
基于统计方法学的焦化类污染场地风险筛选决策研究
2022-12-20 06:22武文培陈梦舫韩璐顾明月陈雪艳龚泽瀚李婧
环境科学研究 2022年12期
武文培,陈梦舫,韩璐,顾明月,陈雪艳,龚泽瀚,李婧
1.中国科学院南京土壤研究所,中国科学院土壤环境与污染修复重点实验室,江苏南京 210008
2.中国科学院大学,北京 100049
3.南京凯业环境科技有限公司,江苏南京 210008
4.四川师范大学化学与材料科学学院,四川成都 610066
随着我国经济快速发展和产业结构的升级调整,大批高污染、高能耗工业企业搬迁,遗留工业场地的土壤与地下水污染问题突出,对城市及周边环境具有较大的健康与环境风险[1-4],污染场地的安全再开发利用已成为城市高质量发展的瓶颈问题[5-8].针对工业场地污染状况不清、污染风险不明的问题,我国生态环境部已经出台了一系列管理规范和技术导则以监管工业污染场地的良性流转和安全开发,同时中国科学院南京土壤研究所也率先开发了污染场地土壤与地下水风险评估软件系列(HERA、HERA++、HERA-3D)[9-12]以支持污染场地风险评估技术的实际应用和推广.为提高对工业污染场地的监管效率,我国生态环境部于2018年正式颁布了《土壤环境质量建设用地土壤污染风险管控标准(试行)》(GB 36600−2018),用于对场地污染风险的初步筛查和管控.当场地土壤中关注污染物的浓度等于或低于筛选值时,场地污染的健康风险可以忽略,场地可直接进入开发环节;反之,该场地将进入地方政府环境监管的污染场地名录,需要对场地开展详细调查和风险评估工作,评估关注污染物的健康风险并判断是否需要实施修复措施.因此,在风险初步筛选阶段,场地的污染程度往往决定了该场地是否需要进入污染场地名录的关键要素[7-8].
在污染场地风险评估实践中,依据我国《建设用地土壤污染风险评估技术导则》(HJ 25.3−2019),基于污染物单点浓度的筛选比较是一种常用的方法[13-16].但是人类活动的强烈干扰以及场地土壤的非均质性,往往导致场地土壤污染存在高度的空间异质性[17-18],即使在很小的空间尺度(0.10~1 m)上,不同采样位置也会导致污染物浓度相差数倍甚至更高[18].因此,基于单点浓度代表采样单元或区域土壤的污染程度具有极大的不确定性,可能导致过高或过低估计场地污染的风险水平,难以对污染场地的风险管理形成有效支撑.环境统计学方法则可以基于对大量样本数据的统计分析结果,整体反映场地受污染的平均水平,更加接近场地污染的真实状况,从而降低污染场地风险管控决策的不确定性[19].
目前,基于统计方法的污染场地风险评估研究在我国尚未受到广泛关注和认可,一方面受限于政府部门对统计学方法的接受程度,另一方面我国尚未针对场地污染风险评估工作的环境统计方法颁布专门的技术导则.相关系列导则涉及统计学方法的描述微乎其微,如HJ 25.3−2019导则仅提及可以利用正态分布污染物检测数据平均值的置信上限值计算致癌风险和危害商;《污染地块风险管控与土壤修复效果评估技术导则》(HJ 25.5−2018)指出样品数量≥8个,采用样品平均值的95%的上限值与修复标准进行比较进而评估修复效果.但上述导则并未给出正态分布判别以及置信上限值的计算方法.此外,不同污染物在土壤中赋存和迁移特性的差异导致多数场地污染数据不符合正态分布特征[19-22],对非正态分布的污染物浓度的估计及风险表征方法亟待研究.
在污染场地风险管理中,英美两国已经形成了成熟、系统的统计方法.英国环境署(UK Environment Agency,UK EA)于2008年颁布的《土壤污染浓度与临界浓度比较导则》(Guidance on Comparing Soil Contamination Data with a Critical Concentration)[23](简称“英国CL:AIRE导则”)中详细介绍了统计学方法在临界浓度(如筛选值、管制值或修复目标值)与土壤污染浓度比较以及在场地管理决策中的应用,其统计方法也在我国HERA系列软件中得到应用[10-12].英国环境署于2020年更新了该导则,进一步丰富了场地管理决策方法,并强调全面理解数据集的重要性[24];美国环境保护署(USEnvironmental Protection Agency,USEPA)自1989−2006年先后颁布了多个导则,利用统计学方法评估或管理污染土壤[25-29],此后又相继开发统计学软件ProUCL协助管理决策者做出更加可靠合理的决定[30].经多次补充与修正,该软件于2022年更新至ProUCL 5.2版本,同时发布了ProUCL技术导则(ProUCL Technical Guide,Statistical Software for Environmental Applications for Data Sets with and Without Nondetect Observations)(简称“美国ProUCL导则”)[30]以协助相关人员管理处置污染场地.依据收集的污染物数据,英美两国导则进行风险筛选决策的流程大致相同,依次为描述性统计分析、污染数据审查、分布类型判别、真实平均浓度估算等,最后对场地风险水平进行筛选(见图1).其中英美两国导则在分布类型判断、真实浓度估算及风险水平筛选存在区别.该文以我国某污染场地为研究案例,依据英美两国导则,基于统计方法学估算场地平均浓度进而评估场地的污染程度,并以筛选值作为临界浓度初步筛选污染风险,进而比较上述两种方法的差异性及优缺点,以期为我国建立精细化工业污染场地土壤的健康风险评估方法提供理论依据.
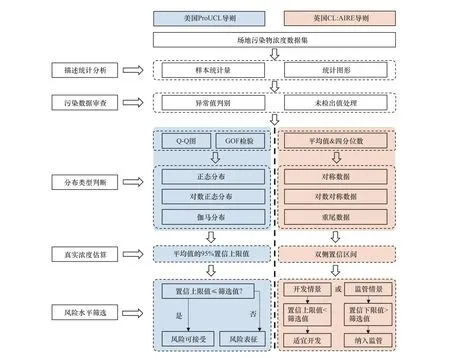
图1 基于统计方法学的污染场地风险筛选决策框架Fig.1 Framework on risk screening decision of contaminated sites based on the statistical methodology
1 研究方法
1.1 研究对象
该研究区域为某焦化场地,包括生活办公区、煤场区、炼焦区、制气区、焦油精炼区(见图2).经初步调查可知场地特征污染物为萘.地层结构自上而下依次为杂填土(0~1 m)、粉质黏土/淤泥质黏土层(1~2 m)和黏土层(2~4 m).采用系统布点法,在0.2、0.5、1.5 m深度分别采集171个土壤样品,在3 m处采集103个土壤样品,累计获取616个萘污染土壤样本.
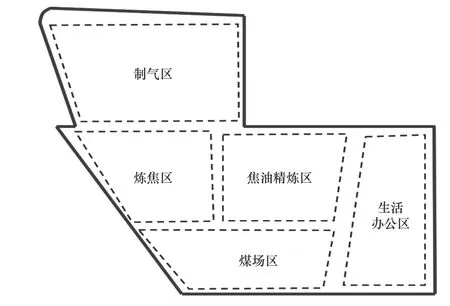
图2 焦化场地历史空间布局Fig.2 Historical space layout of coking contaminated land
1.2 污染数据审查
合理有效的样本数据集是统计学应用的前提,因此在统计分析前需对样本数据集进行审查.数据集要求采取简单随机、分层随机或者分层系统采样方法获得样本;样本均匀分布在整个研究区域,而不应针对疑似污染地块进行加密布点,避免对某一区域施以过高的权重;基于统计分析表征识别场地内异常污染区域;样本位置应处于同一性质的地层,即相同的介质类型;且样本量需足够大以提高统计分析结果的可靠性[24,30].对于不同分布类型和偏度的数据集,样本量的要求也存在区别,一般数据偏度越大,要求的样本量越多[30].
此外,场地调查数据中通常含有大量低于检出限(detection limit,DL)的数据[31],即未检出值(ND).为了保证数据样本的完整性,对未检出的数据也应做出处理. ND数值介于0~DL之间,通常采用0、DL或DL/2替代ND,再对数据统计分析,或者只对高于检出限的数据进行统计分析[23,30-31].但是上述ND数据的处理方法均会影响统计分析的结果,例如,如果使用DL替代ND会高估样本平均值、低估变异系数,而用0代替则产生相反的结果[19].英国CL:AIRE导则采用DL或DL/2替代ND,但是当ND在数据集中的比例大于15%时,则需对ND替代之后的数据进行敏感性分析,判断选择不同替代值对数据统计结果的影响程度[23].该文采用DL/2替代法处理ND值. 除替代法外,美国ProUCL导则中提供了Kaplan-Meier(K-M)非参数估计法,也称为“乘积极限估计法”(product limit estimate,PLE)[32]和次序统计量回归法估计样本中ND[33-34].
除ND值外,样本中可能存在严重偏离样本的异常值,这可能是因为采样或者分析操作失误等引起的,也可能是场地真实情况,必须谨慎判断、识别异常值[19,23,29-30].通常应对包含异常值和剔除异常值的样本分别进行统计分析,判断异常值对统计结果的影响程度,然后决定异常值的取舍.英美两国导则均提供了异常值判别方法,包括Dixon、Rosner、Grubbs和Walsh检验等方法[23,30].该研究采用Rosner检验方法判断异常值,该方法要求样本量大于25,且异常值的个数小于10个[35].具体判断步骤如下.
第一步:假定场地污染采样分析结果为Xi,按照递增顺序排列得X(1),X(2),···,X(n),确定数据中异常值样本点的最大数量r0(r0≤10).
第二步:计算n个样本的平均值x和标准差s,分别记为和s(0).首先确定距最远的样本,记为y(0).从数据集中剔除y(0),计算剩余样本点的平均值和标准差,分别记为和s(1);其次确定距离最远的值,记为y(1). 从数据集中剔除y(1),计算剩余样本点的平均值和标准差,记为x(2).依次类推直到去除r0个异常值.计算完成后,得到数组如下所示:,s(0),y(0)];,s(1),y(1)]; ···;,s(r0−1),y(r0−1)].

第三步:检验数据集中是否存在r个异常值,计算检验统计量Rr:
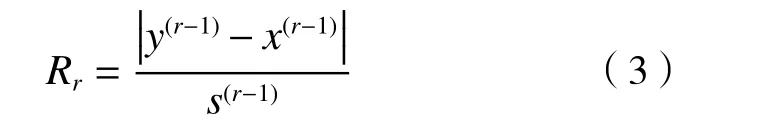
将Rr与临界值λr比较:如果Rr≥λr,则存在r个异常值,否则返回第三步检验数据是否存在r−1个异常值,直至确定数据集中的全部异常值,参数r从r0开始至1结束,临界值λr可参考USEPA相关导则[29].此外,Rosner异常值检验法可与箱尾图和Q-Q图结合使用,帮助决策者确定潜在异常值的数量[30].
1.3 数据分布特征判断
污染数据的分布特征与真实平均浓度的估算结果密切相关,准确分析数据分布特征是评估场地污染程度的前提.通常,从数据的集中趋势、离散程度和分布形状3个方面测度和描述数据的分布特征,集中趋势反映数据向中心靠拢的程度;离散程度反映数据远离中心值的趋势;分布形状反映数据的偏态和峰态[36].
美国ProUCL导则首先利用统计直方图和箱线图刻画场地污染数据,并统计了包括样本量、平均值、中位数、标准差、偏度和峰度系数等测度值分析数据分布特征;同时,美国ProUCL导则总结了场地污染数据常见的3种分布类型−正态分布、对数正态分布、伽马分布,并利用Q-Q图(quantile-quantile plot)和拟合优度(goodnessof fit,GOF)检验方法进行判断.GOF是一种用于判断检测数据与理论分布预期值一致性的统计假设检验方法,其中Shapiro-Wilk(S-W)和Lilliesfors GOF检验用于判断数据是否服从正态分布和对数正态分布[37-38],而Kolmogorov-Smirnov(K-S)和Anderson-Darling(A-D)GOF检验用于判别数据与伽马分布的符合程度[39-40].S-W检验属于P值检验法,P值表示原假设为真时样本观察结果或更极端结果出现的概率[36].假设显著性水平α=0.05,当S-W检验P>0.05时,则可接受数据呈正态(对数正态)分布的假设,否则拒绝原假设.其余检验方法属于临界值检验法,当检验统计量小于检验临界值时,可接受数据的分布假设,反之则不能接受.
英国CL:AIRE导则同样采用直方图和箱线图刻画场地数据,通过分析数据的对称性、离散程度、平均值与中位数、上四分位数和下四分位之间的关系将污染物数据归为3类,分别是对称数据、对数对称数据和重尾数据[24].与美国ProUCL导则采用严格的假设检验方法不同,英国CL:AIRE导则依据经验法则判断数据类型.对称数据特征的判断依据为平均值与中位数接近,且直方图以中位数为轴呈镜像对称形式.对称数据一般符合正态分布数据类型,该类型污染物通常在土壤中迁移扩散的能力较强,在一定时间内可与土壤基质充分混合[24].对数对称数据直方图明显不对称,数据平均值大于中位数且小于上四分位数,取自然对数后数据符合对称数据特征.符合对数对称特征的污染物往往不易分解,土壤污染程度较低且空间异质性较高[24].重尾数据直方图特征与对数对称数据相似,但是数据平均值是中位数的10倍以上且大于上四分位数,取自然对数后直方图仍呈现非对称形式.一般而言,如果场地历史上发生过污染泄漏事故或存在扩散性污染物间断性进入土壤环境,污染物数据集往往符合重尾数据特征[24].一般而言,对称数据服从正态分布,对数对称数据可能服从对数正态分布或者伽马分布,而重尾数据由于数据尾部存在明显偏离样本的极值,通常不服从上述3种分布.
1.4 场地污染程度评估
1.4.1 UCL95计算
为降低样本平均值的不确定性,美国ProUCL导则采用污染物浓度平均值的UCL95(95%upper confidence limit,UCL95)估计场地污染物真实平均浓度,并据此计算污染物致癌风险和非致癌危害商.UCL95的数学含义是污染物浓度的实际平均值等于或低于该值的概率为95%[30].当UCL95小于或等于筛选值时,场地风险水平可接受,场地适宜开发;反之,则需对场地关注污染物进行详细风险评估;利用ProUCL软件,该研究使用参数法,即学生t-UCL、H-UCL和近似伽马-UCL分别计算UCL95估算正态、对数正态和伽马分布污染物真实平均浓度[30,41-42].如果数据不服从上述3种分布类型,则采用非参数法切比雪夫不等式计算UCL95[43],计算方法如式(4)~(7)所示.
学生t-UCL:

1.4.2 置信区间计算
英国CL:AIRE导则最先采用假设检验的方法判别污染物浓度是否超标[23],首先假设污染物浓度大于或者小于筛选值,通过比较检验统计量与对应检验临界值的大小来判断污染物浓度是否超标.当检验统计量在临界值一侧时,假设为真,在另一侧时假设为假.该方法利用机械的“明线”方法判断污染物浓度是否超标,这可能导致错误的风险管控决策[44].2020年修订后的英国CL:AIRE导则摒弃了对上述单一检验方法的依赖,强调全面理解数据集的重要性[24].修订后的统计方法基于中心极限定理(central limit theory,CLT),计算不同置信水平下污染数据的双侧置信区间.该定理指出当样本量n趋于无穷大时,样本平均值的渐近分布服从平均值为μ和方差为的正态分布[36].其中,置信下限(LCL)和置信上限(UCL)的具体计算过程如式(8)(9)所示.最后,通过刻画污染物空间分布特征,分析不同点位污染物浓度之间是否存在关联,从而分析污染物可能的来源.

与美国ProUCL导则仅使用UCL与临界浓度进行比较不同,英国CL:AIRE导则针对污染场地的未来用途,分别在开发(Planning Scenario)和监管(Part 2A Scenario)两种情景下进行污染场地管控决策[23-24].开发情景判断场地是否适宜开发,该情景下需判断“场地土壤的污染风险是否可接受”,如果UCL低于筛选值,则场地适宜开发的可能性更大;而监管情景判断场地是否需要监管,该情景下需判断“场地土壤的污染风险是否超出可接受水平”,如果LCL高于筛选值,则场地有必要纳入监管.
2 结果与讨论
2.1 萘检测数据分析处理
2.1.1 描述性统计分析
该场地未来用地类型为居住用地,基于场地一类用地规划下,萘筛选值为25 mg/kg.根据地层结构,该研究将采样深度为0.2和0.5 m的土壤样品代表第1层土壤污染状况,将采样深度为1.5和3.0 m的样品分别代表第2层和第3层土壤污染状况.对土壤样品中萘浓度的初步统计分析结果如表1所示,所有深度土壤样品中,萘的浓度平均值均小于筛选值(25 mg/kg),但其最大值均高于筛选值.不同深度采集样本浓度的偏度表现为0~1 m<2~4 m<1~2 m(偏度依次为0.60、1.53、3.45),离散程度表现为0~1 m<2~4 m<1~2 m(标准偏差依次为4.62、8.37、13.26)(见表1).此外,从萘的污染数据直方图(见图3)中也可以清晰观察到数据的分布特征:0~1 m土壤中,数据直方图大致呈现以中位数为轴的对称图形,属于正态分布;而1~2 m和2~4 m土壤的数据则呈现右偏分布,数据主要集中在坐标轴左侧.

表1 土壤样品中萘浓度统计描述Table1 Statistical description on naphthalenecontaminated soil samples
2.1.2 ND和异常值处理
该研究采用污染物浓度的DL/2代替数据样本中的ND值,由于ND样本量所占总样本量的比例不到1%,远小于需对ND值进行敏感性分析的阈值(比例为15%),因此不考虑ND值对统计量的影响.根据直方图数据的分布特征(见图3)可知,0~1、1~2和2~4 m数据集中分别存在2、3和1个明显偏离数据集中其他样本的观测值.假设上述明显偏离的观测值为异常值,基于5%的显著性水平,经Rosner检验(见表2)可知,检验统计量Rr均大于对应的临界值λr,因此0~1、1~2和2~4 m数据集中分别存在2、3和1个潜在异常值.异常值的取舍会影响UCL95和置信区间的计算结果,进而影响场地风险筛选的决策结果.
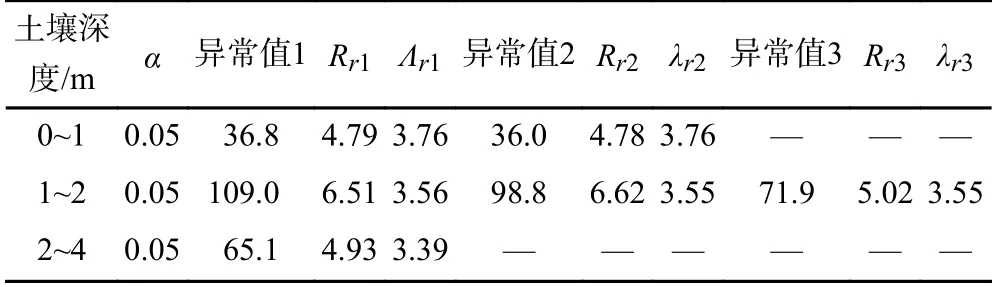
表2 萘浓度数据潜在异常值评估结果Table2 Evaluation of potential outliers for naphthalene concentration dataset
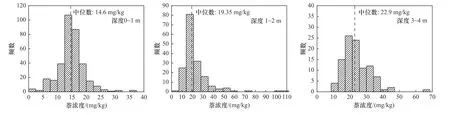
图3 不同土壤深度下萘浓度分布直方图Fig.3 Histogram of naphthalene concentration dataset at different depths
2.1.3 萘数据分布类型
美国ProUCL导则采用严格的统计学方法并结合Q-Q图示法判断污染数据的分布类型.Q-Q图示法是数据分布假设检验的一种直观方法,使用分位数坐标反映样本检测值与理论分位数预测值之间的关系.一般来说,如果Q-Q图中数据点越靠近回归线y=x两侧并均匀分布,则表示数据服从检验的分布形态.该场地不同土壤深度萘浓度数据的Q-Q图如图4所示,根据萘浓度数据与回归线的吻合程度可知,0~1 m土壤中萘的浓度近似服从于伽马分布;1~2 m土壤中3种分布预测的数据点与回归线均存在较大偏离,因此1~2 m数据不符合这3种分布;2~4 m土壤中除存在1个明显偏离的数据点外,对数正态分布预测的数据点最贴合回归线,因此数据可能近似服从对数正态分布.此外,Q-Q图也可直观识别异常值,从图4可以看出,0~1、1~2和2~4 m数据集中分别存在2、3和1个明显偏离的异常值点,这与上述异常值检验结果一致.
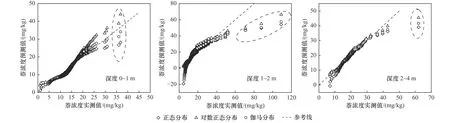
图4 萘浓度数据的Q-Q图检验结果Fig.4 Quantile-Quantile plot of naphthalene concentration dataset
由于Q-Q图仅是一种直观的图示法,需采用更严格的GOF检验法判断萘数据的分布类型.假设显著性水平为0.5,检验结果如表3所示.根据近似S-W和Lilliefors检验以及K-S和A-D检验可知,2~4 m土壤中萘浓度数据对数正态分布和伽马分布的检验统计量(TS)均小于检验临界值(CV),表明该数据集符合对数正态分布和伽马分布,而其余两个深度的萘浓度数据不符合上述3种常见的分布形态.

表3 萘浓度数据拟合优度假设检验结果Table 3 Statistical hypothesis testing for naphthalene concentration dataset
英国CL:AIRE导则利用箱线图中统计量之间的关系来定性判断数据的分布类型.如图5所示,0~1 m土壤中,萘浓度的上四分位数到中位数的距离近似等于下四分位数到中位数的距离,箱线图以中位数为对称轴近似镜像对称;最大值到上四分位数的枝干长度与最小值到下四分位数的枝干长度接近,并且样本的中位数平均值近似相等,因此0~1 m土壤中萘的浓度数据为对称数据.1~2 m 和2~4 m土壤中萘浓度数据的箱线图则呈现非对称形态,其平均值均大于中位数但小于上四分位数,且最大值到上四分位数的枝干长度显著大于最小值到下四分位数的枝干长度,因此萘的浓度数据符合对数对称数据特征.通过对比英美两国导则可知,美国ProUCL导则严格依据GOF检验的结果判断数据分布类型,而英国CL:AIRE导则相对宽松,更利于对数据整体特征的掌握.
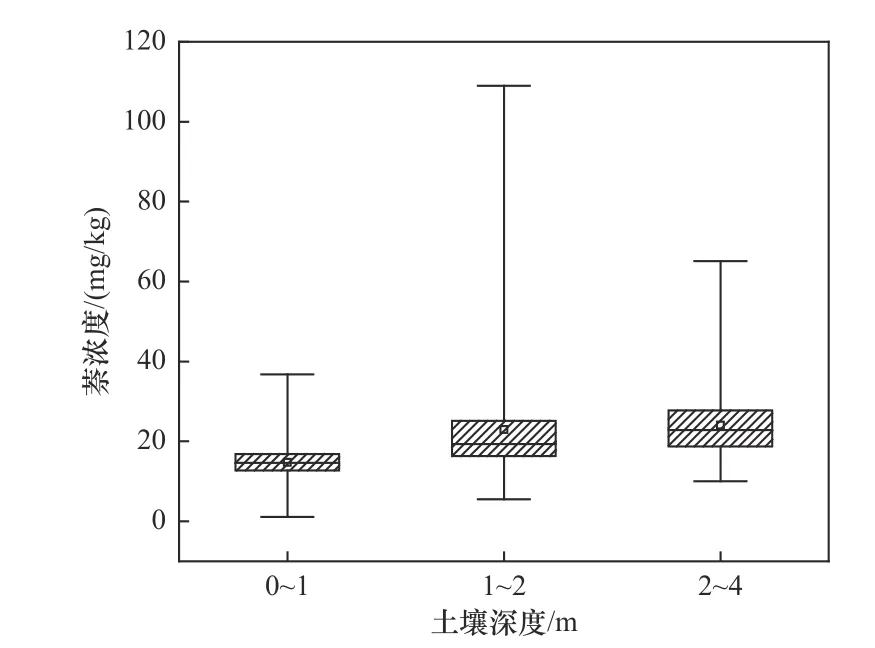
图5 不同土壤深度萘污染物箱线图Fig.5 Box-plot of naphthalene concentrations at different depths
2.2 萘浓度估计及管控决策
2.2.1 单侧上限值UCL95
美国ProUCL导则根据数据分布类型、偏度和样本量选择最适宜的方法计算UCL95.正态GOF检验结果(见表3)表明0~1 m土壤的数据严格意义上并不服从正态分布,但数据具有较小的数据偏度(0.60)(见表1)和良好的对称性(见图3),因此认为数据近似服从正态分布,仍可以选择学生t-UCL估计真实平均浓度.1~2 m土壤数据不符合美国ProUCL导则中已知的污染数据分布类型,因此使用非参数法切比雪夫不等式计算UCL95估算真实平均浓度.2~4 m土壤数据同时符合对数正态和伽马两种分布类型,针对同时满足这两种分布的数据,依据美国ProUCL导则选择基于伽马分布UCL估计真实平均浓度以提高统计结果的可靠性[30]. UCL95计算结果如表4所示,0~1m土壤中萘浓度为15.18 mg/kg(小于筛选值),而1~2 m和2~4 m土壤中萘的浓度分别为27.34和25.40 mg/kg,略高于筛选值(25 mg/kg),需进一步考虑异常值对UCL95计算结果的影响.将异常值剔除后,不同深度土壤萘浓度的UCL均减小且都低于筛选值.针对此种情形,需仔细审查异常值样本在采样、处理分析以及数据转录过程中的规范性和准确性,判断异常值的来源.如果条件允许,需对该采样点进行重复取样,分析污染来源.如果异常值对应的采样点位存在污染的可能,基于保守原则选择保留异常值的UCL95代表场地污染物真实平均浓度,该污染场地存在风险.
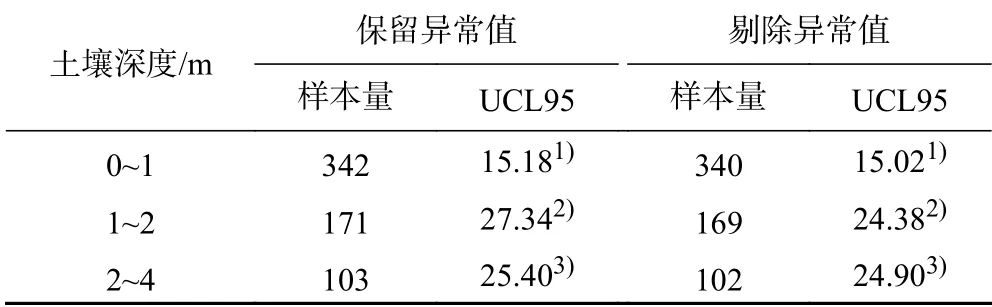
表4 美国ProUCL导则计算的萘浓度置信上限值Table 4 The calculated UCL of naphthalene concentrations based on USstatistical methods
2.2.2 双侧置信区间
英国CL:AIRE导则采用双侧置信区间估计场地萘真实浓度值.置信水平为0.80、0.90、0.95、0.99时萘污染浓度置信区间如表5所以.以0~1 m为例,萘浓度为14.37~15.01 mg/kg的可能性为80%,为14.28~15.10 mg/kg的可能性为90%,为14.20~15.18 mg/kg的可能性为95%,以此类推.随置信水平的增加,LCL逐渐减小,UCL逐渐增大,置信区间的范围逐渐增大.为了降低决策风险的不确定性,英国CL:AIRE导则建议至少选择两个置信区间进行判断.由表5可见,在开发情景下,即使在0.99的置信水平下0~1 m土壤中萘的UCL(15.34 mg/kg)也小于筛选值,因此萘未超标,不需要修复;1~2 m土壤中,虽然0.95置信水平下萘的UCL(24.93 mg/kg)小于筛选值,但是当置信水平为0.99,UCL增至25.56 mg/kg,因此该场地萘浓度仍有很小的可能高于筛选值,需重点关注1~2 m深度的超标点位,尤其是异常值所在点位.2~4 m土壤萘浓度UCL均大于筛选值,综合以上各深度萘浓度估算结果,场地不满足开发条件.当剔除异常值后,0~1和1~2 m土壤中萘浓度在所有置信水平下的UCL均低于筛选值,但是2~4 m土壤萘浓度的UCL在0.90的置信水平下(24.36 mg/kg)低于筛选值,而在0.95的置信水平时UCL(25.10 mg/kg)略高于筛选值,因此开发场地仍具有一定的风险.如果在监管情景下,由于所有深度萘浓度的LCL均显著低于筛选值,因此无需将场地纳入环境监管名录,即使剔除异常值后所有深度土壤萘浓度LCL也都低于筛选值.因此,在监管情景下,异常值的取舍对场地的最终决策无影响,场地均不需要纳入监管.

表5 基于中心极限定理的不同土壤深度萘浓度的置信区间Table 5 CLT theory-based confidence interval of naphthalene concentrationsat different depths
此外,针对非正态污染数据集,相同置信水平下英美两国导则计算的UCL相差较大,如在0.95的置信水平下美国ProUCL导则计算1~2 m土壤中萘浓度的UCL(27.34 mg/kg)大于其依据英国CL:AIRE导则的计算值(24.93 mg/kg);而2~4 m深度则相反(英国CL:AIRE导则计算的UCL=25.70 mg/kg,大于美国ProUCL导则计算的UCL=25.40 mg/kg).由此可知,UCL计算方法的选择对污染浓度的估算影响较大,甚至导致相反的结论.一般而言,对于非正态数据集,美国ProUCL导则推荐的UCL更接近污染物真实值,但是英国CL:AIRE导则可以通过调整置信水平或增加样本量的方法降低污染物浓度估计值与真实值之间差距,提高风险决策的可靠程度.
此外,英国CL:AIRE导则提供了污染场地空间分布图的绘制方法,用于判断不同采样点位污染物浓度是否存在相关性.根据箱线图上四分位数(QU)、中位数(Me)和下四分位数(QL)将污染物浓度(Ci)划分为4个区间,即Ci≤QL、QL

图6 污染场地不同土壤深度土壤中萘浓度的空间分布Fig.6 Spatial naphthalene distribution for a contaminated site
3 结论
a)基于英美两国导则对某萘污染场地进行估计,0~1 m土壤中萘的真实平均浓度小于《土壤环境质量建设用地土壤污染风险管控标准(试行)》(GB 36600−2018)第一类建设用地的筛选值,而1~2 m和2~4 m土壤中萘的浓度大于筛选值,基于场地一类用地规划下,污染场地存在不可接受风险,需进行详细风险评估.
b)基于收集的样本数据,英美两国导则筛选污染场地风险的流程基本相同,均依次进行描述统计分析、污染数据审查、分布类型判别、真实平均浓度估算,最后进行风险水平筛选.异常值会影响污染物真实浓度的估计,当估计污染物浓度接近于筛选值时,异常值取舍显著影响污染场地风险筛选的决策,需要重新审查数据判断导致数据异常的原因.
c)美国ProUCL导则采用严格统计学方法识别数据的分布类型并采用与之相应的UCL95方法计算污染物的真实平均浓度,该方法决策结果更加可靠,但要求相关从业人员熟练掌握统计学方法;相反,英国CL:AIRE导则对数据的分布没有要求,均采用基于中心极限定理的方法计算置信区间估算真实平均浓度,方法简单易于操作.
d)针对国内污染场地统计学应用缺乏的现状,综合考虑英美两国导则的优缺点,建议我国优先推广相对简单的英国CL:AIRE导则中的统计学方法,逐步融入美国ProUCL导则中的统计学方法以提高风险决策水平,以期实现统计学方法在我国的污染场地风险管控中的重要作用.
猜你喜欢
今日农业(2021年11期)2021-11-27
环境科学研究(2021年6期)2021-06-23
环境科学研究(2021年4期)2021-04-25
少儿科学周刊·儿童版(2021年23期)2021-03-24
中学生数理化·高一版(2021年2期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
中国工程咨询(2012年4期)2012-02-14
中国工程咨询(2012年5期)2012-02-13
