
译本的计量风格学研究
——以《献给艾米莉的玫瑰》四个中译本为例
2023-01-02 08:39倪文君
哈尔滨学院学报 2022年12期
倪文君
(浙江大学 外国语学院,浙江 杭州 310058)
一、引言
美国著名意识流作家威廉·福克纳在美国文学史上享有盛誉,其首部短篇小说《献给艾米莉的玫瑰》(ARoseforEmily)被誉为现代小说中最精美的短篇作品之一。[1]故事讲述了南方没落贵族艾米莉在强势父亲压迫之下错失结婚机会,在新旧势力交替的时代下倍感压抑,最终毒死恋人,并将尸体藏于家中长达三十年。小说通过描写艾米莉悲惨无奈的一生,表现了福克纳对美国南方固守成规的社会秩序的批评与揭露,传递了福克纳复杂而矛盾的南方情怀。小说自出版以来广受热议,目前针对其的研究主要围绕主题表达、人物塑造、情节特色进行分析,如意识流技巧、叙事手段和极具哥特式的风格等,主要研究视角有女性主义、叙事学、结构主义、后殖民主义等。
就译本研究而言,已有文献表明《献给艾米莉的玫瑰》中译本研究可以分为两类:一是针对单个译本的翻译风格和策略的分析;[2-3]二是多译本对照研究,研究者对不同译本进行评价和翻译原则进行分析,就文本中的意象和译文的句法特征进行讨论。[4-6]总的来说,以往研究在译本对比和译者风格对比层面尚未达成一致,且具有较强的主观性。在研究方法上,少有研究利用语料库翻译学的相关指标,如标准化类形比、平均句长、词汇密度、R1指标等从词法和句法的层面进行系统讨论不同译本之间的差异,从而分析不同译者的风格特征。由于译者在遣词造句的习惯上会呈现特殊的量化特征,[7]因此采用计量方法统计频次和显著性,可以全面反映译者的风格特征。
据统计,《献给艾米莉的玫瑰》中文译本众多,最早的中文译本可追溯至1960年我国台湾译者何欣的译本,而大陆的中文首译本出现在1979年,出自我国著名翻译家杨岂深之手。而后杨瑞、何林二人于1980年合译该小说。新世纪以来,针对该小说的重译不胜枚举,值得一提的有2015年张和龙译的《致悼艾米丽的玫瑰》和2017年浙江文艺出版社的叶紫译本。
本研究选定了四个译本,分别为1979年杨岂深译本(杨译本)、1980年杨瑞、何林译本(杨何译本)、2015年张和龙译本(张译本)和2017年叶紫译本(叶译本)。译本选择理由是:杨译本是最受欢迎的中译本之一,也是首次译入大陆的译本;杨何译本和杨译本翻译时间较为接近,可以作较好的参照。新世纪以来,译本较多,兼顾译文质量和译者水准,仅选择张译本和叶译本。本文以《献给艾米莉的玫瑰》及其四个中文译本为研究对象,对文本进行聚类,初步得出原文和译文的风格属于何种文体,探究原文和译文的文体是否发生了变异,然后从词汇和句法的层面进行计量验证进行讨论。
二、聚类分析与译文风格
本文选择FROWN语料库作为英文的参照语料库,兰卡斯特现代汉语语料库(简称LCMC)作为中文的参照语料库。这两个语料库为可比语料库,语料库的大小为100万词左右,库容相当,且建库原则一致。两个语料库各含有15个体裁一致的子语料库。
使用参照语料库,对中英文进行聚类分析,步骤如下:首先分别对英文原文、FROWN语料库、四个中文译本以及LCMC语料库进行分词词性标注。英文语料处理采用CLAWS part-of-speech tagger for English软件,中文语料分词、清洗使用NLPIR-ICTCLAS汉语分词系统。其次,统计原文、译文以及各子语料库中各词性的出现次数。由于原文和译文中的词性类别比语料库的词性类别少,最终选取的词性种类以原文和译文为准。选取好作为特征的词性种类后,分别进行归一化处理。最后,原文、译文以及各子语料库都被分别处理成一个特征向量。计算原文特征向量与各英文子语料库特征向量的欧氏距离平方和,同样,分别计算四个译文特征向量与各中文子语料库特征向量的欧氏距离平方和,聚类结果见下表1。
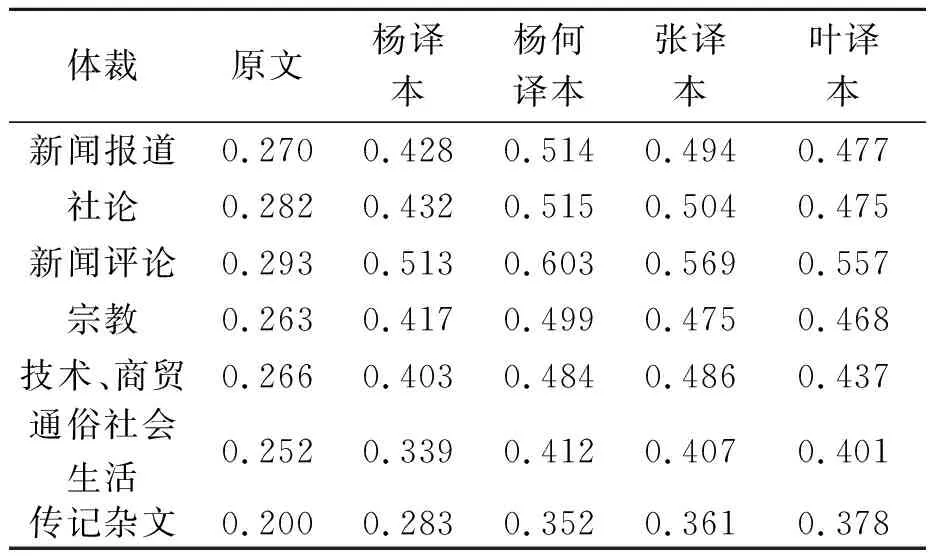
表1 四个译本及原文聚类分析结果
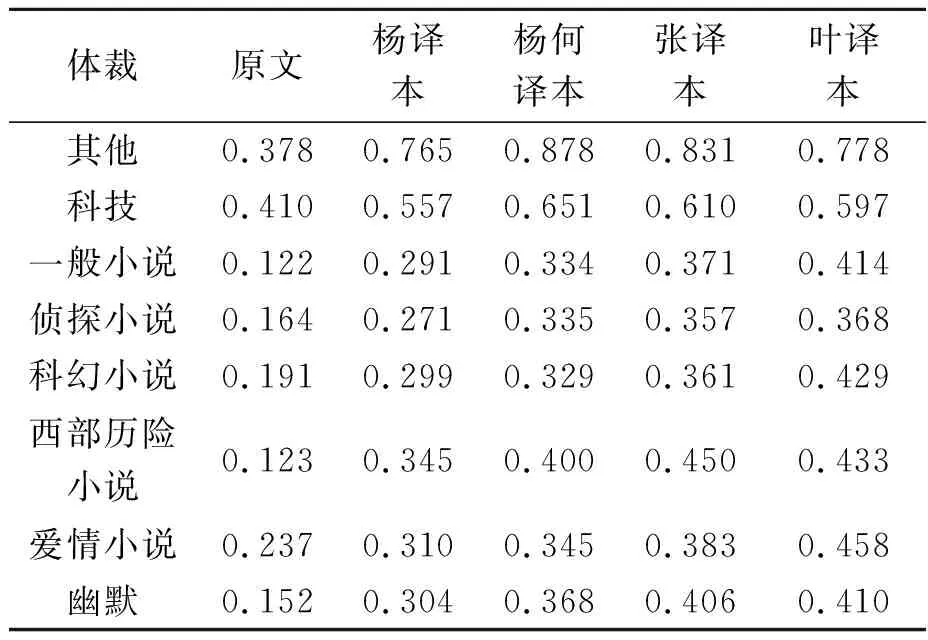
续表1
欧式距离平方和值越小,说明两个语料库的相似度越大,且风格越接近,[8-9]意味着目标语料库和参照语料库某个子类最为接近,使用的词性特征最为相似,因此可以判断体裁特征。由表1可知,《献给艾米莉的玫瑰》原文与一般小说的欧式距离平方和最小,为0.122,说明《献给艾米莉的玫瑰》原文的风格最接近一般小说,这是由于英文原文是由多种元素交织而成,包括哥特式的恐怖、悲剧的爱情婚恋情节以及对“南北战争之后新旧社会秩序的交替”的美国南方风土人情真实写照等描述,[10]使得小说的词性特征最终聚类在一般小说体裁。
就四个译本的聚类结果而言,采用配对样本T检验,发现四个中译本聚类分布和原文的欧式距离平方和结果存在显著差异(t1=-7.839,p=.001;t2=-9.516,p=.001;t3=-11.404,p=.001;t4=-13.832,p=.001),这说明四个译本在词性特征向量层面和原文词性特征存在统计学上的显著差异,不同译者针对目的语的词性选择做了相应的变异,体现了译者的主观能动性,挑战了“译者的隐形”的论断。就具体译本而言,杨译本最接近侦探小说,欧式距离平方和为0.271,其次为一般小说,欧氏距离平方和为0.291。同样,杨何译本与科幻小说的欧式距离平方和最小,为0.329,其次为一般小说,欧式距离平方和为0.334。张译本与侦探小说欧式距离平方和最小,为0.357,其次为传记杂文和科幻小说,然后才是一般小说,欧式距离平方和为0.371。叶译本欧式距离平方和最小的为侦探小说类别,为0.368,紧跟其后的体裁有传记杂文和幽默,然后才是一般小说,欧式距离平方和为0.414。
总之,通过比较译本对应的体裁与英文原文对应的体裁欧式距离平方和值的变化幅度,发现四个译本相对于原文都发生了风格变异,其中:与原文相比,杨译本和杨何译本的欧式距离平方和变化幅度较小,说明翻译风格变化较小,而张译本和叶译本的距离平方和变化幅度较大,说明翻译风格变化较大。根据聚类结果讨论,本文将探究四个译本的风格变化特征。
三、词汇层面
译本风格研究有多个衡量指标,包括词长、高频词、句长等指标。就词汇层面而言,译本比较研究可考察不同译本词汇丰富程度的特征,包括类符/形符比(type/token ratio)、标准化类符/形符比值(standardised type/token ratio)以及R1等指标。类符/形符比值可以初步反映译本的词汇多样性,统计出现不同的词形比例,而R1指标则从实词功能词比例的累积频率分布进一步反映译者对原文主题的忠实程度,更加准确地反映词汇丰富程度。
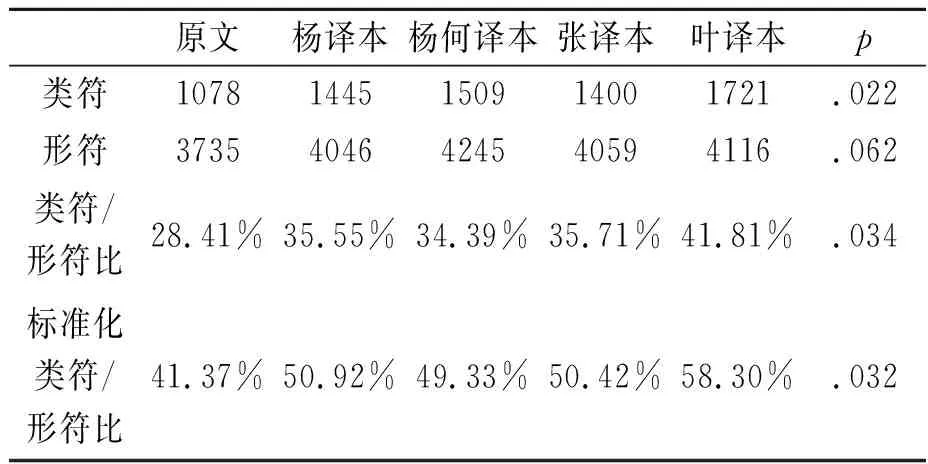
表2 原文及四译本类符/形符比统计
本文首先计算原文和四个译本的类符/形符比值。类符(type)是语料库中不同的词语,形符(token)是语料库中所有的词形。从上表可以看出四个译本在类符数量上存在显著差异(p=.022),但在形符数量上不存在显著差异(p=.062)。与原文相比,译文通常呈现显化的特征。这说明在相同文字总数使用相同的情况下,不同译文的选词数目具有显著差异的多样性和丰富程度。为了避免文本大小对比值的影响,可选择标准化类符/形符比值衡量译者词汇使用的丰富程度和多样性。这一指标避免了大小不一的文本长度,也就是类符均匀程度不同对最终比值结果的影响,从而更客观全面的反映不同译者的词汇使用程度。[11-12]四个译本的标准化类符/形符比值以原文的比值作为基线进行比较,配对样本T检验表明四个译本标准化类符/形符比值均与原文结果存在显著差异(p=.032),其中杨何译本其他三个译本的词汇丰富程度较小,而叶译本标准化类符/形符比最大,为58.30%,词汇多样性较其他三译本高。

从表3可以得出,四个译本与原文相比在词汇丰富度R1指标上存在差异,其中杨译本R1为0.86,杨何译本R1为0.85,张译本R1为0.86,叶译本R1为0.89,这说明叶译本在文本中使用的实词越多样,超过其他三个译本,杨何译本的R1值最低,代表该译本使用的实词种类较少。这一结果和我们分析不同译本类符/形符比值的情况是一致的。原文的R1指标为0.7,由于日耳曼语系和汉藏语系的根本差异,汉语在功能词和实词词类上和英文存在差异,因此四个译本的R1指标都高于英文原文,但我们大致可以推测四个译本中杨译本、杨何译本和张译本的词汇丰富度和原文差距不大,杨何译本最接近。就R1指标而言,叶译本使用的实词比例显著高于其他三个译本,其次是杨译本和张译本保持第二,最低值为杨何译本,杨何译本和原文的实词比例使用最为接近。
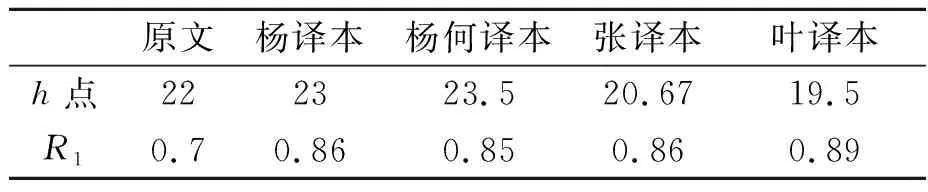
表3 原文及四个译本词汇丰富度R1指标情况
通过以上两个指标的测量,即类符/形符比值和R1指标,初步可以得出在四个译本中,杨译本和杨何译本的词汇丰富程度较小,风格和原文较为接近,而叶译本词汇丰富程度高,实词使用种类较多,风格和原文相比变异较大。
四、句法层面
译本对照研究除了考察词汇层面的语言特征,还可以就句法层面进行探究,特别是译者对译文句子长度的把握。一般而言,汉语平均句段长(以句号、问号、感叹号和部分表句子完结的省略号为句子标志)可作为汉语翻译语言的衡量指标。[15]平均句段长等于总形符数除以作为句段标记的标点符号总数。[16]平均句段长度的差异反映了译文的结构容量和可读性,且同原创汉语相比,翻译汉语的平均句段长度会因文体的不同而有所差别,说明平均句段长体现文体差异。[17]统计句段长度,根据各长度的出现次数绘制关于句段长度的频次图,并在各译本内计算比重,如图1。其中,句段的分隔标志为逗号、分号、冒号、句号、感叹号和问号。四个译本的平均句段长分别是杨译本最长,为39.03,杨何译本其次,为37.44,张译本再次之,为35.83,叶译本最短,为33.84。
由图1可以看出,四个译本及原文的句段分布长度比例整体变化趋势基本一致,呈现先增加后减少的趋势,其中句段容量为2个词的句段比重最大。由图1可以看出,以2个词的句段为分界点,其中文本使用小于2个词的句段随着长度的增加而增加,而3个词以上的句段使用比重逐渐减少。就四个译本与原文对比而言,结合句段变化趋势,在2-8个词的句段长度范围内,原文的句段长都低于所有译本,译本和原文句段比重差距由小到大的版本分别是杨译本、杨何译本、张译本和叶译本;在10-38个词的句段长度范围内,原文的句段长高于译文的长度,译本句段长和原文句段比重差距由小到大分别是杨译本、杨何译本、叶译本和张译本,其中叶译本和张译本在10-38词的句段长度使用比例变化趋势基本保持重合。
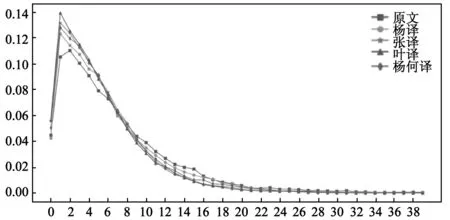
图1 四译本和原文句段频率分布
以上句段长度变化趋势说明了不同译本的句段使用特点。整体而言,杨译本和杨何译本的整体句段长度都和原文较为贴近,而张译本和叶译本则在短句段(2-8词)和长句段(10-38词)使用比重和原文差异较明显,其中较为明显的是叶译本对短句段(2-8词)的使用达到了14%左右。结合文本分析,发现叶译本惯用短句段进行翻译,从侧面反映了译者通过拆分句,避免使用长句段,降低了文本的阅读难度。意识流作家福克纳的写作风格以繁复晦涩的长句为特色,“20世纪的福克纳笔下,长句子占的比例不小,而且句法复杂,子句蔓生。”[18]所以在10-38个词的句段范围内,杨译本和原文的比重较为接近,这说明在长句段范围内,杨译本句式长度尽可能和原文的句式长度保持一致,体现翻译的忠实性。
句段的长度代表了所含的词汇数量多少,和句法复杂程度成正相关。[19]总的而言,叶译本偏好拆分句子,句法复杂程度较简单,短句偏多,结构简明,容量控制较有成效,可读性较强。而杨译本和杨何译本句段较长,与原文的长句段使用特征(10-38词)较为接近,侧面了反映译者与原文在语言形式上保持了较高的一致性。
五、结语
福克纳的短篇小说《献给艾米莉的玫瑰》利用其荒诞、怪异的哥特式风格和悲剧的罗曼史情节反映了美国南方没落贵族在衰亡的奴隶制度之下的扭曲人性。小说自1979年杨岂深将其译入大陆来,四十余年来不断有译者对该文进行重译,在译文中刻画了不一样的艾米莉形象。为了更好地评价不同译本的忠实程度和风格,本文选定四个译本为研究对象,从定量的层面进行探讨。
首先对四个译文进行聚类分析,发现四个译文与原文相比风格都有所偏移,聚类到“侦探小说”或“科幻小说”类别。聚类分析的原理是基于文本词性的相似程度,也就是在词汇层面的考察。词汇和句段长度密不可分。研究发现,尽管四个译本均出现了风格变异,杨译本和杨何译本与原文类别最接近,这表明这两个译本发生的变化最小,忠实程度较高。通过语料库的方法,即从词汇和句法的层面,我们发现杨译本和杨何译本类符/形符比值、R1指标与原文较为接近,长句段使用频率较高,符合福克纳笔下繁复蔓生的长句特征。
本研究通过计量的指标探究了不同译本的风格特点,通过聚类分析和语料库方法进行验证,辅之以语料说明,较为全面的揭示了译本风格变异的表现,为小说译本的计量风格研究提供了实证分析。本研究还可以结合不同时期译本产生的社会文化背景和译者本人的翻译思想进行探讨。
猜你喜欢
天津外国语大学学报(2020年4期)2020-08-24
作文评点报·低幼版(2019年21期)2019-08-13
作文评点报·低幼版(2019年21期)2019-08-13
戏曲研究(2019年3期)2019-05-21
红楼梦学刊(2019年4期)2019-04-13
西夏研究(2019年1期)2019-03-12
中等数学(2018年7期)2018-11-10
中国科技教育(2016年7期)2016-08-27
中国科技教育(2016年6期)2016-08-27
新高考·高二数学(2016年3期)2016-05-20
