
机器学习在有机光电材料筛选中的应用
2022-09-01 08:54郭鹏智
兰州交通大学学报 2022年4期
周 渊,郭鹏智
(1.兰州交通大学 国家绿色镀膜技术与装备工程技术研究中心,兰州 730070;2.兰州交通大学 光电技术与智能控制教育部重点实验室,兰州 730070)
发现或者设计一种新型更高性能的有机光电材料是一个非常艰难的过程,通常都在机缘巧合和数次失败后获得.传统经验丰富的化学家拿到一个新的化合物之后从结构大致能够估测有无进一步进行实验验证的价值,如果再伴以分析测试结果,可以在一定程度上提高估测准确度,但是面对成千上万个化合物进行实验验证,人力就有局限.为了接近光电材料效率的理论极限,传统的研究方法主要包括:设计和合成新的供体和受体材料,优化制造条件和器件结构以及探索器件的运行机制.前两种方法是一种试错程序,需要较高的材料成本、长时间的消耗和大量的人力;最后一种方式更多是从第一性原理出发[1],研究材料的物理化学性质,这类方法需要高性能计算支持,通用性较差.
近年来,在药物发现[2-3]、热电材料[4]和催化研究[5-6]等领域将机器学习与材料信息学结合,通过机器学习方法有效探寻了结构和性能之间的密切关系,为设计材料提供了有益指导[7].
本文结合监督学习与无监督学习的优势,以富勒烯为受体材料的聚合物太阳能电池(polymer solar cells,PSCs)给体材料[8]为例,对大约1 000个材料数据组成的数据集进行机器学习.先使用无监督学习中聚类算法进行数据集聚类并标记,然后使用监督学习中随机森林方法对数据集进行训练、测试;探寻和验证PSCs给体材料筛选的机器学习方法,并针对机器学习方法在其它类型光电材料设计的共性问题上进行拓展[9],尝试筛选或寻找潜在具有更高性能的有机光电材料的新方法.
1 数据集分析与处理
数据集中的主要特征包括短路电流密度JSC、开路电压VOC、填充因子FF、能量转换效率(power conversion efficiency,PCE)、最高占据分子轨道(highest occupied molecular orbital,HOMO)、最低未占分子轨道(lowest unoccupied molecular orbital,LUMO)、分子线性描述符(simplified molecular input line entry system,SMILES)等.其中:能量转换效率是衡量和反映太阳能光伏器件质量和技术水平的重要指标[10-11],其值为器件最大的输出功率Pmax与入射光输入功率Pin之比,表示式为
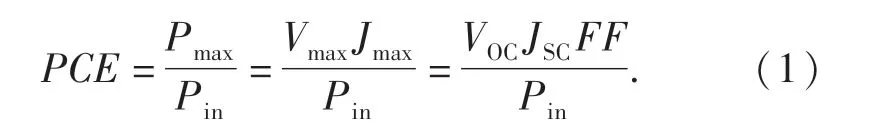
由式(1)可知,器件的能量转换效率在标准入射光强度下与VOC,JSC和FF正相关.传统PSCs材料设计也紧密围绕着设计合成具有高VOC和JSC的分子展开.通过数据集统计形成四者相互关系图,如图1所示.从图1可以看出:VOC和JSC、VOC与FF之间虽有一定关系,但并不线性相关;FF与JSC线性相关,实际中还受制于器件制备、溶解度等影响[12].因此,将VOC,JSC和FF作为一个整体去考虑,使用能量转换效率对PSCs性能进行评价.
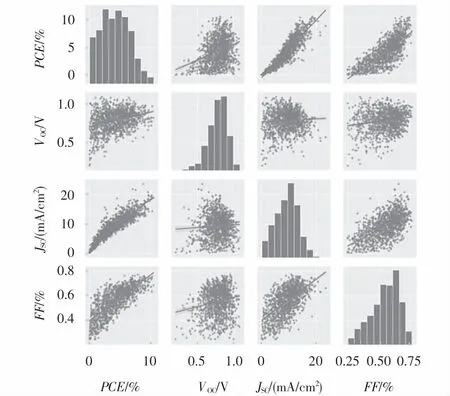
图1 V OC,J SC,FF和PCE分布及相互关系图Fig.1 Distribution and interrelationship of V OC,J SC,FF and PCE
原则上,器件的电子特征与材料分子结构有关,器件的最终性能只取决于其材料,而制造技术和器件结构的功能只是更好地发挥材料的作用.分子之间特征相似则化学性质相似,反映在分子指纹中则具有相似的指纹,如芳香材料分子具有环状大π键共轭结构,与该结构类似的材料具有较高的电子传输能力,从而展现出较好的导电性和丰富的光学特性,是最有潜力的有机光电材料之一[13].
为了表示材料分子的化学结构,采用线性的字符串来描述材料分子的三维化学结构.通过开源工具RDKit,分别计算样本SMILES生成长度为167位的分子访问系统(molecular access system,MACCS)分子指纹和2 048位扩展分子指纹(extended connectivity fingerprint,ECFP)序列,完成分子结构特征编码,如图2所示.对于聚合物PBDD4T-2F的重复单元,首先生成SMILES,然后分别计算两种分子指纹并存储,指纹序列中1表示具有某种结构特征.该聚合物重复单元中存在甲基、芳香、六元环、氧元素和环,故MACCS分子指纹序列中160,162,163,164和165位值为1.ECFP指纹长度更大,因此表示的特征细节更多.
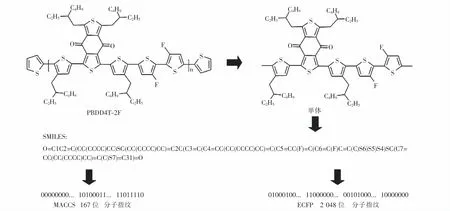
图2 分子指纹生成过程Fig.2 Molecular fingerprint generation process
另外,为提高机器学习效率,对数据集进行特征选择以消除相关特征、无关特征和冗余特征.为消除特征之间值域差别较大带来潜在权重的问题,对数据集除分子指纹外其他特征进行了标准化,形成1 056个给体材料样本的数据集.
2 数据集聚类划分
在监督学习中,数据集和标签集是缺一不可的,而无监督学习的结果为已标记分类的数据集.无监督学习中聚类算法采用一种探索性的分析方法,它从样本属性出发,对数据集进行分簇和标记,这样可以省去面对大量数据时人工分类和数据标记工作,同时聚类结果也可以为初步研究材料性能提供帮助.
2.1 聚类算法介绍
由于k-均值聚类(k-means)具有适合处理稀疏的高维数据、适应各种数据类型等特点[14-15],因此采用此算法聚类.算法使用欧氏距离作为相似性的评价指标.对于输入的数据集和分簇数k,首先堆积选取k个点作为初始聚类中心,迭代求解下面过程:计算各个样本到中心的距离;按距离进行归类;调整新的聚类中心到此类样本的均值处.算法满足下列条件:没有(或最小数目)记录对象被重新分配给不同的聚类;聚类中心不再发生变化;误差平方和局部最小时结束,生成划分为k类的数据集.
实验使用基于Python语言的机器学习开源工具sklearn(scikit-learn)中KMeans模型.模型关键参数分簇数k一般根据数据分布和实际经验进行假定,本文使用手肘法结合轮廓系数法计算确定.
2.2 聚类簇数计算
2.2.1 手肘法
手肘法[16]中,使用误差平方和(sum of the squared errors,SSE)数值的变化拐点来找出最佳的聚类簇数.误差平方和为所有簇中的全部数据点与簇中心的误差距离平方累加和,代表了聚类效果的好坏,其计算如式(2)所示.

其中:Ci是第i个簇;p是Ci中的样本点;mi是Ci的质心(Ci中所有样本的均值).
随着k的增大,样本划分会更加精细,簇的聚合程度会逐渐提高,误差平方和逐渐变小;当聚类簇数k不断趋向于真实类簇数时,误差平方呈现快速下降状态,当超过真实类簇数时,误差平方和也会继续下降并迅速趋于稳定.k-SSE曲线呈现手肘的形状,因此可以通过判定下降的拐点找出较合适的k值.
2.2.2 轮廓系数法
在聚类发现的过程中,最佳的分类具有其簇内差异小,而簇外差异大的特点,轮廓系数s正是描述簇内、外差异的关键指标.s的计算如式(3)所示.
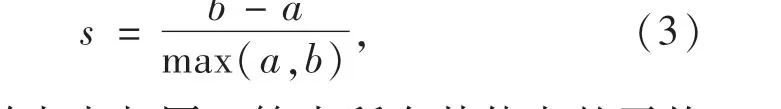
其中:a表示样本点与同一簇中所有其他点的平均距离,即样本点与同一簇中其他点的相似度;b表示样本点与下一个最近簇中所有点的平均距离,即样本点与下一个最近簇中其他点的相似度.s取值范围为(-1,1),其值越接近于1,则聚类效果越好;越接近-1,聚类效果越差.因此可以求得s的最大值而得到最佳分类簇数,计算过程与肘部法类似.
2.3 聚类结果
在数据集的聚类中,尝试探索能量转换效率与分子结构之间的关系,使用MACCS分子指纹与能量转换效率的特征组合作为样本划分时,样本划分效果较差.由于数据集样本数量不足,以及ECFP分子指纹长度(特征数量)与样本数量相近的问题,在单独使用ECFP分子指纹进行聚类数探索时无法收敛,出现过拟合问题,最终使用能量转换效率作为聚类特征.
如图3所示,轮廓系数最大值对应k=2,这表示最佳聚类数为2,但是从手肘图3可以看出,当k取2时,误差平方和非常大,所以k=2不合理,考虑轮廓系数与误差平方和取值比较合理的次大的k=5为最佳聚类系数.
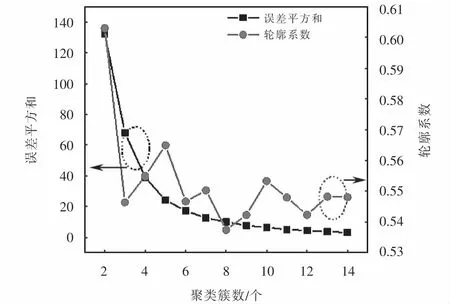
图3 肘部法与轮廓系数法结果示意Fig.3 Illustration of the results of the elbow method and the silhouette method
使用Silhouette Visualizer可视化工具对样本集群的密度和分离进行示意,如图4所示.从图4可以看出:以能量转换效率为特征,聚类后的样本划分较为清晰;图中类簇1图形面积最大,说明归属类簇1的样本数量最多;无轮廓系数为负数的部分,说明样本归类效果较好.
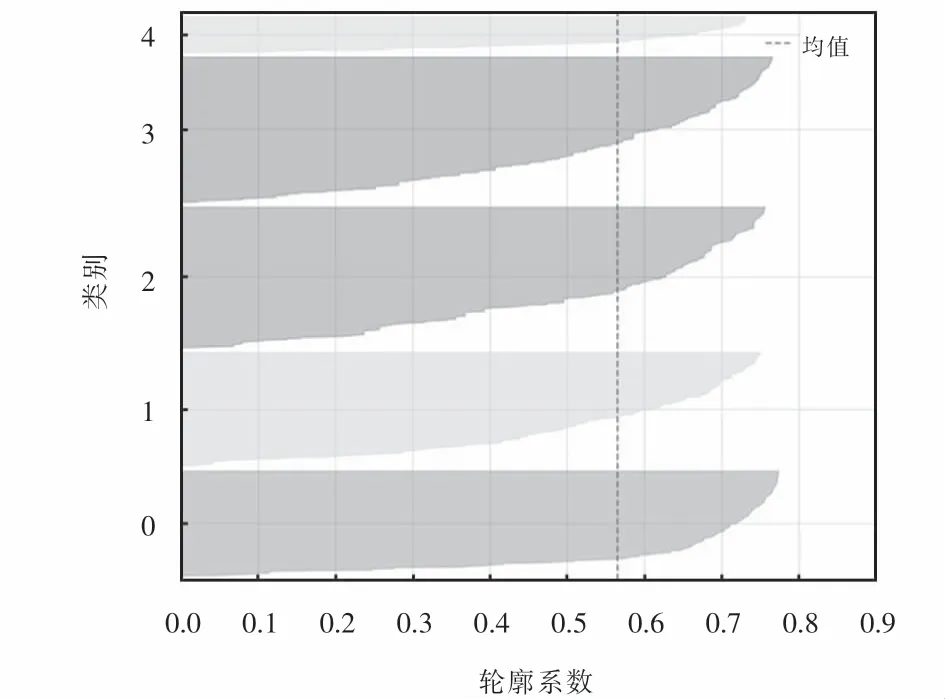
图4 样本集群的密度和分离示意Fig.4 Density and separation of sample clusters illustration
数据集类别标签、各类样本数量、能量转换效率平均值等见表1.类别0,1,2,3,4依次对应材料能量转换效率性能由低到高的变化,各类别中能量转换效率均值分布均匀,取值区间无交叉.由于缺乏高性能的材料数据(对应类别4),数据集存在样本不均匀问题.

表1 监督学习数据集样本划分概况Tab.1 Overview of supervised learning datasets
3 随机森林辅助材料筛选
3.1 随机森林算法
随机森林是一种基于统计的监督学习算法[17].算法的核心思想就是许多棵随机参数生成的决策树组合成一个森林,通过统计每棵树的结果进行分类和预测.算法能够处理具有高维特征的输入样本,同时对缺省值也能得到较好的结果.在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机地无放回地抽取,因此较好地解决了过拟合的问题.
3.2 随机森林分类
使用随机森林算法对已标记数据集进行训练和学习[18].通过在各类中随机抽样70个样本,形成类型分布均匀的子集,按照8∶2的比例划分为训练集和测试集.以样本最高占据分子轨道、数均分子量(Mw)、光学带隙(Eg)和分子指纹序列作为特征,材料性能类别作为标签,对样本进行训练.实验使用sklearn中RandomForestClassifier模型,经过调参,在MACCS分子指纹数据集使用森林中树的数量为110棵,树的深度为16层,子集特征为13个的超参数.在ECFP分子指纹数据集使用森林中树的数量为109棵,最大深度为16层,子集特征为20个的超参数.
采用类似二分类的方法,依次统计每个类别与其他类别之间的二分类学习结果,绘制各类别受试者工作特征曲线(receiver operating characteristic curve,ROC曲线),对每类ROC曲线取平均值,即可得到最终的模型分类ROC曲线,如图5所示.在MACCS分子指纹下AUC(area under curve,AUC)值为0.687 6,ECFP分子指纹下AUC为0.746 3,ECFP分子指纹数据集下模型展示出较好的性能.通过图5(a)、(c)发现,在类别0和类别4中分类效果较好.
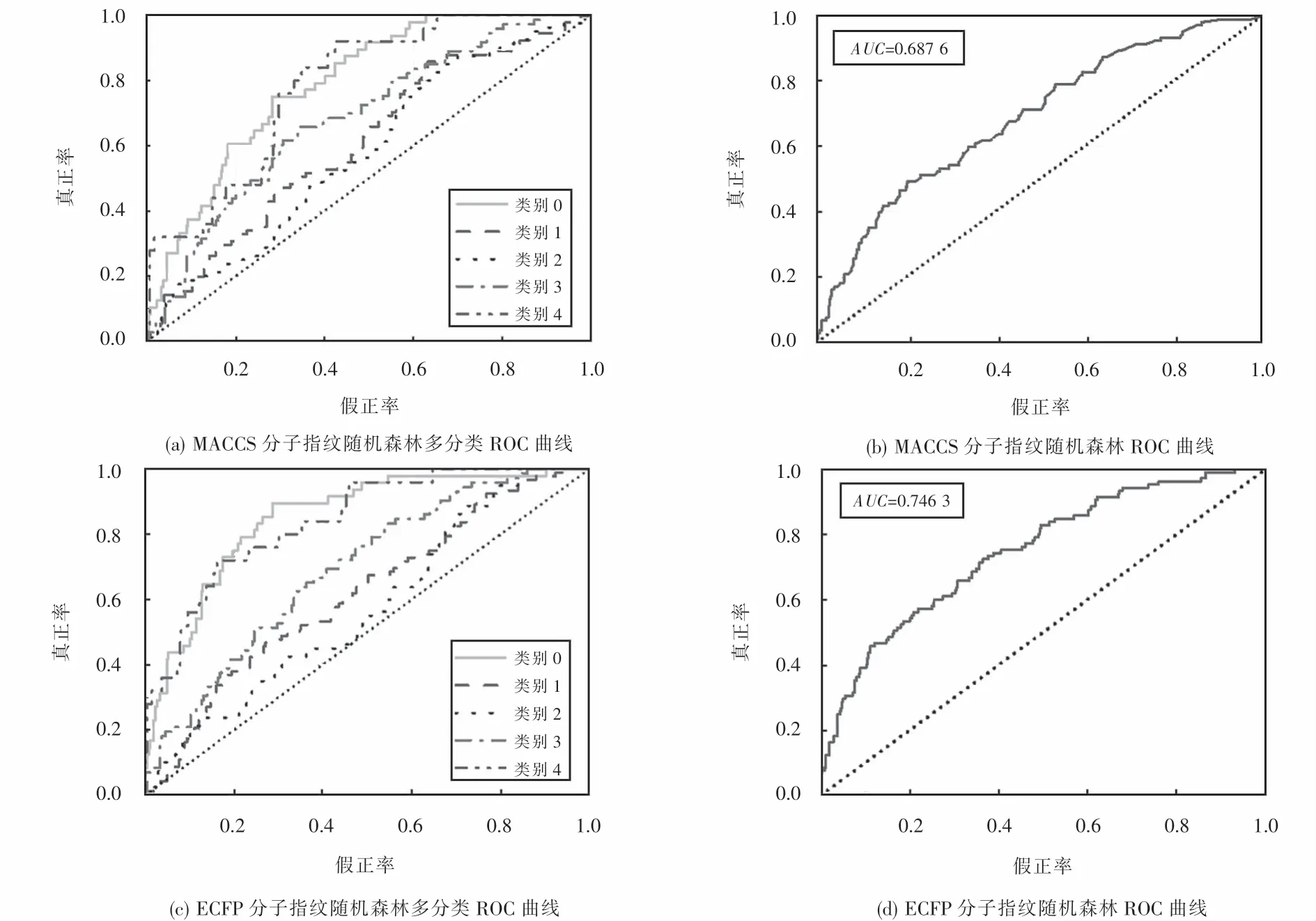
图5 随机森林学习结果ROC曲线Fig.5 ROC curve of random forest learning results
在对随机森林模型训练后,生成测试集混淆矩阵,见表2和表3.矩阵中每行表示一个实际分类的样本,每列表示预测分类的结果,主对角线上的值表示被正确预测的样本数.由表2和表3分别计算两种分子指纹数据集下准确率(Precision)、召回率(Recall)和F1-Score作为模型分类结果的评价指标,如表4~5所列.
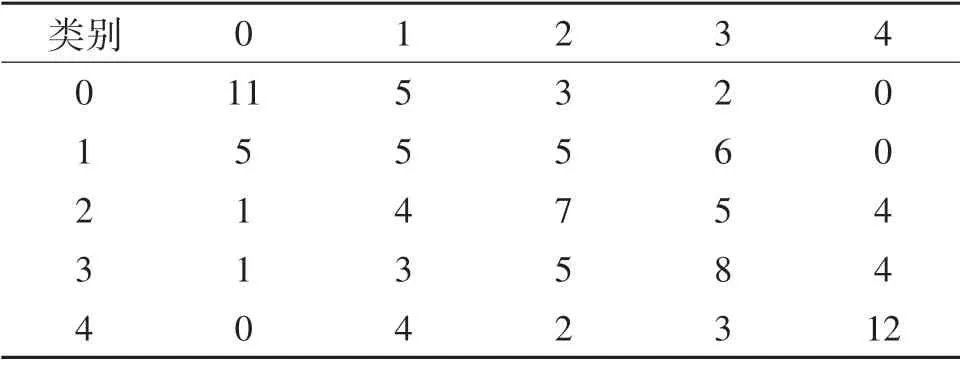
表2 MACCS分子指纹数据集随机森林分类结果Tab.2 Random forest prediction results of MACCSmolecular fingerprint dataset

表3 ECFP分子指纹数据集随机森林预测结果Tab.3 Random forest prediction results of ECFP molecular fingerprint dataset
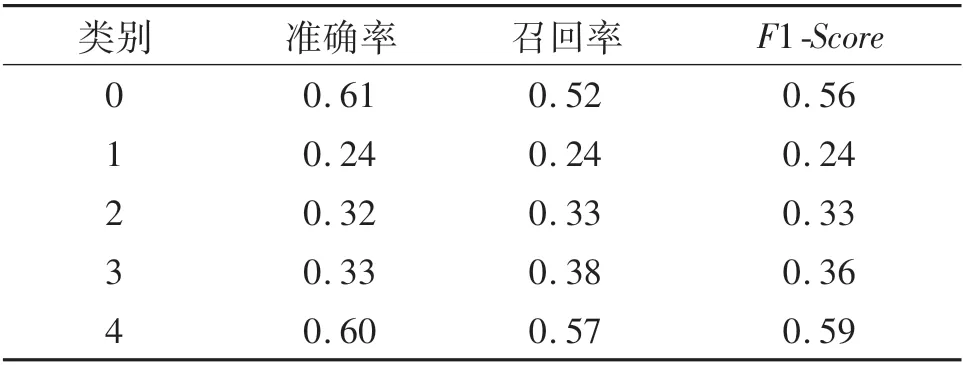
表4 MACCS分子指纹数据集随机森林分类的性能评价Tab.4 Performance evaluation of random forest classification of MACCS molecular fingerprint dataset
由表4和表5可知:在类别0和类别4中的数据准确度、召回率和F1-Score较其他类别高,训练后的机器学习模型较好地区分了这两类,同时表5中数值优于表4,与图5中ROC图呈现的结论一致;由于ECFP拥有比MACCS更多的特征,因此在ECFP分子指纹数据集下模型分类结果更好.
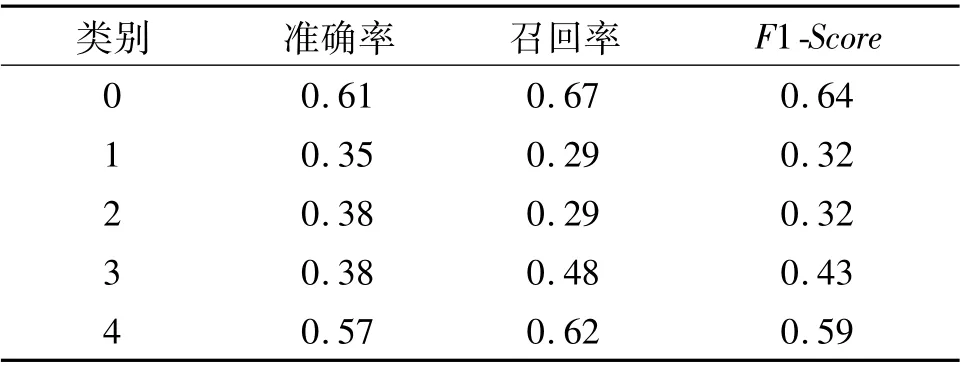
表5 ECFP分子指纹数据集随机森林分类的性能评价Tab.5 Performance evaluation of random forest classification of ECFP molecular fingerprint dataset
3.3 机器学习模型在有机光电材料筛选中的应用
模型训练完成后,对于未知能量转换效率的材料,可以将基本物理性能参数连同分子指纹作为测试样本,使用模型进行分类预测,得到此材料性能类别,即对应类别的能量转换效率数值区间,再辅以经验判断有无材料合成和器件制作的必要.
另外,训练后的机器学习模型建立了一种“结构-性能”关系,可以从公开的有机材料数据库中查询数据来进行批量预测,根据预测结果实现材料的快速筛选.
4 结论
本文通过无监督学习对数据自动分类标记,提高了数据集预处理的效率,同时在监督学习分类中也展示出自动标记的数据集具有良好的质量,为PSCs材料筛选设计提供了机器学习方法和素材.
从迁移学习场景来看,PSCs材料和光电探测器材料分子结构相近,符合迁移学习的要求;从有机光电功能材料功能原理来看,材料光电特性的本质是材料中电子的各种行为带来的结果,与其分子结构是密不可分的,高性能PSCs材料意味着高的光电性能,因此从结构出发的机器学习方法同样可以用在光电探测器等其它有机光电材料的设计筛选中.
综上所述,将机器学习应用于有机光电材料筛选与设计中,有助于加快更多潜在新的材料的发现.另外,受制于缺乏大规模高质量的数据集,未能取得更加准确的分类结果,更多的数据集的收集完善和其他机器学习方法的探索在今后的工作中将逐步展开.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
小天使·一年级语数英综合(2020年10期)2020-12-16
少儿画王(3-6岁)(2020年4期)2020-09-13
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
东方教育(2018年20期)2018-08-22
儿童时代·快乐苗苗(2016年2期)2016-10-22
青少年科技博览(中学版)(2015年7期)2015-08-12
微型计算机(2009年4期)2009-12-23
