
Structural Damage Identification Using Ensemble Deep Convolutional Neural Network Models
2023-01-24 02:51MohammadSadeghBarkhordariDanialJahedArmaghaniandPanagiotisAsteris
Mohammad Sadegh Barkhordari,Danial Jahed Armaghaniand Panagiotis G.Asteris
1Department of Civil and Environmental Engineering,Amirkabir University of Technology,Tehran,Iran
2Department of Urban Planning,Engineering Networks and Systems,Institute of Architecture and Construction,South Ural State University,Chelyabinsk,Russian
3Department of Computational Mechanics Laboratory,School of Pedagogical and Technological Education,Athens,Greece
ABSTRACT The existing strategy for evaluating the damage condition of structures mostly focuses on feedback supplied by traditional visual methods,which may result in an unreliable damage characterization due to inspector subjectivity or insufficient level of expertise.As a result,a robust,reliable,and repeatable method of damage identification is required.Ensemble learning algorithms for identifying structural damage are evaluated in this article,which use deep convolutional neural networks,including simple averaging,integrated stacking,separate stacking,and hybrid weighted averaging ensemble and differential evolution(WAE-DE)ensemble models.Damage identification is carried out on three types of damage.The proposed algorithms are used to analyze the damage of 4585 structural images.The effectiveness of the ensemble learning techniques is evaluated using the confusion matrix.For the testing dataset,the confusion matrix achieved an accuracy of 94 percent and a minimum recall of 92 percent for the best model(WAE-DE)in distinguishing damage types as flexural,shear,combined,or undamaged.
KEYWORDS Machine learning; ensemble learning algorithms; convolutional neural network; damage assessment; structural damage


1 Introduction
Artificial intelligence (AI) methods have had a significant impact on a variety of disciplines,ranging from engineering applications,health sciences,intelligent games,to material discovery [1].Machine learning (ML) methodologies and computing power advancements facilitate not only the handling of big data within reasonable time restrictions,but also the automatic discovery of underlying patterns of the data without requiring human subjective judgments[2,3].The decision-making process may become more reliable and efficient using ML models [4].The application of ML algorithms in civil engineering involves a wide range of disciplines[5–7],including structural health monitoring[8,9],geotechnical engineering[7],and structural and earthquake engineering[10–12].Das et al.[13]adopted a deep convolutional neural network(CNN)to determine crack patterns in strain hardening cementitious composites.The proposed model can predict crack metrics such as average crack width and crack density based on the crack pattern.Abdelkader[14]proposed a hybrid pre-trained deep learning algorithm for the crack identification in various infrastructures using visual geometry group networks,K-nearest neighbors,and differential evolution algorithms.Reis et al.[15]proposed methodologies for classifying images of cracks in historical buildings using a deep learning architecture.Wan et al.[16]assessed an encoder-decoder network-based architecture for identifying pavement cracks with intricate textures under various illumination situations.Bigdeli et al.[17] used a new architecture based on CNNs for densifying crack bifurcation in concrete structures.Mohammed et al.[18]utilized various established open-source CNNs to evaluate their detection accuracy in concrete crack classification.Ye et al.[19]used CNNs,a bridge crack library,to develop a model for structural crack detection of multiple structural materials such as masonry,concrete,and steel.Flah[20]presented an automated inspection framework based on image processing and deep learning techniques to identify defects in otherwise difficult to access regions of concrete structures.Wang et al.[21] developed a structural damage identification framework based on time-frequency graphs and the marginal spectrum of the signals using CNNs and particle swarm optimization algorithm.Meng et al.[22]introduced a modified CNN for long-term structural monitoring using both forward convolution and reverse convolution.Quqa et al.[23]utilized image processing techniques and CNNs for crack identification in steel bridges using an image dataset of the welded joints of steel bridges.Sharma et al.[24] suggested a onedimensional CNN for detecting damaged joints in semi-rigid frames.A novel procedure is suggested by Sony et al.[25]based on a windowed one-dimensional CNN for multiclass damage detection using vibration responses on a full-scale bridge.Alazzawi et al.[26] proposed a deep residual network to extract characteristics from raw response signals recorded from steel beams under various damage situations.Yang et al.[27] presented a CNN-U-Net architecture model combined with a nonlinear regression model for identifying the crack skeleton.The different research studies cited above classified structural damage in structural members using typical DL-based models,which involve classifying the damage using a set of pictures from the desired damage type.However,these ML algorithms still have flaws,such as being inaccurate or weak,having limited generalization capacity,and running at a low speed[28,29].
After a seismic event,a quick and accurate assessment of the damage level of structures is crucial for emergency action and recovery design.Visual identification is commonly used in current quick damage evaluation methodologies.However,visually detecting and classifying existing reinforced concrete structural damage can be laborious.To this end structural health monitoring(SHM)and fast and easy damage assessment following natural disasters has gained significant research interest.In civil engineering design,using DL in vision-based SHM is a relatively recent research direction and to this end some significant challenges remain to be addressed as researchers try to apply these concepts to structural engineering concerns.For example,there is a lack of a standardized automated identification principle or framework based on existing knowledge with acceptable accuracy for structural damage identification.To this end this research evaluates the feasibility of using ensemble learners,including simple averaging,weighted averaging,integrated stacking,and separate stacking ensemble models,to assess the earthquake-induced damage of reinforced concrete structural members.Ensemble models are developed for structural damage identification using deep convolutional neural network models.Damage type corresponds to a complicated vision pattern that is divided into three categories:flexural,shear,and combined damage.The paper is structured as follows:The data are presented in detail in Section 2.Section 3 describes the CNN and ensemble learning techniques models.Section 4 explains the results and discussion,and Section 5 presents the main conclusions.
2 Data Description
In general,reinforced concrete member failures can be divided into three main categories:flexural,shear and flexural-shear.Mechanical characteristics of the reinforced concrete members are directly affected by damage type.In this research,a damage-type dataset was obtained from the Pacific Earthquake Engineering Research (PEER) Center Hub ImageNet (PHI) website [30,31].A total of 4585 images were available in this dataset,comprising the three damage types defined as flexural (F) damage,shear (S) damage,combined (FS) damage,and also the undamaged (UN)condition.Mechanical characteristics and seismic design are directly affected by damage type.Label definitions corresponding to failure type are presented by Moehle [32] and based on engineering judgment as follows:(1)Flexural-type damage is defined as most cracks occurring in the horizontal or vertical directions,or at the end of an element having vertical or horizontal planes,(2)Shear-type damage is defined when the majority of cracks run diagonally or create a“X”or“V”pattern,and(3)It is classified as combined-type damage if the crack distribution is uneven or accompanied by severe spalling.Images have dimensions as high as 224×224×3,where 224×224 is the resolution(pixels)and the last dimension(3)is the number of the color channels.Table 1 shows the number of images for each damage type.Fig.1 shows examples of images in the database.In this study,the ML models are developed on the basis of a random split of the data into a training set(70%),a validation set(15%),and a testing set(15%).

Table 1: Distribution of damage type
3 Ensemble Model
In this research,ensemble neural network models and super learner ensemble are used to characterize different damage types.The ensemble neural network models use deep neural networks such as base sub-models,but super learner ensemble use bagging and boosting algorithms as base sub-models.The ensemble neural network models developed in this research are simple averaging,weighted averaging,integrated stacking,and separate stacking ensemble models.
3.1 Sub-Models
A deep convolutional neural network (DCNN) architecture comprises several layers: an input layer,a convolutional layer,a pooling/dropout layer,fully connected layer,and ultimately output layer.As an example,a configuration of a binary classification is illustrated in Fig.2.A picture is received by the first layer(Input layer).The input data is then processed by the architecture,which reduces its size.Finally,based on the type of categorization,the Softmax layer predicts the final output.For the binary classification,the prediction is based on whether or not the image belongs to a specific group,those classification tasks that have two class labels.For a multi-purpose,classification tasks have more than two class labels.
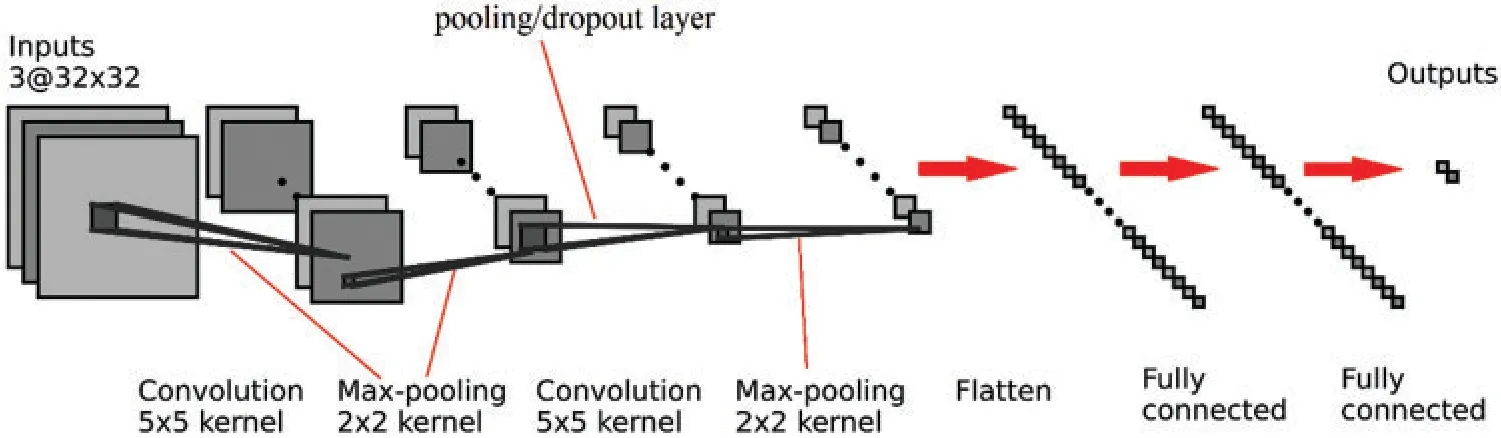
Figure 2:Architecture of the DCNN classifier
3.2 Sub-Models
In this research,five convolutional network models(CNN)are utilized as the base learners(submodels).The number of base learners is determined using a trial and error method.These models are created by modifying deep learning models,including a MobileNetV2[33]and NASNetMobile[34],to capture global context and local deep learning characteristics.This research employs the transfer learning technique(TLT).TLT is a strategy in which a model that was trained to address one problem is reapplied to solve a new problem that is related to the original [35].Typically,the early layers of an image recognition model will learn to identify generic traits,while the later layers will be able to recognize more specific traits[35,36].The last layer of an image recognition model will have N Softmax neurons (assuming we are classifying N classes); therefore,it should be modified appropriately and in some cases additional layers may be required.The important step,is fine-tuning,which involves unfreezing the entire model obtained above and re-training it using the new data with a very low learning rate.
MobileNetV2 and NASNetMobil have a total of 88 and 769 layers,respectively [33,34].CNNs architectures of the sub-models are shown in Fig.3.The additional layers are highlighted in green.The simple averaging,weighted averaging,integrated stacking,and separate stacking ensemble models are created using these sub-models.
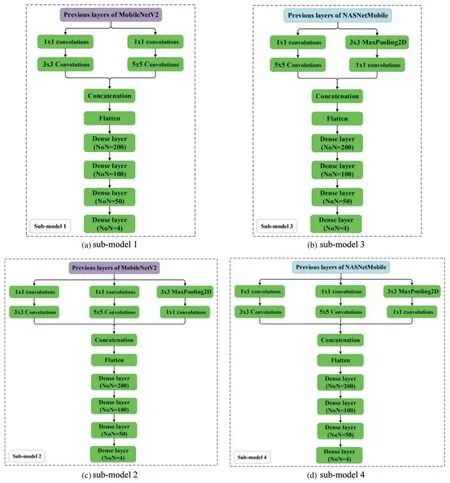
Figure 3: (Continued)
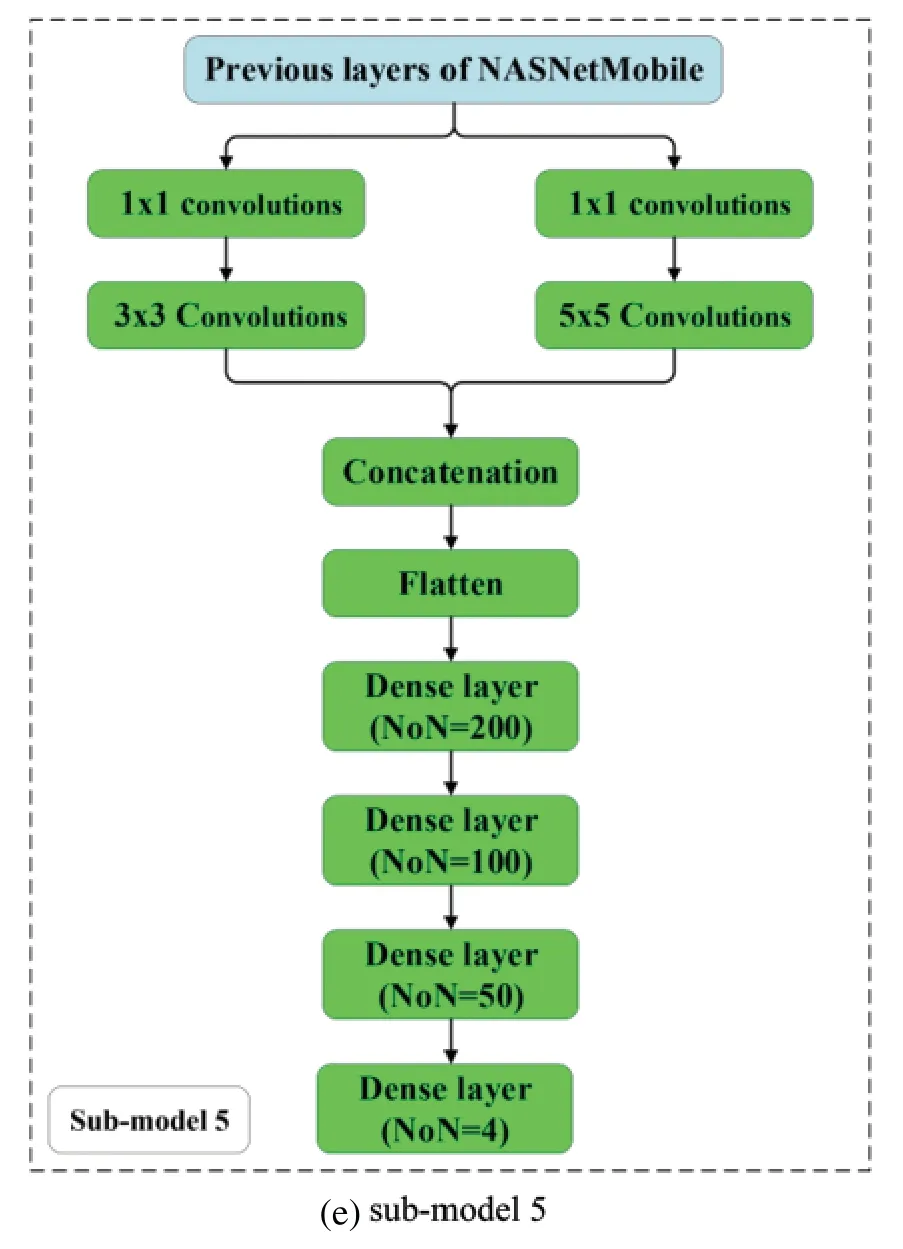
Figure 3:Architectures of the sub-models
3.3 Simple Averaging Ensemble
For numerical purposes,averaging is the most common and basic combination approach.Simple averaging ensemble(SAE)is one of the most widely used approaches[37],and it is often the first choice in many real-world applications due to its simplicity and efficacy.By directly averaging the outputs of the sub-models,simple averaging yields the total output.Here,five CNN base learners(Section 3.2)are considered for developing the SAE.A diagram of the SAE process is illustrated in Fig.4.

Figure 4:Simple averaging method
3.4 Weighted Averaging Ensemble
The simple averaging technique assigns the same weight to all sub-models.The weighted averaging ensemble (WEA),generates a combined output by averaging each sub-model output by varying the assigned weights.Determining the weights may be computationally challenging,and optimization algorithms are usually employed at this stage [38].In this research,differential evolution (DE) is employed to determine the weights in the WEA [39,40].DE is a vector-based technique that,due to its usage of crossover and mutation,is similar to pattern searching and genetic algorithms[39,40].DE is a self-organizing search method that does not rely on derivative information.As a result,it is a population-based,derivative-free approach.DE uses the population’s directional data.Each member of the present generation is allowed to reproduce by mating with other randomly chosen members of the population.For each individual,three other separate individuals are randomly selected.As a result,to breed an offspring,a parent pool of four individuals is generated.After initialization,DE uses mutation to build a mutated vector relating to each population member,and then uses arithmetic recombination to construct a target vector in the present generation.Differentiating one DE scheme from another is the procedure of creating the modified vector.In DE,mutation occurs before crossover,whereas in genetic algorithms,mutation occurs after crossover.Furthermore,mutation is used less frequently in genetic algorithm,whereas it is used on a regular basis in DE to develop each offspring.Fig.5 shows the conceptual schematic of the WAE-DE hybrid algorithm.
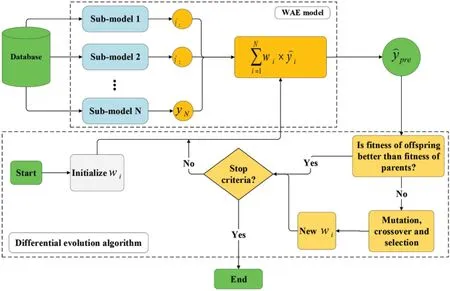
Figure 5:Conceptual schematic of the WAE-DE algorithm
3.5 Stacking Ensemble
Stacking is another ensemble learning approach that employs a meta-model to integrate a large number of the sub-models(usually heterogeneous learners)to provide a more accurate final prediction than a single model(Fig.6)[41].The predictions returned by the sub-models are then aggregated by training a meta-model based on the outputs of individual sub-models.The term“integrated stacking”is used when the meta-model is a neural network;otherwise,“separate stacking”is used.
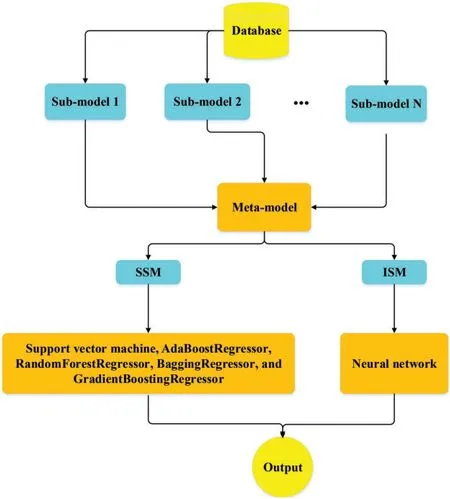
Figure 6:Stacking ensemble algorithms workflow
3.5.1 Separate Stacking Ensemble(SSM)
I had decided4 to spend my two days giving a monologue5 workshop. I wanted the men to have a chance to write and then perform before a camera. I wanted them to see themselves on video before I left the prison at the end of the second day. I felt that life in this prison had probably stripped them of most of their identity and that writing and performance art might restore some sense of who they were or who they could be.
In this research,SSMs are generated with sub-models (Section 3.2) and five different metamodels,including support vector machine,Adaptive Boosting(AdaBoost),RandomForest,Bagging,and Gradient Boosting (GraBoost),default parameters are used for meta-models.Support vector machine (SVM) is firstly developed for classification of different classes.The strategy is that the sample points(input)are transformed into a higher-dimensional feature space using a linear/nonlinear transformation.Then a hyperplane is used to describe the classification.SVM regression is generally regarded as a nonparametric method because it relies on kernel functions.A kernel is used to identify a hyperplane in a higher-dimensional space while reducing the computing cost.When we use SVM,our major goal in the regression problem is to choose a decision boundary that is a certain distance from the initial hyperplane and contains data points that are closest to the hyperplane.AdaBoost is a collection of numerous decision trees,each of which is a poor learner and performs just marginally better than arbitrary guessing[42].The AdaBoost method transmits the gradient of previous trees to subsequent trees in order to minimize the error of the prior tree.As a result,the subsequent learning of trees at each step contributes to the development of a strong learner.The ultimate prediction is a weighted average of each tree’s projections.AdaBoost is more resistant to outliers and noisy data due to its strong flexibility.Bagging is a condensed version of bootstrap aggregation.It is an ensemble technique that splits a dataset into m samples,and samples sets do not need to be disjointed.After that,each of the m samples is trained separately into m different machine learning models.The outputs of all the different models are then integrated into a single output via for example voting or averaging.Random Forest(RF)is a Bagging extension in which randomized feature selection is incorporated[43].At each step of split selecting in the construction of a decision tree,RF first takes a subset of features at random,then performs the traditional split selection technique inside the selected feature subset.Graboost is comparable to other methods of boosting[44].Since it is necessary to incrementally raise or boost weak learners,unlike AdaBoost,which involves adding a new learner after increasing the weight of poorly predicted data,gradient boosting involves training a new model based on residual errors from the preceding prediction.
3.5.2 Integrated Stacking Ensemble(ISE)
When employing deep neural networks as a sub-model,a neural network may be a preferable choice as a meta-model.In the ISE algorithm,a neural network is used as a meta learner.The submodels can be inserted in a larger network that the meta-model learns how to combine the sub-models’outputs in the best way possible.In this work,a shallow neural network consisting of only 1 hidden layer with 25 neurons is selected as the meta-model.The number of neurons in hidden layer has been determined using trial and error method.The activation function and optimizer are“Tanh”and“Adm”,respectively.
4 Result and Discussion
A confusion matrix (CM) is used to assess the effectiveness and efficiency of each ML model in greater depth.The CM is a table that compares the observed and predicted damage.The metrics utilized to assess the performance of the models are in Eqs.(1)–(3):

A TP is when the model forecasts the positive class properly.A TN,on the other hand,is a result in which the model accurately forecasts the negative class.A FP occurs when the model forecasts the positive class inaccurately.And a FN is an output in which the model forecasts the negative class inaccurately.Recall and Precision are very useful when dealing with unbalanced datasets[45].
In Fig.7,F,S,FS,and UN stand for flexural damage,shear damage,combined(flexural-shear)damage,and undamaged.The diagonal cells in the CM reflect the classes that the algorithm properly detected,whereas the off-diagonal cells denote the classes that were mistakenly predicted.The accuracy(Eq.(1))is shown in the lowest cell on the right side of the CM(i.e.,fifth row and fifth column,Fig.7).The precision metric(Eq.(2))is indicated by the column on the far right of the CM.The recall metric(Eq.(3))is indicated by the row at the bottom of the CM.Fig.7 reports the CM of each sub-model for the testing phase.It can be recognized that the worst classification accuracy is represented for the sub-model 1 with a value of 82.7%.The highest accuracy has been recorded for the sub-model 4 with a value of 89.97%.Although the sub-model 4 has the highest accuracy,Recall values of the sub-model 3 for all classes are higher than 84%.
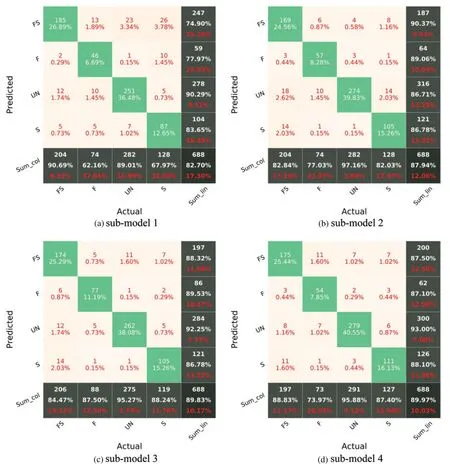
Figure 7: (Continued)
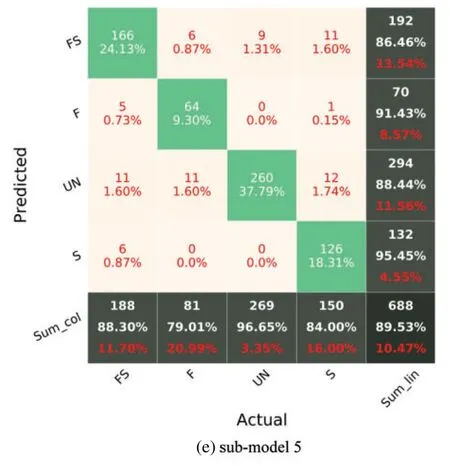
Figure 7:Confusion matrix of sub-models using the testing set
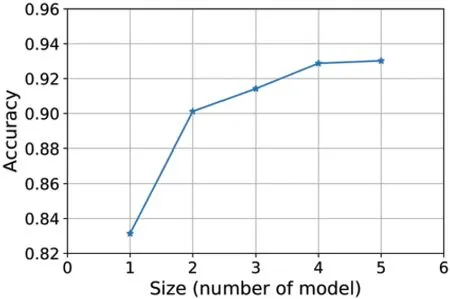
Figure 8:Influence of the number of members
The WAE-DE is the second ensemble learning method.As previously mentioned,the weight of each BL model is computed via the DE algorithm.The weight of each sub-model in WAE-DE is shown in Table 2.Based on Table 2,the sub-models 1 and 4 are given more weight than the others.

Table 2: Optimized weights of the sub-models
The models’accuracy is assessed using an unknown test set.Fig.9 shows the CM of various models for the testing phase.For the testing dataset,all models have an accuracy greater than 91%,demonstrating their ability to quickly assess the damage type after an earthquake with reasonable accuracy.The accuracies of the various models are SAE=91.4%,WAE-DE=94%,ISE=93.7%SSMAdaBoost=92.7%,SSM-Bagging=92.4%,SSM-Graboost=92.7%,SSM-RF=93.1%,and SSMSVM=94%.Among the ensemble models,the WAE-DE and SSM-SVM models fare much better.Meanwhile,the precision and recall of SSM-SVM,ISE,and WAE-DE are greater than 91%for almost all damage classes.While the recognition of FS damage is challenging in other research studies[46,47],the WAE-DE and SSM-SVM model achieved a near 93%recall and 96%precision in identifying the flexure-shear failure type in the testing dataset.Nevertheless,it seems that the prediction of the FS damage is challenging for the other examined models.A modeling averaging ensemble combines the prediction from each model equally and often results in better performance on average than a given single model.Comparison of the performance of the ensemble models(Fig.9)with the performance of single models(sub-models,Fig.7)shows the efficiency of the SSM-SVM and WAE-DE models in classifying damage types of RC members.The rate of increase in accuracy in identifying the type of failure is about 4%.
The SAE equalizes the predictions of each model.A weighted average ensemble is a method for allowing different models to contribute to a forecast in proportion to their level of confidence or anticipated performance.WAE-DE(weighted average ensemble)outperforms the SAE[48].Although model averaging can be upgraded by weighting the influences of each sub-model to the merged prediction by the expected performance of the sub-models,this can be further enhanced by training a completely new model (meta model,such as SVM) to discover how to optimally aggregate the contributions of each sub-model considering nonlinear relationship between inputs and output.Depending on how well the meta model can model the nonlinear relationship between inputs and output,the performance of this type of hybrid model will vary[48].
Gao et al.[49] used some well-known deep CNN (benchmark) models,including VGG-16 [50],VGG-19[50],and ResNet-50[51]models,for structural damage identification using same database.Table 3 shows the results of the VGG-16,VGG-19,and ResNet-50 models.The best benchmark model(VGG-19)is significantly poorer than the SSM-SVM and WAE-DE models in terms of performance.This emphasizes the significance of choosing the right model for future applications rather than relying on a single model.
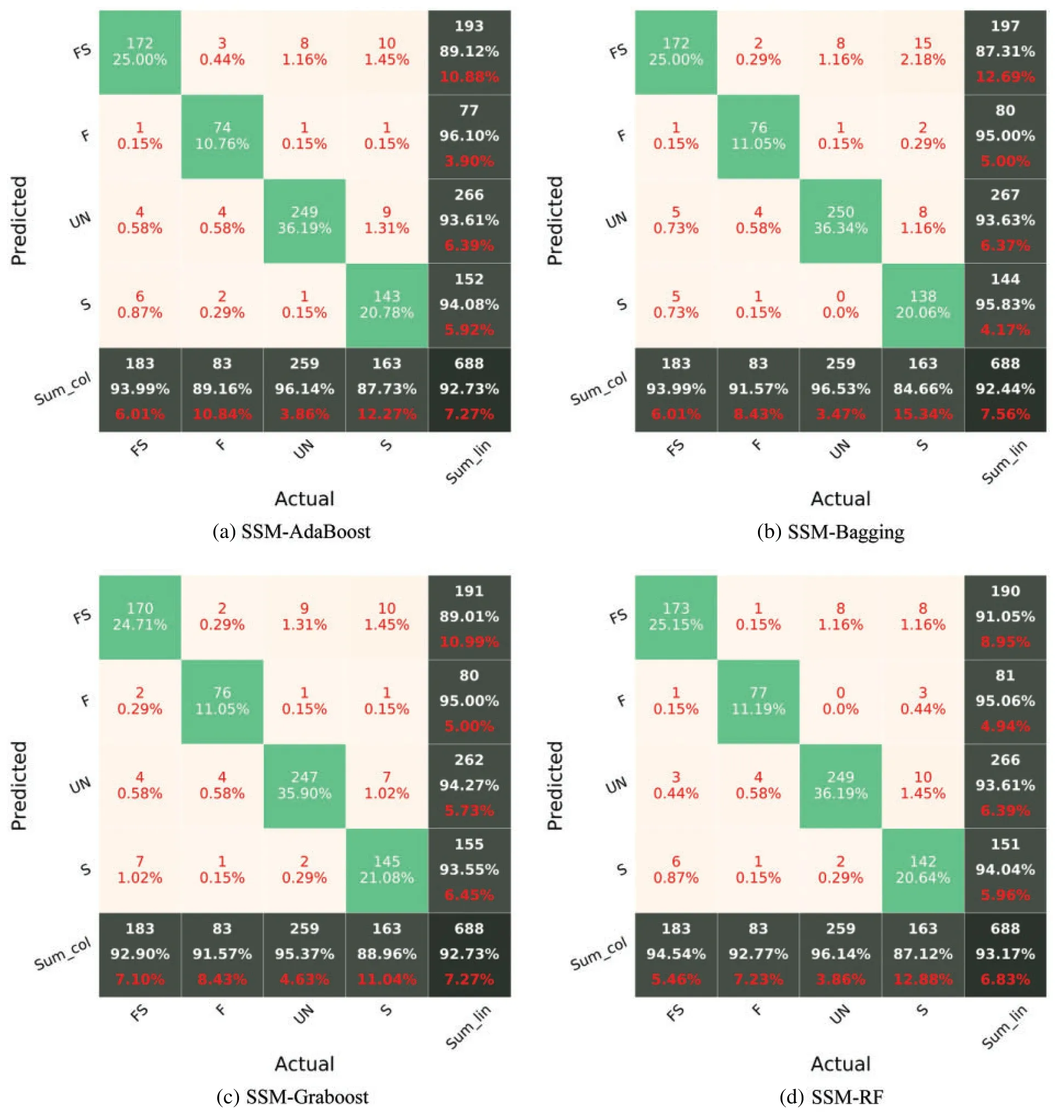
Figure 9: (Continued)
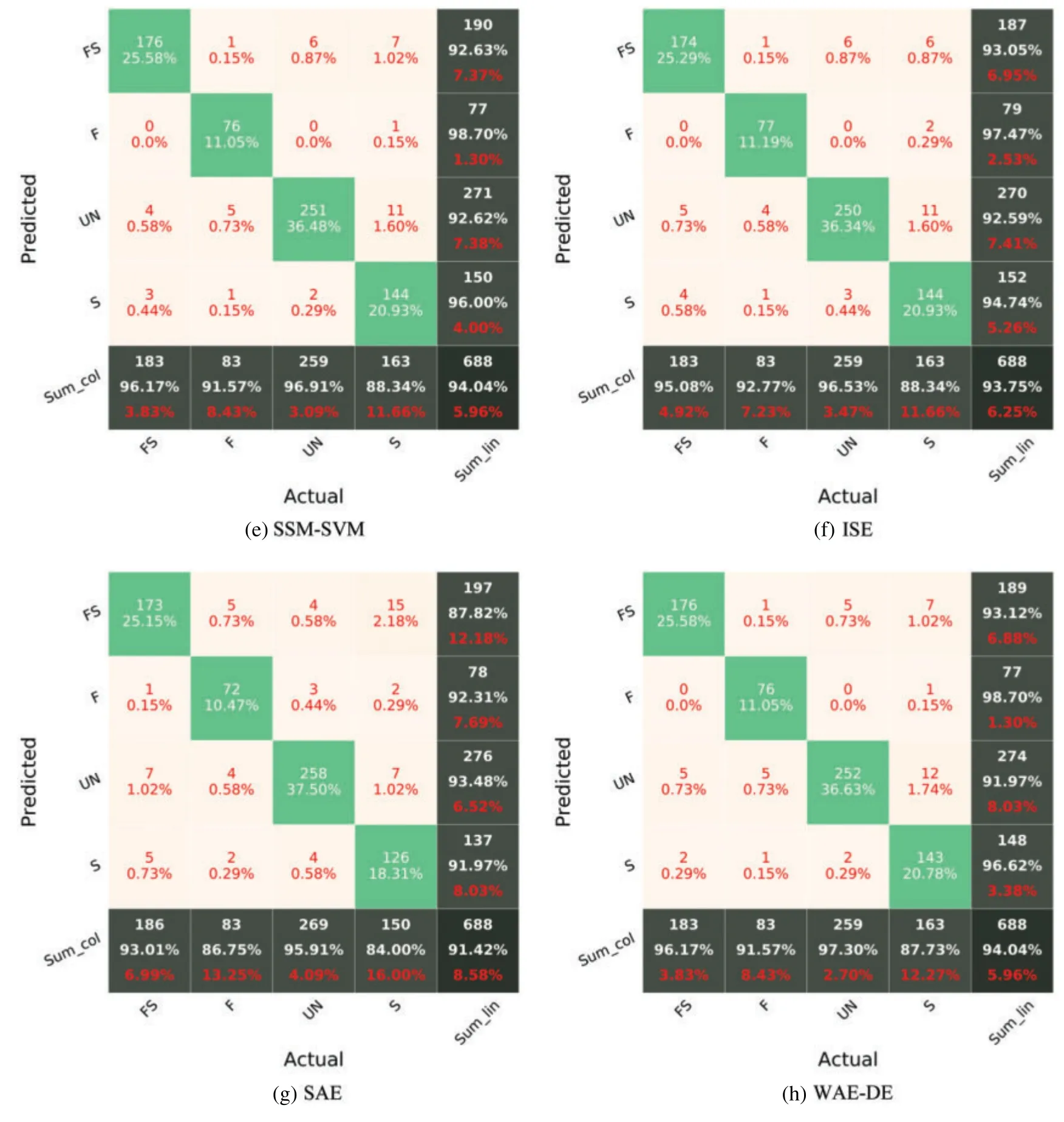
Figure 9:Confusion matrix of various ensemble models for the testing phase
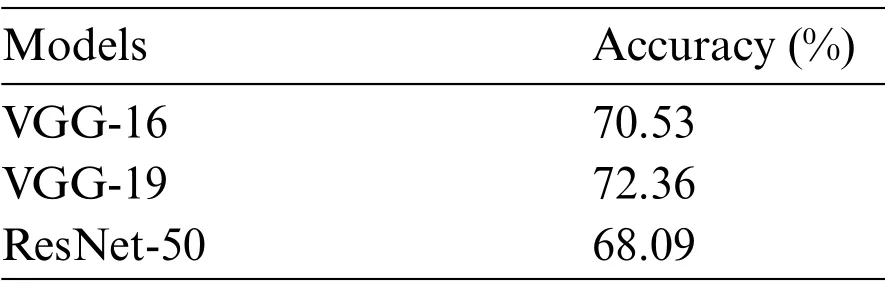
Table 3: Performance of benchmark models for test set
The k-fold cross-validation approach may produce a noisy assessment of model performance after just one run[52].Different data splitting can produce quite various findings.Repeated k-fold crossvalidation [52] is a technique for improving assessment of a machine learning model’s performance.In this method,the cross-validation technique is performed several times and return the mean result across all folds from all runs.This mean result is believed to be a more accurate representation of the genuine unknown underlying mean performance of the model on the dataset.As an example,Box-Whisker Plots of performancevs.repeats for k-fold cross-validation for SSM-SVM and SAE model are shown in Fig.10.The orange line represents the median and the green triangle indicates the arithmetic mean of the distribution.In addition,examining the learning curves of the algorithms during training could be used to discover learning challenges like the overfitting[52].Overfitting results in a model that is too similar to the inputs,lowering the generalizability of the model.Overfitting leads the validation loss graph to rise at a certain level and does not approach a point of stability.Fig.11 illustrates an example of overfitting.The models’curve is depicted in Fig.11.The validation loss curves approach a point of stability,as shown in Fig.12.
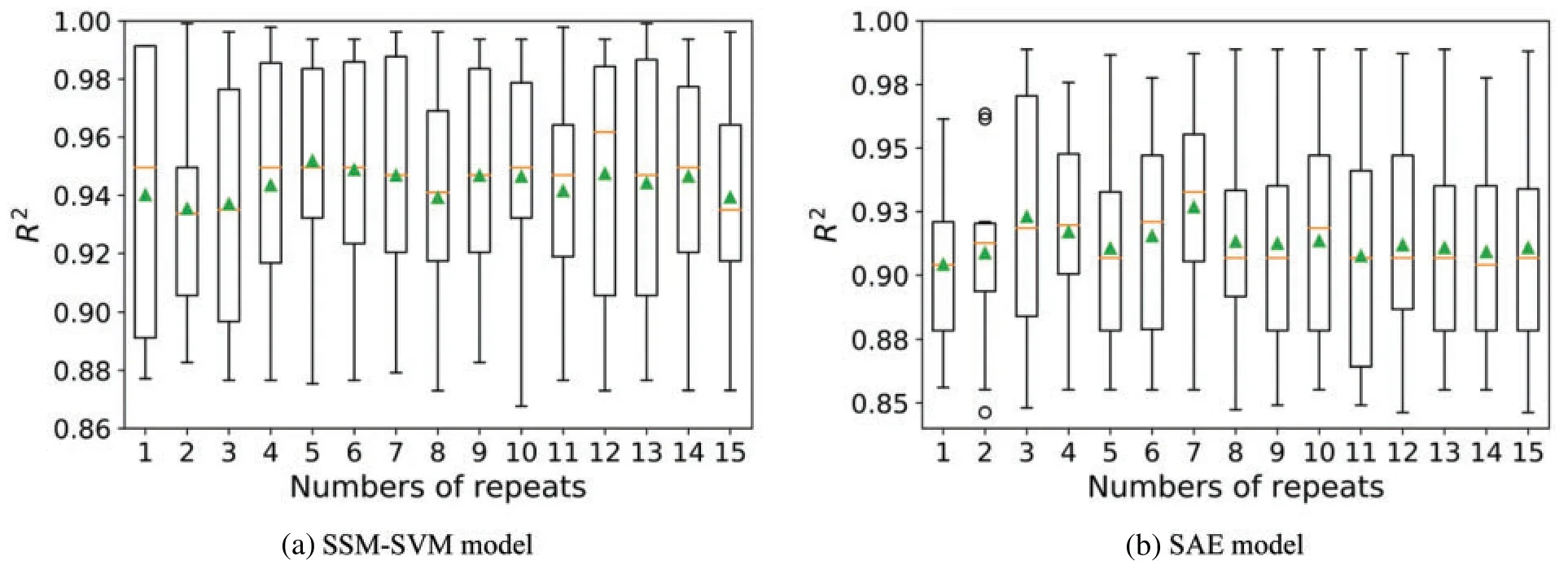
Figure 10:Loss-Epochs curve for a overfitted-model
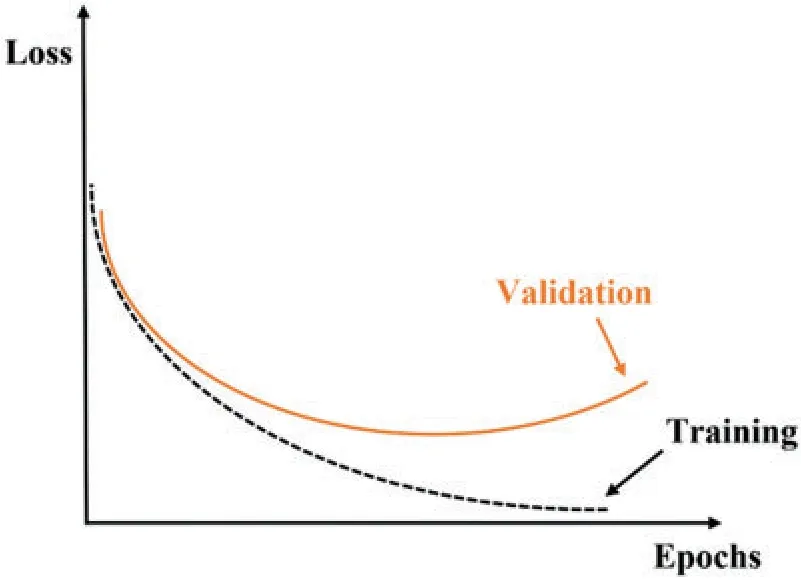
Figure 11:Loss-Epochs curve for a overfitted-model
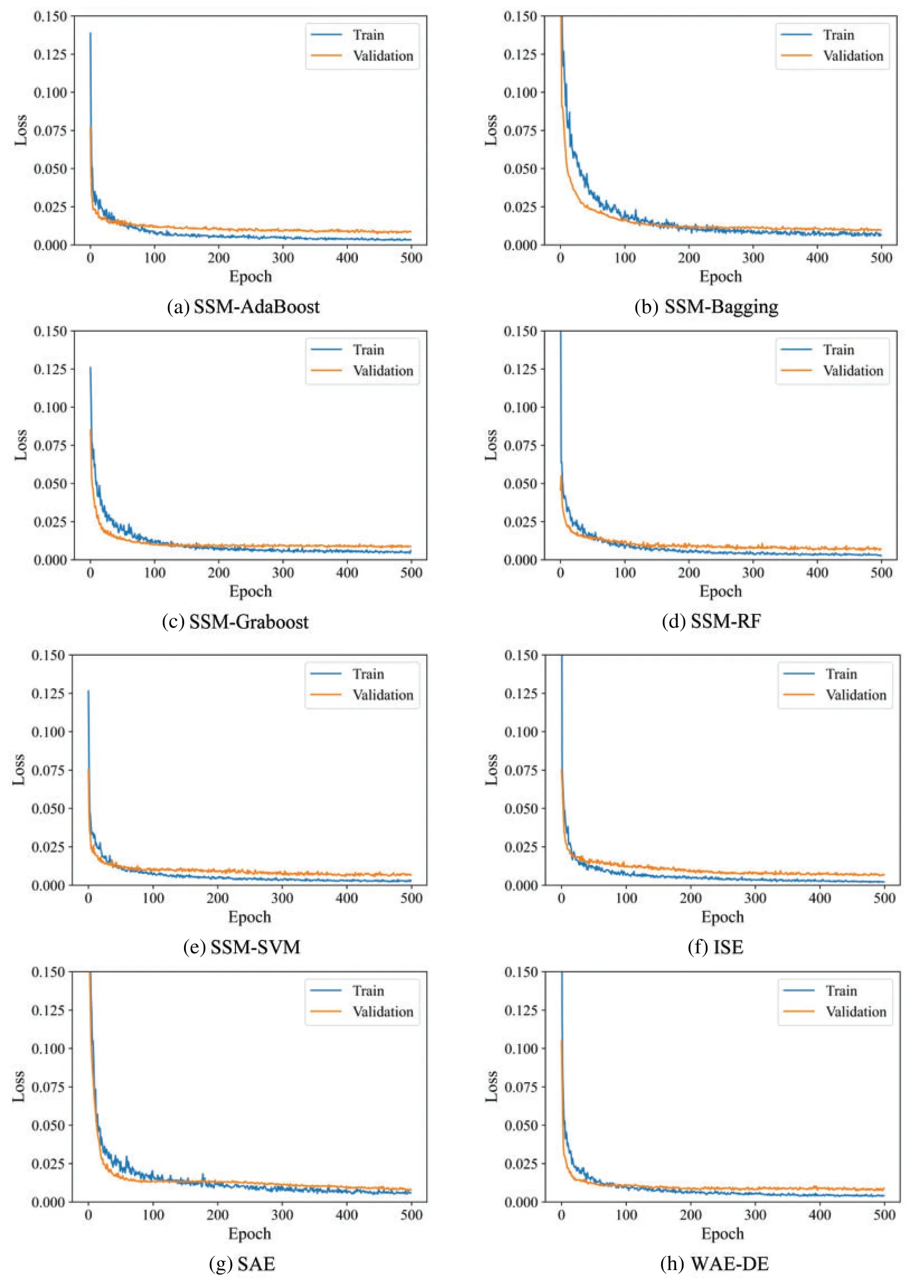
Figure 12:Loss-Epochs curve of various ensemble models
5 Conclusions
After a major earthquake,the timely success of a post-reconnaissance and recovery effort depends on the accurate assessment of inflicted structural damages.It is crucial to assess the seismic risk of structures in earthquake-prone areas and to collect data on the built domain within a possibly wide geographical area,following a severe earthquake.This paper developed and evaluated ensemble learning algorithms for identifying structural damage in RC members.The utilized ensemble algorithms include simple averaging,integrated stacking,separate stacking,and hybrid weighted averaging ensemble and differential evolution(WAE-DE)ensemble model,which are based on deep convolutional networks.The results were reported and examined using a confusion matrix,a table that was used to assess algorithm’s performance.Overall accuracy,precision,and recall metrics are reported for each model.
The results show that the WAE-DE and separate stacking ensemble with support vector machine(SSM-SVM)had the highest accuracy in the testing phase.The prediction accuracy of the ensemble models with the performance of sub-models shows the efficiency of the SSM-SVM and WAE-DE models in classifying damage types of RC members.Furthermore,the results demonstrated that predicting flexural-shear damage was challenging,as the lowest value of the recall corresponded to this type of damage for the majority of the investigated cases.The results of the proposed models were compared with three well-known deep convolutional neuronal networks (benchmark) models,including VGG-16,VGG-19,and ResNet-50 models.The benchmark models were significantly poorer than the of the ensemble models in terms of performance.The best benchmark model(VGG-19)had an accuracy of 72%,but the SSM-SVM and WAE-DE models had an accuracy of 94%.Because the WAE-DE and SSM-SVM models have the highest accuracy,precision,and recall among the various ML models,these two algorithms are recommended as the best prediction models for detecting structural damage.
Data Availability:Some or all data,models,or code that support the findings of this study are available from the corresponding author upon reasonable request.
Funding Statement:The authors received no specific funding for this study.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2023年2期
Computer Modeling In Engineering&Sciences2023年2期
- Computer Modeling In Engineering&Sciences的其它文章
- Detecting Icing on the Blades of a Wind Turbine Using a Deep Neural Network
- Optimizing Big Data Retrieval and Job Scheduling Using Deep Learning Approaches
- Image Representations of Numerical Simulations for Training Neural Networks
- Self-Triggered Consensus Filtering over Asynchronous Communication Sensor Networks
- State Estimation Moving Window Gradient Iterative Algorithm for Bilinear Systems Using the Continuous Mixed p-norm Technique
- Refined Sparse Representation Based Similar Category Image Retrieval