交互且与交互项目间属性特征相似的,说明两项目间存在属性相似连接关系,则用虚线连接。由于项目的高维多模态特征是文本特征和图像特征,计算项目间的文本相似性和图像相似性得到项目间的属性相似性。根据文献[20]将相似度阈值b设为项目属性的平均相似度,当项目间属性相似度达到阈值b时,产生虚边。
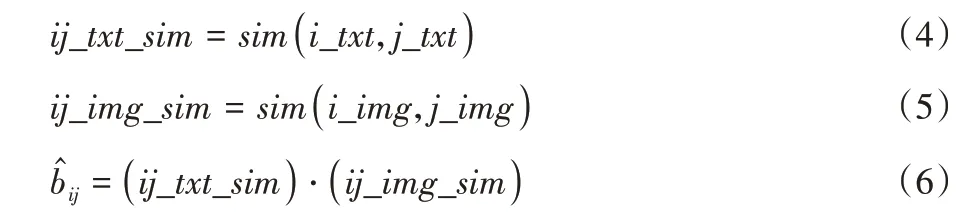
其中:i_txt表示项目i的文本属性特征;j_txt表示项目j的文本属性特征;ij_txt_sim表示项目i和项目j间的文本属性相似度;i_img表示项目i的图像属性特征,j_img表示项目j的图像属性特征;ij_img_sim表示项目i和项目j间的图像属性相似度表示项目i和项目j间的属性相似度。

图3 未引入辅助边和引入辅助边的项目图Fig.3 Item graphs without edges and with auxiliary edges


2.2 多模态深度游走
图嵌入DeepWalk 模型在图上进行截断的随机游走以探索更多节点,但DeepWalk 只考虑了网络结构,忽略了节点连接边中蕴含着丰富的附加信息。本文项目图中,项目间的连接边包括属性相似虚边和交互共现实边,为了在游走采样时对这两种边及其连接节点有所区分,改进传统DeepWalk 中均匀随机采样的策略,提出一种新的节点转移概率,探索更多未交互项目并将项目多模态属性信息融入嵌入向量。本文提出多模态深度游走(MmDW)图嵌入新模型(详细描述见算法1),得到的嵌入表示中不仅保留了图结构信息,还保留了有用的属性信息,具体可归纳为四步:
1)以多模态项目图上的节点为起点进行节点转移,即到达节点vi时,下一步要遍历的节点根据跳转概率选择邻接点vj,重新得到一个由项目节点构成的序列。从节点vi转移到vj的跳转概率为:



3)生成多模态项目图中节点的表示向量。
2.3 偏差校准推荐算法
推荐机制受曝光偏差影响使交互项目呈现不均衡分布,推荐系统通常会放大这种不均衡,当下一次推送时倾向于推荐高曝光项目,低曝光项目往往得不到充分的展示,甚至不被展示。随着系统的迭代反馈,曝光偏差被进一步放大,导致预测结果偏离用户的真实兴趣。校准是机器学习分类任务中的一个常见概念,当分类算法的预测结果分布与实际分布一致时,即为分类校准算法。本文为了缓解偏差放大,将校准策略应用于推荐任务,提出了偏差校准推荐算法(见算法2)。具体为,设计校准因子修正项目对推荐得分的贡献度,使推荐结果中项目的分布比例均衡且符合用户真实的偏好分布,从而规避曝光偏差对用户决策的影响。
用户倾向于与系统主动提供的内容进行交互,因此频繁曝光在推荐页面的高曝光项目得到大多数用户的关注。这种情况下,用户被动地接受推荐内容而产生的交互并不能反映其真实偏好。因此应削弱高曝光项目的贡献度,本文提出项目曝光度校准因子Cexposure,用于校准项目曝光度对兴趣倾向值的贡献,即高曝光项目的相似度贡献值下降,低曝光项目的相似度贡献值提高。

研究表明,用户活跃度对项目间相似性的贡献程度不同,进而影响用户兴趣倾向性得分。系统中存在大量低活跃用户,例如系统新用户等,这些用户需求不明确且偏好不稳定,倾向于与推荐页面曝光的项目直接交互,此行为为高曝光项目提供了高相似度贡献值,加剧了系统中的曝光偏差。本文提出用户活跃度校准因子Cactivity,用于校准用户活跃度对兴趣倾向值的贡献。

其中:|Ni|为项目i在历史记录中的交互次数;|Ni∩Nj|为同时与项目i和项目j交互的用户数。
算法2 BC(Φ,Cexposure,Cactivity)。
输入低维稠密的项目节点表示矩阵Φ,项目曝光度校准因子Cexposure,用户活跃度校准因子Cactivity。
输出下一次点击的TopN预测列表。
1)依据用户历史交互数据构建用户-项目倒排表。
2)计算项目相似度矩阵:

3)基于项目曝光度校准因子和用户活跃度校准因子估计用户兴趣,进一步校准用户兴趣倾向性得分:

其中:N(u)表示与用户u交互过的项目集合;S(i,k)表示与项目i最相似的前k个项目的集合。
4)将用户对各个项目的兴趣倾向性得分由高到低进行排序,选取前N项推荐给用户。
3 实验与结果分析
3.1 实验数据集及运行环境
本文选取被广泛使用的评测协同过滤推荐模型性能的电影评分数据集ML-1M(MovieLens-1M)和Amazon 电商数据集,从真实电商Amazon 平台数据中选择图书类和服饰类作为实验数据集,数据包括从1996 年5 月截至2014 年7 月收集到的用户评论信息(评分、评价、帮助性投票),产品元数据(文本信息、图像信息、品牌、价格等)和链接(浏览/购买)。在真实推荐场景中,用户的隐式交互更广泛,本文通过预处理、采样和筛选原始数据集最终将评级的出现视为隐式反馈,并使用时间戳确定用户交互操作的顺序。两个数据集的细节描述如表1 所示。

表1 数据集的细节描述Tab.1 Details of datasets
Amazon 数据集中项目属性元数据的字段含义如表2所示。

表2 Amazon数据集中元数据字段的含义Tab.2 Meanings of metadata fields in Amazon dataset
本实验在64 位Windows 10 专业版环境下运行,处理器为Intel Core i7-8700 CPU @3.20 GHz,16 GB内存,NVIDIA GeForce GTX 1660 Ti 的显卡,Python 3.7.4。
3.2 留一法划分数据集
在评测推荐模型的性能之前,先用留一法(Leave-One-Out,LOO)划分训练集和标签。留一法是机器学习中对学习器进行评估的一种方法,利用整个数据集几乎所有的数据进行训练,留下一个数据进行测试(验证)。本文实验的学习任务是利用用户历史交互记录预测用户下一次可能交互的项目,因此用LOO 方法进行数据集预处理。对于每个用户,将历史行为按时间戳排序,挑选出时间最近的一次交互项目作为标签,除最新一次交互之外的所有交互作为训练集,详细过程见图4。本文采用的预处理方法使训练集与初始数据集相比只少了最近一次交互的样本,降低了随机划分带来的偶然性,使结果具有确定性;同时又能最大限度地利用初始数据集,使数据利用率更高。
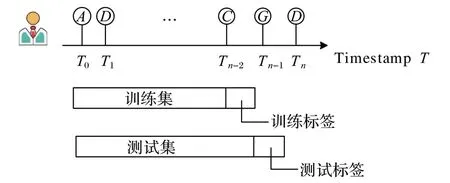
图4 LOO划分数据集Fig.4 LOO method to divide dataset
3.3 评测指标
预测用户下一次点击的TopN项目列表,最常用的评价指标是准确度,该指标衡量的是当前推荐模型预测用户未来兴趣的精准程度,得分越高说明模型预测越准确,推荐效果越好。本实验用到的预测准确度指标是召回率(recall),除了召回率指标,还有衡量排序质量的评价指标,本文采用标准的归一化折损累计增益(ndcg),用户兴趣度高的项目出现的位置越靠前说明排序效果越好。
recall 和ndcg 分别是衡量召回和排序的准确性指标,除此之外,本文还引入了反映推荐系统整体多样性的新颖性(novelty)和多样性(diversity)指标,用于衡量本模型校准不均衡分布的合理性[21]。其中,新颖性关注低曝光项目的推荐能力,常用推荐结果的平均曝光度计算新颖性;多样性关注用户广泛且个性化的需求,常用推荐列表中项目间的不相似度来描述多样性。上述指标可以表示为recall@N、ndcg@N、novelty@N和diversity@N,用于评测推荐模型在列表长度为N时的性能,指标值越大,证明模型的效果越好。
3.4 基线模型及参数设置
基线模型的简要介绍如下:
MostPop:此模型简单地将最热门的项目推荐给所有用户,不考虑用户的个性化需求。
Item-KNN:基于邻域的传统协同过滤模型。
DeepWalk[14]:基于随机游走的图嵌入模型,得到网络结构中节点的表示。
NetMF[17]:整合传统图嵌入模型,统一为具有封闭形式的矩阵分解通用推荐模型。
ProNE[18]:基于稀疏矩阵分解和谱传播的快速且可扩展的图嵌入模型。
RankALS+Re-ranking[22]:为了均衡系统中长尾项目和短头项目的覆盖率,首先基于传统协同过滤RankALS 模型生成推荐列表,在此基础上进行后处理控制(重排序)。
MmDW-BC 实验的参数设置如表3 所示,基线模型的参数设置依据其原论文进行微调。

表3 本文用到的参数Tab.3 Parameters used in this paper
3.5 实验结果与分析
为了检验本文模型的有效性,在真实电商Amazon 数据集和电影ML-1M 数据集上,先进行整体效果比较,再进行多组自身消融对比实验,最后讨论参数变化对实验结果的影响。
3.5.1 推荐性能比较
本文提出的MmDW-BC 模型与六个基准模型应用于稀疏性不同的数据集的整体效果比较结果见表4 所示。

表4 本文模型与基线模型的性能对比Tab.4 Performance comparison of the proposed model and baseline models
MmDW-BC 在四个评价指标上的结果均高于除ML-1M中的ndcg@50 外的其他对比模型,充分说明了本文明确考虑曝光偏差以提升推荐精度的必要性和有效性。MmDW-BC系统整体的多样性较高,验证了偏差校准的合理性。其中,MmDW-BC 模型在不同稀疏度的数据集上的表现略有差异,在recall@50、novelty@50 和diversity@50 指标上,模型在稀疏的Amazon 数据集上的表现明显优于稠密数据集ML-1M,这得益于MmDW-BC 中的多模态深度游走模块可以充分挖掘项目属性的隐含特征,从而有效地缓解数据稀疏性和冷启动问题;而模型在ndcg@50 指标上的表现与之相反,说明MmDW-BC 模型在稠密数据上的排序质量更高。
3.5.2 自身消融研究
Item-KNN 是先进推荐模型的基础,本文在其基础上对项目节点表示和计算用户倾向性得分作改进。为了探索多模态深度游走MmDW 和偏差校准因子BC 分别对低曝光项目的推荐作用,进行了多组自身消融对比实验。其中,MmDW 为基于多模态深度游走的推荐模型,BC 为只引入项目曝光度校准因子和用户活跃度校准因子的推荐模型,消融实验结果见表5 所示。
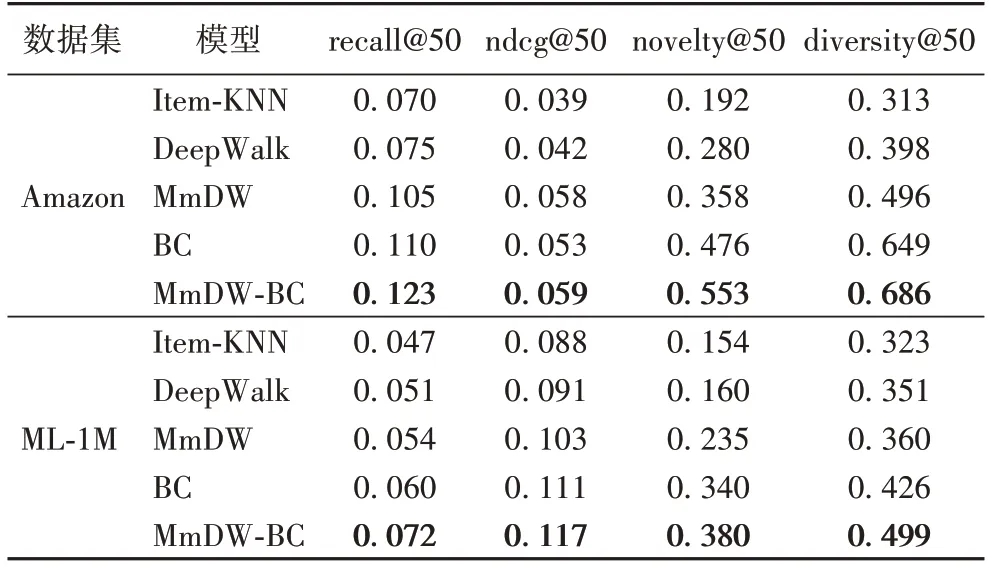
表5 消融实验的结果Tab.5 Ablation experimental results
从表5 可看出,在稀疏Amazon 数据集和稠密ML-1M 数据集上,消融实验结果表现出MmDW-BC>BC>MmDW>DeepWalk>Item-KNN,其中BC 在 recall@50、novelty@50 和diversity@50 指标上的表现均高于MmDW,说明通过引入偏差校准因子来改进用户倾向性得分计算对缓解曝光偏差的贡献更大,消融实验充分验证了偏差校准的合理性和缓解偏差放大的有效性。以上MmDW-BC、MmDW 和BC 三个模型的实验结果都优于基准模型,且MmDW-BC 的结果达到最佳,验证了本文模型MmDW-BC 的有效性。
3.5.3 参数N对推荐性能的影响实验
为了探究推荐性能受预测列表的长度N的影响,本文设置N=10,20,30,40,50,实验结果如图5 所示。随着N的增大,推荐指标也逐渐升高,但上升幅度逐渐减小,考虑到模型运行时间会随N的增大而增加,因此本文设置模型的预测列表长度N为50。

图5 推荐性能随N值的变化Fig.5 Recommendation performance varying with value of N
3.5.4 参数k对推荐性能的影响实验
为了探究推荐性能受项目近邻数k的影响,设置k=10,20,40,80,160,320,实验结果如图6 所示。随着k的增大,模型在Amazon 数据上的推荐指标值先逐渐上升后保持不变,而在ML-1M 数据上持续上升,但当k=160 后增长缓慢,因此本文设置项目近邻数k为160。
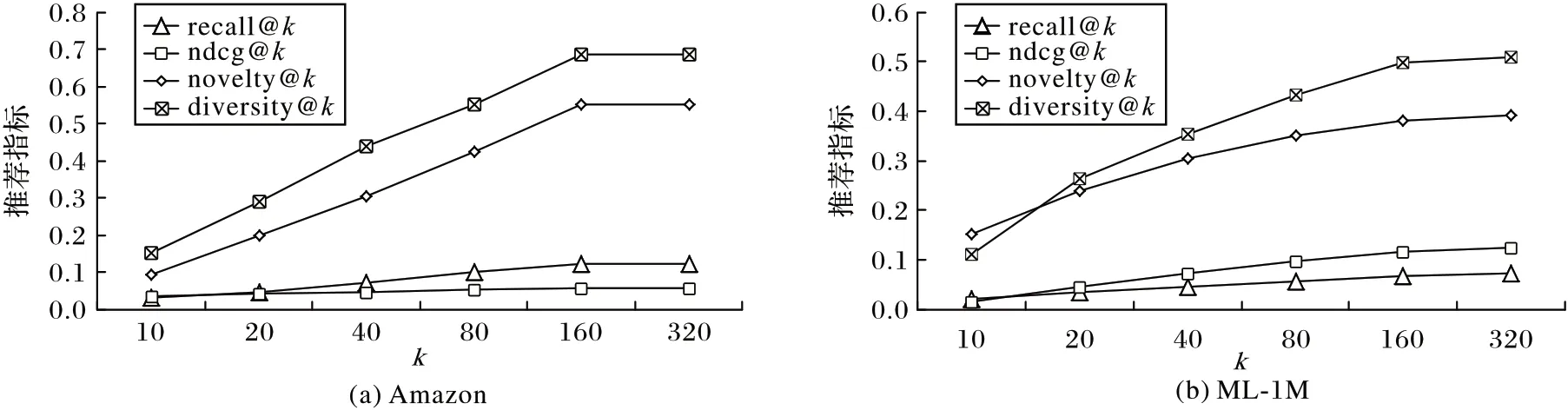
图6 推荐性能随k值的变化Fig.6 Recommendation performance varying with value of k
4 结语
本文为了缓解曝光偏差对协同过滤推荐性能的影响,提出一种融合多模态深度游走与偏差校准因子的TopN推荐模型MmDW-BC。与基线模型在不同稀疏性的数据集上的对比实验结果表明,本文模型MmDW-BC 的整体推荐性能在四个评价指标上均优于基线模型,验证了本文模型在低曝光项目上具有良好的推荐能力。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
昆明医科大学学报(2022年3期)2022-04-19
商界评论(2022年1期)2022-04-13
计算机应用与软件(2021年10期)2021-10-15
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
学生天地(2020年6期)2020-08-25
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
数学大王·趣味逻辑(2019年10期)2019-11-06
