
并行查询交互度量及执行计划选择
2022-09-06 11:08柳浩楠牛保宁程永强
计算机工程与应用 2022年17期
柳浩楠,牛保宁,程永强
太原理工大学 信息与计算机学院,山西 晋中 030600
在绝大多数以数据库管理系统(database management system,DBMS)为支持的应用软件中,查询操作占据的比重最大。查询不仅直接决定了系统的运行效率,也影响着应用的性能。查询执行计划是查询执行的操作步骤,一个查询可以有多种执行计划[1]。查询提交运行时,DBMS 为查询生成一组不坏的执行计划,计算代价,从中选择一个较优执行计划[2]。
查询的并行执行可以提升资源利用率和吞吐量,同时,查询之间的相互影响——查询交互(query interaction,QI)[3-4]使得查询执行计划的选择成为一个难题。QI 是指两个或两个以上的查询并行运行时,查询对系统资源的争用而引起的执行效率的改变[5],体现于查询等待资源与使用资源时间的改变,即查询执行计划代价的改变。由于QI 的存在,较优执行计划的选择需要考虑查询组合及其QI[4]。并行执行的查询集合被称为查询组合(query mix),并行执行的查询个数被称作并行度(multi-programming level,MPL)。由于存在调度、资源竞争等难以量化的动态因素,查询优化器在为一个新进入系统的查询选择执行计划时,难以量化DBMS的资源情况和运行状态,导致难以为该查询选择合适的执行计划。
目前,把QI用于执行计划选择的方法,通过建立分析模型来估算QI[4-6]。这些方法能够在一定程度上反映QI,但存在以下问题:(1)对QI 建模限于查询响应时间的函数,不考虑DBMS 的系统状态。QI 对系统的影响是多方面的,很难用一个值来描述,准确地度量QI需要考查系统的多个维度。(2)预先设定的函数模型难以准确描述复杂多变的QI。
深度学习为QI 的度量提供了新的思路:通过训练深度学习神经网络,建立一个“黑盒”模型,来拟合难以表示的复杂多变的函数关系,在建立模型的过程中可以不用考虑模型的细节,而重点关注模型的输入与输出。更进一步,在度量QI的基础上,深度学习神经网络也可以用来为查询动态地选择较优执行计划。
按照上述思路,本文尝试把深度学习技术用于并行查询的执行计划选择,提出利用查询组合的执行计划特征(features of execution plan,FEP)和并行场景下QI 特征参数的变化量作为输入,训练深度学习神经网络,估算QI;用估算的QI 作为查询交互特征(features of query interaction,FQI),再结合查询的候选执行计划特征(features of candidate plan,FCP)共同作为选择较优执行计划的依据。
本文的创新点如下:
(1)把查询的平均响应时间、平均执行时间、平均I/O 时间和平均缓冲区命中率作为QI 的特征参数;提出一种多维度查询交互度量模型(multi-dimensional measurement of query interaction,MMQI),采用双向长短期记忆(bidirectional long-short term memory,Bi-LSTM)神经网络,把FEP作为模型的输入,预测QI特征参数的改变,度量QI。
(2)引入QueryMixRating,表示一个查询在查询组合中受QI 影响导致的平均响应时间的改变程度,作为度量QI 与选择较优执行计划的依据;提出执行计划选择(execution plan selection,EPS)模型,把MMQI 的输出作为FQI,与FCP 融合后作为另一个Bi-LSTM 的输入,为查询选择较优执行计划。
1 相关工作
与本文内容相关的研究可以分为对QI 的度量方法、选择查询执行计划的方法和深度学习在查询优化方面的应用。
(1)对QI的度量
在查询并行执行场景下,为查询选择合适的执行计划需要考虑QI的因素。目前对于QI的估算采用建立数学分析模型的途径。B2L&B2cB[7]模型用BAL(buffer access latency)——一种基于逻辑I/O 的度量标准来量化并行执行的查询性能影响,采用查询并行与单独运行的时间差衡量QI。QueryRating[5]方法通过计算查询组合中两两查询并行运行与单独运行的时间比值很好地度量两个查询的QI。TRating[6]模型认为查询单独运行的时间会影响其加入查询组合后受QI 作用的时长,显示出QI是影响查询的主要因素。
(2)选择查询执行计划的方法
DBMS 的查询优化器负责为查询选择较优执行计划,采用基于规则和代价的查询优化两个层次,分别为查询生成和选择执行计划[8]。在执行计划生成层次,查询优化器将查询语句转化为关系代数表达式,根据基本表的扫描方式、关系间的连接方式与连接顺序[9]为查询生成执行计划,并计算开销;在执行计划选择层次,查询优化器根据查询所涉及的关系、数据分布、索引等情况,结合DBMS 的静态参数配置,选择较优执行计划。PLASTIC[10]模型假设数据库系统是静态的,通过计算查询的相似度生成聚类,构建查询分类器为新进入的查询判定可能所属的类别而确定查询的执行计划,忽略了QI 对查询选择执行计划的影响。TRating[6]模型综合考虑了查询受到QI 的阻力大小QIs 和特定执行计划与所有执行计划响应时间之和的比值Fac,将二者共同作为选择执行计划的关键因素,可以较好地解决简单QI 场景下的并行查询执行计划选择问题。
(3)深度学习在查询优化方面的应用
近年来,用深度学习的手段优化数据库性能取得了良好的效果,如优化代价模型或提高基数估计准确性等[11-14]。Neural Optimizer[15]利用深度网络估计代价,为查询生成较优执行计划。QPPNet[16]模型引入运算符级神经单元构造树型网络结构进行查询性能预测,显示了查询执行计划父子节点的关联。图嵌入模型GPredictor[17]将查询特征、运算符相关性编码为顶点和边,构建图嵌入网络预测查询性能。采用LSTM 对查询执行时间区间的预测,有较好的效果[18]。LSTM-FCN[19]考虑目标查询响应时间的改变量与剩余各查询受到目标查询影响而引起的响应时间改变量之和,作为设计标签的目标函数,忽略了查询组合中剩余查询之间QI的改变;其设定查询组合中剩余各查询对目标查询造成响应时间的改变量作为FQI,结合目标查询选择不同执行计划时的查询组合特征,在并行查询较优执行计划选择方面取得了不错的效果,未能从DBMS 的角度细粒度地考虑QI 对查询组合的影响。
针对目前QI 复杂多变,数学分析模型难以准确度量的问题,本文提出采用Bi-LSTM 结合特征参数度量QI,为查询动态选择当前查询组合下的较优执行计划。
2 并行查询交互度量及执行计划选择
使用深度学习实现并行查询交互度量及执行计划选择的关键是:寻找能够准确反映QI 的特征参数,设计合适的输入与输出特征,以及选取合适的深度学习模型。
本文涉及到的相关符号定义如表1所示。

表1 相关符号定义Table 1 Definition of related symbols
2.1 QueryMixRating的计算
QueryRating[5]通过计算查询并行时和单独执行时平均响应时间的比值,表示查询qi在MPL=2 时的查询交互,度量查询qi受QI的影响程度。在MPL>2 的情况下,本文推广QueryRating,把查询组合M中其他查询对qi的影响看作一个整体,定义Rqi/M-qi为qi在查询组合M中的QueryMixRating:

其中,tqi/qM表示qi在M中执行的平均响应时间,tqi表示qi单独执行的平均响应时间。
2.2 QI特征参数的选取
查询的响应时间体现了查询使用资源与等待资源的整体效果,但是在选择并行查询的执行计划时,需要考虑QI对系统资源使用的细粒度和多角度的影响。一方面,查询或查询执行计划不同,QI 也不同。例如,某些查询或查询执行计划包括多种聚合函数,此类操作会占用大量的CPU 资源;而另一些查询或查询执行计划的全表扫描操作却会引起大量的I/O。它们对系统资源的消耗体现在查询的执行时间或I/O 时间上。另一方面,DBMS为提高查询效率提供了多种优化手段。查询执行时,DBMS 将查询所需要的数据从外存加载到内存,并且将一部分数据写入共享缓冲区(shared buffer)以提高下一次读取的速度。查询并行执行时,查询可能因读取其他查询写入共享缓冲区的数据而减少I/O,也可能因多个查询同时写入共享缓冲区而导致缓存的数据量减小,使下一次执行时I/O时间增加。
查询的平均执行时间、平均I/O时间、平均缓冲区命中率是查询实际执行代价的具体体现,它们的变化量分别体现QI 引起查询在使用CPU、使用I/O 资源、数据缓冲与共享方面的变化,采用它们结合查询的平均响应时间的变化量,能够更全面地反映QI 对查询的影响。QI特征参数的定义见表2。

表2 QI特征参数Table 2 QI parameters
2.3 QI特征参数变化量的计算
并行场景下,设{texec,tio,rbuf}为QI 特征参数集,依次为查询的平均执行时间、平均I/O 时间和平均缓冲区命中率。其中,QI特征参数的变化量uix计算方式如下:

x为某QI 特征参数,xqi/qM表示查询qi在查询组合M中执行时特征参数x的值,xqi表示查询qi单独执行时特征参数x的值。
2.4 问题定义
并行场景下,设M′={qi|1 ≤i≤MPL-1}为数据库系统中正在运行的查询组合,查询qj加入时,从查询qj的候选执行计划集合Q={qjk|k=1,2,…}中选择执行计划k,使得新查询组合M={M′,qjk}在单位时间内总工作量的变化量最大,即平均响应时间变化量的总和最小:

作为选择较优执行计划的目标函数,此时,M中任意查询qi的QI 状态为。其中,Rqjk/M′表示目标查询qj以执行计划k加入到组合M′后的QueryMixRating;Rqm/M-qm表示原查询组合M′中的查询qm在M中的QueryMixRating。
2.5 多维度QI度量模型MMQI
为了能够更准确地拟合QI,考虑到其复杂性,本文采用深度学习模型度量QI,尝试拟合查询执行计划特征与QI特征参数的变化量之间的复杂函数关系。
(1)模型的选择
查询组合的执行计划(查询组合中的所有查询执行计划的集合)不仅体现了查询自身的执行特征,也蕴含了查询组合的交互特性。考虑到查询执行计划的操作具有时序性,QI 随着查询组合的执行计划中操作的时序而改变,本文构造Bi-LSTM 模型拟合执行计划操作的交互与特征参数变化量之间的复杂函数关系,度量QI,其包含两个LSTM 单元分别从前向、后向提取相邻操作的相关性。Bi-LSTM的结构如图1所示,图中两个虚线框分别表示两个LSTM 单元。每个LSTM 单元包括三个门结构,使信息选择性通过,实现信息的保留或丢弃。LSTM 结构的细节如下[20]:ct是LSTM 当前对信息的记忆状态,W和b分别是权重系数和偏置系数;x是输入,h是输出,t表示当前时刻。⊗表示对应元素相乘运算,⊕表示加法运算。

图1 Bi-LSTM的结构Fig.1 Structure of Bi-LSTM
其中,遗忘门ft是LSTM 结构的第一个门,计算公式如下:

使用遗忘门得到经过遗忘处理后的信息。输入门是LSTM 的第二个门,用于决定保留的信息,计算公式如下:

其中,it是决定更新的信息,c~t是备选更新的信息,二者通过计算得到新的状态:

其中,fc·ct-1是丢弃信息的操作,it·c~t是保留信息的操作。输出门是LSTM结构的第三个门,计算:

得到ht作为输出,ct为当前状态作为下一时刻遗忘门的输入,循环往复。
特别地,考虑到查询执行计划中前驱操作的结果往往被用于后继操作,后继操作的类型常常与前驱操作类型相关联,因此,采用Bi-LSTM网络从两个方向分别学习执行计划操作序列中操作类型与操作结果之间的相关特征。在Bi-LSTM中,从前向后执行运算的LSTM单元在每一步计算时,其输入门和遗忘门分别参与对前驱操作特征的选择性记忆和遗忘;从后向前执行运算的LSTM单元在每一步计算时,对后继操作的特征进行选择性记忆和遗忘。这种双向提取的序列特征比单向提取的序列特征能更充分地表达序列中复杂的QI 特性,在把获得估算的QI特征参数的变化量作为最终输出Y时,能够实现更准确的并行查询交互的度量。在训练阶段,为了拟合FEP到QI特征参数的映射关系,模型需要根据误差动态地调整庞大的参数矩阵,花费的时间较长;在预测阶段,模型对输入的特征向量和参数矩阵只进行一次运算,故能快速得出QI 特征参数变化量的预测值。查询执行计划可以表示为非完全二叉树[8]。例如,关系T1包含字段c1、c2,T2包含字段c3,T2的字段c3上存在索引,则查询“SELECTT1.c1FROMT1,T2WHERET1.c2=T2.c3GROUP BYT1.c1”的执行计划树如图2所示。

图2 查询示例的执行计划树Fig.2 Execution plan tree of example query
在执行计划树中,子节点的操作顺序先于父节点,因此,本文通过后序遍历可得到该执行计划的一个可能的操作序列为{SeqScan,IndexOnlyScan,Hash,Hash-Join,HashAggregate,Sort,GatherMerge},对每个操作编码,生成该查询的执行计划特征。在查询执行过程中,执行计划树中兄弟节点执行的先后顺序是可变的,Bi-LSTM 能够从两个方向提取由于这种执行顺序不同引起的QI 的不同。目标查询加入查询组合的时刻不同,并行查询操作序列节点之间的对位也不同,Bi-LSTM从两个方向提取由于这种对位不同引起的QI的不同。这些不同体现在多个方面,本文选择体现CPU、I/O和缓冲区使用情况的三个最为显著的参数、细粒度地捕捉上述情况下的QI。
(2)模型的输入
按照上面的讨论,MMQI模型的输入为查询组合的执行计划特征。下面讨论如何从查询执行计划提取特征,并对其编码,以及采用何种组合方式形成查询组合执行计划特征。
对于单个查询FEP 的提取,可以遍历查询执行计划树,获取查询执行的操作序列,抽取它的特征。通过后序遍历查询组合中每个查询的查询执行计划,获取到查询组合的FEP 作为模型的输入。考虑到查询执行计划有多个操作,每一个操作具有不同的特性,对每一个操作按照操作类型、操作的关系、操作涉及关系的字段、结果行宽度进行独热(one-hot)编码,映射到向量v={v0,v1,v2,v3}[18]。
查询组合的执行计划特征是查询组合中所有查询执行计划特征的组合,本文将查询组合中所有查询的执行计划特征拼接,生成查询组合的执行计划特征。按照上述方法,将查询组合M={M′,qjk}中的每一个执行计划特征进行编码,拼接成查询组合的计划特征:

作为MMQI模型的输入。其中q1,q2,…,qn表示原查询组合中每个查询的执行计划特征,qjk表示目标查询的执行计划特征。
(3)模型的输出
借鉴QueryRating[5]的计算方式,定义查询的平均执行时间、平均I/O 时间和平均缓冲区命中率在并行与单独执行时的比值来反映QI,结合QueryMixRating 体现并行场景下查询的交互特征,作为MMQI 模型的输出。从候选执行计划集合Q={qjk|k=1,2,…}为目标查询qj选择执行计划k时,模型的输出为:


其中,yik对应查询qi的输出,Rqi/M-qi表示查询qi在当前查询组合M中平均响应时间的变化量,即QueryMixRating;表示查询qi平均执行时间的变化量;表示查询qi平均I/O 时间的变化量;表示查询qi平均缓冲区命中率的变化量。
2.6 选择执行计划的模型EPS
为了尽量涵盖QI 对执行计划选择的影响,本文采用深度学习模型充分考虑并行查询执行计划与QI的特征,为查询动态地选择较优执行计划。
(1)模型的选择
将FCP纳入选择执行计划模型的输入,使EPS模型拟合并行场景下目标查询的FCP 与较优执行计划的复杂函数关系。为了避免特征梯度消失的问题,选择LSTM作为模型的一部分,采用全连接层融合LSTM层输出的信息,为查询选择较优执行计划。为每个目标查询设计3 种候选执行计划,即k=3,模型的结构如图3所示。

图3 选择执行计划模型的结构Fig.3 Structure of model for selecting execution plan
将MMQI 模型估算的QI 特征参数变化量按照最大值划分区间编码,生成FQI,与候选执行计划FCP合并共同作为全连接层的输入,为查询选择较优执行计划。
(2)模型的输入
设计FCP为目标查询在查询组合M下的所有执行计划特征的后序编码:

作为EPS模型输入特征的一部分。特别地,当目标查询选择每个候选执行计划时,将MMQI模型输出查询组合的平均响应时间、平均执行时间、平均I/O 时间、平均缓冲区命中率的变化量组合起来,作为M={M′,qjk}下的查询交互特征:

按最大值划分区间进行独热编码,与FCP拼接生成:

作为EPS模型的输入。
(3)模型的输出
为目标查询qj选择较优执行计划,设计EPS 模型的标签。模型的标签:

每一位对应qj的查询交互特征FQI 与候选执行计划FCP。在训练时,根据目标函数指定的较优执行计划的对应位为1,其余位为0;在预测时,选择L中最大值所在位对应的执行计划为目标查询qj的较优执行计划。
3 实验分析
本章通过实验验证MMQI 模型和EPS 模型的可行性。实验采用TPC-H[21]测试基准的查询模板Q3、Q4、Q7、Q10、Q14、Q22,为它们选择执行计划进行验证。
3.1 实验方案的设计
(1)实验环境
实验所用的服务器为Intel®Xeon®CPU E5-2609 v4@1.70 GHz,RAM 为16.0 GB,NVDIA GeForce GPU GTX1660Ti 6 GB,操作系统为CentOS Linux release 7.3.1611(Core),编程语言为Java 和Python,数据库为PostgreSQL13.0(shared Buffer=4 096 MB),测试基准为TPC-H 2.18(SF=10)。
(2)执行计划的获取
用PostgreSQL 中的pg_hint_plan 插件,通过hint 提示为查询指定代价相差不大的执行计划,用explain 关键字获取查询的执行计划,通过修改表的连接方式、指定索引等方法为查询指定不同的执行计划。为了准确刻画一个查询真正的执行代价,本文为每个查询模板指定3 种候选执行计划,这3 种候选执行计划的确定考虑到以下三个方面:查询优化器生成的候选执行计划的数量非常庞大,因此本文希望一个候选执行计划能够代表一类代价相近的执行计划,通过不同的执行计划将查询可能的执行时间划分成不同的区间;设计2个候选执行计划导致对查询执行代价的划分过于粗糙,50%的随机正确率会造成较多的假阳性数据,干扰对模型的验证;设计4个及以上的候选执行计划对简单查询来说,会造成它们的执行代价范围的“重叠”。
(3)QI特征参数的获取
为了计算四种QI 特征参数的变化量,需要获取查询组合运行的原始系统参数。PostgreSQL 的系统视图pg_stat_statements(https://www.postgresql.org/docs/13/pgstatstatements.html)提供查询反映QI状态的字段。获取读取的共享块数(shared_blks_read)、命中的共享块数(shared_blks_hit)和执行次数(calls)字段,用公式(17)计算平均缓冲区命中率:

平均执行时间(mean_exec_time)字段直接使用;获取块读取时间(blk_read_time)和块写入时间(blk_write_time)字段,用公式(18)计算平均I/O时间。
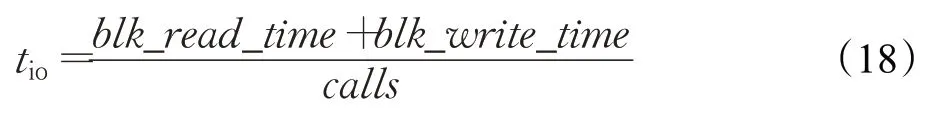
在实验前清空pg_stat_statements视图,并随机执行若干查询以预热缓冲区。
(4)数据集的生成
本文将TPC-H的6个模板作为目标查询,为每一个查询指定3 个候选执行计划。将同一查询的不同执行计划看作不同的查询,与相同标准下定义的73 个查询自由组合,当MPL=n时,生成3C16C7n3-1个样本作为MMQI 的 输 入。PostgreSQL 共 有34 种 操 作 类 型,在TPC-H 中有8 张表、61 个字段。实验发现,当结果行宽度设置最大为20 时,可以包含所有的查询结果行宽度。单个查询的最大操作数为25,因此,编码一个查询执行计划的特征向量为(34+8+61+20)×25=3 075位,一个查询组合的FEP 维数为3 075n。采用3.1 节(3)的方法,计算查询组合中每个查询4种QI特征参数的变化量作为输出,用于训练MMQI模型。
读取MMQI 模型估算的QI 特征参数的变化量,并按照最大值175划分区间独热编码,结合FCP作为选择执行计划模型的输入。因此,编码一个查询组合中四种QI 特征参数的变化量维数为175×4n=700n。目标查询选择三种不同执行计划时该组合的FQI 维度共计3×700n,此时EPS模型的输入样本数为C16C7n3-1。同理,将三种候选执行计划编码,获得FCP 的维数为3 075×3=9 225。故EPS模型的输入特征维度为3×(3 075+700n)。
(5)模型的参数调优与训练
用两层LSTM层作为Bi-LSTM层,每层LSTM单元设置为64,输出结果整合方式为拼接(concat)。全连接层单元个数为2n。最后一层单元数为3,采用softmax激活函数实现多分类任务。全连接层适当采用l1正则化,添加dropout 层,选择失活比率0.2 以防止模型过拟合。模型的优化器采用Adam,学习率为0.001。MMQI模型和EPS 模型的损失函数分别为mse 和categorical_crossentropy。
将数据集按照4∶1 划分训练集和测试集。首先训练MMQI 模型,从MMQI 模型中获得估算的QI 特征参数的变化量后,利用其输出构造FQI,编码后融合FCP,结合标签训练EPS模型。
3.2 实验结果分析
(1)与TRating[6]、查询优化器的对比
实验在MPL=2,3,4,5 时,为新进入的查询选择较优执行计划。MMQI-EPS 与TRating、查询优化器选择较优执行计划的准确率对比如图4 所示。同一实验场景下,MMQI-EPS 选择较优执行计划的准确率相对于TRating平均提高15.1个百分点。这是因为:TRating模型仅通过查询的响应时间建模,未考虑到QI 的多个维度;分析模型对QI 的拟合能力有限。不同MPL 下,MMQI-EPS 均优于TRating,说明本文合理地选取了QI特征参数,对QI的度量更具体,为选择执行计划模型提供了可靠的输入。TRating较查询优化器提升23.5个百分点,是因为TRating 考虑了QI,说明QI 是选择较优执行计划时不可忽略的依据。

图4 与TRating、查询优化器的准确率对比Fig.4 Comparison of accuracy with TRating and optimizer
在MPL=2,3,4,5 时,模型比查询优化器的平均准确率高(31.2+36.4+44.5+46.1)/4=38.6 个百分点。随着MPL 增大,查询优化器对较优执行计划的判断能力大幅降低,这是因为查询优化器仅依据并行度、数据分布、缓冲区大小、单个执行计划代价等静态参数为并行查询选择较优执行计划,不能考虑复杂多变的QI。当MPL=5 时,查询优化器的准确率接近33%,说明在复杂的QI场景下,查询优化器选择执行计划的方法近似于随机选择。MMQI-EPS的准确率比查询优化器有大幅提升,说明模型充分地考虑了QI 这一重要因素,为并行查询选择较优执行计划。
(2)模型的性能
在MPL=3时,按照Q22、Q14、Q10、Q7、Q4、Q3的顺序执行6 个查询3 次,记录总的执行时间。用查询优化器和MMQI-EPS为查询选择较优执行计划的情况下,总执行时间分别为626.29 s 和563.45 s,MMQI-EPS 的用时较查询优化器下降了10 个百分点。这是因为:查询优化器对QI 的考虑有限,选择的执行计划并不是合适的,导致总执行时间较长;而MMQI-EPS 充分地考虑了QI的影响,为查询选择了较优执行计划,使总执行时间缩短。表3为查询第二次执行时,MMQI-EPS选择的较优执行计划,前五个查询的执行计划不同于查询优化器选择的DEFAULT执行计划。

表3 模型选择的较优执行计划Table 3 Better execution plans selected by model
模型选择的较优执行计划与查询优化器不同,引起了总执行时间的缩短,这说明MMQI-EPS可以更灵活地为并行查询选择较优执行计划。模型为Q22 选择的较优执行计划和查询优化器相同,是默认执行计划;为Q3、Q4、Q10、Q14 选择采用索引扫描的执行计划,提高了检索速度;为Q7 选择关闭MergeJoin 的执行计划,使DBMS 采用HashJoin 操作,减少了排序量。由此可知,MMQI-EPS 选择较优执行计划的方法提高了并行查询的执行效率。
(3)并行度对模型准确率的影响
在不同并行度下,MMQI-EPS选择较优执行计划的准确率对比如表4所示。

表4 不同并行度下准确率对比Table 4 Comparison of accuracy under different MPL
由表4 可知,随着MPL 的增大,MMQI-EPS 的准确率分别下降5.8、4.9、3.4 个百分点。这是因为:QI 的复杂程度愈高,对执行计划的代价改变愈大,使选择较优执行计划的难度增加;当MPL继续增加时,MMQI-EPS的准确率略有下降但保持稳定。
(4)数据集大小对模型准确率的影响
在不同的数据集大小下,MMQI-EPS选择较优执行计划的准确率如表5所示。本文分别指定2 000、4 000、6 000和7 000个样本进行训练。

表5 不同数据集大小下的平均准确率Table 5 Mean accuracy in different size of dataset
由表5 可知,随着训练样本数增加,MMQI-EPS 模型的平均准确率逐渐提升。当样本数超过6 000 时,模型准确率的提升随样本数的增加缓慢。当样本数为7 000 时,模型的准确率比6 000 提升0.8 个百分点。采集查询的原始系统参数需要完整的执行查询,耗费大量的时间,因此,综合考虑模型的准确率和数据收集成本,本文选择6 000个样本作为实验的数据集。
(5)模型的时间复杂性
在本文的实验环境下,从开始训练到模型收敛时,MMQI-EPS两部分的训练时间和总训练时间如表6所示。

表6 MMQI-EPS的训练时间Table 6 Training time of MMQI-EPS
分析表6 可知,随着MPL 的增加,MMQI 和EPS 模型的训练时间均有所增加。当MPL=n时,按照3.1节(4)的方法,模型输入和输出的维度与MPL 直接相关。随着MPL 增加,MMQI 的训练时间分别增加33.09 s、49.78 s、74.81 s,这是因为MMQI 模型的输入和输出维度均受MPL的影响,MPL增大时,模型的输入特征FEP增大,需要回归预测的QI特征参数的变化量增多;QI的复杂性不随MPL 的增加而线性增大,模型拟合逐渐复杂多变的QI需要更大的计算量。EPS模型的输入特征维度比MMQI大,但是训练时间较短,分析认为:EPS模型解决的是简单的分类问题,其输出是固定的3 维标签;目标查询qj不变时,FCP不会改变,模型的输入特征受到MPL 的改变时仅体现在FQI 的维度上,易于模型的训练。
为了验证模型选择执行计划的效率,本文使用pg_stat_statements视图的字段mean_plan_time获取查询优化器的平均计划时间,与MMQI-EPS预测查询较优执行计划的时间进行对比。表7是本文选取的6个查询模板在MPL=2,3,4,5 时,MMQI-EPS 与查询优化器的选择执行计划的平均时间差。

表7 查询优化器与MMQI-EPS选择执行计划的时间差Table 7 Time difference between optimizer and MMQI-EPS in selecting execution plan
在本文的实验环境下,仅在预测阶段,MMQI-EPS选择单个执行计划的时间小于2 ms,而查询优化器选择较优执行计划的时间在10~100 ms 之间,远大于模型。这是因为查询优化器选择较优执行计划的两个层次需要生成查询执行计划,再根据各种系统静态配置综合地给出较优执行计划;而MMQI-EPS模型只需要根据输入向量与训练好的参数矩阵进行线性运算,运算速度较快。但是,在执行预测之前,加载MMQI-EPS 两部分模型的平均时间分别为6.67 s和4.69 s,因此模型只适合一次性加载到内存、批量地为查询生成较优执行计划的场景,不适合间断性地选择较优执行计划。
(6)与LSTM-FCN[19]的对比
在本文的实验环境下,使用公式(3)作为目标函数时,MMQI-EPS 和LSTM-FCN 选择较优执行计划的准确率和训练耗时对比如图5所示。

图5 不同并行度下MMQI-EPS和LSTM-FCN对比Fig.5 Comparison of MMQI-EPS and LSTM-FCN under different MPL
MPL<4 时,LSTM-FCN 选择较优执行计划的准确率优于MMQI-EPS;MPL≥4时,MMQI-EPS优于LSTMFCN;LSTM-FCN 的准确率随并行度的增加下降较快。LSTM-FCN 将目标查询与组合中剩余各查询并行时的QueryRating[5]作为FQI,对QI 的描述是粗粒度的,在MPL 较低时,QI 复杂度不高,能够达到较高的准确率。在MPL 增大时,QI 变得复杂,需要细粒度的描述,LSTM-FCN的单向性和QueryRating的粗粒度导致其预测精度降低,而MMQI-EPS 多参数细粒度地度量QI 引起每个查询感知到系统在CPU、I/O 和缓冲区资源的变化,通过Bi-LSTM 更充分地度量QI。LSTM-FCN 为目标查询选择不同执行计划时,将剩余查询的特征纳入选择计划模型的输入,造成冗余,削弱了模型在MPL较大时对不同执行计划的区分能力。
在时间复杂性方面,由于MMQI-EPS通过回归预测QI 特征参数的变化量来度量QI,再结合FCP 选择较优执行计划,其训练时间较长;在预测时,LSTM-FCN 和MMQI-EPS预测较优执行计划的耗时接近。
4 结语
查询是DBMS的主要负载,为查询选择合适的执行计划是提高系统性能的关键。当查询交互存在时,查询优化器面临代价估计、选择执行计划不准确的问题,而采用简单分析模型度量查询交互较为困难。鉴于此,本文合理地考查特定的QI 特征参数,创新性地提出使用MMQI-EPS模型度量查询交互,为并行查询选择较优执行计划,并通过实验验证了其合理性,具有一定的现实意义。当查询执行场景更加复杂时,如何从其他多个维度更准确地度量查询交互,保持模型预测的准确率,或建立图神经网络模型值得本课题继续探索。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
空间科学学报(2020年1期)2021-01-14
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
五邑大学学报(自然科学版)(2019年3期)2019-09-06
中国交通信息化(2019年12期)2019-08-13
江西教育B(2019年2期)2019-04-12
计算机与数字工程(2018年12期)2019-01-02
中国诗歌(2018年6期)2018-11-14
计算机系统应用(2018年3期)2018-04-21
中国交通信息化(2017年8期)2017-06-06
