
基于语义分割网络的动态场景视觉SLAM 算法
2023-05-08 03:56葛仕全
安徽工业大学学报(自然科学版) 2023年2期
赵 凯 ,李 丹 ,程 星 ,管 玲 ,葛仕全
(安徽工业大学 电气与信息工程学院, 安徽 马鞍山 243032)
即时定位与建图(simultaneous localization and mapping,SLAM)技术作为移动机器人实现真正自主的核心技术之一,在智能移动机器人、无人驾驶等领域发挥着重大的作用[1]。常用的SLAM 系统根据使用传感器的不同,可分为激光SLAM 和视觉SLAM。视觉SLAM 主要依靠摄像机传感器数据,融合计算机视觉、深度学习等技术可更好地解决回环检测、语义场景构建等问题,具有简易便携、硬件成本低且定位精度高的优势,已逐步成为SLAM 研究的主流趋势[2]。传统视觉SLAM 有ORB(oriented fast and rotated brief)-SLAM[3]、DVO(dense visual odometry)-SLAM[4]和VINS(visual-inertial system)-SLAM[5]等,但传统SLAM 框架皆采用静态环境的刚性假设。客观世界中,存在行人、动物、车辆等动态物体的环境是不可避免的,动态物体上的特征点会影响特征匹配结果,致使算法的鲁棒性和定位精度明显下降。
学者们常采用传统机器视觉方法解决动态环境下视觉SLAM 的定位建图问题。Kim 等[6]利用IMU 数据对RGB-D 相机自身运动进行旋转分量的补偿,根据位姿变换后生成空间的运动向量区分图像中的动态特征点;Alcantarilla 等[7]利用连续图像序列估计相机的粗略位姿,使用粗略位姿计算图像中的稠密3D 光流,并根据测量的不确定度计算图像间匹配点的马氏距离并剔除外点;Wang 等[8]对连续图像之间的光流轨迹进行聚类分析,合并拥有相同运动趋势的区域,并假设图像中静态区域占多数,利用面积最大的区域计算出相应的基础矩阵,从而区分动态区域。传统机器视觉方法本身在正确率上存在限制,近年学者们利用卷积神经网络等深度学习方法解决动态环境下的SLAM 定位建图问题。Yang 等[9]利用YOLOv3 进行高动态性的目标分割及移除,在此基础上计算相应基础矩阵判断特征点的真实动态性。以上方法均只能得到先验动态物体的信息,对非先验动态物体的鲁棒性较差。鉴于此,提出一种基于语义分割网络的动态场景下的视觉SLAM 算法,同时构建一个纯静态语义八叉树地图,以期实现复杂动态场景下的精度定位。
1 基于语义分割网络的SLAM 算法
基于ORB-SLAM3[10]在静态环境下良好位姿估计和定位性能,选择ORB-SLAM3 作为主体框架,在原有跟踪线程、局部建图线程、回环检测线程的基础上增加语义建图线程,提出一种动态场景下基于语义分割网络的视觉SLAM 算法,其整体框架如图1。
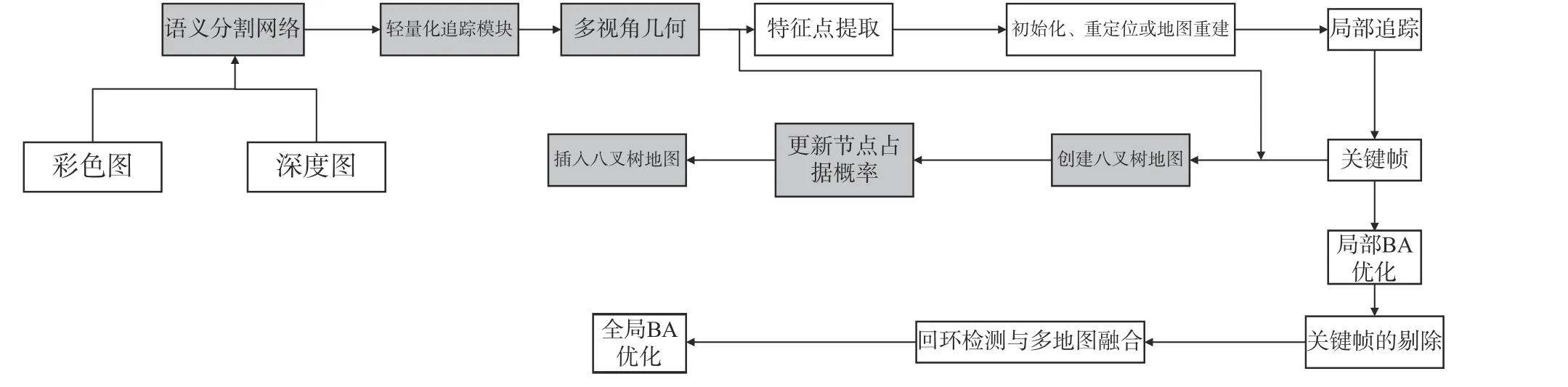
图1 系统框架Fig.1 System framework
图1 中灰色部分为对ORB-SLAM3 的改进部分。利用RGB-D 相机获取RGB 图像和深度图像,RGB 图像经LR-ASPP[11](lite reduced atrous spatial pyramid pooling)语义分割网络处理,获得像素级的语义信息,利用语义信息剔除图像中先验动态物体上的特征点;对于图像上剩余的特征点,通过轻量化追踪模块获得当前帧位姿的粗略估计,该模块只用于估计当前帧位姿,不参与后续建图过程;通过多视角几何算法进一步检测非先验动态物体对应的特征点,对多视角几何的检测结果和语义分割网络的检测结果进行交叉验证,得到完整的动态区域,过滤掉动态区域上的特征点后进入跟踪线程,得到更准确的位姿。如果产生关键帧,语义建图线程会根据关键帧的相关数据构建动态场景下的八叉树地图[12]。
1.1 动态物体剔除算法
语义分割网络可较好地剔除先验动态物体,但对场景中的非先验动态物体区分效果有限,采用多视角几何算法[13]做进一步处理。提出的动态物体剔除算法流程如图2。

图2 动态物体剔除算法流程图Fig.2 Flowchart of dynamic object rejection algorithm
根据关键帧(key frame,KF)之间的运动关系检测动态点,动态点被检测出来后,通过判断是否拥有语义标签将动态点分为拥有语义信息的动态点和没有语义信息的动态点;对拥有语义信息的特征点在语义图上进行语义轮廓搜索,对没有语义信息的动态点在深度图上进行区域生长,充分利用语义信息减少区域生长种子点的数量,提高系统的运行效率;融合没有语义的动态物体掩膜和拥有语义信息的动态物体掩膜,获得完整的动态物体掩膜。
在KF 间运动检测时,需根据当前帧(current frame,CF)从KF 数据库中选取与CF 重叠度最高的若干KF[13]。KF 数据库上限一般设置为20 个,数据库越大,系统初始化越困难,并影响帧查找的速度;重叠KF 的选取数同样会影响系统的运行速度和动态物体检测的准确度。本文实验中,设定KF 数据库上限为20 个、重叠KF 为5 个,作为计算成本和动态物体检测准确性之间的折衷。重叠度的判断标准是KF 与CF 的距离和旋转。多视角几何算法的核心原理如图3[13]。其中x为被挑选出的重叠KF 上的关键点,x在CF 坐标系下的投影为x′,对应的三维点为X,计算x,x′,X之间投影深度lproj和 角度 α。
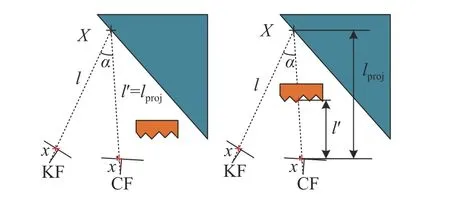
图3 多视角几何检测动态点的原理示意图Fig.3 Schematic diagram of principle of multi-view geometry detection dynamic points
理想情况下,式(1)可根据对极几何关系推理出,x′和x为 特征点的归一化坐标,l′和l为 三维点X在对应帧坐标系下的深度,r为KF 到CF 的旋转矩阵,t为KF 到CF 的平移向量。将式(1)左乘x的反对称矩阵得到式(2),其中 ∧代表反对称矩阵。根据式(2)的左半部分等式求得l,根据右半部分等式求得l′。角度可由式(3)求得。
根据式(2)可求得X的深度信息,从而求得其三维坐标。设p为从KF 相机光心指向X的向量,则可根据式(3)求出 β,同理求出 γ,从而求得 α。实验测试发现,当 α大于某一阈值时,该关键点可能被遮挡,不做处理。α小于角度阈值时,获得CF 中x′关 键点的深度lproj,并将其与深度图投影得到的l′比 较,如果 Δl=lproj-l′超过阈值 τz,即认定其为动态点。经过在TUM 数据集上的实验测试,α= 30°和 τz=0.2 m。
1.2 八叉树建图算法
八叉树地图是通过概率更新地图。存储f来表示节点是否被占据,体素的占据概率可通过反对数变换获得。设f∈R,为概率对数;a为节点被占据的概率为0~1 之间,他们之间的变换可由logit 变换描述:
八叉树地图观测到某节点被“占据”时,f增加,否则f减小。f从-∞到+∞时,a从0 变到1。当某节点被反复观察到时,其f值会不断增加,从而a会不断增加,a超过设定阈值时,该节点就会被判定为占用,并将在八叉树图中可视化。
2 实验与结果分析
使用TUM RGB-D 数据集[14]中关于动态物体的子数据集对本文算法的动态物体剔除、定位和建图效果进行实验评估。TUM RGB-D 数据集的动态物体类子数据集中,数据集sitting 和walking 的8 个序列可代表多数动态环境,对传统的SLAM 系统具有很大挑战性。其中:sitting 序列(下文简称s 序列)属于低动态环境;walking 序列(下文简称w 序列)属于高动态环境。对于2 种类型的序列,相机有4 种运动模式:按照半径1 m的半球轨迹移动(halfSphere);相机沿xyz轴移动(xyz);相机在滚动、俯仰和偏航轴上旋转(rpy);相机手动保持静止(static)。实验均在1 台PC 上进行,CPU 为AMD Ryzen 3700,内存为16 GB,GPU 为RTX 2080,显存为8 GB,依赖于OpenCV 4.3.0,PCL 1.12.0 等第三方库。
2.1 动态物体剔除
采用语义分割网络和本文动态物体剔除算法进行动态物体剔除实验的结果如图4。比较图4(a)(b)可看出:对于w_static 序列中某帧场景,两人正从椅子上起身,并将椅子推入桌下,语义分割网络只分割出人的部分,并未分割出被人移动的椅子;语义分割网络增加多视角几何算法后,椅子也得到了有效分割,因在深度图上进行区域生长的,故椅子的下半部分并未得到有效划分。比较图4(c)(d)可看出:对于w_rpy序列中某帧场景,两人刚进入相机视野中,正准备移动椅子,因人在相机视野中占比过少,语义分割网络未能成功分割出人和被人拖动的椅子;本文算法同样能够分割出被移动的椅子和人的手的部分,进一步证明了本文算法的有效性和鲁棒性。

图4 动态场景下不同算法的动态物体剔除法效果Fig.4 Removal effect of dynamic object with different algorithms in dynamic scenes
2.2 位姿误差估计
利用evo 工具包对ORB-SLAM3 与本文算法在w_half 序列上的位姿估计实验结果进行绘制,如图5,包含整体轨迹、轨迹在xyz坐标轴上和在rpy旋转轴上的分量。其中groundtruth 代表真实轨迹,ORB camera trajectory代表ORB-SLAM3 的轨迹,camera trajectory 代表本文算法的轨迹。分析图5 可看出:ORB-SLAM3 的轨迹与真实轨迹偏差较大,两者不能重合,而本文算法的轨迹与真实轨迹基本保持重合;ORB-SLAM3 的轨迹在x和y轴上的分量在53 s 处出现了波动,这是因为ORB-SLAM3 在移动的人身上提取了大量特征点,导致轨迹与真实轨迹产生位置上的偏差,而本文算法的轨迹在x和y轴上的分量与真实轨迹基本一致;ORB-SLAM3的轨迹在旋转轴上的分量在65 s 产生了剧烈波动,这是因为相机处于旋转状态,人在椅子上并未移动,ORB-SLAM3 在人的格子衫上提取了大量特征点,产生的误匹配点较多,导致旋转分量出现偏差,而本文算法因剔除了动态物体,保持了较好的跟踪效果。
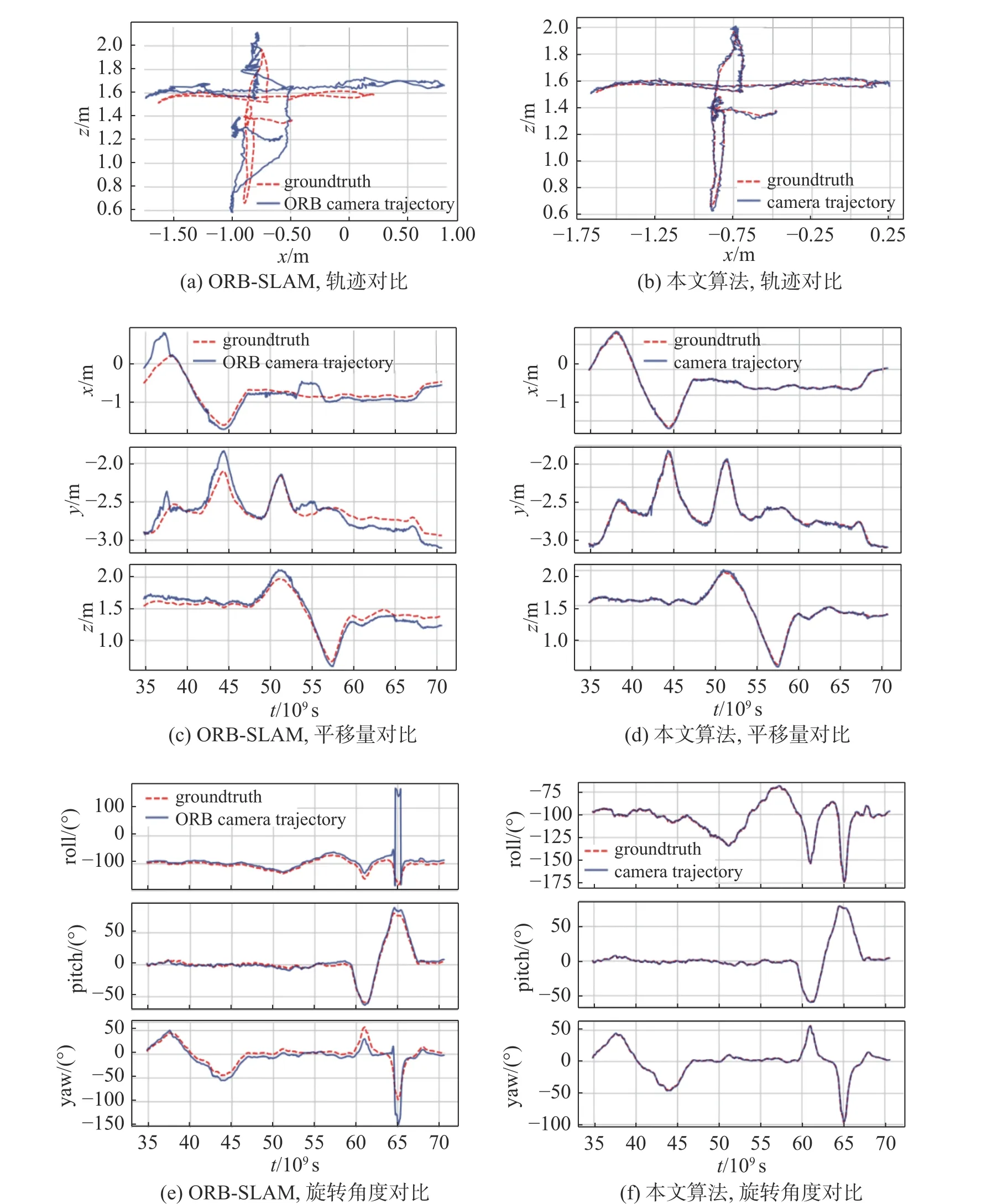
图5 动态场景下ORB-SLAM3 与本文算法的轨迹跟踪结果Fig.5 Track tracking results of ORB-SLAM3 and this algorithm in dynamic scenes
绝对轨迹误差(absolute trajectory error,ATE)为相机位姿的真实值和估计值的差,可直观反映系统精度和轨迹的全局一致性。文中选用ATE 的均方根误差(root mean square error,RMSE)评估算法的定位精度。表1 为ORB-SLAM3 与本文算法的ATE,其中N 代表使用语义分割网络,N+G 代表同时使用语义分割网络和多视角几何算法,加粗部分表示在数据集中表现最好的结果。用相对提升率 ρ评估本文算法(N+G)的提升效果,计算公式为
其中:m为SLAM 算法的测试结果;n为本文算法的测试结果。每次测试均进行5 次,取其结果的平均值为最终测试结果。由表1 可知:本文算法(N+G)无论在低动态还是在高动态的环境中都有卓越表现,在高动态环境下的相对提升率达80%以上,最高为97.16%,体现了本文算法的鲁棒性和稳定性;本文算法在s_rpy序列和s_xyz序列中的表现比ORB-SLAM3 略有下降,因部分图像中的人在图像中所占比重过大,动态区域剔除了较多的特征点,提取到的静态特征点过少,影响位姿估计,但位姿精度仍保持在厘米级。由此表明,使用多视角几何和语义分割网络的效果较好,故后文实验均采取N+G 的模式。

表1 动态场景下本文算法的定位精度提升效果Tab.1 Positioning accuracy improvement effect of this algorithm in dynamic scenes
本文算法与其他动态场景下的DS-SLAM[15],Detect-SLAM[16],DVO-SLAM[4]和MR-SLAM[17]的ATE测试结果如表2。由表2 可看出:本文算法在8 个序列上的位姿估计精度均明显优于其他4 种算法。
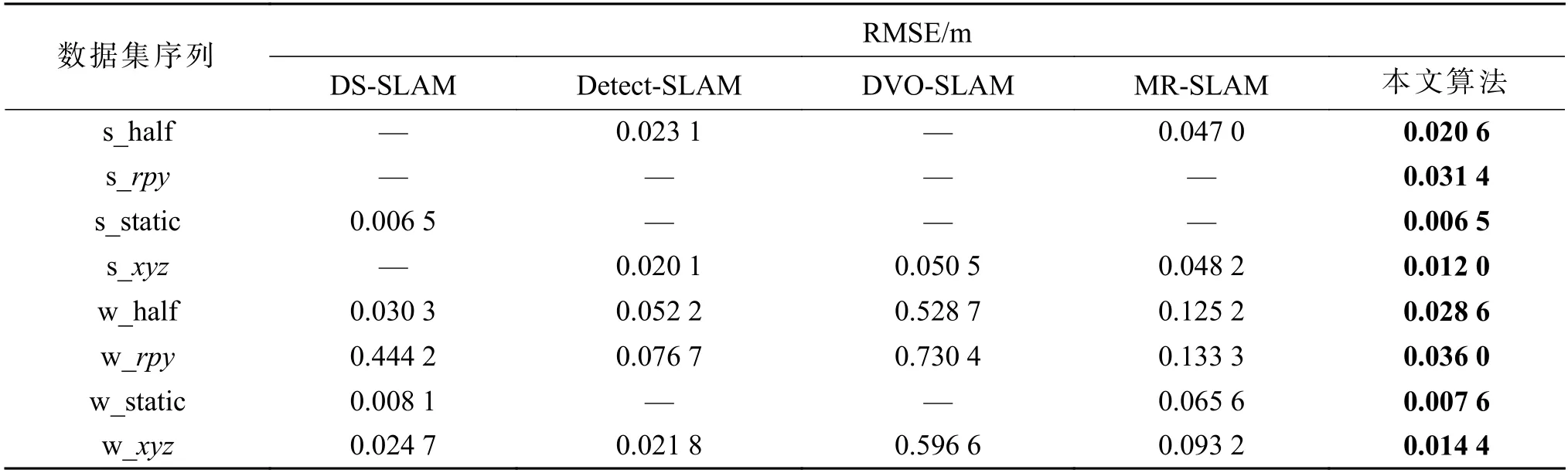
表2 动态场景下不同SLAM 算法的ATE 测试结果Tab.2 ATE test results of different SLAM algorithms in dynamic scenes
2.3 语义八叉树建图
八叉树建图线程通过体素滤波降低点云冗积后构建纯静态环境的语义八叉树地图。图6 为本文算法在s_static 序列的测试结果;图6(a)为数据集拍摄的真实场景;图6(b)为根据s_static 序列生成的语义八叉树地图。对比图6(a)(b)可看出:坐在椅子上人的部分基本被移除,没有因为人一直在场景中移动而出现“鬼影”现象。s_static 序列共707 帧图像,根据图片序列生成的点云地图磁盘文件为55.6 MB;八叉树地图的磁盘文件仅3.1 MB,为点云文件的5.64%,采用八叉树地图可有效对大规模场景进行建图。

图6 语义八叉树建图实验结果Fig.6 Experimental results of semantic octree mapping
2.4 实时性分析
通过各模块运行时间评估算法的实时性,本文算法各模块的平均运行时间如表3。轻量化追踪模块、多视角几何、语义分割网络和特征点提取基本构成SLAM 算法的跟踪线程。语义建图线程与跟踪线程并行,因此不参与计算。由表3 可看出:本文算法各模块的平均跟踪耗时累计130 ms 左右,故本文算法的位姿估计基本满足实时性要求。

表3 本文算法各模块的平均运行时间Tab.3 Average running time of each module of this algorithm
3 结 论
针对室内复杂动态环境,提出一种基于语义分割网络的动态场景视觉SLAM 算法。通过RGB-D 相机采集彩色图像与深度图像,结合轻量化的LR-ASPP 语义分割网络先剔除先验动态物体,再使用多视角几何算法剔除非先验动态物体,得到更准确的位姿估计,最后结合深度图与语义分割网络的语义图,同时构建一个纯静态的语义八叉树地图直接用于导航系统。在TUM 数据集上的验证结果表明:本文算法具有良好的实时性和位姿估计精度;特别是在高动态环境中,依然保持良好的SLAM 定位精度。但本文算法也存在可改进之处,当动态物体在视野中的比重过大时,位姿估计会受到较大的影响,下一步可通过对分割模型进一步优化,使网络能分割更精细的目标区域来解决该问题;多视角几何检测动态物体有滞后性,只有当动态目标移动足够的距离后才会被检测到,可考虑采用概率传播的方式将该帧的动态点向前传播,降低滞后性;同时,在定位过程中没有利用语义信息,下一步可考虑将语义信息用于辅助定位。
猜你喜欢
枣庄学院学报(2022年5期)2022-09-21
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
湖北工业大学学报(2016年5期)2016-02-27
组合机床与自动化加工技术(2014年12期)2014-03-01
机械设计与制造工程(2013年4期)2013-09-12
