
基于双路增强残差块连接的图像去块效应网络
2022-12-30 04:01冯洁丽何小海陈洪刚王新欢
无线电工程 2022年12期
冯洁丽,何小海,任 超,陈洪刚,王新欢
(四川大学 电子信息学院,四川 成都 610065)
0 引言
在信息爆炸的时代,有损压缩因具有较高的压缩率而被广泛应用于图像和视频编码,以节省带宽和存储空间。常见的有损编码方法有JPEG[1], WebP[2]等。在低比特率下,实现JPEG图像的过程中产生的块效应严重影响图像主观和客观评价,减少图像压缩效应成为经典的计算机视觉问题。
去压缩效应算法主要可以分为2类:基于重建的算法和基于学习的算法。在基于重建的方法中,数据项和先验项是最大后验概率框架的2部分。数据项表示压缩图像与原始图像之间的数据保真度;先验项代表用以约束的各种图像先验信息。典型的先验模型包括块相似性[3]、低秩先验[4]和自相似性模型先验[5]等。
基于学习的图像去压缩效应算法包括传统学习和深度学习2种。Chang等[6]提出了一种基于稀疏表示和字典学习的 JPEG 图像去压缩效应的方法。人工智能时代的到来,基于卷积神经网络的去压缩效应取得了不错的效果。Dong等[7]通过引入特征增强层提升单图超分辨率重建网络[8],后来用于JPEG压缩效应去除。Tai等[9]结合长、短跳跃连接和门单元,构建了MemNet网络,在多种图像复原任务中均取得了较好的效果。Chen 等[10]基于宽激活残差模块(Wide-activated Residual Block,WARB)[11],构建了一种多尺度残差块密集连接深度CNN,共享参数的同时取得了良好的去块效应结果。近段时间,还有一些图像复原工作[12-13]致力于提升压缩图像的感知质量,使得生成的图像具有更丰富的细节。总之,基于深度学习的压缩效应抑制方法较传统方法更有效。
借鉴多路网络[14]的发展成果,本文提出了一种新的基于双路增强残差块连接的图像去块效应网络,更好地恢复JPEG图像视觉观感。主要创新点如下:① 本文网络是DPEB模块采用残差连接和密集连接2种方式组成的双路网络结构,可以有效节省参数量和内存开销。② 将多尺度特征学习引入WARB模块,提出一种新的网络结构——双路单元(Dual Path Unit,DPU),对特征图进行全方面提取,实现特征融合降维,强化多个尺度的图像特征。③ DPERBN方法中的局部和全局残差学习在避免梯度爆炸同时加快网络收敛,在主流数据集上的拓展和消融实验证明该方法对多种压缩率的JPEG图像的有效性。
1 去压缩效应网络框架
1.1 网络框架简介
本文提出了一种基于双路增强残差块连接的图像去块效应网络,整体框架如图1所示。

图1 DPERBN整体框架Fig.1 Overall architecture of DPERBN
它是由特征提取块(Feature Extraction Block,FEB)、双路增强块和特征融合重建层组成,主要分为浅层特征提取、全局特征非线性映射和残差图像重建3个部分。X和Fr分别表示JPEG压缩图像和输出的去块效应图像,用2个卷积层FEB从网络输入X中提取底层特征,其过程可表示为:
F0=HFEB(X),
(1)
式中,X为输入图像;HFEB为浅层初始特征提取;F0为特征提取后输出的特征图。完成特征提取后,假如采用D个双路增强块 (Dual Path Enhanced Block,DPEB) 学习非线性映射关系,其映射过程为:
Gi=fDPEB,i(fDPEB,i-1(…fDPEB,1(F0)…)),i=1,2,…,D,
(2)
式中,Gi为经过第i个DPEB后的输出特征图;fDPEB,i为第i个DPEB函数。利用特征融合块(Feature Integration Block,FIB)集成所有DPEB和FEB输出的丰富层次特征图。
H=fFIB(G-1,[G1,G2,…,GD]),
(3)
式中,G-1为第一个卷积层FEB的输出;fFIB为特征融合函数;H为FIB的输出。完成非线性映射后,用一个重建层将64张特征图重建为残差图像,最后将输入图像与加入通道注意力提取到残差图像相加,得到去除压缩效应的结果图像,其过程可表示为:
Fr=Hrec(H)+G-1,
(4)
式中,Hrec为由特征图重建残差图像过程,Hrec(H)为残差图像;Fr为最后输出的去压缩图像。本文所有残差块都采用3×3卷积核,主通道数为64。
1.2 双路增强块


图2 第d个DPEB块的结构Fig.2 Structure of the dth DPEB block
1.3 级联双路单元

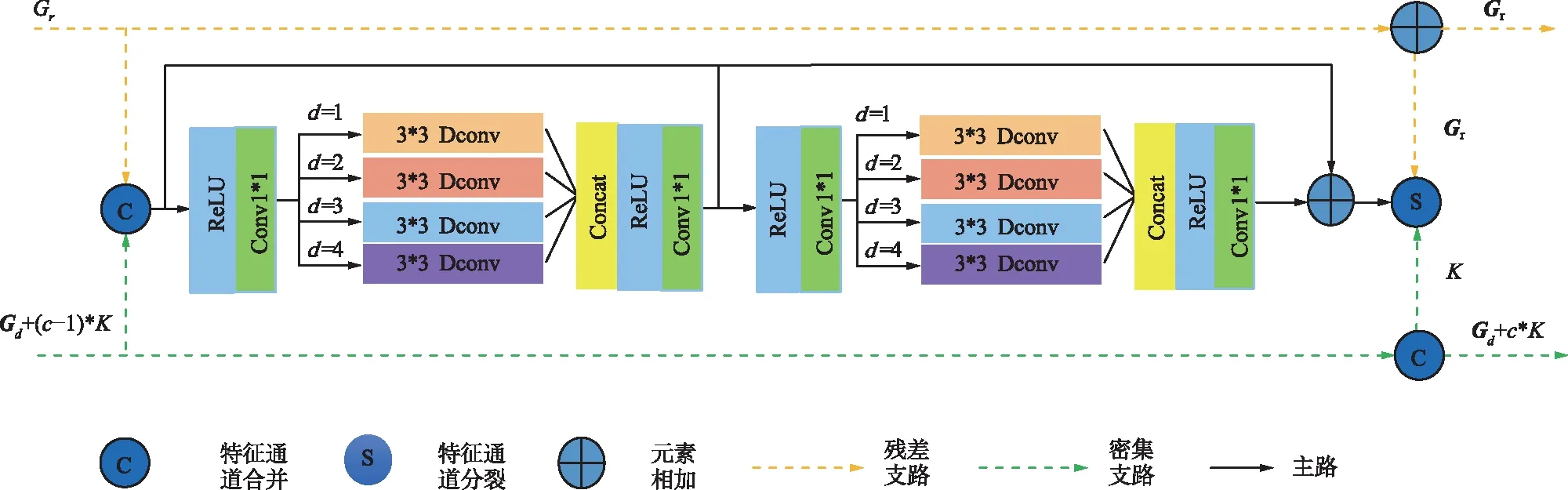
图3 第c个DPU的结构Fig.3 Structure of the cth DPU block
(5)

(6)

(7)
输入特征的密集部分与新学到的密集特征合并以形成密集支路:
(8)
特征图的2路被用作当前DPEB中下一个DPU的输入或者当这个DPU是目前DPEB中最后一个DPU时作为TU块的输入。ReLU函数能自适应地学习矫正线性单元的参数,使网络训练更容易且更快收敛。

图4 TU 的结构Fig.4 Structure of TU
1.4 过渡单元
在DPEB中,每一个密集支路的DPU的输入与特征图的密集部分的输出相连接,即前一个DPEB密集部分的输出为下一个DPEB中第一个DPU的密集部分的输入。假设第一个DPU的输入特征图有Gr个残差支路特征和Gd个密集支路特征,每个DPU的密集支路的增长率是K,经过第d个DPEB的第C个DPU后,可以得到Gr残差支路特征和(Gd+C×K)密集支路特征作为第(d+1)个DPEB的输入。为了使计算复杂度在可控范围内搭建更深的网络,在每个DPEB的尾部引入过渡块,将当前DPEB的(Gr+Gd+C×K)输出特征变换为(Gr+Gd)特征作为下一个DPEB中第一个DPU的输入。每个TU将DPEB中最后一个DPU的输出特征图作为输入,并将它分为残差支路和密集支路。
在第d个DPEB中的TU的函数表示如下:
(9)
(10)

1.5 特征融合块
在FIB里,首先将所有DPEB的输出按顺序连接起来以使用所有DPEB块学习到丰富的层次特征:
(11)

(12)
式(12)为全局平均池化,Z为池化后的输出特征。
H=fHFIB(G-1,Z)=s(Wu(Re(Wd(Z))))+G-1,
(13)
式中,Wd和Wu为通道注意力中下采样和上采样的权重;Re(·)为ReLU激活函数;s(·)为Sigmoid激活函数;H为FIB的输出。
1.6 损失函数

(14)
为此,还需要训练网络参数Θ,由式(14)可知,优化参数需要最小化输出的重建图像与残差图像之间的损失函数来得到[15]。全局残差常用MSE作为损失函数来实现网络的训练,表达式如下:
(15)
式中,N(·)为网络的输出;Θ为网络参数;K为每批次的训练样本数。
2 实验
2.1模型训练
本文使用800张经过旋转和翻转以实现数据增强后的DIV2K数据集作训练集。在模型开始训练前进行裁剪,并以40 pixel为步长,选取60×60的范围进行JPEG压缩,作为网络的输入。验证集采用Urban100[15],测试集采用Classic5[16]和LIVE1[17]。需要说明的是,本文训练和测试的所有实验仅在图像YCbCr 色彩空间的亮度分量Y生成的灰度图像上进行。对于三通道图像,先应用色彩空间转换公式转换到YCbCr空间,再对Y通道灰度图像进行处理。
本实验训练过程采用pytorch深度学习框架,每批次的训练样本数设置为64,硬件设备电脑的CPU为Intel(R) Core(TM)i7-4770K 3.50 GHz,内存为16 GB。深度学习使用的开发环境为Pycharm2019,GPU为NVIDIA GeForce RTX2080ti。使用ADAM算法进行训练过程的网络优化。由于双路策略和残差学习的引入,在实验时能更快使网络收敛。网络的初始学习率设置为0.000 1,训练过程中逐渐降低学习率。
2.2 实验结果及其分析
为验证本文所提出的算法对JPEG图像的去压缩效应能力,本文与算法TNRD[18],DnCNN-3[19],MemNet[9],DPW-SDNet[20],RNAN[21]进行了效果对比。使用Matlab 2017a的JPEG编码器对验证集进行了压缩质量因子(Quality Factor,QF)为10,20,30,40的JPEG图像压缩,以验证本文算法对不同压缩率下的JPEG图像去压缩的能力。峰值信噪比(Peak Signal to Noise Ratio,PSNR)、结构相似度索引(Structure Similarity Index,SSIM)和PSNR-B[22]常作为图像复原领域的客观评价指标来验证实验的有效性。PSNR是比较待测评图像和真实图像之间的相似度的指标,单位为dB,数值越大表示失真越小。SSIM依照图像像素之间的相互关系构建了结构相似性,综合分析待测评图像与真实图像的亮度、对比度以及结构因素的质量评价指标,更符合人眼的视觉感知,所以这个指标数值越高,表示待测评图像质量越好。
表1和表2展示了不同算法的JPEG图像的去压缩效应结果。

表1 不同方法在 Classic5 数据集上的平均 PSNR(dB)/SSIM/PSNR-B(dB)结果Tab.1 Average PSNR(dB)/SSIM/PSNR-B(dB)results of different methods on Classic5 dataset

表2 不同方法在 LIVE1 数据集上的平均 PSNR(dB)/SSIM/PSNR-B(dB)结果Tab.2 Average PSNR(dB)/SSIM/PSNR-B(dB) results of different methods on LIVE1 dataset
由表1可以看出,在QF=10,20,30,40时,提出的算法在Classic5数据集上比目前最先进的算法之一的RNAN取得了更高的客观评价指标,但RNAN具有上百层网络,网络较深,参数量较大。与同样是双路网络,且网络层数相当的DPW-SDNet相比,恢复图像的平均PSNR值分别高出0.24,0.18,0.19,0.22 dB,但在参数量上却减少一半。
同样地,在表2中,与其他3种经典算法相比,本文的算法在PSNR,SSIM和PSNR-B上获得了更高的客观评价指标,且在参数量上也取得较大优势。综上,本文算法在不同种类、不同压缩率的JPEG压缩图像数据集上,去压缩效应效果相较于对比算法,具有明显的优势,重建出图像的PSNR值和SSIM值都有不错的提升。为了便于展示,本文将YCbCr空间下的去压缩图进行局部区域放大,以便与视觉效果对比。图5、图6为本文对QF=10,20的2张不同数据集的图像Monarch和Barbara去压缩效应的结果对比。从图中可以看出,JPEG压缩图像存在严重的压缩块状伪影,主观视觉效果最差。前4种对比算法重建的图像对块效应和压缩噪声有一定抑制,但对于压缩受损严重的细节部分也修复得不够完整。而DPERBN能相对完整地去除JPEG图像中的块状网格,重建图像Monarch具有更清晰的轮廓,更逼真的效果,Barbara的部分线条更规整,与原图保持较高的相似度,获得了更好的视觉效果。

(a) 原图

(b) JPEG

(c) TNRD

(d) DnCNN

(e) MemNet

(f) DPW-SDNet

(g) RNAN

(h) DPERBN图5 不同方法在QF=10时对图像 Monarch 的去块效应视觉效果比较Fig.5 Comparison of deblocking visual effect of different methods on image Monarch at QF=10

(a) 原图

(b) JPEG

(c) TNRD

(d) DnCNN

(e) MemNet

(f) DPW-SDNet

(g) RNAN

(h) DPERBN图6 不同方法在QF=20时对图像 Barbara 的去块效应视觉效果比较Fig.6 Comparison of deblocking visual effect of different methods on image Barbara at QF=20
2.3网络结构分析
为了验证提出的网络结构DPERBN的有效性,本文基于WARB,MWRB[23]和DPEB 模块,将 DPERBN结构改为单路残差连接,单路密集连接,在相同的条件下重新训练网络。表 3 给出了不同网络结构在 Urban100数据集上当QF=40时的结果。

表3 不同网络结构在Urban100数据集上当QF=40 时的去块效应结果PSNRTab.3 Deblocking PSNR results of different network structures on Urban100 dataset at QF=40 单位:dB
由表3可以看出:① 密集支路和残差支路中DPEB的PSNR值高于WARB和MWRB,验证了多尺度特征学习的有效性;② 残差支路同一模块恢复图像的PSNR值高于密集支路,验证了局部残差及全局残差学习的有效性;③ 双路连接时DPEB的PSNR值高于WARB和MWRB,且高于只有单一密集支路和单一残差支路时的去块效应结果,验证了双路连接策略的有效性。
2.4 主观质量分析
在实际工作中,为了节省容量和降低带宽,通常对Web图像进行下采样和压缩,往往会引入一定的压缩伪影,影响后续的处理分析。为了测试该方法应用在真实网络图像上的效果,从Internet上下载了一张彩色的JPEG图像。由于互联网的图像是无参考图像,所以仅以主观视觉质量作为评价标准。将DPERBN网络中的DPEB模块替换为WARB和MWRB,在真实网络图像的Y通道上进行验证,将图像转换回RGB图像,效果如图7所示。由图7可以看出,本文网络恢复出的图像达到了最好的主观效果,DPERBN使帐篷的细节轮廓和线条更清晰,消除了振铃效应和压缩噪声,呈现出更丰富的视觉体验。

(a) 原图大图

(b) 原图小图

(c) WARB

(d) MWRB
3 结束语
针对JPEG压缩图像存在的压缩效应问题,本文提出了一种基于双路增强残差块连接的图像去块效应网络,以去除JPEG图像中的压缩噪声,恢复图像细节信息。本文与经典的去压缩效应算法TNRD,DnCNN,MemNet,DPW-SDNet,STRRN以及RNAN进行了主观与客观上的对比。经实验证明,本文提出的算法在应用于不同压缩率YCbCr的Y通道灰度图像上,具有不错的重建效果。在应用于网络JPEG图像的复原上,也取得了更好的视觉效果。在未来的工作中,将研究更先进的图像去块效应技术,进一步减少去块网络的参数量以及生成模型的大小。现阶段的图像去块主要是针对图像Y分量来进行处理的,在下一步研究中,将会研究三通道YCbCr压缩图像及不同种类的网络图像的去块效应算法以更好地应对实际应用的需要。
猜你喜欢
西安石油大学学报(自然科学版)(2022年5期)2022-10-08
广东通信技术(2022年4期)2022-05-12
今日农业(2021年9期)2021-11-26
汽车维修与保养(2021年5期)2021-09-09
英语文摘(2021年2期)2021-07-22
电机与控制学报(2018年9期)2018-05-14
科技与创新(2017年7期)2017-05-13
中国科技纵横(2016年11期)2016-08-05
汽车维修技师(2016年11期)2016-05-05
BOSS臻品(2015年1期)2015-09-10
