
基于STA-CRNN模型的语声情感识别*
2022-11-21 01:11张志浩王坤侠
应用声学 2022年5期
张志浩 王坤侠†
(1 安徽建筑大学电子与信息工程学院合肥 230601)
(2 安徽建筑大学安徽省建筑声环境重点实验室(安徽建筑大学)合肥 230601)
0 引言
语声情感识别(Speech emotion recognition,SER)是“情感计算”研究领域的一个重要分支[1]。SER在人机智能辅助[2]、人机交互[3-4]、行为识别[5]等应用中发挥着重要作用。在人机交互中,通过输入的语声信号识别说话人的情感状态,可以起到监管、协助和指引的作用。因此SER的研究是一项关键并富有挑战性的任务[6-7]。
近年来,SER研究者们通过对多种特征和分类器的深入研究,使得SER的性能逐渐提高[8]。SER最显著的特征是从整条语声中计算出的一维的低级描述符(LLDs),例如能量、基频(F0)和Mel频率倒谱系数(Mel frequency cepstrum coefficient,MFCC)等[9]。这些特征可以全面地捕捉语声的情感信息,进而有效地改善SER的识别率。然而这些手工特征对于表征语声中的情感信息并不是最有效的,这可能导致性能不佳[10]。而卷积神经网络(Convolutional neural network,CNN)和长短期记忆(Long short-term memory,LSTM)网络在SER特征提取方面表现出卓越的性能[11]。这两种网络能够从大量训练样本中提取关键信息特征进而提高SER的识别率[12]。Mao等[13]提出利用CNN提取LLDs有效的语声情感信息,并在多个公开数据集上表现出优异的性能。Senthilkumar等[14]使用LSTM学习语声信号之间帧与帧的特征信息,获得了较好的SER结果。但是,传统的一维LLDs特征存在着频域信息缺失问题[15],因此,研究者们纷纷将语声信号转换成二维时频特征如频谱图、对数Mel频谱图(Log-Mel)等作为SER模型的输入,用来提取语声高级情感特征,与传统声学特征相比表现出更好的性能[16-17]。如Trigeorgis等[18]利用CNN和LSTM网络提取语声频谱图的时空特征,其实验结果要优于在一维特征上的实验结果。Zhang等[19]则将一维的语声信号转换为具有RGB三通道的频谱图,并将其作为CNN模型的输入。其实验结果表明,在三通道语声频谱图上进行SER的性能比一维特征优越。尽管上述研究者们利用频谱图作为特征并取得了较为不错的效果,但是在使用CNN或LSTM网络进行特征提取时,忽略了在情感识别方面语声频谱图的不同片段区域存在较大差异性。而模型对于图中有效的空间特征和时间特征的提取能力有限,导致大量的有效特征和无效特征冗余,从而限制了SER模型的性能。而注意力机制(Attention mechanism)则可以利用其加权机制来过滤掉冗余特征[20-22],捕获频谱图中的关键情感信息,有利于关键特征的提取与学习,进而提高SER识别率。
为了解决有效的情感特征提取问题,本文基于以上研究提出时空注意力-卷积递归神经网络(Spatiotemporal attention-Convolution recursive neural network,STA-CRNN)模型,即在CRNN模型中引入空间注意力(Spatial attention)[23]机制和时间注意力(Temporal attention)机制。在CNN进行空间特征提取时,空间注意力机制可以聚焦空间关键信息,使网络能够关注情感显著区域。在LSTM网络进行时间特征提取时,时间注意力机制可以对不同时间序列片段特征给予权重,提高有效特征的提取能力。
本文贡献如下:(1)提出了一种基于时空注意机制的CRNN网络模型,包括CNN和LSTM两个模块;(2)经过实验确定了空间注意力机制在CNN网络层中的最佳层间位置;(3)验证了时空注意力机制的CRNN网络模型能够明显提高SER识别率。
1 STA-CRNN模型结构
本文提出了一种基于时空注意力机制的CRNN模型。模型分为两大部分:基于空间注意力机制的CNN网络和基于时间注意力机制的LSTM网络。模型结构如图1所示,首先将Log-Mel谱图和其一阶、二阶差分组成三维Log-Mel谱图,输入到基于空间注意力机制的CNN网络中,充分提取其空间特征;其次将输出结果输入到基于时间注意力机制的LSTM网络中,再将得到的向量输入到全连接层中,进行Softmax分类,最终得到情感类别。

图1 STA-CRNN模型结构Fig.1 Structure of STA-CRNN
1.1 基于空间注意力机制的CNN网络
在CNN网络中,卷积模块包括6个卷积层、2个最大池化层和1个空间注意力层。卷积层的第一层和第二层有128个输出通道,池化层的大小为2×4。其他卷积层的输出通道为256,卷积核的大小为5×3,为了防止过拟合,在每个卷积后添加Relu、Drop和BN模块,并在最后一次卷积后,加入空间注意力层。
空间注意力的计算过程如下:首先将卷积模块输出的特征图作为空间注意力层的输入特征图,再对其做一个基于通道的最大池化(Maxpool)和平均池化(Avgpool)操作,并将它们连接起来生成一个有效的特征图,如公式(1)所示:
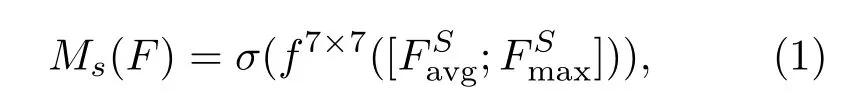
其中,f7×7表示7×7的卷积核尺寸,R1×H×W和分别表示通道上的平均池化特征和最大池化特征。
接着将这两个结果做融合和卷积操作,降维至一个通道。再经过Sigmoid生成空间注意力特征图。最后将该特征图和该模块的输入特征图做乘法,得到最终生成的特征。
1.2 基于时间注意力机制的BiLSTM网络
为了获取Log-Mel谱图的时间特征,采用基于注意力机制的双向长短时记忆网络(BiLSTM)对卷积模块的输出结果进行时间序列上的特征提取。LSTM主要由遗忘门、输入门、输出门以及隐藏状态所构成,具体的计算过程为
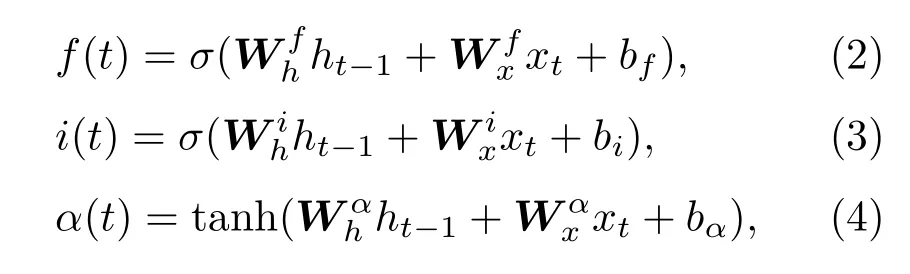
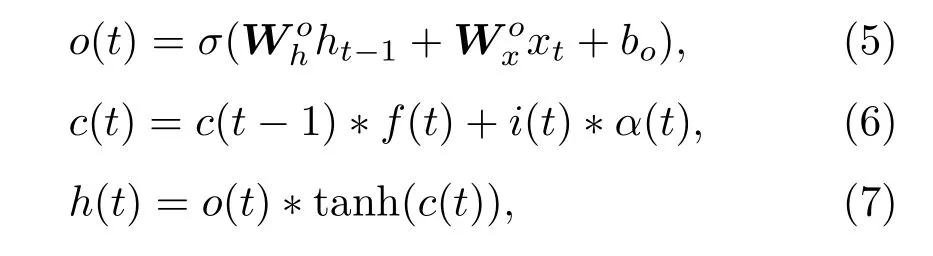
其中,f(t)、i(t)、o(t)、c(t)分别表示t时刻遗忘门、输入门、输出门的值,α(t)表示t时刻对ht-1和xt的初步特征提取。xt表示t时刻的输入,ht-1表示t-1时刻的隐层状态值。W表示权重矩阵,b为偏置值;tanh表示正切双曲函数,σ表示激活函数Sigmoid。
BiLSTM由两个LSTM层组成,并通过方向相反的两个LSTM层来提取信息,包括将来和过去的隐藏信息,最后拼接并输出,见公式(8):

在BiLSTM的基础上,添加一个时间注意力层,该注意力机制会根据式(9)计算出在不同时间序列,BiLSTM输出序列的权重参数,然后采用式(10)根据权重大小将编码序列中的每一个向量进行加权求μ和,最终得到attention数值,并通过Softmax分类器预测情感类别。

2 实验与分析
为了检验本文所提出模型的性能,选择柏林语声情感数据集(Emo-DB)[24]和交互式情绪二元运动捕捉(IEMOCAP)数据集[25]进行相关实验。
Emo-DB:该数据集由来自7种情绪状态(anger、boredom、disgust、fear、happy、neural、sad)共535个话语组成。库中的话语由讲德语的10名专业演员(5名男性,5名女性)记录。Emo-DB语料库的平均重新编码时间约为2~3 s,采样率为16 kHz。Emo-DB作为一种标准数据集,已被广泛用于情绪研究。
IEMOCAP:该数据集由10名专业演员在5个不同的会话中记录,每个会话有2名演员(1名男性,1名女性)。演员以脚本和即兴版本记录不同情绪的对话,由3位专家进行注释,并由至少2位专家同意选择。最终形成包括视频、语声和文本以及9种情感(anger、happy、excitement、sadness、frustration、fear、surprise、other、neural)的离散标签,其中语声平均话语时长为3.5 s。由于该数据库存在样本不均衡的情况,本文和诸多国内外研究者们[11,20]相同,选择(anger、happy、sad、neural)这4类人类基本情感进行实验,并且该数据集所有对比实验也均是上述4类情感。
2.1 数据预处理
实验采用Log-Mel谱图作为输入。Log-Mel谱图提取过程如下:首先将语声信号进行分帧、加窗,随后进行离散傅里叶变换计算每一帧的功率谱,并通过Mel滤波得到Mel频谱图,最后进行对数运算,即可得到Log-Mel谱图[26]。但由于语声数据的时长参差不齐,帧长不一致,故在提取Log-Mel谱图时,统一将帧长归为300帧,不足300帧的用0填充,超过300帧的进行分割处理。此外,为了得到语声的动态特征,提取Log-Mel谱图的一阶、二阶差分并和Log-Mel谱图组成3D Log-Mel特征集。
2.2 评估策略及参数设置
本文将Emo-DB数据库和IEMOCAP数据库划分为10份数据,采用十折交叉验证法,轮流将其中9份数据作为训练集,一份作为测试集,最后将10轮实验结果的准确率取平均值作为最终识别准确率。实验使用两种常见的评估指标:加权准确率(Weighted accuracy,WA)和未加权准确率(Unweighted accuracy,UA)[27],来衡量模型的性能。WA是测试集中所有样本的准确率,UA是全部情绪准确率的平均值。
本文在实验中使用了自适应矩估计(Adam)优化器,并将其初始学习率设置为0.001,权值衰减为5×10-4,批量大小等于32。该模型的参数通过最小化交叉熵目标函数进行优化,而最大迭代次数设置为150。
2.3 实验结果分析
2.3.1 空间注意力机制在CNN层间位置的实验结果分析
为了研究CNN网络中空间注意力层和卷积层不同层间位置关系对于识别率的影响,依次把空间注意力层放入第一层卷积至最后一层卷积之后,记为CNN(AC1)-CNN(AC7),所有的实验均在Emo-DB库和IEMOCAP上进行了150次迭代,实验结果如表1所示。
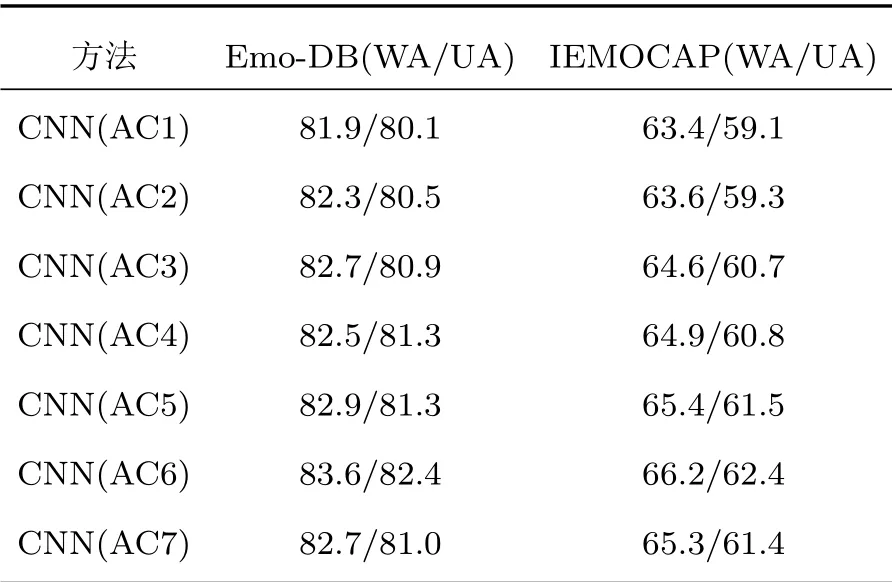
表1 空间注意力机制在CNN不同层间位置实验结果Table 1 Experimental results of spatial attention mechanism in different layers of CNN(单位:%)
通过表1可知,随着卷积层的加深,网络提取的有效特征越来越多,此时可以通过注意力机制聚焦关键情感特征,从而提高模型的识别率。IEMOCAP库中AC1至AC6识别率持续升高,Emo-DB库虽然AC4变低,但总体也呈上升趋势。然而从AC6到AC7时识别率开始变低。此外,由于层数的增多,也会增加训练负担。
图2展示了在150次迭代中,AC1至AC7的收敛曲线。
从图2中可以看出,在Emo-DB库中,经过80次迭代后,模型趋于稳定,其中AC6不仅在第10代准确率最高,而且收敛速度也最快。在IEMOCAP库中,经过60次迭代后,模型趋于稳定,AC6也同样取得了最好的实验效果。
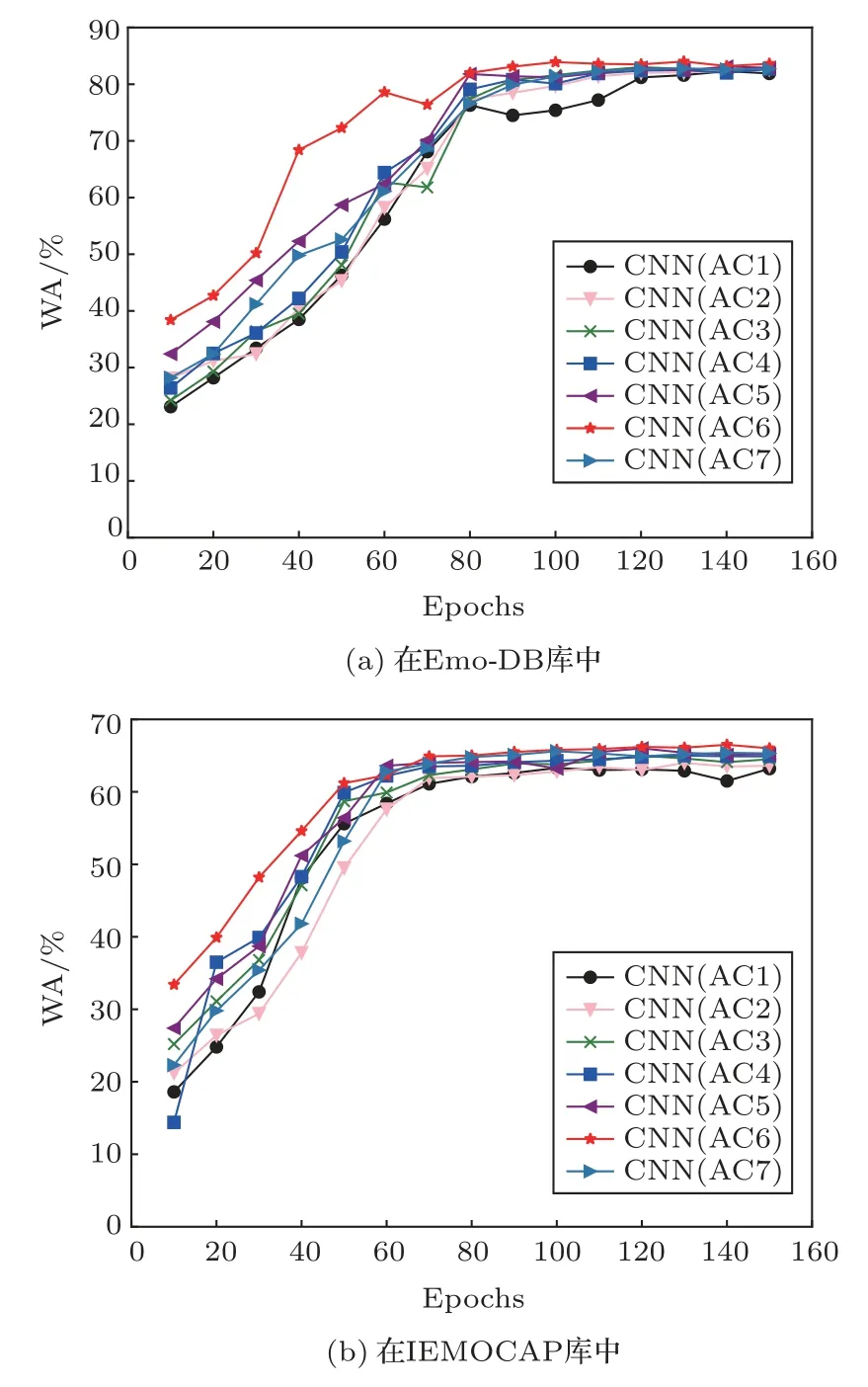
图2 CNN(AC1-7)在Emo-DB库和IEMOCAP库中的收敛曲线Fig.2 Convergence curves of CNN(AC1-7)in Emo-DB and IEMOCAP
综上所述,本文选择在第6层卷积后加入空间注意力机制具有科学性和有效性。
2.3.2 STA-CRNN实验结果分析
为了验证本文所提模型的有效性,创建了由CNN+BiLSTM模型以及在此基础上加入两种注意力机制所组成的基线模型。设置了具体实验如下:
(1)Base1(CNN+BiLSTM):以CNN+BiLSTM作为基线模型。
(2)Base2(ACNN+BiLSTM):在Base1的基础上,在CNN中加入时空注意力层。
(3)Base3(CNN+A-BiLSTM):在Base1的基础上,在BiLSTM网络后加入时间注意力层。
(4)Base4(并行STA-CRNN):将带有空间注意力机制的CNN和时间注意力机制的BiLSTM采取并行方式,采用特征融合的方法,和本文串行的STA-CRNN模型进行对比。
(5)本文模型(STA-CRNN):和上述实验进行对比,验证本文所提出网络的有效性。
表2为4种模型的实验结果。
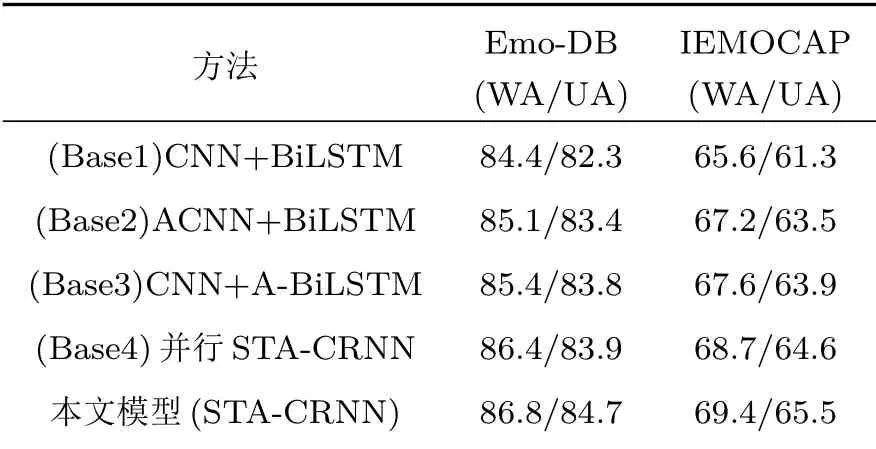
表24 种模型实验结果Table 2 Experimental results of four types of models(单位:%)
图3为在Emo-DB和IEMOCAP库中4种模型的收敛曲线。
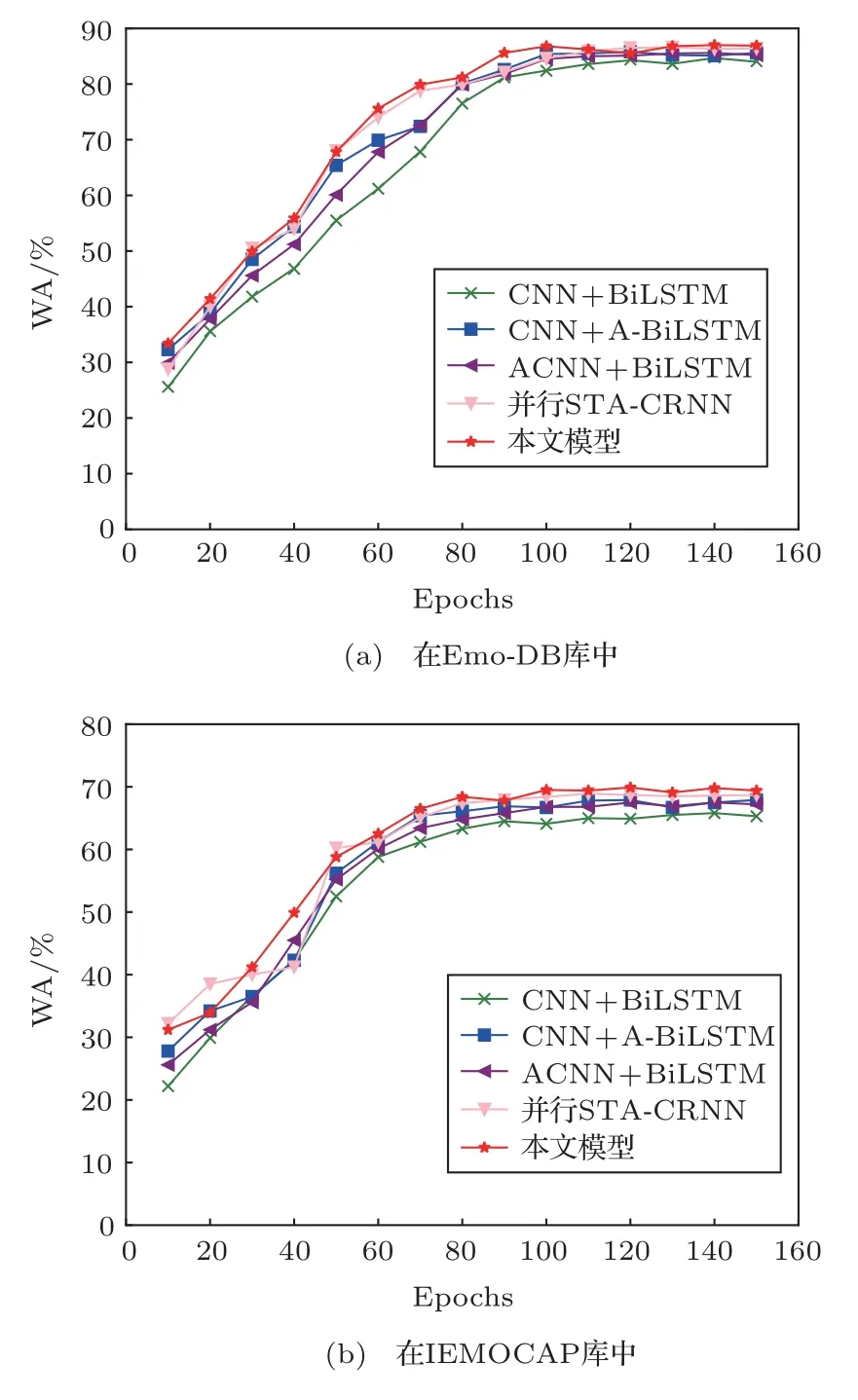
图3 在Emo-DB和IEMOCAP库中4种模型收敛曲线Fig.3 Convergence curves of four model in Emo-DB and IEMOCAP
通过表2和图3可知,在Base1的基础上,不论是在CNN中(Base2)还是在BiLSTM中(Base3)加入注意力层,WA和UA都有增长,但是都没有达到预期的效果。而本文的模型把两种注意力机制结合形成了时空注意力机制,集合了两者的优点,无论是串行结构还是并行结构均使得模型的性能得到了显著改善。串行的STA-CRNN模型相较于并行的STA-CRNN模型,在两个数据库上均取得了最好的结果,在Emo-DB库中WA和UA分别高了0.2%、0.8%,在IEMOCAP中分别高了1.3%、1.1%,并且其收敛曲线也最为稳定。
图4展示了本文模型在Emo-DB和IEMOCAP库上实验的混淆矩阵,通过分析混淆矩阵可知,本文所提出的模型对于angry的识别率较好,在Emo-DB和IEMOCAP库上分别达到了95%和80%的准确率。
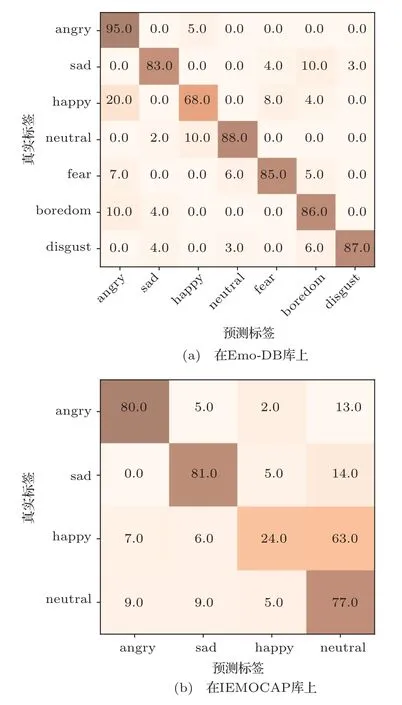
图4 本文模型在Emo-DB和IEMOCAP库上实验的混淆矩阵Fig.4 The confusion matrix of the model is tested on Emo-DB and IEMOCAP
但是本模型对于happy的识别效果较差:在IEMOCAP库中仅有24%,因为大部分的happy被识别成neutral情感;在Emo-DB库中识别率为68%,有20%的happy被识别成愤怒。上述分析结果与之前的研究结果一致[28-29],由于训练数据的有限性以及happy类别比其他类别更依赖语境,导致happy类别很难被识别。
2.4 与现有SER实验结果对比
本文选择以下8种网络作为对比实验:基于三维注意的卷积递归神经网络(Convolutional recurrent neural networks with attention,ACRNN)[12],并行卷积递归神经网络(Parallelized convolutional recurrent neural network,PCRN)[30],多重卷积递归神经网络(Multiple convolution recurrent neural network,MCRN)[28],1D和3D多特征融合网络[31],基于卷积的胶囊神经网络(Capsule neural network based CNN,CapCNN)[32],时间注意池网络(Attentive temporal pooling,ATP)[33],上下文叠加拓展的卷积神经网络[34],以及卷积循环神经网络(CNN-LSTM)[11]。结果如表3所示。
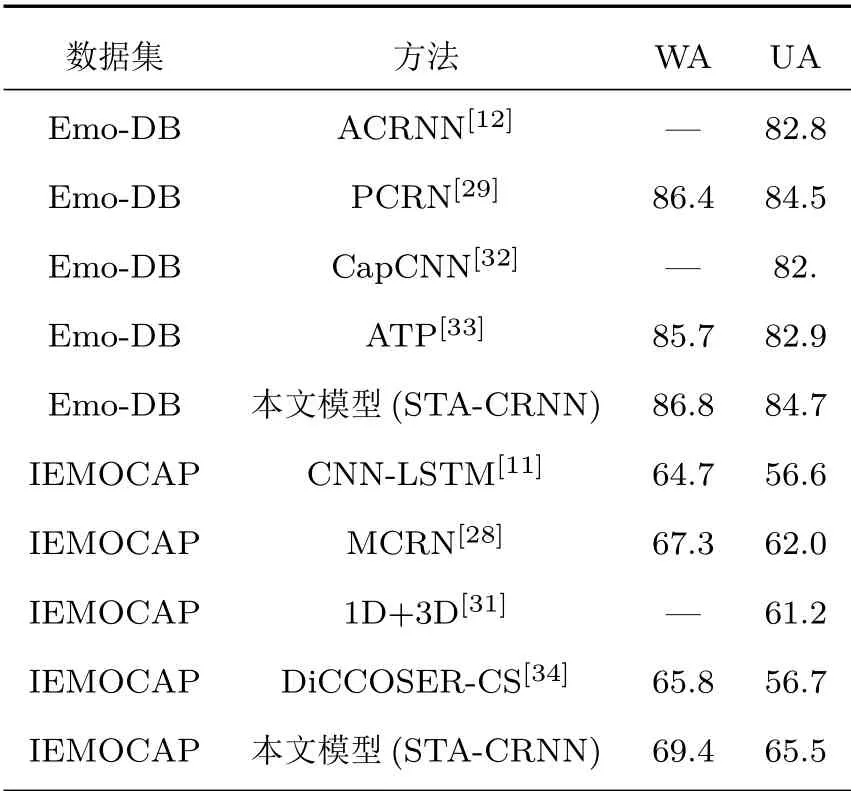
表3 与现有SER结果准确率比较Table 3 Comparison with the accuracy of existing SER results(单位:%)
通过表3可以看出,在Emo-DB库中,本模型比ACRNN[12]的UA提高了1.9%;比PCRN[29]模型的WA和UA分别高了0.4%、0.2%;而与最近较为火热的CapCNN[32]、ATP[33]对比,也体现了一定的优势,两者UA皆是提高了1.8%。在IEMOCAP库中,本文模型比传统CNN-LSTM[11]的WA增长了4.7%,而UA的增幅高达8.9%;和MCRN[28]相对比也表现出了更好的识别率,WA和UA提升达2.1%、3.5%;在和最新的一些的方法对比中可以得出比1D+3D网络[30]的UA提高了4.3%;和DiCCOSER-CS[34]相比,本文模型的WA提高了3.6%,而UA的提升幅度高达8.8%。综上所述,本文所提出的模型优于大多数先进方法。
3 结论
本文提出了一种用于SER的STA-CRNN模型。该模型包含CNN、LSTM两大模块。分别在CNN和LSTM网络中加入了空间注意力机制和时间注意力机制,以便更好地提高模型性能,从而提高语声情感识别率。从两个情感数据集中的实验结果以及在和其他先进的方法对比中可以得出,本文的模型可以更好地提取语声频谱图中的有效特征信息,过滤掉无效特征信息,使得SER的识别率大幅度提高。由于本文所提取的特征是类似于图像的RGB三通道结构,而通道与通道之间的重要性不同,故也会影响卷积过程中特征的提取。因此,在未来的研究中,本文会在CNN中加入通道注意力机制以提高SER的效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
第二课堂(课外活动版)(2016年2期)2016-10-21
