
基于深度学习的语声抑郁识别*
2022-11-21 01:11吴情胡维平陈丹丹肖婷
应用声学 2022年5期
吴情 胡维平 陈丹丹 肖婷
(广西师范大学电子工程学院桂林 541000)
0 引言
抑郁症属于一种精神疾病,在临床上主要表现为明显的长久性心境低落,主要由心理、生理等因素引起,影响着患者的日常生活,长期性的治疗会造成极大的经济负担,并可能导致极端的厌世,做出自杀等行为,需要及时治疗[1]。
可喜的是,抑郁症是一种可以治愈的疾病。目前,诊断抑郁症的主要方法是靠医生根据患者对症状的自我报告和心理健康问卷进行临床评估,这种诊断方法的准确度主要依赖于患者对治疗的配合程度、对问卷的理解程度以及医师的专业水平和经验。随着社会的飞速发展,人们处于快节奏、高压力的生活中,抑郁症患者数量不断攀升,抑郁症的诊断面临着医生短缺的问题。因此,通过计算机技术提供一种客观有效的方法迫在眉睫。
近年来,很多研究者致力于利用生物、生理、行为等多模态去对抑郁症患者的患病情况进行评估,语声、血浆蛋白、面部表情、眼球移动、体态、步态、脑电、核磁等多种信息被用于抑郁识别的研究之中。由于声音状态与情绪密切相关[2],且语声具有非侵入、易获取、低成本等优势,基于语声信号的抑郁检测成为近几年的研究热点之一[3]。
语声情感识别的通常做法是先进行特征选择。特征的选择直接关系到情感识别结果的好坏,常用的声频特征有梅尔频率倒谱系数(Mel-frequency cepstrum coefficient,MFCC)[4]、语谱图[5]、共振峰[6]等。提取特征后再采用分类算法来研究特征与抑郁程度之间的关系,分类方法分为机器学习和深度学习两类,经典的机器学习方法包括高斯混合模型(Gaussian mixture model,GMM)、支持向量回归(Support vector regression,SVR)、随机森林(Random forest,RF)[7]等。随着近几年计算机的发展,深度学习取得了突破性的进展,与机器学习方法相比,深度学习可以更好地提取高层语义特征,适应性强,易于迁移。
国外对语声抑郁识别的研究相比国内较早,一些研究人员发现并证实了人的声频特征与抑郁症之间有着明显的相关性,这给利用语声信号来识别抑郁症提供了理论基础。Rejaibia等[8]提出将MFCC及基频特征送进卷积神经网络(Convolutional neural networks,CNN)进行识别,证明了MFCC在抑郁识别中的有效性。He等[9]利用语声信号提取改进的语谱图特征和eGeMAPS(Extended Geneva minimalistic acoustic parameter set)特征集,利用深度卷积网络通过特征融合进行识别,证明了改进的语谱图特征效果较好。Sun等[10]利用级联的RF进行语声、文本及视频的多模态抑郁识别,发现RF分类对抑郁识别有着较好的效果。Ma等[11]提出了一种基于CNN+长短期记忆神经网络(Long-short term memory,LSTM)的深度模型DeepAudioNet用于处理语声抑郁信号的语谱图特征,证明了该模型的有效性。
国内对语声抑郁识别研究较为著名的是兰州大学的普适计算实验室基于国家973项目支持[12],与北京安定医院和兰州大学第二附属医院等著名医院合作,通过实地采集被试者的语声信号,基于语声分析进行抑郁症识别并评估被试者抑郁的严重程度,整个实验的过程全部是由该实验组完成,未采用国外的抑郁症语声库,通过实验达到78.9%的识别率。考虑到患者隐私等问题,其数据集是不对外公开的,无法获取。湖南师范大学从生物信息研究方向出发,利用医疗上功能磁共振方法从医学专业层面来进行抑郁症识别,实现了84.21%的识别率,该研究方法也为国内现阶段基于生理信号进行抑郁症识别起到了一定程度上的借鉴意义。刘美[13]从语声出发,利用语谱图特征,结合生成式对抗网络和CNN来进行抑郁症识别,实现了62%的识别率。
本文探究了几种经典的传统手工特征对抑郁症识别的效果,在基础的LSTM模型上引入注意力机制,通过对比发现,注意力机制对于语声抑郁识别效果有着一定的提高,在此模型的基础上进行改进,提出了CNN和结合注意力机制的双向长短时记忆
(Bidirectional long short-term memory,BLSTM)
特征融合模型,经过实验测试,取得了较好的语声抑郁识别结果。
1 分类算法
1.1 结合注意力机制的BLSTM模型
注意力机制的提出受人类自身的启发:比如在看一个场景的时候,不会每次都把场景内的所有东西全部看一遍,而是只看感兴趣的东西[14]。换句话说,如果最想看的那个东西总是出现在某一部分时,以后再在相似的场景中,就会把注意力放到这部分上,尽量不去看其他部分,节省时间以提高效率。
注意力机制最关键的部分就是计算一串权重参数,它从序列中学习每一个元素的重要程度,然后按重要程度将元素合并[15]。这串权重参数也称为注意力分配系数,它决定了给哪个元素分配多少注意力,权重参数越大,则代表这个元素对于结果更有效。
模型如图1所示,由两部分组成。第一部分是BLSTM,第二部分是注意力机制,它为LSTM的隐藏状态提供了一组求和权向量。这些加权向量的集合与LSTM隐藏状态进行点乘,得到的加权LSTM隐藏状态被认为是最终的特征向量。

图1 结合注意力机制的BLSTM模型Fig.1 BLSTM model combining attention mechanism
假设一条声频有n帧,则可以用s表示:
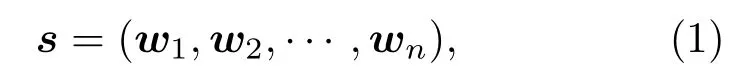
其中,wi代表语声中第i帧的特征向量,每一帧有d维,因此,s是一个n×d的二维矩阵。
首先,将s通过BLSTM,每个前向ht与后向ht连接起来得到一个隐藏状态ht。若每个单向LSTM的隐藏单元数为u,将所有n个ht记为H,它的大小为n×2u。然后通过注意力机制,将LSTM的整个隐藏状态H作为输入,首先将输入经过Dense层,且使用softmax变换将Dense层输出结果转化为[0,1]之间的数,确保所有计算出的权重之和为1,从而得到注意力权重a:

其中,ws1、ws2都是可以学习的模型参数,ws1大小为2u×d,ws2大小为d,则a的大小为n。
然后将a和LSTM隐藏状态H进行求和,得到输入特征向量表示m。向量m只集中在一帧中,它反映一帧语声中的情感,然而,一句语声中可以有多帧,它们共同构成整个语声句子的情感。为了完整全面地识别语声的整体情感,需要多个“m”。因此,可能需要进行多次注意力权重的计算。假设想要从语声中提取r个不同的部分,需将ws2扩展为一个r×d的矩阵,记为Ws2,由此得到的注意向量a成为注意矩阵A:

然后根据注意矩阵A提供的权值与LSTM隐藏状态H相乘,计算加权和,更新隐藏状态,得到最终的隐藏状态:
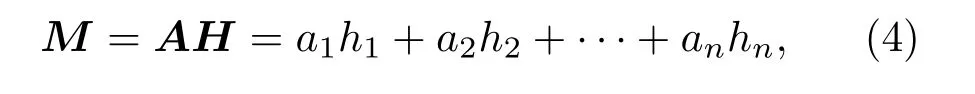
此时矩阵M大小为r×2u,A为r×n。
最后,把矩阵M送进全连接层和softmax层进行最终的抑郁二分类。
1.2 改进的CNN和结合注意力机制的BLSTM特征融合模型
随着深度学习在语声情感识别上的广泛应用,基于CNN、循环神经网络和卷积循环神经网络的模型被广泛用于语声情感识别,然而这些模型都是单纯地使用了一种或者两种方法串行实现,并不能捕捉足够的情感特征。从各种文献中知道CNN可以有效地处理空间信息,而每个语声序列包含不同比例的抑郁情感信息,可以通过BLSTM上下文关系从语声中获取更丰富的抑郁特征。本文提出一种基于CNN学习的语声抑郁信息的空间特征和BLSTM-ATT上下文特征融合方法实现语声抑郁识别。模型如图2所示。

图2 基于CNN和BLSTM-ATT的特征融合模型Fig.2 Feature fusion model based on CNN and BLSTM-ATT
图2中CNN支路是由4个Conv2D black组成,而每个Conv2D black是个二维卷积块,里面由5个部分组成:
(1)二维卷积层:卷积核大小为3×3,步长为1,padding为1。
(2)归一化层:加速神经网络的收敛过程以及提高训练过程中的稳定性[16]。
(3)Relu层:引入非线性因素。
(4)最大池化层:核大小为4×4,步长为4×2,对特征进行压缩,减小模型大小。
(5)Dropout层:防止过拟合,提升模型泛化能力。
BLSTM-ATT支路是由一个最大池化层和一个结合注意力机制的BLSTM层构成,最大池化层核大小为2×4,步长大小为2×4,BLSTM的隐藏层单元个数设为128,最后通过拼接层将空间特征和上下文特征进行融合并分类。
2 实验测试
2.1 数据集
采用公开的遇事分析访谈语料库DAIC-WOZ中的数据集进行实验[17],该数据集共189条数据,其中抑郁56条,非抑郁133条,由189位参与者和一位虚拟采访者Ellie共同录制,每段语声时长7~33 min不等,采样率16 kHz。数据集包含录制的声频文件、参与者和采访者的对话内容记录、声频提取的Covarep特征集、声频提取的前5个共振峰特征以及医生根据参与者自身健康调查表得分结果进行的标签标记,标签中给出了问卷调查结果的具体分数、性别以及是否抑郁的标注,其中0为非抑郁个体,1为抑郁个体,根据这个二元标签进行对语声抑郁症的二分类。
2.2 数据预处理
剪接:将采访者的话语从原语声中剪掉,然后剔除被采访者话语中小于1 s的片段,最后将被采访者话语中大于1 s的片段进行拼接(原始语声包含参与者和采访者,是一问一答的形式,参与者的每句话都是对采访者问题的独立回答,是完整的一句话,没有语意中断,参与者小于1 s的语声回答一般是语气词或者礼貌用语和杂音,对于实验是不需要的)。
数据增强:本文采用的数据增强方法共有两种,包括添加噪声和改变音调[18]。(1)添加噪声:在语声中添加随机噪声,提高模型的泛化能力,噪声因子设为0.01。(2)改变音调:改变语声信号的音调,扩张倍数设为1.5。
语声切片:将拼接好的语声按15 s进行切分,总共得到5395个样本(其中80%用于训练,20%用于测试)进行训练和测试。
2.3 实验设置
2.3.1 特征提取
(1)MFCC:汉明窗,帧长25 ms,帧移10 ms,滤波器个数26,对189个声频进行分帧,最后每个声频得到(帧数,39)维数据。
(2)基频:汉明窗,帧长25 ms,帧移10 ms,最后每个声频得到(帧数,1)维数据。
(3)共振峰:将数据集里自带的声频前5个共振峰特征结合参与者和采访者的对话内容记录,将只有参与者声频的前5个共振峰特征提取出来,最后每个声频得到(帧数,5)维数据。
(4)语谱图:汉明窗,帧长500 ms,帧移250 ms,将一帧设为一个块(chunk),一组梅尔滤波器组包含128个梅尔滤波器,最后每个声频得到(128,126)维数据。
(5)Opensmile:使用的特征为Interspeech 2009 Emotion Challenge中的基准特征,所用窗函数为汉明窗,帧长25 ms,帧移10 ms。特征包含过零率、能量、基频、谐波噪声比1~12阶MFCC,共16维的低级描述符(Low-level descriptor,LLD),然后计算这16维LLD的一阶差分,可以得到32维LLD,最后在这32维基础上应用均值、标准差等12个统计函数,每个声频得到(1,384)维特征。
(6)Coverap:将数据集里自带的声频Coverap特征结合参与者和采访者的对话内容记录,将只有参与者声频的Coverap特征提取出来,特征包含基频、发声/不发声,归一化幅度参数、拟开熵、前两次谐波的振幅差异化声门的源谱、抛物面反射光谱参数、最大分散熵、峰值斜率、声门脉冲动力学、Rd_conf、0~24阶MFCC、谐波模型和相位畸变均值,最后每个声频得到(帧数,74)维数据。
2.3.2 实验测试
实验1结合注意力机制的BLSTM算法
用上述提取的手工特征,分别送进结合注意力机制的LSTM模型中对抑郁症进行分类,观察实验结果,模型如图3所示。以不加注意力机制的LSTM模型做实验对比(不加注意力机制模型除少了注意力机制模型外,其他参数和图3均相同),实验结果如表1和表2所示。

图3 手工特征结合注意力机制的LSTM模型Fig.3 LSTM model of manual features combined with attention mechanism

表1 不同的手工特征在没加注意力的LSTM模型上的性能对比Table 1 The performance comparison of different manual features on the LSTM model without attention
从表1和表2中可以看出,对于所探究的6个特征而言,网络加上注意力机制之后,分类效果都有一定的提高,其中MFCC、Opensmile、语谱图这3种特征对于语声抑郁识别有着较好的结果。加注意力机制时,MFCC的精确度达到77.19%,比不加时提高了2.5%,F1分数达到74%,比不加时提高了12%;Opensmile的精确度达到76.16%,比不加时提高了2.48%,F1分数达到76%,比不加时提高了13%;语谱图的精确度也提高了1.92%,F1分数提高了8.44%。由此可得出,注意力机制对于分类结果指标都有一定幅度的提高。

表2 不同的手工特征在加注意力的LSTM模型上的性能对比Table 2 Performance comparison of different manual features in the attentionadded LSTM model
实验2 CNN和结合注意力机制的BLSTM特征融合算法
实验1得出,在所研究的手工特征中,MFCC的效果最好,所以在实验2中,采用MFCC特征来进行实验,实验结果如表3所示。

表3 MFCC在基于CNN和结合注意力机制的BLSTM特征融合模型上的性能Table 3 Performance of MFCC in BLSTM feature fusion model based on CNN and combining attention mechanism
从表3的结果可以看出,由于实验2比实验1多了一条CNN支路以获取空间信息,对于语声信号的抑郁识别效果有了一定的提升,模型精确度达到78.06%,比实验1提高了0.87%;F1分数达到74.68%,比实验1提高了0.68%。
从两个实验和前人研究的结果中都可以看出,在语声抑郁识别的众多声频特征中,MFCC相对其他手工特征而言效果都是较好的,可能是因为梅尔频率反映了人耳的感知频率与声音的真实频率之间的关系,而MFCC就是在梅尔频谱的基础上提取的。两个实验也证明了注意力机制的加入,使网络的识别效果得到提升。
3 结论
研究发现,不同的语声特征对于抑郁症的识别具有不同的效果。本文对几个常用的特征进行了比较,客观地得出MFCC能较好且稳定地识别是否有抑郁症。本文在结合注意力机制的LSTM模型上进行改进,提出了基于CNN和结合注意力机制的BLSTM特征融合的语声抑郁识别模型,效果有了一定的提升。
目前语声抑郁识别具有一定的难度,因为涉及患者的隐私,所以对外公开的抑郁语声数据集很少,如何在数据集上进行数据扩充是有必要研究的。而且数据集中正负样本的数量相差很大,抑郁患者的数量远远小于非抑郁患者的数量,如何使数据达到平衡也是需要探究的。除此之外,人类情感具有模糊的边界,且一句话可能包含多种情感,比如抑郁和伤心的大多数语声特征是相似的,这就会造成识别混淆,所以如何实现长时语声的复杂情感识别,也是未来的研究方向。
抑郁症检测是一个较为复杂的研究课题,单纯语声参数不足以反映抑郁症患者的特点,在未来的研究中,可参考医生的经验,结合表情、眼神等图像特征,尝试用多模态方法来提高检测正确率。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
当代陕西(2019年9期)2019-05-20
文苑(2018年21期)2018-11-09
当代贵州(2018年21期)2018-08-29
第二课堂(课外活动版)(2016年2期)2016-10-21
Coco薇(2015年12期)2015-12-10
阅读(中年级)(2009年11期)2009-04-14
