
面向电力运维的SDH通信网故障定位
2022-12-12 05:54李建路王振乾
机械设计与制造工程 2022年11期
李建路,朱 珠,王振乾,昌 艳,李 柯
(南方电网调峰调频发电有限公司,广东 广州 510630)
随着电力通信网规模的扩大,对网络中SDH(synchronous digital hierarchy)设备的运维难度也越来越大。传统的SDH通信网主要依赖于人工检测和专家经验,无法高效率实现故障定位,因此不适用于广泛的故障定位,如王沛晶等[1]提出基于混合粒度的奇偶校验故障注入检测法推断SDH设备运维状况,但该方法仅适用于单跳测试,无法对电力通信网中的单个节点进行检测,故不适用于电力通信的SDH设备故障定位;高松川等[2]提出将故障定位限制在某个区域内,以减少故障定位时间,但该方法不能用于SDH光网络故障定位。为实现电力通信网故障快速定位,本文提出一种基于DNN(deep neural networks)的SDH通信网络设备故障定位方法,并通过仿真对该方法的可行性进行验证。
1 DNN简介
DNN由多个受限玻尔兹曼机(restricted boltzmann machine,RBM)组成,每个RBM可学习不同的特征,结构如图1所示。在DNN网络中,RBM节点间相互独立,且每个RBM包含一个可见层和一个隐藏层。RBM中,层与层之间通过权重连接,越高层的特征表示越具有不变性和抽象性。而多个RBM叠加即形成DNN网络,具体结构如图1所示[3-4]。
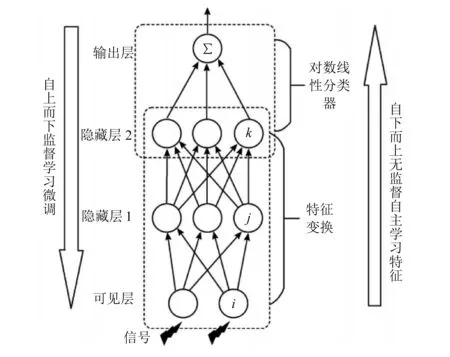
图1 DNN网络结构
由于RBM是一种能量模型,因此它可对输入模型中的数据概率分布进行无监督学习,并最大程度拟合输入模型中的数据。DNN正是借助RBM的无监督学习方式,从下到上逐层提取深层特征。特征提取步骤为:首先训练输出一层的特征序列,并将其作为下一层的RBM输入;然后采用反向传播算法,从上到下对模型参数进行调整优化;最后得到最优模型参数,并将参数设置为模型的训练参数。
2 SDH光通信网络数据采集及预处理
2.1 数据采集
要实现SDH通信网络故障定位,首先要对SDH光通信数据进行采集,包括SDH设备性能指示数据、设备相关数据、告警信息、事件数据等。由于现有的电力SDH光通信网络数据本身可通过网管采集平台获取数据,因此只需利用网管数据采集平台即可完成。另外,考虑到不同的SDH设备规格和型号,所以应开放采集接口,以确保采集数据的全面性。采集完成后,将不同类型的数据存储于对应的告警记录数据库中。
2.2 数据预处理
2.2.1数据清理
原始告警数据中含有大量非告警数据,且原始告警数据分布不均,因此为确保告警数据质量,需要对原始告警数据进行数据清理。具体清理过程分为3个阶段:一是对数据中的缺失数据进行去除或补全;二是对逻辑错误的数据进行去除或修改;三是对不需要的数据进行去除。
2.2.2数据标注
完成原始告警数据清理后,还需对得到的告警数据之间的关系进行分析并用标签标注,从而获得可用于监督训练的告警数据集。在本文中,对告警数据进行标签标注的步骤为:首先通过滑动时间窗口对告警数据实物进行切分;然后通过FP-Growth得到数据间的关联规则;最后根据电力SDH光网络的故障类型与频繁项集间的关系进行标签标注。其中,利用分布式FP-Growth算法找出数据间的关联规则是对告警数据进行标签标注的关键[5-6],具体寻找数据间关联规则的步骤分为以下几步:
1)设置数据项的最小支持度阈值。通过分析告警数据将阈值设置为40%。
2)计算数据项支持度。将阈值≥40%的告警数据按降序存储于M列表中。同时对M列表中的每个数据项创建对应的链表,以便后续数据搜索。
3)创建FP-Tree根节点和FP-Tree树,标记根节点为空。FP-Tree树每个节点按M列表顺序进行创建。若创建的FP-Tree树没有相同的前缀路径,则创建一个新的节点,并将其支持度值设置为1;反之,则将相同节点的支持度值增加1。
4)按M列表的反向顺序遍历列表,创建条件模式基,并设置支持度最小的值为支持度。
3 基于DNN的SDH光网络运维定位
本文采用上述的DNN算法构建SDH故障定位模型,具体定位模型如图2所示。在该定位模型中,以预处理后的样本作为输入,然后经过隐藏层对特征的提取和融合,得出故障定位结果。
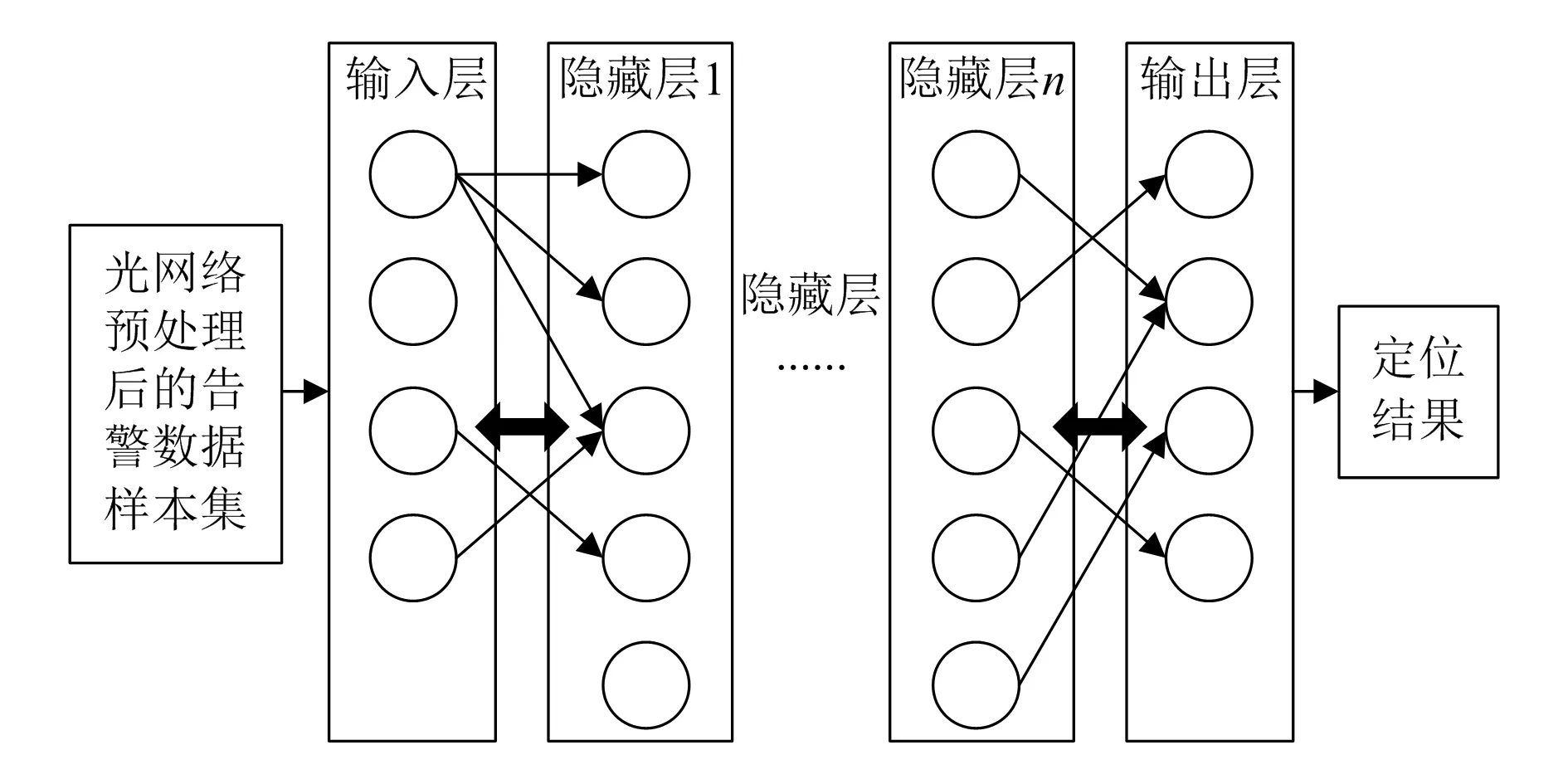
图2 基于DNN的光网络故障定位
由图2可知,SDH故障定位的结果与输入层神经元个数、隐藏层层数等有很大关系。当隐藏层层数过多时,模型结构相对复杂,且模型参数也会增多,容易导致模型过拟合,进而降低网络的泛化能力;当隐藏层层数较少时,模型结构较为简单,无法有效处理输入数据,且学习能力较差,进而导致无法深度挖掘数据的隐藏特征。因此,选择合适的隐藏层层数有利于提高模型的学习能力、泛化能力、处理数据能力,进而提高模型故障定位的精确性。为确定模型隐藏层层数以及最佳故障判别模型,本文采用控制变量法建立不同的故障判别类型[7],具体步骤为:
1)结合告警数据样本集规模,通过对模型进行简单训练,初步确定模型隐藏层层数最少为4层。因此,在本训练中设置隐藏层层数分别为4、5、7,然后进行故障定位的仿真,进而确定DNN模型的最佳隐藏层层数。
2)利用固定学习率和自适应学习率对DNN故障定位模型进行训练,对比训练后模型效果,确定模型的最佳学习率。
3)采用3种激活函数——Sigmod函数、Tanh函数和ReLU函数对DNN模型进行训练,然后对比不同激活函数训练模型的效果,确定最佳激活函数。
4 仿真实验与结果分析
4.1 仿真环境搭建
本文基于Python和TensorFlow进行仿真实验。实验数据来自某电力城域网中的SDH光网络告警数据。应用上述不同故障定位模型对预处理后的告警数据集进行训练,最小均方误差函数选择Loss函数[8],利用告警数据验证集对模型训练结果进行验证,包括模型的故障定位准确率、模型故障查全率、模型故障查准率等[9]。最后,确定最佳模型参数。
4.2 仿真结果分析
在不同隐藏层层数、不同学习率和不同激活函数下,得到以下的仿真结果。
4.2.1隐藏层层数与学习率对模型性能的影响
图3所示为在不同隐藏层层数和不同学习率的条件下,DNN模型多次训练后的Loss函数值。由图可知,当模型采用自适应学习率时,其Loss函数值比采用固定学习率的Loss函数值小,说明选用自适应学习率可提升模型训练速度和效果,使模型性能更好;当模型隐藏层层数为5时,模型的Loss函数值小于隐藏层层数为4层和7层的Loss函数值,说明选用隐藏层层数为5可提升模型训练速度和效果,使模型性能更好。

图3 不同学习率和隐藏层层数对Loss值的影响
图4所示为在不同隐藏层层数和不同学习率条件下,DNN模型多次训练后的准确率、查全率和查准率。由图可知,当模型采用自适应学习率时,其故障定位的准确率、查全率和查准率比固定学习率更高,说明选用自适应学习率可提升模型性能;当模型隐藏层层数为5时,其故障定位的准确率、查全率和查准率比隐藏层层数为4层和7层更高,说明选用隐藏层层数为5可提升模型性能。由于隐藏层层数对模型的训练效果具有巨大的影响,因此在条件允许的情况下,为避免因隐藏层过多带来的模型容易出现过拟合问题,应对模型进行多次反复实验,以选择合适的隐藏层层数,从而提高基于DNN的面向电力通信的SDH设备故障定位模型性能。
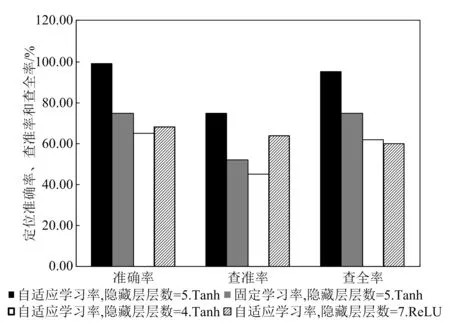
图4 不同隐藏层层数和不同学习率对模型指标的影响
4.2.2激活函数对模型性能的影响
图5所示为不同激活函数对模型Loss值的影响,图6所示为不同激活函数对模型指标的影响。由图可知,DNN故障定位模型选用Tanh函数作为激活函数时,其Loss值小于Sigmod函数和ReLU函数的Loss值,且其故障定位的准确率、查全率、查准率更高,达到95.43%以上,说明选用Tanh函数作为激活函数可提高基于DNN的面向电力通信网的SDH设备故障定位模型性能。
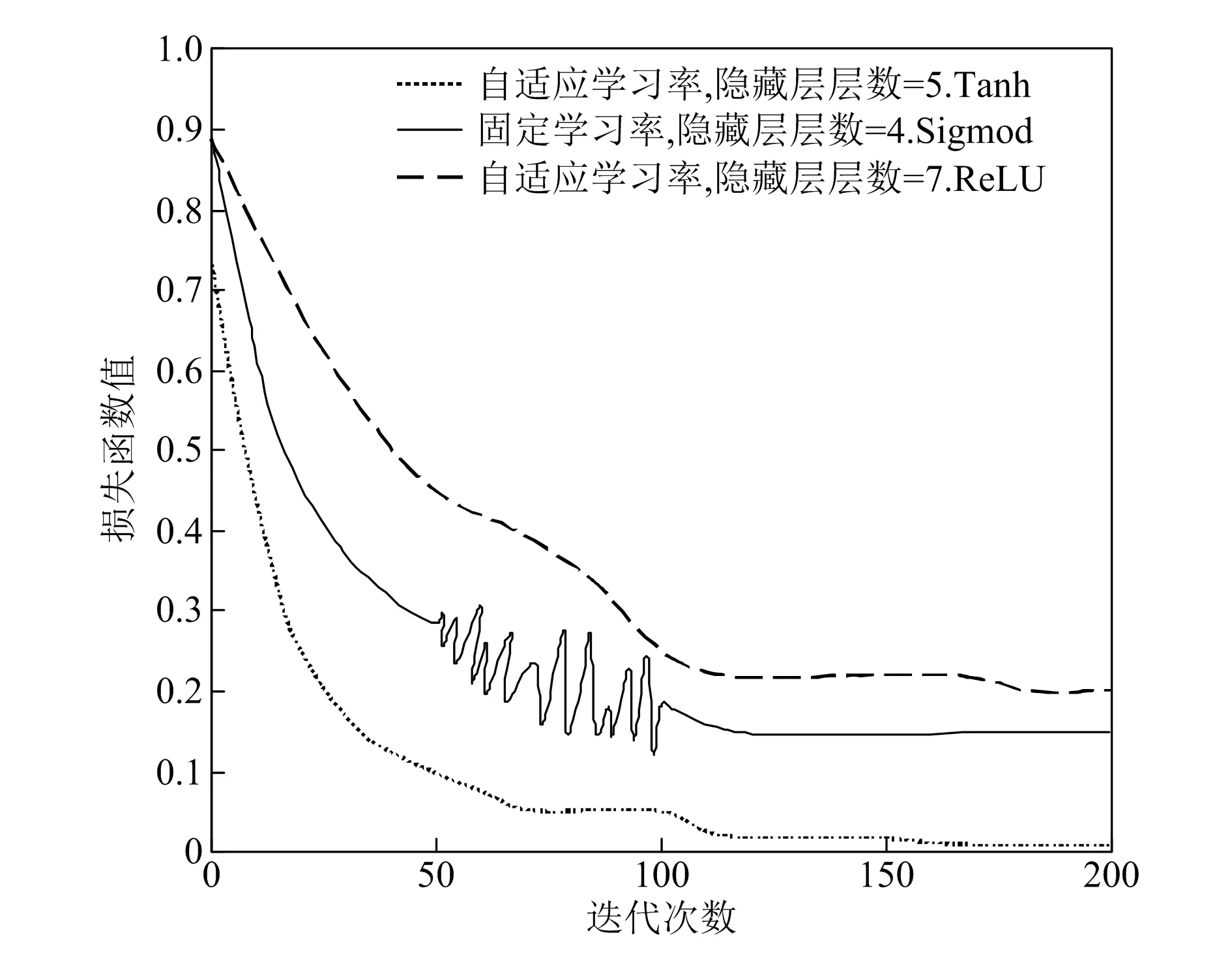
图5 不同激活函数对Loss值的影响
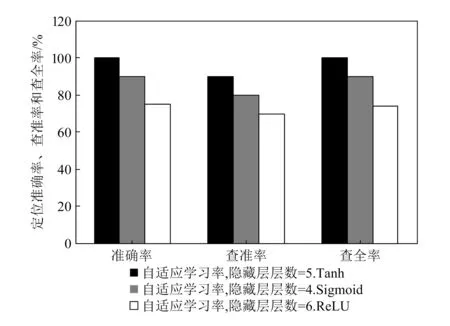
图6 不同激活函数对模型指标的影响
4.2.3不同算法模型性能对比
在上述最优参数下,建立SDH故障定位的DNN模型。同时以CNN、GA、AA、FA的故障定位作为对比[10],分别对采集到的告警数据进行仿真预测,仿真结果如图7所示。由图7可知,基于DNN模型的故障定位准确度高于CNN、GA、AA、FA的故障定位模型的准确度,说明基于DNN模型的故障定位效果更好。
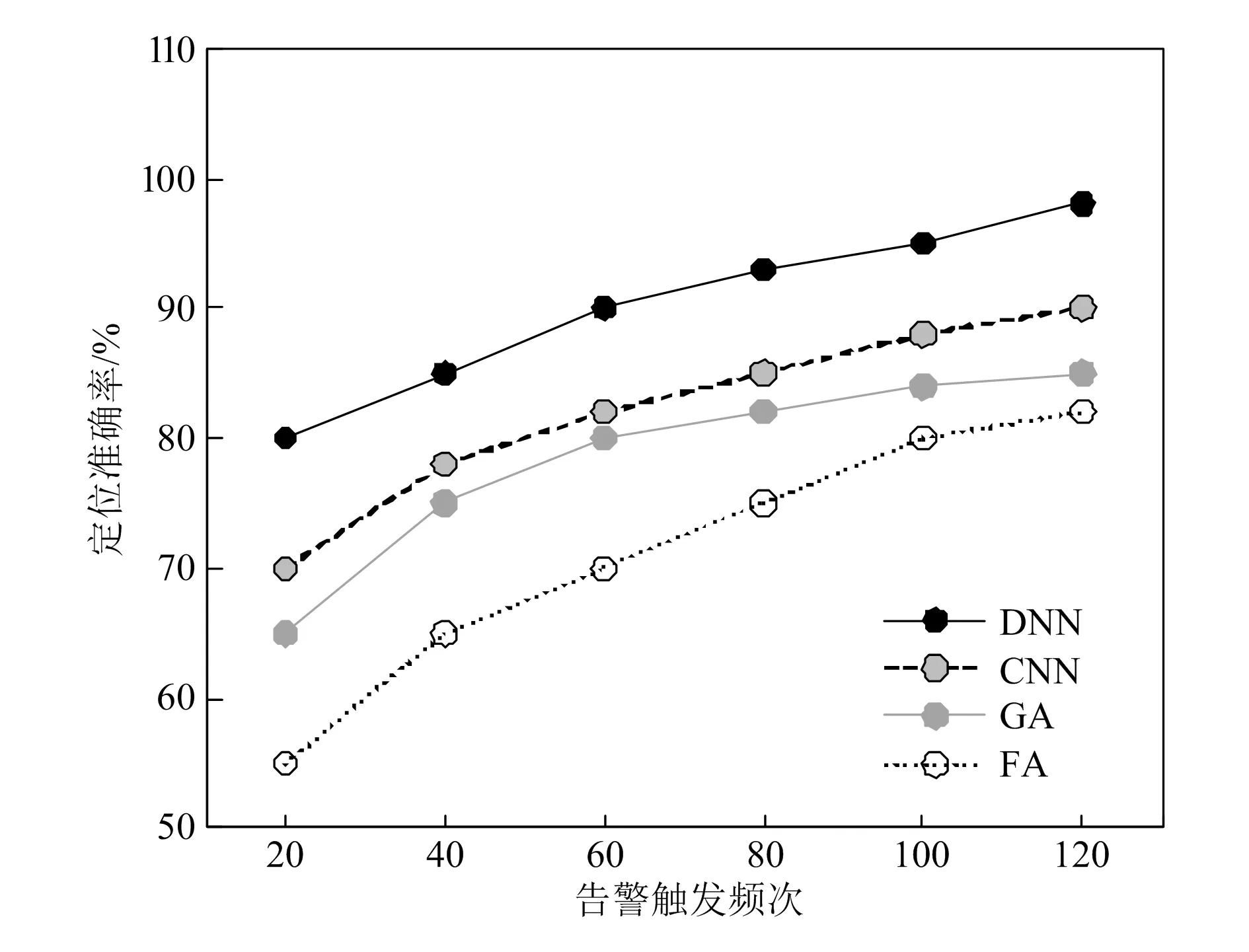
图7 不同故障定位算法的准确度
5 结束语
通过文中仿真结果可知,不同模型参数对模型性能具有巨大的影响,当模型采用自适应学习率、Tanh函数、隐藏层层数为5时,模型性能更优秀。与CNN、GA、AA、FA的故障定位模型相比,本文提出的基于DNN模型的SDH设备运维故障定位的准确率更高,更能准确定位故障。
猜你喜欢
当代陕西(2020年21期)2020-12-14
当代陕西(2020年21期)2020-12-14
航空模型(2019年4期)2019-03-18
现代电子技术(2018年20期)2018-10-24
现代情报(2018年11期)2018-01-07
花样盛年(2016年12期)2017-01-09
新高考·高一数学(2016年4期)2016-12-02
中国民族医药杂志(2016年2期)2016-05-14
中国民族医药杂志(2016年4期)2016-05-09
哈尔滨理工大学学报(2015年4期)2015-12-31
