
面向海洋的多模态智能计算:挑战、进展和展望
2022-09-20 09:13聂婕左子杰黄磊王志刚孙正雅仲国强王鑫王玉成刘安安张弘董军宇魏志强
中国图象图形学报 2022年9期
聂婕,左子杰,黄磊,王志刚,孙正雅,仲国强,王鑫,王玉成,刘安安,张弘,董军宇,魏志强,*
1. 中国海洋大学,青岛 266100; 2. 中国科学院自动化研究所,北京 100190;3. 清华大学计算机科学与技术系,北京 100084;4. 青岛海洋科学与技术试点国家实验室,青岛 266061;5. 天津大学电气自动化与信息工程学院,天津 300072; 6. 北京航空航天大学宇航学院,北京 100083
0 引 言
海洋是高质量发展的要地,是人类社会的未来。但目前对海洋系统的精细认知不足5%。通过观测、监测、调查、分析和统计获取的海洋大数据是人类认识海洋的主要途径。如图1,随着全球海洋立体“空—天—地—海—底”观测系统的不断发展(吴立新 等,2020),形成了面向海洋的遥感图像、时空序列数值、仿真数据、文献资料以及监控视音频等大规模多模态数据。根据当前关于海洋数据量的研究,2014年全球各种海洋数据总量约为25 PB,预计2030年全球海洋数据总量将达到275 PB。这表明海洋多模态数据的存量已经接近EB级,日增量也达到TB级。其中,海洋遥感图像和时空序列数值是其主体,时空序列数值以矩阵形式呈现,通常也作为图像对待。所以,对以图像为主的海洋多模态大数据的深入分析和挖掘,是认知海洋动力过程、能量物质循环、蓝色生命演变,实现科学重大发现、生态环境健康、应对极端天气和气候变化的关键途径,也是支撑人类社会可持续发展的重大战略需求。
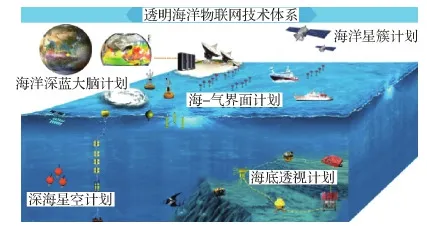
图1 透明海洋立体观测网(吴立新 等,2020)Fig.1 The draft of observation network of “Transparent Ocean”(Wu et al., 2020)
与传统大数据相比,海洋多模态大数据具有超巨系统(占地表71%面积,日增量10 TB)、超多视角(“陆—海—气—冰—地”耦合、“水文气象声光电磁”多态)、超跨尺度(“厘米至百公里”空间尺度,“微秒至年代际”时间尺度)等显著特征,导致现有的多模态智能计算技术难以应对跨尺度多模态融合分析、多学科跨领域协同推理、大算力多架构兼容应用等难题。因此,虽然我国对海观测能力日益强大,但海洋多模态大数据价值挖掘的智能化水平不足,迫切需要针对其差异化特点,构建面向海洋的多模态智能计算理论体系和技术框架。目前,海洋多模态智能计算领域的研究刚刚起步,尚未形成体系化和差异化研究方向,现阶段的工作大多关注现有多模态数据挖掘技术在海洋场景下的应用优化,并未针对海洋领域数据的分布特点开展深入研究。因此,本文通过梳理现阶段海洋领域面向多模态智能计算中的内容分析、融合推理以及智能计算等方面的现有工作,结合领域场景需求,提出海洋多模态智能计算的主要研究内容、现有进展、关键问题和未来展望。
1 海洋多模态智能计算概述
本文从海洋大数据内容分析、推理预测以及实时计算应用需求出发,通过介绍海洋科学大数据的全生命周期,如图2所示,引出海洋多模态智能计算的研究对象、科学问题以及主要的应用场景。

图2 针对典型场景的海洋大数据生命周期Fig.2 Marine big data life cycle for typical scenarios
1.1 海洋多模态大数据
海洋多模态大数据主要来源于观测监测、调查统计、仿真计算和文献资料4个方面。1)观测监测数据。主要包括实测和遥感两类(侯雪燕 等,2017)。实测数据针对定点局部区域通过船基观测、定点观测和移动观测方式,采集海洋气象(风场、温度、湿度和气压等)、物理海洋(温度、盐度和海流等)、海洋化学(营养盐、溶解氧和二氧化碳等)以及海洋生物(叶绿素、生物量)等海洋环境要素的实测数据,数据具有局部的时空连续性,时空精度较高,但受制于传感器可靠度差异,原始数据可信度参差不齐。遥感数据主要包括卫星遥感和航空遥感两类,通过搭载不同的遥感载荷,实现对海洋水色(水色、水温、海冰、绿潮和海岸带等)、动力环境(海面高度、海面风场、海洋锋面和中尺度涡等)、关键目标和事件(海冰、海岛和溢油等)进行大范围高频动态监测。遥感观测区域范围较大,但时空精度和连续性相互制约,易受大气等因素的干扰;其次,数据可读性较差,需进行复杂的数据处理,才能开展内容分析和知识挖掘。2)调查统计数据。调查数据的获取途径是利用海洋调查船的固定航次,开展海洋环境要素的原位采样调查;统计数据主要来源于政府部门对海洋经济,例如海洋渔业、滨海旅游等产业统计数据。此类数据的时空跨度较大,倘若调查船一年仅执行4个航次,单次调查数据为季平均数据;统计年鉴数据大多为月平均、年平均数据。3)仿真计算数据。海洋数值模拟是海洋自然科学的基础。以生态动力学模拟为例,通过构建描述动力过程的Navier-stokes方程(郑沛楠 等,2008)进行背景流场的计算,加入包含生物地球化学过程的生态模块,构建物理、化学和生物过程耦合的生态动力学模型。模型通过同化操作实现模拟数据向实测数据的逼近,获得再分析数据产品(李宏和许建平,2011)。再分析数据是时空连续的3维网格数据,精度高、规模大,但由于数值模拟对物理、化学和生物过程认知不足,导致仿真结果与真实数据差距较大。4) 文献资料。主要包括海洋科学领域的科学文献、政策法规、图文资料和视音频等多媒体大数据。
原始数据普遍存在时空缺失、可靠性低和可读性差等问题。因此需要进行数据清洗、补全和反演等预处理,提升数据的可靠性和可读性。例如遥感图像需经过校正、配准、融合、定标和反演形成环境要素的数据产品(赵忠明 等,2019);仿真数据需经过等高线、等值线和轮廓面等可视化手段,形成时空连续的动态可视的视音频资料(解翠 等,2021)。预处理能够提高数据的时空完整性、可读性和可靠性,图3是海洋环境变量时空数据场可视化后的图像序列示例,包括叶绿素浓度和海表面温度,可视化图像提高了科研人员对数据的理解,更易于开展机理分析。

图3 海洋环境变量时空数据场可视化图像示例Fig.3 Visual image examples of spatiotemporal data field of marine environmental variables((a)global Chl-a concentration visualization image sequences;(b)global sea surface temperature visualization image sequences)
1.2 海洋多模态智能计算的主要科学问题
海洋多模态智能计算研究对预处理后的海洋数据产品进行融合、交互、分析、推理和决策/预测的智能技术,达到辅助海洋领域专家提升理解、发现规律和探明机理的目标。其主要科学问题可以归纳为以下4个方面,如图4所示。
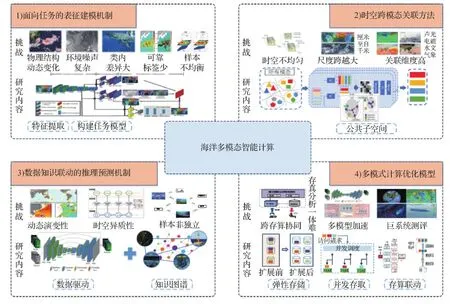
图4 海洋多模态智能计算的主要科学问题Fig.4 Main scientific problems in marine multimodal intelligent computing
1)面向任务的表征建模机制,即特征工程。对多模态大数据中隐含刻画的目标、现象、过程和规律进行表征建模。针对特定任务,抽取具有因果性、区分性、显著性和鲁棒性的有效特征,构建任务和数据之间的有效桥梁,克服大数据和特定任务间的“任务鸿沟”。
2)时空跨模态关联方法。针对多圈层、多尺度和多视角异构时空数据,获取具有任务匹配性、语义一致性和时空相关性的跨模态关联建模,实现多模态合理融合,跨模态有效映射,克服多模态间的“异构鸿沟”。
3)数据知识联动的推理预测机制。融合智能感知能力和知识驱动的认知能力,重点需要建模领域专家的知识、经验和推理机制,针对海洋时空演变造成的未来时空演变不确定性问题,填补对非完全数据空间的“未知鸿沟”。
4)多模式计算优化模型。海洋多模态大数据刻画时空范围广、精度高。随着对海观测从大尺度向亚中尺度、微尺度演进,分辨率的提升和海洋过程的细化导致相同时空区域下的数据规模激增(宋振亚 等,2019);海洋场景下的目标识别、气象预报和灾害预警等典型应用又对海洋数据处理和响应的时效性有所要求。因此,需开展计算模型的优化研究,克服海洋超巨系统复杂计算和实时在线响应需求之间的“计算鸿沟”。
1.3 海洋多模态智能计算的典型应用场景
海洋多模态智能计算技术支撑内容理解、决策预测和交互分析等典型场景。1)海洋多模态大数据的内容分析。包括语义理解(例如海面/体/底的目标分类、检测和图像分割)以及过程和事件检测(例如中尺度涡、台风、赤潮和绿潮等)。如使用卫星遥感图像数据、卫星接收器状态数据等多模态数据检测台风风速等海洋过程与事件。2)数据和知识协同的推理决策和演变预测。包括海洋知识图谱构建、海洋环境变量的时空演变趋势预测,例如:海洋初级生产力时空预测、气象预报、灾害预警和海洋经济指数估计等,如有学者通过多光谱遥感仪推算出视场范围内的单体有义波到达视场中心的用时及变化趋势,同时根据流速流向仪和升沉加速度仪优化波浪参数预测算法,提高了海浪预测的精度,为海洋活动提供及时有效的预警服务。3)海洋多模态大数据的交互分析,包括海洋结构和现象的可视化以及可视分析系统,例如海洋峰、涡旋的可视分析。
2 海洋多模态智能计算的研究进展
目前,海洋多模态智能计算的研究工作处于起步阶段,尚未形成体系化理论和技术框架,现阶段工作大多关注现有多模态数据挖掘技术在海洋场景下的迁移和应用。本文从海洋多模态大数据内容分析、推理预测和高性能计算3个主要研究领域出发,展开现有研究工作的介绍。
2.1 海洋多模态大数据内容分析
内容分析旨在对多模态大数据中隐含刻画的目标、现象、过程和规律进行表征建模,提升用户对数据的理解性和交互性。海洋多模态大数据主要包括针对面向任务的表征建模学习和时空跨模态关联方法学习两个前沿研究方向。
2.1.1 面向任务的表征建模学习
针对特定的海洋大数据内容分析任务,对海洋多模态数据中包含的目标、现象、过程和规律进行表征建模,抽取具有因果性、区分性、显著性和鲁棒性的有效特征是实现海洋多模态大数据内容分析的基础。根据任务不同,回顾海洋目标识别、海洋目标重识别、海洋现象/过程识别以及海洋目标检索等任务的表征建模学习工作。
1)海洋目标识别。因复杂的环境噪声导致的物类内差距较大,或者因不同物种差异微小难以区分问题,会造成特征提取的困难,Liu等人(2021) 提出一种更为精细的混合注意力网络,能够聚焦细微差异的区域,将特征图按区域划分为区间,根据区域方向学习注意特征。此外,He等人(2021) 将Transformer引入细粒度识别,TransFG(Transformer architecture for fine-grained recognition)整理每一层编码器的注意力权重,准确地选择具有区别度的图像块并计算它们之间的关系,相比ViT(vistion transformers)能更大程度地保留细粒度信息,是未来细粒度目标识别任务的一个重要方向。
针对小样本问题,早期的工作主要从构建更大的数据集角度开展研究。Guo等人(2020)尝试以度量学习的角度解决小样本识别问题,Guo和Guan(2021) 使用卷积神经网络(convolutional neural network, CNN)提取特征,然后通过采用软最大损失函数和中心损失函数的联合训练的方法,以最小化特征类内距离,最后使用迁移学习对新类进行微调,实现了海洋浮游生物的识别。Chen等人(2019) 利用孪生网络(Koch等,2015) 对水下声学目标进行识别,该网络由两个相同的神经网络组成,对两个图像分别提取特征,利用对比损失函数计算两幅图像之间的相似性来识别目标。此外,研究者利用元学习的方法使得模型学习一个好的初始化参数,Villon等人(2021) 首先使用Reptil (Nichol和Schulman,2018) 算法在大的数据集上进行元训练,训练后的模型可以很快地适应新的学习任务,然后在鱼类数据集上进行小样本识别任务。
2)海洋目标重识别。海洋目标重识别(Re-ID)旨在识别(匹配)通过多个不重叠的摄像机拍摄到的同一海洋目标。现有研究中主要涉及的目标包括水下鱼类(Fisher等,2016;Vidyarthi和Malik,2022;Schneider等,2020)、水面的船舰(Schneider等,2020)。
对海洋生物进行重识别一般使用视觉生物特征识别方法,通过形态结构、形状、颜色和皮毛图案或点状图案等动物个体独特的生物特征识别目标。Vidyarthi和Malik(2022)提出了一种基于座头鲸尾部图案的重识别方法,为了最小化梯度消失的影响,提出了一种稠密模型和用于ROI(region of interest)分割的自由流算法(free flow algorithm),使用限制对比度自适应直方图均衡(contrast limited adaptive histogram equalization,CLAHE)做预处理以优化参数来增强特征的可重用性。由于拍摄角度的多样性,遮挡是海洋目标重识别中的一个关键问题,不仅造成有效特征的丢失还引入了干扰。针对该问题,Moskvyak等人(2019)通过从自然标记中学习姿势不变嵌入特征实现对蝠鲼的鲁棒重识别,构建了一种基于独特自然标记的视觉重识别系统,对遮挡、视角和光照变化具有一定的鲁棒性。
3)海洋现象/过程识别。海洋现象/过程识别的对象主要包括台风、海面涡旋和海洋锋面等典型现象。
在台风识别领域,蒋众名(2018)提出了利用深度学习的方法对台风云系进行识别,通过对台风以及 FY-2 气象卫星数据的特点进行深入调研,设计了利用Faster R-CNN(faster region-convolutional neural network)深度学习模型识别台风云系的方法,对台风云系进行了较为准确的识别。由于海洋现象的物理结构动态变化迅速,针对现有卫星云图特征提取复杂、识别率低等问题,邹国良等人(2019)基于卷积神经网络,使用1978—2016年间发生在北太平洋的1 000多个台风过程的卫星云图作为样本, 提出了改进的深度学习模型Typhoon-CNNs,该模型采用循环卷积策略增强模型表征力,提高了区分度,在台风等级分类中取得了较好的分类效果。
在识别海洋锋面领域,Li 等人(2022a)针对海洋锋面的弱边缘特性,将锋面检测转换为弱边缘识别问题,提出弱边缘识别网络模型进行锋面检测,网络由4个卷积块组成,每个块都有一个侧输出层,用于检测特定图像表示级别的前缘,随后对侧输出进行融合,以预测海洋锋面的位置。Li 等人(2022b)设计了一个具有U-Net架构的深度学习模型,用于检测和定位灰度海面温度图像中的重要锋面区域,随后采用面积阈值对模型的输出进行滤波以改善结果,该方法不仅可以合并凌乱的锋面,还可以捕捉锋区的整体模式。
在对中尺度涡的识别中,芦旭熠等人(2020)选择深度学习多目标检测网络对涡旋同时进行识别和定位,在提高涡流检测速度的同时达到了较好的识别结果。不同模态的数据构建的特征空间往往不同,Santana 等人(2020)设计和实现了用于涡流识别和分类的 CNN 模型,并使用海表面温度(sea surface temperature,SSH)和海平面异常(sea level anomaly,SLA)等数据对模型进行评估,以此验证训练数据和指标的选择对模型训练效果的重要性。
4)海洋目标检索。海洋目标检索旨在根据用户的需求,对海洋相关的文本、图像、音频和视频等多媒体信息进行查找,并按相关性反馈结果。海洋目标包括水域(李轶鲲 等,2016)、水下的鱼类(孙建伟等,2016)、藻类(李伟伟,2015)、对虾、鲸鱼、矿物等海洋生物(Song等,2019)和物质;水面的船舰以及风暴潮、中尺度涡(Piedra-Fernndez等,2014)和海啸等海洋环境现象。
鱼类、藻类等海洋检索目标种类繁多但外形相似,个体差异微小,难以提取具有区分性的特征。孙建伟等人(2016)提出了一种基于多特征的鱼类图像检索方法——多特征鱼类图像检索(multiple features fish image retrieval,MFFIR),选择全局颜色特征和Gabor特征作为鱼类图像检索特征向量,采用MFFIR法通过计算多维特征向量的特征相关性,实现了鱼类图像的匹配与检索。Osman和Mustaffa(2015)提出了一种全局—局部特征融合方法,融合鱼类图像基于轮廓的形状特征和基于区域的形状特征,提高鱼类相似性的准确性。李伟伟(2015)提出了一套基于内容的方法对藻类图像进行分类检索,采用SIFT(scale-invariant feature transform)算法、PCA(principle component analysis)技术、K-means聚类算法相融合的方式针对藻类图像进行识别检索。李轶鲲等人(2016)提出一种遥感图像数据库水体区域检索方法,结合综合区域特征提取算法的检索结果和平均高频信号强度逆序排序的检索结果,通过减少因特征提取误差所造成的检索错误,实现对遥感图像水体区域的精准检索。
2.1.2 时空多模态关联方法学习
针对单一模态下的数据的表征建模之后,需要对多圈层、多尺度和多视角异构时空数据,研究具有任务匹配性、语义一致性和时空相关性的跨模态关联建模,实现多模态合理融合,跨模态有效映射。
1)海洋现象/过程识别。不同模态的数据构建的特征空间往往不同,Santana 等人(2020)设计和实现了用于涡流识别和分类的 CNN 模型,并使用海表面温度SSH 和 SLA等数据对模型进行评估,以此验证训练数据和指标的选择对模型训练效果的重要性。但是海洋现象往往会受到多种因素的影响,利用单一模态的数据构建的特征空间来识别涡流效果有限,Fan等人(2020)提出了一种新的基于多模态数据融合的深度学习模型,综合利用海面高度、海面温度和流速数据识别中尺度涡。
2)目标检索。海洋现象的物理结构在形状上具有高度可变性,位置随海水流动持续性动态变化,难以保持持续稳定的物理结构性。常用的目标检索方法不适用于如上升流、尾流、冷核涡流和暖核涡流等海洋现象,检索效果不佳。针对中尺度涡的高度形状可变性和快速的位置变化问题,Piedra-Fernndez等人(2014)提出了一种基于模糊内容的海洋遥感图像检索系统,结合模糊逻辑和地理空间信息技术,将系统和神经模糊分类器连接到模糊数据库,实现中尺度涡的神经模糊分类和模糊检索。
2.1.3 公开数据集简介
1)Wildfish(Zhuang等,2018)是最大的野生鱼类识别图像数据集,由1 000个鱼类类别和54 459幅无约束图像组成,允许训练用于自动鱼类分类的高容量模型。数据集为现实场景提出了一种新颖的开放式鱼类分类任务,并研究了具有许多实际设计的开放式深度学习框架。此外,在成对文本描述的指导下提出了一种新颖的细粒度识别任务,并设计一种多模态网络来有效区分成对的两个容易混淆的鱼类类别。
2)Fish4Knowledge(Fisher等,2016)项目记录和分析了来自10个摄像机位置的 9 万小时视频,并按照海洋生物学家的指示对鱼类进行人工标记,生成了 27 370 个经过验证的鱼类图像,整个数据集分为 23 个集群。该数据集来源于中国台湾南湾、兰屿和后壁湖水下观测站3年的观测数据,项目存储超过100 TB的数据,构建了远程网络、超级计算处理、视频目标检测和跟踪、鱼类识别与分析以及大型数据库的高效检索机制。然而由于不同物种之间数量的差异,数据之间非常不平衡,最常见的物种比最不常见的物种多出约1 000倍。
3)Labeled fishes(Cutter等,2015)数据集图像包括鱼类、无脊椎动物和海床图像,由于移动的成像平台、复杂的岩石海床背景以及静止和移动的鱼类目标多方面的因素,数据集图像成像环境变化很大。数据集由3部分组成:用于训练和验证正图像集(包含3 167幅图像)、负图像集和测试图像集,其中负图像集表示非鱼类的图像,训练集和测试集具有随附的注释数据,用于定义图像中每个标记的鱼类目标对象的位置和范围,同时也定义了不同种类、大小和范围的鱼,并包括不同背景成分的部分。
4)Humpback是Kaggle座头鲸识别赛中官方给出的识别座头鲸尾部的数据集,该数据集包含了25 000多幅训练图像以及将近8 000幅测试图像。训练数据中,有3 000多条鲸鱼尾巴只有几幅图像。研究人员已对个别鲸鱼进行了识别,并给出了标注,但依然有大量的属于未知个体的鲸鱼尾巴,即存在近三分之一的无标注数据。目前,该数据集广泛应用于海洋目标重识别。
5)COMS全球海洋科学数据集(COMS global ocean science data,COMS-GOSD)是由中国科学院海洋大科学研究中心构建的全球海洋现场观测数据集。COMS搜集了1900年以来的大量全球海洋观测数据,包括海水温度、盐度、pH、溶解氧和CO2分压等13个物理或生物地球化学要素;也包括抛弃式探温仪器(expendable bathy thermograph,XBT)、温盐深仪(conductivity temperature depth,CTD)、Argo、Glider和浮标等11种仪器类型观测到的数据。COMS-GOSD中,仅温度和盐度数据就各有上千万条廓线。此外,COMS数据准实时更新,实现了海洋环境状况的实时监测。
6)SSTG(a global gridded sea surface temperature data)数据集是2002—2019年的全球海面温度数据,以摄氏度为单位,时间分辨率为月,空间分辨率为0.041°。数据集是由2种红外辐射计(MODIS(moderate resolution imaging spectroradiometer)和AVHRR(advanced very high resolution radiometer))及3种被动微波辐射计(AMSR-E(advanced microwave scanner radiometer-earth),AMSR2和Windsat)得到的逐日海面温度卫星反演数据和逐日海面温度观测数据相结合,通过一个温度深度和观测时间校正模型校正后产生的海温图像数据。精度评价表明,重建后的数据集有明显改进,可以用于海洋中尺度现象分析。
2.2 海洋多模态大数据推理预测
海洋多模态大数据推理预测主要包括针对数据驱动的海洋多模态大数据预测预报和针对知识驱动的海洋多模态大数据推理预测两个前沿研究方向。
2.2.1 针对数据驱动的海洋多模态大数据预测预报
将多模态时空序列输入深度神经网络,构建端到端的预测预报模型,成为突破海洋环境预测瓶颈的新途径,引起了全球海洋科学和人工智能领域顶级科学家的关注。数据驱动方法相较于基于机理的海洋预报模式,能够支撑更长时序的可靠预测。目前,数据驱动方法按照数据的时空组织形式,可分为基于规则时空网格(时序空间数据场)的方法和基于非规则点源的方法两类。
在规则时空网格数据驱动方法中,Ham等人(2019)首次利用海洋模式计算获得的海表面温度时空序列,通过构建深度卷积神经网络预测模型,实现长达18个月的厄尔尼诺指数稳定预测。Ye等人(2021)在Ham等人(2019)工作的基础上,通过自适应选择不同前置时间的网络架构,实现了不同任务(前置时间)的时空依赖可变性建模,突破了利用相同的深度学习模型进行预测而导致的对不同前置时间内ENSO(El Nio-Southern Oscillation)可变性挖掘不充分的问题,从而提高了长期预测的可靠性。朱贵重和胡松(2019)利用长短时记忆循环神经网络(long short term memory-recurrent neural network,LSTM-RNN)对西太平洋研究海区的海表温度(sea surface temperature,SST)构建时序模型,通过海区历史平均月SST、风场等物理变量实现了该海区次月的SST预测。在以上方法中,针对时空异质性问题,均采用了时域和空域划分的方法,针对不同时域和空域,开展平行建模,或者将时空作为参数代入模型,但以上模型均未考虑时空预测时样本的非独立性问题,针对该问题,Zheng等人(2020)基于遥感获得的海表面温度图像序列,利用多尺度的深度学习模型实现了热带不稳定波海表面温度场的预测。该模型由深度神经网络和偏置校正映射组成。其中,偏置校正模块采用地统计学原理,对样本非独立的问题进行了误差的估计和校正,同时该模型针对跨尺度建模的问题,构建了4个级联卷积层,在上一层和本层接收SST映射,在下一层输出SST映射。每一层接收的SST映射具有不同的分辨率。该模型解决了全局和局部信息同时建模的问题,Chattopadhyay等人(2020)通过胶囊神经网络(CapsNets)预测了北美大陆在30°N和60°N之间的亚热带和中纬度地区的极端温度事件。该方法利用迁移学习的思想,从中层大尺度环流模式(Z500)构建的仿真数据进行训练并预测冷浪或热浪的发生区域,解决了灾害监测中负样本缺失的问题。
在非规则点源预测的研究中,陈英义等人(2018)对水产养殖溶解氧预测展开研究,首先通过主成分分析方法提取主要影响因素,在减小因素间关联性的同时,降低了数据维度。在处理数据之后,利用长短期记忆(long short term memory, LSTM)方法做出最后预测。石绥祥等人(2020)利用LSTM预测叶绿素a浓度,根据影响因素与叶绿素a浓度的依赖程度,将影响因素划分为长时序依赖和短时序依赖两类,分别利用两类因素预测叶绿素a浓度,最后融合两个预测结果得出最终预测。Park等人(2015)利用人工神经网络(artificial neural network,ANN)和支持向量机(support vector machine,SVM)对分别位于上游(淡水储集层)和下游(河口水库)的Juam水库和永山水库的叶绿素浓度进行预警预测。使用7年期的每周水质数据和气象数据来训练和验证ANN和SVM模型。采用LH-OAT(latin hypercube-one factor at a time)方法和模式搜索算法分别对输入变量进行灵敏度分析,并对两个模型的参数进行优化。在非规则点源的预测问题中,数据驱动模型,特别是采用跳步预测的深度学习模型和迭代预测模型相比,不容易产生迭代误差累积,更适合于长时序的预测,但由于无法利用一个深度学习模型对长时序预测的稳态、非稳态等特性同时建模,因此,采用结构化的集成学习方法是突破该问题的有效手段。
2.2.2 针对知识驱动的海洋多模态大数据推理预测
作为知识驱动方法的代表,知识图谱是利用图模型描述知识和建模世界万物之间关系的技术方法,是人工智能从智能感知向智能认知发展的重要技术。当前主流的知识图谱将可识别的客观对象进行关联,以形成客观世界实体和实体关系的知识库,本质上可以视为语义网络,其中节点代表实体(entity)或者概念(concept),边代表实体/概念之间的各种语义关系。按领域范围,可将知识图谱划分为通用知识图谱和领域知识图谱。其中领域知识图谱由行业场景中高维度的专业化知识构成,对知识的深度和质量提出更高的要求,表达方式不限于以实体为节点,进一步引入以事件为节点的图谱网络,在领域流程优化、辅助决策和预测分析等应用服务发挥优势。
海洋领域知识图谱相较于通用知识图谱和医学、经济等领域的知识图谱而言相对较少。其中,华东理工大学构建了面向舟山图书馆的海洋知识图谱,所开发的集成工具包括知识获取、知识整合和知识存储3个关键模块,涉及鱼类、渔场、鱼类加工方法、相关学者以及地方企业等知识(Ruan等,2014);东南大学基于国际海上避碰规则构建了面向海洋法律法规的知识图谱,设计了包括概念、对象、环境、动作和目录在内的5类本体,基于此抽取得到416个实体节点和532个关系的海洋避碰知识图谱(Liu和Wang,2019);武汉理工大学针对海上危险物品安全运输对于领域知识的迫切需求,提出了海上危险物品知识图谱的3层结构,并且将知识表示形式化为实体层和概念层,所形成的知识图谱对于简化专业知识检索过程和促进智能运输发挥重要作用(Zhang等,2019);以上工作基于领域知识和本体模型进行实体和关系抽取,为了实现开放域的实体关系自动抽取,挪威科技大学开发了面向海洋科学及相关学科文献的文本挖掘演示系统,该系统能够自动抽取变化事件(如CO2增加)中的实体(如CO2)以及事件间的共现和因果关系(如CO2增加导致海水pH降低),形成包含百万级节点的知识图谱(Marsi等,2017)。中国英大传媒投资集团针对自动识别海图符号任务,提出了使用领域知识描述符号领域含义的方法,为此开发了基于多个数据源的航海知识图谱构建工具,所形成的知识图谱包含约1 500个概念、2.5亿下位关系、8千万实体以及3千万实体间关系(Nie等,2019)。以上知识图谱均为静态知识图谱,为了建模表示真实世界知识的演化特性,动态知识图谱的研究逐步成为当今的热点,它们通常是在静态知识图谱方法的基础上,将时序演化信息注入已有的静态得分函数之中,用以表示动态场景下的演化知识。法国诺曼底大学将海洋环境态势感知任务建模为知识图谱的链接预测任务,为此针对多源异质海洋数据构建了百万级节点的动态属性知识图谱,其中节点表示为向量的时间序列用以刻画其演化特性(Everwyn等,2019)。为了建模表示真实世界知识的多模态属性,提出了多模态知识图谱的概念。它与传统知识图谱的主要区别是,传统知识图谱主要集中研究文本和数据库的实体和关系,而多模态知识图谱则在传统知识图谱的基础上,构建了多种模态(例如视觉模态)下的实体,以及多种模态实体间的多模态语义关系。在海洋领域,上海交通大学基于100余万篇地球科学相关论文构建了迄今最大规模、最全面的地球科学多模态学术知识图谱,在所提出的回路框架下,创新性地将机器阅读、信息检索技术与地球科学家手工标注相结合,实现了知识实体抽取方法,所形成的知识图谱包含6 800万三元组(Deng等,2021)。
2.3 海洋多模态大数据的高性能计算
围绕跨存算协同、多模型加速和巨系统测评3个挑战,展开海洋多模态大数据高性能计算的相关工作梳理和介绍。
2.3.1 存算协同
NetCDF(network common data form)是海洋多模态数据最常用的存储格式,其作为结构化文件,可高效组织多维度﹑多变量和结构紧凑的信息。然而,现有大数据存储系统主要面向松散结构的行式数据,其采用大文件分块机制,将不同分块散布于云计算集群中的多个物理节点上,并通过数据备份来提高数据安全性与访问速率。因此,如何在分布式环境中读取NetCDF文件以及如何缓解分块过程中导致的信息结构破坏则是海洋多模态数据存储的关键挑战。
现有研究者按照业务需求将NetCDF文件预处理后提取所需信息进行格式变换与存储,以适应现有云存储机制。刘金凤(2015)将NetCDF 文件转换成自定义txt格式数据,Zhao等人(2010)将NetCDF数据转换为基于文本的CDL文件以便大数据编程模型MapReduce并行访问,张玉娟等人(2017)基于分布式数据库与实际业务场景调整时空分片和时空索引方案,Duffy等人(2012)利用MapReduce将数据集转换为序列文件。但预处理转换操作会破坏NetCDF原有压缩特性,浪费存储空间,且引入较大的预处理开销。
另一种解决思路是直接将 NetCDF文件按流式分割进行分布式存储,并通过重构数据获取分块的物理存储地址信息,以支持分布式环境中的快速查询和高效计算(夏伟 等,2019)。Bibin等人(2019)根据并行计算粒度对中间数据规模进行评估以选择合适的内存数据结构,设计了用户自定义的同步磁盘存储模式,以提升数据存储容量。谭凯中等人(2021)在分析时空关联特性后,基于HDFS(hadoop distributed file system)创建分布式主从索引,通过主节点与多个工作节点分级过滤查询条件,提高数据请求的响应速度。黄冬梅等人(2016)从数据敏感性、扩展性和安全性角度考虑,提出基于公共云平台和本地私有云平台的混合存储体系,并提出根据数据生命周期的不同建立代价收益函数,以指导数据在不同位置之间的动态迁移。Qu等人(2020)则基于扩展性良好的NoSQL数据库,以唯一的全球空间识别码为主索引、时间码为次索引,创建时空二级复合索引,可快速检索海洋时空大数据。
针对GPU(graphies processing unit)的单指令多数据集、访存速度差异性等硬件特点,王春晖等人(2013)从计算过程中的数据访问方式与存储位置布局进行了优化,以确保执行相同指令的临近线程访问地址连续的内存空间,合理使用共享存储器硬件提高多线程之间的数据交换效率,并通过计算流与传输流的重叠来覆盖CPU内存与GPU显存之间的数据传输开销,最终提高GPU存储带宽资源和计算资源的利用率。为进一步提高数据访问效率,Linghu等人(2018)将数据的存储布局细化到缓存级别并锁定CPU内存页面,而张留莹等人(2020)则灵活调整局部变量与全局变量的声明形式以充分利用高速寄存器内存。
此外,超级计算通常配置专门的数据存储服务节点,以提供大容量的高速访存服务。何晓斌和蒋金虎(2020)通过虚拟化整合异构的网络存储设备以提供全局统一的共享数据存储服务,通过层次化结构设计实现负载均衡、多级缓存和高可用保障。
2.3.2 并行加速
结合新型硬件设备(如多核CPU集群、GPU以及超级计算机等)特性研究海洋数值模型的可并行化是实现海洋高性能计算的重点研究内容。海洋数值模型并行化的主体设计思路是将网格数据分布到不同的计算单体,降低通信开销、均衡负载以及优化计算流程与任务调度,充分利用硬件资源。下面将依据计算硬件设备介绍并行加速的相关内容。
多核CPU架构由于其成熟的技术体系,成为并行加速的首选基础平台,相关并行化研究主要致力于合理地将数据及其计算负载分配到多个计算任务,即输入域的分解。Cowles(2008)因此采用水平分解方式并使用MPI(message passing interface specification)插件简化计算任务之间的通信管理。Um等人(2017)将卫星图象数据网格化分配到不同计算任务,以并行化LM(Levenberg-Marquadt)模型,从而加速叶绿素分布的预测时效。为精准定位并行加速过程中的关键代码位置,杨晓丹等人(2017)以MASNUM(marine science and numerical modeling)海浪模式为例,利用诊断工具Intel Vtune Amplifier XE 和 Intel Trace Analyzer Collector对性能和负载均衡性进行分析,以寻找热点函数,采用MPI实现任务间并行与OpenMP实现任务内并行的组合策略进行加速。输入域的分解一方面可充分利用集群中的计算节点以及节点内的多核算力,另一方面由于任务内并行可实现更加高效的共享内存方式交换数据,显著减少MPI通信规模。此外,海洋模型通常采用紧耦合策略以提高开发效率,即在全局范围内进行函数调用与数据共享,给并行计算带来了巨大负担。Yang等人(2012)提出细粒度组件开发方式重新设计海洋并行模型,单独封装共享函数与变量以简化依赖关系,使得各个组件可独立完成并行化。改进后的模型粗粒度并行采用ESMF(earth system modeling framework)的虚拟机完成信息交互以适应每个组件对资源的个性化需求。Valera等人(2019)直接利用可扩展科学计算库PETSc(portable, extensible toolkit for scientific computation)对海洋模型进行并行化,以减少并行开发的工作量,保证并行效率(Valera等,2019)。
针对GPU设备,常用的并行策略是将每个输入网格的数据单体映射到单独的线程,以充分利用其并发算力优势(Linghu等,2018)。景辉等人(2018)利用大数据处理系统Spark调度多个GPU进行易并行(又称本质并行)任务计算(即任务间无通信需求),并针对异构GPU设备导致的算力差异研究了多项式时间的任务均衡调度算法。
超级计算机作为大科学装置,其研发的初始目的就是为海洋、国防等科学计算领域提供算力支撑。超算平台的并行加速技术从早期的纯MPI(范培勤 等,2016)逐渐发展到MPI+X(张林 等,2017)以及MPI+X+Y(吴琦 等,2019)相结合的混合并行方式。不同超算平台一般都有各自独特的硬件架构设计,因此基于超计算机平台的海洋模型并行化设计,除需要考虑数据域分解等常见问题之外,还需结合特定模型与超算平台的硬件特性进行定向优化。如Wang等人(2005)针对ROMS(regional ocean modeling system)模型,从输入数据的区域网格大小和SGI Origin 2000与SGI Altix两种硬件平台的并发线程规模角度考虑,提供可选的1D与2D域划分技术提升并行效率。张玉娟等人(2017)分析了水声传播模型计算中的经典方案,发现深度层面的计算适合粗粒度并行,而距离层面由于存在数据依赖关系适合采用共享内存并行,结合曙光HPC(high-performance computing)具有多层次体系结构的特点,采用MPI+OpenMP的混合编程模型,提供节点间和节点内的两级并行。Córdoba等人(2014)利用向量技术实现CPU内部并行,并采用K-means和KL(Kernighan-Lin)算法对输入的网格数据进行域分解,以优化通信开销。吴琦等人(2019)研究神威超算平台上的高分辨率区域海洋模式POM(princeton ocean model)并行化加速。其采用主从并行加速思想,通过分析POM中不同模块的并行性与数据交换时机,对通信与计算开销占比进行理论分析,指导主核与从核簇的任务分配,完成线程级并行加速与MPI进程级通信操作。李镔洋等人(2018)考虑了多气候模式耦合的海冰模式超算并行加速问题。在传统MPI+OpenMP的混合并行架构设计下,进一步采用细粒度优化措施以适应申威众核超算配置,将传统基于网格的数据域分解改为按层分解以提高从核访问的地址连续性,基于压缩与预测技术动态调整主核与从核之间的数据交换频次以降低通信开销,以及根据模型中开放水面与冰层的计算负载不同分配主从核任务等,最终提升了超算平台的处理性能。
2.3.3 性能评测
计算机算力的提升取决于两个方面,即纵向角度的单体性能提升(如CPU频率、内存容量与带宽以及网卡吞吐率)和横向角度的多节点组网(如云计算集群、超算平台)。受限于硬件设计与制造工艺,前者的提升幅度一般较小,因此相关的测评工作虽然存在但关注度较低。如浪潮公司对Intel最新发布的10 nm工艺第3代至强可扩展处理器产品,从其重点改进的浮点运算速度和内存访问效率两个层面展开测试。参与测试的中尺度预报模型WRF(weather research and forecasting model)、跨尺度预报模型MPASA (model for prediction across scales)和地球气候系统模型CESM(community earth system model),属于计算密集和I/O密集型应用,因此均会从硬件工业的改进中得到性能收益。
多节点组网平台(如高性能集群和超算平台)可以突破硬件制造工艺的制约,使存储和计算能力随着节点规模的增加呈线性或近线性扩展,但跨节点通信和并行任务管理等操作会引入额外开销,故模型的实际性能收益与并行粒度之间不一定线性相关。
高性能集群评测方面,在FVCOM(finite volume community ocean model)等经典海洋模型的并行加速测试结果表明,由于存在边界信息交互,随着计算节点规模的增长,模型计算速度先上升后下降(杨宁 等,2013)。而拐点的位置则为最佳并行粒度,其具体值可通过分析模型中的并行代码比例、通信计算开销比例以及输入数据规模等因素进行理论评估,从而指导选择合适规模的计算平台,以合理的经济代价获取最佳性能收益。黄瑞芳等人(2012)从浮点运算能力、I/O与通信延迟等硬件指标和操作系统、编译优化等软件指标系统化建立了科学客观的量化评估标准,以全球中期数值天气预报模式、全球并行海洋预报模式(parallel ocean program,POP)和海陆气耦合模式(community climate system model version 3,CCSM3)为例分析不同模型的计算特征,即高吞吐数据密集与计算密集、多核并行性能与计算通信均衡性、周期性大通信与大I/O耦合,从而测试高性能集群的综合表现。先通过小规模集群测试探索应用模型对高性能集群的需求,以聚焦评测目标;然后通过变换输入数据规模、应用模型与集群配置等生成多个测试实例,利用Intel Trace Analyzer and Collector工具跟踪指标数据、提取关键参数和最终构造配置矩阵,以指导模型与高性能集群之间的匹配。
超级计算机作为集成度更高的混合架构集群系统,其物理性能的影响因素更加复杂,对相关模型的最优运行配置的挑战度更高。王天一等人(2016)以中国科学院地球系统模式CAS-ESM(Earth system model of Chinese Academy of Sciences)为例探索了其“元”超级计算平台的特性。CAS-ESM是基于CESM发展而来的耦合系统,包括可独立运行的大气分量模式(atmospheric general circulation model,AGCM)、海洋分量模式(LASG/IAP climate system ocean model,LICOM)、陆面分量模式(common land model,CoLM)和海冰分量模式(sea ice model, CICE),以及用于数据交换的耦合器。首先针对负载较重的AGCM与LICOM单独测试了最优CPU核心的2维划分组合,以区别不同模式的计算需求;然后进行系统耦合并利用硬件性能计数工具PAPI (performance application programming interface)与程序热点分析工具Intel VTune分析并行加速瓶颈,发现耦合过程的加速受通信规模的影响较大。Irrmann等人(2022)则汇集海洋、算法与计算机领域的专家共同制定测试方案,以配置文件的形式简化测试环境的构建。特别地,作者通过自行修改程序热点位置提高性能计数数据的采集精度,从而更好地指导性能调优与计算资源配置。
3 海洋多模态智能计算的主要挑战
由于海洋多模态大数据具有超大规模、超高维度和超异构性等显著特征,同时受到海水流动性、地球系统动态性和数据获取成本高等因素的影响,导致现有面向互联网等经典多模态大数据的计算技术难以在海洋领域开展有效的应用。本文将从表征建模、跨模态关联、推理预测和高效计算4个方面,提出海洋多模态智能计算的主要挑战。
3.1 在表征建模问题中的主要挑战
表征建模是计算机视觉、多媒体等领域的经典问题,在海洋场景下开展目标识别、分类、跟踪和事件/现象检测中的表征建模,其差异性和挑战主要体现在物理结构动态变化、环境噪声复杂、类内差异较大、缺少可靠标签、样本不均衡和缺少公开数据集6个方面。
1) 物理结构动态变化。海面涡旋、台风、赤潮和海面峰等现象与结构随着海水的流动持续发生较大程度的变化,并且物理结构性显著,而传统的面向语义的时空表征建模方法利用卷积、池化等操作,采用扁平化方法提取代表目标语义的显著特征,难以保留海洋现象的物理结构性。
2) 环境噪声复杂。在海面目标(例如:船舶、浮标等)识别和分类问题中,由于介质变化、光照变化和海洋拍摄条件的限制,不同摄像机捕获的图像,其背景、光照、相机分辨率和遮挡情况等存在较大差异。在水下目标(例如鱼类)识别问题中,水体中悬浮颗粒的存在和水体的连续运动导致严重的椒盐噪声,由于海水中悬浮粒子和微小的生物向不同的方向移动,导致纹理细节模糊,并且多重散射导致低信噪比,影响特征工程的开展,如图5所示。

图5 互联网获取的鱼类图像和水下摄像机获得的鱼类图像差异较大(Wei等,2018)Fig.5 The gap between fish images collected from internet and obtained from underwater camera(Wei et al., 2018)
3) 类内差异较大。海洋目标具备种类繁多但外形相似、个体差异微小等特点,导致不同种类间难以区分;同时由于环境噪声、拍摄时空变化、拍摄设备差异和视角变换的影响,又导致同一类别视觉特征差异很大。这种类内差异较大、而类间差距较小的问题,造成区分性特征提取困难。
4) 缺少可靠标签。海洋现象/过程的标注和ImageNet(Deng等,2009)对语义的标注不同,需要领域专家利用经验和知识开展。但由于海洋现象的理解和认知的难度较高,很难获得一致的标注。例如,对海洋涡旋进行标注时不同的参数方案会导致不同的标注结果。
5) 样本不均衡。海洋领域物种规模远超过陆地物种,但由于海洋探测技术的限制,很难在深远海获得物种图像,导致深远海物种样本匮乏,只有有限的标记数据可用;海洋事件/现象主要包括台风、风暴潮、赤潮和厄尔尼诺等负样本事件,相较于正样本而言极为稀疏。
6) 缺少公开数据集。目前海洋数据集大多是卫星、飞机、浮标、海底传感器和海洋探测船等设备收集的海洋观测数据,多是记录型文件,少部分为图像或文本,不仅没有标注,也存在模态较为单一的问题,导致面向海洋领域的研究方案只能基于其他领域的数据集进行实验,不利于开展公平有效的验证。
3.2 在跨模态关联问题中的主要挑战
海洋现象/事件是地球系统多圈层(陆—海—气—冰—地)耦合作用的结果,由于不同环境要素的观测要素和监测手段(水文—气象—声—光—电—磁)不同,因此,刻画同一现象或过程的数据是多态的,也是异构的。在海洋多模态智能计算中,既需要融合不同视角的多模态数据,又需要度量异构数据之间的相似性,因此需要获得跨模态数据的统一表征空间,才能在此空间中展开融合和度量。跨模态关联是跨媒体检索等领域的前沿热点问题,海洋领域的跨模态关联和多媒体领域的跨模态关联在克服“异构鸿沟”目标方面具有一致性,但又存在差异,具体表现在时空不均匀、尺度跨越大、时空约束强和关联维度高4个方面。
7) 时空不均匀。受限于海洋观测成本和传感局限,海洋环境变量的观测数据分布不均匀,一般表现为海表数据丰富、深海数据稀疏;近海数据丰富、远海数据稀疏。即存在不同程度的空间缺失,导致在统一时空下的多模态数据空间结构不均衡且差异较大。
8) 尺度跨越大。以海洋科学数据的可视化图像为例,从时间维度上,单幅图像可以表征秒、小时、日、月等不同尺度的平均数值,从空间维度上,单个像素可以表征平方厘米、平方米、平方千米、十平方千米等不同的空间尺度,在刻画某种海洋现象时,需要开展跨尺度的关联融合。以海浪为例,既需要通过白冠覆盖率(公里级)开展全局视角的能量估计,又需要结合浪花破碎过程(微米级)进行微尺度的局部细粒度建模。图6 是海洋现象/过程的时空尺度图,例如厄尔尼诺现象(EI Nino)的时间尺度约为年,空间尺度为1 000 km,而毛细波(capillary waves)的时间尺度为1 s,空间尺度为1 cm(Cronin等,2012)。

图6 海洋现象的时空尺度图(Cronin等,2012)Fig.6 Time and space scales of ocean variability (Cronin et al.,2012)
9) 时空约束强。海洋多模态数据的耦合性质会随着时空的推进产生演变,例如在不同气象条件下或不同区域检测赤潮现象需要组合不同的环境要素。因此,跨模态关联模型需要结合时空演变规律探索跨模态统一特征空间的构建问题。
10) 关联维度高。传统多媒体技术中的多模态主要表现为文本、视频、音频和图像等少数维度的特征空间,而海洋数据特征维度规模巨大,关联关系更为复杂,例如海洋水文数据包含水深、水温、盐度、水流、波浪、水色、透明度、海冰和海洋光等,海洋气象数据包含气温、压力、湿度、风速、降水、云和雾等,针对同一区域,形成了异构的空间数据场,又按照时间序列将这些空间数据场组合成数据集。随着观测技术的不断发展,特征的维度会不断增高,空间结构和关联关系也将更加复杂。
3.3 在推理预测问题中的主要挑战
实现对未知数据和知识空间进行推理和预测是海洋科学研究的重要目标之一,而这也是海洋多模态智能计算由感知向认知发展的驱动力。在目前的研究阶段,主要开展海洋知识图谱构建和数据驱动的海洋环境变量时空演变预测预报方向的研究。其中,海洋知识图谱能够取代依赖于经验法则和专家系统的分析和预测方法,在典型场景中融合知识机理和场景感知数据,打破抽象知识和场景的壁垒,而数据驱动的海洋环境变量时空演变预测预报是指通过大量时空图像序列(图7),构建端到端的深度神经网络预测模型,替代传统的机理模型或简单统计模型,进行海洋环境变量时空演变规律的预测预报。这是近年来人工智能和海洋科学交叉研究的前沿方向,经典工作发表于2019年《Nature》中,Ham等人(2019)利用海洋模式计算获得的海表面温度可视化图像序列,通过构建深度卷积神经网络预测模型,实现长达18个月的厄尔尼诺指数稳定预测,如图7所示。

图7 利用海表面温度时空图像序列和卷积神经网络进行厄尔尼诺现象的预测(Ham等,2019)Fig.7 ENSO forecasting by using sea surface temperature image sequences and convolutional neural network (Ham et al.,2019)
海洋领域开展知识建模和数据驱动的预测预报研究,主要差异体现在动态演变性、时空异质性和非独立样本3个方面:
11) 动态演变性。海洋数据本身隐含着复杂的时空过程和多元要素的动态变化。在目前的知识图谱构建方面,当前的研究热点主要集中在以三元组形式存储的知识图谱构建,对时序信息和空间属性的建模缺失会极大地限制海洋知识图谱的可用性。尤其对于一大类属性实时流变的海洋对象,虽然对实体的构建和关系构建都提供了信息,但其实体本身多时空动态演变性,无法直接体现在实体—关系的拓扑结构或属性中。
12) 时空异质性。海洋环境要素的空间分布特征不同,具有空间异质性,例如,利用近海样本构建的预测模型难以泛化至深远海区域;同时,不同季节的分布特征各异,具有时间的异质性,例如,利用冬季样本构建的预测模型难以应用于夏季的预测。因此,预测模型训练时需尽量保证数据空间的样本分布满足同质性。目前采用深度学习框架解决时空预测问题的工作,大多采用经验方法人工设定,或直接将全部样本视为统一空间,并未对该问题展开讨论。这种假设全部样本时空同质的方法会导致模型训练不收敛,难以获得有效的预测模型。
13) 样本非独立。即样本不满足独立同分布假设。在经典统计学中,抽样是独立进行的,但在海洋等地统计学中,样本之间具有空间相关性;如果按时间序列进行采样,样本之间也存在时间相关性。如果使用经典统计学进行估计,将会忽略由于样本的时空相关性造成的统计误差。
3.4 在高效计算问题中的主要挑战
海洋数据处理通常基于严谨的理论推导模型且对参与计算的各要素有严格的一致性约束,导致硬件性能的提升很难等比例转换为海洋数据处理的性能收益。因此,在高效计算中主要的挑战在于存算协同、多模型加速和巨系统测评3方面。
在跨存算协同中,现有通用数据存储架构与策略未考虑海洋大数据多维度时空关联以及海洋计算模型的语义完整性,数据存储与应用计算之间出现层次断裂,缺乏协同优化。
多模型加速挑战在于面向不同机理过程的海洋推理模型,涉及陆海气多位面要素的复杂整合,计算特征异构,且不同硬件平台属性差异显著,导致已有串行代码的并行加速过程在通信、负载均衡和异步计算等角度面临不同挑战,难以实现算力的高效利用。
在巨系统测评中,模型与算力之间实现协调匹配是一个巨大而重要的系统工程问题,而如何设计测评方式以保证结果的可靠性具有很大的挑战性。
4 海洋多模态智能计算展望
4.1 海洋多模态大数据内容分析方面
4.1.1 构建海洋领域目标/现象识别的公共数据集
海洋领域目标和现象的识别对认识海洋、经略海洋和保障海洋安全具有重要的意义,但当前已公开相关数据集较少,只有一些水下目标(鱼类等)、水面目标(船舰)的数据集,极大地限制了海洋多媒体内容分析领域的发展。随着海洋观测及信息技术的发展,目前已可获得大量的海洋领域的多媒体数据,包括卫星遥感数据、浮标数据等,构建可公开下载的海洋领域目标/现象识别数据集将会是推动该领域发展的加速器。
4.1.2 海洋领域的无监督和小样本学习
由于海洋领域的标注通常需要专业背景知识,比如中尺度涡等,对标注人员有较高的要求,大规模的数据集通常不容易获得,因此,无监督学习和小样本学习将是是海洋多媒体内容分析的发展趋势之一。在通用多媒体内容分析领域,无监督学习和小样本学习已取得了一定的进展,在一些特定领域,取得了与有监督学习相当的准确率,但在大部分领域,无监督学习与有监督学习的准确率还有一定的差距,因此,未来海洋多媒体内容分析可从以下两个方面开展研究:新的无监督学习和小样本学习方法,研究无监督学习和小样本学习本源问题,提高其性能;将无监督学习和小样本学习与海洋领域特点相结合,提高其在海洋多媒体内容分析中的性能。
4.2 海洋多模态大数据推理预测方面
4.2.1 多视角多关联的海洋时空聚类
现有数据驱动的海洋环境预测预报问题大都忽略了样本的独立和同分布假设。针对时空预测建模对样本同质性需求,在多尺度融合和多视角协同的场景下,研究时空聚类方法。将环境变量在空间和时间维度上的数值看做按照时间排序的图像序列后,提升了输入数据的维度、尺度和多元性,可以提升预测模型的高维感知能力,但也给时空聚类带来了挑战,因此,需要提升应对高维多尺度复杂关联的能力,更需要能够在不同视角下衡量多种关系。首先,研究多元多尺度融合的时空相似性度量方法,刻画复合效应下的样本距离;其次,开展多视角时空异常识别方法,充分发挥多视角协同在时空异常识别中的优势;最后,研究多视角多关系时空聚类方法,研究如何融合多尺度相似性度量和多视角异常度量构建距离函数,实现时空聚类的方法。
4.2.2 适应对象时空演化的跨模态海洋知识图谱构建
包括多模态海洋知识自动抽取、跨时空维度的海洋知识过程建模和海洋知识图谱动态更新,打破传统知识图谱用于现实场景的诸多限制,为属性实时流变的海洋对象分析和预测提供了可能。针对海洋科学知识的特点,开展支撑多时空尺度和多层次结构的知识表示研究,设计时间过程、位置过程、属性过程识别及其动态链接方法,提升预测的精准性。开展支撑跨模态协同的可扩展近似推理机制,结合深度学习、一阶逻辑和概率图模型优势,实现海洋大数据与大知识的语义统一、动态融合、智能推理和全局预测。
针对海洋现象表观知识具有极强的时空过程性和动态性要求,考虑设计融合时间和空间维度的动态知识表示框架,如图8所示。具体地,海洋现象由一种按照时间先后顺序采集时空过程状态组成,可以视为一个过程时空序列,首先研究海洋现象的时间过程、位置过程和属性过程的识别策略,设计时间过程域、空间过程域和事件域与时序链接之间动态关联生成方法,通过表达时间域、空间域和时空实体域之间的链接,形成海洋时空过程知识图谱。在此基础上,研究基于时序和空间约束随机游走的连续时间动态图谱嵌入表示模型,捕获实体、属性和关系的潜在生成过程及其内在演化现象,通过动态确定短期或者长期有代表性的历史拓扑结构捕获新增知识的语义特征,采用融合注意力机制的图神经网络模型获取新增知识的嵌入表示。

图8 时空演化跨模态海洋知识图谱构建Fig.8 Spatio-temporal evolutionary cross-modal ocean knowledge graph construction
4.3 海洋多模态大数据的高性能计算方面
目前海洋模型与高性能计算交叉融合仍处于初级阶段,主要关注传统串行代码到高性能计算平台的可移植问题,而深层次的性能优化尚未展开,尤其是计算机领域最新并行加速技术与海洋模型的深度融合。目前海洋高性能计算的并行加速的瓶颈主要是通信开销,而计算机领域中的新型的流式分割、点割和点边混合分割等技术均衡分配计算负载并减少通信开销。此外,海洋模型通常需要反复处理输入数据,这与计算机领域的迭代计算极为相似,而后者已有大量关于通信约减(如以块为中心的计算、通信消息合并)和迭代收敛加速(如异步计算、优先级计算)的研究工作,但由于领域跨度较大,上述最新技术并未及时应用到海洋高性能计算。在高性能计算评测中,现有的研究背景是给定高性能计算平台,然后讨论所用模型的并行化加速实现,较强的领域专业性导致相关的评测工作很难展开。未来,根据已有硬件平台选择合适的模式计算,或根据模式计算特征选择硬件平台、甚至指导硬件平台的建设与研发,将成为可能。
5 结 语
本文从海洋多模态数据技术的角度出发,首先介绍了面向海洋现象/过程的智能感知、认知和预知的交叉研究进展。从海洋多模态大数据内容分析、推理预测和高性能计算等角度系统地分类和回顾了现有的具有代表性的工作。之后总结提出了海洋多模态大数据表征建模、跨模态关联、推理预测和高性能计算4个关键科学问题中的挑战,最后提出了海洋多模态智能计算关键科学问题的发展展望。
海洋多模态数据智能计算技术通过海洋多模态数据进行融合、交互、分析、推理和决策/预测,有助于实现海洋机理、规律的进一步认知与发现,提升海洋领域专家的理解水平。本文最终希望可以为海洋多模态智能计算在海洋领域的进一步应用提供理论支撑,同时为海洋领域相关工作者提供实际参考。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年9期)2022-05-20
四川党的建设(2022年8期)2022-04-28
作文大王·低年级(2018年10期)2018-12-06
成长·读写月刊(2018年8期)2018-08-30
琴童(2017年7期)2017-07-31
小学科学(2017年5期)2017-05-26
小猕猴智力画刊(2016年8期)2016-05-14
小猕猴智力画刊(2016年5期)2016-05-14
计算机辅助工程(2012年5期)2012-11-21
