
基于特征增强的开放域知识库问答系统
2022-09-06 11:09李帅驰杨志豪王鑫雷韩钦宇林鸿飞
计算机工程与应用 2022年17期
李帅驰,杨志豪,王鑫雷,韩钦宇,林鸿飞
大连理工大学 计算机科学与技术学院,辽宁 大连 116024
近年来,随着诸如DBpedia[1]、Freebase[2]、Yago[3]、NLPCC-ICCPOL-2016KBQA 评测任务[4]发布的中文知识库等大规模知识库(knowledge base,KB)的产生,基于知识库的问答(knowledge based question answering,KBQA)任务逐渐成为自然语言处理研究领域的热点之一。知识库是将知识结构化存储的数据库系统,其中的知识以三元组的形式存在,如<实体,谓词,目标值>。基于知识库的问答系统以知识库作为知识来源,理解用户输入的自然语言形式的问题,识别出实体和谓词查找对应的目标值作为答案。例如,对于问题“谁是奥巴马的妻子?”,结合三元组<贝拉克·奥巴马,妻子,米歇尔·奥巴马>,可以查找到米歇尔·奥巴马作为答案。根据回答问题所需三元组的数目为单个或者多个,可以分为简单问题和复杂问题,本文工作聚焦在简单问题问答的研究。
现有的中文简单问题知识库问答的主流方法通常将问答任务拆分为实体链接和谓词匹配两个子任务,其中实体链接包含实体提及识别和实体消歧两部分,构建一个流水线式的问答系统,如图1 所示。以“精忠岳飞由谁运营?”这一问题为例,首先通过实体提及识别模型识别问句中的实体提及“精忠岳飞”;结合知识库可以生成与“精忠岳飞”相关的候选实体集合,通过实体消歧模型打分,将得分最高的候选实体“精忠岳飞(2014年全新战争策略游戏)”作为该问题的主题实体;结合该主题实体和知识库,将主题实体的一度谓词作为候选谓词集合,接下来将实体提及替换为统一标识符“entity”的问句和候选谓词输入谓词匹配模型,得到得分最高的谓词“运营商”;结合实体和谓词,查询知识库得出最终答案。
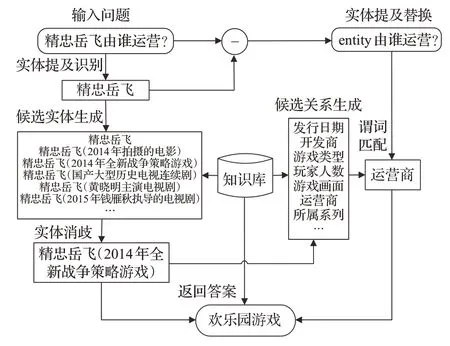
图1 知识库问答整体流程Fig.1 Overview of CKBQA
对于上述示例中,问题中提及的“精忠岳飞”,在知识库中可以找到多个相关的实体,问答系统应该判断问句询问的“精忠岳飞”是哪一个,在问句较短、信息较少的情况下为实体消歧任务带来了难度。并且,同一个问句意图可以有不同的表达形式,然而知识库中的三元组表达形式是固定的,导致了问题与知识库知识的差异性,为谓词匹配任务带来了挑战。另外,在开放域知识库中,实体数量和谓词的数量往往规模较大,而用于训练的数据集由于需要人工标注通常规模较小。针对上述问题,本文提出一种基于中文预训练语言模型BERT[5]的流水线式问答系统BERT-CKBQA,用于提升中文知识库问答的性能,其创新性在于:(1)融合知识库的拓扑信息,引入从候选实体出发的一度谓词集合特征,来增强候选实体的上下文信息的BERT-CNN模型进行实体消歧,提高实体消歧的准确率,进而启发式地缩小候选谓词集合的规模,提升系统的问答效率。(2)提出通过注意力机制引入答案实体一度链出谓词的BERTBiLSTM-CNN 模型进行谓词匹配,提升谓词匹配任务的性能。(3)BERT-CKBQA 方法在NLPCC-ICCPOL-2016KBQA数据集上取得了最高的平均F1值,为88.75%。同时该方法在各个子任务中也取得了较好的结果,充分说明了该方法的有效性。
1 相关工作
目前主流的知识库问答方法主要分为:语义解析方法、信息检索方法和向量建模方法。语义解析方法[6]对自然语言问句成分进行解析,将查询转化成逻辑表达式,再结合知识图谱转换成知识图谱查询,得到答案,如谓词逻辑表达式[7]、依存组合语义表达式[8]等。这种方法虽然可解释性强,但需要大量人工标注,且在开放域知识库中难以解决歧义。信息检索方法从问句中提取关键信息,用这些信息限定知识库的知识范围再检索答案。Yao 等人[9]首先抽取问句中的实体和谓词,构建问题的图模型,与知识库进行匹配。王玥等人[10]提出了DPQA,采用动态规划的思想进行问答。随着深度学习的发展,基于向量建模的方法逐渐兴起。Xie 等人[11]使用深度语义相似度模型,计算问题和谓词之间的相似度。Hao 等人[12]训练TransE 模型来获取知识库中的实体和谓词的向量表示,并与问题向量匹配,选择最相似的三元组。
在中文知识库问答的研究中,多数工作集中于NLPCC-ICCPOL 2016 KBQA 任务发布的数据集与知识库。Wang等人[13]使用卷积神经网络和门控循环单元模型获取问句向量表示。Lai等人[14]通过别名词典生成候选实体,构建人工规则进行实体消歧,并且基于词向量计算余弦相似度对谓词打分。随着预训练语言模型BERT的出现,Liu等人[15]针对CKBQA 流程中不同的子任务,使用基于BERT的预训练任务的模型进行微调,在开放域中文知识库问答任务上取得了相当不错的结果。
2 方法与模型
2.1 实体链接
本文提出的BERT-CKBQA流水线式问答系统的实体链接模型分为实体提及识别和实体消歧两部分。
首先,实体提及识别模型用于识别问句中的主题实体,作为问题语义解析的出发点,例如“精忠岳飞由谁运营?”中的“精忠岳飞”为该问题的主题实体的提及形式。实体提及识别可以看作一个序列标注任务,该部分数据使用的是序列标注任务中常用的标签体系“BIO”标签,其中,B 表示实体提及的起始位置,I 表示实体提及的中间或结尾位置,O表示该字符非实体提及。将问句中“精忠岳飞”对应的位置标记为“B I I I”,其他非实体提及部分标记为“O”,进行序列标注模型训练。
实体提及识别部分采用BERT-CRF[15]模型,首先将问题的字符序列Q输入到BERT预训练语言模型,得到每个字符的上下文表示,之后输入给CRF层,对输入特征序列求出条件概率最大的标注路径,即得到预测的标签序列,即得到问句中的实体提及。完成模型训练后,对输入的问题进行实体识别,得到实体提及m,如公式(1)所示:

接下来,由于自然语言问句中提及的实体可能对应知识库中存储的多个实体,因此在得到每个问句中的主题实体的实体提及之后,需要从知识库中生成与该实体提及相关的候选实体集合,并对这些候选实体集进行消歧,从而选择正确的候选实体。准确匹配问题中所询问的主题实体也可以为下一步的谓词匹配减小候选集规模,提升问答系统的效率。本文提出引入实体一度链出谓词特征的BERT-CNN 模型来提升实体消歧任务的性能,例如图1 中的问题,游戏类型的“精忠岳飞”更有可能有“运营商”这样的谓词。
在实体消歧部分,首先,为了获得与问句中主题实体更为接近的候选实体集,根据NLPCC-ICCPOL-2016KBQA 评测所提供的别名词典文件,将上一步识别的实体提及映射到该词典中,生成候选实体集合。对于无法映射的实体提及,依托知识库检索字符级别相似的实体作为候选实体集合。然后,将问句和候选实体集输入至BERT-CNN模型,通过卷积神经网络来增强BERT模型预训练的实体特征进行实体消歧,BERT-CNN模型如图2所示。
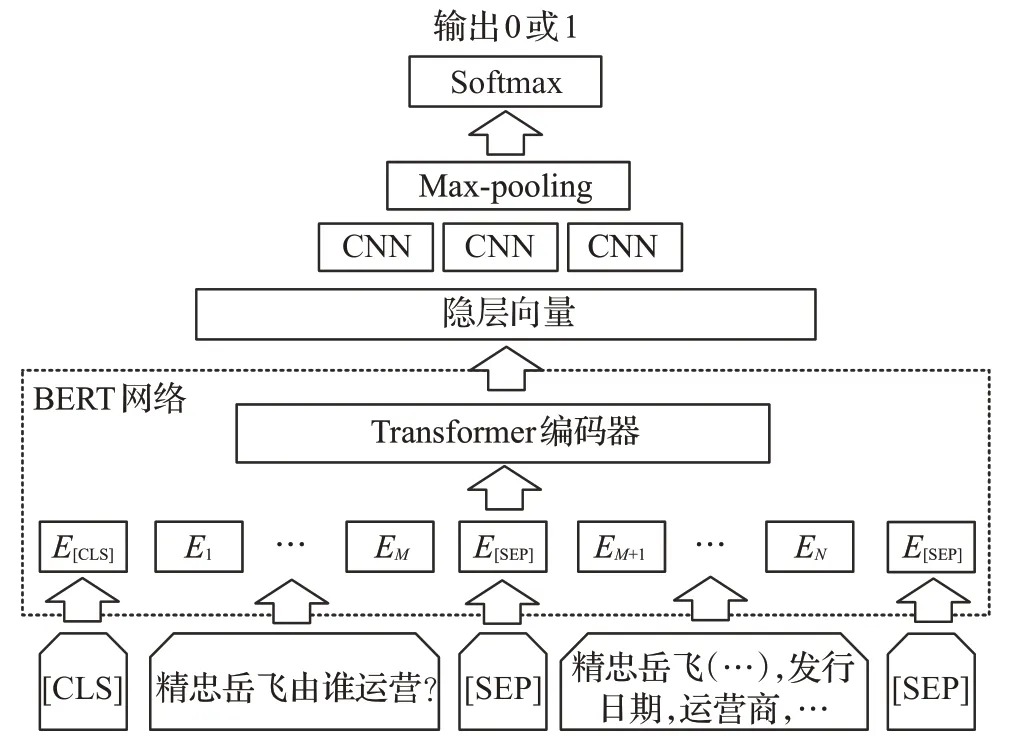
图2 实体消歧模型Fig.2 Entity disambiguation model
该子任务可以看作一个二分类任务,候选实体如果为标注的三元组中的主题实体,则输出标签1,否则输出标签为0。输入数据由[CLS],问题字符序列,[SEP],与谓词特征拼接的候选实体,[SEP]组成。其中一度链出谓词特征即为知识图谱中从候选实体出发,相连接的一度谓词的集合,如公式(2)所示。其中q表示问题,e表示候选实体,pi表示从e出发的一度链出谓词。
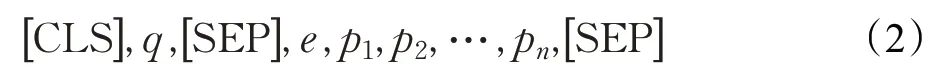
经过BERT 网络编码得到后四层encoder 输出的隐层向量,相加后得到隐层输出H,卷积层的特征C可以表示为公式(3):

其中,σ为sigmoid 函数,⊗为卷积运算,W为卷积核内的权重,b为偏置。H分别通过步长为1、3、5的三个卷积层提取特征。之后输入最大池化层,将得到的三个向量拼接后输入Softmax层分类,输出标签为0或1。损失函数为交叉熵损失函数,如公式(4)所示,训练时最小化损失函数。在预测时,将候选实体被预测为标签1的概率作为候选实体的得分。
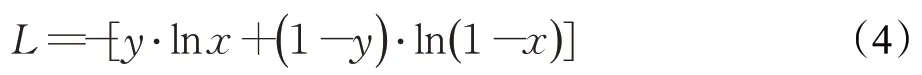
2.2 谓词匹配
由于自然语言问句的表达形式多样,不同的表达可能对应相同的问句意图,并且对于同一个主题实体会产生大量的不同谓词,这为开放域知识库问答任务带来了巨大挑战,如图一中问题的“由谁运营”与“运营商”之间的匹配。谓词匹配模型用于将问句中的谓词与知识库中的谓词匹配,理解问句意图,选择与问句最匹配的谓词。首先,实体消歧结果可以很大程度地减少候选谓词集合的规模,因此从实体消歧任务中获得的候选实体样本出发,检索知识库中该实体的一度谓词集合作为候选谓词集合。接下来,注意到在回答“精忠岳飞由谁运营?”问题时,通过加入候选谓词检索到的候选答案实体的一度链出谓词信息可以丰富候选谓词的信息,如图3中的“发行时间”“业务范围”等答案实体的一度链出谓词与候选谓词“运营商”有一定的关联。
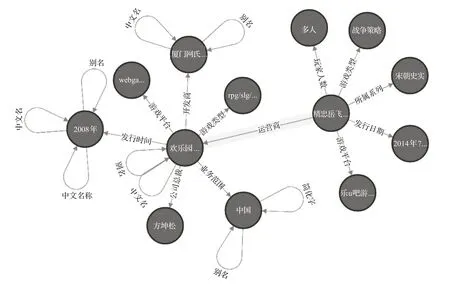
图3 知识图谱子图Fig.3 Subgraph of knowledge base
于是本文提出了一种通过注意力机制引入答案实体的一度链出谓词特征的BERT-BiLSTM-CNN 模型进行谓词匹配,丰富候选谓词在知识图谱中的结构信息,如图4所示。
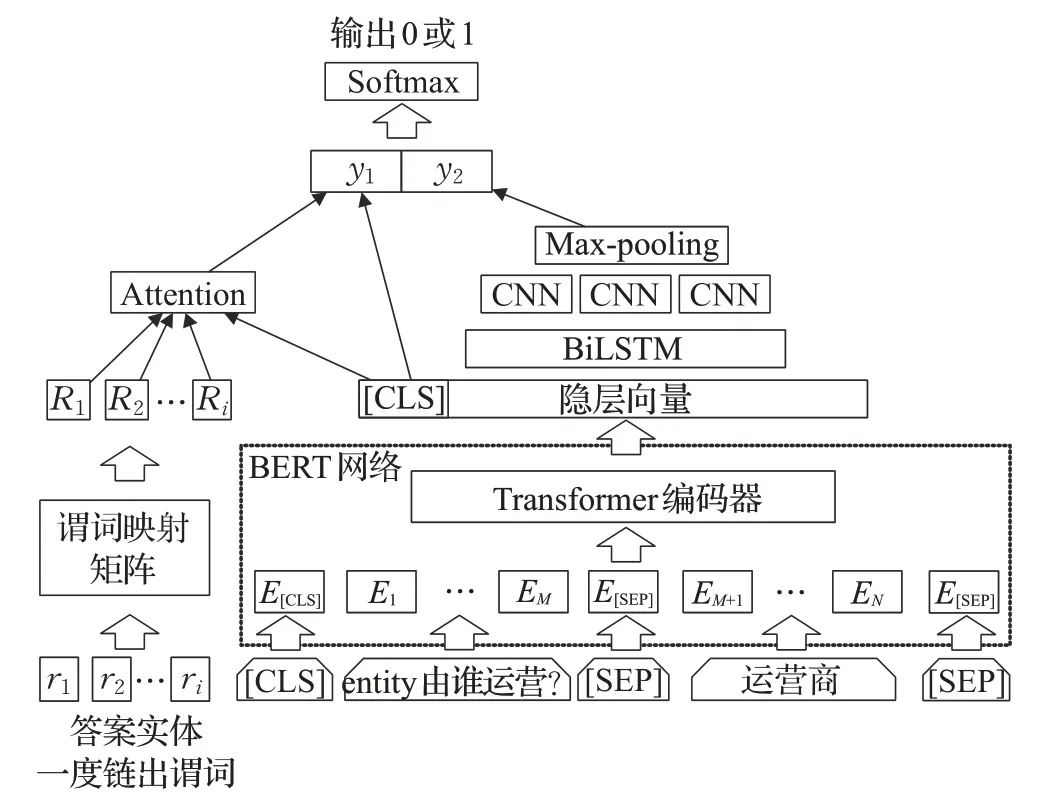
图4 谓词匹配模型Fig.4 Predicate matching model
该任务同样可以看做是二分类任务,对于能够正确反映问句意图的候选谓词样本输出标签为1,不能正确反映问句意图的候选谓词样本输出标签为0。输入数据由两部分组成:问句谓词对部分和答案实体一度链出谓词特征部分。问句谓词对部分的输入数据由[CLS],将实体提及替换为entity 字符的问题字符序列,[SEP],候选谓词,[SEP]组成,如公式(5)所示。其中,pi表示候选实体的一度谓词。
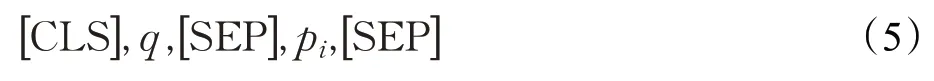
经过BERT 网络编码得到后四层encoder 输出的隐层向量,相加后通过由两个方向的LSTM 网络构成的BiLSTM 网络学习序列的上下文信息。给定输入序列[x1,x2,…,xt,…,xn] ,t时刻LSTM 网络的计算公式如公式(6)~(11)所示:
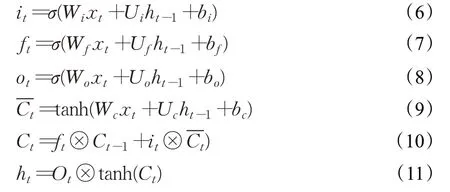
其中,it、ft、ot分别表示LSTM网络的输入门、遗忘门和输出门,W和U为权重矩阵,b为偏置,Ct表示细胞状态,ht表示网络输出。将两个方向的LSTM的输出拼接即得到BiLSTM的输出Ht,如公式(12)所示:

再通过步长为1、3、5的三个卷积层提取特征,之后输入最大池化层将得到的三个向量拼接后得到y2。
答案实体一度链出谓词特征部分的输入数据由以候选实体出发,沿候选谓词检索到的答案实体的一度链出谓词集合[r1,r2,…,ri] 组成。由于在开放域知识图谱中,谓词词表较大,本文工作采用组成谓词的字对应的预训练字向量的平均来作为谓词的向量表示。通过谓词矩阵映射后,得到谓词特征的向量表示[R1,R2,…,Ri] 。接下来,利用注意力机制将答案实体一度链出谓词特征与隐层向量中[CLS]位置的向量H[CLS]进行交互,得到y1。在BERT 预训练任务中,通常将H[CLS]用作分类,所以H[CLS]中包含了问答谓词对经过BERT 编码后的交互信息。注意力机制部分的计算公式如公式(13)~(16)所示:
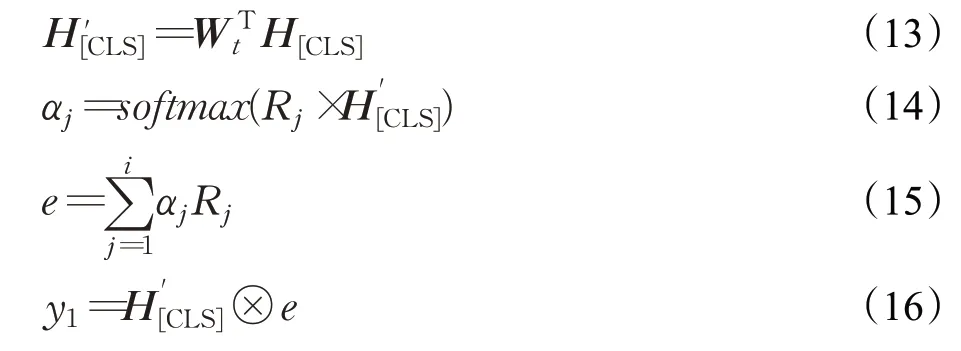
其中,Wt为可学习参数的变换矩阵,维度为dR×dBERT。
将y1和y2拼接后输入Softmax 层分类,输出标签为0 或1。损失函数同样为交叉熵损失函数,训练时最小化损失函数。在预测时,将预测候选谓词为标签1的概率作为候选谓词的得分。
3 实验与结果分析
3.1 数据集与知识库
本文使用NLPCC-ICCPOL-2016KBQA评测任务发布的中文知识库和中文简单问题问答数据集。NLPCC中文知识库包含大约4 300 万个三元组,谓词种类有58万余个。首先对知识库文件进行预处理,例如将繁体中文转换成简体中文,去除三元组中谓词中多余的空格(如<罗育德,民族,汉族>和<罗育德,民 族,汉族>只保留前者),将过长的实体名称截断,将英文字母统一转换为小写便于实验等处理,导入到Neo4j图数据库存储和检索。
问答数据集中训练集共有14 609个问答对,测试集有9 870 个问答对,结合知识库中的单个三元组即可回答问题。但是由于原始数据集中并没有实体提及和三元组的标注,所以本文参考Liu等人[15]的数据标注,生成各个子任务的数据集,数据集标注和子任务数据集的划分情况分别如表1和表2所示。

表1 数据集样本标注示例Table 1 Dataset annotation sample
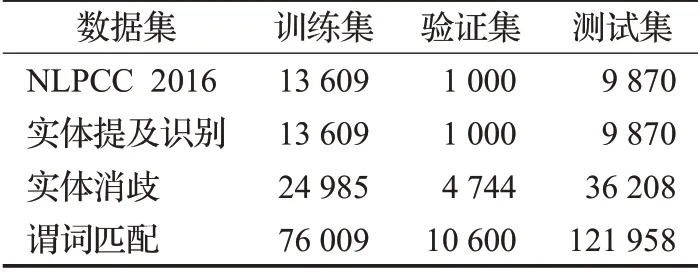
表2 子任务数据集划分Table 2 Subtask dataset statistic
3.2 实验设置
实验运行 在CPU 为Intel®Xeon®CPU E5-2650 v4 @ 2.20 GHz、内存为128 GB 的计算机,操作系统为Ubuntu 16.04.6 LTS。模型训练所用显卡为NVIDIA TITAN Xp,显存12 GB,所用深度学习框架为CUDA 9.0 和PyTorch 1.1.0,知识库数据存储和检索使用Neo4j-community-3.5.8版本。
本文使用预训练模型为BERT-Base Chinese。预训练模型为基于PyTorch 框架实现和微调,有12 层Transformer 编码器,每一层隐层输出的维度为768。预训练字向量使用的是基于中文维基百科预训练的300 维字向量。模型的优化方式采用Adam 优化器。不同子任务的超参数设置如表3所示。
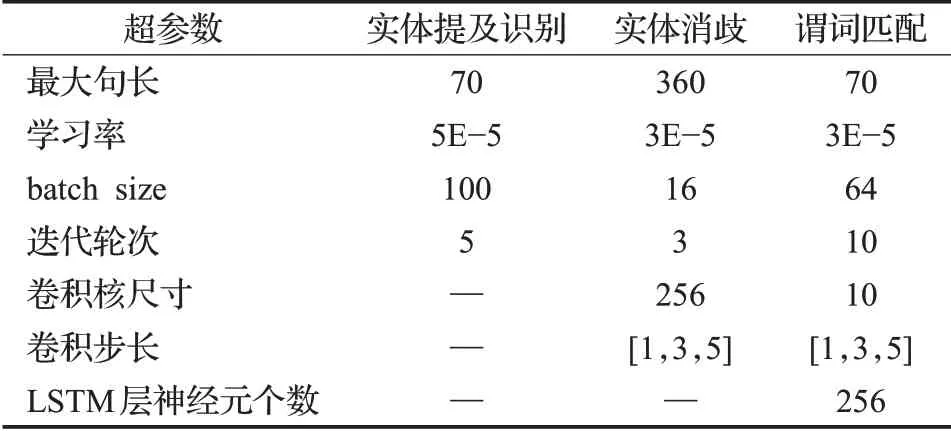
表3 子任务超参数设置Table 3 Subtask hyperparameter setting
3.3 实体链接
实体提及识别实验结果如表4 所示,结果表明BERT-CRF 模型均取得了基本准确的结果。传统的命名实体识别任务需要识别不同类型的实体和实体的边界位置,而实体提及识别子任务只需要识别出实体提及的位置,不需要区分类型,并且简单问句中通常只包含单个实体提及,这都降低了该子任务的难度。

表4 实体提及识别实验结果Table 4 Result of entity mention recognition %
实体消歧子任务训练集中正负例的比例为1∶5,验证集和测试集中均选取所有的候选实体进行预测。该子任务在训练过程中容易发生过拟合,所以选取了较少的训练轮次和较低的学习率。评价指标采用Acc@N,定义如公式(17)所示:
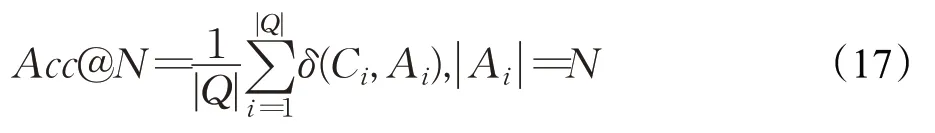
其中,Q是数据集中的所有问题的集合,Ci是正确的答案集合,Ai是模型预测给出的答案集合,|·|表示集合的大小。当Ai中的答案至少被Ci包含一个时,δ(Ci,Ai)为1,否则为0。
在测试集上实体消歧实验结果如表5所示。其中,引入谓词特征在Acc@1 指标上均提高了约10 个百分点。这是因为仅使用问句和实体名称作为输入的基准模型可利用的信息较少,而谓词特征蕴含了主题实体在知识库中的拓扑信息以及其关联的谓词内容,从而增强了主题实体与问句的匹配程度,对于改善实体消歧是有效的。并且,结合CNN的特征提取能力,也带来了一定的提升。保留得分前三的候选实体可以达到一个很高的准确率,有助于减少谓词匹配的候选谓词集合规模,进而提升问答系统的效率。
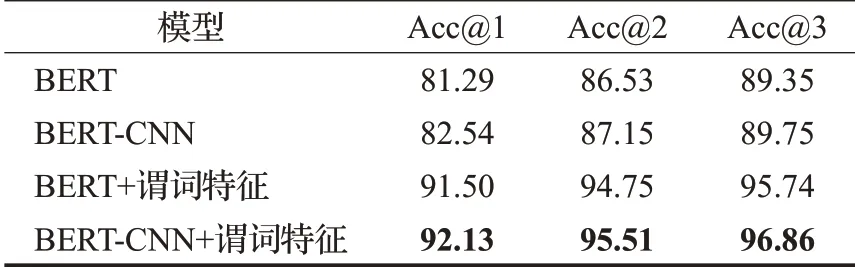
表5 实体消歧实验结果Table 5 Result of entity disambiguation %
3.4 谓词匹配
谓词匹配子任务训练集中正负例的比例为1∶5,验证集和测试集中均取所有候选谓词进行预测。评价指标同样使用Acc@N。在测试集上的实验结果如表6 所示。在只利用问句和谓词的较少信息的情况下,相比于对比基准的的BERT 模型,BERT-BiLSTM-CNN 模型在保留前1~3 个候选谓词时均提高了2~3 个百分点,表明使用BiLSTM 结构建模BERT 编码后的上下文信息,对于理解问句语义是有效的。增加CNN 后,可以增强模型提取特征的能力,进一步提高了问答的准确率。并且在通过注意力机制引入谓词特征后,带来了进一步的准确率提升,本文提出的模型取得了最好的结果,验证了谓词特征的有效性。
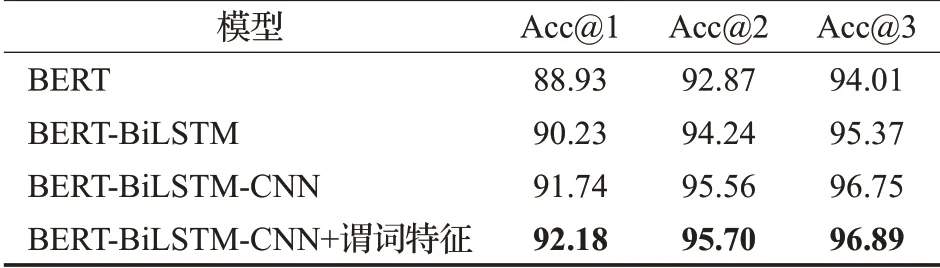
表6 谓词匹配实验结果Table 6 Result of predicate matching %
3.5 问答系统整体性能
在完成了上述子任务的训练之后,可以得到每个问题对应的候选实体的得分Se和候选谓词Sp的得分。选择得分前三的候选实体,以及每个候选实体对应的得分前三的候选谓词,加权相加,选择总分最高的候选实体和候选谓词组成查询路径,转换成Cypher 查询语句到Neo4j 知识库中检索答案。问答系统的整体性能评价指标平均F1值。定义如公式(18)~(20):
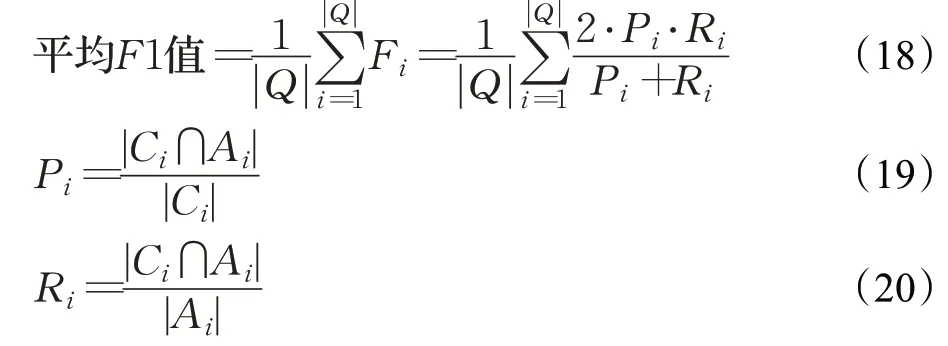
其中,Q是数据集中的所有问题的集合,Ci是正确的答案集合,Ai是模型预测给出的答案集合,|·|表示集合的大小。Pi表示预测正确的答案在预测答案集合中所占的比例,反映了问答系统的准确程度;Ri表示预测正确的答案在正确答案集合中所占的比例,反应问答系统的完备程度。计算每一个问题的F1 值,再对所有问题的F1值求和取平均值作为问答系统的评价指标。本文方法与其他公开方法的性能对比如表7所示。
其中,DPQA[10]是王玥等人基于动态规划思想进行的研究。InsunKBQA[16]是周博通等人基于知识库三元组中谓词的属性映射构建的问答系统,加入了少量人工特征。Lai 等人[14]、Xie 等人[11]、Yang 等人[17]的系统是评测任务的前三名,结合神经网络和人工构建规则保证问答质量。BB-KBQA[15]基于BERT的预训练任务微调,实现实体提及识别、实体消歧和谓词匹配三个子任务,但在各个子任务上的表现弱于本文模型,导致最后的表现低于本文的问答系统。实验结果表明,本文提出的问答方法BERT-CKBQA取得了88.75%的平均F1值,相比于其他公开的问答方法,取得了现有最好的结果,提升了问题回答的准确度。
最后,对问答系统的回答结果进行了分析。除了存在一些三元组标注和答案错误的情况,整个问答系统的结果比较准确。例如,问题“王杰是在什么地方出道的啊?”,对应的知识三元组为<王杰,出道地,台湾>,本文的系统预测的主题实体和谓词为<王杰(港台男歌手),出道地>,表明实体消歧模块可以正确选择是歌手的王杰;问题“请问212型潜艇是哪个厂建造的?”,对应的知识三元组为<212 型潜艇,建造,哈德威造船厂(hdw)>,本文的系统预测的主题实体和谓词为<212 型潜艇,制造厂>,可见虽然谓词匹配模块选择的谓词与标注谓词不同,但通过理解问句意图,选择了正确的谓词,最终找到正确答案。综上,本文工作提出的BERT-CKBQA 问答系统的准确率较高,可以满足中文简单问题的开放域知识库问答的实际应用。
4 结束语
针对中文简单问题的开放域知识库问答系统中实体消歧和谓词匹配任务存在的难点,本文工作提出一种基于中文预训练语言模型BERT 的流水线式问答系统BERT-CKBQA,应用BERT-CRF 模型进行实体提及识别;提出谓词特征增强的BERT-CNN模型用于提升实体消歧任务的性能,提高实体消歧的准确率,进而启发式地缩小候选谓词集合的规模,提升系统的问答效率;提出引入答案实体一度链出特征的BERT-BiLSTM-CNN模型进行谓词匹配,提升谓词匹配任务的性能。最后,在NLPCC-ICCPOL-2016KBQA数据集上BERT-CKBQA系统取得了最高的平均F1值,为88.75%,取得了现有方法中最好的性能。在未来工作中,可以尝试将不同的子任务联合训练,或引入知识图谱表示学习方法融入更丰富的知识图谱特征,带来进一步的提升。
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
山西大学学报(自然科学版)(2021年1期)2021-04-21
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
西夏研究(2020年2期)2020-06-01
现代哲学(2019年4期)2019-12-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
海军航空大学学报(2015年1期)2015-11-11
科技视界(2014年27期)2014-08-15
现代防御技术(2014年6期)2014-02-28
