
融合激光雷达和RGB-D相机建图
2023-03-04 07:48李少伟钟勇杨华山张树范周慧
福建工程学院学报 2023年6期
李少伟,钟勇,杨华山,张树,范周慧
(福建省汽车电子与电驱动技术重点实验室,福建 福州 350118)
同时定位和地图构建(simultaneous localization and mapping, SLAM)[1]技术是指在没有环境先验信息的情况下,移动平台在运动过程中建立环境模型并估计自身的运动。SLAM技术是搭载传感器的移动平台在未知环境中进行侦查和导航的前提。
经过多年的研究,激光SLAM和视觉SLAM接近成熟[2-3]。国内外学者开源了多种SLAM方法,包括基于激光雷达的Gmapping[4]和Cartographer[5],以及基于视觉相机的RGB-D-SLAM[6]和ORB-SLAM[7]等。然而,在实际应用中,单一传感器容易受到环境干扰,导致环境信息缺失和精度下降等。为了克服这些缺点,学者们开始探索激光雷达和深度相机的融合。通过多传感器融合技术,提高移动机器人在复杂环境中的定位和建图精度。陈文佑等[8]提出了一种激光与相机局部地图融合构建全局地图的策略,近似地获取机器人定位和建图的概率密度,但却导致粒子数量减少,从而浪费计算资源。晏小彬等[9]用单目相机作为辅助进行激光SLAM。Xu等[11]提出了一种基于扩展卡尔曼滤波器原理的RGB-D相机与激光雷达融合的SLAM方法。该方法在相机匹配失败时,通过将激光雷达数据补充到相机数据中并生成地图。白崇岳等[12]使用扩展卡尔曼滤波算法将激光雷达、惯性测量单元(IMU)和光电编码器融合定位。卢俊鑫等[13]提出一种新的RGB-D视觉里程计方法,结合了点线的优点。
本文采用激光雷达和RGB-D相机在数据层次上融合的方法,基于RTABMAP算法提供里程计信息,进行回环检测和全局优化,解决了单一传感器构建地图精度低、易受环境干扰等问题,保证环境地图信息的完整性。
1 系统整体结构与传感器模型
如图1所示,智能小车的主要控制器是树莓派。在电脑上,同样安装了与树莓派相同版本的机器人操作系统,并通过WIFI连接到树莓派的热点。通过SSH建立远程登录,实现远程发布指令。STM32主板负责接收里程计、IMU和电池电压等信息,并将其传输给树莓派ROS主控。树莓派ROS主控将运动底盘的目标速度等指令发送给STM32主板。此外,树莓派还通过USB与激光雷达和RGB-D相机连接。把接收到的数据信息经过处理、整合,通过相关算法完成智能小车的运动、建图等功能。
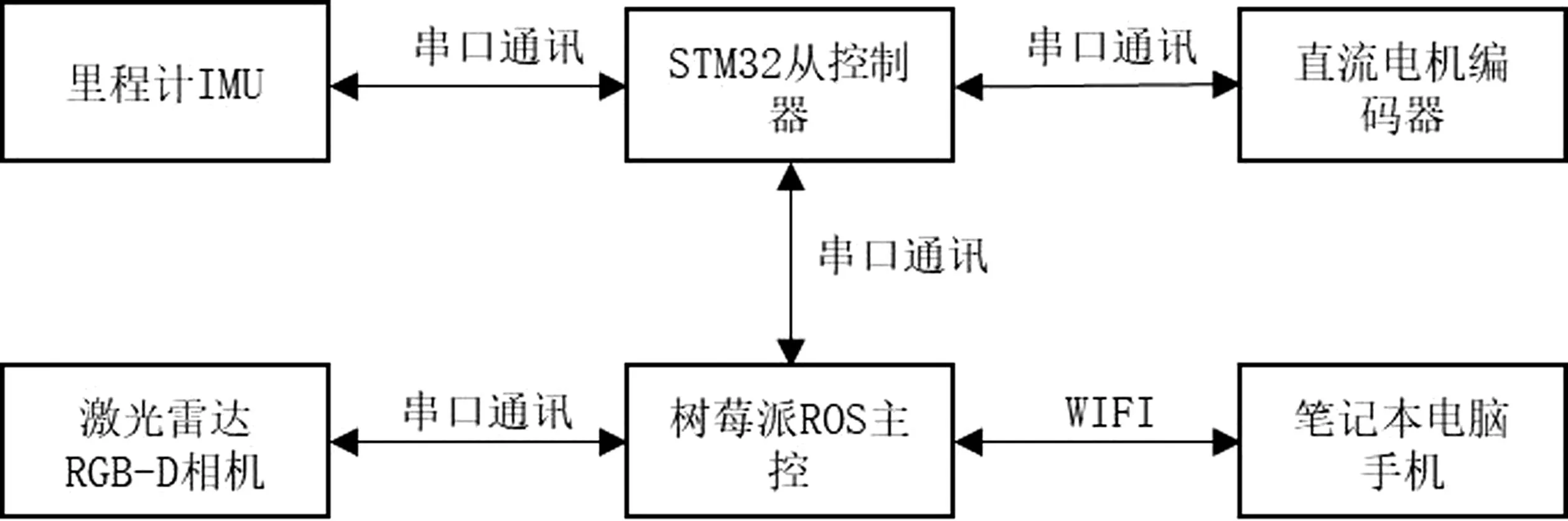
图1 系统结构图Fig.1 System structure diagram
采用奥比中光RGB-D相机获取深度图像,参数如表1所示。采用思岚二维激光雷达RPLIDAR A1,参数如表2所示。
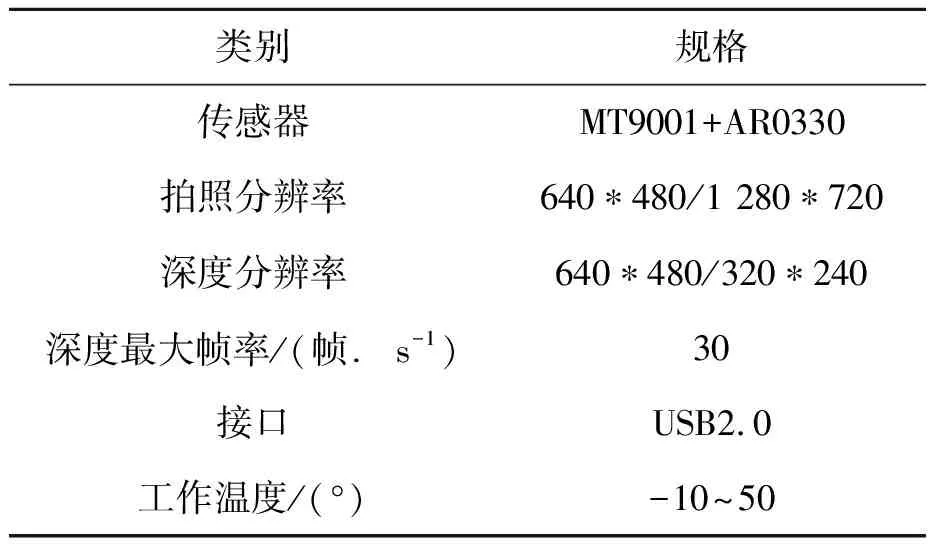
表1 奥比中光RGB-D相机参数Tab.1 Parameters of ORBBEC RGB-D camera
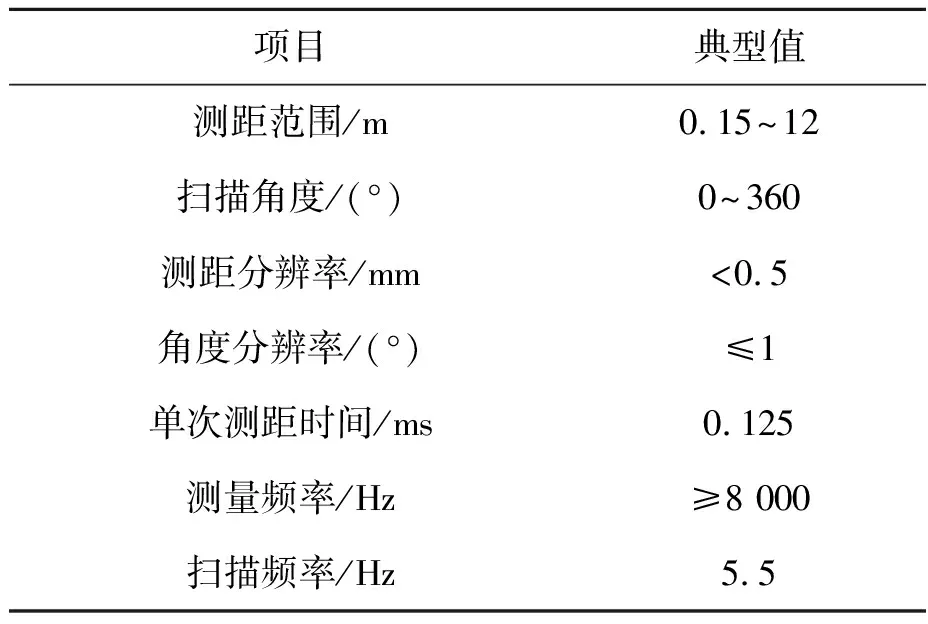
表2 RPLIDAR A1激光雷达参数Tab.2 RPLIDAR A1 LiDAR parameters
2 传感器数据融合方法
2.1 RGB-D相机标定
使用张正友标定法,通过相机标定实验,获取上述相机的内、外部参数。如图2所示,准备一张棋盘格,将其贴在表面光滑的板子上作为标定板。使用RGB-D相机和红外相机分别对棋盘格标定板拍照。两种相机的标定步骤相同。标定实验需要拍摄20组照片,以获得更准确的结果。

图2 棋盘格标定板Fig.2 Checker board calibration board
标定后的总体误差像素在正常范围内,因此标定结果较为准确。通过RGB-D相机标定,获得RGB-D相机和红外相机的内参及畸变系数,如表3所示。
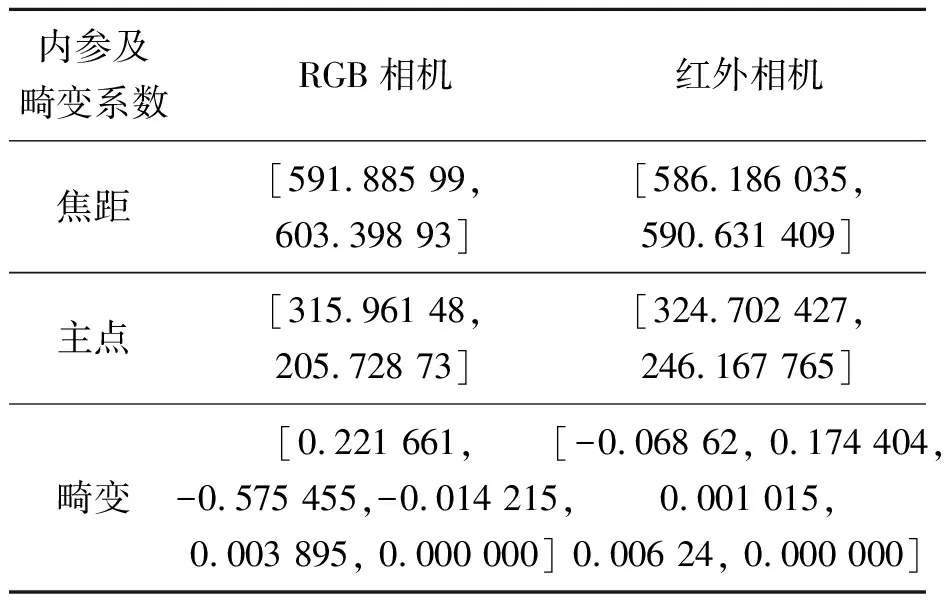
表3 奥比中光相机标定结果Tab.3 ORBBEC camera calibration results
2.2 相机与激光雷达联合标定
2.2.1 相机建模
常用的是针孔相机模型。假设光线从物体通过针孔进入相机成像,o-x-y-z为相机坐标系。点P在世界坐标系中的坐标为(XW,YW,ZW),点P在像素坐标系下投影的坐标为(XC,YC,ZC), 经过世界坐标系到相机坐标系下的变换得:
(1)
式中,M为外参矩阵,R为旋转矩阵,t为平移向量。
根据相似三角形关系可得:
(2)
式中,负号表示倒立的像,f为相机的焦距,X′和Y′分别为成像点的坐标。
将成像平面置于三维空间点同一边,可将式(2)简化为:
(3)
即:
(4)
将式(4)写成矩阵形式表达式为:
(5)
根据针孔相机模型,假如图像物理坐标系的原点O′在像素坐标系中为坐标(u0,v0),令dx、dy分别为像素在X′和Y′方向上的实际物理尺寸大小,则:
(6)
将式(6)用矩阵形式表示:
(7)
联立式(5)和(7),XC、YC用X′和Y′表示可得:
(8)
联立式(1)和(8),XW、YW表示XC、YC,且令fx=f/dx,fy=f/dy,则可得:
(9)
式中,fx、fy、u0和v0为相机内参。
若激光雷达扫描空间中的点P距离激光雷达为d,激光雷达旋转角度θ时,则点P在激光雷达坐标系中的坐标为:
(10)
该点在世界坐标系下可以表示为:
(11)
点P在相机和激光雷达坐标系中的坐标都表示该点的位置,则由世界坐标系中的式(1)和式(7)的关系可得:
(12)
联立公式(9)可得,点P在激光雷达坐标系和相机坐标系下的对应关系为:
(13)
2.2.2 内参数据
通过对相机的标定实验得到内参数据。使用得到的相机内参启动相机激光雷达联合标定程序,接着启动激光雷达节点,使用打开的rviz可视化图形程序观察激光雷达扫描的数据,选定相机和激光雷达汇总的点进行标定,直到满足要求的点标定完毕。将标定结果存储在yaml文件里。联合标定结果如式(14 )矩阵所示。
(14)
2.3 激光雷达与RGB-D相机融合
只使用激光雷达传感器构建的地图并不能准确反映环境特征,因为激光雷达主要提供距离信息而缺乏颜色和纹理等视觉特征。相比之下,RGB-D相机传感器可以直接感受到深度信息,并且能够提供更丰富的点云地图,从而更准确地反映环境的特征。然而,相机的视野较小,测量范围有限,并且容易受到光照条件的影响。因此,通过将多个传感器融合可以显著提高整个传感系统的精度和鲁棒性。本文使用RTABMAP算法实现融合视觉图像和激光SLAM建图。
2.3.1 RTABMAP系统框架
RTABMAP系统框架的设计如图3所示。将视觉传感器、激光传感器和机器人底盘等通过tf关系输入系统。经过同步模块进行时间戳对齐,以确保数据的一致性。RTABMAP系统采用图结构来组织地图,图结构由节点和节点之间的连接边组成。经过同步后的传感器数据将被存储到短期内存(short-term memory,STM)模块中。对于每一帧传感器数据,系统会创建一个节点,并将该节点中包含的信息存储其中。这些信息包括该帧对应的里程计位姿、视觉和激光的观测数据,以及从该帧中提取出的视觉单词和局部地图等有用信息。
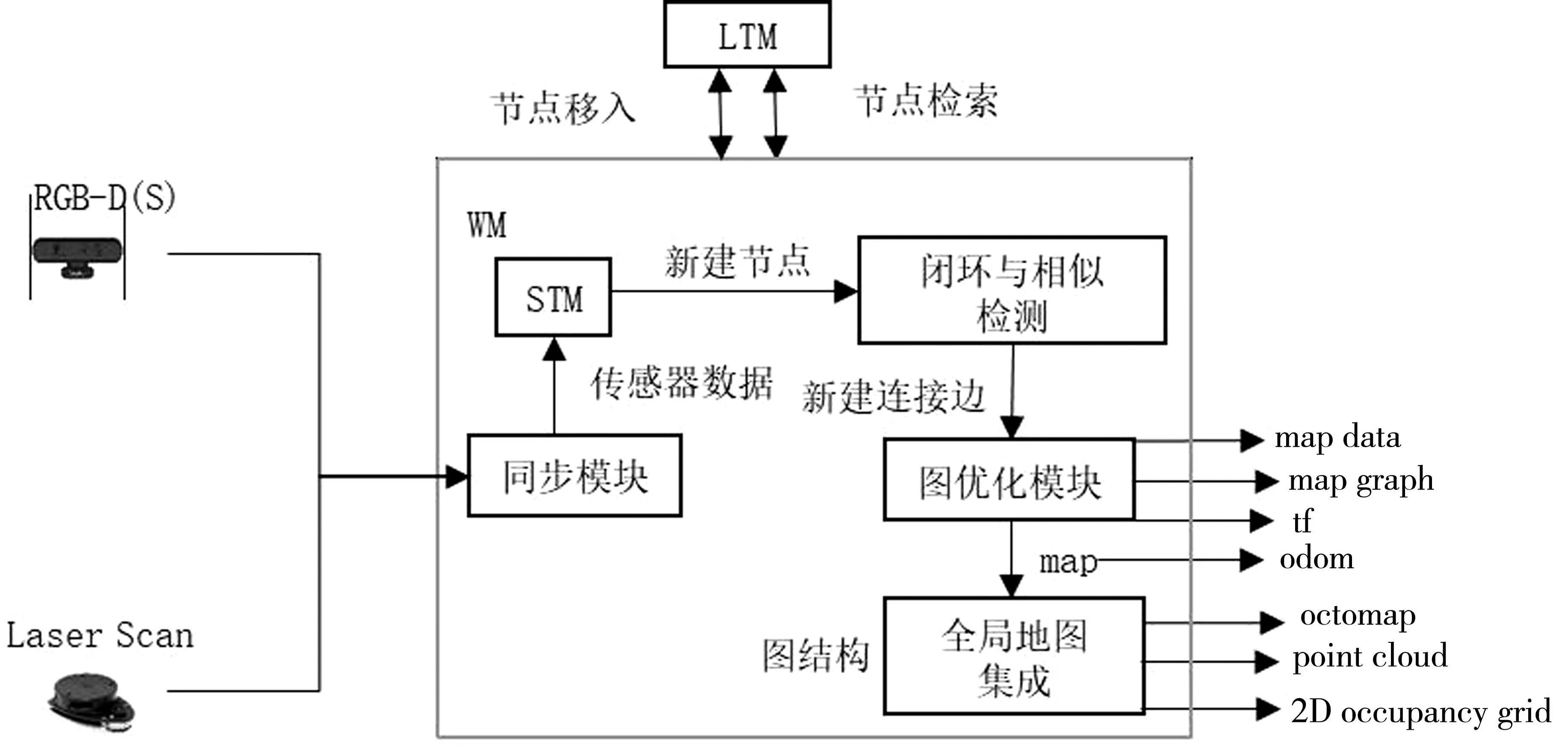
图3 RTABMAP系统框架Fig.3 RTABMAP system framework
2.3.2 内存管理机制
RTABMAP采用图结构组织全图,每采集一帧传感器数据创建一个节点存储相关数据,当所建的图规模很大时,创建的节点数量也很大,如果只在全部节点上闭环检测和全局优化就会影响到实时性,RTABMAP引入内存管理机制,以分级管理这些节点。内存管理机制将地图中的节点分成3个级别: STM用于存储局部地图的节点;工作内存(working memory,WM)用于存储全局地图的节点;长期内存(long-term memory,LTM)用于存储暂时与全局地图无关或不重要的节点。
内存管理机制的具体过程如图4所示。传感器数据经过传感器内存(sensor memory,SM)模块进行预处理,包括数据维度的精简和特征提取,计算出当前的位姿信息,处理后的数据被用来创建新的节点加入STM中。如果新节点与前一个刚加入STM的节点非常相似,那么可以利用权重更新方法将这两个节点融合在一起。
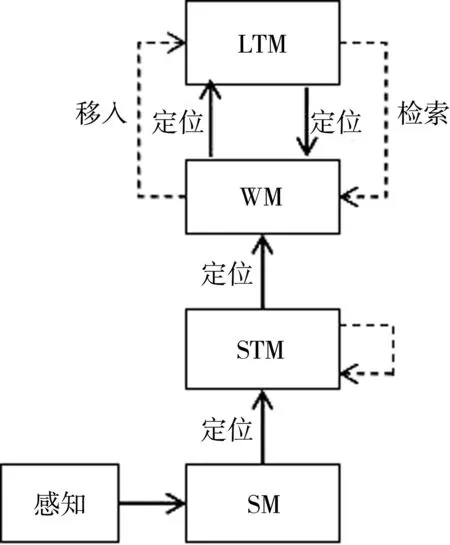
图4 内存管理机制Fig.4 Memory management mechanism
2.3.3 闭环检测与图优化
当STM创建一个新的节点时,可利用深度图像、激光扫描数据、点云数据等来生成对应的局部地图。如果选择生成三维地图,可以直接用三维点云创建三维局部地图,也可将三维点云经过三维光束模型处理创建三维局部地图。
通过一个独立的ROS节点提供RTABMAP所需的里程计信息。由于局部建图所依赖的里程计存在累积误差,因此需要进行回环检测和全局优化。在RTABMAP中,回环检测包括视觉闭环检测和激光相似检测,而全局优化则采用位姿图优化方法,视觉闭环检测基于视觉词袋模型和贝叶斯滤波器。视觉词袋模型能够快速计算当前位姿节点与候选回环节点之间的相似度。它通过提取图像特征并构建词袋表示,实现高效的图像匹配和相似度计算。贝叶斯滤波器用于维护候选回环节点相似度的概率分布,通过更新概率分布来选择最可能的回环节点。视觉闭环检测能有效地检测到不同时刻和位置下的相似场景,从而解决里程计累积误差的问题。
2.3.4 全局地图集成
局部地图在机器人自身坐标系下构建,而全局地图在世界坐标系下构建。这两者之间通过机器人坐标系到世界坐标系的变换关系进行转换。算法主节点RTAB-Map利用闭环检测和全局优化来维护机器人的全局位姿估计,并通过发布机器人坐标系和世界坐标系之间的变换关系来实现转换使用。
使用RGB-D深度传感器和激光雷达对信息采集和建图是RTABMAP建图的关键步骤。在RTABMAP中,当每个新的特征节点被添加到地图中时,新生成的局部地图将与已构建的全局地图进行融合。这个过程基于各个节点的里程计位姿,将各个局部地图拼接起来形成一张全局地图。
3 实验验证
3.1 环境建图
搭建一台室内智能小车,该智能小车具有长达8 h的单次续航时间,系统整体架构组成:阿克曼转向系统、驱动电机、树莓派4B、STM32主板、激光雷达和惯性测量单元(IMU)。选择的场景长约10 m,宽约8 m,具有明显的空旷区域、障碍区域和线条清晰的边界,同时具备闭环的特性,能直观地对比建图效果。
激光雷达建图结果如图5所示,启动小车环绕周围环境一圈后形成了栅格地图,白色部分代表智能避障车已经扫描到的无障碍区域,即可以到达的区域;黑色部分表示存在障碍物的区域,可以观察到激光雷达所扫描的范围较广,建立的环境地图接近真实环境,且地图的完整性和精确度较高。
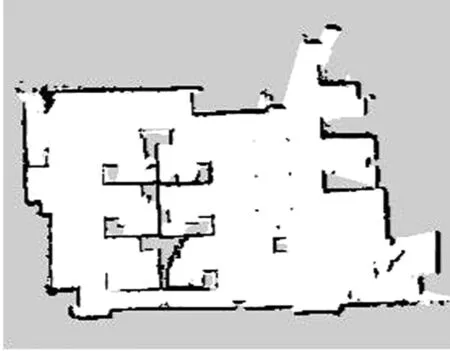
图5 激光雷达环境建图Fig.5 Lidar environment mapping
RGB-D相机检测环境三维建图如图6所示,启动小车和建图程序,初始建图效果如图6(a)所示,控制小车绕周围场景一圈,最终的建图效果如图6(b)所示。整体的建图效果较为准确,虽然视觉传感器易受光照影响且视野范围有限,但障碍物的重要特征信息并未丢失,这也是将视觉传感器与激光雷达融合的依据。

图6 视觉传感器三维建图Fig.6 3D construction of visual sensors
通过融合激光雷达和相机两个传感器进行环境建图,实验结果如图7(a)和(b)所示。结果表明,通过准确投影三维空间点到二维平面并处理深度相机数据后,地图更新能够与激光雷达构建的地图保持一致,同时能够较为完整和清晰地反映实验场景。这说明融合视觉和激光雷达的建图方法具有良好的效果。相比于单一传感器建立的地图,融合建图方法能够获取更为完整的环境信息,更接近真实环境。
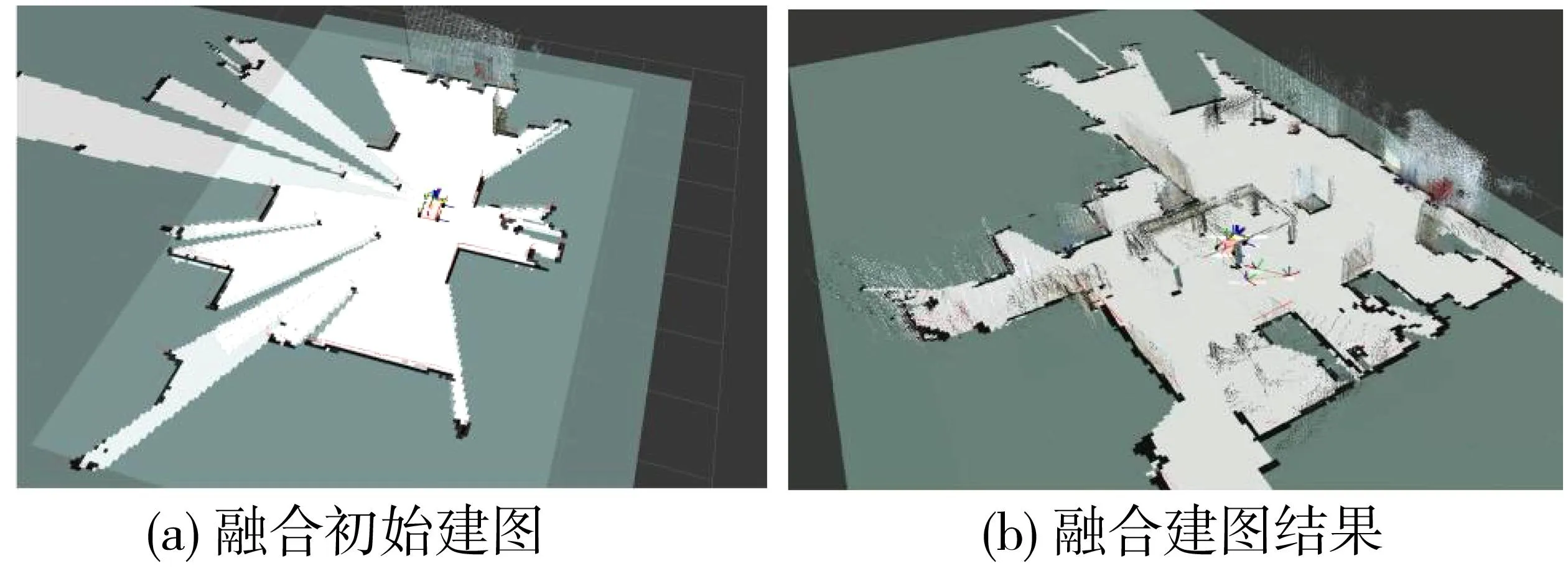
图7 融合激光雷达和视觉建图Fig.7 Fusion of LiDAR and visual mapping
用激光雷达与RGB-D相机融合计算建图时间、障碍物检测率和地图的尺寸精度及角度精度,计算结果如下。
(1)建图时间和障碍物检测率
建图时间为10次建图所用的平均时间。假设障碍物检测率为p,则
p=C1/C2
(15)
式(15)中,C1为融合传感器建图所检测到的障碍物总边长,m;C2为实际图中障碍物总边长,m。
建图时间和障碍物检测率如表4所示。
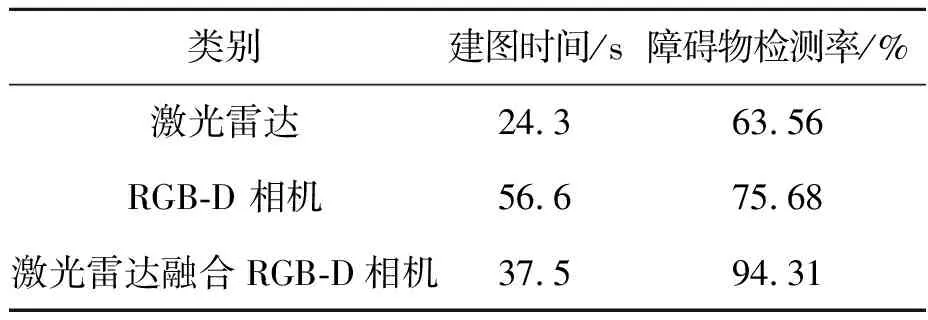
表4 障碍物检测率和建图时间Tab.4 Obstacle detection rate and mapping time
(2)地图尺寸精度及角度精度
选取图中3条线段和两个角度进行测量和误差分析,结果如表5所示。
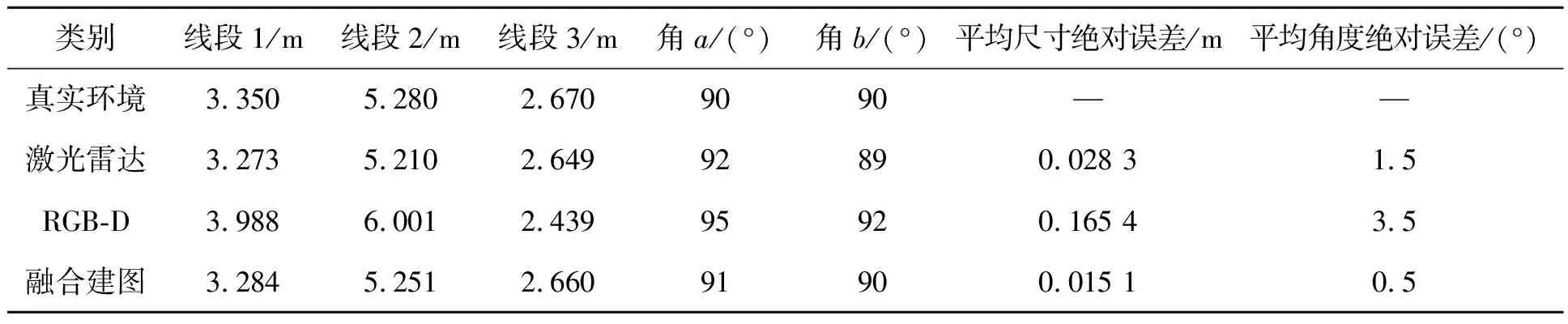
表5 测量结果及误差分析Tab.5 Measurement results and error analysis
由表4、表5可见,激光雷达与RGB-D相机融合建图方法的障碍物检测率为94.31%,比仅使用激光建图高出30.75%,比仅使用RGB-D相机建图高出18.63%。此外,在地图尺寸精度方面,平均绝对误差比仅使用激光建图小了0.013 m,比仅使用RGB-D相机建图小了0.150 m。在角度精度方面,平均绝对误差比仅使用激光建图小了1°,比仅使用RGB-D相机建图小了3°。综上,激光与RGB-D相机融合建图方法在多个方面都表现出更高的性能和更好的精度,为机器人在复杂环境中的导航和感知任务提供了更可靠的支持。
4 结论
1)提出一种RTABMAP算法,将视觉传感器与激光雷达采集到的信息按照一定的规则融合,以弥补单一传感器不能准确构图的问题。
2)通过利用多传感器感知的冗余信息进行融合,构建了一张鲁棒性更高、精度更高的3D栅格地图。
3)将激光雷达与RGB-D相机融合建图,障碍物的检测率比单独使用激光雷达建图和RGB-D相机建图分别提高了30.75%和18.63%。地图尺寸平均绝对误差相比单独使用激光雷达建图和RGB-D相机建图,分别减少了0.013 m和0.150 m。地图的角度平均绝对误差比激光雷达建图的小1°,比RGB-D相机建图小3°。
猜你喜欢
北京测绘(2022年5期)2022-11-22
汽车工程师(2021年12期)2022-01-17
汽车观察(2021年8期)2021-09-01
汽车维修与保养(2020年11期)2020-06-09
电子制作(2019年10期)2019-06-17
中国交通信息化(2019年1期)2019-03-26
成都信息工程大学学报(2018年4期)2019-01-23
电子制作(2018年16期)2018-09-26
自动化学报(2017年4期)2017-06-15
中国惯性技术学报(2017年1期)2017-06-09
