
面向非受控场景的人脸图像正面化重建
2022-09-20 09:13辛经纬魏子凯王楠楠李洁高新波
中国图象图形学报 2022年9期
辛经纬,魏子凯,王楠楠*,李洁,高新波
1. 西安电子科技大学通信工程学院,西安 710071; 2. 西安电子科技大学电子工程学院,西安 710071;3. 重庆邮电大学图像认知重庆市重点实验室,重庆 400065
0 引 言
在非受控场景下的人脸识别任务中,如何克服图像采集视角以及人脸姿态变化是一个关键问题。人脸正面化重建为解决这一问题提供了一种有效的方法,进而实现非受控场景与现有成熟识别技术的衔接。人脸正面化重建旨在从一张任意光照、任意姿态的人脸图像准确地合成出正常光照和姿态的正脸图像。重建的人脸图像可以直接用于一般的人脸识别处理,而不需要引入额外的推理操作。除了可以作为其他高层视觉任务(如人脸识别、人脸语义解析和人脸动画生成等)的前置任务(王欢 等,2020;祝恺蔓 等,2022;曹申豪 等,2022),人脸重建技术也是一个独立的研究问题,存在如人脸编辑、配饰和重构等虚拟现实与增强现实中的潜在应用。
人脸正面化重建是一个具有挑战性的课题,因为计算机不仅需要推理出给定的人脸经过正面化旋转后的视图,同时还应该保持相同的身份。一般而言,解决该问题的经典方法主要包括基于模型驱动的方法(Blanz和 Vetter,1999)、基于数据驱动的方法(Zhu等,2014;Yan等,2017),以及两者结合的方法(Zhu等,2016;Rezende等,2016)。近年来,Goodfellow等人(2014)提出的生成式对抗网络(generative adversarial network,GAN)在多人脸视图生成方面展现出了令人印象深刻的结果(Tran等,2017;Zhao等,2018a)。这些基于GAN的方法通常有一个标准的设计路径:一个编码器—解码器网络,之后是一个鉴别器网络。编码器(E)将输入图像映射到一个潜在特征空间(Z)中。随后其表征在经过初步处理后再送入解码器(G)以产生新的视图。
人脸的先验信息对于人脸图像的重建过程具有积极的指导意义,并已在人脸正面化重建领域取得广泛应用。Hu等人(2018)提出了一种基于姿态引导的任意视角人脸重建算法(couple-agent pose-guided generative adversarial network, CAPG-GAN),该方法通过引入人脸地标性热图的先验信息来引导图像重建。Zhao等人(2018b)提出了一种基于3D辅助的人脸姿态不变模型(3D-aided deep pose-invariant model,3D-PIM),该模型通过人脸地标和3D先验引导模型从任意姿势中恢复真实的正面人脸视图。Wei等人(2020)提出了一种基于光流的特征翘曲模型(flow-based feature warping model,FFWM),用于多视角人脸正面化重建,该模型能够有效利用人脸光流先验信息,从而在不一致光照下合成逼真且保持光照一致的正面人脸图像。虽然现有的方法在人脸正面化重建任务中已经展现出了令人满意的表现,但它们通常需要使用显式的先验知识作为约束或使用额外的计算处理操作。而在非受控环境下,显式的人脸先验信息获取成本较高,不足以支持现有模型的训练需求,而且额外的计算处理操作会消耗大量的计算资源,进一步限制了人脸正面化在现实中的应用。因此,本文专注于提供一种无先验依赖和低计算成本的方法来执行人脸正面化重建任务。
为了实现无人脸先验信息引入情况下高质量的人脸正面化图像重建,本文构造了一种双层级表征集成推理网络。该网络以人脸的身份特征和视觉特征为基础,无需引入额外的先验知识即可恢复正面化人脸图像。网络由两个编码器和一个解码器构成。在编码阶段,考虑到人脸的辨识度信息在图像质量感知及评估中的重要性,引入了预训练的人脸识别模型参与人脸特征的编码过程。该识别模型是在大规模数据集上预先训练的,对于人脸姿态及表情变化具有较强的鲁棒性。与之并列的另一个编码器则用于捕获人脸图像的色彩、纹理等底层视觉信息。该信息将用于图像重建的色彩、细节的渲染过程。在图像解码重建阶段中,该网络以像素级表征为基础、以语义级表征为引导的对两种表征信息进行融合,随后进行图像解码并得到最终的正面化人脸图像。图1展示了本文方法的一些人脸正面化重建结果。

图1 本文方法人脸正面化重建结果Fig.1 Face frontalization results of the proposed method((a)Multi-PIE;(b)CASIA-WebFace)
本文的主要贡献总结如下:
1)构造了一种双层级表征集成推理网络。网络的编码过程同时结合了底层的基础视觉信息以及高层的语义表征信息,并充分挖掘利用了图像的自身信息。相较于现有方法,该网络能够在无额外先验信息引入的情况下取得较理想的图像重建表现。
2)提出了一个多类别特征融合解码网络。该网络能够充分结合两种类别信息之间的对立性和互补性并用于图像的重建。得益于该融合模型机制及结构的合理性,与现有方法相比,本文方法能够以更低的计算复杂度取得更优的性能。
3)大量实验验证了本文方法的有效性,并分析了不同的表征建模方式对于重建图像的影响。在最终的模型性能评估中,除了标准的Multi-PIE(multi-pose, illumination and expression)数据集之外,本文展开了在真实非受控场景中的实验评估。实验表明,本文方法无论在标准的评估数据集中还是真实非受控的场景中,均能取得当前最优的表现。特别地,与当前先进的方法FFWM(Wei等,2020)相比,本文方法节省了79%的参数数量和42%的运算操作数。
1 相关工作
人脸正面化重建是指从给定的非正面人脸图像中合成出其对应的正面的人脸视图。由于重建过程中的不确定性,该任务是一项非常具有挑战性的问题。传统的方法中,解决该问题的方式通常是通过对输入人脸图像的2维或3维的局部纹理进行翘曲(张剑 等,2014;Hassner等,2015; Zhu等,2015)或统计建模(Sagonas 等,2015)。Hassner等人(2015)构建了一种人脸的3维表征模型用于重建正面化的人脸图像。Zhu等人(2015)基于人脸3D形变统计模型(3D morphable model,3DMM)(Blanz和Vetter,1999)提供了一种具有高细节保真度的人脸姿态和表情的正则化方法。Sagonas等人(2015)构建了一个统计学模型,用于联合完成人脸正面化重建以及地标定位任务。这些方法在理想的受控场景中能够取得优秀的表现,但是对于面部非刚性变化的鲁棒性较低。在非受控的场景中,多样化人脸姿态会导致重建人脸图像的纹理细节严重丢失,模型性能急剧下降。
随着深度技术的发展和普及,Kan等人(2014)提出了一种叠加渐进式的自编码器,该模型通过特征编解码的方式,从网络提取的深度特征中进行人脸正面化重建。Yang等人(2015)采用了一个递归卷积编码器—解码器网络来合成离散的人脸3维视图。Yim等人(2015)引入了一个多任务学习模型来合成人脸正面化视图。此外,Cole等人(2017)首先通过人脸识别网络提取的特征中生成面部地标和纹理,随后将它们引入图像重构网络,合成具有中性表情的正面化人脸图像。
受益于GAN在图像重建任务中的优异表现,基于GAN的人脸正面化重建方法同样取得了显著的成就(Huang等,2017;Hu等,2018;Cao等,2018;Wei等,2020)。Yin等人(2017)将人脸的3维表征模型纳入了GAN框架中,为图像的重建过程提供形状和外观等先验信息。Huang等人(2017)同时结合面部的局部和全局信息用于正面化人脸图像的重建过程。Hu等人(2018)提出了基于姿态引导的任意视角人脸重建算法,该方法引入了人脸地标性热图来辅助多视角人脸正面化重建。Zhao等人(2018c)结合区域自适应策略,构建了一种姿态不变表征模型。Cao等人(2018)使用一种新的纹理翘曲方案实现了高质量的人脸正面化重建。Wei等人(2020)提出了一个新的基于光流的特征翘曲模型,可以在光照不一致的条件下合成出照片般逼真的正面人脸图像。Tu等人(2022)提出了一种人脸姿态归一化模块,通过感知输入人脸与参考人脸姿态间的差异引导人脸正面化重建。
2 双层级表征集成推理网络
本文提出的基于双层级表征集成的人脸图像正面化重建框架如图2所示,该架构实现了联合底层视觉特征与高层语义特征的正面化人脸视图求解。

图2 双层级表征集成推理网络结构Fig.2 Two-level representations integration inference network structure
2.1 模型基础框架

FH=EH(x),FL=EL(x)
(1)
式中,EL和EH分别代表底层视觉编码器和高层语义编码器。FL和FH则分别代表经过编码得到的底层视觉特征和高层语义特征。随后将两者输入到解码器中用于恢复正面化人脸图像。特别地,本文提出的多类别信息融合解码器的数据处理过程可以分为两个阶段,首先是多类别信息的融合阶段,即
FM=M(FH,FL)
(2)
式中,M为底层视觉特征和高层语义特征的融合模型,FM为经过融合处理后得到的输出特征。在随后的图像解码重建阶段中,则将从该特征中恢复出最终的正面化的人脸图像,即
(3)
式中,G代表最终的图像重建解码器。
2.2 双路径的编码过程
双路径的编码过程包括高层的语义信息编码和底层视觉信息编码。首先,为了从具有任意姿态的人脸图像中学习到更加丰富的身份表征信息,将经过预训练的人脸识别模型的部分卷积权重共享到了语义信息编码器路径中。该人脸识别模型在大规模数据集上进行训练,能够适应复杂的人脸变化,通过隐含的人脸先验知识,为人脸的编码过程提供了对复杂人脸变化的适应能力。语义信息编码器借助人脸识别模型对于身份信息出色的建模能力获取到准确的语义表征信息。
假设预训练的人脸识别模型为R,则语义信息编码器EH为
EH←RP
(4)
式中,RP为人脸识别模型的中前端,包括图像输入层以及特征提取阶段。←代表权重共享操作,将模型RP部分的卷积权重分享给语义编码器EH。经过预先训练的人脸识别网络为语义信息编码器提供了稳健的语义表征信息,从而减轻模型面向身份信息建模的困难。同时,该人脸识别模型用于后续的身份保存损失的评估,可充分约束人脸正面化的过程。
面向重建人脸图像的纹理信息,本文提出了视觉编码器来补充网络中的纹理特征。一般而言,感受野的大小决定着网络映射过程的信息来源范围,更广泛的信息来源会促使映射过程更易于取得精准的预测结果。考虑到感受野对非线性映射能力的影响,该编码器采用了降采样卷积与空洞卷积相结合的特征提取过程,即网络中每个降采样的模块均由一个降采样卷积和一个空洞卷积组成,即
(5)

(6)
式中,Cin代表初始特征提取卷积,将输入图像提取为一组特征图。编码阶段中一共包含有N个降采样模块,其设置与输入图像大小相关。对于每个空洞卷积,空洞系数统一为2,即式(5)中r=2。
2.3 多类别信息融合解码过程
图像解码重建是图像重建任务的核心过程,本文方法的解码过程是从经过编码得到的高层的语义信息和底层视觉信息中进行图像的重建。因此如何对两者不同类别信息进行融合是该过程的重点。考虑到图像重建任务对于图像的底层视觉信息敏感的特点,若直接将编码得到的视觉表征和语义表征相结合,模型的图像重建过程会过分依赖于视觉表征而忽略语义表征的指导作用。因此多类别信息融合阶段的核心是求取人脸图像在特征空间中概率分布的映射关系,然后基于该分布重建出用于重建正面人脸图像的表征信息。本文方法的多类别信息融合解码过程如图3所示。该融合过程首先构造了一个变分自编码器网络MP,根据已知的人脸特征分布来重建图像,即

图3 多类别信息融合网络结构Fig.3 Multiple information integration network structure
μ,σ2⟸MP,C(FH,FL)
(7)
式中,MP,C是自编码器MP的编码部分,其输出μ和σ2代表均值和方差。与经典的变分 (Kingma等, 2014)方法保持一致,其中KL(Kullback-Leibler)散度选为度量方式,以表示两个分布之间匹配的程度。更近似的概率分布可以使特征的非线性映射过程更高效。假设先验服从高斯分布N(0,1)。那么给定N个数据样本,可以计算出KL散度项为
(8)
接着采用重参数化方法对获取的分布进行采样处理,并得到
FP,E=μ+ε⊙σ
(9)
式中,ε∈N(0,1)代表服从正态分布的随机向量,⊙代表点乘操作,FP,E为经过采样后得到的表征向量,并对其进行解码,即
FP=MP,D(FP,E)
(10)
式中,MP,D为自编码器MP的解码部分,FP为最终得到的基于分布映射的表征信息。考虑到分布映射过程中的高信息损耗,利用前一阶段得到的视觉表征和语义表征对FP进行补充可有效降低信息损耗。但由于视觉表征和语义表征之间存在较大差异,网络难以直接从中学习到同质的相关信息,本文构造了两个基于卷积块堆叠的补偿网络(MH和ML)对于两者进行补偿表征推理,即
F′H=MH(FH),F′L=ML(FL)
(11)
式中,F′H和F′L则分别为语义表征FH和视觉表征FL对应的补偿表征。随后将得到的F′H、F′L和FP沿通道维度并联后输入最终的解码器G中,该解码器具有与编码器EL相对称的网络结构,即
(12)

2.4 模型损失函数
双层级表征集成推理模型以端到端方式训练,训练过程受到5个损失的协同监督,包括像素级损失、对抗损失、感知损失、身份保留损失以及KL散度损失。
(13)
2)对抗损失。面向于更加真实的人脸图像重建,模型训练的监督过程采用了对抗损失,引导重构的人脸图像具有与真实的人脸图像相同的特质。对抗损失定义为
(14)
式中,D为区分真实图像与合成图像的判别网络,E为对概率分布的期望。
3)感知损失。像素级损失的使用易导致重建图像纹理平滑,通过引入感知损失能够有效缓解该问题。感知损失是在ImageNet上预先训练的VGG-19(Visual Geometry Group layer-19)网络的帮助下实现的。感知损失定义为
(15)
式中,Φ()代表VGG-19模型第“ReLU5-3”层的输出特征图。
4)身份保留损失。为了维持正面人脸重建的过程中图像的身份一致性,模型训练的监督过程同样采用了身份保留损失。该损失通过一个预先训练的人脸识别网络来计算重建图像和参考图像之间的身份差异。身份保留损失定义为
(16)
式中,Ψ()代表预训练的人脸识别模型LightCNN-29(Wu等,2018)的输出结果。
5)模型总损失。最后,综合以上损失函数,可以得到模型训练的总损失函数为
L=λ1Lpixel+λ2Ladv+λ3Lp+λ4Lid+λ5LKL
(17)
式中,λi代表不同损失之间的权衡参数,KL散度损失LKL已在式(8)中给出。
3 实 验
在实验阶段,除了在标准的Multi-PIE数据集(Gross等,2010)中进行评估外,还进一步地在非受控场景下获取的CASIA-WebFace(Institute of Automation, Chinese Academy of Sciences—WebFace)数据集(Yi等,2014)(人脸识别任务经典数据集)中进行了定性和定量的评估。首先介绍模型训练和测试数据集以及实现细节,接着进行一系列的消融研究以验证模型各个模块对性能的增益,最后通过定量的客观质量和定性的主观质量对所提出方法进行全面的性能评估。
3.1 实验设置
在人脸识别模型的预训练阶段,采用了MSCeleb-1M数据集(Guo等,2016)对人脸识别模型进行训练。需要说明的是,遵循与工作ArcFace(Deng等,2019)相一致的训练方式,对该数据集进行了精细化处理,处理后的数据集包含有85 K个身份以及对应的3.8 M幅图像。
首先使用经典的Multi-PIE数据集用于模型基础的性能评估,包括模型的训练和测试阶段。Multi-PIE数据集是受控场景下用于人脸合成和识别的最大的公共数据库。它包含4个部分,包含15个姿势和20个光照条件下337个身份的754 204幅图像。为了进行公平的比较,本文中训练和测试过程与现有工作(Tu 等,2022;Wei等,2020;Yin等,2020;Zhao等,2018a;Hu等,2018;Huang等,2017)保持了相同的实验设置。
CASIA-WebFace数据集是非受控场景下常用于人脸识别的公共数据库。数据集包含了10 575 个人的494 414 幅图像。面向人脸正面化重建任务,本文首先对该数据集进行了模型输入及输出样本的划分。通过训练一个正面人脸识别模型对数据集中的正面/非正面人脸进行分类,其中非正面的人脸图像为输入图像,对应相同身份的正面人脸图像则为重建图像的参考图像。随后,数据集的10 575个身份中前9 000个身份划分为训练集,剩余的10 575个身份为测试集。数据集划分示例如图4所示。

图4 CASIA-WebFace数据集划分示例Fig.4 Example of CASIA-WebFace dataset partition
用于训练和测试的两个数据集图像统一调整到尺寸为128×128像素的标准视图。网络中降采样模块个数N=2。采用了ResNet-18(He等,2016)作为预训练的人脸识别模型,其训练过程与工作ArcFace保持一致。在训练过程中,语义信息编码器网络的参数不更新,仅将其用于约束重建脸与目标人脸之间的相似性以维持身份信息的保留。该语义信息编码器若随着网络训练进行同步更新,模型的重建结果则更加倾向于好的视觉质量,但身份信息的提取能力会受到影响,重建人脸的身份识别率会降低。身份保持损失通过LightCNN-29计算,该模型在MSCeleb-1M数据集上进行了预训练后并在后续评估数据集上进行了微调。在损失函数权衡参数的选择过程中,首先将它们初始化为1,随后对每个参数变化对于重建结果的影响进行了深入分析,最终确定了一组能够同时取得较好识别精度和视觉质量的折中结果:λ1=5,λ2=1,λ3=0.5,λ4=0.5,λ5=1。模型使用Adam算法(β1=0.5,β2=0.999)进行优化,学习速度为10-4,训练批次大小为16。该网络基于开源的PyTorch平台,在两个NVIDIA Titan X Pascal GPU上实现,单GPU内存为12 GB。
3.2 双路径编码的有效性分析
在语义信息编码器的构建方面,分别采用了ResNet-18以及ResNet-50作为预训练的人脸识别模型。实验发现,基于两者所重建的人脸图像质量仅具有微弱差异。相较于ResNet-18,基于ResNet-50的平均Rank-1识别率仅领先0.02%。结合模型的计算复杂度与重建精度,最终确定采用ResNet-18作为预训练的人脸识别模型。
消融实验在维持网络其他部分不变的情况下,分别移除了编码阶段的视觉信息编码路径以及语义信息编码路径(两者在多类别信息融合模型中对应的补偿推理分支也进行了移除),得到了网络NetES以及NetEV,并对两者进行重新训练。实验结果如表1和图5所示。可以发现仅基于视觉表征的重构人脸图像身份信息丢失严重。而基于语义表征的重构人脸图像则能具有更加准确的身份。将两者相结合则能够取得最优的重建结果。
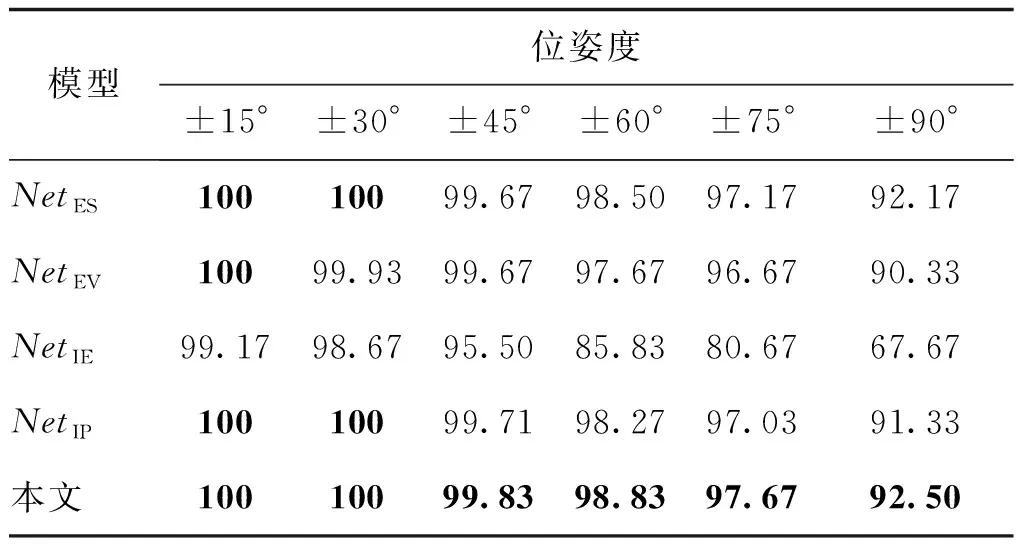
表1 模型组件分析:Multi-PIE数据集中Rank-1识别率Table 1 Component analysis: Rank-1 recognition rates under the Multi-PIE dataset /%
图5 模型组件分析:Multi-PIE数据集重建结果Fig.5 Component analysis: synthesized results on the Multi-PIE dataset
3.3 多类别信息融合模块的有效性分析
与3.2节设置相似,网络分别移除了联合表征自编码分支以及两个补偿推理分支得到了网络NetIE以及网络NetIP,并对两者进行了重新训练。网络NetIE以及网络NetIP分别用于评估信息补偿以及分布映射对于模型性能的影响。实验结果如表1和图5所示,NetIP的重建结果能够保留相对较高的身份识别率。NetIE的重建结果当姿态差异较小时(±15°或±30°)性能尚可,但当姿态差异较大时(±75°或±90°)性能严重退化。将两者相结合则能够取得最优的重建结果。
3.4 各损失函数对模型性能的影响
为了进一步验证损失函数的有效性,全面地分析了各个损失函数对模型性能的影响,实验结果如表2所示。消除身份保留损失对结果的影响最大,这说明了身份保留损失的重要性。Lpixel对于重建人脸的局部纹理具有较大影响。Lid对于重建图像的身份保留程度具有较大影响。在没有Ladv的情况下,重建人脸图像的轮廓往往比较模糊,可能会出现局部生成误差。Lp的存在能够有效避免重建人脸的边缘区域出现伪影的情况。
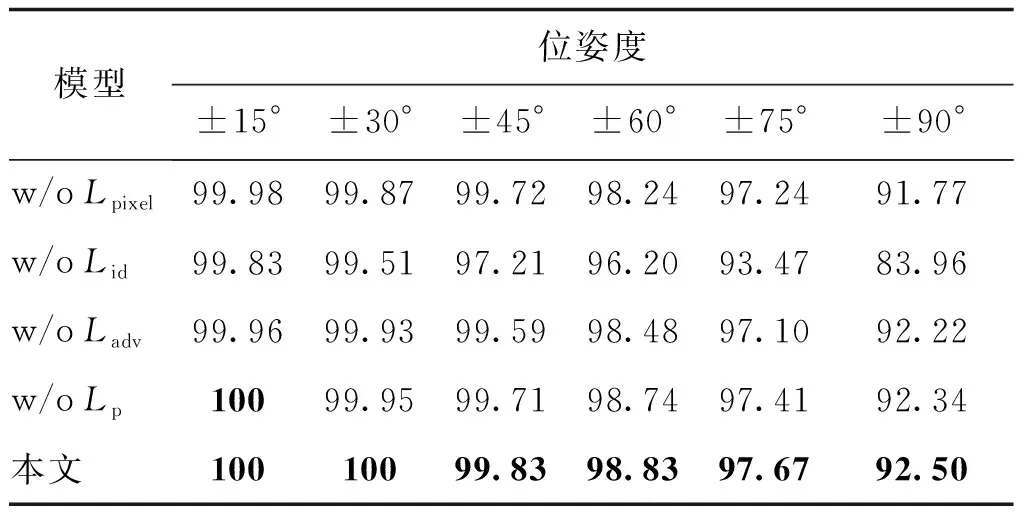
表2 损失函数分析:Multi-PIE数据集中Rank-1识别率Table 2 Loss function analysis: Rank-1 recognition rates under the Multi-PIE dataset /%
3.5 客观质量评估
人脸识别的准确性通常用于定量评价不同方法的身份保持能力。人脸正面化的目的是将其应用到人脸识别模型中,以提高在大姿态跨度下重构人脸的识别准确性。因此,本文定量地比较了本文方法与其他方法重建人脸图像的识别精度。识别精度越高则代表模型重建结果的身份信息越准确。
首先在Multi-PIE数据集上进行正面化人脸重建性能评估。LightCNN-29用来作为基础的人脸识别模型,并将所提方法与当前较先进的方法,包括:TP-GAN(two-pathway generative adversarial network)(Huang等,2017)、CAPG-GAN(Hu等,2018)、PIM(pose-invariant model)(Zhao等,2018a)、3D-PIM(Zhao等,2018b)、DA-GAN(dual-attention generative adversarial network)(Yin等,2020)、FFWM(Wei等,2020)以及FFN-S(face frontalization sub-net-separate)(Tu 等,2022)等进行了对比。实验结果如表3所示,所有方法在姿态变化较小的情况下(±15°和±30°)均具有较高的识别精度,但所有方法的精度都随着位姿度的增加而降低,特别是在±75°和±90°。这是因为当位姿度增加时,会丢失更多的身份信息。与现有方法相比,本文方法在±15°、±30°、±45°和±75°时均取得了最优的人脸识别性能。特别是在±15°和±30°时达到了100%的识别率,并在所有姿态中取得了最优的平均识别率。
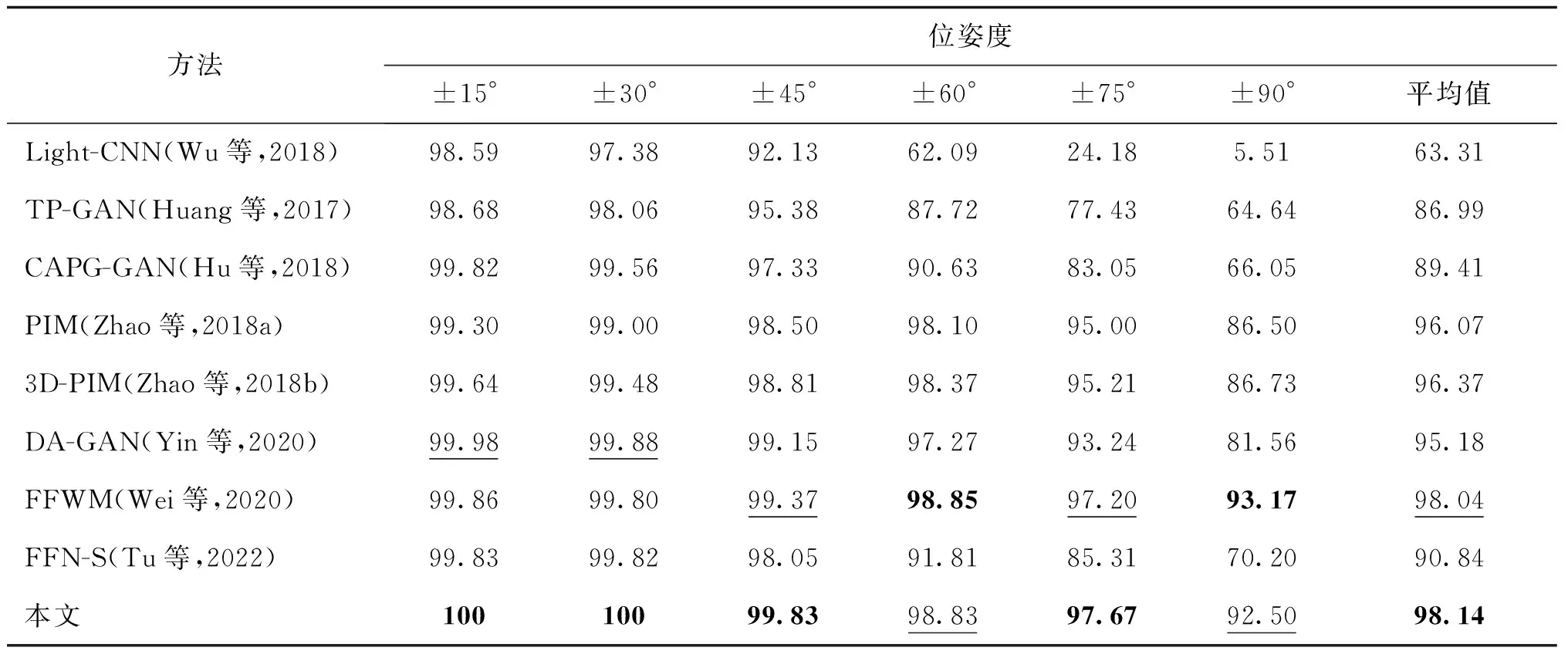
表3 在Multi-PIE数据集中跨姿态重建人脸图像Rank-1识别率对比Table 3 Rank-1 recognition rates across poses of the Multi-PIE dataset /%
实验进一步定性比较了不同方法的参数数量和计算复杂度。评估过程中各模型输入输出图像尺寸统一为128×128像素。实验结果如表4中所示,本文方法在模型参数数量以及计算复杂度方面具有显著优势。其主要原因在于现有方法大多使用如面部地标热图等显式的先验知识作为约束,或使用额外的如流估计等复杂操作,导致网络存在高昂的存储和计算资源需求。与目前最先进的FFWM方法相比,本文方法不仅节省了79%的参数数量和42%的计算操作数,且展现出了更优的重建图像性能。

表4 现有方法模型参数量和计算复杂度对比Table 4 The number of parameters and computational complexity (FLOPs) of existing methods
3.6 主观质量评估
尽管现有的一些工作已经在大姿态上取得了较可以发现,本文方法重建的正面人脸图像能够具有为满意的视觉效果,但是人脸正面化重建过程中的身份信息丢失问题是难以避免的。因此相较于图像的视觉质量(细节纹理等逼真程度),视觉上身份的一致性更为重要。本文方法在Multi-PIE数据集上各种姿态中的表现如图1所示,重建人脸图像具有稳健的身份一致性。
为了验证本文方法的先进性,进一步与现有工作进行了比较。考虑到现有方法对数据集处理方式的差异会影响到主观质量评估的公平性,实验选择了具有开源代码的DA-GAN(Yin等,2020)、CAPG-GAN(Hu等,2018)以及TP-GAN(Huang等,2017)等方法进行了定性比较。并在Multi-PIE训练集上进行了完备的训练。实验结果如图6所示。图中展

图6 不同方法在Multi-PIE数据集上的重建结果Fig.6 Reconstruction results on the Multi-PIE dataset by different methods ((a) input images; (b) reference images; (c) ours; (d) DA-GAN; (e) CAPG-GAN; (f) TP-GAN)
示了不同方法在不同姿态下的综合结果。通过对比可以发现,本文方法重建的正面人脸图像能够具有更加明确的身份特征以及视觉质量。
3.7 面向真实场景的质量评估
在CASIA-WebFace数据集上进行了面向真实非受控场景的性能评估。与3.6节设置相似,实验选择了DA-GAN(Yin等,2020)、CAPG-GAN(Hu等,2018)以及TP-GAN(Huang等,2017)等方法与本文方法进行定量和定性的比较,验证不同方法在真实非受控场景中的泛化能力。定量的结果如表5所示,所提方法能够领先现有方法超过10%的识别精度。图1展示了所提方法在CASIA-WebFace数据集上的视觉表现,在非受控环境下依然具有良好的正面化性能。图7展示了所提方法与现有方法的主观质量对比结果。本文方法的重建图像质量具有显著的优越性,所保留的身份信息更加丰富。

表5 与现有方法在CASIA-WebFace数据集上Rank-1识别率对比Table 5 Rank-1 recognition rates comparison with existing methods on the CASIA-WebFace dataset

图7 不同方法在CASIA-WebFace数据集上的重建结果Fig.7 Reconstruction results on the CASIA-WebFace dataset by different methods ((a) input images; (b) reference images; (c) ours; (d) DA-GAN; (e) CAPG-GAN; (f) TP-GAN)
4 结 论
可用数据集不足问题是当前人脸正面化重建技术发展的限制因素之一。本文提出了一种双层级表征集成推理网络,该网络通过联合输入图像的视觉信息以及表征信息获取更加完备的人脸表征方式,并以视觉表征为基础、以语义表征为引导对两种信息进行有效融合,实现了人脸正面化图像的高质量重建。该方法是一种无图像配准和人脸先验信息需求的人脸图像正面化重建方法,仅对常用的人脸识别数据集进行正面/非正面的粗划分后即可用于模型的训练,进而在真实场景中可实现任意姿态人脸图像的正面化重建。完备的定量和定性实验结果表明,本文方法不仅能够在基准数据集中取得最优表现,而且在真实非受控场景下的性能评估中也展现出了显著的优越性。
当前方法在大规模的人脸识别数据集中的训练过程仍有待进一步提升,包括更加完善的数据集划分的策略、损失函数的选择以及参数设置等。除了实验相关设置外,如何为人脸图像建立更加完备且便捷的表征建模方法将是后续研究的主要问题。
猜你喜欢
奥秘(2021年5期)2021-06-15
文萃报·周五版(2021年17期)2021-05-31
中国计算机报(2020年13期)2020-04-26
小雪花·初中高分作文(2017年9期)2018-05-21
通信产业报(2018年10期)2018-04-13
米娜·女性大世界(2016年8期)2016-08-17
发明与创新·大科技(2016年1期)2016-02-01
长江学术(2015年1期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
