
面向数字人文的典籍语义词汇抽取研究
——以SikuBERT预训练模型为例*
2022-09-23 00:58孙文龙张逸勤王凡铭鱼汇沐刘江峰王东波
图书馆论坛 2022年10期
孙文龙,张逸勤,王凡铭,鱼汇沐,刘江峰,王东波
0 引言
2020年11月教育部新文科建设工作组发布的《新文科建设宣言》指出,融入现代信息技术赋能文科教育,新文科建设势在必行[1]。近10年数字人文在推动古文信息处理研究迈向交叉研究道路上发挥着重要作用,成为新文科建设的热门话题,为人文学科拓宽问题域,实现研究范式创新与重构人文知识脉络提供了契机[2-3]。
在大数据时代,信息之于读者阅读需求的可得性(Availability)和可及性(Accessibility)均得到空前提升,这与关键词抽取技术的快速发展有着密切关系。关键词是文章主旨的高度凝练,代表特定文献的主题内容,是人们在阅读、研究文献内容时快速判断是否需要精读的重要线索。另外,在人们无法快速获取文本关键内容时,关键词抽取还可以帮助其节约时间。在现代汉语文本中,关键词抽取技术已经相对成熟,但古汉语文本相关研究仍处于起步阶段。我国古籍浩如烟海,承载着中华优秀传统文化。因此,利用好关键词抽取技术并对古籍进行整理研究,意义重大。一方面,古籍关键词抽取可以帮助读者快速了解古籍文本的核心内容;另一方面,该技术还可应用于古籍分类管理,为古籍电子化平台提供信息检索、在线查阅、知识关联等服务。在新文科建设背景下,以数字人文研究为抓手,探索关键词抽取技术在古汉语文本中的实践路径,有助于降低古籍文献阅读门槛、普及古汉语知识。
1 相关研究
近年随着深度学习技术及预训练语言模型发展,研究者开始关注面向数字人文的古籍文本自动处理问题,基于BERT模型框架,构建面向古文智能处理任务的SikuBERT预训练语言模型的系列研究具有较强的代表性。王东波等基于BERT模型框架,以《四库全书》全文语料作为无监督训练集,提出构建“SIKU-BERT典籍智能处理平台”设想,论述了该预训练模型较强的古文词法、句法、语境学习能力和泛化能力[4]。其后涌现一批以SikuBERT预训练模型为例,专门探讨进一步提升古代典籍的自动分词、词性自动标注、典籍分类、摘要自动生成、典籍命名实体识别效率的系列研究,通过相关实证实验研究从多维度探索SIKU-BERT典籍智能处理系统的发展和应用前景[5-9]。然而,在古文典籍关键词提取方面,尚未有验证SikuBERT预训练模型的适用性及应用前景的研究。
在关键词自动抽取研究方面,自Luhn提出基于词频的关键词自动抽取方法以来[10],经过60多年发展,关键词自动提取方法已经衍生出众多类别,大体可分为两类:基于无监督的方法和基于有监督的方法[11]。从现有研究看,以采用TF-IDF 算法、LDA 主题模型和图模型TextRank算法3种无监督方法的研究为主。
TF-IDF是被广泛用于自然语言处理领域的经典算法,具有简洁易实现的特点,对字词或短语具有很好的分类能力。国外的该算法研究起步早。Salton等针对文本中词语重要性问题,提出用来评估一个词对一个文本集合中某一文本的重要程度的TF-IDF 算法[12]。Basili 等提出的TF*IWF*IWF算法提高了特征词在文档集合中的权重,一定程度上解决了逆向文档频率没有考虑特征项分布情况的问题[13]。Bong 等提出利用CTD来改进TF-IDF,以改善不同类别的文档数引起的误差[14]。国内研究集中在改进TF-IDF算法对现代汉语各类文本的处理能力。许晓昕等提出以主题方式缓存历史来提高TF-IDF算法对聊天文本的处理能力[15];张建娥探索融合词语关联度的TF-IDF改进算法,避免TF-IDF在汉语关键词抽取上产生的偏差[16]。国内外对LDA模型的研究集中于主题挖掘、社交网络分析等领域。Zhao等构建可同时对用户和文本进行主题建模的Twitter-LDA 模型,提高文本数据分析准确性[17];Wang 等考虑到网络文本随时间变化特点,提出基于时间的变迁主题模型,用于对网络文本的主题挖掘[18];陈晓美等分析LDA主题模型从海量网络评论中提取舆情观点的优势及路径[19];陈嘉钰等利用LDA主题模型和文本挖掘方法探讨微信用户倦怠的潜在主题[20]。较之上述两种算法,TextRank 在文本处理领域应用更广泛,计算速度较快,通过构建词与词之间的逻辑分布矩阵来抽取文本关键词,是一种有向有权的图模型。Rahman等将用户搜索喜好作为特征,基于TextRank算法完善搜索系统的识别和定位功能[21]。张莉婧等设计改进TextRank-CM 算法,该算法在现代汉语文本关键词自动抽取方面的性能表现良好[22]。赵占芳等的发现与之类似,较之经典的TextRank和TF-ID算法,改进后的TextRank关键词抽取算法在准确率、召回率及F值上均有显著的提高[23]。
综上所述,在现代汉语文本中,关键词抽取技术研究及其应用已较普遍,但针对篇章相对短小、单字词较多的古汉语文本而言,关键词抽取技术的研究才刚刚起步。近5年虽然学界对古汉语研究中关键词抽取技术的关注逐渐增多,但仍不足以挖掘和有效呈现古汉语丰富的知识价值。在中国知网中,能够检索到的直接以古籍关键词抽取技术为主题的研究仅有1篇[24]。该研究基于关键词抽取的3 种无监督方法,对数字化后的《春秋经传》进行关键词抽取,对比分析关键词的分布情况和抽取效果后发现,TextRank算法明显优于其他两种关键词抽取算法,更适用于针对古汉语典籍的关键词抽取研究。在古籍关键词抽取技术研究领域,该研究具有一定的补白性。然而,TextRank算法对分词结果有很强的依赖性,即:如果某词在分词时被切分成两个词,那么在关键词提取时,TextRank仅有部分黏合效果,且要求这两个词均为关键词。因此,是否添加标注关键词进行自定义词典,会导致关键词抽取结果在准确率、召回率的评估方面出现大相径庭的情况。此外,TextRank模型虽考虑到了词之间关系,但仍具有抽取高频词作为关键词的倾向性。与TextRank算法相比,深度学习模型存在无需预先对语料文本进行分词等优越性,该算法模型在古文关键词抽取研究领域具有较大的应用前景,值得进一步探索。鉴于尚未有基于BERT模型来提取古文关键词的相关研究,本文采用SikuBERT模型对先秦两汉的古文典籍进行关键词抽取,选择具有代表性的“儒家”“史书”两个子类别古籍作为分析对象,通过对预训练模型所抽取关键词的文本相似度的分析,探讨SikuBERT模型在古汉语文本关键词抽取任务中的技术实现路线与应用前景。
2 实验设计与流程
2.1 预训练模型选取
本实验采用模型为南京农业大学、南京师范大学团队基于《四库全书》语料训练得到的SikuBERT模型。与Google开发的BERT模型相比,该模型在训练方法的深度、掩码方式的有效性、输入表示的全面性等方面均展现出更出色的性能。SikuBERT模型已在古文领域的分词、断句、词性标注、实体识别等任务上得到了实际应用,取得了预期中的实验效果,为本研究的开展打下了前期研究基础。本研究的实验框架包括3个部分,见图1。

图1 词汇抽取实验框架
2.2 数据描述
典籍语义词汇抽取任务中的SikuBERT预训练模型训练语料来源于网络资源“中国哲学书电子化计划”网站①。该网站提供中国历代传世文献,收藏的古籍文本超过3 万部,文本质量较高,包括中文善本特藏项目中的高质量影印本(如收录的燕京图书馆500多万页历代中文文献的影印资料)。该资源站包括“先秦两汉”“汉代之后”两大数据库,每个数据库下又分设按不同标准建成的子库。前者依据研究主题细分为13个子库:儒家、墨家、道家、法家、名家、兵家、算书、杂家、史书、经典文献、字书、医学、出土文献;后者按照时间顺序构建魏晋南北朝、隋唐、宋明、清代、民国5 个子库。本实验下载“先秦两汉”全文数字资源作为SikuBERT预训练模型的数据来源。依据“先秦两汉”数据库大规模语料的预训练任务完成后,为确保最终训练模型的准确性,选取“儒家”“史书”两个子数据库作为SikuBERT预训练模型下游任务中的语料来源。“儒家”语料库包括26部古籍②,“史书”语料库包括19部古籍③。两类语料在先秦两汉典籍中占比大,影响力强,具有作为实验训练语料的适宜性与合理性。其基本信息及语料样本分别见表1和图2。

表1 实验语料的基本信息

图2 语料样本
2.3 实验流程
(1)获取文档向量。SikuBERT模型以字为单位对输入的中文序列进行分词,通过模型内置的中文字典将字符映射为数值序列。例如,当模型读入“风者何谓也?风之为言萌也……”序列时,序列先被模型按字符为单位进行分割,再为每句添加起始标记[CLS]和终止标记[SEP]。通过标记特殊标志位,原始文本被转换为输入序列“[CLS],风,者,何,谓,也,[SEP]……”然后模型将自动结合每个字在词表中相对应的索引值原字符生成词向量,同时结合词在句中的位置向量与表示句子类别的分段向量,使得组合向量满足后续实验任务的需求。
(2)过滤停用词。研究选取的基础停用词表是包含1,753个词汇的现代汉语停用词表,包括数字、符号、标点和无实际意义的词汇。鉴于研究对象为古汉语文本,在现代汉语停用词表基础上,根据齐夫定律对“史书”语料进行词频统计,将出现频次超过1,000次的词汇认定为高频词。从高频词与停用词之间的关系看,高频词并不等于停用词。停用词多为副词、助词、虚词、代词等,如“之”“乎”“者”“也”“而”“无”等没有实际意义的词汇。经过逐一校对筛选,最终确定将107个词频虽高但不具有实际意义的词语列入停用词表。之后利用算法,在模型读取时自动去除文档中包含的停用词,降低对最终关键词抽取结果影响。
(3)关键词抽取。此步骤需从文档中创建一个关键词或关键词列表,词语长度根据具体实验进行调整。因古汉语单字的单音节性和多义性,将关键词长设置为1(即单字),暂不考虑双音节词或其他类型词语作为关键词的情况。在抽取方法上,采取基于BERT的Tokenizer方法来实现对文档中的词进行向量表达。该方法具有表达能力强、保留原字词特征等优点,与N元语法词、词袋模型等方法相比,注重对上下文语境信息和一词多义等问题的处理。
(4)相似度计算。文本相似度是预训练模型计算关键词之于所抽取文档的代表性数值指标。采用SikuBERT模型的古汉语典籍关键词抽取实验不同于TF-IDF、LDA主题模型等常规的机器学习算法,其差异点主要体现在关键词抽取方式上,即:SikuBERT模型不是基于词语的出现频次,而是通过词向量与文档向量的相似度比较结果来确定。
依据上述步骤,在获取文档的篇章向量及候选词向量后,再通过余弦相似度算法依次计算出词语向量与文档向量的相似度,按降序排列,选取相似度最高的20个词作为最终的抽取关键词。
3 实验结果分析
3.1 模型抽取效果评估
在现代汉语文本关键词抽取任务中,传统机器学习方法的应用已有不俗表现,但大多数技术路线对复杂的先验知识有着较高要求。例如,在利用词汇特征时,过度依赖分词精度会导致分词错误、词性错误、停用词错误,影响关键词抽取结果的信度。有学者指出,由于古汉语在词法、句法和语法等方面与现代汉语存在较大差异,将适用于现代汉语的关键词抽取技术直接迁移至古文文本会产生适用性差与精确性无法保证的缺陷[25]。本研究采用的SikuBERT模型是将繁体汉字无注释与标点版《四库全书》作为训练语料得到的预训练语言模型。由于BERT模型的基础框架具有双向transformer编码器结构的特性,SikuBERT模型在词向量的训练中能够最大程度地保留古汉语文本的原始特征,从而使关键词抽取实验过程能够摆脱训练文本分词质量的限制。在利用SikuBERT模型对先秦两汉时期的“儒家”“史书”语料进行关键词抽取后,选择排序最高的前20个词作为最终结果。实验结果表明,SikuBERT预训练模型能够较好地适应古汉语文本篇章短小、单字词多的语言特征,关键词抽取结果大体上反映了相关文本内容的主题特征。
3.2 儒家典籍关键词抽取结果分析
本研究对SikuBERT模型提取出的前20个儒家典籍关键词依次进行语境共现排序(见图3),从关键词所反映的主题内容看,可以将其分为4类:一是为政类,包括:王、人、废、下、民、乐、道、尊、世、士;二是修身类,包括:言、身、改、养、长;三是人与他者关系类,包括:虫、物;四是其他类,包括:子、为、卫。从模型“相似度”计算结果看,上述关键词与所抽文本的相似度介于76%~78%,较好地反映了先秦两汉儒家典籍的主题内容。
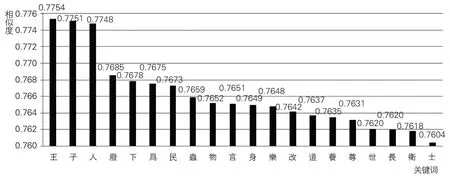
图3 儒家典籍关键词抽取结果
第一类关键词与儒家治国理政思想密切相关。从“王”(6,698次)的语境信息看,语境分布大致分为两大类:以“圣王(或先王)”或是以“楚王、魏王、齐王、秦王、晋王”等为代表的君主。与前者相关的主题以颂扬尧、舜、禹、商汤、周文王和周武王的仁德为主,与后者相关的主题多探讨先秦诸侯或君王“德”“位”匹配情况。虽然叙事视角不同,但两个主题围绕着一个共有内核,即王道政治。孔子所讲“先王之道,斯为美,小大由之”(《论语·学而》),孟子建言梁惠王等所效法的“王天下”之道(《孟子·梁惠王下》),以及荀子论述的“王者之人”“王者之制”“王者之论”“王者之法”4个概念,共同构成一条理解儒家王道思想的线索。其他9个关键词均与“王”字所揭示的主题有着直接或间接的联系。具体而言,“人”字多出现在寡人、人君、人臣、庶人、贤人、仁人、人心、择人、取人等语境中,话题多与君臣关系和用人之道有关;“人”还较多地出现在周人、殷人、秦人、齐人、楚人、燕人、晋人、鲁人、宋人、郑人等语境中,通过对各国外交、军事和民风等方面的评述来说明治国之道。“废”的语境共现信息虽然偏少(414次),但其是唯一一个从反面来揭示儒家王道理想的关键词。例如,“长幼之节”“君臣之义”的伦理纲常不可废(《论语·微子》),刑罚和庆赏不可废(《中论·赏罚》),礼乐不可废(《荀子·乐论》),王道不可废(《新书·过秦中》)。这可能是SikuBERT模型提取该字作为关键词的重要原因。“下”的语境共现信息有5,783次,近一半出现在“天下”语境中,另有较多的语境与“序上下”有关,如“君臣上下父子兄弟,非礼不定”(《新书·礼》)、“明别上下之伦”(《春秋繁露·度制》),均与君臣之礼和教化民众有密切关系。其他几个关键词的主要语境信息也均与儒家倡导的王道政治相关:“民”与儒家民本思想有关;“乐”多与始自夏商的礼乐制度相关;“道”的语境共现信息较多体现了“天道”“先王之道”(或“王道”)方面的内容信息;“尊”较多地出现在尊王和尊上的语境中;“士”的语境分布最为集中,主要围绕“何如斯可谓之士矣?”(《论语·子路》)这一问题展开,体现了春秋时期的尚士传统;“世”的语境多与王道的传承有关。篇幅所限,上述几个关键词不再逐一展开论述。另外,值得注意的是,10个关键词并不是孤立存在的,相互之间存在着或多或少的联系,其中“王”起着提纲挈领的作用,其他9 个关键词各有侧重,可以从不同方面揭示儒家王道思想的内涵。
第二类关键词与个人修养有关。在此类5个关键词中,从数据看,“言”“身”的语境共现频次最多,分别为5,369次和1,837次,与总文本的相似度也分列第一、二位,均接近76.5%,较之其他几个关键词,体现出“言”“身”在该类关键词中的统摄地位。具体而言,常与“言”共现的字词有“信、行、礼、德、仁、君子、笃敬”等,主题思想是做人要多做实事,少讲空话,这是君子的立身之本之一。“身”字则对古人的身心修养之道做了多维性描述。该字常出现在“察身、省身、修身、治身、正(其)身、为身、身行、身正”等语境信息中,明显体现出古人对正身修德的重视,相关例证在《论语》《春秋繁露》《潜夫论》《韩诗外传》《新序》《荀子》等典籍中均有较多体现。“改”字的语境信息较少(417次,在该类5个关键词中出现频次最低),但其是唯一一个从反面来体现儒家对修身立德的态度,即“过则勿惮改”(《论语·学而》)与“过而不改,是谓过矣”(《论语·卫灵公》),这与“身”字所体现的主题之一“自省”是相照应的。“养”“长”均与儒家所倡导的伦理道德规范相关。“养”与孝道有较大关联,如“今之孝者,是谓能养。至于犬马,皆能有养。不敬,何以别乎?”(《论语·为政》);“长”主要指“长幼之序”,与“君臣之义”“父子之亲”“夫妇之辨”(《说苑·贵德》)共同构成了儒家伦理思想体系的要义。
第三类关键词较多体现了人与他者的关系。在儒家的三维哲学中,“天一,地二,人三”是最常见的思维方式。SikuBERT 模型提取的“虫”“物”两个关键词集中体现了该类内容主题。“虫”字的语境信息主要出现在《春秋繁露》(“五行逆顺”篇和“治乱五行”篇)、《大戴礼记》(“夏小正”“易本命”“曾子天圆”篇)、《论衡》(“商虫”“物势”“无形”“顺鼓”“遭虎”“龙虚”“感虚”“别通”篇,“商虫”篇中最多)、《孔子家语》(“执辔”篇最多)、《礼记》(“月令”篇最多)中,其他儒家典籍中也有部分语境信息(如《说苑》“辨物”“修文”篇)。在上述篇目中,“虫”是儒家“考日月星辰”与“知幽明之故”的通达路径之一,因为在他们看来:“万物鸟兽昆虫,各有奇偶,气分不同,而凡人莫知其情,唯达道德者能原其本焉。”(《孔子家语》“执辔”篇)。“物”字的语境共现信息能够反映出儒家对外部世界的基本看法,也体现了改造外部世界的实践取向。“物”的初始含义是“大共名也”(《荀子·正名》),即物是一个最大的类,作为“自我”的人和“他者”的非人都在其内。但在具体讨论人与世界关系时,往往要将二者剥离开来。例如,《大戴礼记·诰志》中讲到“天生物,地养物,物备兴而时用常节曰圣人”,就是从天地人的三维哲学观来探讨其对物的理解。整体看,儒家对“物”持较为中庸的看法:一方面承认人主观能动性的有限性,赞同“善假于物”(《荀子·劝学》)的实践方式,另一方面又从德化角度对人的物欲进行约束,如孟子所提及的“亲亲而仁民,仁民而爱物”。
第四类关键词在揭示儒家典籍内容主题方面呈现出一定的离散性,故将之归入其他类。首先,“子”被抽取为关键词的一个重要因素在于其语境信息频次较高(20,565次)。该字主要出现在“子曰”(3,299次)、“孔子”(2,772次)、“君子”(2,578 次)、“天子”(1,774 次)、“夫子”(653 次)、“孟子”(436 次)、“曾子”(471 次)、“之子”(339次)、“父子”(240次)等语境中。显然,造成“子”指代多样性的主要原因与本研究仅提取单字词有着直接的关系。其次,“为”字被提取为关键词的原因更为复杂:一方面该字的语境信息频次较高(13,747 次),另一方面读音、词性和用法多样,导致一词多音多义问题,SikuBERT模型无法处理此类问题。例如,“为”读wéi时,仅用作动词时就包含多个含义:“见义不为,无勇也”(《论语·为政》)中意为“做、干”;“为政以德”(《论语·为政》)中作“掌管、治理”。同时,“为”还用作连词和语气助词。再考虑到其读wèi,作动词(言说、告诉)和介词(因为、由于)的用法时,SikuBERT模型在提取古文关键词时面临的情况会更加复杂。因此,尽管“为”字所展示的儒家典籍主题内容并不明确,但受上述两个方面的影响,SikuBERT模型仍将其识别为儒家典籍关键词。“卫”的语境信息相对单一,近90%语境信息与卫国有关。该字被抽取为关键词的一个主要原因可能在于其与孔子的关系较为密切。公元前497年,孔子55岁,开始周游列国,第一站便是卫国;孔子周游在外14年,近一半时间居住在卫国,卫国之于孔子的重要性不言而喻,这从《论语》记载的许多与卫国有关的事例即可管窥一二。如“鲁卫之政,兄弟也”“富之”“教之”(《论语·子路》)、“吾未见好德如好色者也”(《论语·子罕》)等均与卫国密切相关。
综上,上述4类关键词中,前三类能够大体展现出先秦两汉儒家典籍的主题内容,第四类仅能为读者提供一些了解儒家典籍的认知线索,在揭示主题内容方面呈现出明显的离散性。究其原因,这一方面与部分古汉语字词语义和用法的复杂性有关,另一方面也与SikuBERT模型仅抽取单字词的人文计算方法相关。
3.3 史书典籍关键词抽取结果分析
通过逐一检索图4 中关键词的语境共现信息,依据其揭示的内容主题,可将20个史书典籍关键词大致分为五类:国别史类,包括:卫、吴、曹、梁、魏、赵;皇族类,包括:公、王、长、立、元、宫、家;军事类,包括:武、击;历史人物类,包括:子、厉、樊;其他类,包括:为、皆。上述关键词与所抽史书文本的相似度为74%~78%,整体上略低于前文SikuBERT模型有关儒家典籍文本的相似度计算结果。究其原因,这可能与儒家典籍的主题多与抽象的理念相关(如治国和修身),文本主题思想相对一致;相比之下,先秦两汉时期的史书文本所载内容更为具象,历史事件常与某一国家、某一时期或某一特定人物紧密联系在一起。因此,史书类关键词所展现的内容主题也具有更大的离散性。

图4 史书典籍关键词抽取结果
第一类关键词主要展现春秋战国时期部分诸侯国的历史。在20个关键词中,“卫”与文本的相似度最高(约78%)。一方面,从语境信息分布看,这可能与“卫”的主题内容相对集中有着较大关系。该字语境共现信息共计2,441条,其中约80%语境与卫国相关。例如,卫君、卫侯、卫公、卫世子蒯聩、卫灵公、卫穆公、卫缪公、卫定公、卫恒公、卫孙良夫、卫世叔齐、卫公孟彄、侵(围)卫、卫地、卫人、卫师(兵)等,内容主要涉及卫国的政治、军事和外交。另一方面,从卫国兴衰看,这也可能与其特殊的历史地位有关。卫国是周朝姬姓诸侯国之一,从立国至灭国出现41位国君,共计907年。在强敌环伺的春秋战国时期,卫国多次躲过灭国之险,可谓国运多舛,这在先秦史书中有较多记载。例如,成候三年(公元前372 年),赵国“伐卫,取乡邑七十三”(《史记·赵世家》);怀君三十一年(公元前254 年),“魏囚杀怀君”(《史记·卫康叔世家》)。卫国一直生存到秦二世时期:“始皇既并天下,犹独置卫君,二世时乃废为庶人”(《汉书·地理志》)。卫国是周朝姬姓诸侯国中最后被秦灭亡的国家,这既是奇迹,也反映了先秦时期的政治生态——军事上弱肉强食,道统上宗周为正。卫国虽小,却成为春秋战国时期大国之间博弈的重要棋子,这可能是“卫”这一关键词与文本相似度最高的主要原因之一。其他几个关键词的语境信息分别如下:“吴”主要与《越绝书》《吴越春秋》《国语》中的《吴语》《越语》相关,反映的主题集中在吴越地区的政治、经济和军事方面,尤其是吴越争霸的史实最丰富。“曹”语境约有40%与曹国相关,集中在《春秋谷梁传》《春秋公羊传》两部典籍,主要共现语境关键词有(围)伐曹、救曹、入曹、过曹、灭曹、曹师、曹人、曹叔振铎、曹伯、曹伯阳等,主题内容反映了统治集团如何利用礼义教化和宗法情谊来缓和内部矛盾。“梁”语境有近三分之一出现在《战国策》《史记》中,梁国自建国到灭亡仅130年,是春秋战国时期诸侯割据一方、战事纷争不断的缩影。“魏”字的语境共现信息共3,013条,约83%与魏国相关,集中出现在《战国策》《国语》《史记》《汉书》四部典籍中。从其反映的主题内容来看,魏国与春秋战国时期的各个国家几乎均有交集,《战国策》中有关魏国的记载就是一个典型例证:在该典籍中,“魏”主要出现在东周策(一卷)、西周策(一卷)、秦策(五卷)、齐策(五卷)、楚策(四卷)、赵策(四卷)、魏策(四卷)、韩策(三卷)、燕策(三卷)、宋卫策(一卷)和中山策(一卷)中,涉及《战国策》三十三卷中的三十二卷。此外,《史记》中有关魏国记载的《魏世家》《晋世家》《卫康叔世家》《周本纪》《秦本纪》《魏公子列传》《苏秦列传》《春申君列传》《商君列传》等则是另一佐证。简言之,魏与周、晋、齐、楚、燕、韩、赵、齐、秦、宋、卫等国之间的关系得到充分展示。与“魏”相比,“赵”字的语境信息更加丰富(4,444次),约78%信息与赵国有关,但涉及的主题内容不如“魏”广泛,更多地集中在“赵”与晋、楚、齐、韩、魏、燕、秦之间的关系上。
第二类关键词表明先秦历史较多关注皇族政治和宫廷生活。“公”主要指王朝大臣或诸侯,如卫灵公、秦惠公、齐景公。“王”是诸侯在其封地的称号,如越王勾践、定陶王、秦昭王、楚成王。“长”语境共现信息多与官职名有关,如左庶长、长史、丞长、礼乐长、署长。“立”较多出现在立君、立为王、立皇后等语境中。“元”多用在年号或纪年、诸侯谥号等语境中,如元帝庶孙、元延四年、永建元年、许元公。“宫”多与宫廷生活相关,如太子之宫、长信宫、内宫、东宫、后宫。“家”是和“国”相对应的一个概念:先秦时期诸侯的封地为国,大夫的封地称家。从“家”语境共现信息看,语境多出现在皇家、世家、汉家、太子家、王家、国家等语境中,《史记·班彪列传上》中所述“都都相望,邑邑相属,国藉十世之基,家承百年之业”可以说是对先秦史书中“家”概念的最好注解之一。
第三类关键词以“武”“击”为代表,展现先秦时期(尤其是春秋战国时代)各诸侯国之间相互征伐的军事活动,以及汉朝时期抗击匈奴的战争。例如,武王克殷、扬武将军、武威将军、武夫、扬威武、击韩之新城、击秦、击赵、击楚军、击匈奴、击汉军、击杀。《竹书纪年》记载了夏朝至战国时期所发生的血腥政变和军事冲突,即使是在周王朝所奉行的礼治时代,军事征伐也是主题,如《穆天子传》前五卷详述周穆王率师南征北战盛况。《越绝书》《逸周书》《吴越春秋》《国语》《战国策》等典籍中所记载的君权之争、诸侯争霸、强国谋略和战争过程等内容更加丰富。
第四类关键词与先秦两汉时期的著名历史人物有着密切的关系。“子”的语境共现信息多达25,630 次,集中在天子、太子、弟子、臣子、父子、孔子、子曰等语境中,其中与孔子相关的语境信息最多(2,253 次),这一点与前文中“子”在儒家典籍中也被抽作关键词的情况有相似之处,其原因可能有两点:一是儒家典籍与史书典籍存在交叉之处,如《春秋谷梁传》《春秋公羊传》既属于儒家典籍,也可划入史书范畴;二是先秦两汉时期的正史与儒家思想有着密切关系,“孔子”是两者耦合的一个关键节点,即时常通过引用孔子的言论以达到针砭时政的目的,如《史记·酷吏列传》中的“孔子曰:‘导之以政,齐之以刑,民免而无耻。导之以德,齐之以礼,有耻且格’”。《汉书·地理志》中的“繇文翁倡其教,相如为之师,故孔子曰:‘有教亡类’”等均为典型例证。“厉”和“樊”的语境共现信息偏少,前者有651 条信息,后者仅389条。从语境分布看,“厉”有123条语境信息有明确指代,即周厉王,其他语境信息较分散,尚无明确的主题。在先秦史中,周厉王是处于历史转折期的关键人物之一,周王室自其始逐渐走向衰微,多数史书均有记载。例如,“下至幽、厉之际,朝廷不和,转相非怨,诗人疾而忧之曰:‘民之无良,相怨一方’”(《汉书·楚元王传》)。“樊”字有约88%的语境信息作为姓氏,如樊姬(楚庄王夫人)、樊迟、樊哙、樊丰、樊于期、樊陵、樊崇、樊稠、樊鯈、樊宏、樊晔、樊重、樊准等,其中有关樊哙的描述最多,占到全部语境信息的三分之一(113条)。此外,对樊鯈开创的“樊侯学”,参与荆轲刺秦的樊于期的着墨也较多,以历史人物为触角,生动展示了先秦两汉时期的历史画卷。
第五类关键词未能展示先秦和两汉时代的历史特点与社会风貌,“为”和“皆”被抽取为关键词的重要原因在于其多义性和常用频次高。“为”的语境共现信息共计36,052条,其信息量在20个关键词中位居首位,但该字词性和语义多变,如作动词时具有“种植,耕作”“以为,认为”“掌管,治理”等含义,还常用作连词(和,表示并列关系)、助词(的,用于名词性偏正结构中)、介词(被)。这与“为”在儒家典籍中被抽为关键词的原因相同。“皆”的语境信息多达7,610条,意义较单一,绝大多数用作副词,意为“都(是),一同”。简言之,以“为”“皆”为代表的多义词,具有搭配能力强、使用频次高的特点,目前SikuBERT模型尚不能有效识别和处理该类字词。另外,现阶段亦无专门针对古文的停用词表,这也是造成“为”和“皆”被模型识别为关键词的另一重要原因。
从上述分析看出,利用SikuBERT模型的儒家和史书典籍关键词抽取结果既存在明显差异,也呈现出相似之处。相似之处主要体现在二者存在一些共同关键词——王、长、子、卫、为。其中,“子”“卫”在两类典籍中的语境共现信息基本相同,均与孔子和卫国相关,展现了孔子思想的影响力和卫国在春秋战国时期的特殊历史地位。“王”和“长”的语境信息则各有侧重:在儒家典籍中,“王”与先王之道的王道思想密切相关,“长”多与“长幼之序”和“尊长”的儒家伦理有关;在史书类典籍中,“王”和“长”的语境信息更侧重于展现较为具象的皇族生活和官场体制。“为”字因其词性多变、语义复杂和搭配能力强的特点,虽然在两类典籍中均有大量的语境共现信息,但并未有效揭示主题内容。
4 结论与展望
将关键词抽取技术应用于古汉语典籍研究中不仅可以拓宽数字人文领域的发展广度与深度,而且能够有效加深研究者对古汉语文本内容的主题挖掘,进而推动中国古籍知识的传播和普及。本文通过实验设计,以先秦两汉时期的“儒家”和“史书”文献为研究和分析对象,探究了SikuBERT模型在古汉语文本关键词抽取任务中的适用性和应用前景,为未来进一步构建面向古籍研究的深度学习预训练模型提供有益参考。
在后续研究中可进一步展开以下工作:(1)提升对古汉语中单字与双字词的识别和区分。本研究中,抽取关键词的词长被设定为1,可能会导致双字词被机械切分成单字后不能有效体现相关古文信息的真正主题。比如,“中庸”和“君子”被切分成“中”“庸”“君”“子”,失去了术语的原意。(2)加强对多音、多义和跨词性单字词的识别和处理,从而避免抽取出以“为”和“皆”为代表的、与文本主题内容不相关的关键词。(3)开发专门针对古汉语的停用词表。下一步研究可通过迭代多次补充停用词表和重复抽取关键词,同时辅以结合专家知识的人工筛选方式,避免抽取出无效关键词,从而达到提高关键词文本相似度的目的。
注释
①访问地址:https://ctext.org/confucianism/zhs.
②分别是:《白虎通德论》《蔡中郎集》《春秋繁露》《大戴礼记》《独断》《风俗通义》《韩诗外传》《孔丛子》《孔子家语》《礼记》《论衡》《论语》《孟子》《潜夫论》《申鉴》《说苑》《素书》《太玄经》《孝经》《新书》《新序》《新语》《荀子》《扬子法言》《中论》《忠经》。
③分别是:《春秋公羊传》《春秋谷梁传》《东观汉记》《古三坟》《国语》《汉书》《后汉书》《列女传》《穆天子传》《前汉纪》《史记》《吴越春秋》《西京杂记》《盐铁论》《晏子春秋》《逸周书》《越绝书》《战国策》《竹书纪年》。
猜你喜欢
社会科学战线(2022年5期)2022-07-23
社会科学战线(2022年4期)2022-06-15
潍坊学院学报(2021年4期)2021-11-20
红河学院学报(2021年4期)2021-11-19
金桥(2021年4期)2021-05-21
邯郸学院学报(2020年3期)2020-10-27
汉字汉语研究(2020年2期)2020-08-13
红楼梦学刊(2019年2期)2019-04-12
汉字汉语研究(2018年1期)2018-05-26
江淮论坛(2017年2期)2017-03-30
