
高维类不平衡冠心病数据的变量选择
2022-09-26 04:18宗敏洁吴愿交卢秀青
数字技术与应用 2022年9期
宗敏洁 吴愿交 卢秀青
1.黄河交通学院;2.西南交通大学希望学院;3.机械工业第六设计研究院有限公司
近几年,随着大数据概念的不断升温,学术界及产业界对不平衡数据处理问题的研究热情仍未消退,且呈现逐渐升温的趋势,医疗数据成为其重要处理对象。医疗数据的特征是高度不平衡性、变量相关性程度高且维度高。该文首先对数据集进行相关性分析,得出变量间存在严重的相关性,变量之间存在相关性会对分类结果产生影响。之后,分别采用LASSO和SPLS方法,对数据进行变量选择,选出8个最优变量作为最优子集,利用支持向量机分类器,对最优子集进行分类处理,提高了分类精度。同时,变量选择降低了维度冗余与数据存储问题,节约了时间与成本。研究表明:在高维不平衡数据分析中,变量选择是行之有效的预处理策略。
1 研究背景
1.1 问题背景
自20世纪90年代末以来,不平衡数据处理一直是机器学习与数据挖掘领域的研究热点与难点之一。近几年,随着大数据概念的不断升温,学术界及产业界对不平衡数据处理问题的研究热情仍未消退且呈现逐渐升温的趋势。
在医疗诊断中如果把正常人(多数类)误诊为疾病患者(少数类)固然会给他带来精神上的负担,但如果把一个疾病患者(少数类)误诊为正常人(多数类),就可能会错过最佳治疗时期,从而造成严重的后果。此时,少数类样例被误分的代价要比多数类被误分的代价大[1]。这样的医疗不平衡数据是普遍存在的,因此,提高不平衡数据中少数类的分类精确度,从而应用到实际例子中,比如软件缺陷预测、网络入侵检测、石油泄漏检测、信用卡欺诈等领域,以及在代谢组学中确定稳健的生物标志物可以帮助提供一种较好的疾病诊断方法。
冠状动脉粥样硬化性心脏病,是冠状动脉血管发生动脉粥样硬化病变而引起血管腔狭窄或阻塞,造成心肌缺血、缺氧或坏死而导致的心脏病[2],常常被称为“冠心病”。近几年,随着我国社会的快速发展和人们生活水平的提高,冠心病发病率呈现上升趋势,该疾病已逐渐成为严重影响人们健康生活的主要疾病之一[3]。因此,对于冠心病及其并发症数据的研究是非常重要的。
变量选择是统计分析和推断中的重要内容,在建模过程中往往需要通过变量选择方法,寻找对响应变量最具有解释性的自变量(协变量),以此来提高模型解释性和预测准确性,变量选择结果的好坏影响着所建模型的质量。变量选择是为了减少数据集中的变量数量,它可以带来许多好处,例如更快的模型训练,降低过度拟合的可接受性,抵消维度冗余的影响,以及减少数据分析期间的存储、内存和处理要求。在类不平衡数据中特别是高维数据中,变量选择也极其重要。
1.2 国内外研究情况
在不平衡学习问题中,研究了几种变量选择方法。对所提出的标准方法进行分析,以检验这些方法是否有利于实现不平衡分类。Xiaojuan Zhang等人建立了一种基于偏最小二乘(PLS)判别分析(DA)结合可变迭代空间收缩法的石菖蒲与菖蒲鉴别模型。筛选出樟脑、长环烯和δ-cadinene 3种挥发物作为石菖蒲和菖蒲的关键鉴别因子。该方案可作为中草药潜在生物活性成分的质量控制和筛选的有效策略[4]。Zhongquan Xin等人建立了基于偏最小二乘(PLS)判别分析(DA)的高效判别模型,通过交叉验证和置换检验对模型的可靠性和预测能力进行了评价。结果表明,色谱指纹图谱与化学计量学方法相结合为RP的质量控制提供了一种有效、便捷的方法,有助于揭示复杂分析样品的化学特征[5]。Robert等人提出了一种线性模型估计的新方法—LASSO,可以应用于各种统计模型的变量选择,对广义回归模型和基于树的模型的扩展进行了简要描述[6]。
本论文以不平衡冠心病数据为研究目的对象,对不平衡数据进行相关性分析和变量选择处理,选出最优子集,降低维度冗余和数据存储,以此来改善不平衡数据的分类效果,提高少数类的分类准确率。从中探讨不平衡数据处理在冠心病数据分析中的应用价值,为冠心病防治工作提供理论依据,使其能采取有效的防治措施,从整体上降低冠状动脉粥样硬化性心脏病的发病率。
2 数据来源
数据集包括21例冠心病(CHD)患者和51例健康志愿者。所有患者均来自中国云南省第一人民医院。另外,健康对照组51例健康成人均来自同一城市,无血缘关系。采用超高效液相色谱-高分辨质谱(UPLC-HRMS)联用技术检测了50种代谢产物。临床特征包括年龄、收缩压、舒张压、空腹血糖等。一般情况下,健康人样本比冠心病患者的样本更容易获得,所以这里的健康人样本类代表的是多数类,冠心病患者样本类代表的是少数类。本数据集无缺失数据。
3 方案设计
高维不平衡数据的主要特征是:变量维度高、样本少、数据共线性严重、数据的不平衡度高。本文从算法层面和评价标准两个不同层面对高维不平衡数据进行变量选择处理。从算法层面上,采用支持向量机算法[7];评价标准使用了预测精度(Accuracy,ACC),ROC曲线及其下的面积AUROC和PRC曲线及其下的面积AUPRC来度量不平衡数据的分类性能[8]。
本论文针对不平衡冠心病及其并发症数据,从两个层面进行分析,并对数据进行变量选择,以提高分类精度。具体流程如图1所示。
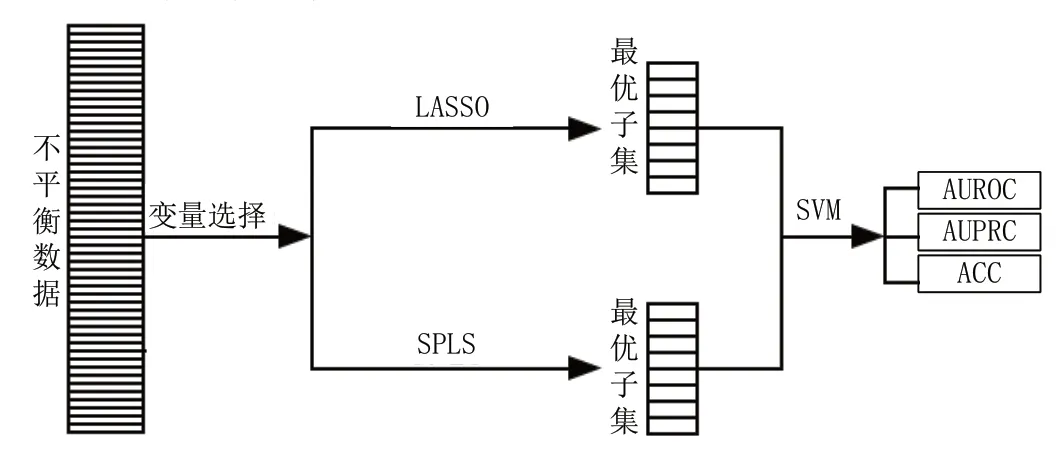
图1 方案设计流程图Fig.1 Plan design flowchart
4 变量选择对于分类的影响
以下以冠心病数据为例,从算法和评价准则的角度,按照图1的实验设计方案,对高维类不平衡医疗数据进行分析。
4.1 变量间的相关性分析
在高维不平衡数据集中,变量之间的相关性对数据的分类效果有所影响,变量之间的相关系数越大对于数据的分类效果影响越大,尤其对于正类的分类效果产生很大的影响。
本文所使用的冠心病不平衡数据集中各变量之间也存在一定的相关性。如图2所示,颜色越深,表明两变量之间相关性越强。中间一块颜色最深,表明变量间存在严重的相关性,变量之间存在相关性会对分类结果产生影响,所以需要对数据集进行变量选择。

图2 变量间相关系数矩阵热图Fig.2 Claolic coefficient matrix hot map
4.2 变量选择对于分类的影响
变量选择的目的就是剔除相关性较大的变量,医疗不平数据不仅维度高,数据间的相关性也很强,因此医疗数据的研究都离不开用变量选择方法来提取最优变量,以此达到降维的目的。变量选择的过程在于去掉相关性不大的变量,把更少的变量应用于算法研究,目的是从原始数据中选择使得某种评估标准最优的子集。在分类问题中,变量选择目标是提取使分类器准确度最大化的最优子集,仅使用一小部分变量捕获数据集中固有的大多数信息。stabilityLASSO方法和stabilitySPLS方法都是变量选择较为常用的方法。
分别运用stabilityLASSO方法和stabilitySPLS方法对不平衡比为51:21的数据集进行变量选择,根据被选择频次排序选出8个变量(如图3所示)。对不平衡比为51:10的数据集进行变量选择,根据被选择频次排序选出8个变量(如图4所示)。
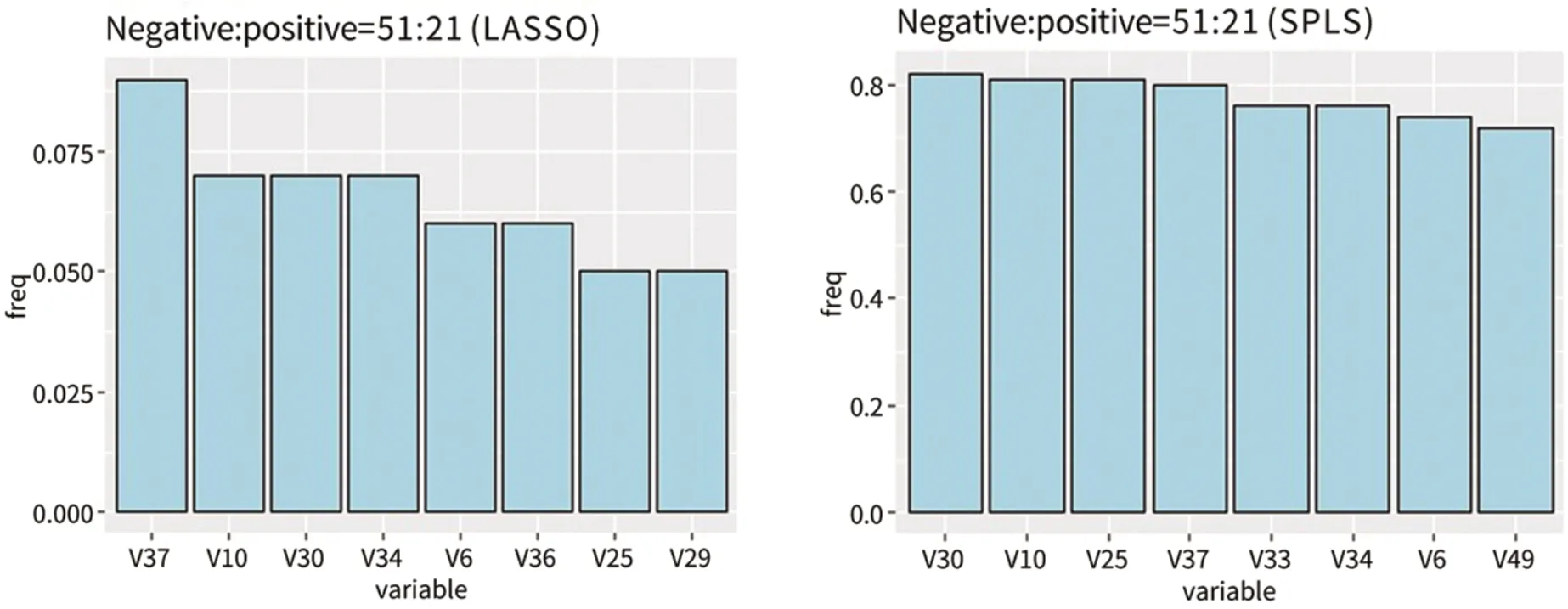
图3 不平衡比为51:21的数据集,根据被选择频次排序选出8个变量Fig.3 In the data set with an imbalance ratio of 51:21, 8 variables were selected according to the selected frequency

图4 不平衡比为51:10的数据集,根据被选择频次排序选出8个变量Fig.4 In the data set with an imbalance ratio of 51:10, 8 variables were selected according to the selected frequency
根据stabilityLASSO方法和stabilitySPLS方法对不平衡数据集进行变量选择得出的8个变量,使用支持向量机(SVW)对变量选择后的数据集进行分类处理,结果如表1所示。
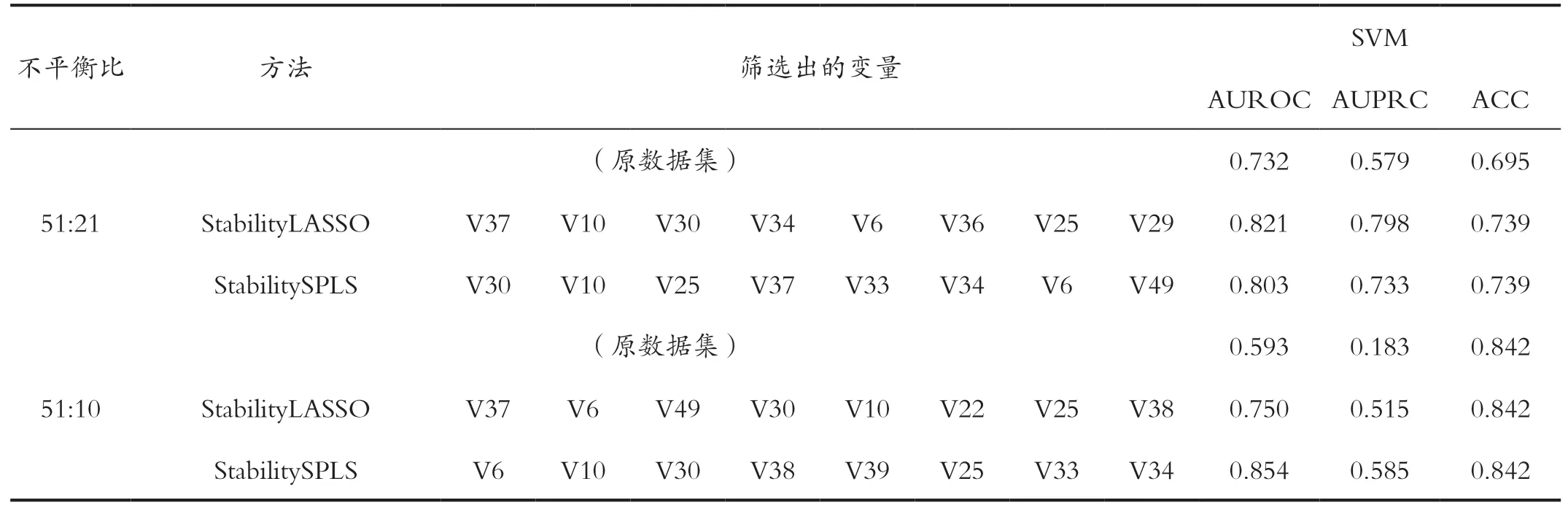
表1 两种方法变量选择表Tab.1 Two methods variable selection table
由表1得出,对数据进行变量选择后在使用支持向量机(SVW)进行分类,AUROC、AUPRC和ACC的值均有所提高。为了能直观的比较数据集变量选择前后使用支持向量机(SVW)进行分类结果的变化情况,对变量选择前后的结果进行可视化(如图5所示)。
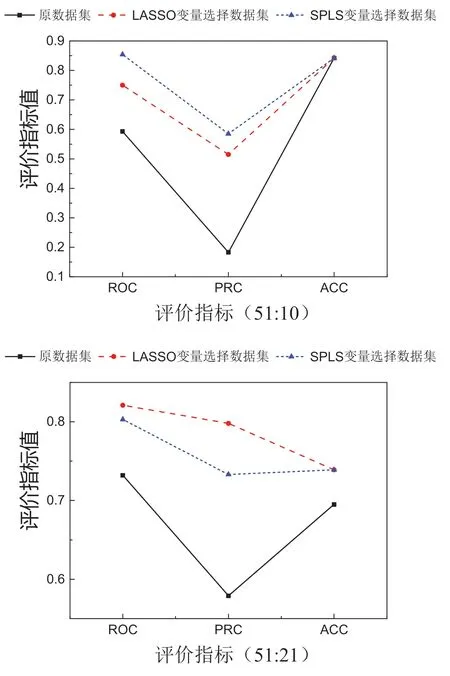
图5 不平衡比为51:10和51:21的数据集变量选择前后在SVW分类器的结果Fig.5 Unbalance ratios of 51:10 and 51:21 data sets were selected before and after the results of the classifier
5 结论
不平衡数据广泛存在于许多科学领域,如医学。变量选择也是医学数据研究中很重要的一项问题,因此如何使用变量选择方法很重要。本文采用LASSO和SPLS方法,对数据进行变量选择,选出8个最优变量作为最优特征子集,结合支持向量机算法,提高了分类精度。同时,变量选择降低了维度灾难与数据需求问题,节约了时间与成本。
本文的实际应用意义在于:首先为医疗不平衡数据提供了一种可行的处理手段;其次,一些重要变量,通过变量选择筛选出来,可以作为冠心病数据收集的重要指标进行分析;最后,体现了不平衡数据对医疗数据分类的重要性。同时,也为其他领域不平衡数据处理理论增加一种可能的实现依据。
引用
[1] 李勇,刘战东,张海军.不平衡数据的集成分类算法综述[J].计算机应用研究,2014,31(5):1287-1291.
[2] 徐玲,尹婷婷,俞吉,等.冠心病冠状动脉粥样硬化发生的危险因素多因素Logistic分析[J].临床和实验医学杂志,2019,18(6):626-629.
[3] 路航.早发冠心病的危险因素及冠脉病变特点分析[J].中国疗养医学,2019,28(4):348-351.
[4] ZHANG Xiao-juan,YI Lun-zhao,DENG Bai-chuan,et al. Discrimination of Acori Tatarinowii Rhizoma and Acori Calami Rhizoma Based on Quantitative Gas Chromatographic Fingerprints and Chemometric Methods[J].Journal of Separation Science,2015, 38(23):4078-4085.
[5] XIN Zhong-quan,REN Da-bing-,ZHANG Xiao-juan,et al. Chromatographic Fingerprints Combined with Chemometric Methods Reveal the Chemical Features of Authentic Radix Polygalae[J].Journal of Aoac International, 2017,100(01):30-37.
[6] Robert Tibshirani.Regression Shrinkage and Selection Via the Lasso [J].Journal of the Royal Statistical Society.Series B (Methodological), 1996,58(01):267-288.
[7] FU Guang-hui,ZHANG Bing-yang,KOU He-dan,et al.Stable Biomarker Screening and Classification by Subsampling-based Sparse Regularization Coupled with Support Vector Machines in Metabolomics[J].Chemometrics and Intelligent Laboratory Systems, 2017(160):22-31.
[8] YANG Ri-dong,LI Lin,CHEN Qiu-yuan,et al.Prediction of Disease-free Survival in Patients with Hepatocellular Carcinoma Based on Imbalance Classification[J].Journal of Biomedical Engineering Research,2019,38(1):27-31.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
测控技术(2018年4期)2018-11-25
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电信科学(2017年6期)2017-07-01
灯与照明(2016年4期)2016-06-05
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
数学年刊A辑(中文版)(2015年3期)2015-10-30
应用数学与计算数学学报(2014年3期)2014-09-26
