
基于差分进化改进灰狼优化的BP模型的全国粮食产量预测
2023-03-15 08:55陈灿虎陈英伟
农业与技术 2023年5期
陈灿虎 陈英伟
(河北经贸大学数学与统计学学院,河北 石家庄 050061)
引言
我国自古以来就是农业大国。“民以食为天”,粮食安全与粮食生产是国民经济安全的战略性问题,是农业经济工作的根本重心,关系到国计民生,因此精准预测粮食产量及变化趋势是非常有必要的。由于气候、自然灾害以及其它不可控因素的影响,粮食产量预测往往具有较大难度和不确定性。
粮食产量预测是一个复杂性极高的重大现实问题,学者对粮食产量的预测主要体现在3个方面。从投入占用产出、遥感技术、气象学等角度入手,这类方法关注的是农作物的生长过程;依靠粮食产量历史数据挖掘内生规律,常见的方法有灰色预测模型、时间序列模型等,此类方法所需数据量小,预测简单;以粮食产量相关影响因素建模并预测,常见的方法有支持向量机、神经网络等模型,这类方法所需数据量适中,由于数据的易获得性和科学性,预测结果更加合理,预测精确更高。
近年来,智能算法成为粮食预测领域研究的宠儿。2002年王启平采用BP神经网络模型预测粮食产量[1],对比发现,BP神经网络对于单输入单输出的时间序列预测具有一定的优越性,且泛化能力强;李武鹏提出以自适应遗传算法优化BP神经网络建立模型预测粮食产量[2];郭庆春等以非线性最小二乘法优化BP神经网络,拓宽了粮食产量预测的途径[3];2017年戎陆庆等把灰色关联分析和BP神经网络相结合预测粮食产量[4];2020年Saleh I A等提出以一种反向传播的神经网络改进萨尔普群算法(SSA)预测粮食产量[5];2021年胡程磊等以改进的粒子群算法优化BP神经网络,大幅度提高了粮食产量预测精度[6];2021年黄琦兰等提出使用改进的差分进化算法优化最小二乘SVM参数,建立了ADE-LSSVM粮食产量预测模型[7]。综上所述,近年来粮食产量预测主要通过对各种算法加以组合和优化,预测精度不断提高。
新形势下,我国粮食安全面临需求增长与土地劳动力消耗的双重挑战。因此本文提出以差分进化改进灰狼算法优化的BP神经网络模型对粮食产量进行预测[8],该算法具有结构简单、通俗易懂的特点,通过实证对比,验证了该模型预测具有精度高、预测结果稳定性高的优点。
1 数据来源和指标选取
1.1 研究区域概况
本文研究数据来自于《中国统计年鉴》,图1为1981—2021年全国粮食产量时序图[9]。总的来说,1981—2021年间,粮食产量由32000万t上涨到约68000万t,实现了总量上的“翻番”,整体呈现波动中增长的趋势。具体来说,有11个年份较前一年出现了粮食减产的现象。在1985—1997年这段时间,每间隔2a就会出现1次粮食减产,而减产的原因都是受灾面积的猛增。在1999—2003年期间,只有2002年粮食产量较前一年有增加,其余年份都在减少,累计下降超过8000万t,主要原因是粮食播种面积出现大幅度下降[10]。此外,只有2016年、2018年出现小幅度减产现象,原因是机械总动力下降和受灾面积的增加。目前,全国粮食产量呈连续3a增加趋势。
1.2 指标选取与探索性分析
1.2.1 指标选取
为了对粮食产量进行精准有效预测,本文研究了影响全国粮食产量的众多指标及相关数据[9]。结合前人研究从中选取第一产业从业人数、上一年粮食商品零售价格指数等8个指标作为输入变量[11,12],粮食产量作为输出变量。指标选择具体见表1。

表1 粮食产量预测相关指标
1.2.2 数据预处理
由于各指标的单位不全相同,在进行粮食产量预测前,需要进行数据的归一化来消除量纲,本文采用最小—最大规范化:
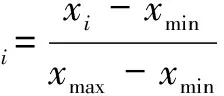
(1)
式中,x′i代表已处理的数据;xi代表待处理的数据;xmax、xmin分别代表指标x的最大值、最小值。
关于指标x2,从中国统计年鉴中只能获取以前一年为基期的粮食零售价格指数,而指标x2要求以1980年的粮食零售价格指数为基期(1980=100),因此需要进行累乘来获取1981—2021年的指标x2数据。数据中2021年的用电量是缺失的,利用时间序列预测的方法对该数据进行了插补,预测结果为9883.6亿kWh。
1.2.3 探索性分析
对插补得到的数据集进行相关系数分析和描述性统计分析,得到表2。

表2 粮食产量影响因素相关性及描述统计表
根据表2可知,x1、x8这2个指标与指标y之间呈负相关关系。指标x1、x8的增大会导致粮食产量的降低。x2、x3、x4、x5、x6、x7这6个指标与指标y之间呈正相关关系,要想增加粮食产量,理论上可以从加大这6个指标的投入入手。其中,导致x7与y之间关联度不高(只有0.52)的原因很明显——可供种粮的土地有限,而粮食产量却发生了翻天覆地的改变。在1981—2021年这41a中粮食产量由32000万t上涨至68000万t,而粮食播种面积却始终在112000千hn2上下小范围内浮动。有学者证明粮食作物播种面积对粮食产量的影响是显著的[13]。由此可见,以上指标的选取还是很可行的。
由各指标的最大值、最小值和区间长度了解到,粮食播种面积的波动范围最小,其区间长度仅为该指标最小值的1/5。农村用电量的波动范围最大,由最初的370亿kWh增加到了9884亿kWh,增长超25倍;涨幅第2大的指标为上一年粮食零售价格指数,涨幅超11倍,由基期的100%增长到了1227%。结合标准差和平均数来看,各指标的变异系数由大到小依次为x4、x2、x5、x6、x8、x1、x3、x7,同样是农村用电量的变异系数最大,达到0.84,说明其离散程度最大;粮食播种面积的变异系数仅为0.04,其离散程度最小。
2 算法介绍
2.1 算法基础
在农业领域上逐渐采用人工智能方法。其中在粮食预测方面,BP神经网络发挥着巨大的作用。
BP神经网络中,假设输入层、隐含层以及输出层节点数依次为l、m、n。隐藏层节点数可由经验式(2)确定,其中p∈[1,10]。
(2)
记输入层、隐藏层、输出层分别为Xi、Yj、Zk;wij表示输入层第i节点到隐藏层中第j节点的权重;wjk表示隐藏层第j节点到输出层中第k节点的权重;bj表示隐藏层中第j节点的阈值;bk表示输出层中第k节点的阈值。信号激活函数用f(x)表示。信息的正向传播可用公式表示如下:
Yj=f(∑wijXi+bj)
(3)
Zk=f(∑wjkYj+bk)
(4)
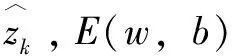
(5)
在BP神经网络中,参数的选取对预测精度影响特大,大量参数的选取也必将导致迭代时间久、效率低,故通常先利用粒子群优化或差分进化等其它智能方法来优化权值和阈值初始值,再进行神经网络建模预测。
2.2 DE-GWO-BP模型的建立
本文建立了差分进化改进灰狼优化的BP神经网络模型。差分进化算法(DE)具有如下特点:结构简单,利于使用;性能优越;自适应性;算法通用;具有利用个体局部信息和群体全局信息指导算法进一步搜索的能力。灰狼优化算法(GWO)脱胎于灰狼捕食猎物的过程,其优点是能够有效避免陷入局部最优。灰狼种群内遵循严格的社会等级制度,可表示为α、β、δ和ω狼。其中α狼为头狼,在种群内有着绝对的领导地位,其位置始终是最优位置,β狼次之,δ狼更次,β、δ狼起辅助决策的作用,ω狼仅服从命令。
然而灰狼优化用来确定最优的权值和阈值中,变异的单位是一头狼(个体),或者是多头狼的线性组合,无法明显体现单个属性的变异,变异的程度不够大。并且也无法体现出α、β、δ狼在领导性上的先后顺序。而差分进化变异的单位(属性)更小,因此借助差分进化算法来对灰狼优化算法进行改进,从而增加了种群多样性,避免早熟状况的出现。实践表明,采用差分进化改进灰狼算法来确定BP神经网络的权重和阈值的最优初始值是可行的,效率更高。
3 实证分析
3.1 参数设置
以1981—2021年中国粮食产量作为输出数据,对应年份的第一产业从业人数、农村用电量等8个指标为输入数据,其中2019—2021年数据作为测试集。本文采用Matlab 2016b软件,DE-GWO-BP模型的参数设定如表3所示。

表3 DE-GWO-BP模型参数
3.2 模型预测
根据DE-GWO-BP神经网络模型对2019—2021年粮食产量进行预测。由于每次预测的精度并不完全相同,因此进行5次仿真实验,见图2。
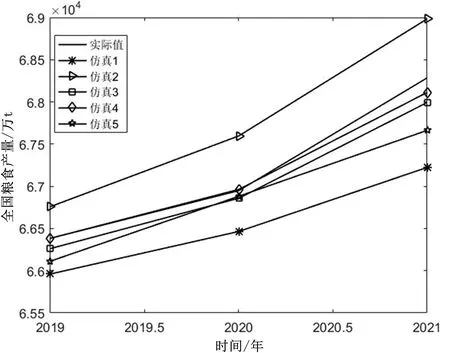
图2 DE-GWO-BP神经网络模型5次预测结果
从图2可以发现,DE-GWO-BP模型5次预测中,仿真3的预测最精准,对2019年、2020年、2021年的预测都是5次仿真的最优值,分别为0.04万t、14.25万t和172.23万t;仿真1和仿真2的预测效果较差,但5次仿真综合来看,该模型预测效果还是很好的。从预测值与实际值的平均绝对误差来看,3a预测结果中2021年的预测效果最差。平均绝对误差为577.16万t,平均相对误差不到1%,预测效果同样不错。
3.3 模型对比
DE-GWO-BP模型与其它模型的预测结果对比,本文选择的对照模型是粒子群PSO-BP、BP模型,见表4,其中PSO-BP、BP模型用到的参数尽可能与DE-GWO-BP模型保持一致。实验结果显示了该模型的优越性。
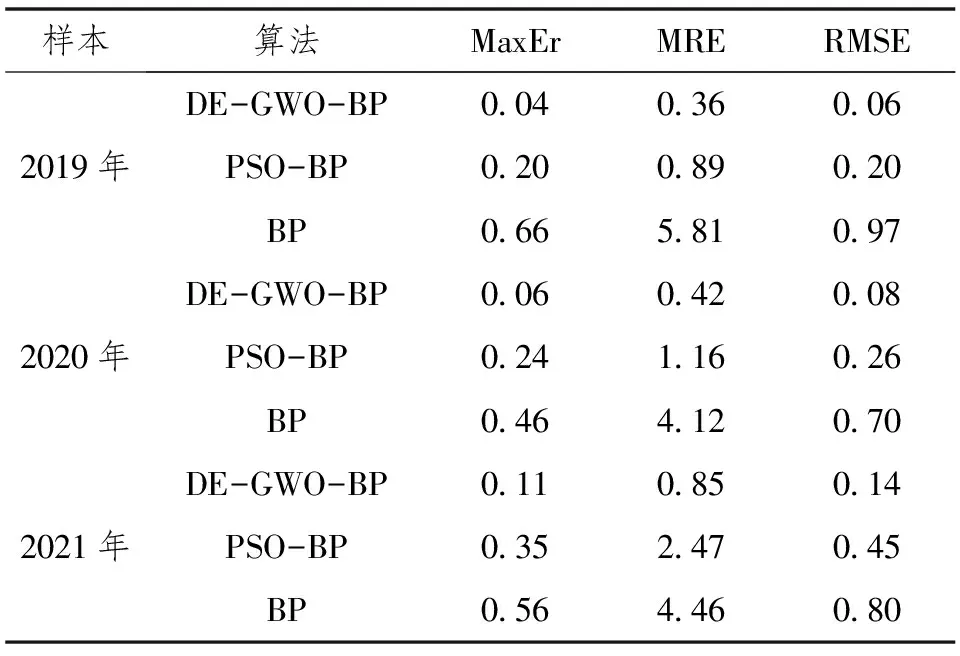
表4 3种模型5次预测结果的均值比较
取5次仿真的最大误差MaxEr(亿t)、平均相对误差MRE(%)和均方根误差RMSE(亿t)作为评价指标[6,7]。从均方根误差RMSE来看,DE-GWO-BP模型的RMSE远小于PSO-BP模型和BP模型。实验表明,GWO-BP模型预测的稳定性最好,多次预测之间的差异最小;从最大误差MaxEr来看,DE-GWO-BP模型的最大误差同样远小于另外两模型,仅为2019年的0.04亿t、2020年的0.06亿t和2021年的0.11亿t,这说明DE-GWO-BP粮食产量预测模型有效地减小了预测误差;从平均相对误差MRE来看,在2019—2021年粮食产量预测中,DE-GWO-BP模型的平均相对误差分别为0.36%、0.42%、0.85%,显著地降低了预测误差,提高了预测精度。综合来看,均方根误差、最大误差和平均相对误差3个指标的结果都体现了DE-GWO-BP模型的优越性。
3.4 模型应用
由于该模型具有较高的预测精度,对2022—2026年全国的粮食产量进行预测。首先根据ARIMA模型对2022—2026年的全国粮食产量及其影响因素进行预测,以获取DE-GWO-BP模型这5a所需数据。
在预测的过程中,始终秉持多次预测取平均以减小误差的原则。利用DE-GWO-BP模型成功预测出了2022—2026年我国的粮食产量,取5次预测平均值作为最后的结果,见表5。

表5 2022—2026年我国粮食产量DE-GWO-BP预测结果
在DE-GWO-BP模型的预测结果中,2022年、2023年粮食产量连续减产,于2024年有了一定的恢复,在2024—2026年连续增产,最终在2026年全国粮食产量达到69679.02万t。预测结果呈现波动结果的原因是利用ARIMA模型获取的未来5a所需数据存在一定的误差,在预测中,指标x1、x5、x8在2022年和2023年上的数值与周围年份存在较大差距,受灾面积和第一产业从业人数有大幅度的增加,而机械总动力出现大幅度降低。
4 结论
粮食产量预测对于国家粮食安全政策制定具有重要的意义。本文通过实际数据,验证了DE-GWO-BP粮食预测模型的优越性。并应用该模型对未来5a(2022—2026年)的全国粮食产量进行预测,得出以下3条结论。
掌握近年我国粮食产量变化规律。通过观察1981—2021年全国粮食产量时间序列图,发现我国粮食产量在41a间整体呈上升趋势,由1981年的32502万t上涨至2021年的68284.75万t,实现了“翻番”。在1999—2003年全国粮食产量出现大幅度下降,累计下降超8000万t。全国粮食产量呈连续3a增加趋势。
构建DE-GWO-BP粮食产量预测新模型。DE-GWO算法提高了BP神经网络算法的全局搜索能力,降低了陷入局部最优的可能性。在2019—2021年粮食产量预测上,DE-GWO-BP模型的预测值与实际值的平均相对误差MRE分别为0.36%、0.42%、0.85%。相对PSO-BP和BP模型,最大误差和平均相对误差的缩小说明了DE-GWO-BP模型的准确性,均方根误差的减小证明了DE-GWO-BP模型的稳定性。总的来说,DE-GWO-BP粮食产量预测模型的准确性和有效性均得到了验证,具有较大应用价值。
短期预测了未来5a的全国粮食产量。利用DE-GWO-BP模型预测2022—2026年的全国粮食产量,分别为67362.16万t、67095.97万t、67886.80万t、68995.71万t和69679.02万t。准确预测我国的粮食产量,可对政府政策制定和计划实施提供一定程度上的数据支持。
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28
电子制作(2019年19期)2019-11-23
小太阳画报(2019年1期)2019-06-11
数学大王·低年级(2018年5期)2018-11-01
快乐语文(2016年15期)2016-11-07
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
信息安全研究(2015年3期)2015-02-28
海军航空大学学报(2015年4期)2015-02-27
读写算(中)(2015年6期)2015-02-27
