
基于BERT的云蜜罐服务编排方法研究*
2022-11-09 02:34陈军
计算机与数字工程 2022年9期
陈 军
(武汉数字工程研究所 武汉 430025)
1 引言
随着云技术的不断发展,大规模的业务与数据向云上迁移的同时,针对云主机和云服务的网络攻击也日益严重[1~2]。众多安全事件表明,云环境的安全威胁不容忽视。而防火墙、入侵检测等传统安全防御技术防御手段单一,无法及时应对云安全威胁的快速变化。基于网络欺骗技术的云主机安全防护方法逐渐成为国内外众多学者的研究重点。
文献[3]结合Openstack云计算平台提出一种新型蜜罐系统,以解决蜜罐系统存在的性能、安全性和真实性相互制约问题。文献[4]将开源蜜罐工具Honeyd、Honeywall和Honeycomb部 署 在Openstack中来提高云环境中的威胁检测率。文献[5]在云环境中使用蜜罐识别和诱捕内部入侵,来增强云环境中的安全性能。文献[6]采用增强型蜜罐算法对云服务器中的文件进行加密保护,提高了云服务器存储的安全性。上述研究,蜜罐技术不同于其他安全手段,蜜罐以尽可能多部署在目标系统中来提高捕获攻击者行为的可能性,因此在云平台的环境下具体表现为消耗虚拟主机资源来部署蜜罐服务[7]。对于小型私有云来说,当所需蜜罐服务种类较多时,存在着平衡资源开销的需求。
针对上述背景和研究基础,本文提出了一种基于BERT的云蜜罐服务编排方法,使用BERT模型对捕获流量进行识别分类,基于蜜罐捕获数据集给出蜜罐与捕获网路攻击的关联关系,依据分类结果和关联关系编排云上蜜罐占用资源。
2 相关技术
2.1 BERT模型
BERT模型[8]是一个设计简单但效果显著的无监督预训练语言表征模型,其架构如图1所示。该架构采用Tranformer堆叠,是一个典型的双向编码模型,每个时刻t都获得前后时刻的输入,同时使用了Transformer的注意力机制。BERT模型采用预训练模型和微调任务两部分的实现设计。预训练模型预先使用大量的数据来进行训练,通过对所有层的左右上下文进行联合调节,从未标记的文本中预训深度双向表示,得到一个泛化能力较强的基础模型;遇到特定任务,无需针对特定任务进行大量模型结构的修改,只需额外添加输出层,可对预训练模型进行微调,从而为下游任务构建模型。
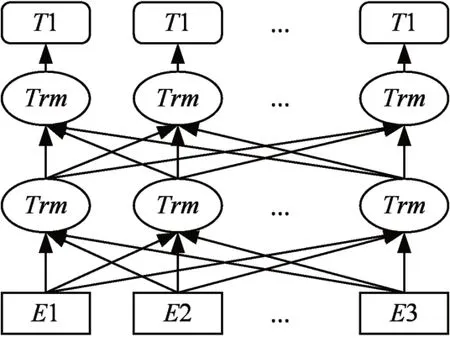
图1 BERT模型架构图
2.2 阈值分割算法
阈值选取的最佳算法。大津法(OTSU)是一种确定二值化分割阈值的算法,在图像的分割阈值确定上具有性能稳定、适应性强的特点[9]。其基本原理是:基于图像的灰度特性将图像分为背景和前景两部分,因方差是灰度分布均匀性的一种度量,背景与前景的类间方差越大,说明构成图像两部分的差异越大,当部分前景错分为背景或部分背景错分为前景时都会导致两部分差别变小。因此,类间方差最大的分割阈值意味着错分概率最小。
3 基于BERT的云蜜罐服务编排方法
本文中基于BERT的云蜜罐服务编排分为3部分:1)基于BERT模型对捕获流量进行报文分类;2)以软投票(soft voting)方式分类网络会话所属的攻击类别;3)使用OTSU算法对蜜罐报文数据集进行阈值分割,确定网络攻击与蜜罐服务对应的编排策略。
3.1 基于BERT模型的网络报文分类
报文层面的分类是针对各类协议报文进行识别,首先需要对报文数据进行预处理和量化。深度学习框架采用张量(Tensor)进行运算,要求输入数据保持等长,通常采取填充或截断操作进行数据归一化。考虑到截断操作会丢弃数据带来信息损失,对报文采用填充操作理成相同长度,其中以最长报文的字节数量作为max_len,将其他样本填充pad符号到最大字节数量,填充后的报文数据的形式化表达见式(1)。对输入数据应用卷积操作,本文在填充的基础上对报文数据的形状进行变化,将报文的序列数据转化为n×n的灰度图,其中n为max_len的平方根向上取整。
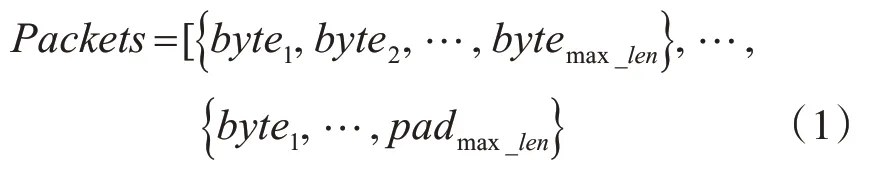
对网络报文的攻击类型识别属于分类任务,使用BERT模型编码能力对转换位灰度矩阵的报文进行映射,根据映射结果对报文进行分类。考虑BERT模型对输入数据的要求,本文在BERT模型的输入前级联卷积神经网络,对填充后的数据进行统一特征向量提取。同时在BERT的输出后级联一个由全连接层组成的分类神经网络,基于BERT进行修改的模型结构如图2所示。
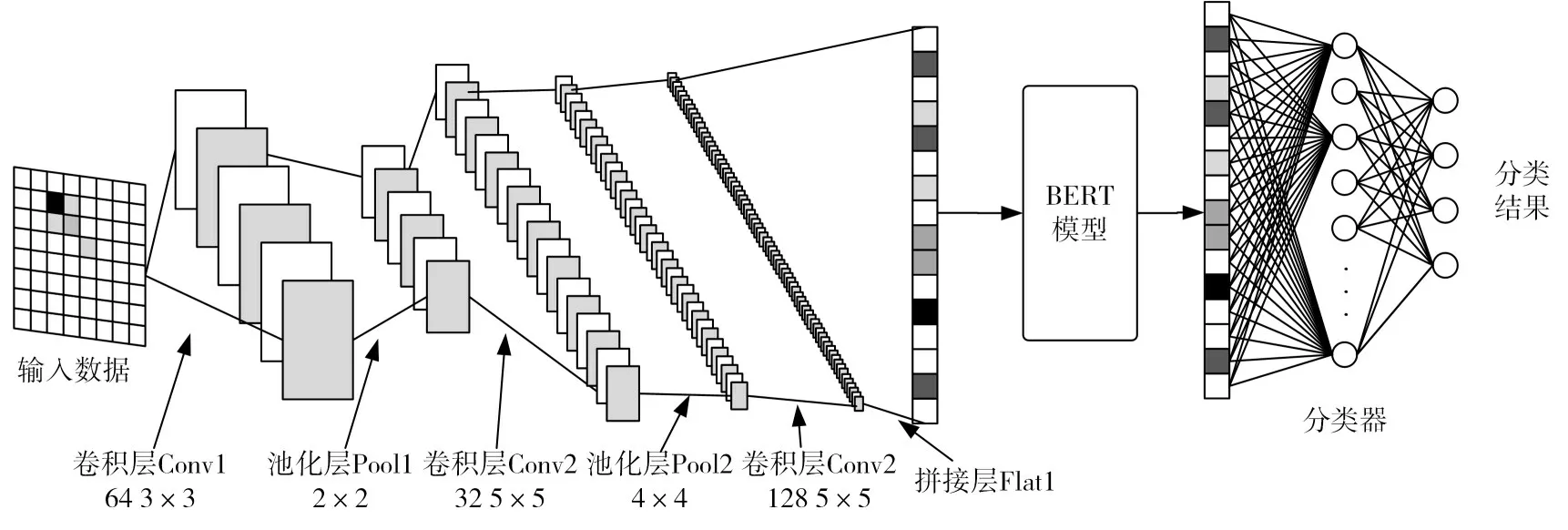
图2 基于BERT的报文分类模型结构
其中卷积神经网络结构的第一层为卷积层Conv1,使用64个3×3大小的卷积核对输入数据进行卷积,得到64通道的48×48特征图。在卷积层后接池化层Pool1,使用2×2大小的窗口对输入的64通道特征图进行最大池化,输出64通道的24×24特征图。池化层后接卷积层Conv2,采用32个5×5大小的卷积核对输入特征图进行卷积,得到32通道20×20特征图像。在Conv2后接池化层Pool2,使用4×4窗口对32通道的20×20特征图进行最大池化得到32通道的5×5特征图;在池化层Pool2后接卷积层Conv3,利用128个5×5的卷积核将Pool2的输出转化为128×1的张量,同时在Conv3后接拼接层Flat1对Conv3的输出进行降维,拼接层的输出将作为BERT模型的输入。
为了获取分类结果,本文在BERT的输出层后级联一个由两层全连接层组成的分类器,分类器由全连接层和soft-max分类器组成。分类器的输出结果有5类,包含扫描攻击、DoS攻击、WebShell攻击、暴力破解攻击以及正常会话。在模型训练过程中,使用交叉熵函数作为损失函数对模型进行训练。
3.2 网络会话分类
单次网络会话由一系列有序报文组成,因此在网络会话分类中,研究解决将一系列单个报文的分类结果转换为网络会话类别,受网络会话长度不同的影响,无法直接使用深度学习模型对会话序列进行分类,根据上节分析,本文使用多数投票算法中的软投票法来确定会话的类别。

在实际应用投票算法中考虑到WebShell攻击的特点,一次WebShell攻击的会话中被判定为带有攻击载荷的报文数量只占少数部分,如果只保留投票结果中的最高平均概率,会导致只有少量恶意报文的会话类型被错误判定为正常会话,而无法启动蜜罐服务。考虑到上述情况,在本文中选取软投票中概率较大的前3种结果来启动云蜜罐服务。
3.3 蜜罐服务编排策略
对于制定蜜罐服务编排策略,需要明确基于云环境的蜜罐系统应当提供的蜜罐服务种类,开源蜜罐项目[12~13]中提供的部分蜜罐服务统计信息见表1。对现有蜜罐软件的统计分析和实现角度考虑,选择SSH蜜罐、Web蜜罐、Telnet蜜罐和SQL蜜罐服务作为编排基础。

表1 部分蜜罐服务类型及说明
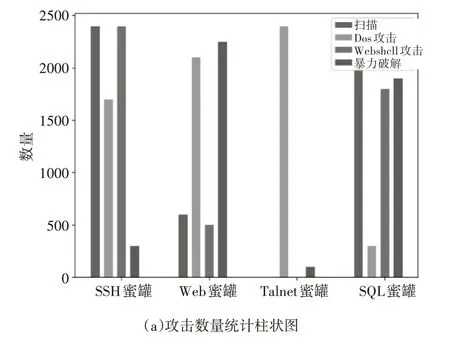
蜜罐与流量关联关系的分析基于蜜罐捕获的报文数据集进行。数据集中包含捕获的多种攻击类型的流量。本文中使用IEEE Dataport上公开的蜜罐捕获数据集DWCAIH,该数据集内包含在HoneySELK环境中捕获网络攻击报文数据,数据收集 时 间 涉 及2016年、2017年 和2018年。Honeys ELK的开发目的是在巴西利亚大学电气工程系的研究实验室内实时控制、捕获、分析和可视化新的和未知的攻击[10]。在数据集DWCAIH的描述文件中,数据集制作者给出了不同蜜罐服务类型和服务所在端口,因此本文对数据集DWCAIH按照端口对会话进行提取,获得会话后利用报文分类模型和头片机制对会话进行分类,统计结果如图3所示。
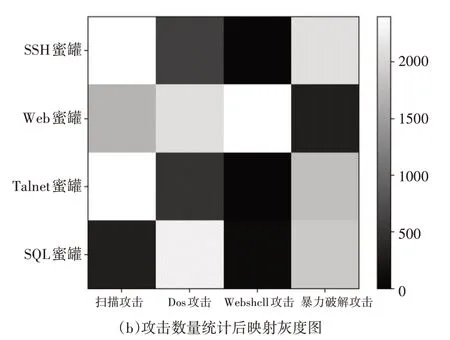
图3 蜜罐捕获网络攻击数量分布
报文统计数据映射为灰度图像后,采用自适应算法Otsu获取分割阈值,对于输入的灰度图像,其像素数为256,灰度级的取值范围取为[0,255],ni代表灰度级为i的像素点数量,Pi代表灰度级为i的点出现的频率,则:
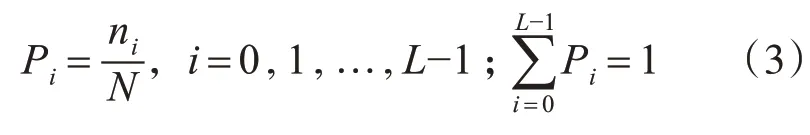
根据灰度值特征,基于阈值t把图像中的像素点归类为背景类和目标类,分别用C0和C1表示。C0中元素灰度值的取值范围为[0,t]之间,C1中元素灰度值的取值范围为[t+1,L-1]之间。整幅图像的灰度均值为

C0和C1的均值为
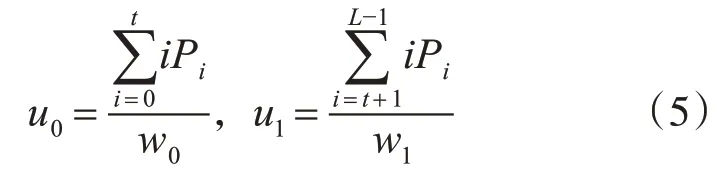
综合上述公式可得:

其中,t∈[0,L-1],使类间方差取值最大的t值即为理想分割阈值,得到分割阈值后,对各类蜜罐下的捕获攻击类型进行过滤,保留网络攻击与蜜罐强相关的一对多映射关系,用于检测到攻击时启动相应蜜罐服务。
映射关系具体如下,扫描攻击与SSH、Web、Telnet蜜罐服务对应;DoS攻击与Web、SQL蜜罐服务对应;WebShell攻击与Web蜜罐服务对应;暴力破解攻击与SSH、Telnet、SQL蜜罐服务对应。
4 实验分析与结果
4.1 实验环境
本文针对云蜜罐服务的编排方法搭建了如图4所示的蜜罐系统实验环境,将蜜罐与云计算环境结合,引入Openstack环境作为所有蜜罐底层虚拟化的提供者,便于蜜罐服务的编排。实现环境在VMware ESXi系统上虚拟私有云Openstack所需的5台节点计算机(1台控制节点、3台计算节点和1台存储节点)。
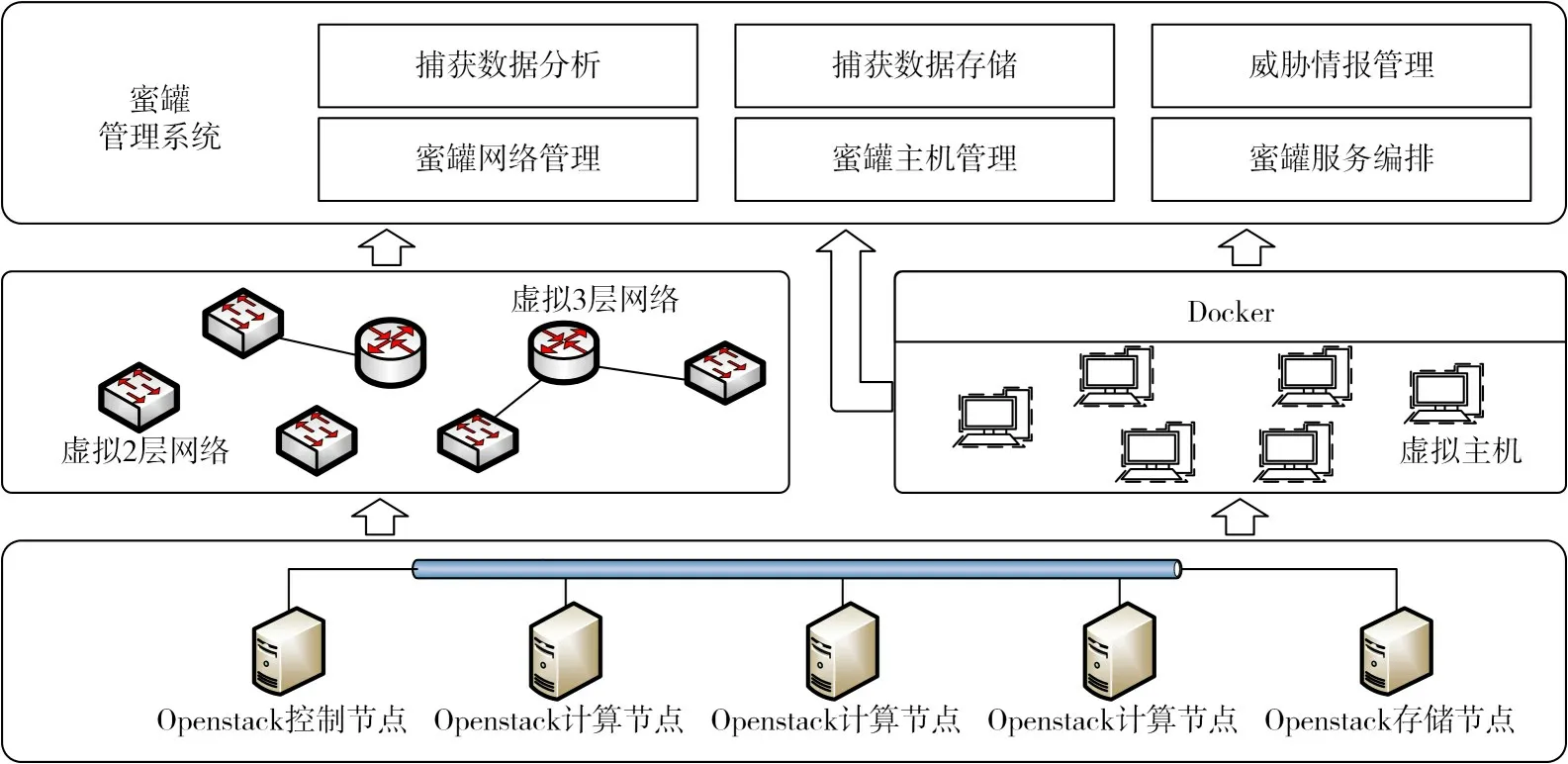
图4 面向云平台蜜罐的系统组成
4.2 评价指标
实验结果的评价指标主要为各个类别的准确率和可信度,类别准确率和可信度分别按照式(7)、(8)计算。

上式中TPi(True Positive)指的是实际类别为i的样本中被分类模型正确预测的样本数。FNi(False Negative)指的是实际类别为i的样本文被分类模型误判为其他类别的样本数[14]。FPi(False Positive)指的是实际类别为非i的样本被分类模型误判为类别i的样本数量。
4.3 实验结果
报文分类模型训练中使用DWCAIH数据集,在单个报文分类结果上使用软投票计算会话类别,在训练集和验证集上的分类结果见表2。
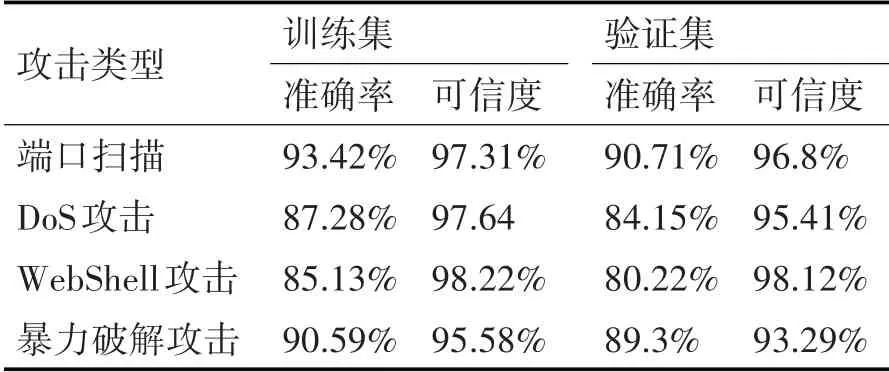
表2 网络会话分类指标统计
在系统环境中,随机选择DWCAIH数据集中报文进行地址映射和重放,使用报文分类模型作为探针,将检测为攻击的报文引流至蜜罐。分别在应用本文中提出的编排算法和直接启用所有蜜罐的条件下,记录蜜罐在CPU核数、内存等方面的开销,具体数据见表3。在本文实验中需要注意的地方是,Openstack对于虚拟机CPU、内存等开销的计算以虚拟机的配置为准,而不以虚拟机运行过程中实际使用量来计算,例如设置了CPU为1核、内存为2G的虚拟机硬件规格,当虚拟机启动时,Openstack管理端查看到的计算资源消耗即规格所指定资源,而不是虚拟机实际运行时占用。
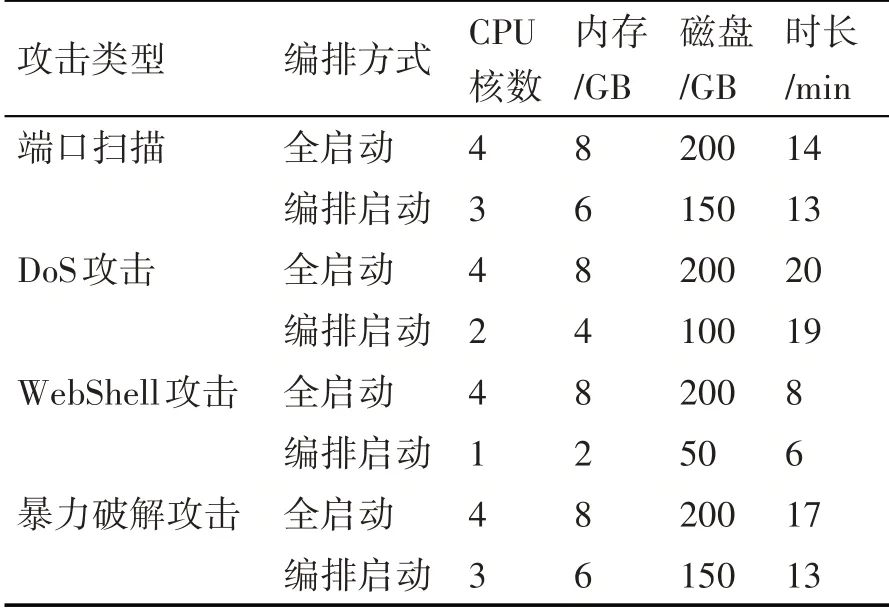
表3 蜜罐使用的计算资源统计
4.4 结果分析
实验结果主要分为两部分,首先是基于BERT的模型对网络会话分类的准确率平均在89.11%,其中WebShell的准确率对整体准确率影响较大,主要原因在于,数据集中包含WebShell脚本的报文较为复杂并且数量在整体数据集中占比小,存在小样本的问题。在蜜罐使用的计算资源统计中,编排启动方法无论是在资源消耗量还是时长上均优于以全启动的方式部署蜜罐。
5 结语
云蜜罐服务技术存在着计算资源消耗大的问题。本文提出了一种基于BERT模型的云蜜罐服务编排方法,主要利用深度学习模型BERT对流量进行分类识别,根据流量分配结果按需启动蜜罐主机,以降低云计算资源开销,并提高云环境下蜜罐系统的自动化程度。实验结果表明该方法能够对捕获流量进行准确分类,在平均准确率为89.11%的情况下,降低了大量部署蜜罐带来的资源开销。
猜你喜欢
汽车电器(2022年9期)2022-11-07
铁道通信信号(2020年4期)2020-09-21
中外文摘(2019年20期)2019-11-13
中国外汇(2019年11期)2019-08-27
知识窗(2019年6期)2019-06-26
系统管理学报(2018年3期)2018-08-13
中国三峡(2017年4期)2017-06-06
铁道通信信号(2016年8期)2016-06-01
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
