
基于轻量密集神经网络的医学图像超分辨率重建算法
2022-08-24 06:30王一宁赵青杉秦品乐胡玉兰宗春梅
计算机应用 2022年8期
王一宁,赵青杉,秦品乐,胡玉兰,宗春梅
(1.忻州师范学院计算机系,山西忻州 034000;2.中北大学大数据学院,太原 030051)
0 引言
图像超分辨率(Super-Resolution,SR)技术的应用非常广泛,在医学成像、人脸识别、高清音视频[1]等领域有很高实用价值。医学影像发展至今,在医学界占有重要地位,高分辨率的医学图像可以提高医生的工作效率及降低漏诊率[2]。引导放射治疗时常用到电子计算机断层扫描(Computed Tomography,CT)图像,因此获得高清晰度的CT 图像有很大意义。
SR 技术分可为序列图像SR[3-4]与单幅图像SR[5]。在现实生活中,很难在同一场景中获取序列的医学CT 图像,所以本文的主要目的是通过SR 技术提高单幅CT 图像的分辨率。单幅图像SR 是一种典型的病态问题,任务是从一个低分辨率(Low Resolution,LR)的输入去产生一个高分辨率(High Resolution,HR)的输出。因为输入一幅LR 图像可能生成多幅有差异的HR 图像。当超分辨率因子变大时,这个不确定性会变得更大。对于更大的因子(×4),LR 图像可能丢失大量的高频细节。在广泛采用卷积神经网络(Convolutional Neural Network,CNN)之前,超分辨率重建技术被归类成了一种基于预测的方法(最近邻(Nearest Neighbor,NN)[6]、Bilinear[7]和Bicubic[8])、基于边缘检测法[9]、图像统计学方法[10]、基于实例的方法[11]。在这些方法之中,传统的单帧图像超分辨率方法,如NN 选取距离目标位置最近点的像素点作为新插入点的值,在灰度变化的地方易出现明显的马赛克和锯齿现象。Bilinear 在水平和垂直方向分别进行一次线性插值,具有低通滤波器性质,缩放后图像的高频分量受到损失,图像边缘较模糊。Bicubic 取插值点周围的16 个采样点的加权平均求得插值点的像素值,插值后图像边缘比前两者更平滑,但锐度仍存在问题。
上述四种方法中,基于实例的方法复原效果最优。基于外部实例的方法由Glasner 等[12]首次提出,随后陆续出现多种加速优化过程的改良变体形式。这些基于外部实例的方法从外部实例数据集中学习低/高分辨率像素块之间的映射关系。
在外部实例方法中,基于邻居嵌入[13]和稀疏表示[14]的方法都可重建出较好的图像特征。Yang 等[15]提出了基于稀疏编码的图像重建方法。Dong 等[16]受稀疏编码的启发,将稀疏编码的原理推广到了CNN 中,提出了基于卷积神经网络的图像超分辨率(Super-Resolution using CNN,SRCNN)算法。SRCNN 在图像的超分辨率任务中取得了成功,证实了深度学习比传统方法更易重建出有效的图像特征。Ledig等[17]利用残差网络设计出了一个深层结构的网络模型ResNet,使梯度更容易传播到前面的卷积层,解决了深层网络梯度弥散的问题。Yu 等[18]提出的宽残差的高效超分辨率(Wide activation for efficient and accurate image Super-Resolution,WDSR)网络认为,在SR 网络中线性整流函数(Rectified Linear Unit,ReLU)会阻止信息流的传递,因此为了降低激活函数对信息流的影响,对残差块中激活函数之前的特征图数目进行扩展,促使更多低层信息传递到前面的卷积层。深度学习方法和其他方法之间的最显著的区别在于,它们通常直接从训练数据(例如,完整和损坏的图像对)学习用于图像恢复的参数,而不是依赖于预定义的图像先验知识。
作者基于残差神经网络提出图像SR 改进算法,其中有3个有代表性网络模型:双任务损失卷积神经网络(Double Task Loss CNN,DTLCNN)、多阶段级联残差卷积神经网络(Multi-section Cascade Residual CNN,MCRCNN)和多阶段残差神经网络(Multi-Section Residual CNN,MSRCNN)[19]。DTLCNN 层数为72,MCRCNN-apart 为38 层,两者均获得良好重建指标及重建出有效纹理特征,但由于网络层数较深、训练参数多,较低配置的智能终端无法满足网络训练需求,训练所需时间较长。轻量级MSRCNN-fast 为6 层,算法实时性强,对硬件要求低,超分辨率重建指标及重建细节虽优于SRCNN,但远不如DTLCNN 和MCRCNN-apart。本文为提升轻量级神经网络重建效果,在残差神经网络基础上提出了一种轻量密集神经网络算法。由于SR 这种低抽象任务需要更多的底层信息反映特征,于是本文采用了密集神经网络以增加低层特征到高层的传递通道。首先由密集神经网络学习得到LR 与HR 医学图像块之间的特征差值;接着把密集神经网络学到的差值与原图的特征进行叠加;再使用反卷积对图像进行上采样操作,重构出对应的高分辨率图像;最后,将重构出的2 倍与4 倍HR 医学图像与相应大小的原图同时做双任务损失。密集网络结构,每层均与前层连接,相较于残差网络可获取更多输入信息,使较浅层网络可提取更丰富的纹理特征。实验结果显示,本文算法的网络结果与NN、Liner、Bicubic 插值、SRCNN、ResNet 超分辨率重建算法相比,在拥有较少网络层次与参数条件下,获得了更好视觉效果与更高评价指标。
1 相关理论
1.1 ResNet算法
在卷积神经网络中,随着网络深度的加深,梯度消失问题愈加明显。针对此问题,ResNet 有较好的表现。ResNet 结构较SRCNN 复杂很多,网络中使用了16 层的残差块,如图1所示,很大程度上加大了网络对图像纹理的学习。

图1 ResNet残差块Fig.1 Residual block of ResNet

其中:x为输入;y为输出;F(x)为残差映射。ResNet 中残差块宽度有两层:第一层是堆叠的Conv、批量正则化(Batch Normalization,BN)层、ReLU、Conv、BN;第二层是从x连接到BN 的跳层连接,x与F(x)直接相加的前提为Conv 没有改变x的维度。当F(x) →0 时,残差结构y=F(x) +x退化为y=x,即残差网络训练最差结果是退化为未添加残差映射F(x)的结构。残差块在前向传播时,浅层特征可以在深层得到重用。反向传播时,深层梯度可直接传回浅层。
ResNet 的跳层结构一定程度上解决了网络加深出现的原始特征的部分丢失和梯度消失问题。但是跳层结构将网络中层数靠前的输出x与残差块输出直接相加,低层与高层的特征图有较大的特征差异,可能影响网络中图像特征参数信息更好的流动。
1.2 DenseNet算法
DenseNet[20]不是通过加深网络层数和加宽网络结构提升网络性能而是通过特征重用提升网络的效率。相较于ResNet,DenseNet 提出了一个密集连接机制,每层都会与前面所有层进行连接,作为其额外的数据输入,使较浅层的网络也可提取更丰富的图像特征。同时DenseNet 大量用到跳层结构,使梯度消失问题得到优化。DenseNet 的密集连接机制如图2 所示。

图2 密集块Fig.2 Dense block
密集连接将浅层的图像原始特征与深层学习的高频特征进行叠加,在原始特征保留的基础上,添加高频纹理特征,也可弥补网络学习过程中丢失的原始信息。
2 轻量密集神经网络
2.1 改进思想
网络的宽度和深度影响网络的性能,特征重用影响网络的效率。本文基于这三点在ResNet 和DenseNet 的基础上进行了改进。通过增加网络架构的层数使深度增加,通过改进层与层的连接机制使宽度增加。深层的网络结构意味着需要训练更多的参数、更长的训练时间、更高的计算机性能。浅层的网络结构虽然不易产生特征丢失与梯度弥散,但往往难以提取出高频纹理信息。本文在宽度与深度之间寻求平衡,在保证浅层网络架构的前提下,加强特征的重用,尽可能地学习高层次的纹理信息,使医学图像得到更优的重建效果。
所以本文采用密集连接机制改善网络层数过浅带来的一系列问题,使深层网络能更快更好地达到收敛的效果。本文改进后的网络结构有跳层连接,可学习到更多的局部特征;同时,对2 倍HR 图像与4 倍HR 图像都进行损失函数运算,更好地指导网络中的参数进行调节优化。最终本文提出8 层的基于双任务损失的轻量密集神经网络图像超分辨率改进算法。
2.2 网络结构
轻量密集神经网络(Lightweight Dense Neural Network,LDNN)的设计采用了与加速的超分辨率卷积神经网络(Fast Super-Resolution CNN,FSRCNN)相同的8 层网络架构,较浅的层数使网络可以达到实时的效果。但同样层数浅会导致网络中无法提取更丰富的图片特征,特征也无法进行更好的拟合;于是本文采用了密集连接,不仅增加了网络的宽度,而且使每层有限的特征达到了更好的传递和重用的效果,弥补了层数较浅的不足。
图3 是本文构建的一种轻量密集神经网络,LDNN 使用3×24×24 的LR 图像作为输入,使用大小为5×5 的卷积核Conv1 提取特征,输出256×24×24 的特征图。将特征图增加到256,可以拓宽网络的特征维度,使图像特征更好的传播。接着输入到密集块中学习图像的高级特征,分别是大小为1×1 的Conv2,大小为3×3 的Conv3,大小为1×1 的Conv4,此3层的步长为1,padding 为SAME,输出256×24×24 的特征图。ReLU1 到ReLU4 间的密集连接是256 个特征图像素的相加,方便每一层可以利用之前层学习到的所有的特征,有利于浅层与深层特征的融合。

图3 轻量密集神经网络结构Fig.3 Structure of lightweight dense neural network
最后使用大小为9×9 的转置卷积DeConv1 对图像进行上采样,输出大小256×48×48 的特征图,再输入大小为3×3 的卷积核Conv5,输出大小为3×48×48 的2 倍HR 图像Output×2。同时使用9×9 大小的转置卷积DeConv2 对图像进行上采样,输出3×96×96 的4 倍HR 图像Output×4。本文网络将LR 图像分两条支路进行超分辨率重建,2 倍HR 图像和4 倍HR 图像处分别有均方误差损失函数对网络进行监督指导。
由于本文针对图像的4 倍超分辨率进行研究,浅层与深层特征差异大,于是在密集块中使用了BN 给数据进行归一化,易于网络的训练。在BN 层后,使用ReLU 激活函数提高网络的非线性建模能力。
2.3 双任务损失函数
本文使用均方误差(Mean-Square Error,MSE)作为损失函数。由于网络结构有两条支路,因此设置了两个损失函数,分别对应图3 的Output×2 和Output×4。构建双任务损失函数如下:

当网络迭代次数至5×104时,网络的损失变化曲线逐步平稳。

图4 单任务损失变化Fig.4 Changes in single-task loss
当本文的网络结构使用损失函数为式(4)时,训练结果如图5 所示。

图5 双任务损失变化Fig.5 Changes in dual-task loss

当网络迭代次数至3×104时,网络的损失变化曲线已逐步平稳。由此可以得出,两条支路同时进行损失计算可加快网络的收敛速度。
3 实验与结果分析
3.1 数据集预处理
训练数据集:为验证本文所提LDNN 算法的有效性,本文采用了两个数据集:一个是拥有127 万张图像的ImageNet的图像识别竞赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge)2014 数据集[16];另一个是962 张肺部医学图像,数据集由Kaggle 肺部癌症识别比赛提供。
ImageNet 数据集处理:任意挑选35 万张图片,并统一压缩为256×256 大小的图像,接着用随机裁剪的方式截取96×96 大小的图像片段作为HR 标签。对96×96 的原图像进行区域插值Area 下采样得到大小为24×24 与48×48 的标签。高斯滤波核大小为5×5,δ=1.5。24×24 的LR 图像作为网络的输入。
医学图像数据集处理:将原图像重采样成512×512 大小,并转为jpg 格式的RGB 图片,以随机位置截取96×96 大小的图像片段,得到HR 标签。LR 训练图像为24×24,由随机碎片图像Area 下采样得到。其余处理同ImageNet 数据集。
3.2 训练
训练方式一:使用肺部医学图像训练模型,运用Minibacth 训练方式,bacth-size 大小为16,采用Adam 优化方法自动调节学习率,学习率初始设置为10-4,训练6×104次,学习率更改为10-5,接着训练14×104次。
训练方式二:网络先通过自然图像训练105次,接着用医学图像数据集训练105次,优化器、学习率等都与方式一相同。图6 为SRCNN 两种训练方式的对比,图7 为LDNN 两种训练方式的对比。

图6 SRCNN两种训练方式对比Fig.6 Comparison of two training methods of SRCNN

图7 LDNN两种训练方式对比Fig.7 Comparison of two training methods of LDNN
ImageNet 数据集中的自然图像包含复杂的场景和丰富的高频纹理信息。肺部图像数据集的纹理特征相近、灰度不连续。场景更加丰富的自然图像更利于网络参数学习,可避免网络训练过程中过拟合。在自然图像训练的基础上,再使用肺部图像进行训练,从而重建出与肺部图像相关的特征。实验结果如图6~7 所示,训练方式二的HR 重建效果略高于训练方式一,图像纹理更清晰。
3.3 实验结果与分析
为验证本文算法LDNN 的有效性,使用ImageNet 数据集和Kaggle 肺部癌症识别比赛提供的医学图像数据集对各网络结构进行4 倍的HR 训练,以峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似性(Structural SIMilarity,SSIM)作为评价指标。
本文所使用GPU 处理器是NVIDIA Tesla M40,使用Tensorflow 深度学习框架作为开发和训练工具,运用Python3.5 进行仿真。本文所提到的方法都是基于原论文中论述的模型,在以上的环境中进行验证,并对医学图像超分辨率的结果进行了评估。与传统的超分辨率方法、基于深度学习的超分辨率算法(例如SRCNN、ResNet、WDSR),以及作者曾提出的DTLCNN、MCRCNN-apart 和MSRCNN-fast 三种SR 算法[19]进行对比分析。
在测试集的8 幅肺部图像中选了2 幅图像与其他算法进行对比,实验结果如图8 所示。实验测试指标见表1,其中平均PSNR、平均SSIM 为8 幅测试图像的PSNR 和SSIM 均值。实验证明LDNN 算法有较高的应用价值。

图8 各算法的实验结果Fig.8 Experimental results of each algorithm
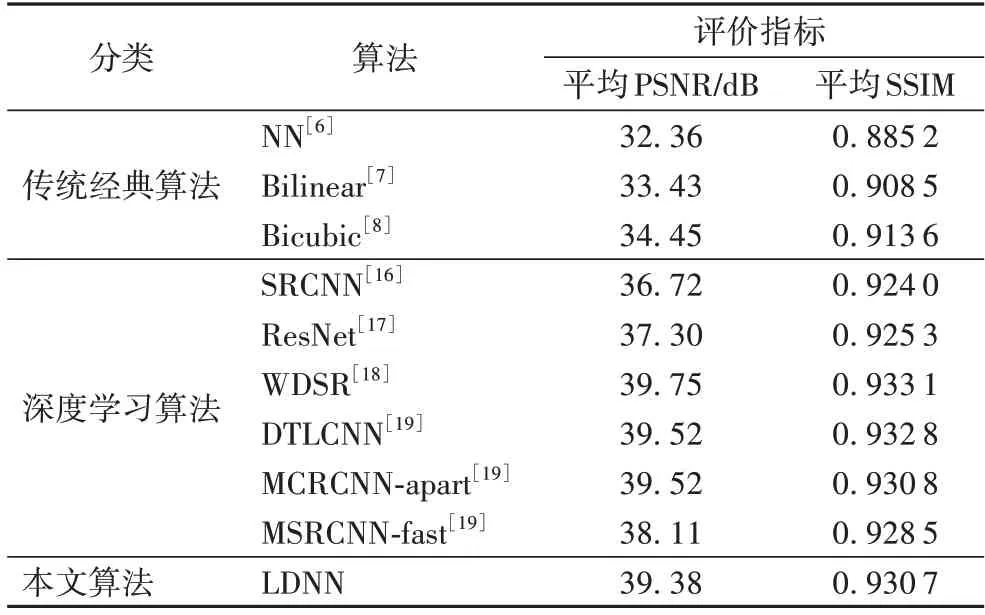
表1 各算法的平均PSNR和平均SSIMTab.1 Average PSNR and SSIM of each algorithm
图8 中可明显看出:NN、Biliiner 和Bicubic 方法重建的肺中叶图像有锯齿和棋盘效应,纹理边缘不平滑;SRCNN 与ResNet 相较于传统超分辨率算法细节表现较好但缺少高频纹理。WDSR 用到16 个残差块,层数达到50,通过扩大残差块中ReLU 前的特征图数量,使有用的信息尽可能地传递到网络的后端,比ResNet 重建出的信息更加接近原始图像。
作者之前提出算法中,72 层的DTLCNN 与38 层的MCRCNN-apart 表现与50 层的WDSR 相近。MSRCNN-fast 为获得更好的算法实时性及对硬件的低要求,层数设计为6,但相应算法超分辨率重建效果明显相对较弱。本文提出的LDNN 相较于前三者层数为8,网络中使用密集网络增强网络中的信息流动,使低层信息更易传递到高层,在保证了对智能终端的低硬件要求以及算法运行的实时性的同时,超分辨率重建效果仍在较高水平,与DTLCNN 和MCRCNN-apart的重建效果相差不大,性能远高于MSRCNN-fast、SRCNN、ResNet 和传统经典算法。LDNN 相较于WDSR,训练过程中参数量更少,训练速度更快,在医学影像超分辨率上显示出了更好的细节收益以及更少的噪声,重建效果相差无几,为大多数智能终端的硬件运行医学图像超分辨率重建网络模型提供了可能性。从表1 中的评价指标可发现LDNN 相较于NN、Liner、Bicubic 插值以及SRCNN、ResNet 都取得了更好的结果。
4 结语
深度学习的发展为图像超分辨率重建提供了新的思路。本文提出一种解决医学影像问题的图像超分辨率重建算法LDNN。LDNN 算法可用于人任何部位的医学图像,可将医学图像放大4 倍。对比实验显示,对于4 倍医学HR 图像,LDNN 算法的评价指标均显著高于NN、Liner、Bicubic 插值以及SRCNN、ResNet 等SR 算法。重建出的HR 医学图像有更好的细节收益和更少的伪影信息。LDNN 的网络结构较浅,可达到较好的实时处理效果。下一步可在保持网络实时性的前提下,尝试进一步提高网络的精度。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
北京大学学报(自然科学版)(2022年1期)2022-02-21
今日农业(2021年9期)2021-11-26
英语文摘(2021年2期)2021-07-22
北京航空航天大学学报(2020年10期)2020-11-14
家庭影院技术(2020年2期)2020-03-25
北京航空航天大学学报(2019年9期)2019-10-26
汉语世界(The World of Chinese)(2018年6期)2018-01-22
CHIP新电脑(2016年3期)2016-03-10
BOSS臻品(2015年1期)2015-09-10
