
改进SteGAN的嵌入式图像隐写方案
2022-09-01 08:54杨忠鹏李启南
兰州交通大学学报 2022年4期
杨忠鹏,李启南
(兰州交通大学 电子与信息工程学院,兰州 730070)
在信息安全隐藏领域中,隐写技术作为提高通信过程中安全性的最主要方式,已成为了近年来在网络安全领域的热点研发方向之一.传统的自适应隐写术算法可以使嵌入信息对载体图像中的统计性特征所产生的失真尽可能的较小,但也无法减少在人为设计隐写术算法时嵌入信息对载体图像产生的改动痕迹,所以在隐写术计算仍未可知的情形下,隐写技术分析可以通过反复检查,测试隐写图像中是否存在着秘密信号.在这样的过程中,隐写技术和隐写分析技术的相互竞争、互补,直接驱动了信息隐藏技术的发展.
随着计算机硬件的进步,计算机性能逐年提高,而基于计算机性能的深度学习近年来也得到了迅速发展,出现了各式各样的深度学习模型,如卷积神经网络、生成对抗网络等各种神经网络模型,并在很多领域进行应用,诸如计算机视觉、机器翻译、数据挖掘等领域都取得了很多成果,解决了很多传统方法无法处理的问题.因此,研究者们将信息隐写理论与深度学习相关技术结合起来,使得信息隐写相关理论技术更为快速地发展,其中与生成对抗网络的结合尤为密切,其生成对抗的特点与信息隐写和隐写分析的对立思想十分相似,这为两者的结合提供了思路[1].
文献[2]首次提出了SGAN(steganographic generative adversarial networks)模型,将GAN(generative adversarial networks)应用于图像隐写,通过输入随机噪声,生成尽可能真实的载体图像,嵌入方法使用传统的1算法实现,最后对载密图像进行隐写分析.文献[3]提出的隐写生成对抗网络(steganography generative adversarial network,SteGAN)将编码-解码网络应用到隐写领域,编码器负责嵌入信息,解码器则提取嵌入的信息,并判断提取信息的准确性,隐写分析器则对载密图像的安全性做出评估,但生成图像使用DCGAN,使得载密图像生成质量较差.文献[4]提出使用无载体的隐写方法来嵌入秘密信息,通过建立一种嵌入信息与图像类别标签之间的映射关系,将载体图像与类别标签融合,由ACGAN(auxiliary classifier GAN)中的生成器生成载密图像,而重构秘密信息通过提取载密图像中的类别标签来完成,但该方法因其类别标签数量较少,导致模型的隐写容量较低.文献[5]通过将秘密信息映射成噪声向量,从DCGAN(deep convolution generative adversarial networks)生成的载密图像中提取输入噪声,从而恢复秘密消息,但模型训练消耗时间与成本大幅增加.文献[6]在SGAN基础上,用WGAN(wasserstein GAN)将DCGAN 替换,相较于原始的SGAN,生成的载体图像质量更好,抗隐写分析的能力增强,但未对隐写容量做出提高.文献[7]将灰度图像隐藏在彩色图像中,通过引入对抗模型和新的隐藏位置来提高隐蔽性和安全性,对隐写信息做出了改变,有效地缓解了梯度消失问题.文献[8]提出了可以抵抗噪声等攻击的隐写模型HiDDeN(hiding data with deep networks),使用卷积网络来构造编码-解码结构,并且考虑到载密图像在通信传输过程中的安全性问题,在编码-解码结构中加入噪声层进行噪声训练,以抵抗噪声攻击,但是,将秘密信息转换成数据时存在维数过大的问题,从而导致隐写容量最高只能达到0.2位/像素左右.
为解决SteGAN训练时图像特征信息丢失,生成的载密图像质量较差的问题,本文提出基于改进SteGAN的图像隐写模型(improved steganography generation adversarial network,ISteGAN),该模型使用密集连接改变SteGAN网络内的连接方式,加强特征的传递,引入注意力机制来获取图像深层特征,并在判别器中引入谱归一化的方法,以此提高模型训练的稳定性,使得生成的载密图像更加接近载体图像.
1 相关算法
1.1 SteGAN
图1为SteGAN模型图,SteGAN是一个由生成器(Alice)、判别器(Bob)和隐写分析(Eve)组成的三方对抗模型.生成器Alice通过融合载体图像与随机二进制序列的秘密消息,生成载密图像,并传递给判别器Bob,使其从载密图像中提取出秘密信息;而Eve则作为隐写分析器进行窃听,并判断接收到的图像中是否有秘密消息的存在,从而评价隐写安全性.
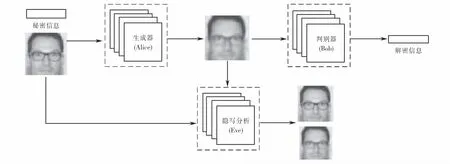
图1 SteGAN模型图Fig.1 SteGAN model diagram
在不断的对抗学习中,Alice学会了在任意的载体图像中隐藏秘密信息,Bob通过解析Alice的载密图像使隐写算法更加成熟,所以它可以准确地恢复信息;而Eve不断的优化网络结构,更容易判断两种类型的图像是载体图像还是隐写图像,通过对抗博弈反作用于Alice和bob,使其学习能力不断提高,在双方之间达一个纳什均衡[9].

SteGAN的信息嵌入过程在训练生成器网络时完成,秘密信息的提取过程在训练判别器网络时实现,它们各自的损失函数可写为:


隐写分析器在模型中起着鉴别分类的作用,它接收载体图像和载密图像作为输入,并从这两种类型的图像中判断该图像是载体图像还是载密图像.
1.2 密集连接
密集连接网络DenseNet(densely connected convolutional networks)的出现,加强了网络中特征的流动,从而缓解网络中梯度消失和网络退化的问题.DenseNet并不是复杂的公式和模型,它只是简单的与CNN(convolutional neural networks)连接方式有所不同.CNN采用的是一对一的连接方式,网络中某层的输入是前一层网络的输出;密集连接则是将之前网络层输出的特征图通过在通道上的连接操作,连接在一起作为该层的输入,再进行网络中的操作.密集连接块将每层网络提取到的不同程度的特征紧密的连接在一起,使得数据的特征完整的保留下来,使模型学习到更丰富的数据特征[10].密集连接过程如图2所示,其中:BN(batch normalization)代表批量归一化层;ReLU(rectified linear unit,ReLU)为激活函数;Conv2D代表卷积层.

图2 密集连接块Fig.2 Dense connection module
1.3 谱归一化原理
基于GAN的深度学习模型训练较为困难,主要体现在:1)模式坍塌,即最后生成的对象仅有少数几个模式;2)不收敛,即在训练过程中,判别器较早就进入了收敛状态,能很容易地分辨出真假,所以无法使生成器网络梯度更新而导致训练无法进行.谱归一化技术在不破坏矩阵结构的情况下,只需让每层网络的网络参数除以该层参数矩阵的谱范数即可满足Lipschitz的约束[11].
为了稳定判别网络的训练,使其映射函数满足Lipschitz的约束,引入谱归一化技术,通常使用SN(spectral normalization)代表谱归一化,它在计算上既轻便又有效.如式(5)所示,W表示神经网络的权值,σ(W)是权矩阵W 的谱范数,用它规范判别器网络的每一层,它等于W 的最大奇异值.
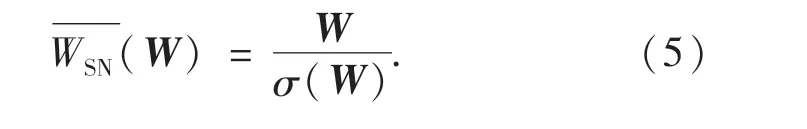
1.4 注意力机制
为了提升模型对载体图像与秘密信息的关注能力,在网络结构中结合卷积注意力模块[11],即通道注意力模块和空间注意力模块以串联的方式组合,使其特征传递的过程中,加强对图像样本纹理细节的处理能力.
如图3所示的通道注意力模块,在图像特征到达后,通过全局两个不同的池化操作,分别为最大池化和平均池化对输入的特征进行压缩,此时压缩的特征属于空间维度上的特征,通过该操作得到两个不同的描述符;接着经过共享的两层全连接层的处理,将两个输出值进行叠加,经过激活函数处理就得0~1之间的权重系数;将最初的输入特征图与权重系数逐元素相乘,完成通道注意力的操作.

图3 通道注意力模块Fig.3 Channel attention module
空间注意力模块结构如图4所示.在图4中,与通道注意力相似,依然使用全局两个池化操作,不同之处在于此时压缩通道维度上的特征,通过该操作将两个不同的全局特征描述拼接在一起,同样的使用卷积将拼接的描述符进行处理,使用激活函数得到空间权重系数;将初始输入特征图与空间权重系数相乘,得到新的特征图,此时的特征图含有空间注意力.
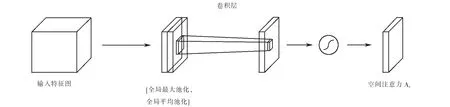
图4 空间注意力模块Fig.4 Spatial attention module
2 本文方案
2.1 ISteGAN总体架构
本文改进的模型如图5所示,使用密集连接来改变SteGAN网络中生成器与判别器的连接方式,保护图像信息固有特征的完整性;在网络之间加入卷积注意力模块来获取图像的深层次特征,减少特征的丢失[12];在判别器中引入谱归一化的方法,以此提高模型训练的稳定性.

图5 ISteGAN模型图Fig.5 ISteGAN model diagram
2.2 生成网络模型
生成器Alice通过学习来获取真实样本的分布,使输入载体图像与秘密信息能够通过微步卷积的方式生成真实样本.Alice的网络结构如图6所示,Alice接受载体图像与秘密信息作为输入,将图像与信息融合,先使用BN层对数据进行归一化处理,接着连续应用五个具有相同网络结构层的组.每个组包含密集连接与卷积神经网络构成的连续卷积层;每个卷积层后面都跟着一个LReLU(leaky-ReLU)激活函数,通过结合密集连接的方式,加强特征传递,加速网络训练,进一步增强生成器对真实图像深层次特征的提取能力;而卷积注意力模块使得网络获取到真实图像的复杂纹理区域特征,从而生成高质量的载密图像.

图6 Alice网络结构图Fig.6 Alice′s network structure diagram
本文所使用图像为3×H×W的载体图像,Alice接受载体图像与秘密信息后,通过第一层卷积将载体图像与秘密信息融合,利用网络第二层中的卷积注意力模块提取复杂纹理区域特征,而引入密集连接可以保留前面网络提取到的特征与后面提取到的特征相结合,这样可以更有效利用图像特征,得到3×H×W的隐写图像.生成器Alice的具体网络结构见表1.

表1 生成器Alice具体网络结构Tab.1 Generator concrete network structure
2.3 判别网络模型
判别器Bob接受来自生成器Alice的载密图像.图7Bob网络使用4个C2D-SN-LR(Conv2D-spectral normalization-leaky ReLU)卷积网络组合与注意力机制提取图像特征,并且通过构造谱归一化的卷积层,使得判别器参数更新更加稳定,减缓了判别器的收敛速度,从而提升了网络训练的稳定性.Bob不断学习优化自己的神经网络[13],准确的从载密图像中解析出消息M′,通过与原始秘密信息M比较来判断Bob的学习能力.

图7 Bob网络结构图Fig.7 Bob′s network structure diagram
隐写图像通过Bob的多层卷积后获得一个与秘密消息M相同大小的M′,同时判别器网络采用与生成器网络相同的结构,引入密集连接网络,保留图像特征.判别器产生M′,试图恢复秘密信息M.判别器Bob的具体网络结构见表2.

表2 判别器Bob具体网络结构Tab.2 Discriminator Bob concrete network structure
2.4 隐写分析网络模型
隐写分析器Eve的网络结构如图8所示,将载体图像与载密图像均输入到该网络结构中,经过每层的卷积操作(共四层),得到一个判断该类图像的概率值.因此隐写分析网络的最后一层是含有一个输出通道的卷积层,其分类任务由Alice影响,不需要加入密集连接与注意力机制,这样就降低了内存的消耗.隐写分析器Eve的具体网络结构见表3.

表3 隐写分析器Eve具体网络结构Tab.3 Concrete network structure of the steganography analyzer Eve

图8 Eve网络结构图Fig.8 Eve′s network structure diagram
2.5 信息的嵌入与提取
信息的嵌入过程包含在生成器的训练中,生成模型由两部分内容组成:一部分是预处理,另一部分为编码.预处理部分将嵌入的秘密信息进行转换,以便与载体图像进行融合.首先,将载体图像与秘密信息融合后,利用卷积网络第一层扩充为三维张量,最后得到32×H×W的特征图;其次,在嵌入过程中,将每一层的特征向量与预处理后的秘密信息进行拼接,将新得到的张量输入到下一层的多层编码网络,实现载体图像与秘密信息的融合.
提取模型是判别器模型对载密图像中每个像素位中嵌入的秘密信息进行提取,这个数据包含每个像素位中的所有数据,并将数据进行平均,得到重构的秘密信息.判别网络首先通过一个3×3卷积核的卷积层将载密图像扩充为通道数为32个的特征向量;通过预处理模块对特征向量映射的数据进行聚集,在空间维度上恢复嵌入数据;最后通过模型的最后的平均池化层和线性层进行映射,将恢复的数据转换为嵌入的秘密信息.
3 实验结果与分析
运行实验的设备为使用64 GB内存的服务器,操作系统为NVIDIA Tesla T4 GPU和Ubuntu 16.04.本实验数据集采用公共数据集CelebA与Animals-10.CelebA数据集包含10 177个名人身份的202 599张图像;Animals-10数据集包含10种动物.本文优化器采用Adam,学习率为0.000 2,批大小为32,迭代次数根据需求不同来设置.从四个方面分析载密图像的性能:不可感知性、隐写容量、解码准确率和隐写安全性.
3.1 隐写容量
本文隐写容量的计算公式如式(6)所示.

其中:Q为秘密信息(随机信息)的位数;N为图像的像素值.
将Q位随机消息与每个数据集的每个样本连接起来,改变信息的大小Q,以测试可以有效隐藏在载体图像中的信息量的极限.采用的数据集由32像素×32像素的图像组成,当将Q设置为100位到700位时,相当于隐写容量大约在0.1位/像素到0.7位/像素之间.
ISteGAN与其他模型隐写容量对比结果见表4.以95%的准确率为阈值,ISteGAN最大容量可以达到0.6位/像素,其他隐写模型最大容量为0.4位/像素,也就是说,ISteGAN模型嵌入容量相较于其他模型能够提高50%.

表4 模型容量比较Tab.4 Model capacity comparison
3.2 不可感知性
不可感知性是隐写术最基本和最直观的指标,采用均方误差(mean square error,MSE)反应图像变化的整体质量,峰值信噪比(peak signal to noise ratio,PSNR)用来比较图像的压缩质量,结构相似性(structural similarity index,SSIM)显示两个图像相似性的指标,结合这三种指标来评估图像质量.MSE越低越好,而PSNR与SSIM越高越好[14],结果见表5.

表5 不同模型的图像质量评估Tab.5 Image quality assessment based on different models
为了便于与原模型进行比较,使用与原模型相同的迭代次数,均采用500次.从表5可以看出:横向比较来看,ISteGAN模型在CelebA数据集上表现的更好,尤其是MSE指标,远小于在Animals-10数据集上的值;纵向比较来看,改进模型的MSE均小于其他模型,ISteGAN模型的PSNR与SSIM均大于其他模型,特别是MSE指标,改进的模型远低于其他模型,说明了改进模型的有效性.
如图9所示,随机选取载体图像,将其训练后生成载密图像,嵌入容量分别为0.4位/像素、0.5位/像素、0.6位/像素和0.7位/像素.
观察图9可知:0.7位/像素嵌入容量的载密图像出现明显失真,已经没有使用价值;从0.4位/像素到0.6位/像素图像不能通过人类的感知系统直接区分载体图像和载密图像,说明图像质量都具有很好的不可感知性,可以选择0.6位/像素作为嵌入容量的阈值.
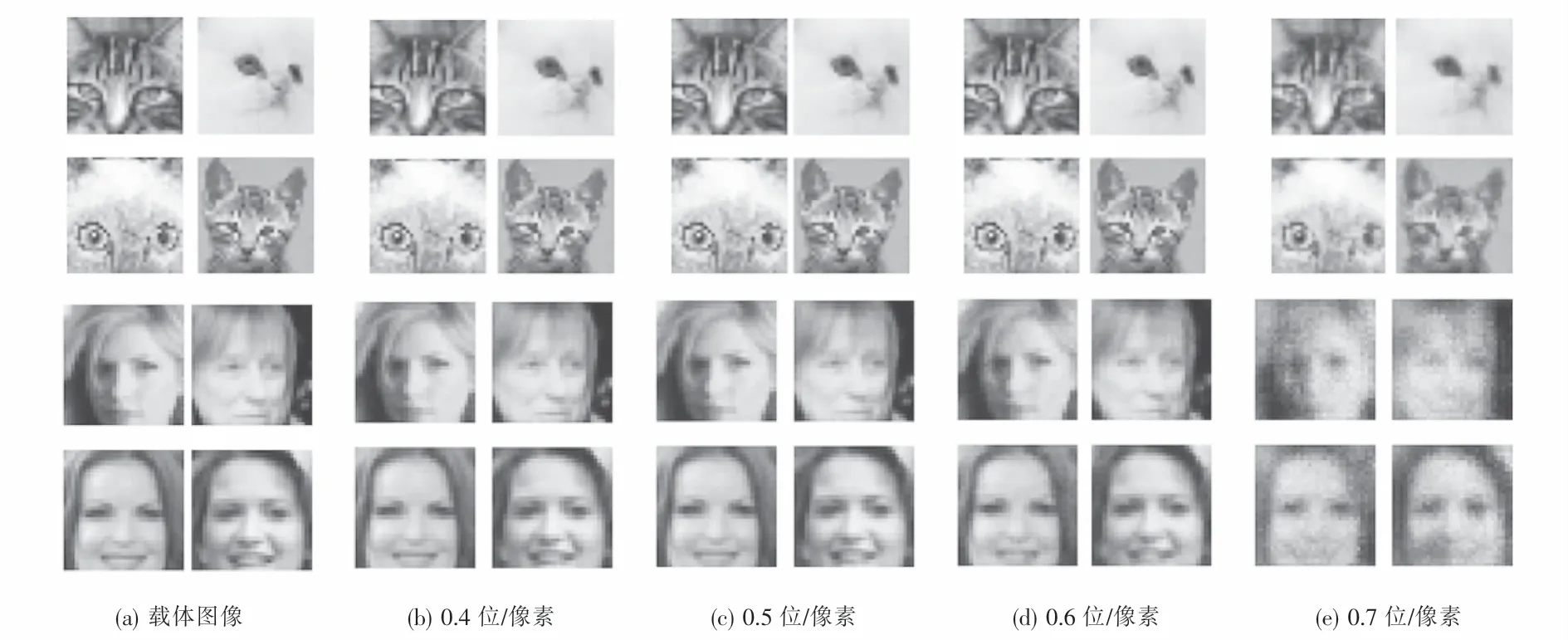
图9 ISteGAN在不同嵌入容量下的载密图像Fig.9 Dense load image of ISteGAN under different embedding rates
为了进一步定量确定嵌入容量的阈值,对ISteGAN模型在不同的嵌入容量下进行质量评估,结果见表6.从表6可以看出:和定性分析一致,嵌入容量为0.7位/像素时,图像的各个指标表现差,说明此时的载密图像已经没有使用价值;当嵌入容量为0.6位/像素时,图像的质量有所降低,但载密图像依然具有使用价值.因此ISteGAN模型图像的容量在嵌入容量达到0.6位/像素时达到最大.

表6 ISteGAN模型图像质量评估Tab.6 Improved SteGAN model for image quality assessment
ISteGAN与SteGAN比较结果见图10与表7,双方的模型均在CelebA数据集上生成载密图像.通过人类的感知系统来看,ISteGAN在嵌入隐写信息更多的情况下与SteGAN生成的载密图像没有区别.

图10 在CelebA数据集生成的图像Fig.10 The image generated in the CelebA dataset
进一步通过数据对比来看(见表7),ISteGAN在高嵌入容量的情况下,不可感知性均优于SteGAN,进一步证明改进模型的有效性.
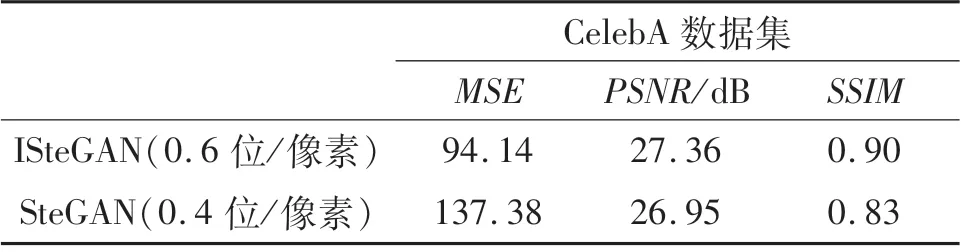
表7 在CelebA数据集上图像质量评估Tab.7 Image quality assessment on CelebA dataset
从图11与表8可以看出:在Animals-10数据集上,ISteGAN模型依然可以生成大容量的载密图像,但是在不可感知性上效果略差于CelebA数据集,这是因为Animals-10数据集使用的均为全身动物图像,图像特征分布过多,难以提取,而CelebA数据集均为人脸图像,图像特征更容易提取.
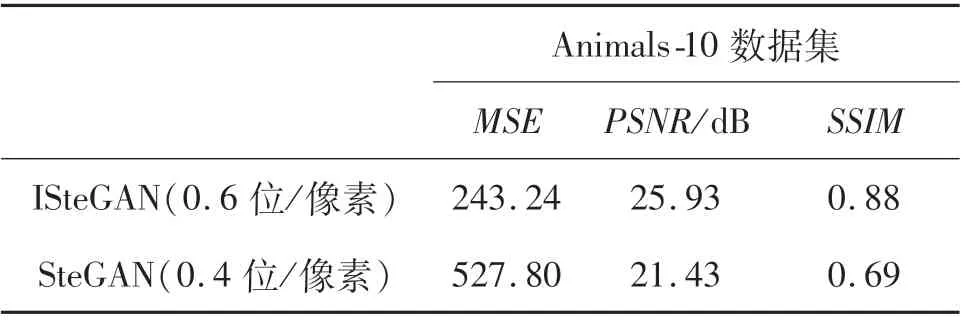
表8 在Animals-10数据集上图像质量评估Tab.8 Image quality assessment on Animals-10 dataset

图11 在Animals-10数据集上生成的图像Fig.11 Image generated in the Animals-10 dataset
3.3 解码准确率
图像隐写的最终目的就是为了安全准确的传输信息,所以对于秘密信息接收方来说,信息的准确率尤为重要,ISteGAN在不同的嵌入容量下,Bob解码准确率如图12所示.
由图12可知:随着训练次数增加,Bob解码准确率能够达到95%以上的准确率阈值,满足隐写信息的要求,达到了提高嵌入容量的目标;而且嵌入容量由0.4位/像素增加到0.5位/像素.
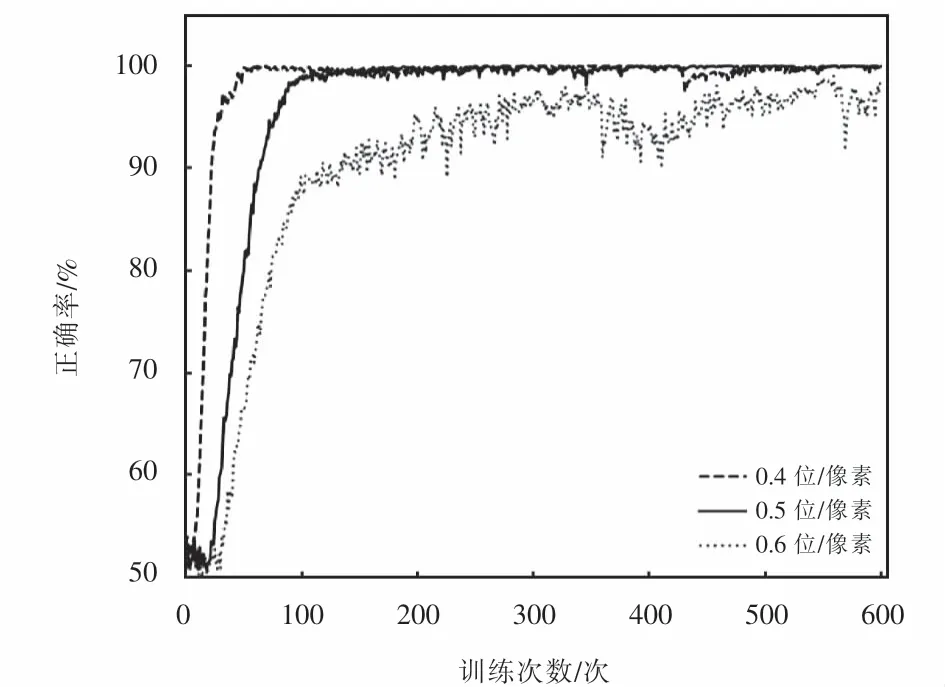
图12 不同Q值下Bob解码成功率Fig.12 Success rate of Bob decoding under different Q values
在实际应用中,应根据不同应用场景选择不同的嵌入容量:在秘密通信应用场景,应选取嵌入容量为0.5位/像素的载密图像,以降低嵌入容量换取秘密通信100%的安全性;而在图像隐写应用场景,则可以选择嵌入容量为0.6位/像素的载密图像,通过提高嵌入容量来完成隐写任务.
3.4 隐写安全性
传统的自适应隐写算法大多通过人为经验来设计最小嵌入失真代价,去寻找载体图像中最优的嵌入位置,不仅需要花费大量的时间精力,而且涉及到嵌入后的图像失真及安全性问题,载体图像中可选嵌入位置有限[15].现阶段基于深度学习的图像隐写模型,将秘密信息嵌入到噪声或纹理复杂区域,使得 隐写图像的隐蔽性更强,隐写分析更加困难.
为了验证SteGAN生成的隐写图像抗隐写分析性能,本文使用一种开源的隐写分析工具StegExpose.从CelebA,Animals-10两个测试集中分别随机选择1 000张载体图像,使用嵌入容量分别为0.4位/像素、0.5位/像素、0.6位/像素的载密图像,检测后的结果见表9.
从表9可以看出:使用StegExpose工具仅仅比随机猜测出隐写图像略微有效,这表明ISteGAN模型在进行隐写安全检测时可以成功达到检测标准,满足信息隐写算法的可行性,但是在最大的嵌入容量0.6位/像素下检测率已超过60%,可见本文提出的网络的抗隐写分析能力仍然不足.

表9 StegExpose在不同嵌入容量下的检测率Tab.9 Detection rates of StegExpose at different embedded capacities
4 结论
本文利用密集连接来改变SteGAN网络内的连接方式,加强图像特征传递,并使用卷积注意力模块获取图像的深层次特征,保证载密图像的质量,并在判别器中引入谱归一化方法来缓解SteGAN训练的不稳定性.将原始模型与改进模型进行比较,仿真实验结果表明:在保证传输信息准确性的情况下,载密图像的不可感知性和隐写容量均有所提升,隐写容量从0.4位/像素提高到0.6位/像素,并能有效地抵抗隐写分析器的检测;然而,ISteGAN在嵌入容量为0.6位/像素时,解码成功率仅达到95%,还需要进一步改进,并且随着图像隐写容量提高,图像的不可感知性与抗隐写分析性能并没有提高很多.在今后的工作中,将进一步研究对于载密图像不可感知性以及抗隐写分析性能的提高.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
华人时刊(2022年9期)2022-09-06
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
三悦文摘·教育学刊(2021年52期)2021-04-27
华人时刊(2020年15期)2020-12-14
发明与创新·小学生(2020年4期)2020-08-14
人大建设(2018年6期)2018-08-16
发明与创新·小学生(2016年4期)2016-08-04
