
基于自监督的深度神经网络稳健性提高方法
2022-12-08 13:39李佳文黄晓霖
厦门大学学报(自然科学版) 2022年6期
李佳文,方 堃,黄晓霖,杨 杰
(上海交通大学图像处理与模式识别研究所,上海200240)
深度神经网络作为一种具有强大计算能力的模型,在图像分类[1-3]、目标检测[4-5]、语义分割[6-7]和自然语言处理[8-9]等任务中广泛应用.针对图像分类任务,著名的分类网络有AlexNet[2]、GoogleNet[10]、ResNet[1]和DenseNet[11]等.然而近年来,有学者研究发现,此类神经网络易被特定的图像样本误导.研究者通过在原始的干净图像样本上添加一种小幅度的、精心设计的噪声,得到新的图像样本.新样本与干净样本高度相似,难以由人眼辨别,却可诱导神经网络输出与干净样本完全不同的类别预测结果.此类人为产生的新样本称为对抗样本[12].产生对抗样本的方法称为对抗攻击方法[13].很多对安全性要求较高的人工智能应用场景,如自动驾驶、医疗诊断和人脸识别等,在研发阶段都必须关注对抗样本带来的潜在威胁.
针对对抗样本,研究者提出了多种防御方法,希望防止其对模型的干扰.按照防御思路的不同,大致可将其分为两大类:主动式防御和被动式防御.主动式防御[14-15]希望在样本输入模型前检测出对抗样本并拒绝对其分类,被动式防御则是在样本输入模型后还原出原始的干净样本或直接输出正确的类别.常见的被动式防御方法有对抗训练[12,16]、图像去噪[17-19]、稳健优化[20-21]、稳健性网络[22]等等.图像去噪将对抗样本中含有的扰动视为一种普通的噪声,在样本输入模型前,利用滤波或降维等方法去除该噪声,从而还原出干净样本,避免对抗扰动对模型的干扰.相比于其他防御方法,图像去噪有不依赖于任务和模型、即插即用、训练速度快等优点[23],可用于防御多种攻击方法产生的对抗样本.常用的用于去噪的模型有去噪自编码器(DAE)[17]、变分自编码器(VAE)[24]、生成对抗网络(GAN)[25]等.本文研究的模型结构为自编码器(AE)与分类网络(C)的级联结构,称为“AE+C”结构,如图 1所示.
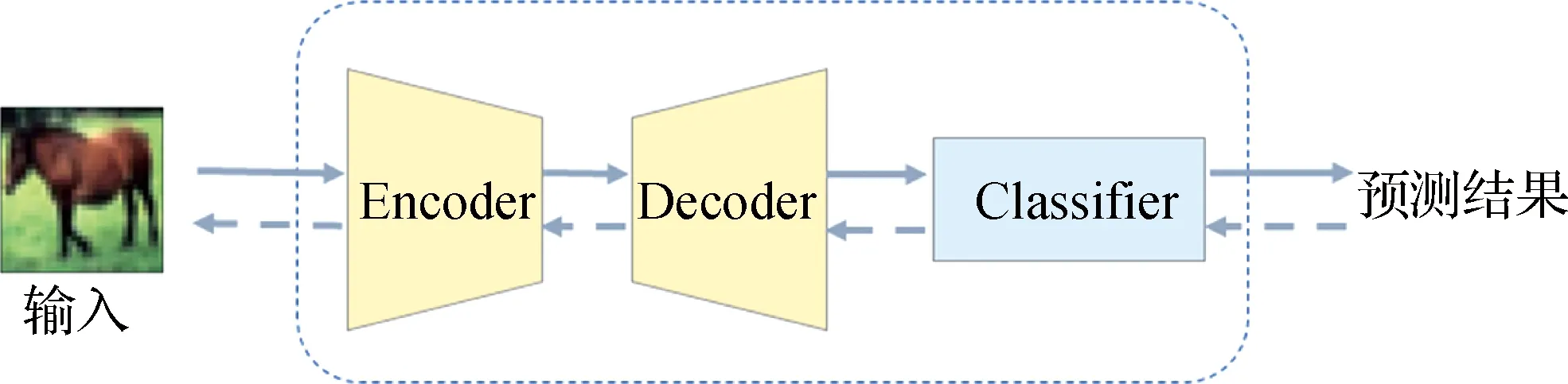
Encoder、Decoder和Classifier分别为结构中的编码器E,解码器D和分类模型C.实线流为前向计算,虚线流为反向梯度传播.图1 “AE+C”防御结构Fig.1Structure of AE-C model
以“AE+C”结构为基础,大多数防御者使用干净样本训练AE模块,并选择预训练网络作为C.攻击者攻击C产生对抗样本,防御者将对抗样本输入AE部分进行去噪重建,再将重建样本输入C获得预测类别.此类方法有效的原因在于AE部分尽可能模拟干净样本的分布,将输入投影到该分布上,而攻击者无法获知AE的存在,只能利用C的信息攻击整体的防御模型.这种攻击方法也称为“灰盒攻击”.当攻击者利用整个结构的信息产生对抗样本,该结构的防御性能将会大大降低甚至完全失效.这种攻击方法称为“白盒攻击”.在实际应用中,攻击者很难获取关于防御模型的所有信息,甚至只能有限次地访问目标模型,仅仅根据模型的预测输出设计对抗样本.因此,灰盒攻击与黑盒攻击更应该成为防御者需要考虑的威胁.目前利用该结构制作的模型可以有限程度地防御对抗样本,但随着攻击方法的不断更新,模型的防御能力也需要提升.
本文提出一种新的训练方法,使用条件变分自编码器(CVAE)作为该结构中的AE部分,事先利用干净样本与类别信息训练CVAE重建输入,训练中加入自监督信号,辅助CVAE筛选最有效地训练通道,再将CVAE与C级联,采用端到端训练方式同时训练两个模块.实际应用中,CVAE与C可作为整体防御模型,防御多种攻击方法产生的对抗样本,且防御能力超过了前人方法.
1 攻击与防御现状分析
1.1 攻击方法
对抗样本最早由Szegedy等[12]发现并提出,攻击者在干净样本xclean中加入扰动δ,得到对抗样本xadver,目的是寻找一个合适的δ使得目标模型F对xclean和xadver输出不同的类别预测结果.换句话说,攻击者试图解决式(1)的优化问题:
(1)
其中:‖·‖p代表扰动的p-范数约束,F(·)代表目标模型F的预测结果.
迄今为止研究者已经提出了很多产生对抗样本的攻击方法.按照对目标模型信息的获取程度,攻击方法可分为3类:
1) 白盒攻击:攻击者获得目标模型的全部信息,包括输入、输出、全部模型参数、梯度、可能存在的防御机制等;
2) 灰盒攻击:攻击者获得目标模型的部分信息;
3) 黑盒攻击:攻击者仅能获得目标模型的输出,不能获得其他模型信息.
具体地,攻击者利用4种攻击方法产生对抗样本:FGSM[13],BIM[26],PGD[27]和CW[28].其中PGD被认为是强度最高的基于梯度的攻击,CW为基于优化的攻击.4种攻击方法在验证模型稳健性的场景中均有大量应用.
FGSM由GoodFellow等[13]于2014年提出,直接利用损失函数针对输入的梯度制作扰动δ:
(2)
其中:ε固定了扰动的大小,L(θ,x,y)代表目标模型F的损失函数.
作为迭代式的基于梯度的攻击,PGD随机初始化对抗噪声,在每一次迭代中利用损失函数针对当前输入的梯度生成对抗样本,将该对抗样本作为下一次迭代的输入,逐步得到最终结果.如式(3)所示:
(3)
其中:∏代表每次迭代中,都需要将当前对抗样本投影到干净样本的固定邻域Ω内,t代表当前迭代次数.
BIM方法与PGD方法基本相同.唯一不同在于是否使用随机初始化.
CW方法通过求解式(4)的优化问题得到扰动δ:

s.t.x+δ∈[0,1]n.
(4)
其中f(x+δ)代表特定的损失函数,本文采用2-范数形式的CW攻击验证模型稳健性.
1.2 防御方法
1.2.1 对抗训练
为了防止对抗样本的干扰,最直观的方法是在训练模型的同时攻击模型产生对抗样本,并用对抗样本和对应的真实类别标签扩充训练数据集,使得目标模型能很好地拟合这些对抗样本.数据增强是对抗训练的本质,防御者可根据实际需要选择特定攻击方法产生对抗样本加入训练集中.GoodFellow等[13]提出FGSM攻击方法并利用产生的对抗样本训练目标模型,被认为是最早的对抗训练.Madry等[27]提出基于PGD的对抗训练并解决了优化过程中的鞍点问题.采用多种攻击方法的对抗训练被称为联合对抗训练,可以提高模型针对多种攻击的稳健性.近年来,陆续出现了对抗训练的多种变体.Zhang等[29]理论证明了模型的稳健性和准确性存在Trade-off,将稳健误差分解为标准误差和决策误差,设计新的对抗训练方法兼顾了稳健性和准确性.针对对抗训练收敛过慢的问题,Zhang等[30]提出友好的对抗训练(FAT),设计对抗样本的停止生成条件,加速训练过程.Wang等[31]在训练过程中将正确分类与错误分类样本分开,针对两者分别设计新的损失函数,提升了对抗训练带给模型的稳健性.Yan等[32]在对抗训练过程中观测到,对模型进行对抗训练后,干净样本和对抗样本在模型中激活的通道并不一致,因此在损失函数中加入正则化项,约束两者在激活通道上保持对齐,减小了模型的稳健性与准确性之间的差距.然而对抗训练所带来的额外的梯度计算,使得训练模型需要巨大的计算代价,这一缺点一直无法忽略.
1.2.2 图像去噪
图像去噪是另一种应用广泛的防御方法,防御者可选择在输入或模型中间的特征层去除样本中的对抗噪声,还原样本的真实类别.早期的去噪方法有图像的JPEG压缩[33]、比特压缩[34]等其他传统的数据预处理方法[35].近年来,防御者使用生成模型拟合干净样本的分布,希望利用生成模型重建对抗样本时尽量符合干净样本的特征,达到去噪效果.最常用的结构即为AE与C级联的“AE+C”结构.Hwang等[24]利用CVAE和额外的监督标签信息,将对抗样本投影到每个类别流形上,将距离最近的投影作为去除噪声的重建样本.Vacanti等[36]认为在模型输出端攻击效果最显著,因此他们选择在输出端去噪,训练AE部分重建样本,约束干净样本与重建样本在输出端保持对齐.同样,他们使用预训练的分类器.Takagi等[37]在训练的数据集中随机加入高斯噪声或高斯模糊,希望提高AE部分在重建过程中的去噪能力.除了AE,一些研究者也尝试将AE换成GAN或其他生成模型,如Defense-GAN方法[25]用以训练GAN将随机噪声逐步重建出符合干净样本分布的重建样本,达到去噪效果.这些方法有一个共同的缺点,即都是在灰盒攻击模式下验证模型的稳健性.一旦攻击者获知AE部分的存在,模型的防御能力将会大大降低.针对这个问题,Naseer等[23]尝试将AE的训练与自监督信号相结合,希望模型能防御白盒攻击,不久即被新的攻击方法攻击成功.Shi等[38]设计了新的训练方式,以AE为基础,提取AE部分的潜在向量,利用潜在向量设计新的自监督学习任务,使得AE获得更多关于干净样本的信息.实验证明,该方法可一定程度防御白盒攻击.缺点是训练时间依旧过长,而且需要逐样本的去噪.
1.2.3 稳健网络
上述方法重点分别放在优化算法和输入端,部分研究者希望开发出本身即具有稳健性的模型结构,如模型集成,防御者将多个分类模型集成为新的基础分类模型,随机输出某个子模型的预测结果,尝试误导攻击者选择错误的子模型进行攻击,进而实现模型稳健性.近年来,有研究表明具有一定稀疏特性的网络本身具有对抗稳健性.2019年,Ye等[39]将模型剪枝与对抗训练相结合,希望在训练过程逐渐修剪网络来抑制神经网络在潜在特征级别的脆弱性.Sehwag等[40]设计了一种名为HYDRA的稳健性感知分数,用于衡量模型权重对于稳健网络的重要性,通过评分,对分数较低的权重进行剪枝.Özdenizci等[22]在2021年提出贝叶斯稳健稀疏网络,在训练过程中控制网络的稀疏程度,进而降低对抗样本对模型的干扰度.
1.3 自监督学习
自监督学习旨在从无标签数据中学习有意义的数据表征.近年来的研究表明,自监督学习任务可以作为很好的辅助训练方法,有利于提高深度神经网络的稳健性.很多研究者均在自己的防御方法中加入了自监督学习任务.Chen等[41]提出自监督学习的对抗训练方法,Hendryck等[42]发现给基于PGD的对抗训练加入图像重建的自监督学习任务有助于提升训练过程的稳定性.Naseer等[23]和Zhou等[43]融合了图像去噪和对抗训练,分别利用不同的自监督辅助信号产生对抗样本训练AE进行去噪.本文同样在训练过程中添加自监督信号,设计筛选标准,令CVAE在训练过程中选择最适合的训练通道,并在该通道最小化重建样本与输入的距离.
2 方 法
本文定义干净样本和对抗样本数据集为Xclean与Xadver,数据集维度为d.用ytrue代表样本的真实类别,ypred代表分类模型的预测结果,类别维度为c.CVAE是一种强大的生成模型,可生成符合指定分布的样本.关键假设是CVAE中潜在变量z的先验分布服从多元混合高斯分布Q.
2.1 单独训练CVAE
训练阶段,通过优化ELBO(evidence lower bound)来训练CVAE,如式(5)所示:
ELBO=Ez~Q[log(P(x|z,y))]-
DKL(Q(z|x)‖P(z,y)).
(5)
其中第一项控制了CVAE的输出与输入的重建差异,第二项用KL散度保证先后验分布的距离最小化.基于关键假设,进一步利用KL散度项最小化后验分布与多元高斯分布的距离.
图2展示了模型的训练过程.第一阶段,使用xclean与ytrue组成输入对单独训练CVAE部分,先保证CVAE部分具有一定的重建能力.其中,编码器E将输入编码为潜在空间的均值μ和标准差σ,如式(6)所示:
μ,σ=E(xclean,ytrue).
(6)
从潜在空间采样潜在变量z,利用解码器D重建出图像样本,如式(7)和(8)所示:
z=μ+ε·σ,
(7)
xrecon=D(z,ytrue),
(8)
其中,xrecon代表重建的图像样本,与xclean具有相同的维度d.此时CVAE需要真实标签信息ytrue监督其重建过程.
训练CVAE部分的损失函数按照ELBO设计,分为式(9)和(10)两项:
L1=xcleanlogxrecon+(1-xclean)log(1-xrecon),
(9)
L2=μ2+σ2-logσ2-1.
(10)
其中,L1与L2分别对应ELBO的两项的损失函数.
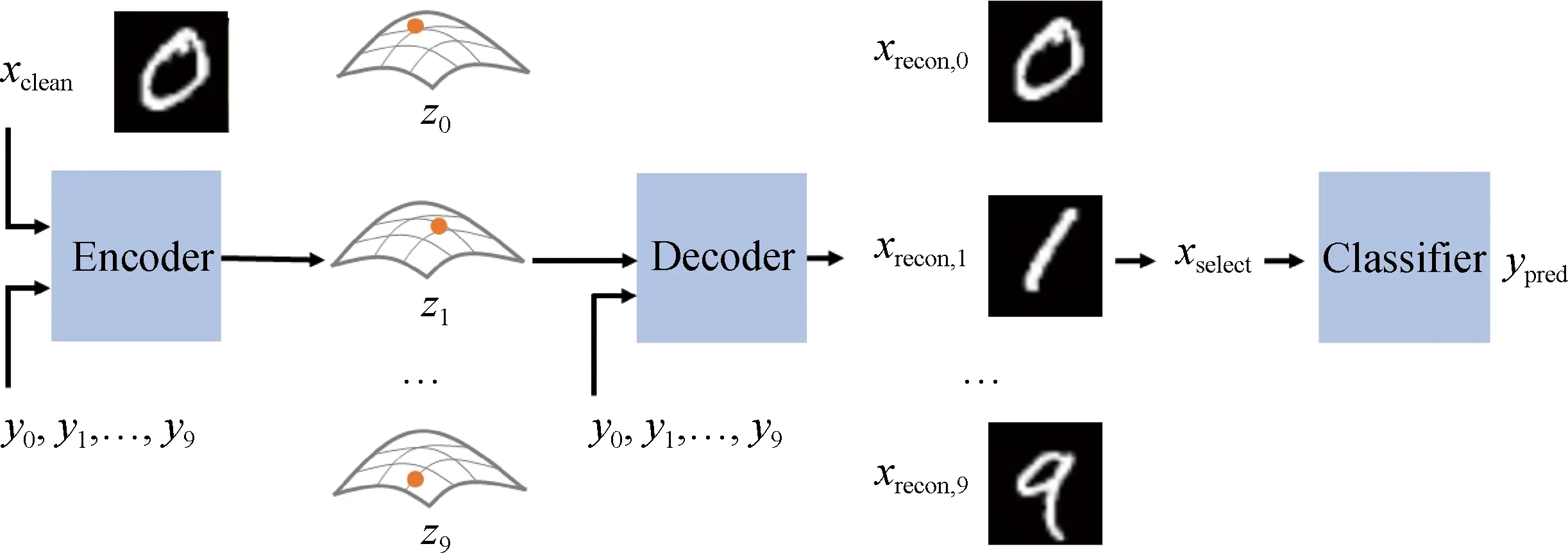
将xclean与y0, y1,…, y9组成输入对,经Encoder编码为潜在向量z0, z1,…, z9,经decoder重建出10张图像,选取与xclean相似度最高的图像为最终重建结果.图2 模型训练与测试展示图Fig.2Training and testing process of our algorithm
2.2 联合训练“CVAE+C”结构
训练一定时间的CVAE后,对“CVAE+C”结构进行端到端式训练.具体地,将CVAE的重建输出xrecon作为分类模型C的输入,C输出对xrecon的预测结果ypred,如式(11)所示:
ypred=C(xrecon).
(11)
由于实际应用中无法获取样本的真实类别,因此与单独训练CVAE不同,不再利用ytrue监督CVAE的图像重建,而采用自监督信号yselect进行监督.yselect由CVAE本身产生.将xclean与每个类别yi均组成输入对,输入模型进行一次前向计算,并重建出相应的图像样本,如式(12)所示:
xrecon,i=D(E(xclean,yi)),
(12)
其中xrecon,i代表第i个通道的重建样本.
本文中定义重建样本与干净样本的2-范数差异为训练通道的筛选标准,将差异最小的重建样本作为CVAE部分的最终重建结果,将对应的类别作为重建通道监督样本的重建过程:
(13)
在端到端训练中,将CVAE的重建过程视为一种自监督的辅助学习任务,令CVAE自适应地选择最优训练通道,当验证模型稳健性时,该结构不需要真实类别的监督,即可筛选出正确的重建通道.
筛选出训练通道后,希望此通道与真实类别保持一致,当筛选通道与真实类别一致时,约束重建样本与输入干净样本尽可能相似,不一致时,则约束重建样本与输入干净样本尽可能不同,因此将约束重建能力的损失函数修改为式(14):
(14)
采用交叉熵损失函数训练分类器C,具体如下:
L3=ytruelogypred+(1-ytrue)log(1-ypred).
(15)
训练时,为了避免梯度爆炸,加入模型权重w的正则化项,约束权重大小:
(16)
最后利用Adam算法训练整个防御模型,联合损失函数由4部分组成:
Ltotal=α1L1,new+α2L2+α3L3+α4Lreg,
(17)
其中αi代表各损失函数对应的权重.具体训练流程见算法1和图2.
算法1模型训练
输入:xclean,ytrue,随机初始化E,D,C
单独训练CVAE,迭代次数T1
For 每一类别i执行
利用式(12)重建每一通道的样本
End for
根据式(13)筛选重建通道及对应类别yselect
判断yselect与ytrue是否相等,确定损失函数形式
联合训练E,D,C,损失函数为式(17)
函数收敛,训练完成
输出:训练好的E,D,C
2.3 模型测试
测试阶段,由于输入样本的类别未知,采用与训练阶段类似的前向计算过程与通道筛选过程,得到多个重建样本:
xrecon,i=D(E(xtest,yi)),
(18)
与训练阶段相同,xrecon,i代表第i个通道的重建样本,即输入向所有类别的分布上的投影.
经过解码器D重建后,筛选与原输入差异最小的投影作为去噪后的重建样本,进而输入分模型C得到还原后的预测结果ypred:
(19)
xselect=D(E(xtest,yselect)),
(20)
ypred=C(xselect).
(21)
详细测试流程见算法2和图2.需要注意的是,模型的训练过程与测试过程均可利用图2展示.不同的是,训练过程中的yselect将作为自监督信号辅助模型训练,本文中采用真实类别ytrue监督CVAE部分的筛选.测试过程中由于ytrue缺失,CVAE部分得到筛选通道后将直接获得重建样本.
算法2测试流程
输入:xtest,训练好的E,D,C
For 每一类别i执行
利用式(18)重建每一通道的样本
End for
根据式(19)筛选重建通道
根据式(20)得到去噪样本xselect
根据式(21)得到预测类别ypred
输出:去除噪声后的样本xselect,预测类别ypred
3 实 验
下面验证防御模型针对4种攻击方法:FGSM,BIM,PGD,CW的稳健性.参与对比的防御方法有基于FGSM方法的对抗训练[13]与PuVAE[24].本文防御模型的CVAE结构见表1,验证稳健性时采用多种结构的深度神经网络作为目标分类模型,包括应用非常广泛的残差神经网络ResNet18[1],其他网络的结构见表2,用于验证的数据集为MNIST和CIFAR10.MNIST[44]是一个包含60 000张训练数据和10 000张测试数据的10分类手写数据集.CIFAR10[45]包含10类小尺寸自然图像,共有50 000张训练数据和10 000张测试数据.本文中对两个数据集中的图像均做了归一化处理.对于MNIST,FGSM和PGD攻击中扰动采用∞-范数约束,设定ε=0.3与ε=0.4两种强度,其中PGD的迭代次数t=7,单步扰动约束α=0.1,CW攻击中扰动采用2-范数约束,设定迭代次数为100.对于CIFAR10,FGSM和PGD攻击中扰动采用∞-范数约束,设定ε=0.06与ε=0.15两种强度,其中PGD的迭代次数t=7,单步扰动约束α=0.01,CW攻击中扰动采用2-范数约束,设定迭代次数为100.整个训练过程中,仅采用干净样本训练.本文的实验平台为Pytorch,硬件条件为单张NVIDIA 1080Ti.

表1 CVAE结构
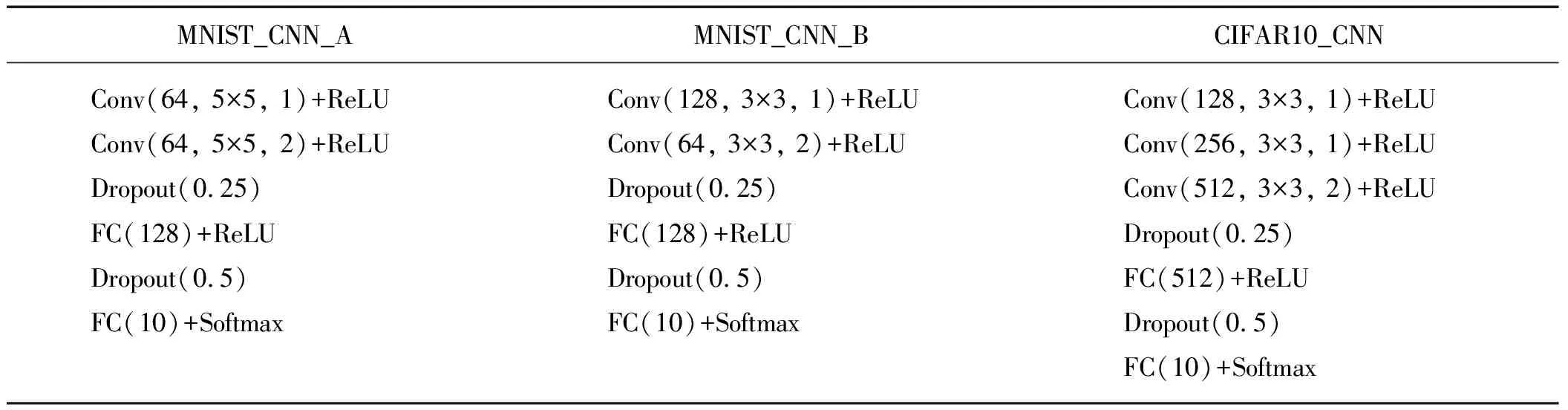
表2 用到的分类模型
3.1 灰盒攻击
本部分验证模型在灰盒攻击条件下,针对3种攻击方法的稳健性.攻击者获得分类部分的模型信息,并利用其产生对抗样本.验证过程中,本文方法与PuVAE均将对抗样本输入CVAE部分重建去噪,将重建结果输入分类部分预测类别,根据预测准确性评估模型针对该攻击方法的稳健性.在基于FGSM的对抗训练方法中,本文采用与测试过程相同的扰动幅度,这也符合灰盒攻击的条件,攻击者能获取对抗训练模型,但未知训练所用对抗样本的强度.所有列表中的“No Attack”表示仅用分类模型预测干净样本类别的准确率.
MNIST数据集上验证了MNIST_CNN_A与MNIST_CNN_B两种网络模型的稳健性,验证结果如表3和表4所示.为方便对比,本文与PuVAE方法设置一致的对比实验.由于PuVAE文中未给出训练的全部参数,因此本文直接引用其报告的实验结果.采用FGSM-AT方法训练时,学习率默认0.001,采用阶梯式衰减.本文方法中损失函数的权重设置为1,1,10,5×10-4.

表3 不同攻击方法下MNIST_CNN_A实验结果(灰盒)
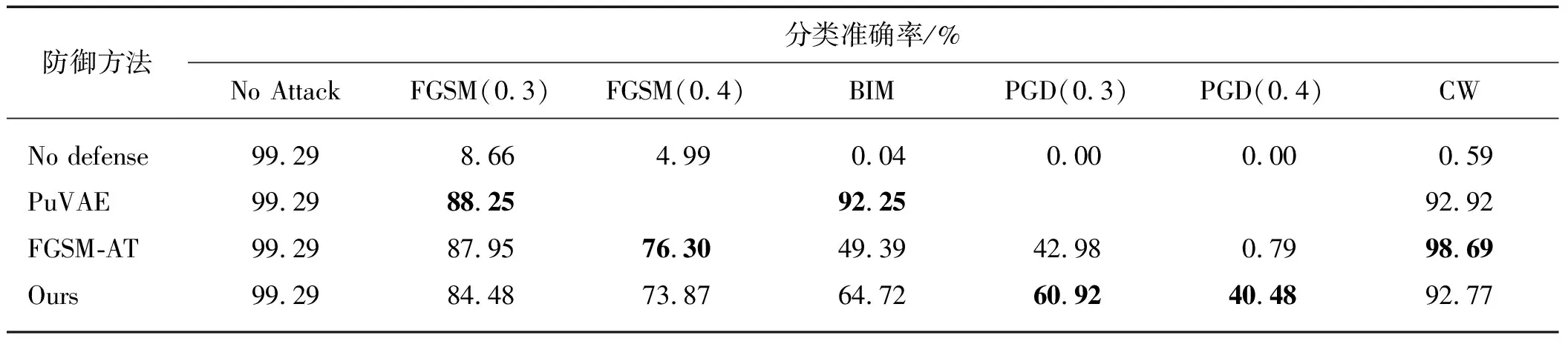
表4 不同攻击方法下MNIST_CNN_B实验结果(灰盒)
从验证结果可以看出,FGSM-AT针对FGSM攻击方法体现了超过其他方法的稳健性,但针对更强的PGD攻击方法时,防御性能大大降低.本文模型针对PGD攻击方法的稳健性较强,针对FGSM方法产生对抗样本的分类准确率高于PuVAE,然而在使用BIM迭代攻击方法攻击模型时,PuVAE报告了高于FGSM的稳健性,也高于本文模型的报告结果.可能的原因是PuVAE仅提供了PGD方法的扰动幅度,而攻击的迭代次数和单步扰动未知,因此本文模型准确率低于PuVAE可能的原因是单步扰动较大,或迭代次数过高.
CIFAR10数据集的验证实验里,用到的分类模型为CIFAR10-CNN与ResNet18.采用FGSM-AT方法训练时,学习率与MNIST实验相同.本文中直接引用PuVAE论文中汇报的准确率为验证结果.设置4个损失函数权重分别为2,1,2,5×10-4.
表5与表6分别为CIFAR10-CNN和ResNet18的稳健性验证结果,二者结果有很多相似之处,从“No defense”一行可以看出,两种分类模型均很容易被对抗样本攻击成功.FGSM-AT方法针对FGSM攻击有一定防御性能,且超过了PuVAE,然而在更强的PGD攻击下完全失效.由于PuVAE未汇报在ResNet18上的分类结果,且在训练PuVAE提供的CVAE与ResNet18的级联结构时发现很不稳定,因此ResNet18表中未将PuVAE加入对比结果.本文模型在多种攻击方法下的分类准确率都超过了FGSM-AT与PuVAE.且相比于MNIST,该数据集下的稳健性验证结果更明显地体现了本模型的优越性.

表5 不同攻击方法下CIFAR10_CNN实验结果(灰盒)

表6 不同攻击方法下ResNet18实验结果(灰盒)
3.2 黑盒攻击
由于黑盒攻击条件下,攻击者仅能访问模型输出,因此大多数攻击者选择训练目标分类模型的替代模型,希望替代模型的输出与目标模型尽可能一致,攻击者便可通过攻击替代模型获得目标分类模型的对抗样本.本文在验证A模型的稳健性时,使用B模型作为替代模型产生对抗样本.如验证MNIST_CNN_A模型稳健性时,使用MNIST_CNN_B模型产生对抗样本.黑盒攻击实验中,采用的模型文件与灰盒攻击实验完全相同,各项参数均保持一致,MNIST数据集上的验证结果如表7与表8所示,CIFAR10数据集上的验证结果如表9与表10所示.
MNIST实验中,FGSM-AT方法在CW攻击下的稳健性优于本模型,本模型针对PGD对抗样本的分类准确率较高.值得注意的是,在FGSM攻击下,FGSM-AT方法效果在不同模型中有很大不同,在A模型中优于本模型,在B模型中与本模型几乎一致.与灰盒攻击结果结合,可发现对抗训练很依赖特定模型的缺点,使用对抗训练得到的模型对使用特定方法攻击同类模型得到的对抗样本的稳健性很高,而对于跨模型的对抗样本,稳健性将受到影响,可能升高也可能降低.
CIFAR10实验中,与灰盒攻击下的结果类似,本模型显示了针对多种对抗样本的稳健性.

表7 不同攻击方法下MNIST_CNN_A实验结果(黑盒)

表8 不同攻击方法下MNIST_CNN_B实验结果(黑盒)
表9表明,FGSM-AT方法针对不同强度FGSM的防御性能均超过了本方法,但相比于FGSM-AT方法,本模型在多种攻击下的防御准确率较为均衡,而FGSM-AT针对PGD的防御性能劣于FGSM.FGSM-AT方法在CW攻击方法下的稳健性稍高于本模型.表10表明,当目标模型换成使用更加广发的Resnet18后,FGSM与PGD攻击下本方法防御效果均大幅度超过FGSM-AT,CW攻击下FGSM-AT的稳健性最强.和MNIST数据集的实验结果一致,对于跨模型生成的对抗样本,对抗训练得到的模型稳健性将大幅降低.

表9 不同攻击方法下CIFAR10_CNN实验结果(黑盒)

表10 不同攻击方法下ResNet18实验结果(黑盒)
4 讨 论
本文针对的人工智能任务是图像分类,目的在于降低甚至防止对抗样本对分类模型的影响,保证模型能在被攻击的同时输出准确的预测类别.由于本文提出的方法本质是一种去噪方法,因此除分类任务之外,本文的CVAE部分也可以与其他任务中的模型级联,如检测模型或分割模型,可扩展范围很大.另外,本文主要验证的是防御模型在灰盒攻击与黑盒攻击两种条件下的鲁棒性,这是由实际的应用条件决定的,在白盒攻击条件下,本模型的防御效果将会降低,这也是符合常理的.本模型以去噪为基本思想,而去噪本身对模型自身的性质并没有做出实质改进,因此防御白盒攻击效果不佳.若希望将此方法扩展到白盒攻击条件下,则需要考虑与对抗训练相结合,或在训练中加入适当的正则化项,用于约束模型的决策边界与输入样本保持较大的距离.
5 结 论
本文以图像去噪方法常用的“AE+C”级联结构为基础,设计了一种利用自监督重建信号的辅助训练方法,得到的防御模型作为一个整体的分类模型,在对抗样本输入后,先利用编码器部分对其进行去噪,还原出原始的干净样本,并由后续的分类器预测其真实类别.与前人方法相比,本方法继承了可扩展性强的特性,在灰盒攻击与黑盒攻击两种攻击条件下,利用多种攻击方法产生对抗样本验证了模型的稳健性.实验表明,本文训练方法得到的模型在多个数据集上都实现了针对对抗样本的较高分类准确率.证明了本训练方法有效提高了模型的稳健性.
猜你喜欢
少儿画王(3-6岁)(2020年4期)2020-09-13
商情(2019年3期)2019-03-29
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
财讯(2018年22期)2018-05-14
西安航空学院学报(2017年4期)2017-12-30
现代商贸工业(2016年35期)2016-04-09
指挥与控制学报(2015年4期)2015-11-01
浙江大学学报(工学版)(2015年1期)2015-03-01
微型计算机(2009年4期)2009-12-23
