
协同过滤推荐算法的性能对比与分析
2022-10-25 11:59王子茹宋尚文阎红灿
计算机仿真 2022年9期
王子茹,宋尚文,阎红灿,2*
(1. 华北大学理学院,河北 唐山 063210; 2. 数据科学与应用重点实验室,河北 唐山 063210)
1 引言
随着网络信息的爆炸性增长,各种各样的信息被提供给用户,如何帮助用户筛选出自己喜欢的物品,成为众多专家学者关注的问题。为了解决这一问题,诞生了推荐系统,它利用用户历史交互记录,发现用户的隐含信息,为用户推荐他们喜爱的产品。推荐算法作为推荐系统的核心,一直备受关注,但依然面临数据稀疏性和推荐准确率较低的问题,不能准确反映用户兴趣变化的规律。本文将对几种典型的协同过滤算法实验重现,进行对比分析,横向对比算法的优劣。
2 协同过滤推荐算法
协同过滤推荐算法是目前最流行的推荐算法,核心是只需用户的评分历史,与被推荐的内容无关。最早出现在GroupLens的新闻推荐系统中。自1992年提出以来,就备受关注。主要分为三种:基于内容的协同过滤推荐算法(User-based CF)、基于用户的协同过滤推荐算法(Item-based CF)和基于模型的协同过滤推荐算法(Model-based CF)。而基于模型的推荐算法有基于图模型、矩阵分解、聚类等。推荐时经常面临数据稀疏性问题、可扩展性问题造成推荐准确率低,本文主要对比分析基于用户的协同过滤和基于模型的协同过滤中基于聚类的协同过滤。
个性化推荐时首先根据用户评分的历史数据构建评分矩阵,根据用户间的相似结果筛选相似度较高的用户集合作为最近邻,最后对目标用户没有交互记录的项目进行评分预测,选取前N个评分最高项目,完成推荐。在推荐系统中,最核心的关键技术是用户间的相似度计算见图1。
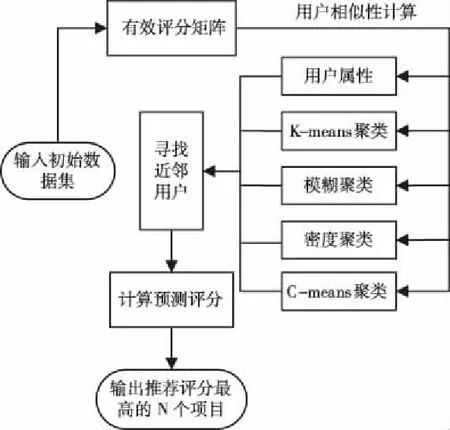
图1 推荐算法流程
3 用户相似度计算
推荐过程是在用户的近邻中完成,根据用户间的相似度计算,可以分为基于用户属性差异或聚类两种方式,计算相似度时,用户的属性差异可以采用距离法度量,而采用聚类的方式计算用户间的相似度主要有以下几种聚类方式:模糊聚类、K-means聚类、密度聚类、C-means聚类等。
3.1 基于用户属性的相似度计算
User-based CF分两个步骤实现协同过滤推荐,第一步根据用户历史交互记录,得到用户间的相似性,第二步设定阈值,将两用户之间的相似性大于某阈值的用户归为相似用户,设置近邻个数即取几个相似性用户参与预测评分,并选取前N个评分最高项目,完成推荐。在计算用户间的相似度时常采用如欧氏距离、余弦距离、皮尔逊距离、杰卡德系数和曼哈顿距离等。
为进一步缓解数据稀疏性问题,刘航利用拉普拉斯变换与归一化处理进行矩阵的稀疏值处理,同时避免余弦距离计算相似度时的偏差问题,提高原始数据利用率;任永功等分别基于用户和物品的相似度进行混合填充,改善原数据的稀疏性,提升推荐效果;郭宁宁等针对数据稀疏性,设计了交互数据与评价数据的融合协同过滤,利用特征相似性进行行为估测,并通过计算最优评价得到最终推荐方案。
也有人提出对相似度的计算进行改进,王岩等考虑用户评分差异性和用户评分倾向性且将标准差作为离散系数参与用户间相似性计算,与皮尔逊系数结合更精确模拟用户间的相似关系;黄创光等提出一种动态近邻的协同过滤推荐,根据不同场景,动态选取近邻,缓解用户群稀疏和推荐物品不稳定的影响,提高预测准确性;董立岩等通过权重调节流行物品的影响程度,改进相似度计算方式,加入项目等隐含信息提升推荐的准确性;李炎等基于评分和用户分别从时间和空间角度改进相似度结果,改善推荐效果;王娜娜采用修正的余弦相似度计算用户兴趣相似度,见式(1),改进皮尔逊系数计算用户评分相似度,见式(2),融合用户兴趣相似度与评分相似度综合计算用户间相似性见式(3),改进用户评分公式,改善推荐性能。
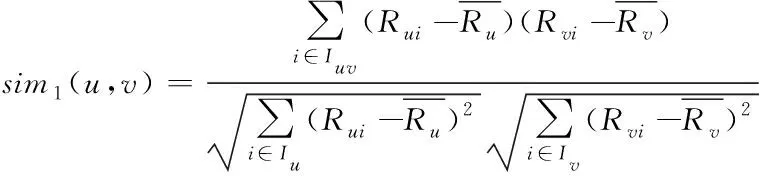
(1)

(,)=
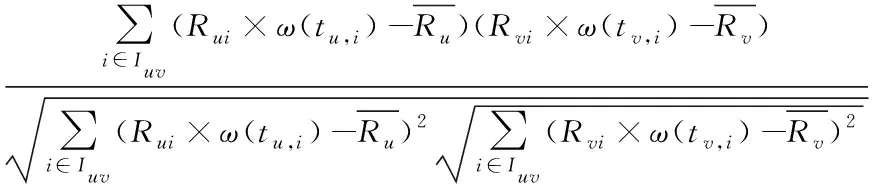
(2)
其中,(,)表示用户和之间融合时间因素的用户评分相似度;(,)表示用户对项目评分的时间权重。
(,)=(,)+(1-)(,)
(3)
其中,、1-分别表示(,)、(,)的权重,且∈[0,1],本文取05。
也有学者提出综合计算用户的相似度,张怡文等基于用户、项目和项目的属性特征构建用户对项目、属性的双极特征向量,表示用户的喜欢程度和讨厌程度。通过对双极特征向量进行加权计算相似度。王建芳等将用户属性、用户偏好和用户轨迹,通过参数调节相似度权重;赵森通过引入用户偏好,加入惩罚因子处理冷门和热门产品在相似度计算中的比重,同时与项目关联相似度进行加权计算综合相似度完成推荐。
3.2 基于聚类的用户相似度计算
近年来,许多学者在协同过滤中加入一些聚类方法取得了一些行之有效的研究。如K-means聚类、模糊聚类(Fuzzy clustering)、C-means聚类、密度聚类(Density clustering)等。
K-means聚类,聚类中心任意选取,找到K个中心,计算剩余点与这K个中心的距离,将距离较小的点归为同类,每次加入新点,重新计算,直到聚类对象不在重新分配或聚类中心不再改变。张娅采用K-means聚类实现大数据频繁项集挖掘方法,获得较好的效果;梁丽君等优化K-means聚类算法,将用户属性与偏好加入并改进相似度模型。李艳娟等提出蜂群K-means聚类。龚敏等首先采用K-means 算法对用户属性特征进行聚类,然后利用SlopeOne算法对矩阵进行缺值填充,最后利用协同过滤思想进行评分预测;姜少鑫采用巴氏系数改善共同评分问题,缓解数据的稀疏性,采用全局相似性,见式(4)和局部相似度,获取用户间隐含信息,见式(5),综合计算用户间的相似性;同时加入K-means聚类,减小了近邻的搜索范围,提高推荐的准确性。
结合巴氏系数的相似度
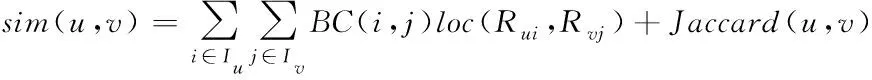
(4)
其中,(,)为项目和的全局相似度,(,)为项目和的局部相似度。
考虑到用户和之间可能没有公共评分的项目,为扩大相似度用户的搜索域,定义局部相似度
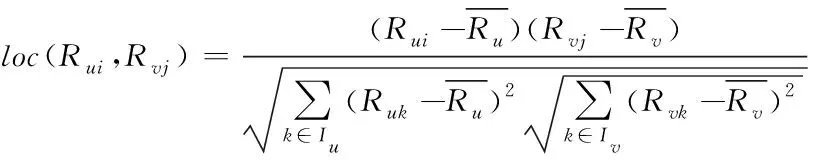
(5)
K-means算法虽然可以一定程度上提高推荐的准确性,但面临信息挖掘不充分的问题,用户的隐含信息难以捕捉,属于硬聚类,在现实生活中一个用户可能属于多个类别,于是有人提出使用软聚类对用户的邻居进行选取。
一些聚类方法不规定聚类中心的个数,称为软聚类,如模糊聚类、密度聚类、C均值聚类等。模糊聚类是根据用户的相似关系构建模糊相似矩阵,创建模糊等价矩阵,设置相应的截集完成模糊等价类的选取并完成推荐。李悦等利用RP-IIP算法形成细粒度用户-项目偏好矩阵,更好的模拟用户兴趣偏好,缓解数据稀疏性,利用蝙蝠优化的模糊聚类,增强了用户的聚类效果并提高可扩展性;王永贵等首先构造的用户类别偏好矩阵反映用户的兴趣偏好,采用花朵授粉优化的模糊聚类算法对用户进行聚类,并融合项目属性隐含的信息改进项目评分公式,考虑时间因素对用户兴趣变化的影响,提高推荐的准确性。苏庆等引入冷门、热门和时间差权重因子改善相似度计算结果,见式(6)。
-,=Cos,×,×
,×,
(6)
其中,∈[0,1]表示冷门物品权重;,∈[0,1]表示时间权重;,∈[0,1]表示热门物品权重。
同时加入模糊划分聚类提高推荐准确性。熊乐改进初始样本中心选择,将样本加权与样本聚类中心加权参与目标函数计算,最后引入模拟退火算法跳出局部最优。
密度聚类算法首先计算每两个点之间的距离,使满足两个条件:类簇点和邻居点之间的距离大于阈值,类簇点与其它点之间的密度大于设定条件,这种点归为近邻点,在邻居集合中完成推荐。有些专家做了一些改进,李昆仑等首先采用修正的余弦距离计算两个样本点之间的距离,然后采用密度峰值聚类进行用户间相似度计算,大大降低计算复杂度,以等效电阻方式充分挖掘用户间的隐含信任关系;样本点的密度见式(7),样本点的距离见式(8)。

(7)
其中,为在截断距离内样本点的总个数,采用高斯核函数代替样本密度,避免样本点密度相同。

(8)
每个样本点之间的距离,分为两种情况,样本点到高密度点之间的距离和样本点为密度最大点时,表示和除样本点之外的点的最大距离。
陈帆等根据物品属性并结合密度峰值聚类进行推荐。张凯辉等利用斜率填充用户项目矩阵,采用CFDP算法对项目集合进行聚类,同时引入时间因子参与评分预测,获得实时推荐。
C-means聚类首先确定聚类个数C,设置模糊指数m,通过优化初始隶属矩阵得到聚类中心矩阵,计算聚类中心矩阵获得的样本与聚类中心之间的距离和隶属度矩阵,判断目标函数的变化情况,最后根据隶属度矩阵得到最终的模糊聚类结果并完成推荐。文献[27]为提高系统的推荐精度,提出了一种模糊C-means方法,实验结果表明该方法相比传统的K-means聚类算法具有更好的推荐效果;Verma等人将模糊C-means聚类加入传统的协同过滤推荐算法,FCM是一种软聚类算法,设置不同的隶属度,将用户划分到不同类簇中。韩亚运在模糊聚类之前,通过对传统的FCM算法进行改进,利用C均值聚类确定最优的初始聚类中心作为FCM算法的输入,同时引入时间因子进行实时推荐。蒋宗礼等将模糊C均值聚类与差分隐私保护结合并推荐;郭路路引入用户评分信任度改进相似度公式,通过权重设置融合用户的信任因素与用户间的评分,同时利用用户隐含信息构建用户偏爱模型,同时优化C均值聚类中聚类中心的选取,提高推荐效果;根据用户的评分偏好与用户间的信任值将用户间的相似性计算分为两部分,具体见式(9)和式(10)。
如果0≤d(u,v)I≤0.5,公式如下所示
(,)=
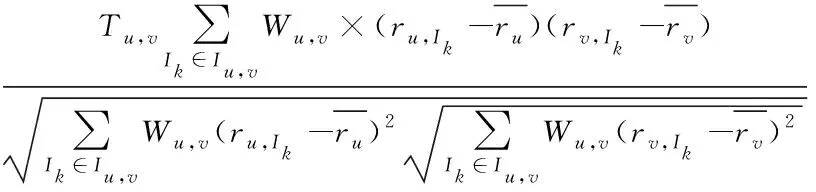
(9)
如果0.5≤d(u,v)I≤1公式如下所示
(,)=
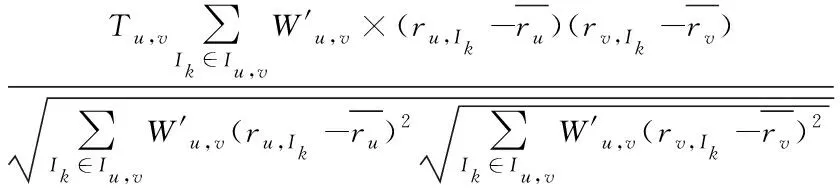
(10)
4 实验重现与性能分析
在两种不同大小数据集下,比较基于用户属性与结合聚类的协同过滤算法,分析推荐效果。在每个文献中参数设置最优的前提下,进行实验重现,实验分为两组,第一组对比文献[11],[17],[21],[26],[29]中的算法,第二组对比文献[14],[18],[22],[23],[30]中的算法,分析每种算法在不同大小数据集下的推荐性能及每种推荐算法适合的情境。
4.1 数据集
两组实验选择GroupLens项目组收集MovieLens 100k、MovieLens 1M数据集,评分都为1-5的整数,稀疏度分别为93.7%和95.54%,可以得到MovieLens 1M数据集的处理难度更大,这两组数据的评分值越高,代表用户越喜欢该项目。
4.2 推荐评价标准
本文选择平均绝对误差(Mean absolute error,MAE)式(11)和均方根误差(Root mean square error,RMSE)式(12),作为评价标准判断推荐系统的推荐性能。
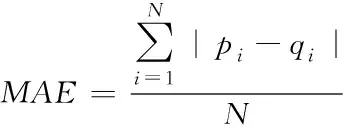
(11)

(12)
式中:为用户的实际评分,为推荐系统对用户的预测评分,为测试集中用户的所有评分项目个数。MAE和RMSE的值越小代表推荐性能越好。
4.3 实验结果
第一组实验以MAE和RMSE为评价标准,在基准数据集MovieLens 100k上进行,实验中的每种算法来自文献[11],[17],[21],[26],[29],具体数据结果见表1和表2。第二组实验基准在数据集MovieLens 1M下以MAE、RMSE为评价指标验证聚类算法的推荐性能,实验中的每种算法来自文献[14],[18],[22],[23],[30],具体数据结果见表3和表4。
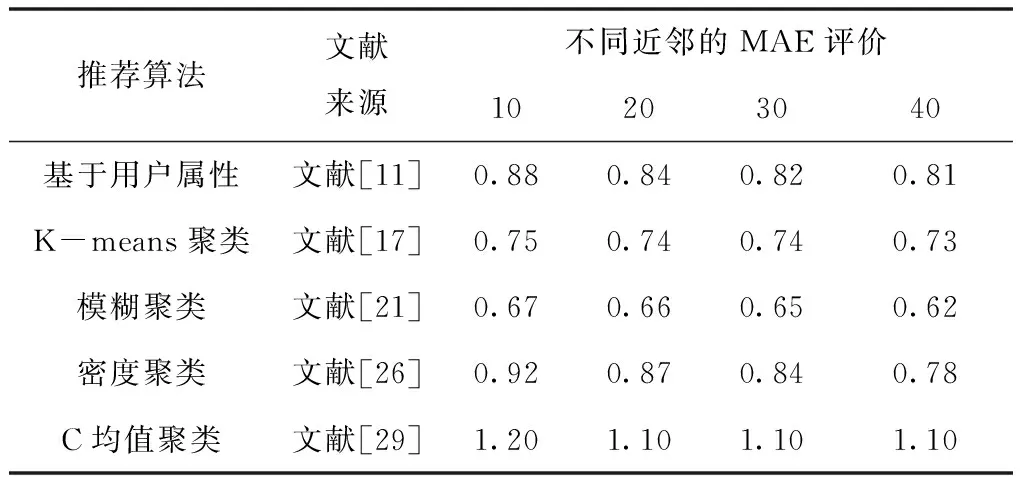
表1 MovieLens 100k数据集上的MAE对比

表2 MovieLens 100k数据集上的RMSE对比
在MovieLens 100k数据集上,随着用户近邻个数不断变化,基于用户属性的协同过滤算法的MAE、RMSE分别集中在0.82和1.04;融合K-means聚类的协同过滤算法的MAE、RMSE分别集中在0.74和0.92;加入模糊聚类的协同过滤算法的MAE、RMSE分别集中在0.65和0.92;结合密度聚类的协同过滤算法的MAE、RMSE分别集中在0.90和1.14;融合C均值聚类算法的MAE、RMSE分别集中在1.10和1.20,可见在小数据集上,软聚类再推荐效果上相对于硬聚类占有一定的优势,但计算的复杂度高也不可忽略。
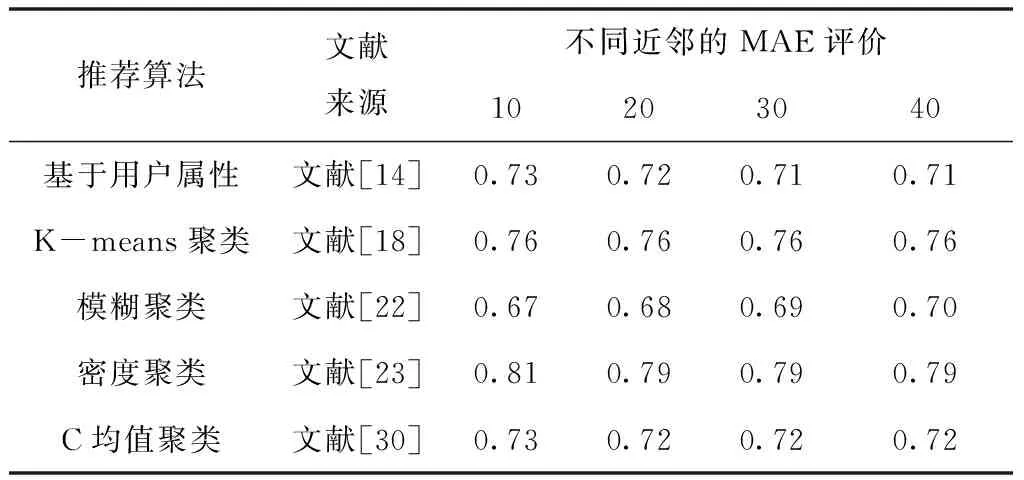
表3 MovieLens 1M数据集上的MAE值对比
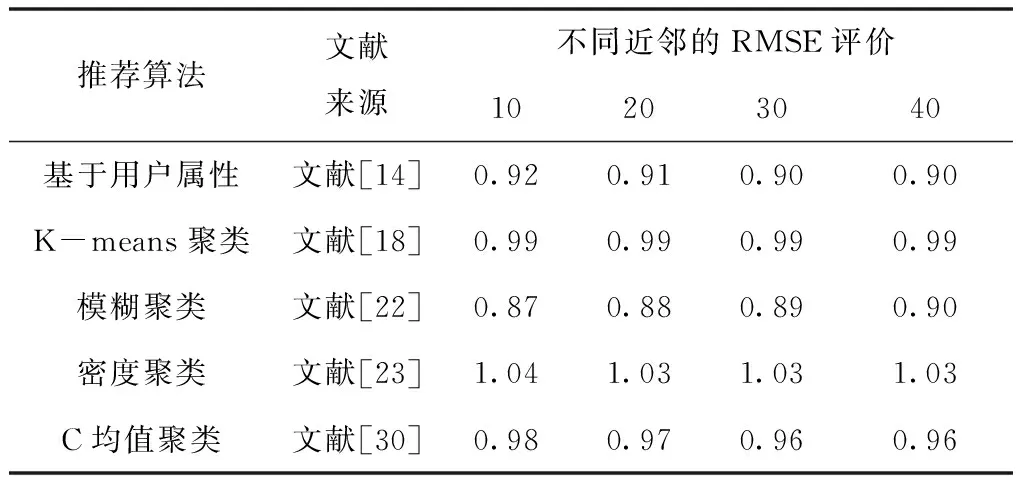
表4 MovieLens 1M数据集上的RMSE值对比
在MovieLens 1M数据集上,随着用户近邻个数不断变化,基于用户属性的协同过滤MAE、RMSE分别集中在0.72和0.91,较100k数据集MAE下降了0.1,RMSE值上升0.1;融合K-means聚类的协同过滤的MAE、RMSE分别集中在0.76和0.99;加入模糊聚类的协同过滤的MAE、RMSE分别集中在0.68和0.89;结合密度聚类的协同过滤算法的MAE、RMSE分别集中在0.79和1.03;融合C均值聚类的协同过滤推荐算法的MAE、RMSE分别集中在0.72和0.96,较100k数据集MAE下降了0.4,RMSE值下降0.2。
4.4 推荐性能分析
文献中的算法采用加入用户的信任值、引入属性距离与评分距离进行加权运算、降维等方式对稀疏值做了一定处理,缓解了数据的稀疏问题,同时提高推荐的准确性。由表1~4可得,每种聚类算法在不同的数据集上会产生不一样的推荐效果,综合表1和表2,基于用户属性的协同过滤推荐算法与结合聚类的协同过滤推荐算法在近邻用户为30~40个时可以获得较好的推荐质量。但由表3和表4可以观察到在更高维的数据集下,用户的近邻个数不影响推荐效果。对比文中5种推荐方法,基于用户属性的协同过滤在高维数据集上更能充分的挖掘用户的隐含信息;K-means聚类的协同过滤作为硬聚类的一种推荐,过程简单,性能稳定,但容易陷入局部最优;加入模糊聚类的协同过滤对数据集的要求不高,推荐效果好,但面临时间复杂度较高的问题;结合密度聚类的协同过滤在数据稀疏的高维数据集上比低维数据集更容易找到聚类中心,推荐效果较低维数据集好;引入C均值聚类的协同过滤推荐效果稳定,在高维数据集上推荐效果更好,不受近邻个数的影响,但聚类中心的选取是一个难题。
5 结语
推荐算法具有广泛的应用场景和商业价值,当前最常用的是协同过滤推荐算法,因而本文针对协同过滤类别的推荐算法做了系统分析和对比研究。通过基于用户属性的协同过滤和几种基于模型的聚类法协同过滤算法进行对比,分析每种推荐算法的特点和其应用领域的优劣,在实际应中提供策略指导。
在未来的工作中,将研究更多影响推荐效果的因素,如将深度学习和多层神经网络用于推荐算法中,改进推荐性能,为用户进行个性化智能推荐。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机研究与发展(2022年1期)2022-01-19
计算机应用与软件(2021年7期)2021-07-16
计算机应用(2020年12期)2020-12-31
舰船电子对抗(2017年6期)2018-01-11
读与写·教育教学版(2017年10期)2017-11-10
互联网天地(2016年1期)2016-05-04
文苑(2015年9期)2015-09-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
