
视觉问答语言处理方法综述
2022-09-06 11:08王瑞平吴士泓张美航王小平
计算机工程与应用 2022年17期
王瑞平,吴士泓,张美航,王小平
1.远光软件股份有限公司远光研究院,广东 珠海 519085
2.华中科技大学 人工智能与自动化学院,武汉 430074
3.武汉科技大学 机械自动化学院,武汉 430081
视觉问答是随计算机视觉和自然语言处理的成熟而衍生出的一门多学科跨模态人机交互技术,其过程伴随着对视觉和语言特征的感知、识别和理解,以及跨模态融合推理,具有重要的理论研究价值,此外,视觉问答也被认为是人工智能迈向更高层次的重要途径,极具应用潜力。
视觉问答系统主要由三部分组成,分别是视觉特征处理、语言特征处理和跨模态特征融合。语言特征处理是视觉问答任务的重点和难点之一,其核心方法和理论源于自然语言处理。语言特征处理涉及的关键技术包括但不限于命名实体识别、常识推理、关系抽取和逻辑推理,此外,还包括跨模态融合及答案生成。
针对视觉问答中的语言处理方法,相关综述已经对其进行了归纳总结。例如Zhang等人[1]从图像和视频问答入手,简要分析了相关研究中所使用的语言处理方法,并指出不论在图像问答还是视频问答,LSTM[2]和GRU[3]都是当前最受欢迎的语言编码方式;Manmadhan和Kovoor[4]对语言处理方法的研究则更为具体和深入,他们以单词和文本嵌入为切入点进行分类阐述,讨论了词嵌入近来的发展趋势,并对最先进视觉问答模型中所使用语言处理方法进行了对比分析,其中使用情况统计结果如图1所示。

图1 语言处理方法使用情况统计Fig.1 Usage statistics of language processing methods
更普遍的情况出现在已公开发表的视觉问答论文当中,每一篇研究视觉问答的文章都会对所涉及语言处理方法进行描述。例如Zhang 等人[5]使用双向GRU 进行词表达,以实现问题表征,而在答案生成阶段,则使用了基础GRU方法,同样使用双向GRU进行问题表达的还有Urooj等人[6];Sharma等人[7]利用GRU进行问题表达,使用LSTM执行答案生成;Rahman等人[8]使用GloVe[9]+LSTM 的方式来编码输入问题,其中GloVe 执行单词嵌入,LSTM 用于问题特征生成和与视觉特征的融合;Whitehead 等人[10]使用了BERT[11]对语言特征进行提取和表达。尽管上述文献均涉及到了对语言处理方法的描述,但多数情况下仅仅是指出所选用的方法及基础理论模型,并不会给出选择原因。此外,通过进一步观察和分析语言处理方法在每一篇文章中所占比重,能够发现语言处理方法并不受视觉问答研究群体重视。
形成鲜明对比的是近年来自然语言处理技术的快速发展。李舟军等人[12]将自然语言处理分为三个阶段,分别是以Word2Vec[13-14]和GloVe[9]为代表的静态词嵌入技术,以ELMo[15]、GPT[16]和BERT 模型[11]为代表的动态预训练技术,以BERT改进模型[17-18]和XLNet[19]为代表的新式预训练模型,其中静态词嵌入技术常与LSTM 和GRU 结合使用。陈德光等人[20]将自然语言处理的预训练方法分为传统预训练技术和神经网络预训练技术,并对两者进行了细致阐述。此外,他们还针对自然语言处理算法模型的压缩方法进行了分类陈述,对具体应用领域的研究进展进行了介绍。Otter 等人[21]重点调查了深度学习在自然语言处理中的应用,并对自然语言处理的整个体系进行了细致介绍,如语言模型和词嵌入的关系,语言模型的构建、评估,以及几类具有不同理论基础的语言模型,并进一步对自然语言处理中涉及到的词法、句法、语法和语义进行了介绍;最后,还对自然语言处理应用进行了细致探讨和分析,指出Transformer 已经开始取代LSTM单元。结合上述调研结果,通过总结和分析,发现自然语言处理目前正朝着基础理论研究和应用性能提升两个方向快速发展。
纵观视觉问答中的语言处理方法和自然语言处理领域的发展现状,很容易感受到两者之间的发展进程不一致。以图1所展示的语言处理方法和李舟军等人[12]提出的自然语言处理三个发展阶段进行对比,不难发现目前在视觉问答中广泛使用的语言处理方法在整个自然语言处理体系中基本都处于第一阶段,即以Word2Vec和GloVe 为代表的静态词嵌入技术,甚至还出现了像One-hot这种在自然语言处理领域已经要被淘汰的语言编码技术。较高层次的动态预训练技术仅在Whitehead等人[10]推荐的视觉问答中有所涉及,而更高层次的新式动态预训练技术[12]则尚未在视觉问答文献中被发现。
本文重点分析了视觉问答中语言处理方法的重要价值,调查并整理了视觉问答中涉及到的语言处理方法和最新研究进展,归纳总结了自然语言处理在视觉问答中涉及的相关应用场景,并在文章结尾展望了语言处理方法的未来发展方向以及自然语言处理技术对视觉问答的推动作用。
1 视觉问答中的语言处理方法
传统视觉问答系统中,语言处理是关注度最低的关键技术之一。大多数视觉问答的研究焦点是多模态融合及关系推理,对于视觉和语言处理方法的重视程度相对较低。但近年随着来面向视觉的关系推理和视觉语义网络提出,被看作是提升视觉问答准确性的有效途径,进而推动了视觉处理在视觉问答中的快速发展。语言处理相对视觉处理而言,研究领域和应用场景相对较窄,且目前广泛使用的深度神经网络与自然语言处理的结合又比与计算机视觉要晚,在各种因素的影响下,导致视觉问答中语言处理方法的研究进展较为缓慢。此处通过对近年来视觉问答领域相关性较强的论文进行分析,得到如图2所示结果。

图2 视觉问答中关键支撑技术历年情况统计Fig.2 Statistics of key supporting technologies in visual question answering over years
图2 对视觉问答涉及的三类关键技术从2016 到2021 年近六年的相关研究情况进行了统计,发现除2016年并没有涉及多模态融合和推理外,其余每一年都有大量相关研究工作公开发表,且数量远超视觉和语言处理;而语言处理领域的论文数量除2018 和2019 年超过视觉处理外,其余年份均低于视觉处理。为了更加直观展示两者之间的关系变化情况,这里引入相关论文的累计发表数量进行评价,如图3所示。

图3 视觉问答相关技术的论文累积发表情况Fig.3 Cumulative publications of papers on visual question answering technologies
图3相比于图2更加直观地展示了各关键技术近年来相关研究成果的总体变化情况。在收集的92篇视觉问答论文中,研究多模态融合与推理的共计74篇(占比80.4%),研究视觉处理的31篇(占比33.7%),研究语言处理的24篇(占比26.1%)。很显然,针对语言处理方法的研究在低于多模态融合与关系推理外,同样也低于视觉处理。
然而,作为视觉问答中关注度最低的关键支撑技术,语言处理方法所发挥的作用和存在的意义却极为重要。图4展示了常规视觉问答组成。

图4 常规视觉问答组成Fig.4 Regular visual question answering composition
其中“+”用来表示跨模态融合与推理,“=”表示生成或得到答案的过程。通过图4可知,常规视觉问答是输入一幅图像和一个问题,得到一个答案,并循环往复这一过程。但在某些时候,这一标准模式会被改变,例如将输入图像、问题或输出答案进行压缩合并,得到如图5所示的情况。

图5 压缩某一部分输入输出后的视觉问答Fig.5 Visual question answering after compressing certain part of input and output
图5(a)合并了输入图像,此时的视觉问答转变为视觉对话;图5(b)合并了输入问题,即针对多张不同图像,仅完成针对某一个问题的回复,此时的视觉问答退化成一个类似于目标检测、识别或者关系推理问题;图5(c)合并了输出答案,属于视觉问答中的一种特殊情况,即面向不同图像通过输入不同问题后获得了相同答案,这类研究可以用于科学问题探索,以找出不同现象背后的本质原因。
进一步对图5(a)~(c)进行分析能够发现如下现象:(1)面对同一幅图像,不同的输入问题会产生不同的答案,如图5(a)所示;(2)不同的输入图像,也有可能获得完全相同的答案,这取决于输入问题引导,如图5(c)所示;(3)同一个问题,有可能会得到完全不同的答案,如图5(b)所示,这源于问题的选择。上述分析结果表明,视觉问答中输入问题的选择、设定和引导对于视觉问答最终结果具有极大影响,换言之,输入问题不同可能会产生不同的答案类型和结果,因此,解析输入问题的语言处理方法意义重大。
2 语言处理方法综述
语言处理方法是视觉问答的重要组成部分,但针对视觉问答中语言处理方法的文献综述尚未被公开发表。本章将对图2和图3所整理的视觉问答相关论文进行总结归纳,并按照是否针对语言处理方法展开研究,研究是在传统自然语言处理的基础上进行改进优化,还是有针对性地提出一套全新理论,以此对语言处理方法进行划分。
其中第一类方法直接采用成熟的自然语言处理技术,未对其进行改良和优化而直接作为视觉问答的语言处理,这一类方法本文将其称为基础型方法;第二类引入了更加先进的自然语言处理技术,或者在传统技术的基础上进行了卓有成效的调整和改进,使其能够更好地与视觉特征进行多模态融合及关系推理,以获得更加准确的答案,这一类语言处理方法被称为进阶型语言处理方法;第三类方法不同于目前已经公开的自然语言处理方法,而是研究人员根据提出的视觉问答模型中各个组成的内在需求重新设计语言处理方法,此类方法被称为专有型语言处理方法。
2.1 基础型语言处理方法
语言处理作为视觉问答的关键支撑技术,在每一类视觉问答方法中都会被用到,然而,并不是所有新提出的视觉问答方法都会针对语言处理部分进行研究,多数情况下仅仅是将自然语言处理中成熟的方法引入到视觉问答中,然后与视觉特征进行跨模态融合,实现关系推理。
基础型语言处理方法在三类方法中占有较高比重,因此这部分工作目前已经在众多视觉问答相关综述中被涉及。例如Manmadhan 等人[4]针对视觉问答开展的综述,以及Zhang 等人[1]针对信息融合开展的研究均对语言处理方法有所讨论,但上述文献对语言处理方法的讨论过于笼统。同时,发现在阅读某一篇论文时,常常会出现两种或多种语言处理方法,究其原因,是相关研究人员在分析视觉问答的语言处理过程时并没有将词嵌入(word embedding)和词表达(word representation)区分开来,从而导致了语言处理方法阐述的混乱。本节将针对语言处理过程中的词嵌入和词表达分别进行分析,以获得对语言处理方法更加清晰的认知。表1对基础型语言处理中的词嵌入方法进行了整理归纳。

表1 基础型语言处理中的词嵌入方法统计Table 1 Statistics of word embedding methods in language processing
通过对公开发表的92篇与视觉问答具有强相关性的论文进行统计分析,发现属于基础型语言处理方法的共计64 篇,其中能够明确找出词嵌入方法类型的共计53篇,其余11篇作者并未提及具体使用的词嵌入方法,例如Bai 等人[72]和Yu 等人[73]的研究成果。而在能够确定词嵌入方法类型的53篇论文中所使用的词嵌入方法主要分为五类,分别是One-hot、BoW、Word2Vec、GloVe和Skip-thought。
进一步对上述53篇论文中所使用的词嵌入方法进行分析,能够发现如下现象:(1)GloVe词嵌入方法在视觉问答中占据主要地位,特别是在2018 年之后,换言之,GloVe是目前使用最为广泛的词嵌入方法;(2)Onehot在2017 和2018 年使用较多,而在GloVe 出现并被广泛使用后,One-hot逐渐被放弃;(3)BoW和Skip-thought仅仅在某一时间段被使用,这也说明这两种方法存在着极大弊端;(4)Word2Vec 尽管每年数量不多,但持续在被使用,可见其本身具备某些优异性能。总体来说,GloVe是目前使用最广的词嵌入方法,其余方法使用较少。进一步的,对词表达方法的使用情况也进行总结归纳,见表2所示。
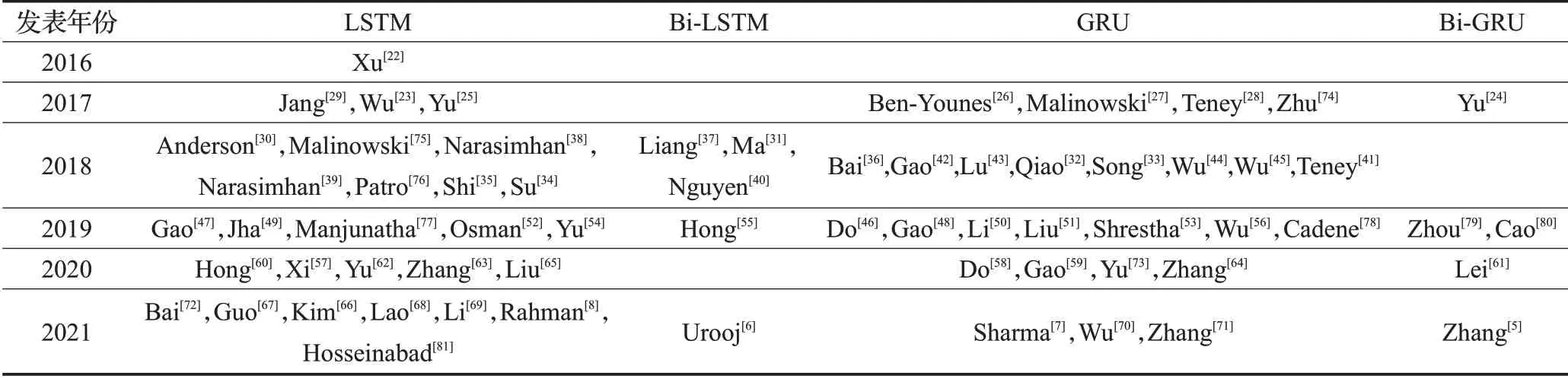
表2 基础型语言处理中的词表达方法统计Table 2 Statistics of word embedding methods in language processing
表2所展示的统计结果表明,基础型语言处理方法中所包含的词表达方法共有四类,分别是LSTM[2]、GRU[3]、Bi-LSTM和Bi-GRU,其中,Bi-LSTM和Bi-GRU表示双向LSTM和双向GRU。显然,LSTM和GRU两者相比于Bi-LSTM和Bi-GRU具有明显优势,而LSTM和GRU之间并没有显著差异。为了直观展示基础型语言处理方法中词嵌入方法和词表达方法的历年变化情况,本节将表1和表2的结果进行了可视化处理,并展示在图6中。

图6 视觉问答语言处理方法随时间变化曲线Fig.6 Time-varying curve of language processing methods for visual question answering
2.2 进阶型语言处理方法
相比基础型语言处理方法,进阶型语言处理方法的最大区别在于并没有在词嵌入和词表达过程中使用表1和表2中所涉及的传统语言处理方法,而是引入了自然语言处理领域更加先进的语义处理模型,例如Bert 和Transformer等,这些语言模型往往是在传统的LSTM以及GRU 基础上发展进化而来。除此之外,进阶型语言处理方法还包含了那些针对基础型语言处理方法的改进版本,例如堆叠式GRU[82],因此将这些语义处理方法统称为进阶型语言处理方法。为了清晰展示这些方法,从词嵌入、词表达和时间维度来对进阶型语言处理方法进行了可视化展示,结果见图7所示。
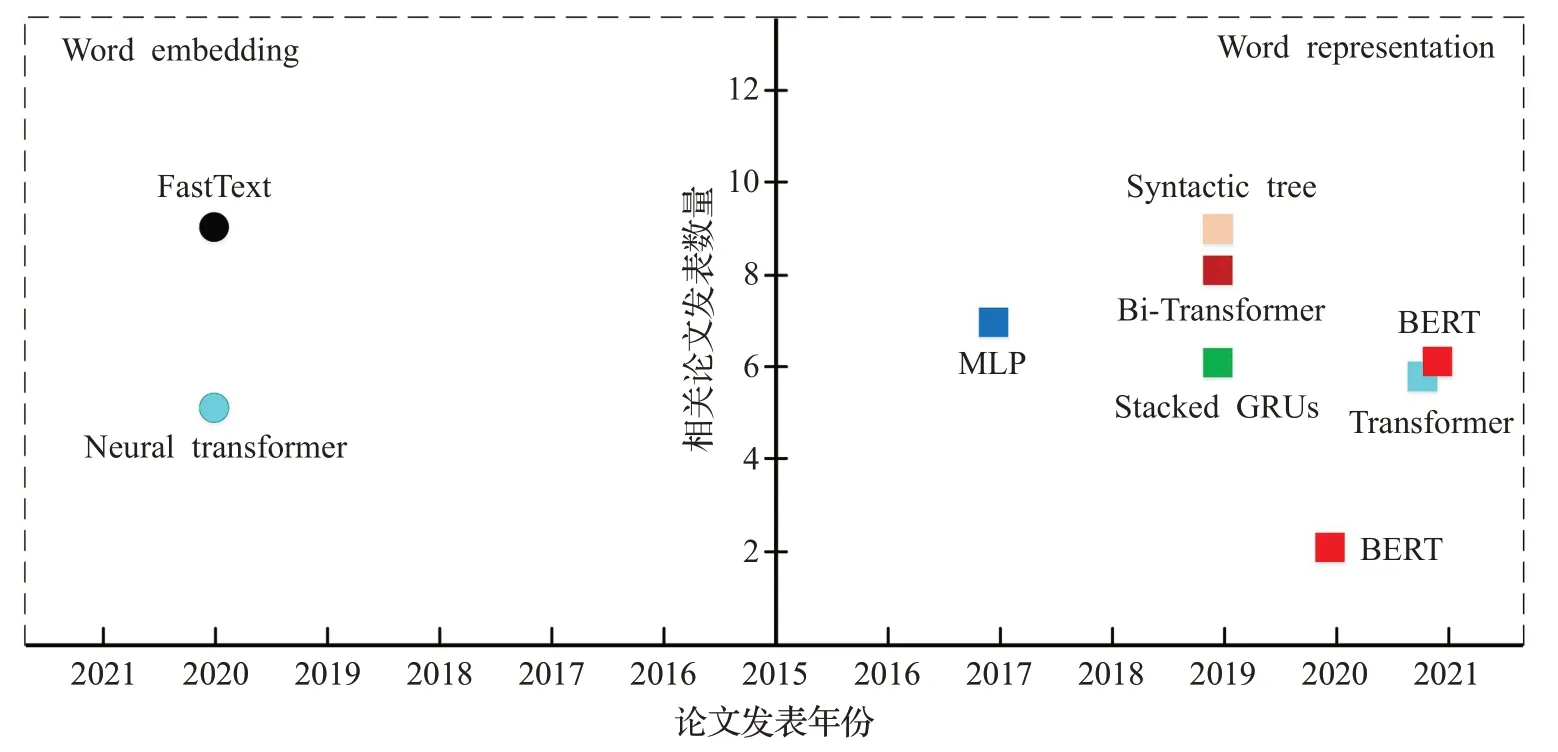
图7 进阶型语言处理方法相关论文发表统计Fig.7 Published statistics on advanced language processing methods
图7中的实心圆用来表示进阶型词嵌入方法,正方形用来代表词表达方法,不同的颜色则表明具体方法不同。通过观察图7中的统计结果可以发现如下现象:(1)在进阶型语言处理方法中,词表达方法所在比重更高,这表明视觉问答的相关研究人员更愿意针对词表达方法进行改进优化;(2)词表达方法中,BERT 和Transformer各出现了两次,结合引言部分关于自然语言处理部分的论述不难发现,视觉问答领域逐渐意识到需要从自然语言处理领域学习最先进的算法,并将其引入到视觉问答当中;(3)在词表达一侧,发现了堆叠式GRU,该方法是在GRU的基础上改进而来。考虑到图7展示得比较简单,接下来,将对调查到的进阶型语言处理方法做进一步阐述。
Whitehead 等人[10]和Gokhale 等人[83]在词表达过程中引入了BERT[11]模型,以提升视觉问答过程中的语言处理精准度。Liang 等人[84]提出了图视觉问答,他们的核心观点是将一个自然语言问题转化为在图节点之间传递多个消息迭代的问题,用到的语言处理方法是序列到序列的Transformer;同样用到Transformer的还有Gao等人[85],不同之处在于他们使用了Bi-Transformer[86]。Liu等人提出了一种空间语义注意力模型,用于学习图像区域与疑问词之间的视觉文本关联和对齐。在注意力模型中,利用连体网络来探讨视觉内容与文本内容的一致性。然后,将树结构的LSTM模型和空间语义注意模型与联合深度模型相结合,利用多任务学习方法训练模型进行答案推理[87]。针对语言处理方法,作者使用了树形结构的LSTM来编码问题语句。Fang等人[82]以GRU为基础,设计了四种堆叠式GRU结构用于问题编码,并探讨了性能差异。Zhu 等人[88]使用了一个简单的MLP 模型进行问题编码和答案解码。
除了上述提到的进阶型词表达方法外,也有少量针对词嵌入的改进和优化,例如Gupta等人提出了一种问题分割技术,并将该技术应用到分层深度多模态网络当中用于产生可能的答案。在词嵌入部分,作者首先使用了GloVe技术,除此之外也引入了子词嵌入来捕获医学术语中未知词的嵌入,而在字词嵌入过程中,使用了FastText 词嵌入技术[89]。Huasong 等人提出了一种新的自适应神经模块Transformer,用来代替传统的前馈式编解码结构。
2.3 专有型语言处理方法
不同于基础型和进阶型语言处理方法,专有型语言处理方法是作者根据视觉问答模型需要而专门设计的语言处理方法。因此,这些方法和对应的模型往往都是独一无二、且难以被其他类型的视觉问答系统所使用。然而,这并不是说研究专有型语言处理方法就没有意义,恰恰相反,这些独一无二的语言处理方法在解决某些问题时往往具有非常好的借鉴意义,因此把这一部分放在三类方法的最后来介绍。
视觉问答提出的早期,由于缺少实践经验,研究人员并不清楚哪一种类型的语言处理方法在视觉问答系统中能够有更好表现,因此各种类型的语言处理方法纷纷涌现并被尝试,其中专有型语言处理方法也不例外。
Shih等人[90]提出了一种图像区域选择机制,可以学习识别与问题相关的图像区域。语言处理部分使用Word2Vec和一个三层网络对解析后的问题和答案进行编码。此外,受到基于向量的语义表示方法启发,Shih等人使用相似向量编码相似单词,以便于更好地回答开放式问题。在实验部分,作者展示了他们提出的向量平均语言模型明显优于更复杂的基于LSTM模型,从而证明了这种类似BoW 模型为VQA 任务提供了非常有效和简单的语言表达。
Hu 等人[91]提出了一个端到端的模块化网络,该网络能够直接通过预测实例网络层来学习推理,而并不需要解析器辅助。该模型能够通过学习生成网络结构(通过模仿专家演示)和网络参数。其语言处理部分采用了序列到序列的循环神经网络布局策略,作者希望为每个问题都能够预测最为合理的推理结构,再根据这个推理结构组装神经网络模型来输出问题答案。但在实际使用过程中,该方法适应性和泛化能力较差,因此难以获得推广。
Aditya 等人[92]提出了一个在端到端神经网络结构上采用显式推理层的集成系统。推理层支持推理和回答需要附加知识的问题,同时为最终用户提供可解释的接口。具体来说,推理层采用基于概率软逻辑的引擎对视觉关系、问题的语义解析和来自ConceptNet[93]的本体论知识背景进行推理。其中问题处理与通用解析器密切相关,通用解析器使用逻辑语言或标记图来表示句子。
Gao 等人[94]指出问题在视觉问答中起着主导作用,因为它指定了机器应该处理的视觉对象。为此,作者提出了问题引导的目标注意力,即通过探索问题语义、细粒度图像信息以及两者之间的关系来提高视觉问答性能。在语言处理方面,Gao等人提出使用卷积神经网络来提取问题短语特征,之所以使用卷积神经网络,是因为在视觉问答中,问题通常用一组短语描述关于查询对象的重要信息,而与LSTM和GRU相比,具有权值共享能力的卷积单元拥有更好捕获连续单词之间丰富结构和组成的能力。
Liu等人[95]提出了一种具有共同注意网络的双重自注意力视觉问答模型。具体来说,该模型包含三个子模块,其中视觉自注意模块通过对每个区域所有位置的视觉特征进行加权求和,选择性地聚合每个区域的视觉特征;文本自注意模块通过整合句子中词与词之间的关联特征,自动强调相互依赖词特征;视觉-文本共注意模块探讨了从自注意模块学习到的视觉特征和文本特征之间的密切关系,这三个模块集成到一个端到端框架中来推断答案。针对语言处理方法,作者发现传统循环神经网络存在问题,即不能很好地捕捉不同位置单词之间的内部依赖关系,而为了解决这一问题,提出了将时间信息编码为特征级的自注意力,以捕获词的依赖关系从而进行表征学习。
专有型语言处理方法相比基础型语言处理方法和进阶型语言处理方法而言,研究群体相对较小,且多出现在视觉问答提出的早期,因此整体成熟度和普及型较低,但因其与提取的视觉特征和多模态融合过程具有更好的嵌合度,因此同样是一类比较重要的语言处理方法。
3 语言处理方法分析
通过对当前已有的强关联性视觉问答系统所涉及的语言处理方法系统综述,基本可以了解该研究领域的研究现状,但还缺少对各类型语言处理方法的深入分析和优缺点解析。本章将对基本型、进阶型和专有型语言处理方法的特点进行更加细致分析,从而揭示各自特点和适用情况。
基本型语言处理方法在三类语言处理方法中占比最重且应用广泛,但由于所涉及的词嵌入和词表达方法提出得较早,因此某些性能方面无法与进阶型语言处理方法相比。基本型语言处理方法的最大优势是模型简单,简单的模型往往更容易训练和改进优化,因此以基础型语言处理方法作为底层,发展出了大量的新方法,这其中就包括有进阶型语言处理方法和专有型语言处理方法。
进阶型语言处理方法是从先进的自然语言处理领域引入或者在基础型语言处理方法的基础上发展而来,因此在某些关键性能方面相比于基础型语言处理方法具有先天优势,能够获得更好的语言识别效果。但进阶型语言处理方法的模型一般较大,训练过程更长,同时在进行端侧部署时难度也更大。
专有型语言处理方法是针对视觉问答模型特别开发的语言处理方法,其思想来源于基础型语言处理方法和自然语言处理领域,原则上与视觉问答模型的切合度更高,融合性更好。但该方法的设计难度较大,且很多时候需要配合特定的训练数据集使用,适用范围受限;此外,专有型语言处理方法往往仅针对特定视觉问答模型效果较好,当迁移到其他模型上时会出现性能大幅度下降的问题。基于上述两方面原因,专有型语言处理方法的发展较为缓慢。
三类方法中,基础型语言处理方法目前依然被广泛使用,其原因在于视觉问答研究人员普遍将精力放在多模态融合上,而很少关注基础的语言和视觉处理方法,所以针对语言和视觉处理方法往往直接引入现成的算法模型进行使用,所以,基础型语言处理方法适合于仅关注多模态融合及其他非语言处理方向的研究工作。进阶型语言处理方法模型相对比较复杂,性能也更加优异,且具有一定的优化改造空间,因此特别适合于实验设备性能较好,且有意通过改进语言处理方法来提升视觉问答性能的研究人员,同时,针对企业级用户,进阶型语言处理方法是更好的选择。专有型语言处理方法适合于专门研究语言处理方法与视觉问答关系的相关研究人员,这类研究需要较好的自然语言处理知识和多模态融合知识,但整体而言,这类算法的价值相对较小。
尽管本文将语言处理方法分为了三种类型,但不可否认的是自然语言处理领域的发展为语言处理方法的推陈出新提供了巨大帮助。正如基础型语言处理方法本身脱胎于自然语言处理,进阶型语言处理方法源自于先进的自然语言处理或者以自然语言处理为基础而进行的改进优化,即使是专有型语言处理方法,其创新的灵感往往也离不开自然语言处理,因此,可以毫不夸张的讲,自然语言处理是视觉问答语言处理方法的基础;而从另一个角度来看,视觉问答中语言处理方法面临的困境,同样也是在向自然语言处理领域提出的挑战,这种挑战可以促进自然语言处理向着更有性能和更加完善的方向发展。
4 未来研究方向展望
4.1 基础型语言处理方法的更新迭代
基础型语言处理方法会长期占据主导地位,但这并不意味着本文中所述的基础型词嵌入和词表达方法会一直存在并始终占据主导地位。未来,随着自然语言处理的持续发展,会有新的、性能更加优异的算法提出,并被引入到视觉问答的语言处理过程中,在此过程中,基础型语言处理方法将会被目前的进阶型语言处理方法及其变体替代,基础型语言处理方法将会是一个迭代更新的过程。既然如此,目前众多的进阶型语言处理方法中哪一种会成为未来的基础型语言处理方法,这是非常值得探讨并研究的工作。
4.2 词嵌入方法的研究
正如文中所述,视觉问答中的语言处理方法包括了词嵌入方法和词表达方法,而通过对第2章研究现状的分析发现,从基础型到进阶型语言处理方法,再到专有型语言处理方法,多数情况下发展的都是词表达方法,而词嵌入方法基本上一直沿用固定几类,这几类词嵌入方法即使是最新的,提出时间也已经有近十年。词嵌入方法直接关系着语言处理模型的规模,未来如果想要将模型进行无损压缩,词嵌入方法的发展必然是一个非常重要的研究方向。
4.3 端到端的视觉问答
目前的视觉问答系统都是由视觉处理、语言处理和多模态融合等几个关键部分组成,因此需要对应的图像处理方法和语言处理方法,而不同的处理方法在处理模态数据并进行理解的过程中,总会产生偏差,甚至出现偏置,正如某些论文中提到的即使没有输入图像,仅仅给出问题,系统有时也能够得到正确答案。为此,研究端到端的视觉问答系统,将图像处理和语言处理部分直接取消,也许是另一个值得研究的内容。但同时值得注意的是,这种针对某种模式的彻底改变,难度和可行性是首先需要评估和研究的。
5 结语
语言处理方法在视觉问答中起着沟通、引导图像内容和最终答案的作用,基于语言处理方法的问题解析对于最终答案的正确与否意义重大。本文首先分析并指出了语言处理方法对于视觉问答的价值和重要性;进一步的,对于目前广泛使用的语言处理方法进行了系统性阐述,并根据其先进性和构成要素将其分为三类,分别是基础型语言处理方法、进阶型语言处理方法和专有型语言处理方法,同时对每一类语言处理方法的研究现状进行了调研和分析;最后对于三类方法各自的特点和选用依据进行了阐述,为后续研究人员开展视觉问答语言处理方法研究奠定了基础。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
汽车观察(2019年2期)2019-03-15
汽车观察(2018年12期)2018-12-26
汽车观察(2018年12期)2018-12-26
能源(2018年8期)2018-09-21
中国现代医生(2014年10期)2014-04-23
电影新作(2014年1期)2014-02-27
海外英语(2013年7期)2013-11-22
