
多媒体智能:当多媒体遇到人工智能
2022-09-20 09:13朱文武王鑫田永鸿高文
中国图象图形学报 2022年9期
朱文武,王鑫,田永鸿,高文
1. 清华大学计算机系,北京 100084; 2. 北京大学计算机学院, 北京 100871
0 引 言
从20世纪60年代第1次出现到今天的广泛使用,多媒体一词一直有着不同的含义。现在称多媒体为“交互式访问的多种媒体组合,包括视频、静态图像、音频和文本。”(“an electronically delivered combination of media including videos, still images, audios, and texts in such a way that can be accessed interactively.”)(https://en.wikipedia.org/wiki/Multimedia)经过二十多年的迅猛发展(Li等,2013;Zhang和Rui,2013),多媒体研究在图像/视频内容分析、多媒体搜索和推荐、流媒体和多媒体内容分发等方面取得了很大进展(Zhu等,2015)。人工智能理论早在20世纪50年代之前就出现在了学术研究者的视野中,并在几十年内发展出了各种方法,包括专家系统、智能搜索与优化、符号与逻辑推理、概率论方法、统计学习方法和人工神经网络等。多媒体和人工智能这两个重要的研究领域在以前几乎是各自独立发展,直到各种丰富的多媒体数据不断增加,人工智能才得以发展出更多实用模型来处理各种真实世界的多媒体信息,进而在真实世界的场景中得到应用。因此,一个值得深入思考的关键问题出现了:当多媒体和人工智能结合在一起时会带来什么?
为了回答这个问题,本文通过探索多媒体和人工智能之间的相互影响,提出了多媒体智能的概念。当多媒体作用于人工智能时,多媒体促使人工智能向着更具可解释性的方向发展:在丰富的、带有可解释语义信息数据的帮助下,大量多媒体数据为人工智能模型可解释能力的增强带来了可能。由此产生的新一轮人工智能热潮也可以从国内外顶尖大学或中央政府为未来人工智能制定的许多计划中看出来。例如,美国斯坦福大学在2014年为人工智能提出了“人工智能100年(AI 100)”计划,以理解人们是如何工作、生活和娱乐的。此外,美国政府在2016年宣布了一项“为人工智能的未来做准备”的提案,成立了“人工智能和机器学习委员会”。欧盟(European Union, EU)提出了欧洲人工智能新理论,强调让以人为中心的人工智能可信任,包括技术鲁棒性、安全性、透明性和可靠性等。与此同时,中国也制定了新一代人工智能发展计划,强调可解释的、可推理的人工智能。当多媒体被人工智能所影响时,人工智能反过来会带来更加可推理的多媒体技术,这相较于现有的多媒体技术方法具有更强的解释性并且更符合人类认知习惯的推理能力。人工智能的终极目标之一是弄清楚一个智能体如何才能在现实世界中成长与发展,并再现这一过程。感知和推理能力是使得人类能在多样环境中生存的一个重要因素。因此,研究人工智能中的类人感知和推理过程将带来具有感知和推理能力的可推断的多媒体,能够对感知到的外部环境进行推理并做出决策。然而,关注这一方向(即利用人工智能来增强多媒体的推理能力、推动多媒体发展)的工作却很少。本文从两个方面探讨多媒体与人工智能之间的相互关系和相互影响:
1)多媒体对人工智能的影响:多媒体推动人工智能向着更具可解释性的方向发展。
2)人工智能对多媒体的影响:人工智能促进多媒体技术推断能力的发展。
因此,本文将多媒体智能定义为多媒体和人工智能的融合。如图1所示,它的内涵是多媒体和人工智能相互促进和增强的良性循环,它的特点在于具有可解释性和推断能力。
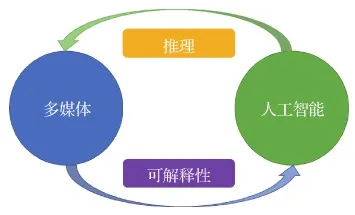
图1 多媒体智能的“循环”Fig.1 Cycle of multimedia intelligence
更具体地说,由于当前蓬勃发展的机器学习理论方法在基于人工智能的数据建模和分析中占据了统治地位,同时机器学习技术作为目前人工智能领域中的代表广泛应用于多媒体领域,因此为便于叙述和阐释,以机器学习为例,从本文下面两个方向讨论多媒体与人工智能之间的双向影响:
1)多媒体信息通过催生许多适用于特定多媒体任务且更易于解释的机器学习技术来促进机器学习发展,并扩大了机器学习的应用范围。
2)机器学习赋予多媒体技术更强大的推理能力,增强了多媒体信息分析模型的推断能力。
本文对多媒体智能的相关研究工作及进展进行讨论与总结,同时指出还有哪些值得研究的工作尚未完成,以及如何才能完成。此外,还阐述了可能对多媒体智能产生深远影响且具有前景的研究方向,并提出了一些不成熟的见解。
1 多媒体推动机器学习发展
一方面,多媒体数据的多模态核心推动机器学习发展出了许多新兴技术,来帮助多媒体很好地捕捉和建模多媒体数据的异构特征(Cord和Cunningham,2008)。另一方面,大量的多媒体数据使得视听语音识别、图像/视频标注和视觉问答等多种多模态应用成为了可能。如图2所示,本节将从两个方面讨论多媒体促进机器学习发展的方式:多媒体如何推动机器学习技术发展;多媒体如何推动机器学习应用发展。
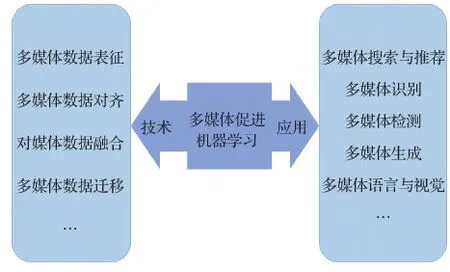
图2 多媒体推动机器学习发展Fig.2 Multimedia promots machine learning
1.1 多媒体推动机器学习技术发展
多媒体数据包含图像、音频和视频等多种类型的数据,其中单模态数据在过去十年中被研究者广泛研究。然而,近来多模态和异构的多媒体数据越来越多,这给机器学习算法在正确处理多模态数据时试图精确捕捉不同模态之间的关系带来了巨大的挑战。因此,本文聚焦在多模态多媒体数据上,总结了多模态多媒体数据分析中的4个基本问题,即多媒体数据表征、多媒体数据对齐、多媒体数据融合和多媒体数据迁移,并重点介绍了相应的机器学习技术,旨在通过解决这4个问题正确地处理各种多媒体数据。
1)多媒体数据表征。学习多媒体数据表征的方法主要可以分为两类:联合表征和调和表征。联合表征将多个单模态数据组合到同一个特征空间中,而调和表征在将不同模态的数据进行分别处理的同时对它们施加某些相似的约束,使它们在坐标空间中具有可比性。为了获得多媒体数据的联合表征,研究人员设计和利用了元素操作、特征串联、全连接层、多模态深度置信网络(Srivastava和Salakhutdinov,2012)、多模态压缩双线性池(Fukui等,2016)和多模态卷积神经网络(Ma等,2015)等方法来组合不同模态的数据。为了获得调和表征,一个典型的例子是深度视觉语义嵌入模型(deep visual-semantic embedding model,DeViSE)(Frome等,2013),它构造了一个从图像到文本特征的简单线性映射,这样相对应的注释和图像表征之间的内积值将大于非对应的值。其他一些工作也在两个单模态自动编码器的共享隐藏层上建立了调和的空间(Wang等,2015;Yuan等,2019a)。图3展示了多模态数据表征的一个示例。
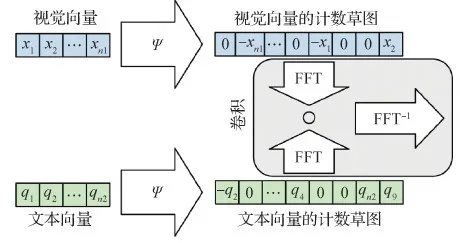
图3 多模态压缩双线性池(Fukui等,2016)Fig.3 Multimodal compact bilinear pooling (MCB)(Fukui et al., 2016)
越来越多的工作表明了深度自注意力网络(Transformer)在众多领域取得成效,因此使用Transformer来统一多模态的表征成为一种可能。如LXMERT(learning cross-modality encoder representations from Transformers(Tan和Bansal,2019))、Oscar(object-semantics aligned pre-training for vision-language tasks(Li等,2020))等工作,通过Transformer来获取数据的联合表征;而CLIP(contrastive language image pre-training(Radford等,2021))、BriVL(bridging vision and language by large-scale multi-modal pre-training(Huo等,2021))则用以获取数据的调和表征。
2)多媒体数据对齐。多模态多媒体数据对齐是理解多模态数据的一个基本问题,其目的是发现两个或多个模态实例之间的关系和对齐方式。多模态问题,如时域语句定位(Gao等,2017;Hendricks等,2017;Yuan等,2019b)和描述目标定位(Liu等,2019a;Zhang等,2018)都属于多模态数据对齐的研究领域,因为它们需要将句子或短语与相应的视频片段或图像区域对齐。多模式数据对齐可分为两种主要类型——隐式对齐和显式对齐。Baltrušaitis等人(2019)将显式多模态对齐定义为两种或以上模态的实例对齐。而隐式对齐一般用于任务的中间步骤。隐式对齐的模型不直接对齐数据也不依赖于监督数据对齐样本,而是通过模型训练学习如何以隐藏的方式来对齐数据。对于显式对齐,Malmaud等人(2015)利用隐马尔可夫模型(hidden Markov model,HMM)将菜谱步骤与(自动生成的)烹饪视频字幕对齐,Bojanowski等人(2015)通过学习视觉和文本模态之间的线性映射来解决时域对齐问题,以便在视频中自动为句子找到对应的时间(帧)戳。对于隐式对齐,注意力机制(Bahdanau等,2015)作为机器学习领域中一个典型的工具,能够使解码器更多地关注于需要处理的目标子元素,例如图像(Vinyals等,2015)的某个子区域、视频(Yao等,2015;Yu等,2016)中的帧或片段,句子(Bahdanau等,2015)中的单词和音频(Chan等,2016)的片段等。图4展示了多模态数据对齐的一个示例。

图4 多模态对齐的变分上下文模型(Zhang等,2018)Fig.4 The proposed variational context model (Zhang et al., 2018)
3)多媒体数据融合。多模态融合也是多媒体人工智能的关键问题之一。它旨在整合来自多种模式的信号,以预测特定结果:通过分类预测类别(如正或负),或通过回归预测一个连续值(例如,中国某一年的人口)。总体而言,多模态融合方法可以分为两个方向(Baltrušaitis等,2019):与模型无关的方法和基于模型的方法。与模型无关的方法也可以分为3种类型:早融合、晚融合和混合融合。早融合在提取特征后立即整合来自多种模态的特征(通常通过简单地连接它们的特征来实现)。晚融合在每种模态做出自己对于某个任务的决策(例如,分类或回归)后进行整合。混合融合通过将早融合预测结果和单模态的预测结果通过概率加权聚合在一起来获得合并的输出。与模型无关的方法几乎可以使用任何单模态分类器或回归器来实现,这意味着它们使用的技术不是专门为多模态数据设计的。相比之下,在基于模型的方法中,囊括了3类模型来完成多模态融合:基于核的方法、图模型和神经网络。多核学习(multiple kernel learning,MKL)(Gönen和Alpaydn,2011)是基于核的支持向量机(support vector machine,SVM)的扩展,允许将不同的核用于来自不同模态/视图的数据。由于核可以看做是估计数据点之间相似性的函数,因此MKL中特定于模态的核可以更好地融合异构数据。图模型是多模态融合的又一系列流行方法,可分为生成方法(如耦合(Nefian等,2002)、阶乘隐马尔可夫模型(Ghahramani和Jordan,1997)以及动态贝叶斯网络(Garg等,2003))和判别方法(如条件随机场(conditional random field,CRF)(Lafferty等,2001))。图模型的一个优点是它们能够利用数据的时间和空间结构,使其特别适合用于解决视听语音识别等时域建模的任务。目前,神经网络(Ngiam等,2011)已广泛用于多模态融合的任务。例如,长短期记忆(long short-term memory,LSTM)网络(Hochreiter和Schmidhuber,1997)已经证明了其在多模态情感序列识别(Wöllmer等,2013)方面优于图模型的优势;自动编码器(auto encoder,AE)在多模态散列(Wang等,2015)、多模态量化(Wang等,2019b)和视频摘要(Yuan等,2019a)方面达到了令人满意的效果;卷积神经网络(convolutional neural networks,CNN)已广泛用于图像文本检索任务(Ma等,2015);CEN(channel exchanging network(Wang等,2020))则利用通道交换来实现多模态数据的融合,在语义分割和图像转换任务上取得了较好效果;MBT(multimodal bottleneck Transformer(Nagrani等,2021))通过引入Transformer,限制不同模态之间信息传递的瓶颈,从而浓缩每个模态中最相关和最必要的信息,在多个视听任务中取得了成功。虽然深度神经网络架构具有从大量数据中学习复杂模式的能力,但它们缺乏推理能力。图5展示了多模态融合的一个例子。
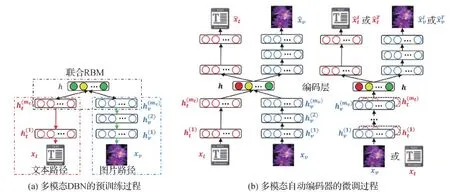
图5 多模态融合的预训练和微调过程(Wang等,2015)Fig.5 Multimodal fusing in pretraining and fine-tuning(Wang et al., 2015)((a) multimodal DBN in pretraining; (b) multimodal AutoEncoder in fine-tuning)
4)多媒体数据迁移。多模态多媒体数据迁移问题旨在不同模态间迁移有用信息,目的是用资源丰富的模态的知识来建模资源贫乏的模态(Baltrušaitis等,2019)。对于假设模态来自同一数据集,并且实例之间存在直接对应关系的并行多模态数据,迁移学习是实现多模态数据迁移的典型方法。例如,多模态自动编码器(Ngiam等,2011;Wang等,2015)可以通过共享的隐藏层将信息从一个模态迁移到另一个模态,这样不仅能得到合适的多模态表征,而且还能得到更好的单峰特征。迁移学习对于假设模态来自不同的数据集,并且具有重叠的类别或概念而不是重叠的实例的非并行多模态也是可行的。这种类型的迁移学习通常通过利用调和的多模态表征来实现。例如,DeViSE(Frome等,2013)将卷积神经网络视觉特征与在单独数据集上训练的词向量(word2vec)文本特征(Mikolov等,2013)调和起来,以达到利用文本标签来改进分类任务中的图像表征的目的。为了在多模态迁移中处理非并行多模态数据,观念框架(Baroni,2015)和零样本学习(Socher等,2013)是实际中采用的两种代表性方法。对于实例或概念由第3种模态或数据集联系在一起的混合多模态情境(并行和非并行数据的混合),最值得注意的例子是桥关联神经网络(Rajendran等,2016),它使用一种枢轴模态来学习非并行数据的调和多模态表征。这种方法也可用于机器翻译(Nakov和Ng,2009)和音译(Khapra等,2010),以连接没有并行语料库但共享共同枢轴语言的不同语言。图6展示了一个多模态迁移的例子。
图6 模型结构与可视化结果(Frome等,2013)Fig.6 Model structure and visualization results(Frome et al., 2013)((a) joint model;(b) t-SNE visualization)
1.2 多媒体推动机器学习应用发展
如前所述,当前人工智能技术的核心在于机器学习的发展,因此本文将重点介绍几个具有代表性的机器学习应用,包括多媒体搜索与推荐、多媒体识别、多媒体探测、多媒体生成和多媒体语言与视觉,它们因为丰富可用的多模态多媒体数据而得以广泛流行。
1)多媒体搜索与推荐。相似性搜索(Agrawal等,1993;Ciaccia等,1997)一直是多媒体信息检索中一个非常基础的研究课题,一个好的相似性搜索策略不仅需要准确性,还需要高效率(Gionis等,1999)。相似性搜索的经典方法旨在单个模态内搜索相似的内容,例如,在给定文本(图像)作为查询目标的情况下搜索相似的文本(图像)。另外近年来多媒体应用的快速发展创造了大量属于各种不同信息模态的内容,如视频、图像、语音和文本。这些大量的多模态数据带来了对跨多模态内容进行高效、准确的相似性搜索的强烈需求(Rasiwasia等,2007,2010),例如给定文本搜索相似图像或给定图像搜索相关文本。同时,多模态散列在多媒体检索上的应用和图卷积的结合,可以保证在查询阶段,即使部分模态特征丢失,也能够稳健地捕获各种模态的信息,从而保证搜索的效果(Lu等,2021)。目前已经有一些关于多模态搜索的研究,更多的详细内容可以从相关的综述论文(Wang等,2016a;Wang等,2018)中获取。互联网快速发展带动了各种包含多媒体数据的网络服务的发展,带动了从被动多媒体搜索到主动多媒体搜索的转变,进而带来了多媒体推荐的需求。多媒体推荐技术可以广泛地涵盖用于视频推荐(Yu等,2019a)、音乐推荐(van den Oord等,2013)、群组推荐(Wang等,2016b)和社交推荐(Wang等,2016c,2017,2019a)等的技术。同时,用户与多模态项目之间的交互也可以作为一种隐式建模,来更好地挖掘多模态内容潜在的信息,从而提高推荐的效果(Zhang等,2021)。同样,读者可以从相关的综述论文(Zhu等,2020b)获得关于多模态推荐的更多详细内容。
2)多媒体识别。多媒体研究的最早例子之一是视听语音识别(audio-visual speech recognition,AVSR)(Yuhas等,1989)。这项工作的灵感来源于McGurk效应(McGurk和MacDonald,1976),其认为语音感知是在人们的视觉和听觉交互下进行的。McGurk效应源于一种观察,即人们在观看一位年轻的正在说话的女人的电影时声称听到了音节[da],然而事实是嘴型为[ga]的重复的音节被配音成了[ba]。这项结果激励了许多进行语音研究的研究人员在额外的视觉信息的帮助下扩展他们的方法,特别是来自深度学习方向的研究人员(Afouras等,2018;Ngiam等,2011;Petridis等,2018)。将多模态信息纳入语音识别程序确实提高了识别性能,并在一定程度上提高了可解释性。其他一些人也观察到,当音频信号嘈杂时,视觉信息的优势变得更加突出(Gurban等,2008;Ngiam等,2011)。视听语音识别的发展促进了包括视频中的语音增强和识别、视频会议和听觉增强等的广泛应用,特别是在多人嘈杂环境中说话的情况下(Ephrat等,2018)。尽管之前提及的工作在许多情况下都能够达成较好的效果,但是它们仍然依赖于带标签的训练数据,而在真实生活中的语音数据则多数没有标签,因此半监督(Xu等,2020b)、自监督(Baevski等,2020)或无监督(Baevski等,2021)的语音识别系统能够在语音识别中达到更好的效果。图7给出了视听语音识别的流程。
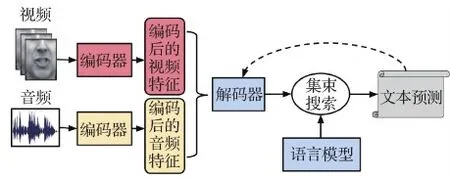
图7 视听语音识别(AVSR)流程概述(Afouras等,2018)Fig.7 Outline of the audio-visual speech recognition(AVSR)pipeline(Afouras et al., 2018)
3)多媒体检测。人类活动检测(Ramachandram和Taylor,2017)是需要大量利用多媒体数据的一个重要研究领域。由于人类在社交活动中经常表现出高度复杂的行为,因此机器学习算法在理解和识别人类活动时自然需要多模态数据的帮助。深度多模态融合的一些工作通常涉及视觉、听觉、深度、运动甚至骨骼等信息(Chen等,2015;Escalera等,2015;Ofli等,2013)。基于多模态深度学习的方法已应用于有关人类活动的各种任务(Ramachandram和Taylor,2017),包括动作检测(Natarajan等,2012;Singh等,2016;Xu等,2020a;Xu,2021)(一个行为可能由多个较短的一系列动作组成)、视线方向估计(Lian等,2019;Mukherjee和Robertson,2015;Zhang等,2020)、手势识别(Chen等,2021;Neverova等,2016;Wu等,2016)、情感识别(Kahou等,2016;Poria等,2016)和面部识别(Ding和Tao,2015;Guo等,2020a;Meng等,2021;Zhang等,2015)。现在包含至少10个传感器的移动智能手机已经流行起来,催生了许多涉及多模态数据的新应用,包括连续生物识别身份验证(Schultz和Sartini,2016;Sitov等,2016)。图8展示了一个多模态检测的例子。
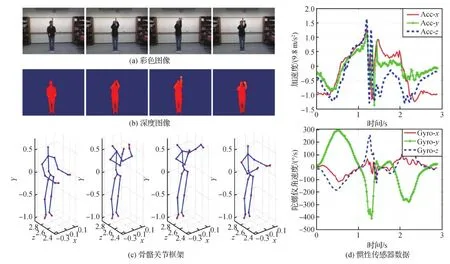
图8 对应于投篮动作的多模态数据的一个例子(Chen等,2015)Fig.8 An example of the multimodality data corresponding to the action basketball-shoot(Chen et al., 2015)((a) the color images; (b) the depth images; (c) the skeleton joint frames; (d) the inertial sensor data)
4)多媒体生成。多模态多媒体数据生成是多媒体人工智能的另一个重要方向。给定一个模态中的实体,多媒体生成的任务是生成另一个不同模态中的同一实体。例如,图像/视频标注和从自然语言生成图像/视频是两组典型的应用。多模态生成的核心思想是将信息从一种模态转换为另一种模态,以便在新模态中生成内容。多模态生成中有很多方法,并且通常是基于特定模态的,它们可以分为两种主要类型:基于实例和基于生成(Baltrušaitis等,2019)。基于实例的方法在模态之间通过构造字典来进行翻译,而基于生成的方法构造能够完成模态间转换的模型。图像转文字(Im2text)(Ordonez等,2011)是一种典型的基于实例的方法,它利用全局图像表征来检索说明文字并将它们从数据集转移到待查询的图像。其他一些基于实例的方法采用整数线性规划(integer linear programming,ILP)作为优化框架(Kuznetsova等,2012),该框架搜索用于描述视觉上相似的图像的现有人工组成的短语,然后有选择地组合这些短语以生成待查询图像的新描述。对于基于生成的方法,基于端到端训练的编码器—解码器神经网络设计是目前最流行的多模态生成技术之一。这些模型背后的主要思想是首先将源模态编码为压缩的矢量表示,然后使用解码器生成目标模态。虽然编码器—解码器模型首先被用于机器翻译(Kalchbrenner和Blunsom,2013;Sutskever等,2014),但它们后来被进一步用于解决图像/视频标注(Kuznetsova等,2021;Venugopalan等,2015;Vinyals等,2015)和图像/视频/语音生成(Liu等,2019d;Mansimov等,2016;Owens等,2016;Ramesh等,2021,2022;Reed等,2016;van den Oord等,2016)问题。图9给出了多模态生成的示例。
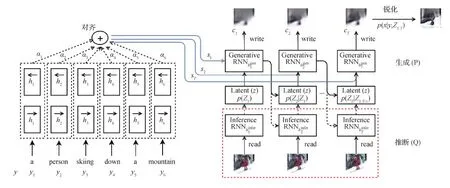
图9 AlignDRAW模型(Mansimov等,2016)Fig.9 Alignment deep recurrent attention writer(AlignDRAW) model (Mansimov et al., 2016)
5)多媒体语言与视觉。还有一类多模态应用强调语言和视觉之间的相互作用。最具代表性的应用是视频中的语句时域定位(Gao等,2017;Hendricks等,2017;Yuan等,2019b)、图像/视频标注(Duan等,2018;Pan等,2017b;You等,2016)以及从自然语言(Liu等,2019d;Mansimov等,2016;Pan等,2017a;Qiao等,2019)生成图像/视频。语句时域定位是视频中动作探测的另一种形式,旨在利用自然语言描述而不是预定义的动作标签列表来识别视频中的特定活动(Gao等,2017;Hendricks等,2017;Yuan等,2019b),因为复杂的人类活动不能简单地概括为有限的标签集。由于自然语言能够提供对目标活动的更详细的描述,因此充分利用视觉和文本信号可以帮助更精确地检测时间边界(Chen等,2018a;Zhang等,2019)。这可以进一步促进一系列下游视频应用发展,如视频亮点检测(Badamdorj等,2021;Yao等,2016)、视频摘要(Narasimhan等,2021;Yale等,2015;Yuan等,2019a)和视觉语言导航(Anderson等,2018;Pashevich等,2021)。此外,在图像区域中定位自然语言的概念类似于描述目标定位(Liu等,2019a;Zeng等,2020;Zhang等,2018)。图像/视频标注旨在为输入图像/视频生成文本描述,其动机是帮助视力受损的人日常生活(Bigham等,2010),并且对于基于内容的检索也非常重要。因此,标注技术可以应用于许多领域,包括生物医学、商业、军事、教育、数字图书馆和网络搜索(Hossain等,2019)。反向任务上也取得了一些进展——从自然语言(Pan等,2017a;Qiao等,2019;Zhang等,2017)生成图像/视频,其目的是提供更多渠道来增强媒体多样性。但是,图像/视频标注和生成任务在评估方面都存在主要挑战,即如何评估预测得到的描述结果或生成的图像/视频的质量。图10展示了视频标注的一个示例。

图10 基于深度学习的视频标注的基本框架Fig.10 Framework of video annotation based on deep learning
2 机器学习推动多媒体发展
一方面,探索计算机算法类似人类的感知和推理能力一直是机器学习研究的首要任务之一。另一方面,人类的认知过程也可以视为感知和推理的级联(Manhaeve等,2018;Peng等,2017)。
1)人类探索周围环境,建立对世界的基本感知理解。
2)人类用人类所学到的知识来进一步推理人类的感知理解,并获得更深入的理解或新知识。
图11展示的是机器的类人认知过程,整个环节与上述人类认知过程极为相似。机器从任务环境和场景中获取原始数据,一边自下而上进行数据感知和特征提取,一边结合已有的知识对获得的特征进行符号化和符号推理,建立起对多媒体数据的进一步理解和认知。从思路上,它模仿了人类的认知过程,而人确实通过这一过程获取了认知能力;从技术上,它充分利用了外部环境的反馈和已有知识的信息,约束了整个学习过程从而能够达到收敛。
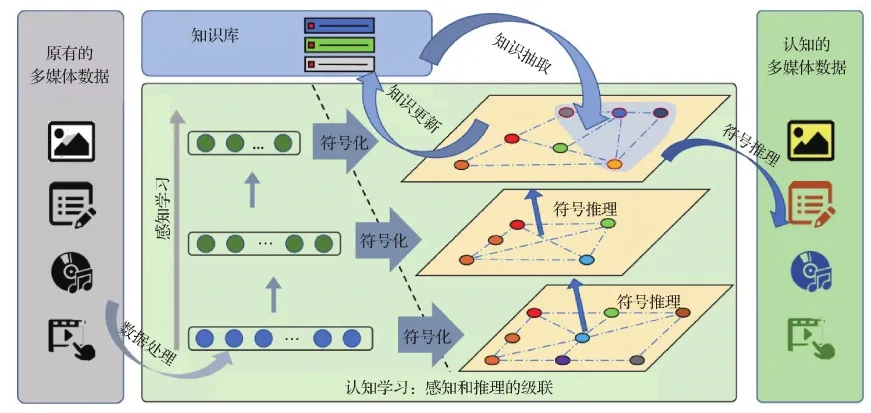
图11 类人认知过程(Zhu等,2020a)Fig.11 Human-like cognition(Zhu et al., 2020a)
因此,一部分机器学习致力于研究感知和推理,以提高模型在特定任务和场景下的表现。尽管部分基于感知和推理的机器学习方法在提出时并不针对于多媒体数据和多媒体任务,但其中所蕴含的思路和策略可以迁移到多媒体领域中。这些相关技术的利用能够增强多媒体中类似人类的推理特征,从而产生推理能力更强的多媒体技术。
目前,深度学习方法已经可以很好地完成感知部分:可以区分猫和狗(Deng等,2009),识别人类(Zhao等,2017),并回答简单的问题(Antol等,2015)。然而,它们几乎无法进行任何推理:既不能对其感知预测给出合理的解释,也不能进行明确的、人类可理解的推理。计算机算法离真正的类人感知和推理还很远,本节简要回顾了深度学习领域神经推理的进展,希望能为读者提供该方向的一些研究进展。
2.1 推理启发的感知学习
一些研究人员试图通过使用推理启发层或模块化来增强神经网络,从而使神经网络具备推理能力。例如,人类的推理过程可能包括多轮思考:人类可能重复某个推理过程数次,直到达到某个目标。在这种情况下,可以将一些递归推理层添加到神经网络模型中,来模拟这一多轮过程。同时,关系信息和外部知识(以知识图谱的形式表示)对于机器学习算法获得对某些事实的推理能力也是必不可少的。在采用图神经网络(Scarselli等,2009)或关系网络(Palm等,2018;Santoro等,2017)设计深度神经网络时,也考虑了这些因素。
1)多步推理。多步推理的目的是模仿人类的多步思维过程,可以利用递归神经网络(recursive neural network,RNN)实现,在这些工作中搜索者将一个递归单元作为多步推理模块插入神经网络(Cadene等,2019;Hudson和Manning,2018;Wu等,2018)。Hudson等人(2018)设计了一个功能强大且复杂的递归单元,该单元能够满足递归神经网络单元的定义,并利用了许多直观的设计,如“控制单元”、“读取单元”和“写入单元”来模拟人的一步推理过程。Wu等人(2018)采用多步推理策略来发现视觉问答(visual question answering,VQA)中分步推理的线索。Cadene等人(2019)介绍了一种多步的多模态融合模式来回答VQA问题。此外,Das等人(2019)提出了使用多步检索—读者交互模型来解决回答问题任务的方法。Duan等人(2019a)使用多轮解码策略来学习更好的视频示例的项目特征。这些模型显著提高了对应性能,并自称是解决相关场景中问题的最新技术成果。然而,这些模型并不完美,因为它们需要更复杂的结构,而其内部推理过程也就更难解释。此外,这些方法采用固定的递归推理步骤以便于实现,这比人工推理过程要不灵活得多。图12展示了一个多步推理的例子。

图12 视觉问答的多步推理模型流程(Wu等,2018)Fig.12 Chain of reasoning for VQA(Wu et al., 2018)
2)关系推理。除了模仿人类的多步推理过程,模拟人类推理的另一种方式是利用图神经网络(graph neural networks,GNN)(Scarselli等,2009)来模仿人类的关系推理能力。这些工作大多使用图神经网络聚合低级感知特征以得到增强的特征,来改进目标检测、目标跟踪和视觉问答任务(Chen等,2019;Narasimhan等,2018;Xiong等,2019;Xu等,2018;Xu,2019;Yu等,2019b)的效果。Yu等人(2019b)和Xu等人(2018)使用GNN来为各种任务集成目标检测方法中的特征。而Narasimhan等人(2018)和Xiong等人(2019)利用GNN作为一种消息传递工具来增强视觉问答对象的特征。除了图像特征方面的工作外,Liu等人(2019c)和Tsai等人(2019)还基于时间和空间数据构建了用于基于视频的社会关系检测的图。Duan等人(2019b)使用关系数据改进了3维点云分类任务的性能,并提高了模型的可解释性。在Duan等人(2019b)的工作中,一个对象可以看做是几个子对象的组合,这些子对象及其关系共同定义了该对象。例如,可以将鸟视为其子对象,如“翅膀”、“腿”、“头”、“身体”,及它们之间的关系的复杂集合,这被认为能够提高模型的性能和可解释性。此外,Wen等人(2019)在多智能体强化学习任务中考虑了多智能体之间的关系,而Chen等人(2018b)则提出了一种将基于卷积和基于图的模型结合在一起的双流网络。图13展示了一个关系推理的例子。

图13 使用GNN作为目标检测任务中的推理工具(Chen等,2019)Fig.13 GNNs as inference tools in object detection tasks (Chen et al., 2019)
3)注意力图和可视化。许多作品将注意力图作为推理的可视化或解释的一种方式,这些注意力图在一定程度上验证了相应方法的推理能力。特别是Mascharka等人(2018)提出将注意力图作为可视化和推理的线索。Cao等人(2018)使用依赖树来指导VQA任务中注意力图的使用。Fan和Zhou(2018)利用潜在注意力图来改进多模型推理任务的效果。
2.2 感知—推理级联学习
一方面,相当多的研究致力于将推理能力集成到深层神经网络(deep neural network,DNN)中;另一方面,其他研究试图将DNN强大但初级的表示能力进行解耦,并将不同层次的感知过程进行级联来模拟高级的、人类可理解的认知,以期实现真正的强人工智能。
1)神经模块网络。神经模块网络(neural modular network,NMN)最早由Andreas等人(2016a)提出,并进一步在视觉推理任务中得到应用。NMN的主要思想是使用一组预定义的神经模块来动态地组装针对某个实例特定的计算图,从而为每个输入实例实现个性化的异构计算。这些神经模块在设计时被赋予了特定的功能,例如查找、关联和回答等,它们通常根据不同的输入实例动态地被组装成层次树结构。
NMN的设计动机来自两个观察结果:(1)视觉推理本质上是合成的;(2)深度神经网络具有强大的表示能力。
NMN的组合特性允许将视觉推理过程分解为几个可共享、可重用的基本功能模块。然后,可以使用深度神经网络将这些原始功能模块作为神经模块来有效地实现。将视觉能力建模为分层原语的优点是多方面的。1)可以区分低级视觉感知和高级视觉推理;2)能够保持视觉世界的合成特性;3)与整体方法相比,这样生成的模型更具解释性,可能有利于未来人机回圈(human-in-the-loop,HITL)的多媒体智能的发展。
VQA任务是开发计算机算法的视觉推理能力的一个很好的测试平台。广泛使用的VQA数据集(Antol等,2015;Goyal等,2017)更强调视觉感知而非视觉推理,这促使多个具有挑战性的多步、组合视觉推理数据集被设计出来(Hudson和Manning,2019;Johnson等,2017a)。CLEVR(compositional language and elementary visual reasoning diagnostics dataset)数据集(Johnson等,2017a)包括了一系列针对合成图像的组合问题,这些合成图像仅由3类对象和12种不同属性(例如,蓝色大球体)所渲染,而GQA数据集(Hudson和Manning,2019)则处理具有更大语义空间和更多样化的视觉概念的真实图像。
最早由Andreas等人(2016a)提出的NMN,利用异构、共同训练的神经模块组成深度网络。他们利用依赖关系解析器和手写规则生成模块布局,然后根据这些布局,使用一小部分模块组装成一个深度网络来回答视觉问题。动态模块网络(dynamic-neural modular network,D-NMN)(Andreas等,2016b)是神经模块网络的后续工作,它学习了如何从手写规则所自动生成的一组候选布局中选择最佳布局。Hu等人(2017)和Johnson等人(2017b)同时提出将布局预测问题转化为序列到序列的学习问题,而不是依赖现成的解析器来生成布局。这两种模型都可以预测网络布局,并都使用了强化和梯度下降相结合的方法来端到端地学习网络参数。值得注意的是,Johnson等人(2017b)提出的模型为CLEVR数据集(Johnson等,2017a)设计了细粒度的高度专业化的模块,例如filter_rubber_material,它在模块实例化中硬编码文本参数。相比之下,Hu等人(2017)提出的端到端模块网络(end-to-end module networks, N2 NMNs)模型设计了一组通用模块,例如查找、重定位,它们接受软注意力机制下的词嵌入作为文本参数。在Hu等人(2018)的后续工作——堆栈神经模块网络(stack neural modular network,Stack-NMN)中,网络不是对模块布局进行离散化的选择,而是使用完全可微的堆栈结构使布局光滑且连续。Mascharka等人(2018)提出了设计透明网络(transparency by design network,TbD-net),该网络使用了与Johnson等人(2017b)类似的细粒度模块,但根据需求功能重新设计了每个模块。该模型不仅在CLEVR数据集(Johnson等,2017a)上展现了近乎完美的性能,而且还展示了可以为模型行为提供解释的视觉注意力机制。
尽管这些模块化网络在合成图像上显示出近乎完美的准确性和可解释性,但在真实图像上执行全面的视觉推理仍然具有挑战性。Li等人(2019)提出了感知视觉推理(perceptual visual reasoning,PVR)模型,用于对真实图像进行合成的、可解释的视觉推理,如图14所示。作者设计了一个包含从低级视觉感知到高级逻辑推理的丰富的通用模块库。同时,PVR模型中的每个模块都能够从指导知识中感知外界监督,这有助于模块学习专门的和解耦的功能。他们在GQA数据集上的实验表明,PVR模型可以在推理过程中产生透明、可解释的中间结果。

图14 感知视觉推理(PVR)模型概述(Li等,2019)Fig.14 Overview of perceptual visual reasoning (PVR) model(Li et al., 2019)
2)神经符号推理。除了组织按照语言学布局的模块化神经网络外,神经符号推理也是一个先进且有前途的方向,它的发展受到了来自于认知科学、人工智能、心理学以及结合了机器学习和自动推理的认知计算系统的推动。Garcez等人(2002)引入了神经符号推理的基本思想:首先使用神经网络学习对场景的低级感知理解,然后将学习到的结果视为离散符号,在推理技术下进行进一步推理。Yi等人(2018)探索了视觉问答下的神经符号推理能力。视觉问答任务可以被解构为视觉概念探测、语言到程序的翻译和程序执行。通过学习视觉符号表征和语言符号表征,神经符号推理能够在预先设计的程序执行器中在视觉符号图上“执行”学习得到的语言符号代码来回答视觉问题。图15展示了神经符号推理的一个例子。
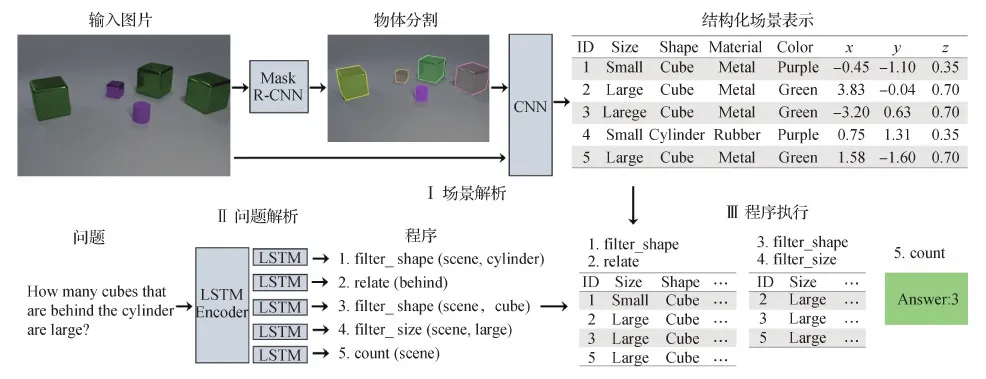
图15 视觉问答的神经符号推理(Yi等,2018)Fig.15 Neural symbolic reasoning for visual question answering(Yi et al., 2018)
神经符号推理因为其对DNN强大的特征表示能力和模拟人类高级推理和认知的能力的运用,在近年来受到了广泛的关注。然而,神经符号推理所使用的点对点(ad-hoc)程序设计和复杂的程序执行器严重限制了其性能,如何开发更好的程序设计和执行器值得进一步研究。
3 未来研究方向
3.1 多媒体图灵测试
本文介绍了多媒体智能的概念,并给出了多媒体和人工智能之间的循环(如图1所示),在这个循环中,多媒体和人工智能相互影响。近年有诸多工作研究了从多媒体到AI(机器学习)的半个循环,而从AI(机器学习)到多媒体的另一半循环的研究却很少,从而显示出了循环的不完整性。本文认为多媒体图灵测试是能够补全循环的一种很有前途的方法。多媒体图灵测试包括视觉图灵测试(视觉和文本)(Geman等,2015;Olague等,2021;Qi等,2015)、音频图灵测试(音频和文本)等,这些图灵测试在多种多媒体模态上进行。本节以视觉图灵测试为例,说明它与多媒体图灵测试中的其他成员是类似的。让计算机算法通过评估人类学习能力的视觉图灵测试可以作为进一步增强多媒体类人推理能力的一个阶段。视觉图灵测试的引入最初是在人类理解图像以及讲述图像故事的能力中得到的启发。在视觉图灵测试中,测试机器和人都被给予一幅图像和一系列问题,这些问题遵循着一条自然的故事线,这类似于人类在观看图像时所做出的反应。如果人类在测试中无法通过检查人和机器对给定图像的一系列问题的答案来区分人和机器,那么可以得出这样的结论:机器通过了视觉图灵测试。显然,通过视觉图灵测试需要类似人类的推理能力。
3.2 多媒体中的可解释推理
在今后的工作中,探索更具解释性的多媒体推理过程是一个值得进一步研究的重要方向。一种简单的方法是利用其他推理特征来扩充深度神经网络,从而丰富具有推理特性的深度神经网络。应该为深层神经网络配备更多更好的推理增强层或模块,这些模块将提高DNN的表示能力。例如,由于各种多媒体对象可以通过异构网络连接在一起,所以可以通过GNN来进行建模(Cai等,2022a,b)。进一步,若能将GNN中的关系推理能力与类人多步推理相结合,也许可以开发出一种新的具有更强推理能力的GNN框架(Liu等,2021;Zhao等,2020)。而在更深层次上,类人认知学习(图11中的感知推理一体化学习)中最吸引人的是推理过程是透明和可解释的,这意味着人类知道模型如何以及为什么会对某个场景起作用。因此,如何借助一阶逻辑、逻辑编程语言以至领域专用语言和更灵活的推理技术来设计更强大的推理模型值得进一步研究。此外,程序语言设计和程序执行器的自动化可以使神经符号推理在更复杂的场景中得到应用,这是在多媒体中实现可解释推理的另一种很有前景的方式(Trivedi等,2021;Verma等,2018)。最后,鉴于当前的神经网络和推理模块是分开优化的,通过一个整体优化框架将神经网络和推理结合起来对于实现多媒体中可解释推理的目标起着重要作用。
3.3 自动机器学习与元学习
自动机器学习(automatic machine learning,AutoML)和元学习是学术界和工业界研究领域快速发展并受到大量关注的研究方向。AutoML的目标是将端到端的机器学习模型在实际应用时进行自动化选取最优超参数(Akiba等,2019;Bergstra等,2011;Bergstra和Bengio,2012;Snoek等,2012)与模型架构(Guo等,2020b;Liu等,2019b;Pham等,2018;Zoph和Le,2017),从而使计算机算法能够自动适应不同的数据、任务和环境。AutoML作为通用的机器学习方法,在多媒体领域中也大有可为,在多媒体数据表征、对齐、融合和迁移的过程中,存在着大量的超参数设置和模型架构选取,即使研究者有充分的专业经验和知识背景也可能花费大量时间和精力才能选出其中较为优秀的参数和架构。尤其当多媒体数据来源于真实的动态开放环境时,数据的分布将难以预先确定,因而更加需要模型自动应对当前的多媒体环境,实现感知和推理。
元学习(meta learning),即学会如何学习,旨在从不同的任务中提取和学习某种形式的一般知识,以供将来的各种其他任务使用,这也是人类特有的特征。关于元学习的现有文献主要集中在估计不同数据或任务之间的相似性,并试图借助额外的存储来尽可能多地记住以前的知识(Finn等,2017;Rusu等,2019;Santoro等,2016)。在多媒体领域中的元学习方法能够增强多媒体模型实现迁移的能力,从而充分地将来自外部或内部的丰富感知结果向资源贫乏的模态进行迁移,提高相关模态的推理能力。
综上,将自动机器学习和元学习的思想应用于多模态多媒体问题,培养在类人任务和环境中的适应能力和知识迁移能力,是推动多媒体智能发展的另一个关键研究方向。
3.4 数字视网膜
在人类认知过程中,感知和推理之间实际上没有严格的界限——人类可能同时感知和推理(如图11所示)。因此,开发一些模拟这一过程的原型系统可能会将多媒体智能“循环”的补全推进一大步。
以现实世界的视频监控系统为例,当前系统中的视频流首先在摄像机上被采集并压缩,然后传输到后端服务器或云上进行大数据分析和检索。然而,人们认识到,压缩将不可避免地影响视觉特征的提取,从而降低后续分析和检索的性能。更重要的是,为了进行大数据分析和检索将来自数十万台摄像机的所有视频流聚合在一起是不切实际的。此时,类似人类的认知学习,即感知和推理的一体化,可以作为一种可能的解决方案,借鉴人类视网膜同时具有影像编码能力和特征编码能力的生物特征,人类能够设计一种更高效的摄像机,称为数字视网膜摄像机,简称数字视网膜(Gao等,2021;Lou等,2019)。这种新的数字视网膜的灵感来源于这样一个事实:生物视网膜实际上同时编码像素和特征,而大脑的下游区域接收的不是图像的一般像素表示,而是一组经过高度处理提取得到的特征。在数字视网膜框架下,相机通常配备全球统一的定时器和精确定位器,并且可以同时输出两个流,包括用于在线/离线观看和数据存储的压缩视频流,以及从原始图像/视频信号中提取的用于模式识别、视觉分析和搜索的压缩特征流。要实现数字视网膜需要有3项关键技术,包括分析友好的场景视频编码、视觉特征压缩描述符以及对视觉内容和特征进行整体压缩。通过只将特征流实时传输到云中心,这些摄像头能够为智能城市提供一个大规模的、像大脑一样的视觉系统(高文 等,2018;高文,2020a,b;Gao等,2021;李赣湘,2021)。在多媒体的未来发展方向中,能够有效地在边缘设备进行感知和推理也是实现多媒体智能的重要因素(曹行健 等,2022;汪志涛,2022)。这一过程中包含了多媒体智能新的挑战和机遇,即在受限硬件设备下的数据建模和特征提取,这与寻常的多媒体数据表征在任务场景上是大相径庭的,但这一需求却是切实存在的。因此有必要将数字视网膜作为多媒体智能的未来发展方向之一,从而推动当前的多媒体研究朝着更实际的场景和更类人感知和推理的方向发展。
4 结 语
本文围绕“大数据”时代多媒体与人工智能融合的背景,提出了多媒体智能的新概念,探讨了多媒体和人工智能之间的相互影响,具体包括以下两个方向:
1)多媒体推动人工智能向着更具可解释性的方向发展;
2)人工智能促进多媒体推理能力的发展。
这两个方向形成了一个多媒体智能循环,其中多媒体和AI以交互和迭代的方式相互促进增强。本文讨论了每一循环中的研究进展,特别是研究多媒体如何推动机器学习发展以及机器学习如何反过来推动多媒体发展。最后,总结了循环中已经完成的工作,并指出完成循环未来所需要做的工作,然后对值得进一步深入探索的多媒体智能相关研究方向进行了思考。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
环球时报(2022-07-13)2022-07-13
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年9期)2022-05-20
中国教育信息化·高教职教(2022年4期)2022-05-13
环球时报(2022-03-14)2022-03-14
煤气与热力(2022年2期)2022-03-09
电影(2018年8期)2018-09-21
成长·读写月刊(2018年8期)2018-08-30
软件(2017年6期)2017-09-23
