
基于深度学习和行为数据的自控力评价研究
2022-08-31 08:59李萌欣代秀云梁皓东刘守印
心理技术与应用 2022年8期
朱 珠 李萌欣 代秀云 陈 娟 梁皓东 杨 祯 刘守印
(1 华中师范大学物理科学与技术学院,武汉 430079)
(2 华中师范大学招生与就业工作处,武汉 430079)
(3 华中师范大学本科生院,武汉 430079)
(4 华中师范大学经济与工商管理学院,武汉 430079)
(5 中南财经政法大学金融学院,武汉 430073)
1 引言
自我控制是个体克服自身的欲望或需求,用一种符合自身发展目标或社会标准的行为方式替代另一种固有的或者习惯的行为方式的过程(谭树华,郭永玉,2008a)。研究表明,自我控制能力(以下简称自控力)是人类最强有力的、让自身获益最大的能力之一(于国庆,2004),是个体适应社会、达成人生目标的一项重要能力(Cheung et al., 2014)。自控力强的人,往往拥有良好的学习适应能力、满意的人际关系和健康的身体与心理,在学习和工作中也更容易取得好的成绩(Glassman et al., 2007)。而较差的自控力更容易引起各类个人问题和社会问题的发生(尚夕琼,2019),轻则导致学业无法顺利完成,重则可能出现酒驾、赌博等恶性事件。因此,保持良好的自控力十分重要。
相比于成年人,学生特别是即将踏入社会的大学生,正处于成长的关键时期,自控力对其更为重要(张慧妍,2019)。大学生可自由支配的时间较多,具有更大的自主性(余友情,2016)。正确的教育指导能够帮助他们提升自控力,养成良好的行为习惯(李琳等,2015),而合理的教育指导需要自控力评价的支撑。评价结果不仅能够帮助教育工作者更加全面地了解学生,也能够帮助学生加强自我认知,更有针对性地提升自控力,促进自身全面发展。
目前,心理学领域对自控力的测量主要有任务实验方法和量表方法(梁献丹,2018)。任务实验方法要求被试者在特定的环境中执行某项任务,由专业人员全程观察,并根据执行任务的过程和结果对被试者的自控力做出评价。该方法测量结果可靠,但执行过程费时费力,也不能大面积展开调查,只能局限于少量人员(管健,2014)。量表方法是由测试对象自己填写公认的标准化问卷,根据问卷的回答结果得出自控力的评分。据统计,用于自控力测量的量表多达一百多份,最早可追溯到1975年Fagen等人发表的自控行为记录表。但大多研究不够全面,1994年Baumeister等(1996)提出有限自控力理论,2004年Tangney等(2004)结合了近十年自我控制领域的研究成果,发表了新的自我控制量表,这是目前国际上使用最广泛的自控力量表。2008年谭树华(谭树华,郭永玉,2008b)将Tangney版的自我控制量表针对中国大学生的特点进行了修订,可作为测量我国大学生自我控制能力的工具。量表方法可同时测评大量被试者,但测量结果的置信度会受到测试对象的记忆和主观意识的影响(苏悦等,2021),也不能在时间粒度上细致分析测试对象的自控力。
针对心理学传统测量方法的不足,心理信息学为自控力的评价提供了新思路、新方法。心理信息学是Yarkoni在2012年正式提出的一门新兴交叉学科,核心思想是使用计算机和信息科学的工具和技术来改进心理数据的获取、组织和合成。Markowetz(2014)强调在大数据时代,心理信息学是一个独立的研究方向,它将计算机科学的技术应用到心理学中,可以克服传统测量方法收集的数据量小、数据质量不高、耗费人力物力、时间粒度粗等弊端,适应进行大规模的人类行为研究。
近年来,随着校园信息化的建设,学生在校园内的各种行为被记录下来,形成了自然环境下丰富的行为数据,如一卡通系统中记录了学生的食堂消费、超市购物、图书借阅等行为数据,校园网系统中记录了学生的网络使用行为数据。这些数据完整记录了行为事件发生的时间、位置和过程等信息,为大学生的心理测量提供了新的数据资源和研究途径(苏悦等,2021)。许多研究已证明,学生在校园内的行为数据蕴含了大量的心理学含义,是了解学生人格、认知、心理健康状况等的新途径。
吴一帆(2018)使用学生一卡通刷卡数据,量化评价大学生的成就性和严谨性,其中成就性和严谨性是大五人格理论中尽责性的细分特质,量化结果与学分绩的斯皮尔曼等级相关系数在0.2左右。Mengyu Zhou等人(2016)提出了教育测量系统(EDUM),通过从校园无线网络收集的数据来描述大学生的准时性,发现在准时性上表现良好的学生往往学习成绩也比较好。罗炜敏(2019)利用学生在校园内的一卡通刷卡数据提取了学生的饮食规律性、图书馆学习规律性、朋友数量等动态特征,并以此构建了大学生抑郁程度预测模型,抑郁二分类模型的F1值可以达到0.9左右。以上研究表明,利用学生在校园内的行为数据建立心理特质的评价模型具有可行性,并且已有学者通过Facebook上发布的帖子构建模型量化评价用户的自控力(He et al., 2014),说明自控力可以在行为数据中得到体现。
深度学习是机器学习的一种形式,也被称为深度神经网络或深度神经学习,它能够将数据中深层次的、抽象的特征提取出来,使得网络模型的预测性更准确。长短时记忆网络(Long Short-Term Memory, LSTM)是Hochreater和Schmidhuber在1997年提出的一种深度学习模型,专门用来处理序列数据的特征提取,已在自然语言处理、股票指数预测等方面取得良好的效果。近来,LSTM已被应用到一卡通行为数据的研究中,如韩泽峰(2020)基于LSTM提出了Consume2Vec模型,以此提取学生行为数据中蕴含的时序特征,在消费金额和消费时间的预测任务上准确率分别为64.41%和55.74%,明显优于随机森林、决策树等,说明LSTM在处理一卡通行为数据方面有独特的优势。
综上所述,本文以大学生在校园内的一卡通刷卡数据作为数据源,通过深度学习提取特征,构建一种自控力测量模型,量化评价大学生的自控力。该测量方法与任务实验和量表方法相比,主要有以下优势:第一,相比任务实验测量方法,该方法可以摆脱对实验室的依赖,进行大规模的调查与研究;第二,相比量表的测量方法,该方法可以避免与学生之间的互动,消除测试对象的主观意识影响,测量结果置信度更高;第三,该方法能够跟踪分析测试对象在某一时间段内的行为,从而研究大学生自控力的动态变化。
2 数据采集
本文采集的数据包括学生行为数据和大学生自我控制量表测试数据两类,其中学生行为数据作为数据源,量表数据作为训练模型的标签。
2.1 行为数据采集
本文采集的学生行为数据为我国某“211”工程重点师范大学两个学院大一和大二学生的一卡通消费数据和图书馆门禁数据,数据时间段为2020~2021学年第一学期,即2020年9月1日至2021年1月17日。获取数据过程严格遵守保护学生隐私的规章制度,通过专人和专用设备获取数据,不泄露给研究无关人员。具体数据情况如表1所示。
一卡通消费数据主要包括学号、消费金额、消费时间、消费地点等字段,其中消费地点除了包括学校内的各个食堂、超市、便利店等,还包括校医院、药店、校车、乒羽中心。乒羽中心是校内建设的室内羽毛球和乒乓球场地。图书馆门禁数据主要包括学号和进入图书馆的时刻两个字段。
2.2 量表数据采集
选取某高校1218名大一和大二学生,以宿舍为单位进行问卷调查,问卷发放形式为纸质问卷。在填写量表之前,调查人员和被试者详细说明了量表的使用方法和调查目的,尽可能保证量表结果的可靠性。共回收有效问卷880份,其中大一学生445份,占50.57%;大二学生435份,占49.43%。
采用谭树华2008年修订的大学生自我控制量表进行测量。该量表包括五个维度:冲动控制、健康习惯、抵制诱惑、专注工作和节制娱乐,共19个条目,其中1、5、11、14正向计分,其余反向计分。采用5点计分,从“完全符合”到“完全不符合”分别为5分、4分、3分、2分和1分,得分越高代表自控力越强。在本研究中,该量表的信度为0.85。
880份有效问卷对应的学生中有864名学生的刷卡次数达到统计要求,因此共有864个有效样本可作为标签使用。864个有效样本的自控量表总得分和各个维度得分的统计描述如表2所示,自控总得分的均值为60,方差为106.58。

表2 自控量表得分统计描述
3 基于深度学习LSTM的自控力评价
人工特征选取和特征提取容易遗漏和忽略数据的部分重要信息。同时学生行为活动之间具有时序特征,因为学生的刷卡行为是在时间轴上依次发生的,行为与行为之间必然存在着前后时序关系(韩泽峰等,2020)。因此,使用深度学习中处理序列数据的LSTM模型对学生行为数据进行特征提取。
3.1 数据编码
学生行为原始数据无法直接作为LSTM模型的输入,需要进行编码表示,其中最常用的编码方式是独热编码(OneHot)(李文杰,2019)。OneHot编码是将类别变量转化为算法模型易于利用的形式的过程,具体方式是将某种变量的M种状态映射为M位二进制向量,每种状态对应二进制向量的其中一位为“1”,并且在任意状态有且只有一位为“1”。
消费数据中的有效信息有消费时间、消费地点和消费金额,图书馆门禁数据与消费数据相比省略了地点和消费金额。首先对消费数据进行编码。假设学生i在一段时间内的所有消费记录集合为ci:
(1)
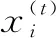
(2)

消费时间。学校课程是按周安排的,学生上课休息是以天为单位循环的,因此学生行为将以周或者天为周期,具有一定的规律性。为了模型能够挖掘出这种规律,本文将时间分别映射成星期和小时的OneHot向量,星期为7维向量,小时为24维向量。
消费地点。经地点整合之后,共统计出25个刷卡地点,包括餐厅、超市、饮料店、药房、乒羽中心、校车和校医院,因此将地点映射为25维的OneHot向量。
消费金额。经统计,学生消费金额分布在0.2~128元之间,消费在1~14元的记录占90.86%,因此将[1,14]按每1元划分不同区间,(14,20]划分一个区间,(20,40]按每10元划分不同区间,小于1元和大于40元各划分一个区间,最后将消费金额映射为一个18维的OneHot向量。
然后对图书馆门禁数据进行编码。门禁数据的关键信息只有进入图书馆的时间,因此只需要对时间进行OneHot编码。假设学生i在一段时间内的所有进入图书馆的刷卡记录集合为li:
(3)

(4)
综上,将每个学生的每条刷卡记录以OneHot编码形式映射到了一个高维空间,得到了每个学生的刷卡记录集合,作为后续深度学习模型的输入。
3.2 评价模型构建
首先将原始刷卡数据按照OneHot编码,得到集合ci和li。但学生刷卡次数不一致,因此还需要对数据进行对齐处理。本文采用的对齐方式是以刷卡次数最多的学生为标准,在刷卡次数不足的学生数据后填充“-1”。假设消费数据和门禁数据最长记录数分别为n和m,ci和li经数据对齐后得到矩阵表示Ci和Li,Ci如公式(5)所示,每一行长度为74。Li与之类似,每一行均代表一条刷卡记录,长度为31。

(5)
自控力评价模型结构如图1所示,包括Masking层、LSTM、隐藏层、回归模块等,以学生的每条刷卡记录作为输入。

图1 基于LSTM的自控力评价模型
输入层为Masking层,其作用是屏蔽对齐数据而添加的“-1”。用LSTM模型从消费数据和图书馆门禁数据中提取与自控力相关的时序特征,同时还采用dropout策略,防止模型过拟合,提高模型泛化能力。Ci和Li经过LSTM模型之后得到隐层表示向量,记为Hci和Hli:
(6)

(7)
Hci和Hli经过隐藏层后分别得到消费数据特征向量hci和图书馆门禁数据特征向量hli,再将两者拼接在一起,得到hi:
hi=Concatenate(hci,hli)
(8)
该模型为有监督学习模型,将大学生自我控制量表的自控总得分和各个维度的得分作为训练模型的标签,hi即学生的自控力特征向量,将hi分别输入不同的全连接层,可生成对学生自控总得分和各个维度得分的预测值。其中,模型的优化方法选用Adam(Adaptive Moments),全连接层的损失函数选用均方误差(Mean-Square Error,MSE):
(9)
其中N为观测样本的个数,yi为因变量y的第i个观测值,f(xi)为回归模型的预测值。
4 实验与结果分析
模型训练期间,批处理大小设为64,最大迭代次数设为200,使用正则化方法防止过拟合,并采用前终止策略,既可以节省训练时间,防止模型后期在训练集上出现过拟合的问题,也能够将在验证集上泛化性能最好的模型保存下来。
将864个有效样本按照7∶2∶1的比例划分为训练集、测试集和验证集。在模型训练中,本文尝试过两层或三层LSTM堆叠,但是发现一层LSTM即可达到较好的效果;关于内部隐藏节点大小,本文尝试过32、64、128和256,发现设为64效果最好;因此最终选用一层LSTM,内部隐藏节点设为64。模型预测结果与多项式回归、SVR回归和RNN模型进行对比分析,自控总得分预测的分析结果如表3所示。

表3 模型预测自控总得分结果对比分析
r是皮尔逊相关系数,表示模型的预测结果与量表结果之间的相关程度,该值越大表示建模效果越好;决定系数R2表示模型解释因变量变化的程度,值越大表示模型拟合的效果越好;均方误差MSE表示模型的计算结果和量表结果之差平方的期望值,该值越小说明预测模型描述实验数据具有更好的精确度。从表4可以看出RNN模型和本文提出的模型在自控总得分预测任务上效果明显优于多项式回归和SVR回归;本文的模型在三个评价指标上的预测效果都是最好的,说明LSTM模型在处理时序数据上有明显的优势;基于LSTM模型的预测结果与量表结果的相关系数r为0.66,呈中高度相关,决定系数R2为0.41,均方误差MSE为54.16,说明该模型对自控力总得分的预测较为有效。
使用本文的模型对量表五个维度上的得分进行预测,结果如表4所示,预测得分与真实得分的相关系数均高于0.5,最小为0.58;决定系数R2均高于0.3,最小为0.33,说明该模型对每个维度得分的拟合效果也比较好。其中健康习惯维度的拟合效果最好,预测值与真实值的相关程度可以达到0.71,说明学生的“健康习惯”更能从平时在校的行为中反映出来。
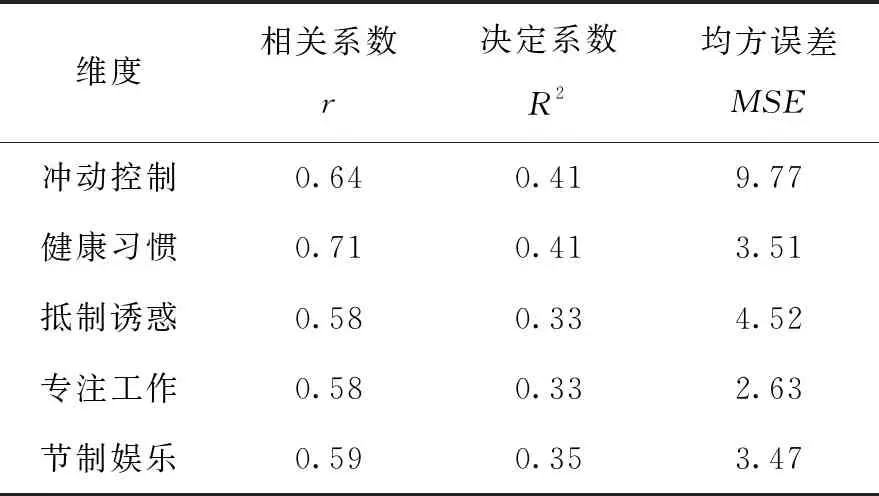
表4 模型预测结果
5 自控力评价应用
大学生正处于成长阶段的关键时期,自控力对其更为重要。因为大学的学习氛围和生活环境都比较轻松,大学生可以独自支配自己的大多数时间,具有更大的自主性。如果能够合理地教育、引导、培养学生具有良好的自控力,则能够很大程度上帮助学生养成良好的行为习惯,使其在面对互联网等各种诱惑时始终保持清醒头脑,意识上克服自身的惰性,行动上合理支配个人时间,对新兴的信息技术加以利用,不断提升自己的知识理论水平和实践操作能力,促进自身向好发展。因此可以使用本文提出的基于LSTM的自控力评价模型帮助高校教育管理者及时发现自控力薄弱的学生,有针对性地对其加以引导和督促。
使用本文提出的模型在某学院2020级学生中进行自控力评价,该年级共370人,行为数据采集时间段为2020年9月1日至2021年1月17日,即大一上学期。自控力总得分整体分布情况如图2所示。自控力总得分满分为95分,其中60~69分数段的人最多,占全年级的48.9%;大于70分的学生人数为23,仅占全年级的6.2%。说明该学院2020级学生的整体自控力呈中等水平,自控力良好的学生占比较小,大多数学生自控力一般。值得注意的是,还有15人的自控总得分低于50分,说明这15人的自控力较差,是辅导员应该重点关注的对象。

图2 自控总得分分布柱状图
自控总得分低于50分的15名学生具体行为表现如表5所示,其中消费水平是学生在校内每次刷卡消费的均值;活动熵描述的是学生在校活动时空规律性的程度,取值范围为[0,1],活动熵值越低,代表学生的在校行为时空规律性越强(任晋华,2018)。从表中可以看出,这15名学生的早餐次数均小于均值,且有9名学生的早餐次数不足10次,最少的仅为1次;消费水平明显高于平均消费水平;图书馆次数均小于平均值,且有4人图书馆次数为0;有5人的活动熵高于平均水平。说明自控力差的学生在行为上会表现出不爱吃早餐和去图书馆、消费水平偏高、行为时空规律性不强的特点。本文提出的自控力评价模型能够发现这些学生,提醒高校教育管理者对其给予关注和督促。

表5 低于50分学生具体行为表现
同时,根据模型给出的每个学生在冲动控制、健康习惯、抵制诱惑、专注工作和节制娱乐五个维度的得分,可以画出五维雷达图,由于每个维度满分不一致,这里先将得分标准化,满分都设置为5分。如图3所示,是表5中学生14的五维雷达图,实线是该年级学生的平均水平,带点虚线是学生14在各个维度的表现,可以看出该学生在健康习惯和冲动控制维度表现趋于中等水平,但专注工作和节制娱乐维度表现较差。根据此雷达图,可以帮助教育管理者发现学生出现问题的具体表现,有针对性地对其加以引导,从而促进学生全面发展。

图3 个体五维雷达图
6 结论
本文旨在利用大学生在校园内的行为数据,构建一种无感知的自控力评价模型,从而能够对学生群体进行大规模的研究与调查。通过研究发现,以学生在校园内的行为数据为数据源建立的自控力评价模型,不仅能够较为有效地测量学生的自控力总得分和各个维度的得分,而且可以克服传统的任务实验法和量表法的弊端,避免了与学生之间的互动,还能够实时跟踪学生的行为,动态分析学生的自控力变化。
本文提出的自控力评价方法是将数据科学与心理学结合的一次尝试,为研究者细致分析个体的自控力提供了一种新的工具。在未来,大数据与心理特质研究的结合可能会成为一种重要方法。研究者可利用行为数据与深度学习模型对其他心理特质展开研究。
猜你喜欢
化工管理(2022年14期)2022-12-02
好日子(2022年6期)2022-08-17
学生天地(2020年8期)2020-08-25
科教新报(2020年1期)2020-02-14
探索科学(2017年2期)2017-03-07
作文大王·笑话大王(2015年7期)2015-05-30
发明与创新(2015年30期)2015-02-27
河北医科大学学报(2010年12期)2010-03-25
