
基于卡尔曼滤波的含噪声小样本数据处理方法
2022-11-12 09:03刘芬范洪强吕涛李谦钱权
上海大学学报(自然科学版) 2022年3期
刘芬范洪强吕涛李谦钱权
(1.上海大学计算机工程与科学学院,上海200444;2.上海大学材料科学与工程学院,上海200444;3.上海大学材料基因组工程研究院材料信息与数据科学中心,上海200444;4.重庆大学材料科学与工程学院国家镁合金材料工程技术研究中心,重庆400044;5.之江实验室,浙江杭州311100)
在数据采集过程中噪声不可避免.这些噪声数据使得进行机器学习、数据挖掘等任务时产生不准确的输出,因此对噪声数据进行处理十分必要.传统的含噪声数据处理方法主要是通过一系列算法检测数据当中的噪声数据并删除[1].这种直接删除噪声数据的方法会损失该条记录的所有信息,因此更适用于数据量较大的数据集.当遇到小样本数据集时,由于数据本身很宝贵,因此需要设计新的处理噪声数据的方法,在充分利用数据信息的同时对噪声数据进行处理.
本研究提出了一种基于卡尔曼滤波的含噪声小样本数据处理方法.首先,结合领域知识,利用数据集背后的物理模型或经验公式,设计系统转移矩阵和系统控制矩阵,并建立系统模型;然后,利用得到的系统模型预测数据,并利用卡尔曼增益结合系统模型的预测结果和观测数据生成修正数据;最后,使用修正后的数据进行数据挖掘或其他数据分析任务.本方法基于卡尔曼滤波对数据进行修正,达到含噪声数据处理的效果,由于不需要删除数据,因此较适合小样本数据集.
1 相关研究
含噪声数据的处理方法主要有基于分箱的方法、基于模型的方法以及基于机器学习的方法.
1.1 基于分箱的方法
分箱方法是一种局部平滑法.将数据分成一个个“箱子”,然后将同一个箱子里面的数据进行取平均值、取众数、取中位数等方式进行平滑,以此达到数据去噪的效果,获得稳定的数据特征.常见的分箱方法有等深分箱法和等宽分箱法[2-3].等深分箱法是将数据平均分成n个箱子,每个箱子中的数据数目是相等的.等宽分箱法是将数据的值区间等分,每个箱子中的数据区间大小相同.
除了上述基本分箱法以外,还可以根据任务自定义分箱方法.Kerber[2]提出了一种ChiMerge分箱方法,用χ2统计量将连续属性值进行离散化.傅涛等[4]结合了基于分箱的Fuzzy C Means算法用于检测网络入侵数据.该方法用分箱方式划分数据集,解决了原Fuzzy C Means聚类算法频繁更换聚类中心的问题.
1.2 基于模型的方法
基于模型的方法是使用原数据训练一个回归模型,然后用训练好的模型对目标变量进行预测.若观测值与预测值相差过大,则被视为噪声数据.对于时序数据主要有自回归(autoregressive,AR)模型、自回归移动平均(autoregressive integrated moving average,ARIMA)模型[5]等方法.Li[6]提出了一种基于支持向量回归模型的图像去噪方法,在带有真实标签的含噪声图像上进行训练,得到了多个支持向量机模型及其权重.然后,利用训练好的支持向量机及其权值,对受到不同程度随机噪声影响的图像进行逐像素点去噪.L´opez-Rubio等[7]提出了一种基于核回归的磁共振三维图像去噪算法,改进了传统核回归方法,使其适应符合Rician分布的噪声.Huang等[8]提出了基于低秩判别的最小二乘回归模型,用来消除标签空间的噪声.Bai等[9]利用图像序列数据中不同像素的振幅变化特征,对每个像素的相应时间序列施加高斯过程(Gaussian process,GP)模型,并通过GP回归进行图像序列数据去噪.
1.3 基于机器学习的方法
基于机器学习方法是用机器学习模型对数据进行处理,然后通过某种方式检测噪声数据.何添等[10]提出了基于维诺图(Voronoi diagram,VOD)和K-Means算法的噪声数据处理方法,通过K-Means算法对原数据进行聚类,再通过VOD方法检测噪声数据.Dong等[11]提出了一种基于聚类的图像数据的稀疏表示去噪算法.通过变分方法结合局部图像模型和非局部图像模型各自的优点:一方面通过构建一个基本函数字典提高稀疏性;另一方面通过聚类将稀疏性与图像源的自相似性联系起来.胡娇娇[12]提出了基于卷积神经网络的噪声处理模型,将噪声数据处理转化为分类或预测问题.Zhang等[13]提出了一种基于神经网络的小波域图像去噪方法.首先对带噪图像进行小波变换得到子带,然后用训练好的分层神经网络对每个子带进行小波变换,得到去噪后的小波系数,最后对去噪后的小波系数进行反变换得到去噪后的图像.Mozhde等[14]提出了一种基于离散小波变换和人工神经网络(discrete wavelet transform-artificial neural network,DWT-ANN)的自适应算法,过滤嘈杂环境中的肺声信号数据.该算法结合离散小波变换的多分辨率特性与人工神经网络的非线性特性,设计了不同信噪比下的独立模型.通过集合这些独立模型来消除输入信号的信噪比信息,便于后续去噪操作.Yao等[15]提出了一种多尺度残差融合网络(multi-scale residual net,MRF-Net)用于图像数据的去噪.该网络综合了图像的空间和上下文信息,首先通过扩张卷积层扩大网络的接受域,然后进行多尺度特征提取形成多级特征图,最后将多级特征图进行残差融合生成残差图像,用于去除图像噪声.
现有的噪声数据处理方法还存在一些问题.基于分箱的方法要求处理的数据具有一定的规模,若数据样本过少,则数据分箱之后取平均值、众数或中位数等方式的平滑效果就会大打折扣.这是因为在数据量较少的情况下,很难通过统计的方式得到数据的分布规律.基于模型的方法和基于机器学习的方法本质上是通过一定的手段检测出噪声数据,然后将噪声数据去除以达到降噪的目的.但直接去除整条噪声记录会损失大量信息.尤其是面对小样本噪声数据时,若直接去除某条噪声数据会损失很大比例的信息资源.因此,针对小样本噪声数据需要设计新的去噪方法.
本工作提出了一种基于卡尔曼滤波的噪声数据处理方法,结合了模型方法中的回归以及分箱方法中的平滑技术.卡尔曼滤波处理方法将数据视为系统的状态,通过数据的经验公式建立系统的状态转移模型和状态控制模型,以此来预测系统的状态,得到系统预测数据.最后,通过观测数据修正系统预测数据,得到最后的修正数据.该修正数据即为降噪之后的数据.卡尔曼滤波处理方法通过修正数据的方式来达到降噪的效果,不用删除数据,更加适用于小样本数据.
2 基于卡尔曼滤波的含噪声小样本数据处理模型
2.1 卡尔曼滤波
卡尔曼滤波是一种线性二次估计方法[16].该方法利用系统的动态模型,通过系统的控制输入数据以及观测数据来对系统的状态量进行估计.该方法相比只使用动态模型获得的估计值更准确,是一种常用的模型数据和观测数据融合的算法.卡尔曼滤波的基本思想如图1所示.
首先,卡尔曼滤波器根据k-1时刻得到的系统状态的最终估计^xk-1(见图1中的黑色曲线),产生k时刻系统状态的预测估计^x-k(见图1中的绿色曲线).然后,根据k时刻系统的测量估计yk(见图1中的蓝色直线),将预测估计以及测量估计根据相应的“权重”进行融合,产生k时刻系统状态的最终估计(见图1中的红色曲线).这里的“权重”是由预测系统的不确定性和观测系统的不确定性综合得出.以上过程在每一个时间步重复,得到每一个时间步系统状态的最终估计.最终状态位于预测状态和测量状态之间,比任何一个单独状态都具有更好的不确定性估计.
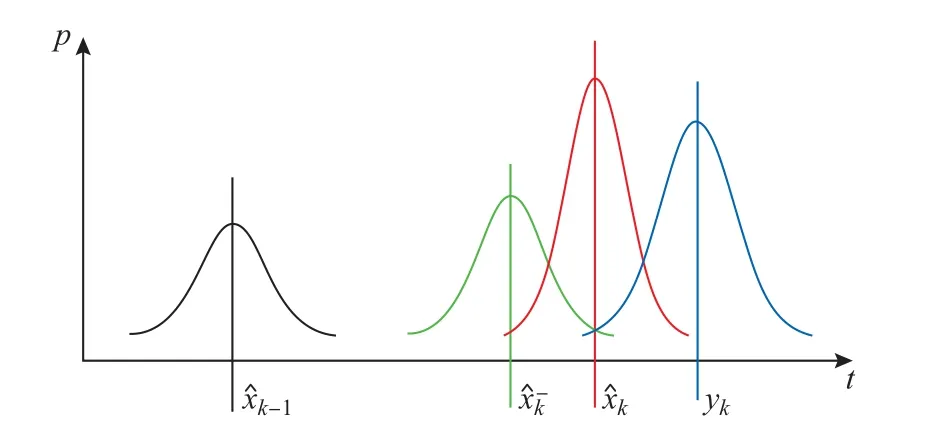
图1 卡尔曼滤波示意图Fig.1 Diagram of Kalman filter
在卡尔曼滤波中,一般线性离散系统可以表示为

式中:X(k)代表k时刻的系统状态向量;Z(k)代表观测向量;u(k)代表输入向量;v(k)代表m维测量噪声向量;A(k+1,k)代表从k时刻到k+1时刻的系统状态转移矩阵;B(k+1,k)代表从k时刻到k+1时刻的系统控制矩阵;H(k+1)代表k+1时刻的预测输出转移矩阵.式(1)被称为状态方程,式(2)被称为测量方程.
卡尔曼滤波算法包括预测和更新两个阶段,其流程如图2所示.在预测阶段,卡尔曼滤波器根据式(3)产生预测模型对当前状态变量的估计,根据式(4)产生当前系统噪声的协方差,即
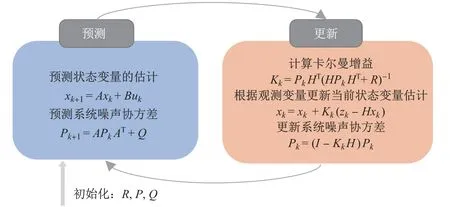
图2 卡尔曼滤波算法迭代图Fig.2 Iteration diagram of Kalman filter algorithm
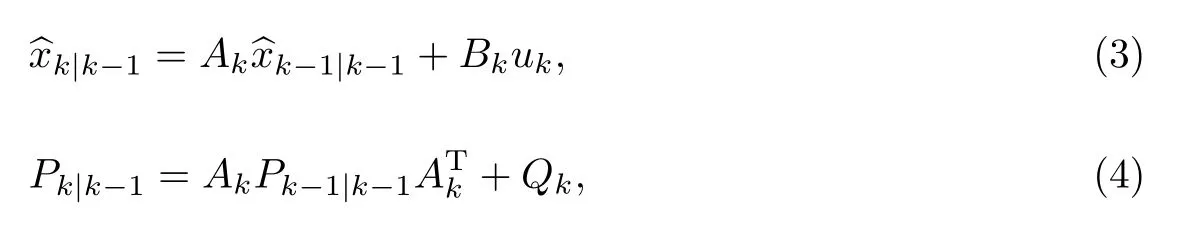
当系统观察到下一个观测数据(观测数据会有一定的误差,如随机噪声等)时,进入到更新阶段.卡尔曼增益的计算公式为
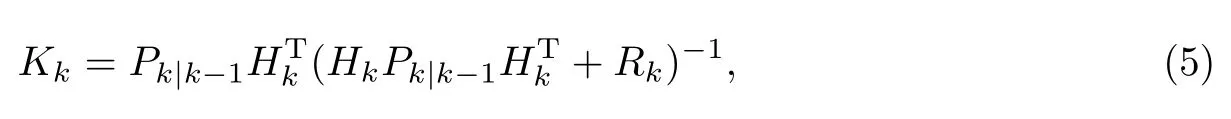
式中:K表示卡尔曼增益;H表示预测输出转移矩阵,即从预测估计到测量估计的计算方式;R代表测量误差协方差.
根据式(6)更新当前系统状态量的估计,根据式(7)计算下一时刻需要用到的估计协方差矩阵,即
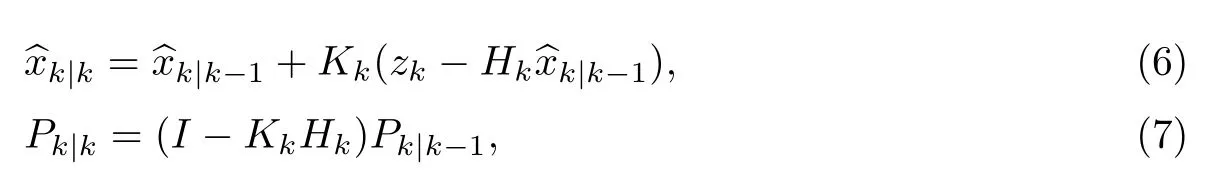
式中,z代表观测数据.
卡尔曼算法是迭代的,不断重复预测和更新步骤.它可以实时运行,仅使用当前输入测量值和先前计算的状态及其不确定性矩阵,不需要额外的历史信息.
2.2 扩展卡尔曼滤波
基本卡尔曼滤波要求必须是线性系统,但大部分都是非线性系统,其中的“非线性性质”既可能存在于过程模型(process model)中,又可能存在于观测模型(observation model)中,或者二者都有.当处理非线性系统时,常用扩展卡尔曼滤波[17].
在扩展卡尔曼滤波中,系统的状态转移模型和观测模型如式(8)和(9)所示,二者只要是可微函数即可,并不要求是线性函数.

式中:函数f用于从过去的估计值中计算预测的状态;函数h用于以预测的状态计算预测的测量值.f和h不能直接计算协方差,需要计算它们的偏导矩阵(Jacobian矩阵).状态转移模型和观测模型的Jacobian矩阵计算如下:

在解决了f和h不能直接计算协方差的问题后,扩展卡尔曼滤波的迭代方程如式(12)~(16)所示.在预测阶段,根据式(12)计算预测模型对当前状态变量的估计,根据式(13)计算当前系统噪声的协方差,即当系统观察到下一个观测数据时,进入到更新阶段.根据式(14)计算卡尔曼增益,根据式(15)修正模型得到的数据,根据式(16)更新系统噪声的协方差P,为下一步迭代做准备.与卡尔曼滤波一样,扩展卡尔曼算法也是迭代的,不断重复预测和更新步骤.
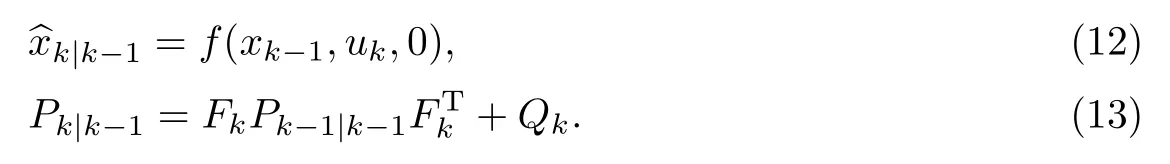
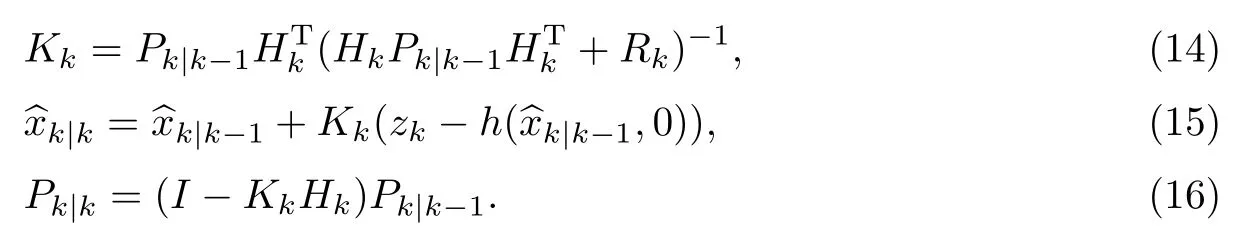
观察卡尔曼滤波的计算公式(式(3)~(7))以及扩展卡尔曼滤波的计算公式(式(12)~(16))可以看出,二者几乎是一样的,只是由于非线性系统无法直接计算状态转移模型和观测模型的协方差矩阵,因此将卡尔曼滤波计算过程中的状态转移矩阵A和状态控制矩阵B替换为相应的偏导矩阵Fk和Hk.观察Fk和Hk的计算公式可以看出,扩展卡尔曼滤波相当于把系统在k时刻按照k-1时刻的方程进行线性化,即系统当前时刻的值等于前一时刻的值加上前后两时刻值之间的变化量.实现方法为不断迭代计算系统在前一时刻的偏导矩阵值.
2.3 基于卡尔曼滤波的含噪声小样本数据处理模型
本工作提出的基于卡尔曼滤波的含噪声小样本数据处理方法的流程如图3所示.首先,对原数据进行处理,用线性模型对数据进行拟合,得到初步的线性模型参数.其次,根据线性模型参数,建立卡尔曼滤波模型中的系统状态转移矩阵和系统状态控制矩阵.再次,根据得到的系统状态转移矩阵和系统状态控制矩阵建立系统模型,结合系统模型得出的结果与观测数据,对原数据进行修正.最后,根据修正得到的数据进行后续的数据挖掘应用.

图3 基于卡尔曼滤波的含噪声小样本数据处理流程Fig.3 Flow chart of noisy sample data processing based on Kalman filter
3 含噪声材料数据处理实验
3.1 数据集
金属腐蚀在自然界中广泛存在,研究耐腐蚀金属已成为材料研究领域的热点[18-20].耐候钢是一种通过在普通钢中添加一定量合金元素所制成的低合金钢,具有较强的耐腐蚀性[21].耐候钢在初期和普通碳钢一样也会锈蚀.但随着合金表面的腐蚀发展,可以在表面形成一层致密的非晶态锈层组织,这层致密锈层是其抗大气腐蚀的关键[22-23].低成本、高强度、高耐腐蚀性的耐候钢开发已成为热点[24],因此对耐候钢腐蚀失效数据的研究十分必要.
本工作以实验室腐蚀加速模拟所获得的BC500耐候钢腐蚀失效数据集为例,提出了一种基于卡尔曼滤波的含噪声小样本数据处理方法,用于处理耐候钢腐蚀失效数据中的数据噪声,便于后续的腐蚀失效数据拟合等任务.耐候钢腐蚀失效数据集包含90条记录,每30条记录为一组,共分为3组,编号为Data1、Data2和Data3,分别代表一次耐候钢腐蚀实验.数据集共含有7维特征:温度、湿度、工业污染物(Na2SO4、NaHCO3和NaNO3)浓度、光照、腐蚀时间.目标变量为耐候钢的腐蚀速率.任务目标为处理该数据集中的噪声,为后续拟合耐候钢的腐蚀速率做准备.
3.2 实验设置
耐候钢的大气腐蚀动力学[25-28]可以表示为

式中:ΔW为腐蚀增重(mg);N为腐蚀时间(h),当腐蚀时间N=1时,F=ΔW.F和n为常数,其中F是作为测试样品初始腐蚀速率的度量;指数n反映了腐蚀动力学的特性.n<1表示腐蚀进程受到抑制;n>1表示腐蚀进程受到加速;n=1表示腐蚀速率恒定.n值越小,表明该阶段的腐蚀强度越小.n的取值与耐候钢所处的环境密切相关.
对式(17)等号两边各取自然对数,推导出式(18).从式(18)可以看出,对耐候钢的大气腐蚀增重ΔW和腐蚀时间N分别取对数后,二者呈线性关系,即

在本实验数据集所涉及到的腐蚀因素(特征)中,温度、湿度、工业污染物浓度、光照这些特征会影响材料的腐蚀速率,即影响式(17)中n的大小.将数据中的腐蚀速率与对应的时间相乘,可以得到式(17)中的腐蚀增重ΔW.根据式(18)所示的lnΔW和lnN的关系,可以用线性模型拟合数据初步建立腐蚀动力学方程.假设线性模型的拟合结果为

式中:x代表输入(lnN);y代表输出(lnΔW);k和b代表线性方程的斜率和截距.根据线性拟合结果,可计算得出F和n的值,即

综上,根据线性拟合结果,已建立了一个耐候钢腐蚀增重的系统模型,其中大气腐蚀增重ΔW被视为系统状态;系统的状态转移矩阵A设置成值为1的单元素矩阵;系统的控制转移矩阵B设置成值为F的单元素矩阵,F的值由式(21)给出.由于实验所用的数据集为每12 h采集一次,因此系统的输入设置为12n,n的值由式(20)给出.系统模型可以描述为
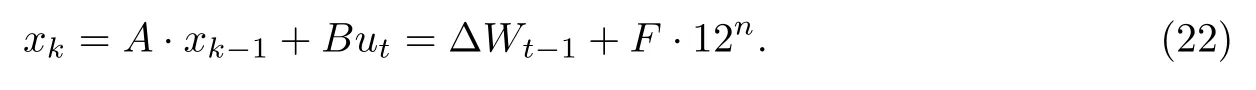
由于本实验数据集中观测变量即为系统状态,因此将预测输出转移矩阵H设置成值为1的单元素矩阵.考虑到测量会造成噪声干扰,因此引入观测噪声σz,系统的测量方程为
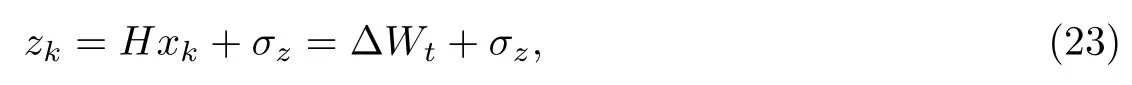
式中,zk为观测变量,噪声服从均值为0的正态分布.
初始化估计协方差矩阵P和预测模型的误差协方差矩阵Q.根据系统模型公式,本工作所用的P和Q矩阵均为单元素矩阵.按照上述方法迭代进行卡尔曼滤波,其预测阶段的计算方法如式(22)和(24)所示,更新阶段的计算方法如式(25)~(27)所示.

经过卡尔曼滤波处理之后,原数据已经过修正,可用于下游任务模型.本工作所用的下游任务模型为差分整合移动平均自回归(autoregressive integrated moving average,ARIMA)模型和随机森林(random forest,RF)模型,用来预测材料数据的腐蚀增重.将时间当作输入,预测该时间下材料的腐蚀增重.
3.3 实验结果与分析
3.3.1 腐蚀动力学方程建模及卡尔曼滤波效果
本实验展示了通过卡尔曼滤波处理含噪声材料数据,来建立腐蚀动力学方程模型的结果,以及数据经过卡尔曼滤波处理后的修正效果.
表1展示了Data1、Data2和Data3共3组数据拟合的腐蚀动力学方程中的各项参数,其中b和k是线性拟合结果,n和A是系统状态转移矩阵及系统状态控制矩阵的相关参数.可以看出,3组数据的n指数均小于1,可见耐候钢在腐蚀进程中其腐蚀速率逐步受到抑制,腐蚀强度逐渐变小.图4为Data1、Data2和Data3拟合的腐蚀动力学方程的可视化结果以及经卡尔曼滤波处理后的效果.可以看出,卡尔曼滤波处理对含噪声数据具有一定的平滑效果,修正后的数据(橙色线)处于模型数据(蓝色线)和观测数据(绿色线)之间,且在一定程度上平滑了原数据中起伏过大(实验中引入的误差)的地方.
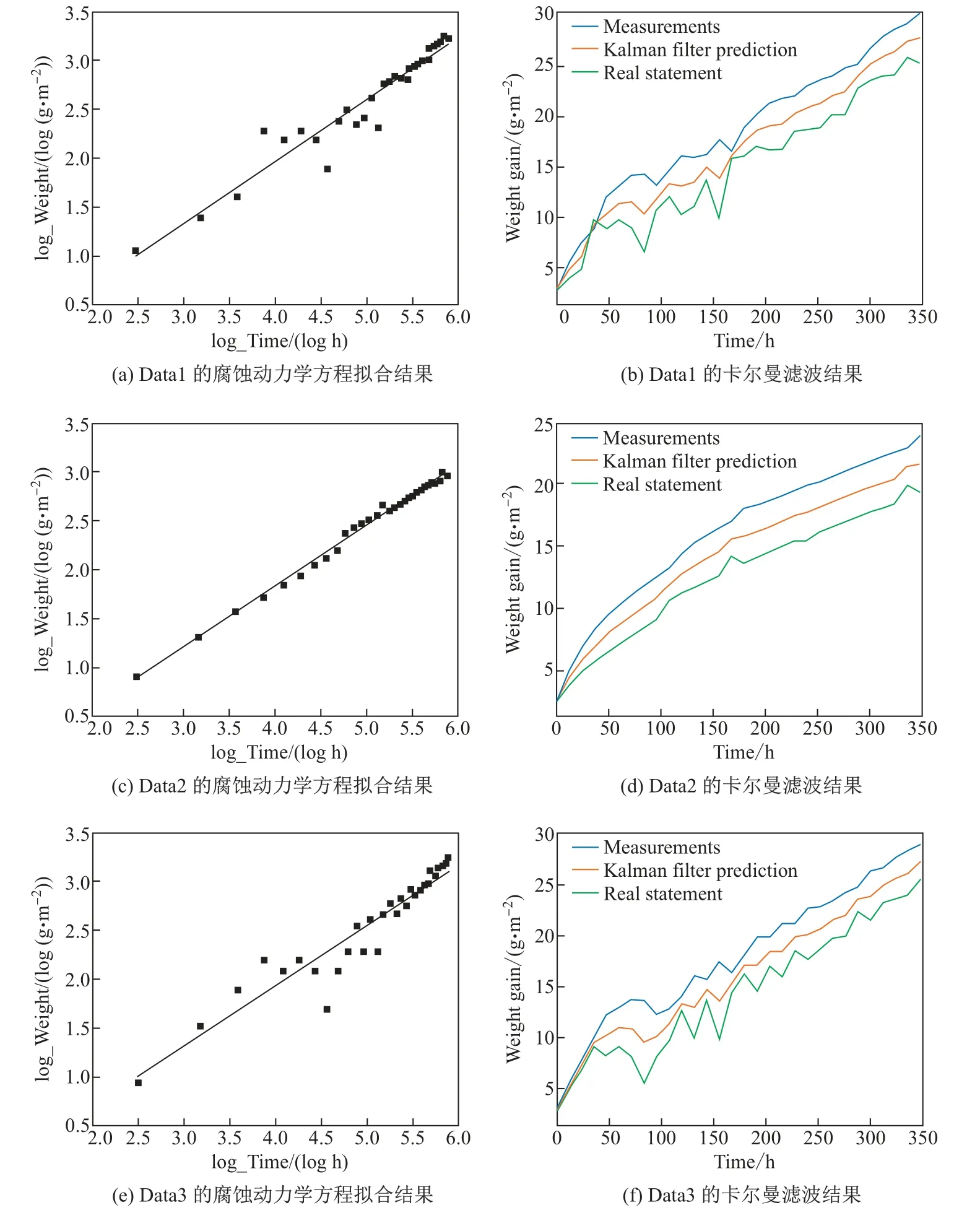
图4 数据集Data1、Data2和Data3的实验结果Fig.4 Experimental results of Data1,Data2,and Data3

表1 耐候钢数据腐蚀动力学方程参数拟合结果Table 1 Parameters estimation results of corrosion kinetics for weathering steel
3.3.2 不同系统噪声协方差对卡尔曼滤波效果的影响
卡尔曼滤波模型中有一个非常重要的参数Q(系统噪声协方差),用来表示状态转换矩阵与实际过程之间的误差.Q越小代表整个系统更加相信模型的结果,Q越大则代表整个系统更加相信观测数据的结果.图5显示了不同Q矩阵下数据集Data1的卡尔曼滤波结果.可以看出:当Q越小时整个系统更加偏向于模型的结果,因此橙色线更加接近蓝色线;当Q越大时整个系统更加偏向于观测数据,此时橙色线更加接近绿色线.不同的Q矩阵对数据修正的结果影响较大,因此需要选择合适的Q矩阵.
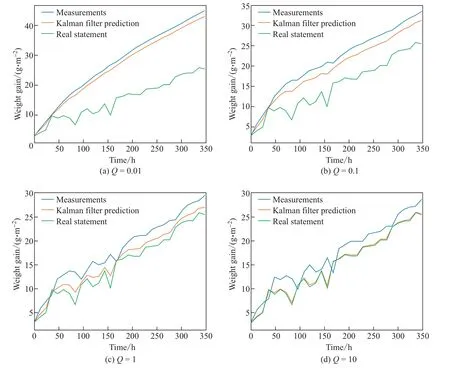
图5 数据集Data1在不同Q矩阵值下的卡尔曼滤波结果比较Fig.5 Data processing results of Data1 data under different Q matrix of Kalman filter
3.3.3 卡尔曼滤波处理噪声材料数据后的建模实验
为了验证本工作提出的方法对噪声数据的处理效果,分别测试了未经处理的数据和经过卡尔曼滤波处理的数据的实验效果.将时间当作输入,分别用ARIMA模型和RF模型来预测该时间下材料的腐蚀增重.
在ARIMA任务模型中,将每组数据(Data1、Data2和Data3)的前20条作为训练集,后10条作为测试集,用训练好的ARIMA模型预测后10个腐蚀增重,并计算结果的决定系数R2.在RF模型中,将每组数据的前25条作为训练集,后5条作为测试集,用训练好的RF模型预测后5个腐蚀增重,并计算结果的R2.ARIMA模型和RF模型的实验效果如表2所示,其中“Raw-Raw”列表示用未经过卡尔曼滤波处理的数据训练的模型,预测未经过卡尔曼滤波处理的数据的R2,“Kalman-Raw”列表示用经过卡尔曼滤波处理的数据训练的模型,预测未经过卡尔曼滤波处理的数据的R2.

表2 经卡尔曼滤波处理含噪声数据后的ARIMA回归和RF回归结果Table 2 ARIMA regression and RF regression results of noisy data processed by Kalman filter
由表2可以看出:在ARIMA模型中,“Raw-Raw”列中Data1和Data3的R2要小于Data2,这是由于Data1和Data3的观测数据具有更高的波动性(见图4),数据噪声较大,因此模型预测的R2较小,效果更差;“Kalman-Raw”列中Data1和Data3的R2要大于Data2,Data1的R2由0.863 0增加到0.943 5,Data3的R2由0.851 1增加到0.945 7,这说明经过卡尔曼滤波处理后,Data1和Data3数据中的噪声被平滑,模型的结果变好.Data2数据经过卡尔曼滤波处理后,其模型的R2反而变小.这是因为这组数据原本的噪声就比较小,而经卡尔曼滤波处理后反而引入了新噪声,对原数据产生了影响,模型结果变差.因此,卡尔曼滤波处理对本身就存在较大噪声的数据才会产生较为积极的影响.在RF模型中,“Kalman-Raw”列中的R2均大于“Raw-Raw”列.这进一步验证了卡尔曼滤波处理对含噪声数据会产生较为积极的影响(两个模型的R2平均提升了6.4%).对比表2中的数据可以看出,卡尔曼滤波处理对时间序列回归模型的影响较大,这是因为时序模型对数据噪声更为敏感.
3.3.4 扩展卡尔曼滤波处理噪声材料数据后的建模实验
本实验测试了扩展卡尔曼滤波对于噪声数据的处理效果.首先按照3.2节中所述方法建模得到了式(17)中F、n的值.假设式(17)的函数关系为f,则可得到

将腐蚀增重ΔW视为系统状态,在k时刻,扩展卡尔曼滤波把系统按照k-1时刻的方程进行线性化以适应非线性系统.将f(N)按照泰勒公式在Nk-1处展开,则系统模型描述为
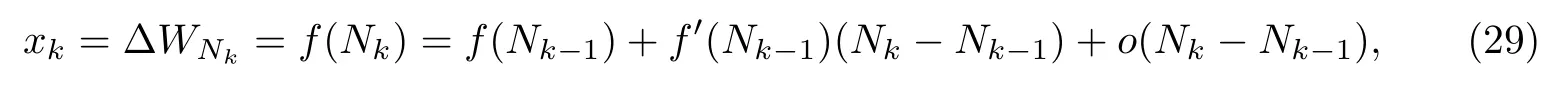
式中:xk为系统状态;N代表时间.系统的测量方程为

式中:zk为观测变量,噪声服从均值为0的正态分布.
由式(29)和(30)可知,系统状态转移模型和观测模型分别为非线性模型和线性模型,因此相应的Jacobian矩阵分别为f′(Nk-1)和值为1的单元素矩阵.已知系统的状态转移模型、观测模型以及二者相应的Jacobian矩阵,然后按照式(12)~(16)进行扩展卡尔曼滤波迭代,对原数据进行扩展卡尔曼滤波处理,用于同3.3.3节的下游任务.
分别测试了经过扩展卡尔曼滤波处理过后的数据在ARIMA模型和RF模型上的实验结果,如表3所示.可以看出,虽然经过扩展卡尔曼滤波处理之后的含噪声数据,其R2也有所增加,但对比3.3.3节的实验结果,扩展卡尔曼滤波处理的效果略差于卡尔曼滤波处理,但差别不大(两个模型的R2平均提升了4.9%).这是由于本实验中的材料数据取自然对数后符合线性关系,因此经扩展卡尔曼滤波处理后效果不明显.
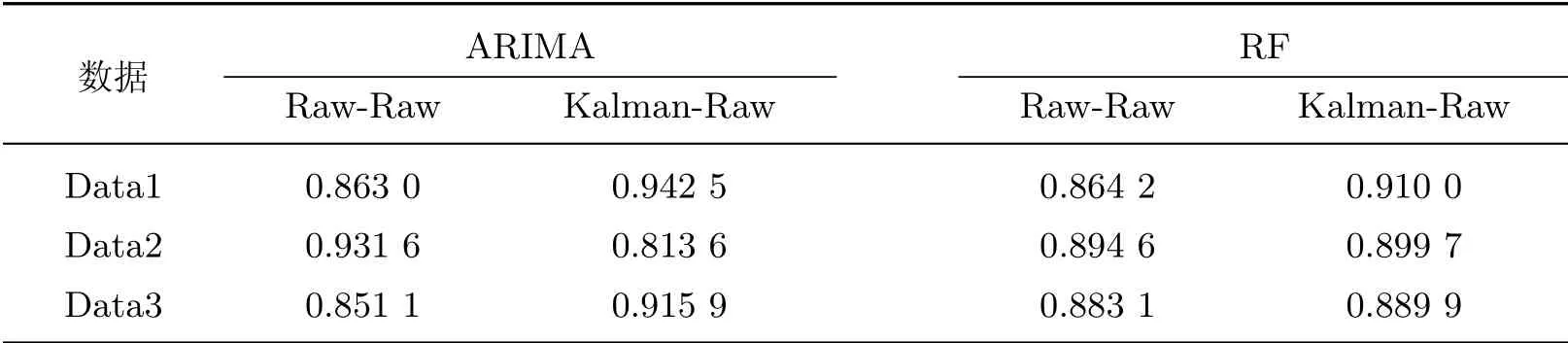
表3 经扩展卡尔曼滤波处理含噪声数据后的ARIMA回归和RF回归结果Table 3 ARIMA regression and RF regression results of noisy data processed by extended Kalman filter
4 结束语
本工作提出了一种基于卡尔曼滤波的含噪声小样本数据处理方法.首先,结合领域知识,用数据集背后的物理模型或经验公式拟合初步模型,得到系统状态转移矩阵和系统控制矩阵.然后,根据得到的系统状态转移矩阵和系统状态控制矩阵建立系统模型.最后,综合系统模型得出的结果与观测数据,得到最后的修正数据.
与传统的噪声数据处理方法不同,卡尔曼滤波处理方法不会直接删掉噪声数据,而是通过系统模型的计算结果与观测数据融合,对原数据进行平滑,从而达到去噪的效果.该方法对小样本数据更加友好,通过修正数据既达到了降噪的效果,又不会因为删去噪声而损失宝贵的材料数据样本.BC500腐蚀数据的实验结果表明,卡尔曼滤波处理含噪声数据取得了较好的效果,Data1预测的R2由0.863 0增加到0.943 5,Data3的R2由0.851 1增加到0.945 7.实验结果还表明,卡尔曼滤波处理对时间序列模型影响更大,在时间序列模型上取得了更好的效果.
Q矩阵代表的是系统噪声协方差.该超参数被用来表示状态转换矩阵与实际过程之间的误差.Q越小代表整个系统更加相信模型的结果,Q越大则表示整个系统更加相信观测数据.因此,选择合适的Q矩阵对实验结果的影响较大.由于难以获得噪声协方差矩阵Q的良好估计,本工作仅通过实验不同Q值对结果的影响找到了一个较为合适的Q值,但如何从数据中估计协方差,可作进一步研究.例如,采用自协方差最小二乘[29-30]、场卡尔曼滤波器[31]等来自动估计系统噪声协方差.
猜你喜欢
物联网技术(2022年7期)2022-07-21
农业与技术(2022年12期)2022-07-04
电脑报(2022年24期)2022-07-01
舰船科学技术(2021年12期)2021-03-29
智富时代(2019年5期)2019-07-05
智富时代(2019年5期)2019-07-05
读与写·教育教学版(2017年10期)2017-11-10
电脑知识与技术(2016年27期)2016-12-15
饮食科学(2016年7期)2016-07-27
南都周刊(2015年4期)2015-09-10
