
多目标混合进化算法求解加工时间可控的开放车间调度问题
2022-08-24 06:30陈揆能袁小芳
计算机应用 2022年8期
陈揆能,袁小芳
(1.复杂环境特种机器人控制技术与装备湖南省工程研究中心(湖南理工职业技术学院),湖南湘潭 411104;2.湖南大学电气与信息工程学院,长沙 410082)
0 引言
开放车间调度问题(Open-shop Scheduling Problem,OSP)作为智能制造领域的重点研究问题,广泛存在于检测、维修、加工等生产制造行业[1],对该问题的深入研究有重要理论和应用价值。目前,大多数OSP 相关文献只考虑了固定的工序加工时间。然而,随着加工制造技术的发展,以数控加工(Computer Numerical Control,CNC)机床为代表的先进加工设备可以通过调节加工功率控制加工时间[2-3],并且缩短加工时间通常需要更高的加工能耗。因此,同时优化完工时间和总加工能耗对高效、节能的开放车间生产具有重要意义。为此,本文研究了可控加工时间的多目标开放车间调度问题(Multi-Objective Open-shop Scheduling Problem with Controllable Processing Time,MOOSPCPT)问题。
OSP 属于NP-hard 问题[4],精确算法很难在合理的时间内找到满足精度要求的近似解。因此,近年来研究人员多采用群体进化算法对相关问题进行求解。Rahmani Hosseinabadi 等[5]和Shareh 等[6]分别提出了一种扩展遗传算法和改进蝙蝠优化算法求解OSP。Abreu 等[7]针对连续加工工序之间存在设置时间的OSP 进行了研究并提出一种混合遗传算法对问题进行求解。Mejía 等[8]和Zhuang 等[9]对考虑工序设置时间和机器运输时间的OSP 进行了研究。Sheikhalishahi 等[10]针对考虑人为失误与机器维修生产因素在内的多目标OSP 进行了研究。然而,目前对OSP 的研究多集中在理论层面,提出的基本算法框架通常无法完全适用于实际问题的求解。因此,依据问题特性设计改进的混合进化算法成为行业内研究的热点问题之一,开发高效的全局搜索算子和局部搜索算子是研究的核心内容。
生物地理学优化(Biogeography-Based Optimization,BBO)算法是由Simon[11]提出的基于种群的新型元启发式方法,常用于全局搜索。BBO 算法通过迁移策略实现不同解之间的信息交流,通过变异策略实现解的内部进化,具有参数少、收敛速度快的优点[12],广泛应用于车间调度等NP-hard问题求解。张国辉等[13]将BBO 算法应用于柔性作业车间调度问题的求解。Wang 等[14]以最小化总延迟时间为目标,提出了一种混合BBO 算法用于解决流水车间调度问题。吴定会等[15]将BBO 算法应用于求解多目标柔性车间调度问题并取得了良好的效果。然而,由于BBO 中解的迁移概率与解之间的优劣关系直接相关,容易使种群多样性降低,导致算法陷入局部最优。为此,本文改进了传统的迁移策略和变异策略用于平衡算法的开发能力与探索能力。
变邻域搜索(Variable Neighborhood Search,VNS)通过系统化地移动当前解到其邻域解空间中的“邻居”位置以实现局部搜索。变邻域搜索显著的特点之一是可以很好地结合问题知识进行邻域结构的设计,从而实现对当前解的规则化的移动,降低搜索的随机性,极大地提高搜索的效率和精度。关键路径是生产调度问题重要的知识,因此,基于关键路径的变邻域搜索得到了广泛的研究。Xia 等[16]针对动态集成工艺规划与调度问题设计了一种混合遗传算法,并使用基于关键路径的变邻域搜索算法增强了算法的搜索能力。Yuan等[17]在差分进化算法中加入了基于关键路径的邻域搜索策略,并对柔性作业车间调度问题进行求解。赵诗奎[18]开发了一种基于关键路径的两级邻域搜索算法,该算法用于求解时间最小化的柔性作业车间调度问题。目前,应用变邻域搜索算法求解开放车间调度问题的研究相对匮乏。为此,本文设计了一种基于关键路径的自调整变邻域搜索用于提高算法的局部搜索性能。
本文的主要工作包括:1)在开放车间环境下考虑可控的加工时间,同时优化了完工时间和总额外能耗,既有效地提高了生产效率又满足当下绿色制造的重大需求;2)设计了高效的多目标混合进化算法(Multi-Objective Hybrid Evolutionary Algorithm,MOHEA)求解MOOSPCPT,在MOHEA 中提出了一系列改进策略,丰富了生产调度优化问题的求解方法。
1 问题描述与模型
本文提出的MOOSPCPT 可以描述为:有n个待加工工件,第i个工件为Ji(i=1,2,…,n);共在m台机器上加工,第j台机器为Mj(j=1,2,…,m);每个工件包含与机器数量相等的工序,且每个工序唯一对应一个机器进行加工;Oij表示Ji由Mj负责加工的工序。同工件的工序之间不存在优先关系。工序的加工时间可以通过调节机器的输出功率控制,对于同一台机器加工同一个工序而言,较短的加工时间对应较高的加工能耗,以最长加工时间对应的能耗为基础能耗,则实际能耗与基础能耗的差值为额外能耗。
因此,MOOSPCPT 包含2 个子问题:安排最优的工序加工顺序,确定各工序最优的加工时间。本文通过解决上述两个子问题同时优化完工时间和总额外能耗。模型中所用到的符号及其含义如表1 所示。
MOOSPCPT 的目标函数为:

其中:式(1)为目标函数——最小化完工时间;式(2)为目标函数——最小化总额外能耗;式(3)表示Oij的实际加工时间在取值范围内;式(4)表示加工一旦开始就不允许中断;式(5)表示同一个工件不能同时在两台机器上加工;式(6)表示同一台机器在同一时刻只能加工一个工件。
2 多目标优化问题及评价指标
与单目标决策可以获得单一最优解不同,多目标优化问题中各个目标函数之间通常是相互冲突的,即一个目标的改进会导致另一个目标的退化。一般多目标问题可以表示为:

如果解向量X不被其他任何解向量所支配,则称X为Pareto 最优解,一组Pareto 最优解称为Pareto 最优解集,问题的所有Pareto 最优解称为Pareto 前沿。多目标优化问题的目标在于尽可能多地找到接近真实Pareto 前沿的解。
本文使用三个通用的性能指标定量衡量算法获得的Pareto 前沿的优劣:
1)GD(Generational Distance):用于表征算法的收敛性。GD 值越小,算法的收敛性越好,其定义为:

其中:N为Pareto 前沿中解的个数;di为Pareto 前沿中第i个解与真实的Pareto 前沿中距离其最近解之间的欧氏距离。
2)IGD(Inverse Generational Distance):用于表征算法包括收敛性和分散性在内的综合性能。IGD 越小,算法的综合性能越好,其定义为:

其中:N为真实Pareto 前沿中解的个数;Dj为真实Pareto 前沿中第j个解与算法得到的Pareto 前沿中与其距离最近的解之间的欧氏距离。
3)Δ(Spread):用于表征Pareto 前沿的分布性与多样性,Δ越小,代表Pareto 前沿的分布性与多样性越好。Δ定义为:

其中:N是Pareto 前沿中解的个数;M为目标函数个数;di、代表Pareto 前沿中第i个解与最近解之间的欧几里得距离,dˉ代表所有di的平均值;dl为Pareto 前沿中第l个目标上的极值解与Pareto 前沿边界解的欧氏距离。
由于MOOSPCPT 的真实Pareto 前沿未知,本文将所有单独求得的Pareto 前沿合并,得到的新Pareto 前沿视为真实Pareto 前沿。
3 MOHEA求解MOOSPCPT
3.1 MOHEA的基本流程
本文所提出的MOHEA 的基本流程如下:
输入参数:种群数量n,最大迁入率I,最大迁出率E,最大变异率mmax,最大迭代数gmax,变邻域搜索初始概率pv,精英库大小nA。
步骤1 初始化:随机产生初始种群。
步骤2 全局搜索:对种群进行快速非支配排序与拥挤度排序,计算得到栖息地的迁入迁出率。对种群进行迁移变异操作产生新解,如果新解优于原来的解则用新解替代旧解。
步骤3 局部搜索:对种群执行基于关键路径的自调整变邻域搜索操作,并更新变邻域搜索概率pv。
步骤4 时间重置并更新精英库:对当前种群Pareto 前沿解进行时间重置。将得到的解与当前精英库中的解合并,并保留新的Pareto 前沿;
步骤5 终止判断:判断是否达到最大迭代次数,是则结束算法,输出精英库;否则转步骤2。
3.2 编码与解码
与普通的开放车间调度问题相比,本文需要额外考虑工序的加工时间。因此,本文采用的编码由加工顺序(Processing Sequence,PS)和工序时间(Processing Time,PT)两部分组成。PS 为1 到n×m的一个随机排列,PS 中的元素代表元素中的数值与固定编号对应的工序;PT 中的元素表示与固定编号对应的工序的加工时间。下面通过一个示例展示编码过程。表2 为一个3×3(n×m)的算例,针对该算例的一个个体编码如图1 所示。PS 中包含一个1~9 的随机排列。PS 第1 个元素值为6,代表编号6 对应的工序O23第1 个加工;同理,如PS 第5 个元素值为9,代表编号9 对应的工序O33第5 个加工。PT 第1 个元素为30,代表编号1 对应的工序O11的加工时间为30 个单位时间;同理,如第9 个元素代表编号9 对应的工序O33的加工时间为28 个单位时间。
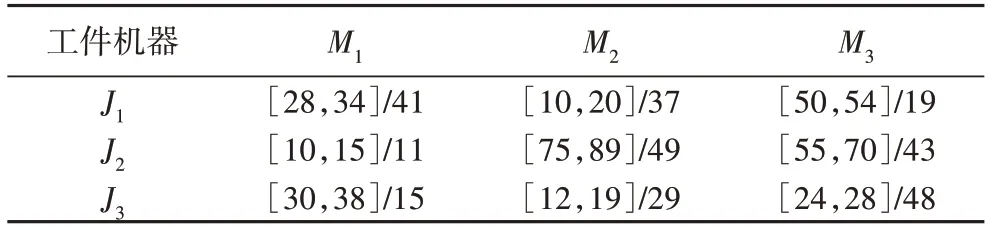
表2 示例的加工信息Tab.2 Processing information of example
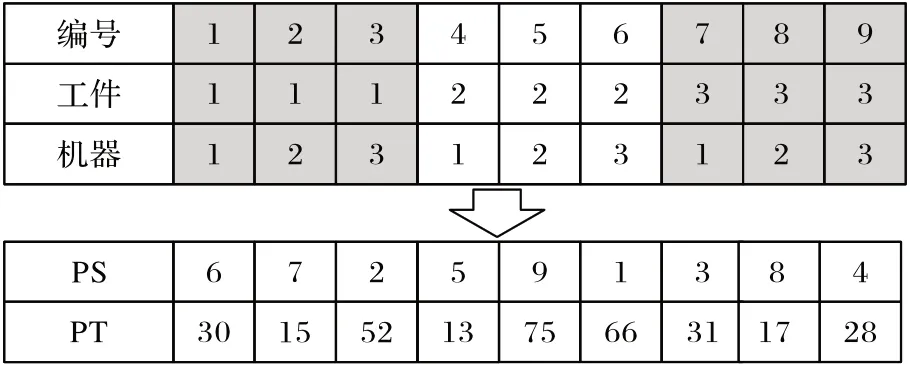
图1 个体编码示意图Fig.1 Schematic diagram of individual encoding
本文采用常用的主动调度[19]解码方式,基本过程如下:按照从左至右的顺序遍历PS 对应的工件;在不推迟其他当前已经安排的工序的前提下,将工序安排在其加工机器上尽可能早的时间开始加工;该工件的加工时间为PT 序列中对应的时间。
为了更加清晰地描述解码过程,对图1 所示编码进行解码。对于同一工序在同一机器上加工,其加工时间越短额外加工能耗越高。因此,本文使用反比例函数刻画机器额外加工能耗随工序加工时间变化的特性,加工Oij的额外加工能耗由式(12)得到。图2 为解码获得的甘特图。可以得到其完工时间为154 个单位时间,总额外能耗为39 个单位能耗。

图2 个体解码甘特图Fig.2 Gantt chart of individual decoding
3.3 基于BBO的改进迁移策略和变异策略
BBO 通过模拟物种在不同栖息地间的迁移行为对种群进行优化,以栖息地作为个体进行操作。BBO 算法主要包括迁移策略和变异策略。
迁移策略模拟了物种在栖息地之间的迁移行为,物种生存的适宜程度决定了栖息地间的物种迁移概率:适宜程度高的栖息地物种数量趋于饱和,物种迁出率高而迁入率低;适宜程度低的栖息地物种数量较少,物种迁入率高而迁出率低。如图3 所示为单个栖息地的物种线性迁移模型,其中:λ为栖息地的迁入率,最大值为I;μ为栖息地的迁出率,最大值为E,S为栖息地物种适宜度;Smax为栖息地物种适宜度最大值。当栖息地迁入率与迁出率相等时,栖息地种群数量达到动态平衡点S0。
变异策略是BBO 算法中另一个重要的搜索策略。变异过程模拟了自然界中由于栖息地环境发生改变引起的栖息地内部的物种进化,用于对个体产生小范围的扰动。积极的变异(如:新物种的出现、附近物种的迁入等)能够有效提升种群的多样性,而消极事件(如:疾病、贪婪捕食者入侵等)引起的突变将降低种群多样性。因此,在设计变异策略时应该更多地引入积极的变异并尽量降低消极事件对种群的影响。图3 为线性迁移模型。当栖息地迁入率等于迁出率时,该栖息地物种种群数量达到动态平衡点S0,迁入该栖息地的种群数量等于迁出该栖息地的种群数量;当栖息地的环境变化平衡点发生偏移(S0增大为正偏移,减小为负偏移):S0增大是由于其他种群突然迁入,例如大量生物从附近栖息地迁入或由于基因突变导致大量的新物种出现;S0减小是由于疾病、贪婪捕食者入侵或一些自然大灾害导致的栖息地种群数急剧减少。
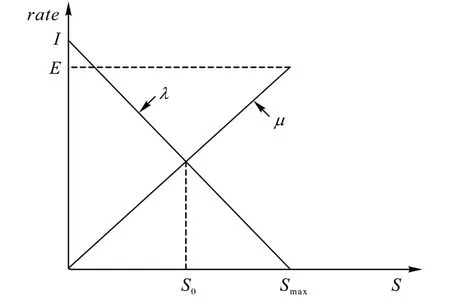
图3 线性迁移模型Fig.3 Linear migration model
本文采用上述BBO 算法的迁移策略对PS 编码进行迁移操作,采用变异策略对PS 编码和PT 编码进行变异操作。其中,每个个体代表一个栖息地,个体优劣的排名代表栖息地物种适应度,迁移概率用于选择个体进行迁移,变异概率用于控制个体是否进行变异。同时,针对BBO 算法易陷入局部最优的缺点,本文对迁移概率和变异概率进行了改进。
为适应多目标问题的求解,本文在计算栖息地的迁入迁出率之前,先对栖息地进行非支配关系和拥挤度排序[20],并根据计算结果将种群按照优劣关系进行排序。其中,最劣的个体排序为1,最优的个体排序为种群数n。以排序为个体i的适应度Si,则Smax=n。
3.3.1 改进迁移策略
本文对传统迁移策略进行改进:在种群进化早期将迁移率设为常数保证种群的多样性,从而获得较好的全局搜索性能;在进化后期迁移率与个体适应度的优劣程度相关,使算法能够进行充分的局部搜索,从而获得更加精确的解。迁入率和迁出率随迭代次数的变化如式(13)~(14)所示:
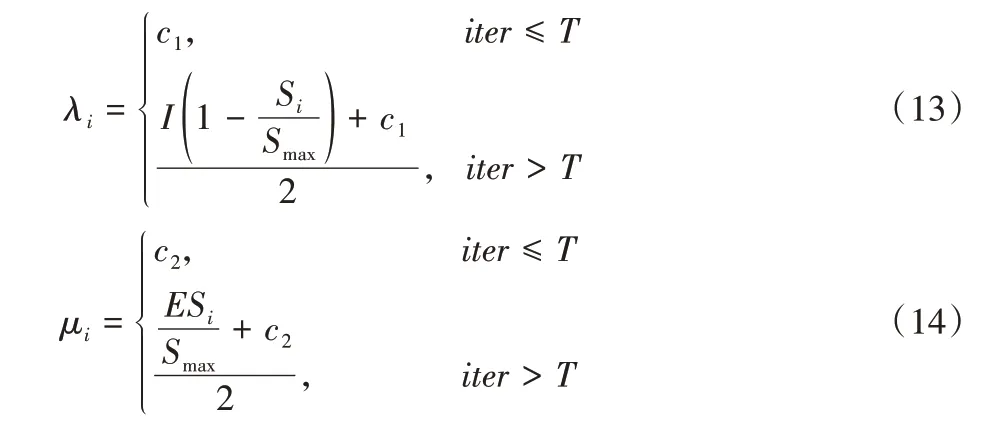
其中:λi和μi分别为Si个体的迁入率和迁出率;c1和c2分别为种群进化早期迁入率和迁出率常数(c1,c2∈[0,1]);iter为当前迭代次数;T为常数。T值较小时会获得较快的收敛速度但全局搜索能力较差,且T与c1、c2之间相互影响,为平衡迁移策略的全局搜索能力和局部搜索能力,实际应用时通过正交实验确定c1、c2和T的具体取值。
迁移策略的伪码如下所示:

第10)行所述的迁移操作过程如图4 所示:1)随机产生两个迁移位点将迁入个体Hi和迁出个体Hj的PS 编码分成3段;2)将迁入个体Hi的中间一段迁入新个体Hk中;3)迁出个体Hj中第1 段和第3 段的元素按照迁出个体Hj中对应元素的顺序填入Hk中的剩余位置。
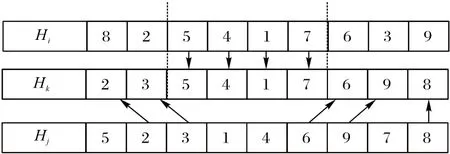
图4 迁移过程示意图Fig.4 Schematic diagram of migration process
3.3.2 改进变异策略
变异策略算法对防止过早收敛具有重要作用。本文对固定变异概率的方式进行了改进:按照个体的优劣采用不同的变异概率,对于特别优或者特别劣的个体变异概率大,从而实现较大范围的局部搜索。Si个体的变异概率定义为:

其中:mmax为最大变异率。
本文通过比较随机数r(0<r<1)与Si个体的变异概率mi控制Si个体是否进行变异:若r<mi,则对Si个体执行变异操作。变异操作包括PS 编码变异和PT 编码变异。其中,PS 编码变异:随机选择PS 编码中的两个元素进行互换;PT 编码变异:在PT 编码中随机选择一个元素,在该元素对应的工序加工时间取值范围内随机选择一个与当前加工时间不相等的值。
3.4 基于关键路径的自调整变邻域搜索
变邻域搜索能快速改善解的质量,加快算法收敛速度。然而,在算法迭代过程中全局搜索的进度往往难以匹配邻域搜索的进度,导致变邻域搜索很难继续对解进行有效的改进,反而由于无效的邻域搜索耗费了大量的时间,影响了算法最终的性能。为了解决这一问题,本文提出了一个自调整选择策略:定义一个变邻域搜索概率pv,当产生的随机数小于pv时,对当前种群执行变邻域搜索;同时,变邻域搜索算法可以根据对邻域搜索结果的分析,自动地调整pv的值,即在邻域搜索对解改进大时增大pv的值,在邻域搜索对解改进小时减小pv的值。
自调整pv的过程为:设定变邻域搜索初始概率pv(本文设为0.4);当前种群的Pareto 前沿PX包含x个非支配解,经过变邻域搜索操作得到新的Pareto 前沿PY包含y个非支配解,定义计数器c=0;对于PY中的每一个解,如果在PX中找到被其支配的解,则c=c+1。定义变量Ra=c/(xy),则下一次迭代时pv由式(16)计算得到:
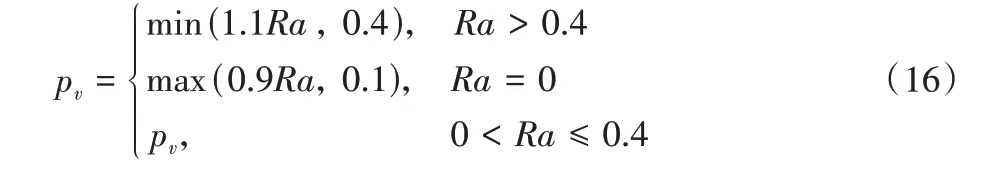
关键路径是在变邻域搜索中常用的问题知识。析取图中从起点到终点的最长路径称为关键路径[21],关键路径上的工序称为关键工序,同一机器上相邻工序组成工序块,工序块中第一道工序称为块首工序,最后一道工序称为块尾工序,其余为块内工序。研究表明:对关键路径上的工序块进行邻域搜索是改善解质量的最有效方式之一[22]。因此,本文采用了基于关键路径的三种邻域结构[23]进行邻域搜索。对于关键工序块L={l1,l2,…,ln-1,ln}[23],这三种邻域结构包括:
1)对块首工序l1与块尾工序ln,将其插入工序块L的内部;
2)对块内工序{l2…ln-1},将其插入块首工序l1之前或块尾工序ln之后;
3)交换工序块前两道工序{l1,l2}或后两道工序{ln-1,ln}。
综上所述,本文所提出的基于关键路径的自调整变邻域搜索步骤如下:
步骤1 生成随机数r,如果r<pv,则进行变邻域搜索,否则结束变邻域搜索;
步骤2 确定选定解的关键路径及关键工序块;
步骤3 随机选择一个未被选中过的关键工序,选取与该关键工序对应的邻域结构对其进行邻域搜索操作,产生新解;
步骤4 若新解支配当前解,则用新解替换当前解,并回到步骤2;否则进入步骤3 直到所有关键工序都被选中过;
步骤5 结束当前解的邻域搜索并选定种群中的下一个解,循环步骤2~5 直到种群中的Pareto 前沿的解都被搜索。
步骤6 根据变邻域搜索结果按照式(16)更新pv的值。
3.5 加工时间重置算子
当一个解中所有工序的起始加工时间确定后,只需调整每个工序的加工时间,就可以在不增大完工时间的前提下得到当前解最小的总额外能耗[1]。为此,本文提出一种工序加工时间重置算子,用于确定解在当前工序的起始加工时间下最优的总额外能耗。
由于本文采取主动解码方式对编码方案进行解码,因此各工序的起始加工时间不可后移。加工时间重置算子在保证所有工序的起始加工时间不变的前提下将所有工序的加工时间尽可能增大,具体扩展规则为:
步骤1 选择选定解的一个未被选中过的工序O;
步骤2 判断:1)编码中工序O同工件上紧邻的后一道工序的开始时间是否等于工序O的结束时间;2)编码中工序O同机器上紧邻的后一道工序的开始时间是否等于工序O的结束时间。若上述两个判断都为否,则工序O存在可扩展的加工时间间隙,转至步骤3;否则转至步骤4。
步骤3 在工序O的加工时间范围内增大其加工时间,直到步骤2 中的判断至少有一个满足时,将此时的加工时间设为工序O的加工时间。
步骤4 若Pareto 前沿中的解都被选中,则终止;否则,转步骤1。
图2 所示个体通过加工时间重置算子优化后得到的结果如图5 所示。将工序O11、O12、O13、O32的加工时间向后扩展(灰色块所示为扩展时间),在总加工时间不变的前提下,加工总额外能耗从39 下降到17,有效地提高了解的质量。
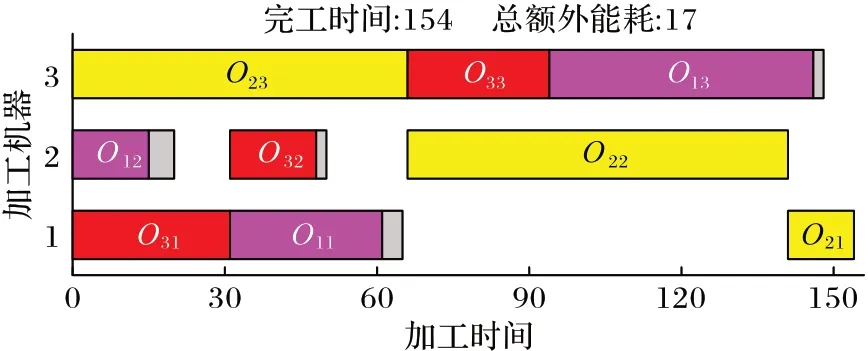
图5 加工时间重置算子示意图Fig.5 Schematic diagram of processing time resetting operator
4 实验与结果分析
为了验证比较算法性能,本文仿真实验所用到的测试算例基于常用的Taillard 系列OSP Benchmarks[24]测试算例集进行拓展。其中,工序的加工时间上界tr为OSP Benchmarks 中的工序加工时间,加工时间下界tl由式(17)产生。
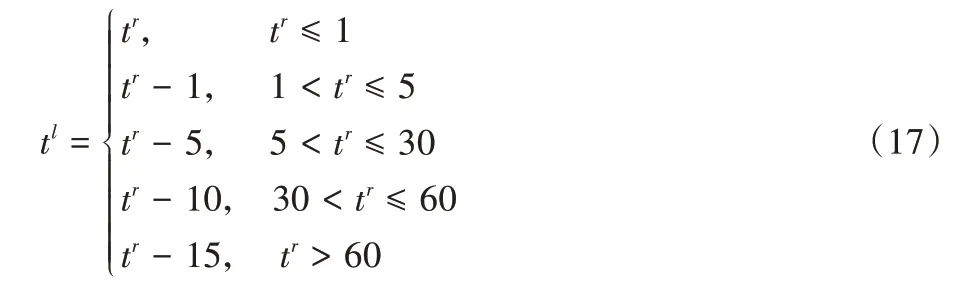
从而产生了与OSP Benchmarks 对应的6 种规模新测试算例,分别为(n×m):4×4、5×5、7×7、10×10、15×15 和20×20,其中每个规模各包含4 个算例,共计24 个算例。为降低随机性的影响,将算法在每个算例运行20 次。所有算法使用Matlab R2018b编程,在 CPU 为 Intel Core i7-8750H(2.20 GHz),内存为4 GB 的环境下运行。
c1、c2和T为MOHEA 的重要参数,本文通过正交实验确定其具体取值。在参数的取值范围内均匀选择了5 个水平,如表3 所示。其中,参数T用于表征进化初期的迭代次数,因此在[0.1×Maxiter,0.5×Maxiter]内取值较为合适。选择了正交实验表L25 进行实验,实验在算例5×5、10×10、15×15 上分别运行20 次,并用获得非支配解级的IGD 值作为评价指标,如表4 所示。对各组IGD 结果进行处理,得到各参数对结果的影响,如表5 所示。可以看出优势水平为c1的第4 水平、c2的第4 水平和T的第3 水平。因此,最终确定的参数值为c1=0.7、c2=0.7,T=0.3×MaxIter。

表3 参数各水平取值Tab.3 Values of parameters with different levels
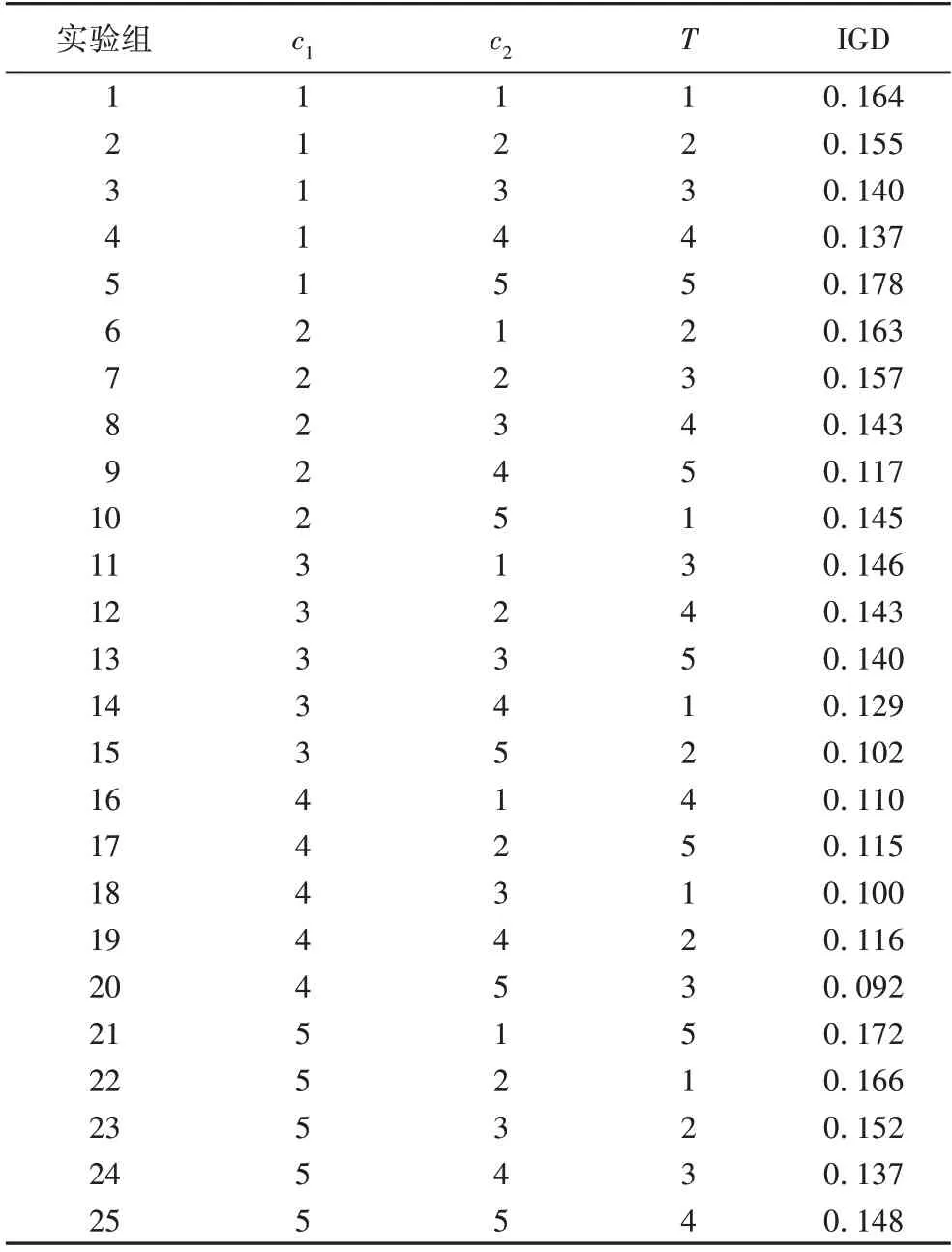
表4 正交实验表及对应平均IGD值Tab.4 Orthogonal experiment table and corresponding average IGD values
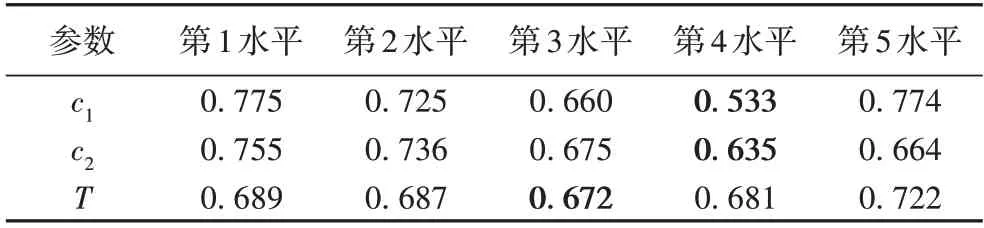
表5 参数水平对应的平均IGD值Tab.5 Average IGD values corresponding to parameter levels
其他参数设置为:种群数n=100,最大迁入率I=1,最大迁出率E=1,最大变异率mmax=0.7。
4.1 新测试算例的收敛时间
算法求解时间应设置在收敛时间附近以得到最优的计算结果。由于新算例的收敛时间未知,首先进行预实验以确定不同测试算例使用MOHEA 求解的收敛时间。预实验基本过程为:1)设置足够长的算法运行终止时间;2)每隔10 s记录一次算法得到的Pareto 前沿;3)计算终止后,计算每个时间间隔采集到的Pareto 前沿解的GD 和IGD 值(算法最终得到的Pareto 前沿看作是算例的真实Pareto 前沿),当GD 和IGD 值不再随计算时间的增加而明显变化则说明计算收敛。
如图6 所示为算例5×5_2 在不同运行时间下Pareto 前沿的GD 和IGD 值。可以看出,当时间到80 s 时,两个指标值基本接近0 并且不再明显变化,表明80 s 时算法得到的结果已经收敛。同理,得到了其他算例的收敛时间如表6 所示。

图6 算例5×5_2的收敛情况Fig.6 Convergence of example 5×5_2
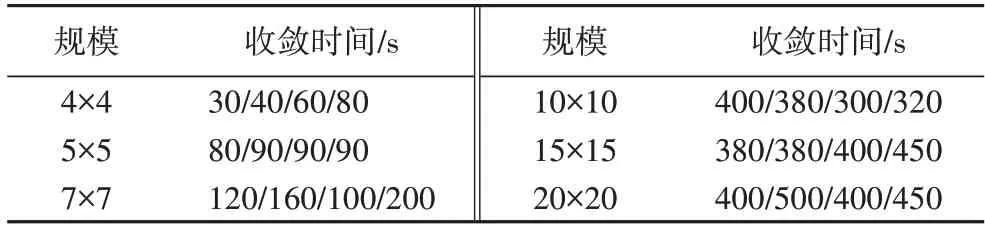
表6 其他算例的收敛时间Tab.6 Convergence times of other examples
4.2 改进策略的有效性验证
为了验证本文所提出的三种改进策略对MOHEA 性能提升的有效性,设计了三个MOHEA 的变体进行对比:1)MOHEA-1,使用传统的迁移变异策略,同时包含自调整变邻域搜索算子与加工时间重置算子;2)MOHEA-2,不包含自调整变邻域搜索算子,仅包含改进迁移与变异策略及加工时间重置算子;3)MOHEA-3,不包含加工时间重置算子,仅包含改进迁移与变异策略及自调整变邻域搜索算子。
将MOHEA 及MOHEA-1、MOHEA-2 和MOHEA-3 在24 个算例上独立运行20 次,GD、IGD 和Δ的统计结果分别如图7~9 所示。图中:A0、A1、A-Ⅱ和A3 分别表示MOHEA、MOHEA-1、MOHEA-2 和MOHEA-3;菱形表示20 次运行结果得到的评价指标平均值;子图名为算例工件数-算例序号。
从图7~9 可以看出:
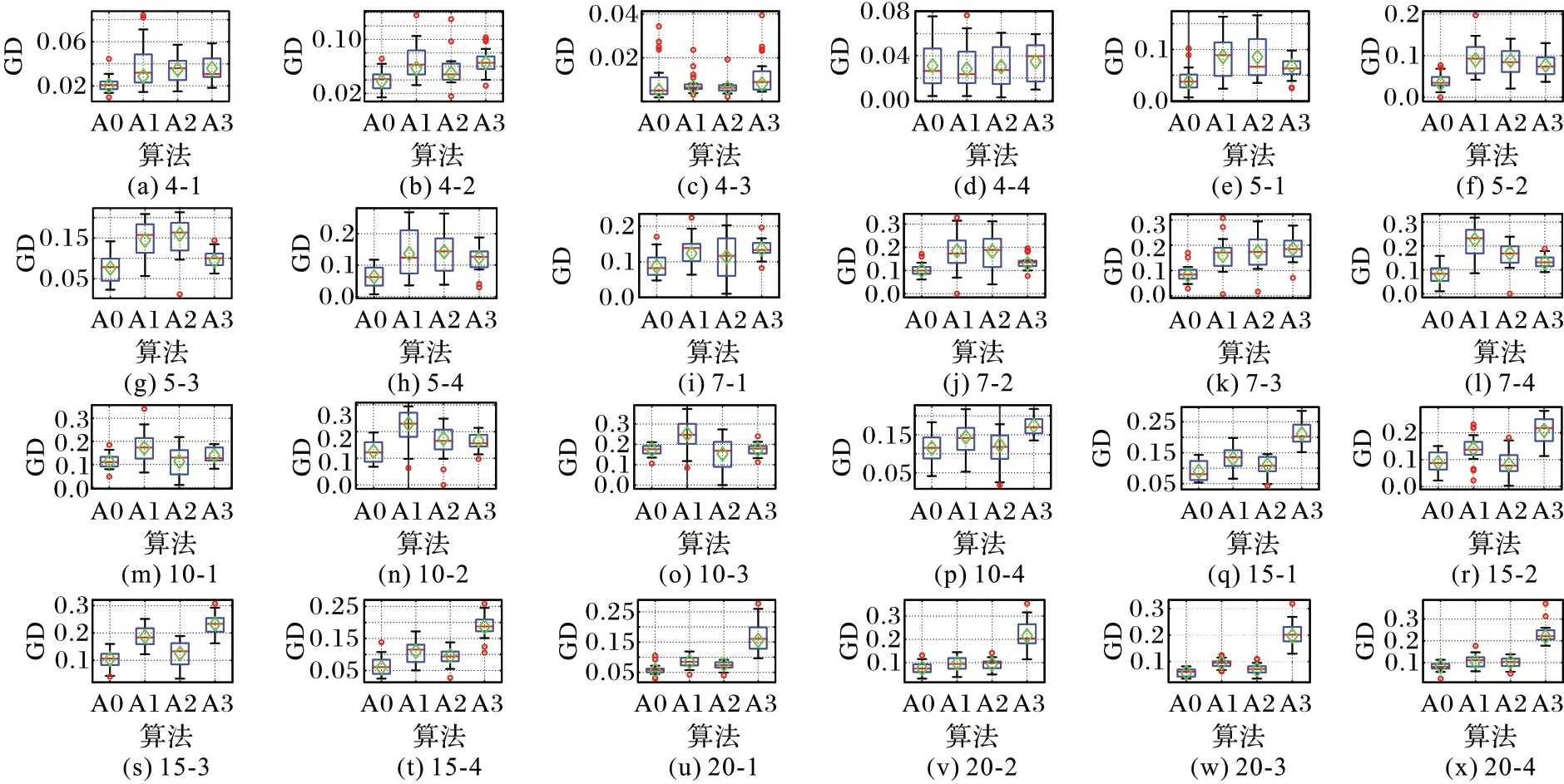
图7 GD结果的箱线图Fig.7 Boxplots of GD results
1)MOHEA 在除4-4、10-3 和15-2 外的所有算例上都获得了最优的GD 均值,因此三种改进策略有效地提升了算法的收敛性;
2)MOHEA 在所有算例上都获得了最优的IGD 均值,因此三种改进策略对算法综合性能有显著提升;
3)可以看出四种算法在Δ方面的差异不大,MOHEA 在除5-2 和20-2 外的所有算例上都获得了最优的Δ均值,因此三种改进策略在对算法求解质量和综合性能提升的同时没有明显影响分布性与多样性;
4)在IGD 方面(图8 所示),MOHEA-1 在小规模算例上(4×4、5×5、7×7、10×10)具有明显的劣势,说明本文提出的改进迁移变异算子对算法综合性能的提升相较于其他两个策略更为显著,归功于改进迁移策略对算法全局搜索能力的提升以及改进变异策略对避免算法过早收敛起到的重要作用;
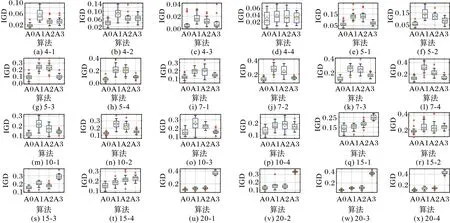
图8 IGD结果的箱线图Fig.8 Boxplots of IGD results
5)MOHEA-3 在大规模算例上(15×15 和20×20)具有非常明显的劣势,表明当问题规模增大或工序加工时间范围增大时,加工时间重置算子能在不增大加工时间的前提下显著降低总额外能耗,从而高效地改进解的质量。
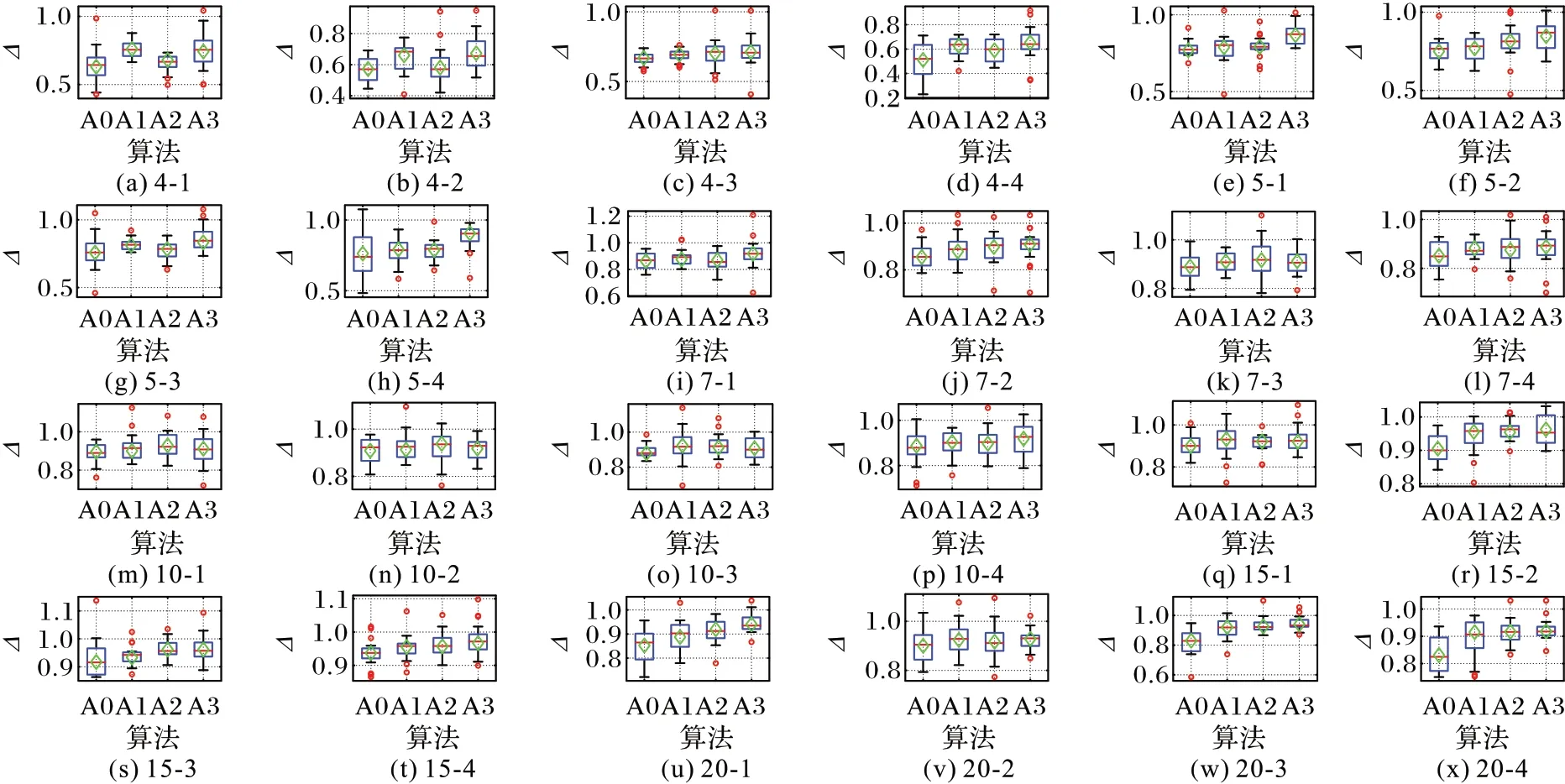
图9 Δ结果的箱线图Fig.9 Boxplots of Δ results
4.3 MOHEA性能验证
为了验证本文提出的MOHEA 的性能,将其与目前广泛应用的多目标求解优化算法NSGA-Ⅱ(Non-dominated Sorting Genetic Algorithm Ⅱ)[25]、NSGA-Ⅲ(Non-dominated Sorting Genetic Algorithm Ⅲ)[26]和 SPEA2(Strength Pareto Evolutionary Algorithm 2)[27]进行比较。对比算法的各参数在文献常用的范围内选取多个取值,然后通过在算例上的仿真进行选优,最终确定的参数值如表7 所示。
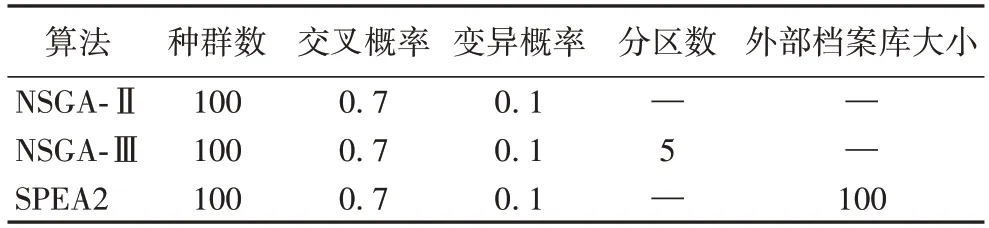
表7 不同算法的参数设置Tab.7 Parameter setting of different algorithms
从表8 所示的评价指标统计结果可以看出:在所有算例上,MOHEA 在GD 和IGD 两个方面均获得了全部的最优均值,因此MOHEA 在求解MOOSPCPT 时要优于另外3 种多目标优化算法;从标准差可以看出,MOHEA 的稳定性也优于另外3 种算法;同时,随着问题规模的增大,MOHEA 的优势更加显著,说明MOHEA 特别适合求解大规模的MOOSPCPT。各算法得到的Pareto 前沿解如图10 所示。
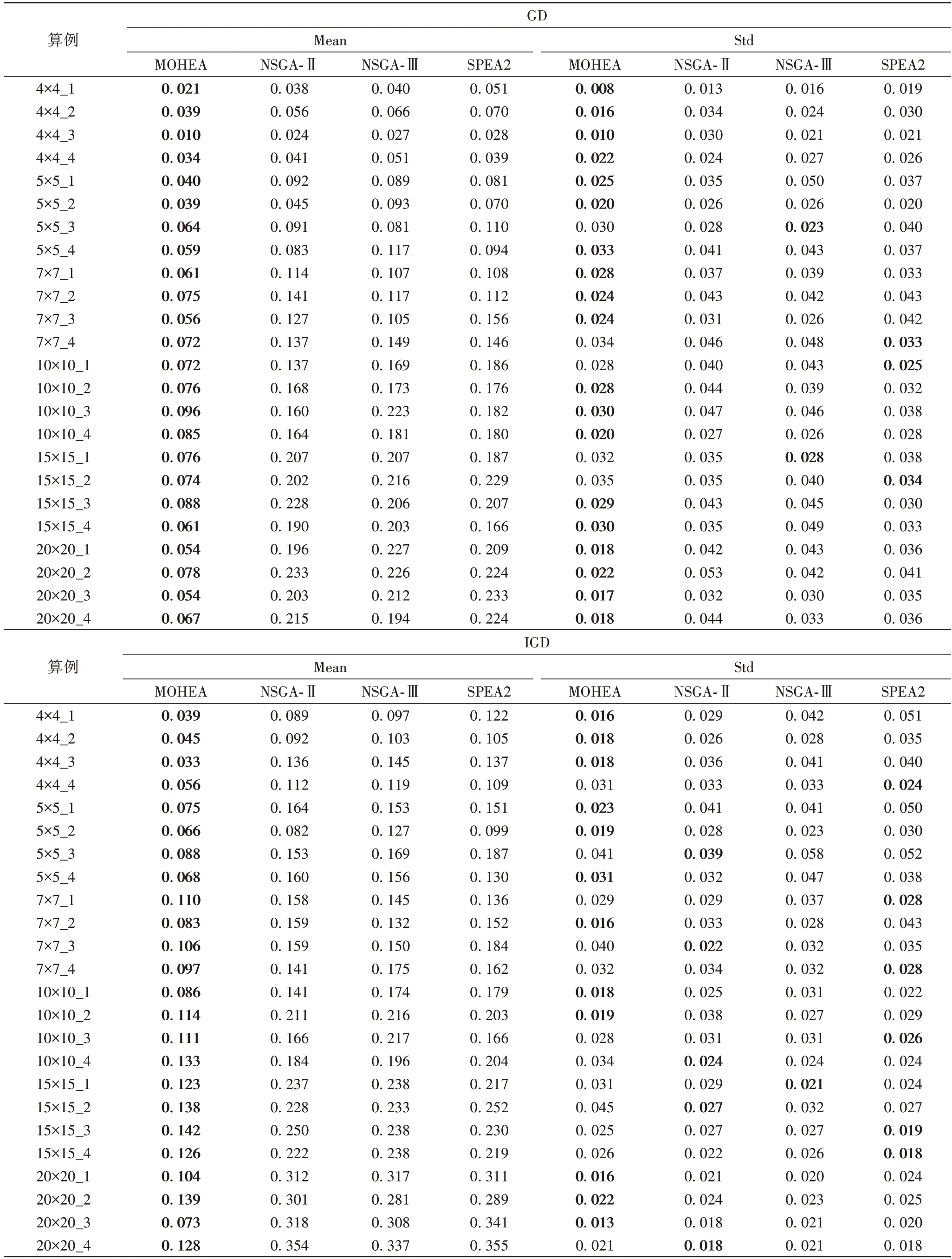
表8 不同算法的计算结果Tab.8 Computational results of different algorithms
从图10 中可以直观地看出:随着问题规模增大,MOHEA 的优势更加明显,且在总额外资源消耗方面,MOHEA 能够求得能耗最小的解。综上所述,相较于NSGA-Ⅱ、NSGA-Ⅲ和SPEA2,本文提出的MOHEA 可以更有效地解决MOOSPCPT。
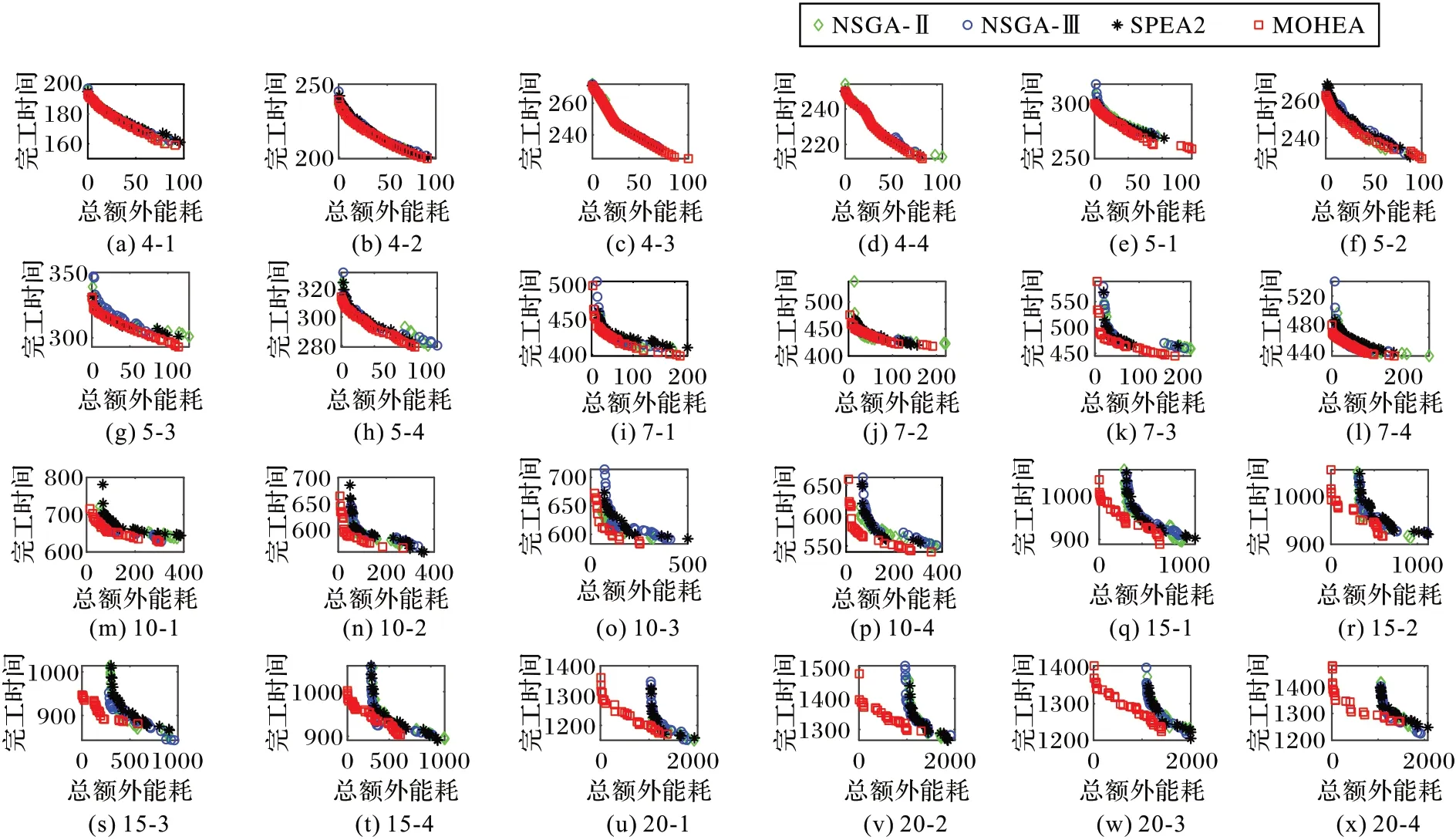
图10 不同算法得到的Pareto前沿Fig.10 Pareto frontiers obtained by different algorithms
4.4 算法时间复杂度分析
对照MOHEA 的基本流程,下面给出MOHEA 各操作策略的时间复杂度:
1)快速非支配排序O(2N2)[25];
2)迁入迁出率计算O(2N)[28];
3)改进迁移变异机制O(N)[28];
4)自适应变邻域搜索O(N4)[29];
5)精英解时间重置策略O(N)。
因此,MOHEA 的时间复杂度为O(N4)。同时,理论上耗时最长的策略为变邻域搜索,与仿真实验的结果一致。结合图7~8 可以得到:在大规模问题中,由于变邻域搜索策略的贡献相对较少,可以通过适当减小变邻域搜索的强度加速算法的收敛。
5 结语
本文针对现实生产场景中机床的加工时间可控的现象,研究了加工时间可控的开放车间调度问题。以最小化完工时间与总额外能耗为目标建立了调度模型,并设计了MOHEA 进行求解。通过仿真实验,首先确定了测试算例的合理收敛时间;验证了本文所提出的三种搜索策略对MOHEA 的搜索性能具有明显的提升作用,尤其对算法的综合性能提升最为显著,同时,改进迁移变异算子对算法综合性能的提升在小规模算例上优于其他算子,加工时间重置算子能高效地降低总额外能耗;最后,将MOHEA 与NSGA-Ⅱ、NSGA-Ⅲ和SPEA2 进行对比,表明本文提出的MOHEA 可以更有效地解决加工时间可控的开放车间调度问题,并且随着问题规模的增大,MOHEA 的优势更加显著。
猜你喜欢
农业工程学报(2022年7期)2022-07-09
工业设计(2022年1期)2022-02-09
逻辑学研究(2021年3期)2021-09-29
波谱学杂志(2021年3期)2021-09-07
汉语世界(The World of Chinese)(2018年3期)2018-10-22
速读·中旬(2018年4期)2018-04-28
阅读(低年级)(2018年12期)2018-03-23
读写算·教研版(2016年10期)2016-06-08
读写算·教研版(2016年6期)2016-03-28
西南学林(2011年0期)2011-11-12
