
基于数据挖掘地域性强关联规则数据提取
2022-12-16 09:38陈刚
吉林大学学报(信息科学版) 2022年4期
陈 刚
(广州华商学院 数据科学学院,广州 511300)
0 引 言
特征挖掘就是准确地提取存储介质中大量的不完整和干扰特征,从而挖掘出人们所需要的潜在有用信息。若想进一步使用大数据需要大量的人力和时间,往往不能得到有价值的分析结果,且关联属性不强,数据提取过程的融合性不好。
成红红等[1]设计了一种有效的相关度测量方法,该方法不存在相关关系的偏差。根据大数据环境下底层关联关系公平排序的要求,结合当前关联度的公理化条件,给出了大数据关联关系度量的可能性质。但这种方法耗时长,不利于实时检索。田方[2]提出了一种基于云计算管理系统的数据查询技术。基于数据挖掘技术,分析了云计算管理系统的数据结构和分布状态模型,并利用数据流互信息特征提取技术对数据进行挖掘,但它需要大量内存和硬件资源。
笔者提出一种基于数据挖掘算法的地域性强关联规则数据提取方法。强关联规则数据,即如果在数据x前和后不久访问数据y,则数据x和数据y将被关联,反之,同时被访问,为此,引入数据关联度,在计算关联特征数据值时具有明显的优越性,能得到较准确的关联特征数据值。
1 地域性强关联规则数据管理系统分析
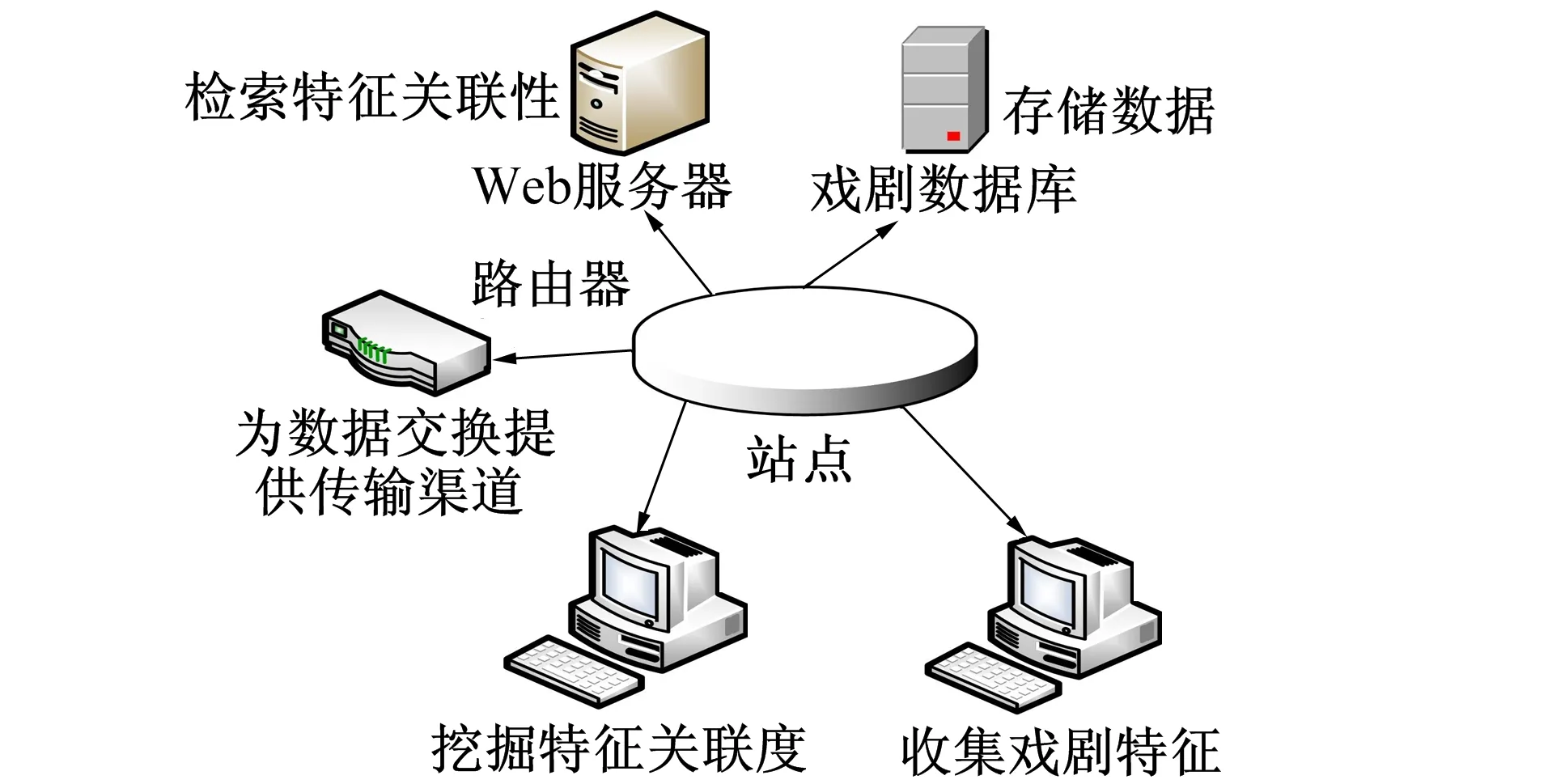
图1 地域性强关联规则数据管理系统Fig.1 Regional strong association rule data management system
地域性强关联规则数据管理系统包括地域种类的划分、存储和顺序的管理等功能。这种设计能给系统带来许多好处,比如提供地域特征的详细分析。系统的硬件支撑平台如图1所示。
如图1所示,该系统利用现有资源,以虚拟社区的形式创建按需开放订阅平台,允许web服务器将收集的信息源发布在互联网上,也可满足用户的需求,查询地域资料,检索特征关联性[3]。并且若没有相关的地域资料,也可通过电子邮件建立地域数据库。通过用户需求处理系统将结果提供给用户,用户要求的信息处理完毕后,工作人员可根据情况进行回复,并以电子邮件的形式提供地域信息,以此收集地域特征,挖掘特征关联度[4-5]。
2 地域数据提取分析方法
2.1 地域特征关联的相似度计算
在地域性强关联规则数据特征挖掘过程中,需要检索速率快和准确性高的方法,为实现地域性强关联规则数据提取,需要计算地域性强关联规则数据特征的相似性,地域检索过程中,用户u选择标记集的特征向量是根据相邻节点v∈Nu对用户实施分析,其主导特征数据表示为

(1)


(2)
通过对同义词和歧义词的协同过滤,使推荐的可靠性和用户的地域性内容和兴趣有所提升。使用余弦相似性过滤同义词,相似度运算式为
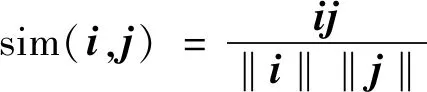
(3)
其中i为同义词的评级向量,j为歧义词的评级向量。
利用数据关联度[6],分析地域信息检索中地域特征之间的关联性,其表达式为

(4)

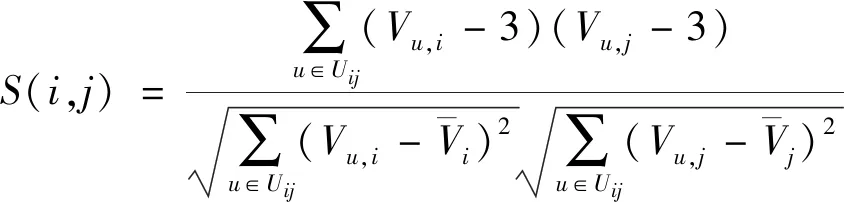
(5)
通过分析标签的上下文信息代替地域信息数量的关联行为,使优先列表受到地域性强关联规则数据特征相似性的约束[8]。详情如表1所示。

表1 相似度约束下的优先级列表Tab.1 The priority list under the similarity constraints
由表1可知,在相似性约束下,利用协同过滤推荐控制查询地域信息种类,利用优先级列表,有效确定上下文信息。
2.2 支持度计算方法
在约束条件Con下,依据支持度和置信度,笔者计算[9],分析地域性强关联规则数据管理的集成性,在关联规则下,若X是A,设Sup(〈X,A〉→〈Y,B〉)用于描述获得的数据集τ中,则Y是B形式的支持度。可得

(6)
其中〈X,A〉和〈Y,B〉为属性概念对,μcyk(ti[xj])为记录ti值对属于概念cxj的属性xj的隶属度,μcyk(ti[xj])的含义与此类似。对于ti,如果其属性值ti[xj](xj∈X,j=1,2,…,r),cxj的隶属度积大于ε(ε为大于零的最小值),说明该记录满足〈X,A〉的条件,并用cxj作为梯形云数字特征表,当ti[xj]在概念cxj的期望区间时,隶属度为1,否则隶属度为(0,1)中的某一值。
2.3 置信度计算方法
置信度是指满足〈X,A〉和〈Y,B〉要求的记录在满足〈X,A〉或〈Y,B〉的记录数量中所占的比例,它反映了所发现规则的确定性[10]。采用Conf(〈X,A〉→〈Y,B〉)表示在约束条件下在Con下获得的数据集τ中,如果X是A,则Y是B形式的置信度。可得
根据式(6),式(7)进行简化处理,得

(8)
根据式(6)和式(7)可知,若在满足记录数据的基础上,计算结果不超过阈值范围,可判定为强关联规则。
2.4 相关性分析
通过支持置信度框架,可从地域性强关联规则数据管理系统中挖掘出大量的关联规则。笔者通过Kulczynski,分析测度Kule不平衡的原因,依据关联规则,对不符合条件的数据进行分析和过滤,它具有零不变性质,是两个方向上条件概率的综合,公式如下

(9)
在关联规则蕴涵式内,不平衡率公式为

(10)
由式(10)可知,当Sup(〈X,A〉)和supSup(〈Y,B〉)相同时,IR(〈X,A〉→〈Y,B〉)为0,当Sup(〈X,A〉)和supSup(〈Y,B〉)不同时,二者的不平衡率越大。Kule利用不平衡比解决支持度置信空间不足的问题,筛分出伪项目集的关联规则。
设置10%、50%、50%和0.3的最小Kule阈值和最大不平衡度阈值、最小支持度阈值、最小置信度阈值。数据及关联性分析结果如表2所示。其中,Sup(a,b)为a、b两个方位点同时超标的支持度;Nab为两个方位点a、b同时超标的数据记录数,其余均相同;Conf(a→b)为若方位点a超过标准的置信度,则方位点b也超标,Conf(b→a)为若方位点b超过标准的置信度,则方位点a也超标,Kule(a,b)为Conf(a→b)和Conf(b→a)在方位点a、b上的概率集;IR(a,b)为对方位点a和b不平衡度的评价。
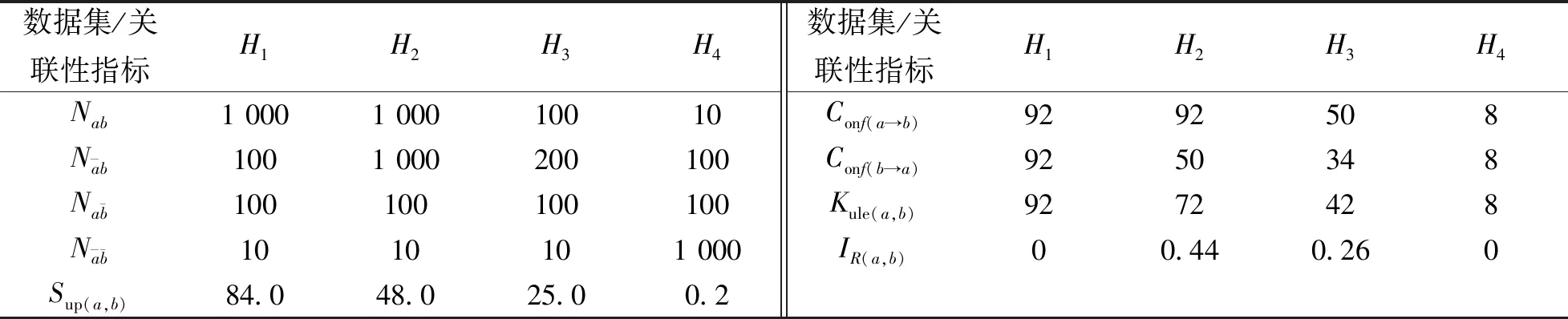
表2 数据及关联性分析结果Tab.2 Data and association analysis results
3 实验结果分析
为验证笔者方法的有效性,选用Matlab 7作为仿真软件,在大型网络数据库中,选取10组测试样本,将10组样本的数据量从500 Mbit逐步增加到5 000 Mbit,将文献[1]和文献[2]方法作为对比对象,测试指标为数据挖掘时间开销,不同方法挖掘时间对比如图2所示。
从图2可以看出,每种挖掘方法的时间成本都随着数据大小的增加而增加。文献[1]和文献[2]关联挖掘方法的耗费时间较长。而笔者挖掘方法耗费时间较短,具有较高的挖掘效率。然后对比不同数据挖掘方法的内存消耗如表3所示。对3种方法分析结果如图3所示。
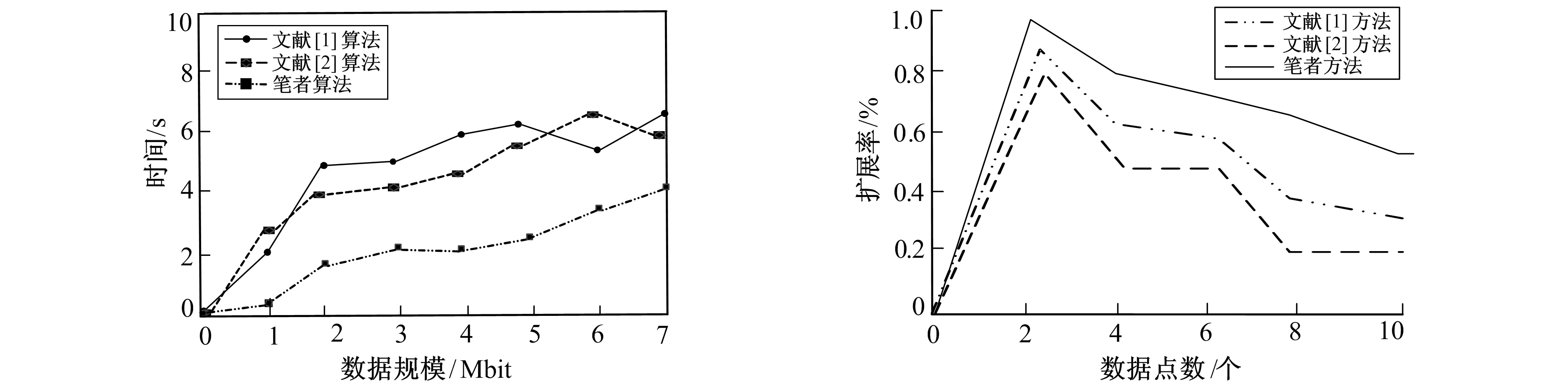
图2 不同方法挖掘时间对比 图3 不同方法扩展率对比 Fig.2 Mining time comparison for different methods Fig.3 Extension rate comparison between different methods
从表3可以看出,笔者方法为0.486 Mbit,内存消耗比较小,不影响系统的正常工作,也不会受到大数据规模操作的影响,在海量数据挖掘方面具有很大的优势。为验证该方法的扩展率,在上述实验条件下,对3种方法进行了比较分析,结果如图3所示。
由图3可知,相比两种文献方法,笔者方法扩展率下降速度较为缓慢,扩展率较高,使挖掘性能有效提升,内存开销可以降到最低极限值。

表3 内存消耗对比结果Tab.3 Memory consumption comparative results (Mbit)
4 结 语
笔者提出一种基于数据挖掘算法的地域性强关联规则数据提取方法,在数据挖掘中的平均时间开销和内存消耗都有所降低,具有一定优势,具备较高的挖掘效率和广泛应用价值。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
九江学院学报(自然科学版)(2022年2期)2022-07-02
小型微型计算机系统(2022年4期)2022-05-09
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
电子技术与软件工程(2016年24期)2017-02-23
读者(2017年5期)2017-02-15
中国科技纵横(2016年20期)2016-12-28
