
终端直通辅助的移动边缘计算任务动态卸载方案
2022-12-30 04:01徐天成
无线电工程 2022年12期
李 斌,徐天成
(南京信息工程大学 计算机学院,江苏 南京 210044)
0 引言
随着5G、物联网和人工智能的融合与快速发展,以及日益增长的用户计算资源需求,利用移动边缘计算(Mobile Edge Computing,MEC)在网络边缘卸载任务,已成为未来互联网发展的重要方向[1-2]。其优势在于能够为网络边缘用户提供近距离通信,并且有效减轻用户设备的压力,同时有利于与物联网和云计算等新技术的融合应用。
为了解决用户资源和计算能力有限的问题,提出了基于终端直通(Device-to-Device,D2D)技术的卸载模式作为MEC的一种有效增补[3],旨在将大量的计算和存储资源协同控制和管理起来,以完成密集型应用任务[4-6]。同时,未来物联网、边缘计算网络等新网络场景高速发展,智能设备数量和用户需求也随之大幅增长,如何将有限的计算、带宽和存储等网络资源最大程度利用起来,并在大量的终端数据上实现自动管理,以获得更高效的网络传输性能和通信质量是实现5G应用急需解决的热点研究问题之一。
关于D2D和MEC集成化的任务卸载方案已有相关研究[7-9]。文献[10]提出了具有边缘计算和D2D通信的5G蜂窝网络节能计算卸载方案,采用Lyapunov优化技术框架解决问题。文献[11]将用户的卸载决策问题表述为序列博弈,为了实现纳什均衡,提出了一种多用户多目的地计算卸载方案。文献[12]将任务调度和功率分配作为一个随机优化问题,其研究目标是最小化协作设备在无线通信和计算方面的平均费用。通过对优化变量的解耦,提出了一种次优化算法。为了最小化单用户多任务协作MEC网络的时延,文献[13]将任务分配和无线资源分配共同定义为MINLP问题。在松弛凸问题最优解的基础上,提出了一种次优解方案。
用户的移动性使得卸载决策高度动态。因此,如何通过考虑用户移动性驱动的网络状态不确定性来设计高效的任务调度和资源分配策略,以增强分布式系统中移动用户的任务卸载体验,成为了一个重要的研究方向。基于此,文献[14]提出了一个基于连续时间马尔可夫链的连接概率模型,以最小化在D2D网络中协作任务的执行时间。目前,越来越多的学者试图用深度强化学习(Deep Reinforcement Learning,DRL)的方法来解决这一问题,通过构建自学习能力更强的神经网络来近似表示Q值。作为智能体的每个卸载节点学会基于与环境的交互做出计算卸载的决定。从长远来看,通过从经验中优化计算卸载策略,系统能耗被最小化。
本文提出了一种基于D2D通信和MEC的2层任务卸载框架。在所提框架下,用户自低到高依次具有设备层(本地设备和D2D协作设备)和边缘层(边缘服务器)2个卸载层级可选。层级越高的卸载模式具有越充裕的计算资源,而将任务卸载到更高层级处理所付出的传输代价也更高。同时,所提框架还利用D2D协作中继技术协助移动用户连接更高卸载层级。为了实现动态、智能的任务卸载模式,提出了一种基于DRL的任务卸载策略。首先,对D2D辅助多任务用户卸载数据的场景进行建模,并考虑用户的移动性构建能耗最小化优化问题;然后,基于强化学习思想,设计了双深度Q网络(Double DQN,DDQN)算法对多任务卸载做出实时决策;最后,利用所提DDQN算法对本文所考虑的场景进行仿真,其优化决策的收敛性较好,并与其他基线方案进行对比,证实了本文所提方案的优越性。
1 系统模型
本文考虑一个支持D2D通信的协同MEC网络,该系统模型由单个用户、单个基站和M个D2D设备组成,如图1所示。其中空闲且资源充裕的设备(如笔记本、平板电脑和手机等可以作为边缘节点)通过与资源有限的用户设备(User Device,UD)建立直接的D2D链路[15],以促进计算卸载。假设UD有J个独立的计算密集型任务要执行,用集合J={1,2,…,i}表示。移动用户的任务沿着用户的轨迹被卸载到D2D设备或基站上。在UD行走的道路上,分布着M个D2D设备,用集合M={1,2,…,m}表示。考虑一种网络辅助架构,其中基站拥有全局网络信息,包括关于用户移动性和任务的细节。
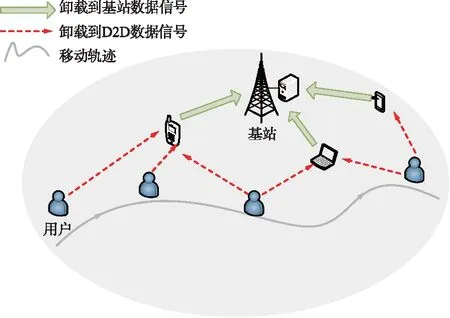
图1 系统模型Fig.1 System model
对于任务卸载,UD可以在基站的帮助下通过建立直接的D2D链路(使用WiFi或蓝牙等技术)连接到附近的D2D设备。基站可检测出UD的位置,以便将其任务调度到D2D设备,使计算卸载总能耗最小化。为了简化计算模型,UD、基站和D2D设备均只考虑装配一根天线。
1.1 用户移动模型
假设UD的轨迹在[0,T]可获得,小区空间划分为二维空间,λ(t)={x(t),y(t)},T={1,2,…,t}表示用户在t时隙所在的位置。由于其有限的处理能力,UD可以选择将任务卸载到附近的D2D进行计算。λm={xm,ym},M={1,2,…,m}表示第m个D2D的位置。
与文献[16-17]中的类似,假设系统在一个持续时间T内工作,以精确捕获用户的移动性。因此,将移动轨迹划分为时间τ相等的时间段,满足T=nτ。记时间段的集合为N={1,2,…,n}。对于每一个选择的n,UD在每个时隙内的位置近似不变。假设UD的移动速度相对较慢,短时间内所走的距离不会有很大的变化。记UD在时隙n∈N中的水平位置为λo(n)=λ(nτ)。根据UD在时隙n∈N中的位置,可以得到UD与第m个D2D设备之间的距离为dm(n)=‖λo(n)-λm‖。
1.2 任务卸载模型
在每个时隙,UD以一个确定概率随机生成i个任务(i∈J)。本文用Υt来表示是否有任务请求,Υt=1表示在t时隙有一个任务请求,Υt=0表示在t时隙没有任务请求。UD的计算任务可由TKi(ci,ai,dli)表示,其中ci表示任务卸载时本地设备需向外传输的数据量,ai表示处理该任务所需的机器语言指令数,dli表示执行任务的最大时延。对于时间密集型任务,每个任务必须在dli内完成,所以每个任务执行时间应该小于时隙长度τ。

(1)
(1) 本地计算模式

(2)
UD在本地计算模式下的能耗定义为:
(3)
式中,ko表示有效电容系数,它取决于UD使用的芯片结构[18]。为了现实,假设CPU频率小于最大CPU频率。
(2) D2D卸载模式

(4)
UD在D2D卸载模式下的上传任务所需能耗定义为:
(5)
此时,UD在D2D卸载模式下的处理时延定义为:
(6)
UD在D2D卸载模式下的计算能耗定义为:
(7)
式中,kD表示有效电容系数,它取决于D2D使用的芯片结构。
根据式(4)~式(7),UD在D2D卸载模式下的执行时延和能耗分别为:
(8)
(9)
(3) D2D辅助中继卸载模式

由此,任务上传到边缘服务器执行所需时间定义为:
(10)
UD在D2D辅助边缘计算模式下的上传任务所需能耗定义为:
(11)
UD在D2D辅助边缘计算模式下的处理时延定义为:
(12)
UD在D2D辅助边缘计算模式下的计算能耗定义为:
(13)
式中,kBS表示有效电容系数,它取决于边缘服务器使用的芯片结构。
根据式(10)~式(13),UD在D2D辅助边缘计算模式下的执行时延和能耗分别为:
(14)
(15)
2 问题描述
在这项工作中,本文的研究目标是最小化时延约束下任务执行的总能耗,包括本地执行能耗、D2D卸载能耗和卸载到基站能耗,可表示为:
(16)
为了减少卸载能耗,利用UD移动过程中不同时隙的位置信息进行任务卸载决策。故本文的研究问题形式化描述为:
(17)
式(17)给出了以任务卸载决策为优化变量的目标函数。约束C1表明用户最多只能选择一种模式来完成它的任务。约束C2表明任务只能全部卸载。约束C3表明分配给移动用户的计算资源不能超过MEC服务器拥有的资源。约束C4表明如果用户选择3种模式中的一种来完成它的任务,其时延不能超过最大时延。约束C5表明移动用户最多同时连接一个D2D设备。约束C6表示UD,D2D的传输功率和MEC服务器的计算资源分配分别是非负的。可见,优化式(17)含有多个离散的决策变量,是一个混合整数非线性规划问题,很难快速求得最优解。本文提出了基于DRL的DDQN算法来解决此问题。
3 基于DRL的算法设计
由于在高维场景下,创建出来的Q-table会过于庞大,导致无法建立。为解决具有高维状态空间的环境问题,DRL将深度神经网络与强化学习的决策能力相结合,通过使用卷积神经网络对Q-table做函数拟合。
由于本文研究的问题是移动场景下任务卸载的决策,随着用户的不断移动,环境也开始发生动态变化。传统的方案使用Q-learning算法来探索未知环境,移动用户通过尝试不同的行动,从反馈中学习,然后强化动作,直到动作提供最佳结果。由于Q-learning算法通过计算每个动作的Q值进行决策,所以会在某些条件下高估动作值。因此,本文提出使用DDQN方案是一种有效的改进,通过选择预测网络中最大Q值对应的动作来计算目标Q值,从而解决过估计的问题。
3.1 基于DDQN的计算卸载
为了使用DDQN算法,先将计算卸载问题转化为一个优化问题。通过优化任务卸载,实现了系统能耗的最小化。由于优化问题是马尔可夫问题,先将其建模为MDP问题。
(1) 状态空间:S={x,y}
UD在第t个时隙内的状态为其自身的位置。其中,xt为UD的横坐标,yt为UD的纵坐标。
(2) 动作空间:A={a}

(3) 奖励函数
奖励是对从先前动作中获得的利益的评估。在这个问题中,优化目标是使系统的能耗最小,而强化学习的目标是获得最大回报。如果借助强化学习来解决问题,就必须将奖励函数与优化目标函数关联起来。因此,将奖励函数定义为优化目标函数的负函数。

(18)
对于DDQN,不是在目标网络里面直接搜索最大Q值的动作,而是先在预测网络中找出最大Q值对应的动作,即:
(19)
然后利用选取出来的动作在目标网络里面计算目标Q值:
(20)
式中,γ为折扣因子。
综合定义为:
(21)

损失函数为:
(22)
式中,E[·]为随机变量期望。
3.2 基于DDQN的能耗最小化算法
本文所提DDQN算法的执行架构如图2所示。

图2 DDQN算法执行架构Fig.2 DDQN algorithm execution architecture
具体实现过程如下:首先,初始化预测网络、目标网络和回放空间(算法1中的第1行)。其次,输入UD初始位置。接下来,利用ε-greedy选择并执行动作at(算法1中的第5行)。在执行动作at后,获得即时奖励rt和新状态st+1(算法1中的第6~7行),并将记忆(st,at,rt,st+1)存储到D(算法1中的第8行)。然后,从回放空间中随机抽取K个样本,通过计算损失函数更新目标网络的参数(算法1中的第10~13行)。

算法1 基于DDQN的能耗最小化算法输入 UD初始位置输出 移动过程中使得系统能耗最小化的卸载决策1.初始化回放空间D,θt和θ-t;2.for episode=1:N3. 获取初始状态s;4. for episode=0:T-15. 将st输入到预测网络中,采用ε-greedy获得动作at;6. 执行动作at,利用式(18)计算即时奖励rt;7. 然后获得即时奖励rt和新状态st+1;8. 存储记忆(st,at,rt,st+1)到D;9. 从D随机抽取K个样本;10. 根据式(20)计算目标Q值;11. 根据式(22)计算损失函数以更新θ;12. 更新目标网络参数;end for
4 仿真结果与分析
4.1 参数设置

4.2 数值分析
为了评估本文方案,比较4种方案:① 本地计算方案,任务都在本地执行;② 随机卸载方案,任务随机选择卸载;③ 无D2D卸载方案,任务通过中继卸载到MEC服务器;④ 本文所提方案,任务可以在本地计算,也可以卸载到D2D设备或者卸载到MEC服务器。
DDQN算法的收敛性如图3所示。折扣因子是对未来奖励的衰减值,代表了当前奖励与未来奖励的重要性。DDQN算法曲线随着迭代次数的增加递减,逐渐收敛。算法训练200个周期,获得了训练回报。

图3 所提算法收敛性Fig.3 Convergence of the proposed algorithm
分别模拟0.1~0.9的任务产生概率(以0.2递增),比较4种算法的系统能耗。任务产生概率对平均能耗的影响如图4所示,可见系统能耗随着任务产生概率的增加而增加,这是由于任务数量的增大,导致系统需要更大的能耗开销,从而使得系统能耗增加。本地计算、随机卸载与D2D卸载算法系统能耗较高,DDQN算法的实验结果更优。

图4 任务产生概率对平均能耗的影响Fig.4 Influence of task generation probability on average energy consumption
不同时隙大小对本文方案系统能耗的影响情况如图5所示。可以看出,随着时隙的增大,任务量减少,从而系统能耗不断降低。

图5 平均能耗与时隙大小的关系Fig.5 Relationship between average energy consumption and time slot length
分别模拟0.2~1.0的最大时延(以0.2递增),比较4种算法的系统能耗。最大时延对平均能耗的影响如图6所示。可以看出,系统能耗随着最大时延的增加而减少,这是由于最大时延的增加,导致设备有充足的计算任务时间。本文方案比其他3种方案能耗更低,进一步说明了本文方案的有效性。

图6 最大时延对平均能耗的影响Fig.6 Influence of maximum latency on average energy consumption
D2D数量对不同方案的系统能耗的影响情况如图7所示。可以看出,随着D2D数量的增加,本文所提方案的能耗在不断减少。这是因为,D2D数量的增加丰富了用户卸载的选择,可以有效减少传输能耗。

图7 平均能耗与D2D数量的关系Fig.7 Relationship between average energy consumption and the number of D2D
5 结束语
本文提出了一种融合D2D和MEC的2层边缘云计算架构,并引入D2D协作中继技术用于辅助用户接入远端边缘服务器。考虑到用户移动性、分布式计算能力和任务卸载时延约束的特性,将任务卸载问题表述为能耗最小化的混合整数非线性规划问题,并进一步提出了基于DRL的DDQN算法来实时优化任务卸载决策变量。仿真数据表明,提出的协同计算方案在计算资源紧张的情况下,能有效降低移动用户的任务执行能耗且优化决策的收敛性较好。在未来的工作中,将研究D2D辅助的计算任务动态卸载方案中的激励机制。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年23期)2021-03-08
通信电源技术(2020年8期)2020-07-21
舰船电子对抗(2020年2期)2020-06-23
探索科学(学术版)(2020年1期)2020-03-26
电子制作(2019年23期)2019-02-23
经济研究导刊(2018年26期)2018-11-14
华人时刊(2018年15期)2018-11-10
现代计算机(2017年5期)2017-03-29
