
基于缺失森林的医疗大数据缺失值插补
2022-12-16 09:44白洪涛何丽莉毕亚茹张婷婷孙成林
吉林大学学报(信息科学版) 2022年4期
白洪涛,栾 雪,何丽莉,毕亚茹,张婷婷,孙成林
(吉林大学 a.软件学院;b.计算机科学与技术学院,长春 130022;c.第一医院,长春 130012)
0 引 言
数据缺失是一个较为常见的现象[1],是许多数据分析任务中的一个阻碍,并有可能严重损害机器学习模型的性能,以及基于这些模型的下游任务。如果能以一种合理的方式成功地恢复输入的缺失数据是理解真实世界数据结构的关键。在医疗数据中经常由于各种原因存在大量的缺失值,因此许多研究人员致力于开发医疗数据的插补算法。插补算法也广泛应用于其他领域,如数据压缩、图像补全[2]、RNA(Ribonucleic Acid)序列缺失值补全[3]等。
缺失数据主要有3种类型[4]:1) 完全随机缺失(MCAR:Missing Completely At Random),指数据集中数据缺失是完全随机的,与缺失变量本身和其他变量无关;2) 随机缺失(MAR:Missing At Random),指数据集中数据缺失并不是完全随机的,而与其他变量完全有关;3) 非随机缺失(MNAR:Missing Not At Random),指数据集中数据缺失的产生不仅与变量本身取值有关,也与其他变量的取值有关,这种缺失机制大都不是随机因素所造成的,经常存在主观因素或变量之间的相互关联,通常是不可忽略的。笔者针对完全随机缺失情况进行研究。
目前人们对缺失数据处理主要有3种策略。1) 不进行处理,这是一种比较简单的方法,常用于缺失数据的样本量很少时,采用插补法,可能会影响样本的总体分布特点和变量间的关系,使原始数据集产生噪声[5]。2) 删除样本法,即将含有缺失值的数据样本删除。对数据缺失率较小,该方法非常高效。但该方法局限性在于它是以缩小数据样本量获取完整数据集,会导致数据信息的浪费,丢失了隐藏在缺失值中的信息[6]。3) 缺失值插补法,对数据集中缺失的数据,通过特定方法进行缺失值填充处理,使数据成为一完整数据集,是针对缺失数据最为常见且较有效的解决方法。常见的缺失数据插补方法有:K最近邻插补法[7]、多重插补法[8-9]、矩阵补全[10]和基于深度学习方法等。
目前针对医疗数据集缺失值处理相关研究报道较少,尤其是当数据集中同时存在离散型变量和连续型变量,缺少合理的解决方法。近年来,大量研究显示谷丙转氨酶(ALT:ALanineamino Transferase)升高是糖尿病发生的危险因素之一[11-12]。ALT被认为是肝功能的替代标志物,也是预测糖尿病的重要风险指标。许多研究报告表明,ALT即使在正常范围内,仍与T2DM(Diabetes Mellitus Type 2)风险增加有关。横截面研究显示,ALT与糖尿病之间存在持续的正相关[13],且无阈值效应。因此,笔者使用缺失森林插补法、K最近邻插补法、多重插补法和GAIN(Generative Adversarial Imputation Nets)[14]插补法对两个医疗数据集进行缺失值插补。同时,通过分析糖尿病数据集中ALT与糖尿病之间的剂量-反应关系探讨缺失森林插补法对下游任务的影响。
1 缺失数据插补方法
1.1 缺失森林插补方法
缺失森林插补法[15]是一种建立在随机森林算法基础上的非参数插补方法,其既可用于连续型变量也可用于离散型变量,不需要对数据分布进行假设。该方法首先对缺失数据集进行快速插补,即对连续型变量选择该变量平均值对缺失数据进行插补,离散型变量选择该变量众数对数据进行插补,若众数存在多个相同值,则随机选择其中一个即可,同时将变量按照缺失值的数量升序排序。然后对每个特征变量,使用缺失森林插补法步骤如下:
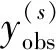

3) 重复上述插补过程,直到达到终止迭代条件γ和最大迭代次数。
算法如下:
输入:缺失数据集X。
Step1 对存在缺失值的连续变量,应用该变量的平均值对缺失值进行初始插补,对存在缺失值的离散变量,应用该变量的众数对缺失值进行初始插补;
Step2 计算缺失数据集X中各个变量的缺失率,将缺失率从小到大排序,并将对应的变量存入向量m中;

Step5 对于s∈m,依次执行:

Step6 更新γ,itermax++,返回Step3;
输出:插补后的矩阵Ximp。

对连续型变量,N为连续型变量的集合,差异可定义为
对离散变量,C为离散型变量的集合,差异可定义为
其中NA为离散型变量缺失值的个数,n为样本数量。
2 实验与结果分析
2.1 数据集
笔者选取了中国Rich Healthcare Group数据库中的糖尿病数据集[16](以下简称数据集1)、Dryad Digital Repository(https:∥doi.org/10.5061/dryad.8q0p192)(以下简称数据集2)两个数据集。
2.2 4种插补方法的比较
2.2.1 评价指标
对连续型变量,选择标准均方根误差(NRMSE:Normalized Root Mean Squared Error,ENRMSE)[15]作为评价指标,其值越小,误差越小,插补效果越好。如下

(1)
其中Xtrue为真实完整数据集,Ximp为插补后的数据集。
对离散型变量,选择错误分类占比率(PFC:the Proportion of Falsely Classified,RPFC)[15]作为评价指标,其值越小,误差越小,插补效果越好。如下

(2)

2.2.2 插补结果
将数据集分别设置10%,20%,30%,40%的随机缺失率,然后针对数据集在不同缺失率的情况下,分别使用缺失森林插补法、多重插补法、K最近邻插补法和GAIN插补法进行缺失值插补,最后计算插补后的数据集与真实数据集间的评价指标,实验结果如表1,表2所示。

表1 数据集1NRMSE指标和PFC指标Tab.1 Dataset 1 NRMSE metrics and PFC metrics

表2 数据集2 NRMSE指标和PFC指标Tab.2 Dataset 2 NRMSE metrics and PFC metrics
由表1,表2可见,根据两个数据集的NRMSE和PFC的评价指标,缺失森林插补法误差较低,插补效果优于K最近邻插补法、多重插补法和GAIN插补法。即使数据集2中缺失森林插补误差较大,但插补效果也优于其他3种方法。因此,缺失森林插补法可有效解决医疗数据缺失问题。
2.3 缺失森林插补法对下游任务的影响
为检验缺失森林插补法对下游任务的影响,笔者使用数据集1原始数据(未插补)与插补后数据探讨ALT与糖尿病之间的剂量-反应关系。采用限制性立方样条模型,在调整年龄、性别、吸烟状况、饮酒情况、BMI(Body Mass Index)、舒张压、收缩压、糖尿病家族遗传史、AST(ASanine aminoTransferase)和胆固醇因素后,分别得到了原始数据与插补后数据ALT与糖尿病之间的剂量-反应关系图(见图1,图2),其中虚线表示置信区间。从图1,图2中可看出,数据插补前后变化趋势一致,均存在显著的线性关联,当ALT浓度升高,糖尿病发病率也随之增加。由此可见,缺失森林插补法稳定性较好,并不影响下游任务的研究。
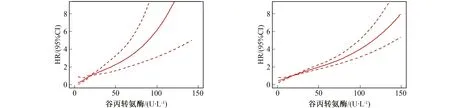
图1 数据集1原始数据ALT与糖尿病发病的剂量-反应关系 图2 数据集2插补后ALT与糖尿病发病的剂量-反应关系 Fig.1 Dataset 1 raw data on the dose-response relationship between ALT and the onset of diabetes Fig.2 Dataset 2 dose-response relationship between ALT and diabetes onset after interpolation
3 结 语
针对医疗数据集中数据缺失问题,笔者提出使用缺失森林插补法进行缺失值补全,从NRMSE和PFC评价指标可以看出,该方法插补误差较低且效果优于K-最近邻插补法、多重插补法和GAIN插补法,即使在误差较高的情况下,该方法插补效果也优于其他3种方法;其次,通过对数据集1中ALT与糖尿病的剂量-反应关系进行分析,证明缺失森林插补法不会对下游任务分析产生不利影响。因此,对缺失率较高的医疗大数据,使用缺失森林插补法进行插补不仅误差较低且稳定性较好,具有一定应用价值。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
课程教育研究(2021年27期)2021-04-13
知识文库(2019年10期)2019-10-20
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
数学学习与研究(2018年16期)2018-11-12
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
山东青年(2016年2期)2016-02-28
新高考·高二数学(2014年7期)2014-09-18
