
结合MacBERT和多尺度融合网络的档案数据分类研究
2022-10-11 07:37刘舸舸
电子设计工程 2022年19期
刘舸舸
(陆军军医大学第二附属医院医学工程科,重庆 400037)
随着档案数据数字化程度的快速增加,各种电子档案数量呈现出爆炸式的增长。面对海量的档案数据,现有的手工分类模式费时费力,效率不高且易误分类[1-2]。如何合理挖掘和分析档案内容的潜在关联性,以及快速识别档案类别已经成为一个急需解决的问题。
传统静态词向量Word2vec[3]和Glove 在训练过程中舍弃了词的位置信息,无法准确表示档案文本的完整语义。动态词向量模型ELMO[4]和BERT[5]结合了每个词具体上下文语境进行动态学习,使得相同词在不同语境下有着不同的词向量表征,解决了一词多义问题。MacBERT[6]模型引入了全词MASK策略,并使用相似的词替换MASK 词,减缓预训练和微调两个阶段的误差,提升了模型的语义理解能力。
档案数据自动分类方法主要有机器学习方法和深度学习方法。机器学习方法需要人为构建复杂特征工程,导致时间、人工成本高,且无法确保提取特征的准确性。而在深度学习方面,文献[7]提出了Word2vec-ABLCNN 的文本分类模型,词向量模型Word2vec 无法表示多义词,词向量语义表示质量低。针对专利分类研究,文献[8]提出了BERT-CNN模型,该模型提升了层级专利分类性能,但CNN 模块仅能捕获文本局部特征,特征提取不够全面。文献[9]提出了BERT-BiLSTM-CRF 命名实体识别模型,BilSTM 受限于循环机制,训练效率不高,且缺乏对局部特征的学习。以上模型未能识别出对分类结果影响更大的关键特征。
针对目前研究仍然存在的不足,文中提出了结合MacBERT 和多尺度融合网络的档案数据分类模型,主要创新和贡献如下:
1)针对静态词向量无法表示多义词的问题,MacBERT 模型获取了文本的动态特征表示,提高了词向量表征能力。
2)为确保特征提取的全面性,采用多尺度融合网络捕获档案文本局部特征和全局序列语义特征。
3)利用软注意力[10]模块赋予模型识别关键特征的能力。
1 MacBERT-MCNN-BiSRU-AT模型
1.1 模型整体结构
文中提出的结合MacBERT 和多尺度融合网络的档案数据分类模型整体结构如图1 所示。档案数据分类的主要步骤如下:1)对档案数据进行清洗和预处理,对错误分类的档案样本进行纠正。2)利用MacBERT 预训练模型提取档案文本的动态特征向量表示。3)由多尺度融合网络提取文本局部语义特征和上下文深层序列特征。4)利用软注意力模块计算每个词对分类结果的权重得分。5)分类层输出档案文本分类结果。
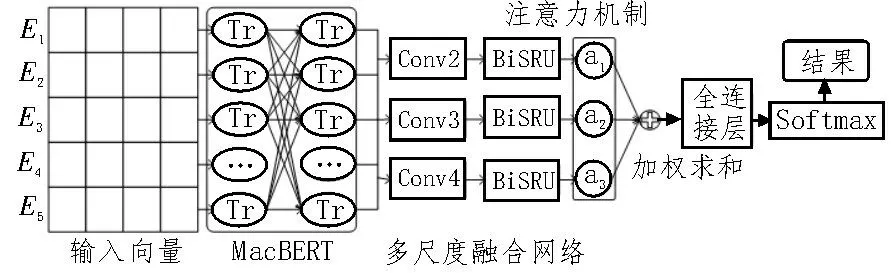
图1 模型整体结构
1.2 MacBERT模型
MacBERT 利用双向Transformer 编码器提取文本语义特征,内置自注意力作为核心模块,能够关注到句子内部每个词与词之间的依赖关系,捕捉到文本句法结构,增强模型语义理解能力[11]。模型结构如图2 所示。

图2 MacBERT模型结构
其中,E1,E2,…,Em为输入向量,由字嵌入、位置嵌入和分句嵌入相加而成,相关过程如图3 所示。经多层Transform 编码器动态语义学习后,得到文本的动态特征表示T1,T2,…,Tm,Ti为文本中词的向量表示。
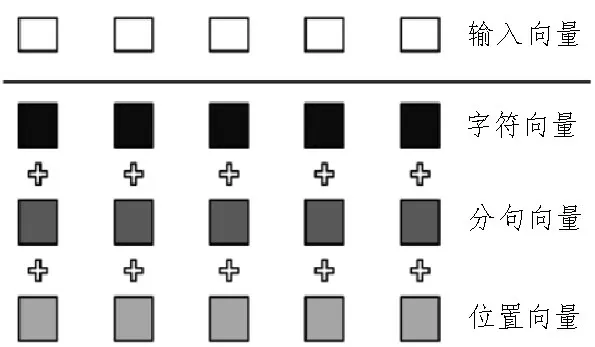
图3 输入向量组成
1.3 多尺度融合网络MCNN-BiSRU
多尺度融合网络主要由多通道卷积模块和双向简单循环网络构成。多通道卷积模块[12]通过设置不同尺寸的卷积核,分别对特征图进行卷积操作,捕获词和短语级别的局部语义特征。双向简单循环网络对局部特征进行多尺度上下文序列特征学习。
在多通道卷积模块中,对MacBERT 模型输出的动态特征表示T进行卷积操作,为降低语义损失,不加入池化操作,得到新的特征表示ci。计算过程如式(1)、(2)所示:
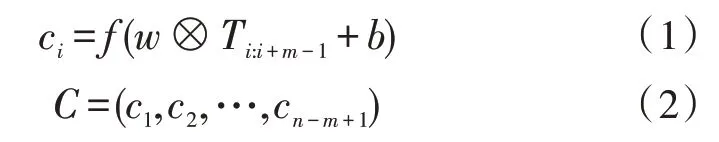
其中,w为卷积核;b为偏置值;m为滑动窗口大小;⊗为卷积操作;f为relu()函数;Ti:i+m-1表示T中第i到i+m-1 行文本向量。
双向简单循环单元(Simple Recurrent Unit,SRU)[13]作为LSTM[14]和GRU[15]的优秀变体,摆脱了传统循环模型固有的对上一个时间步输出状态的依赖,充分利用显卡资源进行并行计算加速,提高训练效率。SRU 前向计算过程如式(3)-(6)所示:
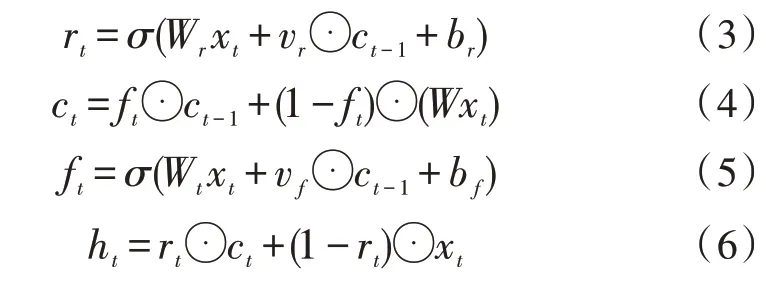
档案文本语义不仅由上文语义决定,也与下文的语义关系密切。因此,将前向SRU 和后向SRU 叠加形成BiSRU 模块,利用BiSRU 提取档案文本的完整语义表示,其模型结构如图4 所示。行向
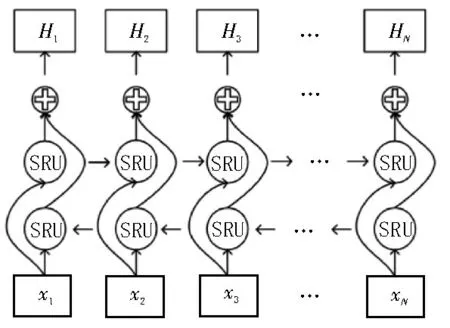
图4 BiSRU模型结构
其中,xt代表卷积操作得到的新特征C的第t行向量。第t时刻的状态输出Ht由前向和后向拼接而成。
将卷积层多个通道输出的局部特征表示[C1,C2,…,Cn]分别输入到BiSRU,将每个BiSRU 最后一个隐状态输出进行拼接,得到多尺度融合特征表示
1.4 软注意力机制
将多尺度特征输出H输入到软注意力层,计算每个特征对分类结果的注意力得分大小ai,赋予关键特征更高的权重。相关过程如式(7)-(9)所示:
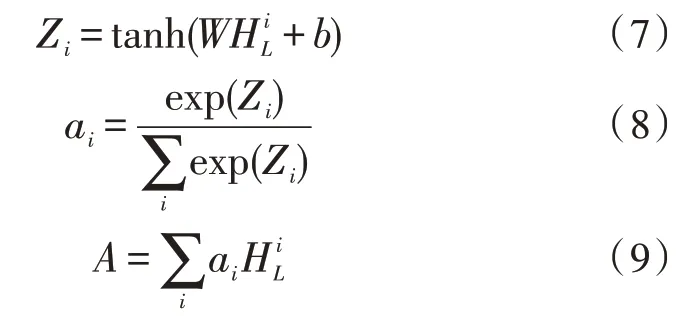
其中,tanh()为非线性函数;exp()表示指数运算。
1.5 分类层
将注意力特征的表示A通过全连接层变换到分类空间,由Softmax 函数得到概率分布Ps,取行最大值对应的档案类别标签作为分类结果,其过程如式(10)、(11)所示:
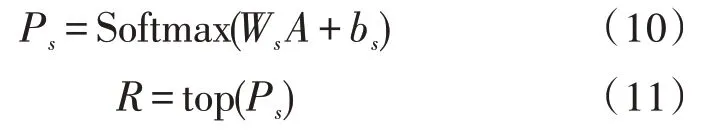
2 结果分析
2.1 数据集和性能指标
采用某企业人事档案数据资源作为实验依据,共8 977 份档案样本。手动标注每份档案文本的所属类别,并加入到样本首部,以 作为分隔符号,用于区分标签和档案内容。由于数据集中类别数量不平衡,因此仅选择档案样本数量较多的类别进行实验,分 别 是C12-User、C13-Upper computer、C14-Identity、C15-Address 和C16-Politics,按照80%、10%和10%划分训练集、测试集和验证集。
模型性能评价指标采用准确率(Accuary)、精确率(Precision)、召回率(Recall)和F1 分数,计算过程如式(12)-(15)所示:

2.2 硬件环境与参数设定
模型训练采用Linux 操作系统,显卡为3090,显存大小为24 GB;Python 版本为3.6.0,深度学习框架Pytorch 版本为1.7.0,使用numpy 等第三方支持库构建模型并进行训练。
文中采用Base版本的中文MacBERT模型;MCNN卷积核尺寸为(2,3,4),特征通道数量均为128;BiSRU隐藏层大小为256,层数为1;软注意力机制维度为256;随机失活概率设置为0.3;最大序列截断长度为300。综合训练参数设定如表1 所示。

表1 综合训练参数
2.3 结果分析
模型性能指标如表2所示。由表2可知,文中模型MacBERT-MCNN-BiSRU-AT 的准确率达到了90.5%,优于近期表现较好的深度学习模型,较BERTCNN 和BERT-BiLSTM 分别提升了5.7%和5.2%,证明了MacBERT 与多尺度融合网络结合的有效性。

表2 性能指标对比
为验证MacBERT 作为词向量提取层的有效性,设置Word2vec[16]、ELMO 和BERT 模型作为对比,结果表明,MacBERT 准确率最高,具有更好的应用效果。
为证明多尺度融合网络的效果,设置消融实验,与MacBERT-MCNN和MacBERT-BiSRU对比,结果表明,MacBERT-MCNN-BiSRU模型准确率与MacBERTMCNN 和MacBERT-BiSRU 相比分别提高了2.5%和2.2%,多尺度融合网络能够全面提取档案文本的局部语义特征和全局序列特征,提升了模型分类性能。
加入软注意力机制的MacBERT-MCNN-BiSRUAT 模型准确率较MacBERT-MCNN-BiSRU 提高了1.9%,证明了软注意力层能够识别关键特征,提高分类效果[17-18]。
综上所述,文中提出的MacBERT-MCNN-BiSRUAT 模型有效地提高了档案文本分类准确率。
3 结论
为提高档案数据分类的准确率,文中提出了结合MacBERT 和多尺度融合网络的档案数据自动分类模型。利用MacBERT 提取档案文本动态特征表示,解决了一词多义问题;多尺度融合网络充分利用文本的局部语义特征和全局上下文语义关联,确保获取文本特征的全面性。使用软注意力机制计算每个特征的权重大小,识别出关键特征。实验结果证明了文中模型在档案自动分类任务上的有效性。在未来工作中,考虑在维持基本精度的前提下,降低MacBERT 模型参数,并将模型应用到其他文本分类领域。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
计算机仿真(2022年7期)2022-08-22
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
