
小样本条件下智能布点代理模型及优化设计
2022-09-14 03:13金亮张哲瑄杨庆新张闯刘素贞
电机与控制学报 2022年8期
金亮, 张哲瑄, 杨庆新, 张闯, 刘素贞
(河北工业大学 省部共建电工装备可靠性与智能化国家重点实验室,天津 300130)
0 引 言
随着电工装备复杂度的增加和科学研究对数值模拟精度需求的提高,面向电工装备结构分析的难度也越来越高,对设备一些性能参数的分析计算会消耗大量的计算资源和时间,因此急需提高电工装备结构分析的时效性和设计效率。考虑到产品级数值模拟或大型电工装备实测样本的珍贵性,所以如何降低样本需求就成为电工装备性能分析与优化的现实问题。
电工装备性能分析与优化的经典做法为通过有限元法进行数值模拟,以实现设计参数的仿真校验并对其进行微调[1-6]。但是受计算速度限制,一些精细模拟难以完成,产品级精细模型的计算也面临计算时间过长的问题。如特高压变压器的仿真计算需要多组工况的计算,而一次计算就需要将近几天甚至几十天的时间[7]。有限元计算的精度很大程度受限于网格剖分精细程度[8],以小型非晶合金变压器为例,为得到高精度计算结果,需要精细剖分近3万个网格,即便关键部分手动剖分也需要近1万个网格。
为了降低数值模拟对计算资源和时间的需求,通过构建代理模型代替数值模拟参与到优化流程中是可行和高效的方法,称为代理优化(surrogate-based optimization, SBO)算法。文献[9]将支持向量机(support vector machine, SVM)与布谷鸟算法相结合对变压器故障进行诊断。文献[10]利用化学反应优化算法优化了双支持向量机(TWSVM)参数来选择最佳训练参数,有效解决了经典支持向量机易受到不平衡和样本不足的问题。文献[11]通过一次或多次加入样本点,改进代理模型的样本选择,提高代理模型计算的收敛速度。现有的代理模型主要分为以下几种:多项式响应面、Kriging和支持向量机SVM等。对于复杂的变压器优化设计问题,目前采用基于径向基核函数的支持向量机SVM作为代理模型是一种高效的SBO算法。文献[12]对油中溶解气体分析方法进行改进,提出了基于支持向量机SVM和基于遗传算法(genetic algorithm,GA)优选的新特征向量,重新建立了基于支持向量机SVM的变压器故障诊断模型,采用遗传算法的同时,对支持向量机SVM参数和特征值进行优化,有效提高了变压器的故障诊断正确率。文献[13]提出了改进麻雀搜索算法(improved sparrow search algorithm,ISSA),引入动态反向学习因子对种群进行优化选择以提高算法全局寻优能力,建立了基于油中溶解气体分析的ISSA算法优化支持向量机SVM的故障诊断模型,从而更精准地预测变压器运行状态。文献[14]对粒子群优化算法进行改进,提出基于改进粒子群算法的支持向量机SVM,对电力变压器故障进行诊断。文献[15]研究了变压器绕组热点温度的支持向量机SVM建模,选用径向基核函数(radial basis function,RBF)优化模型结构,通过遗传算法优化参数,提高了模型预测的准确性。但代理模型在训练时存在样本需求多、易出现过拟合、泛化能力差等问题[16-19]。因此如何进一步降低代理模型训练时所需的样本数和提高预测精度,就具有很重要的科学研究价值和现实意义[20]。
针对以上问题,本文提出一种智能布点的改进代理模型及其优化设计方法。在少量样本点的情况下,着重解决电工装备的代理模型预测精度问题,增强模型泛化能力。首先对代理模型进行优化,在采样上改进拉丁超立方抽样方法,实现基于均匀准则的最优拉丁超立方设计,相较于典型正交试验可降低对有限元样本的数量需求。基于信赖域思想改进并实现智能布点方法,其采样空间会随预测结果自适应变化。当代理模型精度不满足要求时,将测试点与旧样本点合并,利用组合样本重新构造代理模型,极大提高代理模型更新效率和预测精度。考虑到实验的便利性和可重复性,以小型非晶变压器的优化设计为案例验证代理模型和优化算法的准确性。
1 基于代理模型的优化设计方法
1.1 代理模型
代理建模无需对研究对象内在物理具有很深的理解和研究,主要是通过研究对象的输入输出样本数据来建立相对应的映射关系。代理模型方法研究内容主要包含两方面:一是如何选取构造代理模型的样本点,属于实验设计的范畴;二是以何种形式进行数据拟合与预测,这是代理模型方法的主体。两个方面都直接影响代理模型的构建效率和精度。
基于实验设计和样本信息可建立不同类型的代理模型,常用的代理模型包括响应面(response surface,RS)、Kriging模型、径向基函数(radial basis function,RBF),支持向量机(support vector machine,SVM)、神经网络(neural networks,NN)和多元自适应样条回归(multivariate adaptive regression splines,MARS)等。
1.2 优化设计
考虑复杂工况下的目标优化具有重要的工程应用价值。优化设计在电工装备开发中已经得到广泛应用,在对复杂结构电工装备进行分析时,代理模型是利用有限的样本信息建立一种结构输入输出之间的关系,并用简单的函数表达式来显示化。基于代理模型进行结构优化设计,可以有效提高计算效率。
2 基于信赖域智能布点代理模型
传统典型正交试验是设计变压器参数的最常见的试验方法。针对试验所得样本,采用极差分析、方差分析等数理统计方法进行分析,可得出一些定性的结论,进而指导结构参数设计。但是,这种方法在处理少样本情况下具有明显的局限性。
2.1 智能布点技术
在典型正交试验的布点基础上,设计一种智能布点方法,用于减少构建代理模型所需样本点。这种改进来自以下两个方面:
1)按照优化目标构建只符合帕累托前沿的局部高精度代理模型,极大降低代理模型对样本点的需求;
2)考虑到个别样本点会对代理模型精度产生较大的影响,将样本点的选取与基于当前样本点的代理模型优化结果相关联,按照信赖域思想,实时更新样本空间,实现智能布点。
2.2 样本点和测试点的选取
一般通过抽样的方法选取样本点,常用的多维分层抽样需要将输入的样本空间等概率的分成N个区间,抽样数目会随着输入数量的增加而指数上升,呈现指数灾难问题。为避免样本选择量过大,可以通过拉丁超立方抽样法产生初始样本点。
拉丁超立方设计(latin hypercube design,LHD),是一种分层随机抽样,能够从变量的分布区间进行高效采样,假设有n个变量(X1,X2,…,Xn),从每个变量规定的区间中取出L个样本,则每个变量的累计分布被分成相同的N个区间,再使每个变量的L个样本和其他变量的L个样本进行随机组合,从而生成L组样本点。拉丁超立方设计LHD可以最大化的使每一个边缘分布分层,并能够保证每一个变量范围的全覆盖。以两个变量为例的拉丁超立方设计LHD,如图1(a)所示。
为降低拉丁超立方设计LHD的随机性,提高稳定性,按照均匀设计准则,对布点空间进行改进,实现基于均匀准则的最优拉丁超立方设计(optimal Latin hypercube design,OLHD),如图1(b)所示。

图1 抽样方法布点图Fig.1 Layout diagram of Latin hypercube design
通过最优拉丁超立方设计OLHD从初始设计空间中获得初始样本点,在代理模型精度评价和更新过程时,采用基于信赖域样本空间更新策略更新样本空间,再通过拉丁超立方设计LHD产生测试点,并利用优化算法进行优化求解。其中,基于信赖域思想的样本空间更新步骤如下:

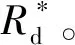
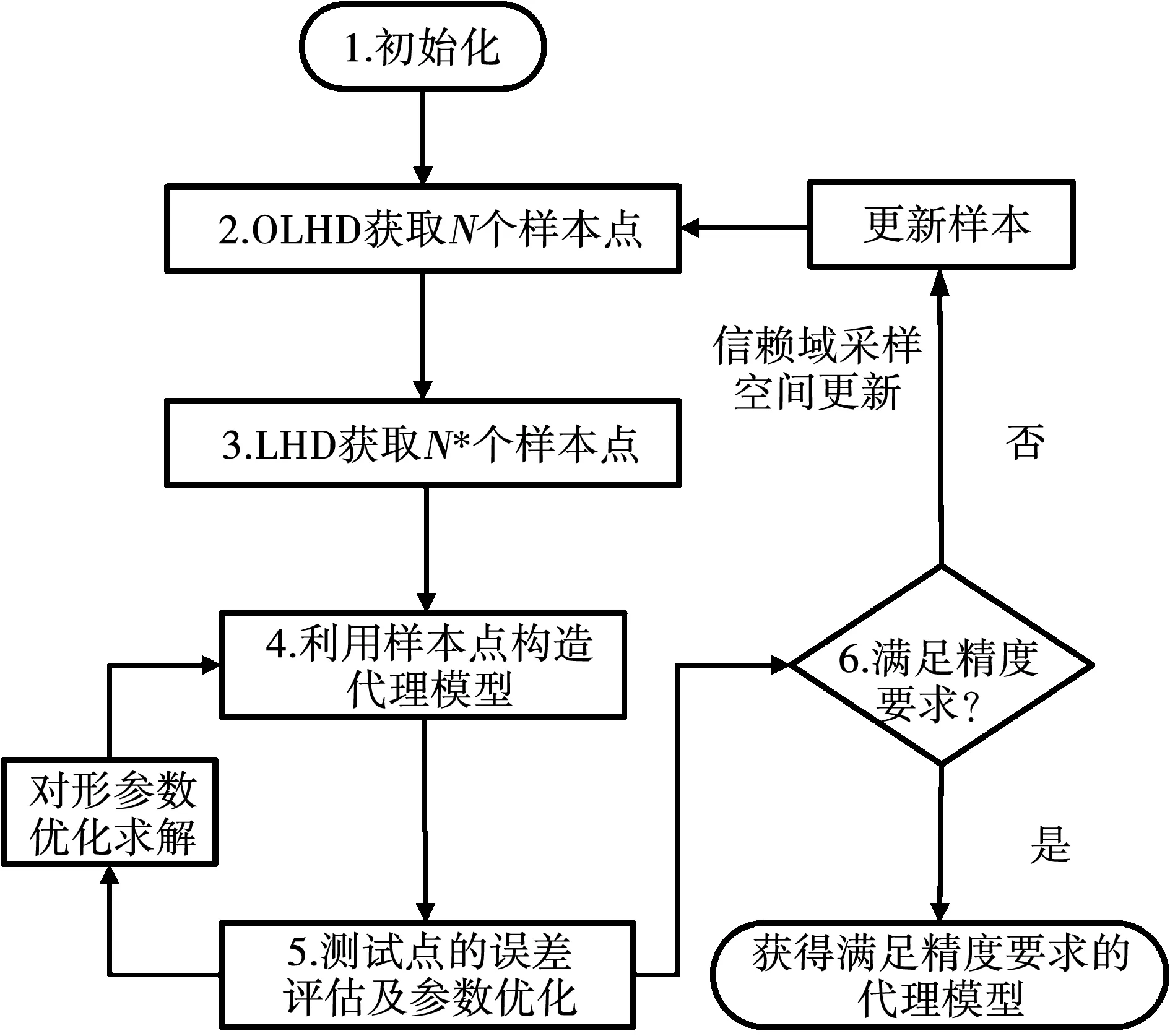
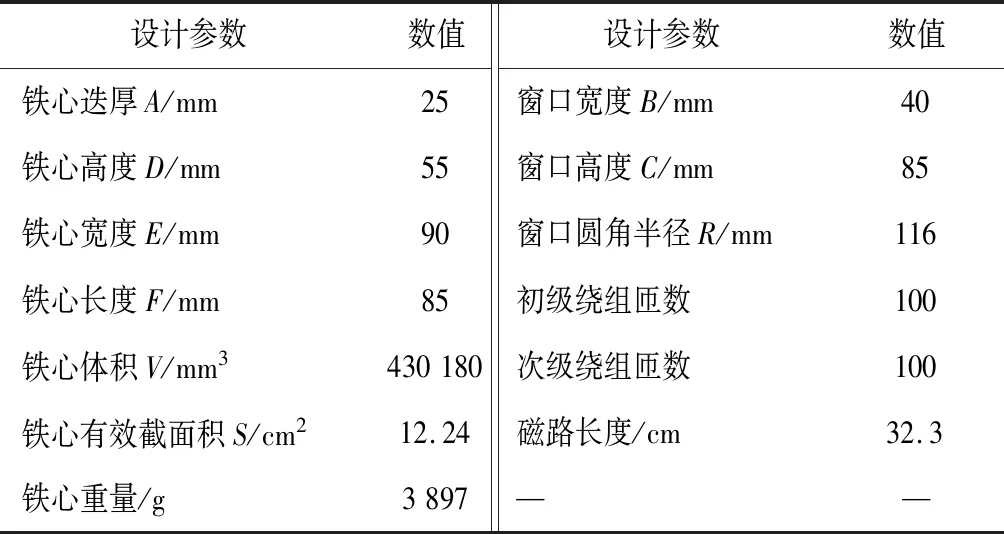
步骤3:信赖域边界控制。为解决对代理模型多次更新迭代后有概率出现信赖域半径连续缩小,致使更新后的样本空间陷入局部固定、新增样本点过于集中,导致支持向量机SVM(以径向基函数为核函数)代理模型精度的陷入局部最优的问题。预先设置最小更新半径Rmin,当更新后的样本空间Rd 二维设计变量空间内进行智能布点实验设计的结果,如图2所示。距离样本点越近误差越小,距离样本点越远误差可能越大,而基于信赖域思想的选取的样本点,其采样空间会跟随上一代样本点得到的目标值自适应变化。 图2 在OLHD基础上获得新样本点Fig.2 Obtain new sample points on the basis of OLHD 当代理模型检验精度不满足要求时,将测试点与旧样本点合并,利用组合样本重新构造代理模型,极大程度地提高代理模型更新精度和效率。 使用了基于径向基核函数的支持向量机SVM构建代理模型,基于信赖域智能布点代理模型的优化流程,如图3所示。 图3 基于信赖域智能布点代理模型流程图Fig.3 Flow chart of intelligent point distribution proxy model based on trust region 步骤1:设定代理模型的精度要求ε、形参数的取值范围、搭建代理模型所需要的样本点个数N和检验代理模型所需要的测试点个数N*。代理模型的精度ε*可表示为 (1) 步骤2:利用最优拉丁超立方设计OLHD获得N个非晶合金变压器的设计参数,通过有限元模型计算代理模型获得的N个非晶合金变压器的设计参数对应的性能值(振动和体积),形成N个样本点。 步骤3:在当前N个样本点的基础上,利用拉丁超立方设计LHD获得N*个测试点,通过有限元模型计算获得N*个测试点所对应的变压器设计参数的真实值。 步骤4:利用有限元模型计算获得的N个样本点搭建代理模型。 步骤5:使用得到的测试点N*对当前代理模型精度进行误差评估并通过优化算法对代理模型的形参数进行优化,使当前代理模型的精度ε*达到最大。 步骤6:判断当前预测精度ε*是否满足规定的精度ε(或上一代的预测精度),若ε*<ε(或上一代预测精度),则表示当前代理模型预测精度不足,可通过信赖域思想重新生成采样空间。需要将拉丁超立方设计LHD生成的测试点并入样本点中,并通过拉丁超立方设计LHD在当前样本点的基础上重新生成和补充新的测试点。重复步骤3到步骤6,直到当前预测精度ε*满足预设精度要求ε*≥ε,可终止迭代过程,得到最终的代理模型。 非晶合金变压器对于新能源技术意义重大,其振动问题引起人们的广泛关注,为实验验证方便,选取小型非晶合金变压器作为案例验证,从理论和实践来讲,结论对于大型非晶合金变压器具有一致性。 在系统容量和工作频率一定的情况下,变压器设计需考虑体积(也就是重量)和振动等问题。一般使用AP法确定的变压器铁芯型号,变压器体积大小主要由铁心尺寸确定,从而确定变压器体积。铁心的尺寸又取决于窗口面积和铁心有效截面积乘积,与铁心长度、窗口高度、窗口宽度、线圈匝数和线圈导线截面积等多个参数关系如下: AP=AwAe; (2) (3) 式中:AP表示铁心尺寸;Aw为窗口面积;Ae为铁心有效面积;U1为有效值电压;Np为匝数;Φ为磁通量;BAC为磁通密度;Kf为波形系数;T为周期;f为频率。 通过在铁心上绕制初级和次级绕组,制成一个小型单相非晶合金变压器样机,铁心模型结构,如图4所示。图中的字母对应变压器的设计参数,如A为铁心迭厚,B为窗口宽度,C为窗口高度,R为窗口圆角半径等。 图4 铁心模型结构图Fig.4 Structure drawing of core model 铁心的主要设计参数如表1所示。 表1 设计参数Table 1 Design parameters 通过有限元仿真软件COMSOL建立非晶合金变压器的有限元仿真模型。按照计算需求和实际情况进行部分简化,例如非晶合金变压器铁心由极薄的非晶带材压制而成,在仿真建模中,建模为整块铁心,简化建模复杂度;线圈绕组也由线圈体所代替。实际工程应用中,非晶合金的饱和磁通密度约为1.5 T,当作为铁心材料时,额定工作磁通密度约在1.2~1.3 T。有限元方法计算的铁心磁通密度,如图5所示。与实际工程应用中非晶合金变压器的工作磁密相吻合。 图5 铁心磁通密度计算Fig.5 Core flux density calculation 变压器振动问题主要为磁致伸缩和电磁力引起的铁心振动。通过电磁场和弹性力学原理,可求解出变压器工作时铁心的磁场分布和振动特性。进一步根据应力-应变和应变-位移的关系,可得振动系统的波动方程为 (4) 式中:M为质量矩阵;C为阻尼矩阵;K为刚度矩阵;u为节点位移;F主要包括麦克斯韦力和磁致伸缩力。对时间t的一阶和二阶偏导分别是节点速度和节点加速度。 规定X方向为平行于铁心厚度方向,Y方向垂直于铁心厚度方向,Z垂直于铁心顶面方向。根据数值模拟的铁心振动云图可确定变压器在X、Y、Z方向振动最大的3个测试点分别为a、b、c,如图6所示。 图6 a、b、c测试点Fig.6 Vibration test a、b、c 根据研究的变压器结构设计问题,将优化目标设定为:a测试点X方向振动加速度峰值ax,b测试点Y方向振动加速度峰值ay,c测试点Z方向振动加速度峰值az和变压器的体积V。 优化目标为x、y、z方向上的振动加速度和变压器的体积,考虑到传统变压器优化设计和AP法对结构限制,选择以铁心高度、铁心迭厚、绕组匝数、窗口宽度、导线截面积作为输入变量,初始样本点个数N=10,测试点个数N*=10,代理模型预测精度要求ε*>95%。 首先利用初始的10个样本点搭建代理模型,通过求解当前样本点生成代理模型的最优目标值,与初始测试点得到的数据进行误差评估,得到的预测结果精度小于初始设定的精度要求。此时,基于信赖域思想,采样空间会跟上一步的样本点得到的目标值自适应变化,即将初始样本点和测试点合并重新生成采样空间,并生成新一组的测试点。重复上述步骤,不断迭代求解当前样本点得到的预测精度ε*。 当迭代6次后,此时通过智能布点得到的训练样本数据N为70个,测试样本点个数为10,编号为70到80,此时的预测精度ε*>95%,达到初始设定的精度要求,然后通过绘制图像分析经过智能布点模型优化后得到的预测结果。在迭代达到预测精度要求ε*>95%时,通过智能布点得到的训练样本数据N的个数为70,编号为1到70,如表2所示。测试样本点个数为10,编号为71到80。 表2 智能布点的样本数据Table 2 Sample data of intelligent distribution points 图7 智能布点模型预测结果Fig.7 Predicted results of intelligent distribution model 为验证代理模型的先进性,在相同样本点数量的情况下基于典型正交试验构建支持向量机SVM。 图8 典型正交试验预测结果Fig.8 Typical orthogonal experiment prediction results 基于智能布点方法,经过6次迭代更新,70个样本点就可达到预定精度标准。而传统方法选取70个样本点则无法构建符合精度要求的代理模型,除变压器铁心体积的预测精度差较小外,其它预测精度差距可达16%左右。原因主要有两个:一是考虑全局精度的样本需求量远大于只考虑局部精度的需求量;二是非帕累托前沿样本数据本身的分散特性也增加了拟合难度。但从实际角度出发,对于优化问题只需构建满足帕累托前沿的高精度局部代理模型即可。 对比可知,通过智能布点进行迭代智能选取样本点方法所构建的变压器代理模型具有极高的局部精度和实用性。 基于智能布点代理模型,使用第三代非支配排序遗传算法(NSGA-III)对变压器进行性能优化。通过计算预测数据与真实值的误差,验证预测模型的有效性。 由于多目标优化时的解是互相冲突的,仅能得到帕累托解,考虑到降噪的重要性,以振动降幅最大为目标,经挑选后的解,如表3所示。 表3 变压器设计参数和性能对比Table 3 Comparison of transformer design parameters and performance 由对比结果可知,除了Y轴方向加速度峰值ay经有限元校验后增加11.6%外,其余方向的测试点加速度峰值均有明显降低,多个性能得到了大幅度提高,X轴方向加速度峰值ax甚至降低了39.6%。有限元校验的结果证明,优化后的数据误差较小,在合理范围内,达到了有效改善变压器性能的目的。 为验证非晶合金铁心优化结果的准确性,搭建实验装置,如图9所示。采用振动测量分析仪对非晶变压器小型样机的铁心振动加速度进行测量。三轴加速度传感器探头粘贴在样机上部与模型参考相近处,方向与坐标参考方向保持一致。然后将供电频率设置为50 Hz,调节励磁电流使非晶变压器工作在指定工况时由振动测量仪测量记录振动加速度数据并记录。振动测量仪为SQuadrigII振动噪声分析仪。 图9 实验装置图Fig.9 Experimental apparatus diagram 非晶合金变压器铁心的振动加速度实验测量结果,如图10所示。 图10 优化前后振动加速度实验测量结果Fig.10 Experimental measurement results of vibration acceleration before and after optimization 对比优化前后的变压器振动加速度实验测量值可知,优化前的X、Y、Z方向上的振动加速度峰值为0.47、0.39、1.13 m/s2;优化后的各方向振动加速度峰值为0.24、0.40、0.78 m/s2,X和Z方向振动加速度峰值明显降低,并且优化后的振动加速度的测量峰值和有限元校验出的结果相近,验证了此代理模型的预测精度和准确性,并且能够有效应用于非晶合金变压器的参数设计,同时兼顾多个优化目标,在少样本条件下提供出设计的最优解。 应用智能布点构建变压器代理模型并对其寻优,相比于典型正交试验方法,智能布点方法需要的样本点更少,预测精度更高。对优化后的变压器结构参数分别进行仿真和实验验证,结果表明: 1)各测试点的相对误差在合理范围内,可满足电工装备优化设计的精度要求,在优化设计中代替数值仿真模型计算,极大程度节省了计算时间。 2)70组样本点时,相比于典型正交试验方法,智能布点代理模型的预测精度可提高16%左右,实现了少样本条件下高精度代理模型的有效建立。
2.3 更新流程

3 非晶合金变压器优化问题



4 实验与结果分析
4.1 预测结果




4.2 优化结果对比

4.3 实验验证


5 结 论
猜你喜欢
水泥工程(2022年2期)2022-08-22
军民两用技术与产品(2022年1期)2022-06-01
区域治理(2021年34期)2022-01-01
防爆电机(2021年3期)2021-07-21
防爆电机(2021年1期)2021-03-29
上海大学学报(自然科学版)(2020年4期)2020-05-24
通信电源技术(2019年6期)2019-07-23
微特电机(2019年2期)2019-02-25
进出口经理人(2017年11期)2017-09-22
商情(2017年23期)2017-07-27
