
基于典型相关自编码器的过敏性鼻炎用药推荐
2023-02-18 07:16徐慕豪葛欣宜刘俊秀朱振峰
计算机与生活 2023年2期
徐慕豪,葛欣宜,刘 洋,刘俊秀,赵 耀,朱振峰+
1.北京交通大学 信息科学研究所,北京100044
2.北京交通大学 现代信息科学与网络技术北京市重点实验室,北京100044
3.北京大学第三医院 耳鼻咽喉头颈外科,北京100191
近年来,随着计算机和信息技术的不断发展,我国的医疗信息化产业逐渐建设完善,其中患者的就诊记录也从原先的纸质材料转变为数字化的电子病历。相比世界其他国家,我国在电子病历建设方面起步较晚。但随着医疗卫生系统愈发受到人们关注重视,近年来我国政府也出台了多项政策来支持医疗信息化的建设与发展。
电子病历是医疗信息化中重要的数据资料,其贯穿于患者就诊看病的全部医疗活动中,涵盖了大量的医疗信息和健康信息,有着巨大的研究意义。首先对于患者来说,挖掘电子病历中的信息有益于自身的健康发展。患者以往的诊断信息和健康状况都被记录在电子病历中,如果能提取、分析这些记录中的数据信息,便可为患者的身体状况、健康信息提供一定的参考与预测。同时,通过挖掘分析患者的电子病历数据,可以在大数据中寻找到其他类似的患者,以其他患者的状况信息和用药信息为该患者提供参考[1-2]。其次对于医生来说,挖掘电子病历中的宝贵信息能提高医疗效率。
推荐系统可以根据用户的偏好预测用户对其他未接触项目的潜在兴趣,从而为用户形成个性化推荐列表[3],已广泛应用在电子商务、新闻媒体、社交网络等众多领域。目前的用药推荐算法一般只限于对患者电子病历数据中数值型、结构化数据的使用,然而本文研究的过敏性鼻炎是一种较为常见的呼吸道疾病,通常情况下医生通过患者的症状和病史便可做出诊断和治疗,少数情况下可能会进行过敏原检测。其病历中一般只包含文本类型的主诉信息和医嘱用药信息,其中主诉文本蕴含了医生为患者做出诊断和医嘱用药的关键信息。同时,注意到症状和用药相当于患者在两个不同视角上的描述,且两视角具有较强的相关关系。因此,本文研究的问题便是通过构建患者主诉和用药信息之间的关联关系,将其投影到一个共享子空间,学习患者表示从而为患者推荐合适的药物,其示意图如图1 所示。
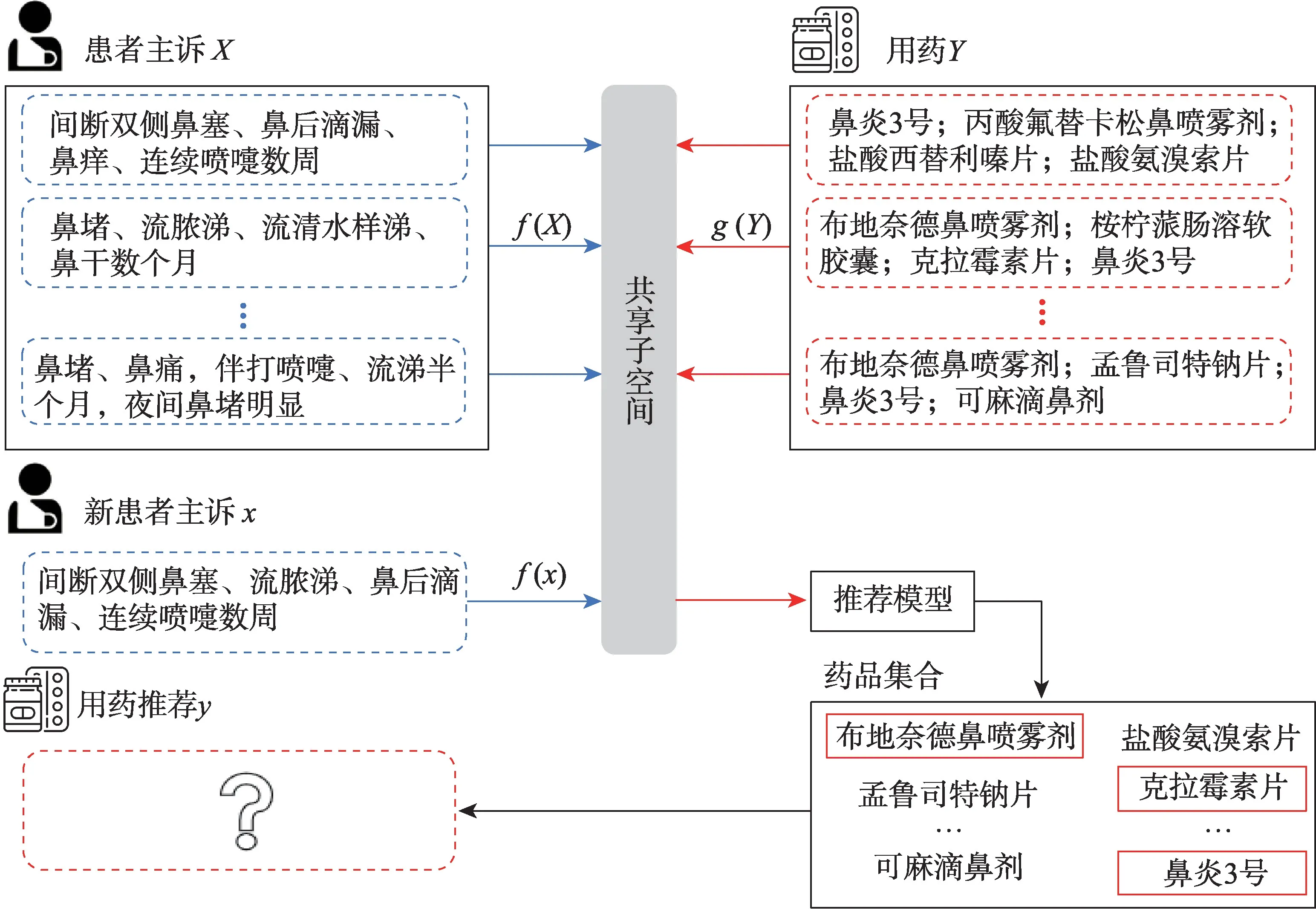
图1 过敏性鼻炎用药推荐示意图Fig.1 Medicine recommendation for allergic rhinitis
为了解决上述问题,本文提出了一种基于深度典型相关自编码器的过敏性鼻炎用药推荐算法。本文首先从非结构化的主诉文本中抽取关键信息,然后通过构建深度典型相关自编码器模型对数据进行特征提取并建立起主诉症状和用药情况之间的关联关系,从而为过敏性鼻炎患者推荐用药。
本文的主要贡献有三方面:
(1)提出一种基于搜索引擎的主诉文本结构化表示方法,使用词语间互信息值对主诉文本进行分词,基于搜索引擎计算词语相似性从而将相似词语归为一类,将主诉分词结果转换为结构化数据。
(2)提出一种基于深度典型相关分析的药品推荐算法,利用深度典型相关自编码器构建患者症状和用药之间的关联关系,进而根据患者症状信息通过近邻搜索来为其推荐用药。
(3)在一个真实的来自三甲医院耳鼻喉科的电子病历数据集上进行实验,实验验证了模型的准确性和有效性,证实了模型的实际应用价值。
1 相关工作
1.1 用药推荐
广义的推荐系统依赖用户和项目之间的交互关系找到用户的个性化需求,从而实现推荐功能。传统的推荐系统主要分为基于内容的推荐、基于协同过滤的推荐和混合推荐[4]。其中应用最广泛的基于协同过滤的推荐可以分为基于用户的协同过滤和基于物品的协同过滤,前者首先寻找与当前用户偏好相似的邻居用户,然后从邻居用户中为当前用户推荐其没有进行过操作的项目;后者则是计算项目之间的相似性,然后为当前用户推荐和他以前喜好的项目相似的项目。文献[5]提出一种基于隐性反馈模型与交叉推荐的药物推荐方法,使用非负矩阵分解提取症状和药物特征。文献[6]提出一种基于多源情境协同感知的药品推荐方法,对情境信息、病情信息和药品信息综合建模。以上研究并未考虑患者的症状和用药信息之间的相关关系,并且线性模型限制了模型的表征能力。
目前用药推荐方面的研究并不充分,且大多数研究主要依据的是患者和药品之间的交互关系,从医学领域来看,仅仅使用交互关系来进行推荐是极其不准确的。
1.2 典型相关分析
典型相关分析(canonical correlation analysis,CCA)[7]是一种多元统计分析方法,用于探寻同一个体中两个多向量之间的关联关系,其使用典型变量对之间的相关关系来衡量两组指标之间的整体相关性。CCA 是一种广泛应用在多视角学习当中的方法,其将两个视角的数据线性映射到低维子空间中,使得映射后的数据具有最大的相关性。
因为CCA 本质上是一种线性映射的方法,不能较好地处理现实世界中错综复杂的数据关系。核典型相关分析(Kernel CCA)[8]将核函数的思想引入典型相关分析中,将低维数据映射到高维的核函数空间后,再进行典型相关分析。深度神经网络和CCA也有较好的结合,Andrew 等人提出了深度典型相关分析(Deep CCA)[9],依据大量数据同时对两个视角进行非线性映射,保持映射后的数据有最大相关性。
2 模型方法
基于深度典型相关自编码器的过敏性鼻炎用药推荐算法整体框架如图2 所示,该模型主要包括三部分。
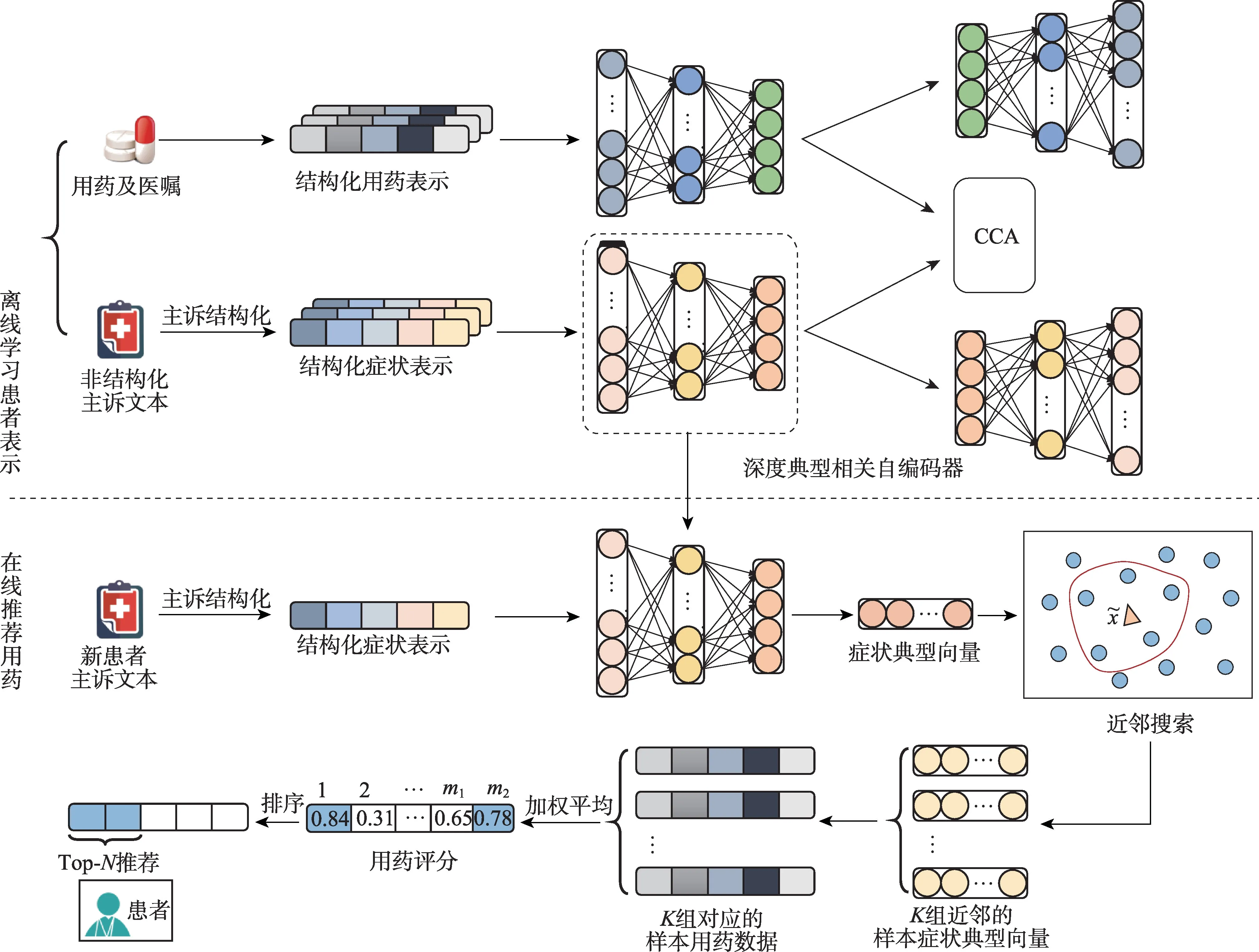
图2 过敏性鼻炎用药推荐算法整体框架Fig.2 Framework for medicine recommendation for allergic rhinitis
(1)主诉文本结构化表示。使用词语间互信息值对主诉文本进行分词,基于搜索引擎计算词语相似性从而将相似词语归为一类,将分词结果转换为结构化的症状表示。
(2)深度典型相关自编码器学习症状和用药表示。主诉症状和用药情况可以看作一位患者的两个视角信息,且两者之间具有较强的相关关系,基于深度典型相关自编码器来学习深层表示并提高两视角数据之间的相关性。
(3)加权近邻搜索进行用药推荐。针对上述获取的症状和用药深层表示,通过距离值加权的近邻搜索为新患者推荐用药。
2.1 基于搜索引擎的主诉文本结构化表示
在过敏性鼻炎患者的电子病历中,最主要的内容便是主诉文本,其蕴含了医生为患者做出诊断和医嘱用药的关键信息。主诉文本通常不超过20 个字,且多以关键词形式呈现,而常用的命名实体识别技术需要大量的标注信息和语料库,需要耗费极大的人力、物力,因此,本文提出了一种主诉文本结构化表示方法,通过分词处理、信息抽取等提取包含的症状信息。
对于本文研究的过敏性鼻炎,患者主诉信息中的医学词语使用较为固定,考虑使用互信息值[10]来进行新词发现,识别出主诉文本中的医学词语和固定搭配,计算公式如式(1)。

点互信息值越大,表明两个词语之间的关联性越强,即相邻出现的概率越大,也就意味着其成为固定搭配组成词语的概率越大。筛选出合适的固定搭配新词,将其添加进自定义词典,对主诉文本再次进行分词。下一步以医院方提供的M类症状作为症状标准词典模板对文本中信息进行提取。但在实际中,由于不同医生的习惯不同,针对同一症状事物,其在主诉上的描述可能存在一定的差异。为了更准确全面地提取主诉文本中的信息,本文提出了一种基于搜索引擎的词语相似性计算方法,将含义相似的词语归为一类。基于搜索引擎的词语相似性计算[11]将网络作为一个实时更新的语料库,其侧重于词语对的相关性。主诉结构化的整体处理过程如图3。
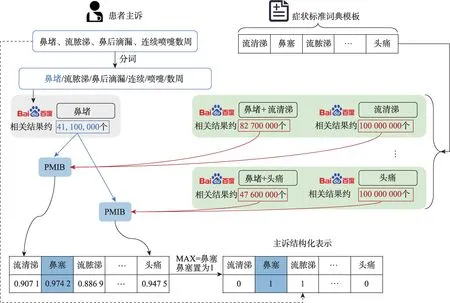
图3 基于搜索引擎的主诉文本结构化表示Fig.3 Structured representation of chief complaint text based on search engine
在进行信息抽取时,首先对分词后的结果与标准逐个对比,若与症状标准匹配,则直接完成抽取工作;若均不匹配,则依据式(2)计算该词语与全部症状标准模板的相似度,若最大的相似度超过设定的阈值,便将其归为对应的标准。
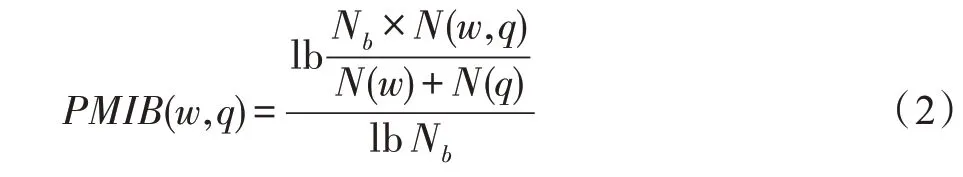
其中,w是分词结果中的词语,q∈Q,Q是全部症状标准词语的集合,N(w)表示使用搜索引擎对w进行搜索返回的查询结果数量,N(w,q)表示同时搜索两个词语w和q返回的查询结果数量,Nb表示搜索引擎的索引总数。
2.2 深度典型相关自编码器学习症状和用药表示
每位患者的主诉症状和用药情况可以看作该患者的两个视角信息,且两者之间具有较强的相关关系。本文将堆栈稀疏自编码器[12]和典型相关分析[13-14]相结合,构建一个深度典型相关自编码器(deep canonically correlated autoencoder,DCCAE)用于更好地获取患者主诉症状和用药情况的表示,模型如图4所示。
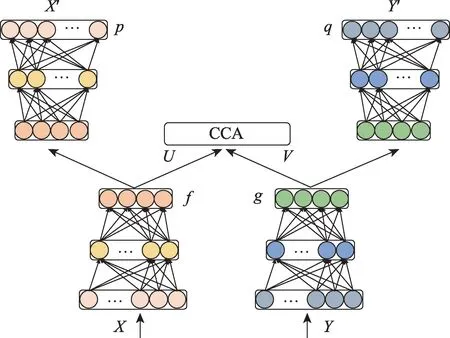
图4 深度典型相关自编码器Fig.4 Deep canonically correlated autoencoder
首先对主诉症状和用药情况分别使用一个堆栈稀疏自编码器重构输入数据,并提取对应的非线性特征。然后对隐藏层的输出进行典型相关分析,将患者症状和用药情况投影至一个共享子空间,并计算两者的相关系数,将结果反馈给网络的输入层,通过迭代训练最小化两个自编码器的重构误差,并且最大化两视角信息的典型相关系数。模型目标函数定义如式(3)。
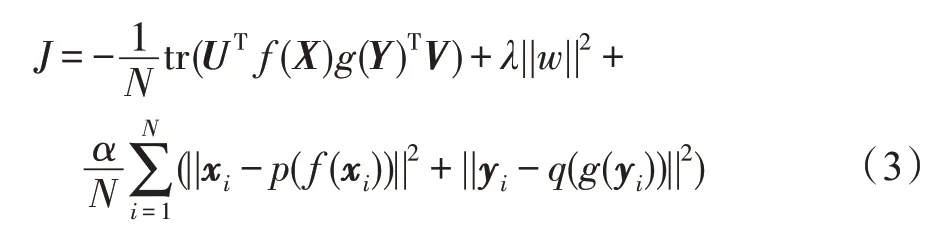
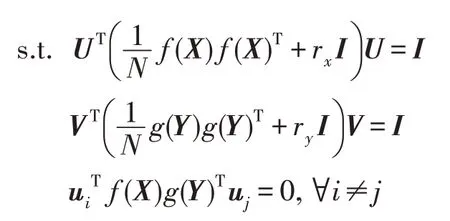
其中,f和g分别是自编码器中编码阶段的深度神经网络,p和q分别是解码阶段的深度神经网络,X和Y表示主诉症状和用药情况的输入矩阵,U=[u1,u2,…,uL]和V=[v1,v2,…,vL]分别表示处理两个隐藏层输出向量的投影矩阵,rx和ry分别是协方差估计的正则化参数,α是重构误差和相关系数之间的权衡参数,λ是自编码器的正则化参数。
2.3 加权近邻搜索用药推荐
通过DCCAE获取了患者主诉症状和用药情况之间非线性的特征表示,分别为。对于一个仅含主诉症状信息的新患者样本,首先通过训练好的症状自编码器获取其症状表示xa∈RL,并计算其经过U投影的典型向量。然后使用K近邻算法搜索在训练集中与该样本距离较近的其他多组典型向量,距离计算公式如式(4)。
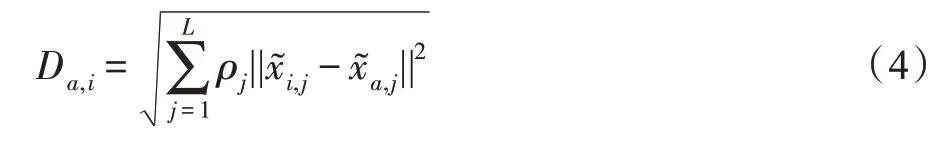
其中,ρ是经过归一化处理的相关系数。
至此,获得了与新样本症状向量邻近的K个症状向量,而这K个症状向量对应着K个原始患者信息,下面根据近邻度距离加权计算用药平均值作为用药评分,计算公式如式(5)。

获取新样本的用药评分后,从大到小将药品进行排序,从而为患者推荐一种或多种药品。
3 实验
3.1 实验数据集
本文实验所用数据集来自某三甲医院耳鼻喉科诊断为过敏性鼻炎的患者电子病历,且经过脱敏处理,对电子病历进行清洗、去重等操作,获得3 700 条电子病历记录,包含患者的基本信息、主诉症状、用药医嘱等。药品种类共100 种,其中使用频率大于1%的药品有23 种。通过2.1 节主诉文本结构化处理得到最终数据集,其中每条记录为一位患者的全部信息,包括16 项症状指标和23 项用药情况,均为二值数据。实验中数据集按比例划分为训练集、验证集和测试集。
3.2 度量指标
本文采用精确率(Precision@R)、召回率(Recall@R)和F1-score(F@R)作为评价指标。精确率表示正确预测正样本占预测为正样本的比例,召回率表示正确预测正样本占实际正样本的比例,F1-score 是精确率和召回率的调和平均值,公式如下:
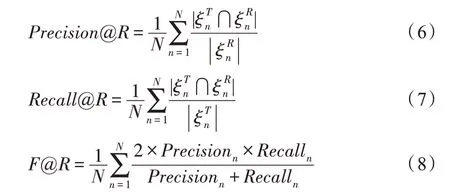
其中,N为数据总数量,表示第n个数据的用药集合,表示第n个数据推荐的前R个用药集合。在本文使用的数据集中,所有患者使用的药物组合中均包含了同一种药品“鼻炎3 号”,因此仅推荐一种药品时的结果没有差异,故R在{2,3}中取值。
3.3 对比方法
为了验证本文算法的效果,选择使用以下5 种算法进行对比实验。
(1)Frequency(Freq)。该方法统计训练数据中每种药品的出现频次,在进行推荐时,对于测试集上每一条数据均以出现频次作为用药评分。
(2)KNN-e[15]。直接使用原始的主诉数据计算欧式距离来找出与此患者最相似的K个患者,计算用药数据的平均值作为用药评分。
(3)KNN-h。将(2)方法中的汉明距离替换为欧式距离。
(4)MLP(multi-layer perceptron)。多层感知机是一种经典的神经网络,包括输入层、输出层和多个隐藏层。将患者的主诉数据作为输入层的输入,使用ReLU 函数作为激活函数,训练其输出每种药品推荐的概率作为用药评分。
(5)CCA。对原始主诉信息和用药信息进行典型相关分析,获取两者的投影向量,再使用3.3 节当中的方法进行用药推荐。
3.4 实验参数
实验中,在验证集上进行多次重复实验,利用网格搜索方法确定最优参数。对于所有方法,设置症状维度为16,用药维度为23。其中KNN 算法中近邻个数K在{12,24,36,48,60}中取值;MLP 具有一层隐藏层,维度在{16,18,20,22}中取值;CCA 算法中最终输出维度在{4,8,12,16}中取值;在本文提出的方法中,隐藏层维度d0和d1均在{4,8,12,16}中取值,近邻个数K在{12,24,36,48,60}中取值,权衡参数α在{0.50,0.75,1.00,1.50,2.00}中取值,正则化系数λ在{10-5,10-4,10-3,10-2,10-1}中取值。
得到的最优参数如下:KNN 算法中近邻个数K=36,MLP 的隐藏层维度为18,CCA 算法中最终输出维度为8;在本文方法中,两个自编码器网络的维度分别为16-12-8-12-16 和23-16-8-16-23,K=36,α=2,λ=10-5。
3.5 实验结果
本文首先对上述数据集进行主诉结构化,图5 和图6 分别给出了词语“流白涕”和“嗅觉下降”基于搜索引擎计算词语相似性的结果图。从结果可以看出,“流白涕”与“流清涕”的匹配度最高,“嗅觉下降”和“嗅觉减退”的匹配度最高,这也符合实际中医生的认知。
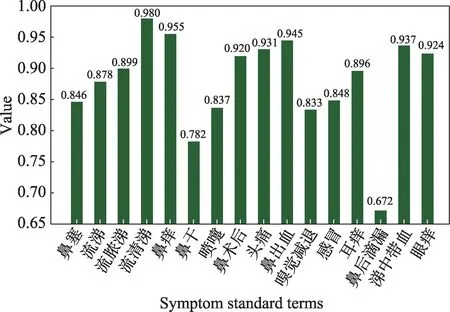
图5 “流白涕”与症状标准词典模板的匹配结果Fig.5 Matching results of word thin nasal discharge to standard dictionary template for symptoms
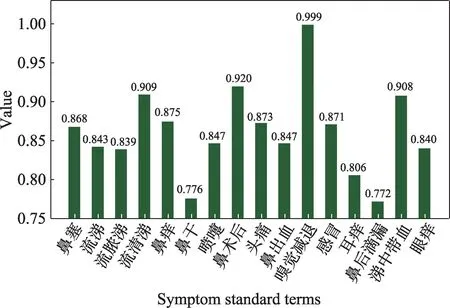
图6 “嗅觉下降”与症状标准词典模板的匹配结果Fig.6 Matching results of word hyposmia to standard dictionary template for symptoms
通过实验比较了本文方法和其他对比方法。表1 给出了不同方法的性能表现,实验结果均是运行5次然后取平均性能所得。观察表1 可以看出:
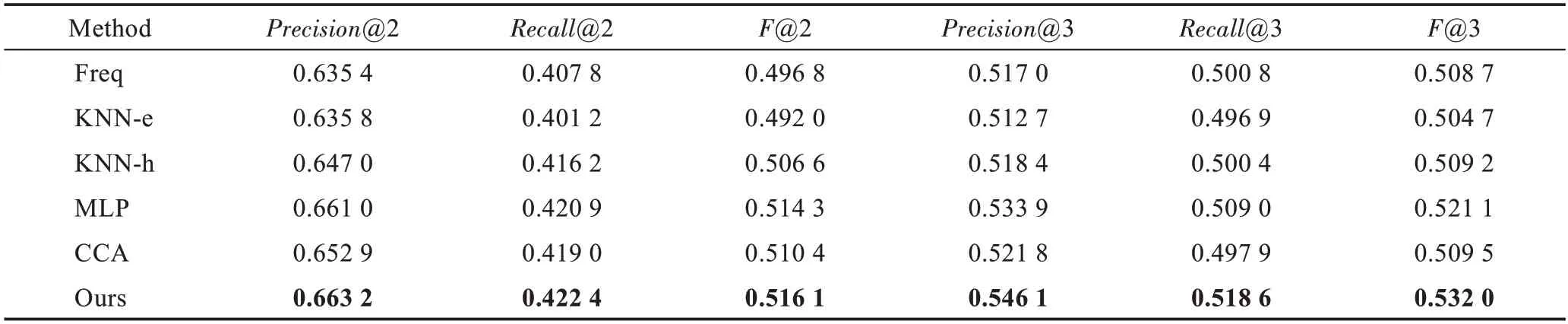
表1 各方法在数据集上的推荐性能Table 1 Evaluation results of different methods on dataset
(1)与所有的对比方法相比,本文方法在精确率Precision、召回率Recall和F1-score 上都取得了最好的结果,这证明本文方法在过敏性鼻炎的用药推荐上能够实现更有效的实验性能提升。
(2)KNN-e 方法未能超过Frequency 方法,可以看作完全无效果。这是因为KNN-e 直接使用患者的二值化症状数据计算欧式距离,不能较好地计算患者之间的相似度。相比而言,KNN-h 使用的汉明距离比欧式距离更加有效。
(3)基于深度学习的MLP 方法比CCA 模型效果更好,这是因为CCA 模型虽然考虑了患者症状和用药之间的相关性,但线性变换的特点限制了模型的表征能力。
(4)对比MLP 和本文方法,前者采用端到端的模式进行训练,没有考虑患者之间的相似性。相较而言,本文方法使用深度典型相关自编码器对患者的症状和用药进行表征并构建相关关系,能够搜索到与患者相似的群体,同时取得良好的推荐效果。
下面测试不同参数设置对模型结果的影响。图7展示了K 近邻中的近邻个数对本文方法及对比方法效果的影响,其中设置推荐药品数为3,调节不同的K值大小。可以看出,在K=36时取得最好效果。这是因为随着K值的增大,搜索得到的患者相似度逐渐降低,可能引入更多的噪声信息,从而降低实验性能。
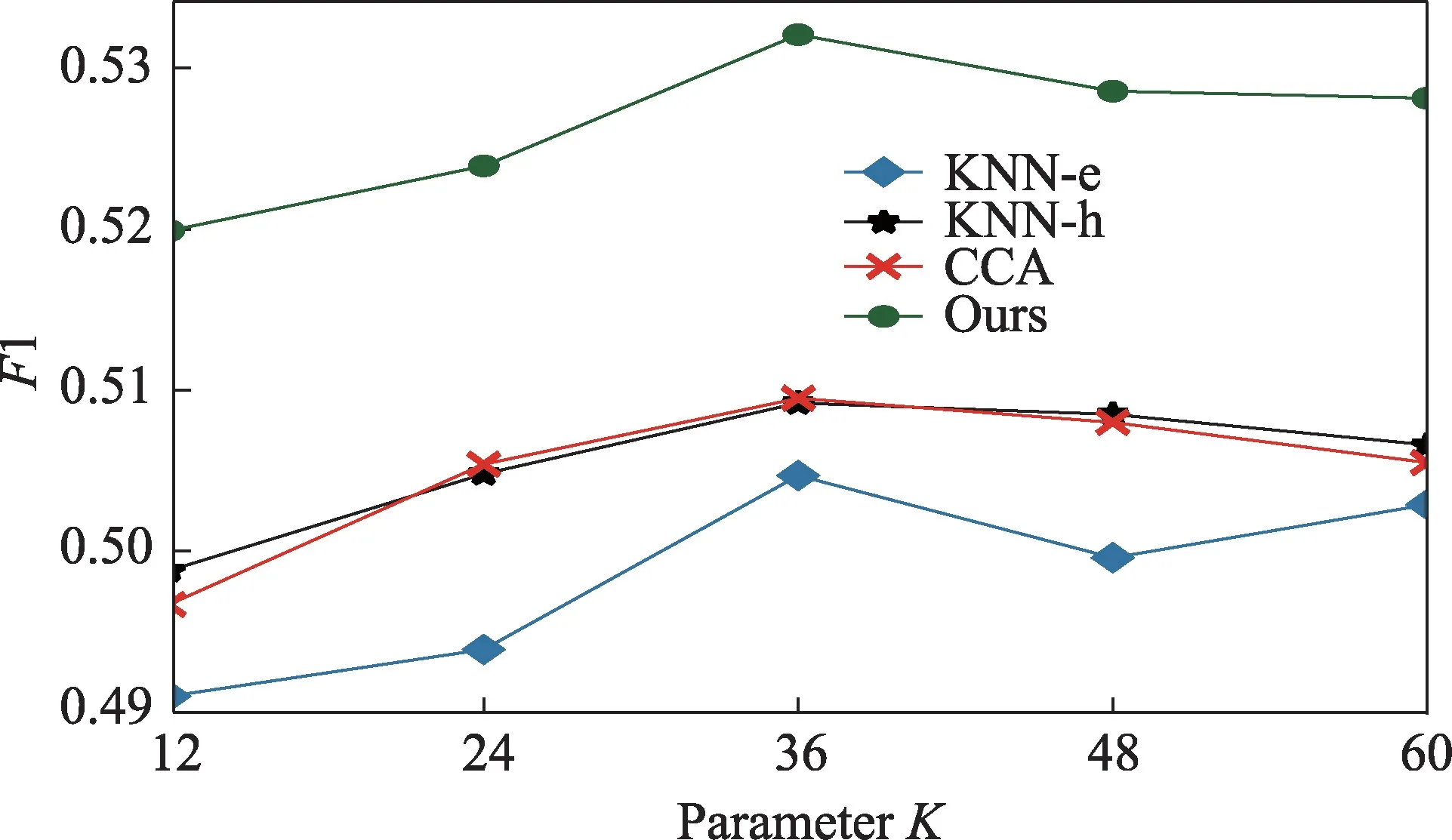
图7 近邻个数K 对性能的影响Fig.7 Effect of the number of neighbors K on performance
本文方法使用了两个含有2 层隐藏层的自编码器,令每层的维度分别为d0和d1。固定d0不变,图8展示了d1的变化对本文方法效果的影响,其中K设置为36,推荐结果数设置为3。可以看出,在d1=8 时取得最好效果,这是因为较低维度的空间没有足够能力表示数据的隐藏属性,而较高维度的空间又不利于模型的泛化能力,造成推荐性能下降。
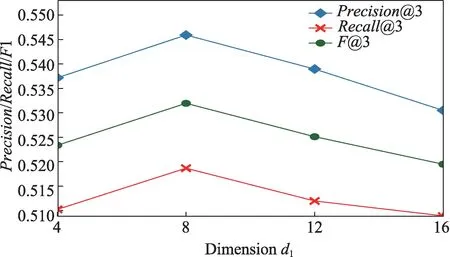
图8 隐藏层维度d1 对性能的影响Fig.8 Effect of hidden layer dimension d1 on performance
4 结论
本文提出了一种基于深度典型相关自编码器的过敏性鼻炎用药推荐算法。该模型通过一种主诉文本结构化表示方法,使用词语间互信息值对主诉文本进行分词,基于搜索引擎计算词语相似性从而将相似词语归为一类,将分词结果转换为结构化的症状表示。与目前常见的自然语言处理方法相比,该表示方法可移植性好,不需要在大量语料库上进行训练便可完成任务。同时,该模型考虑到患者的症状和用药之间存在较强的相关关系,通过深度典型相关自编码器建立起两者之间的关联关系。最后在一个真实的来自三甲医院耳鼻喉科的电子病历数据集上进行实验,验证了模型的准确性和有效性,证实了模型的实际应用价值。
猜你喜欢
小学生作文(低年级适用)(2022年10期)2022-10-31
国际医药卫生导报(2022年18期)2022-09-29
网络安全与数据管理(2022年1期)2022-08-29
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
现代临床医学(2021年1期)2021-01-26
小天使·一年级语数英综合(2020年4期)2020-12-16
成都信息工程大学学报(2018年3期)2018-08-29
西安工程大学学报(2016年6期)2017-01-15
探测与控制学报(2015年4期)2015-12-15
传奇故事(破茧成蝶)(2015年7期)2015-02-28
