
数据稀疏背景下基于协同过滤的推荐算法综述
2023-05-10 16:54朱梦婷
计算机应用文摘·触控 2023年9期
朱梦婷


关键词:推荐系统;协同过滤;数据稀疏;相似度
1引言
随着移动互联网的迅速发展,人们获取大量信息十分便捷。与此同时,如何从海量信息中高效筛选出所需内容变得十分困难。推荐系统能够在用户需求不明确或是信息量过大时,根据用户的行为判断其兴趣,提供个性化的信息以满足用户需求。另外,为提高转化率,推荐系统还能主动将有效信息推送至目标用户。因此,推荐系统既是引导用户获取需要信息的助手,又是公司驱动业务发展的重要动力。
推荐系统最早被应用于电子商务网站,通常是根据用户的订单和评价来推测偏好和需求,从而向用户推荐可能感兴趣的项目。例如亚马逊、淘宝等平台,其中亚马逊网站上约35%的销售额来自个性化推荐,可见推荐系统在电商平台的意义重大。一个好的推荐系统可以提高用户的购买转化率,从而进一步提升企业的收益并增强其用户黏性。近年来,推荐系统在其他领域也有非常广泛的应用,如社交网络、短视频、教育、智慧医疗等。
传统的推荐方法在一定程度上可以有效解决推荐问题,主要有基于内容的推荐、协同过滤的推荐和混合推荐方法。基于内容的推荐主要通过机器学习的方法在内容信息中挖掘用户偏好,不涉及评分数据。而基于协同过滤的推荐核心是计算用户或项目间的相似度,需要用到“用户一项目”评分数据。混合推荐是融合多种推荐技术,充分利用辅助信息,实现优缺点互补。然而,随着数据爆发式增长,推荐系统面临十分严重的数据稀疏问题。具体地,用户通常只对极少部分项目有过交互行为(如浏览,收藏,加车,购买,评价等),这为精确建立用户画像并推荐合适的项目造成巨大困难。例如,电影推荐网站Movielens中“用户一项目”矩阵近95%的数据是缺失的,在电子商务网站Amazon、新闻推荐平台Mind数据中,这种缺失程度更是达到了99.9%以上,这严重影响了推荐的效果[1-3]。因此,如何进一步挖掘用户和项目之间的特征来提升算法准确率变得尤为重要。
下文将对基于协同过滤的推荐算法进行详细的梳理与分析,针对面临的数据稀疏问题,提出解决方法与对策,并预测未来研究的几个发展方向。
2基于协同过滤的推荐
2.1基于内存的协同过滤
基于内存的推荐方法核心是利用“用户一项目”评分矩阵、用户信息和项目信息来计算对象之间的相似度,然后根据相似对象的评分加权值来预测目标用户对特定项目的评分,最后按评分高低进行推荐。按照相似性度量对象,这类算法可分为基于用户和基于项目的推荐:前者主要依据评分情况衡量不同用户间的相似性,进而将相似用户的偏好项目推荐给目标用户,能够发现其潜在的偏好,更能体现社会性;而基于项目的推荐则是依据评分情况衡量项目间的相似性,进而将已知偏好项目的相似项目推荐给目标用户,更能反映自身的兴趣和个性。二者的性能和适用场景对比如表1所列。
基于内存的協同过滤技术的核心是相似度计算,包括常用的余弦相似度、皮尔逊相关系数、欧式距离、杰卡德相关系数等,统一符号后具体如表2所列,可以根据实际场景和数据特点做选择。
2.2基于模型的协同过滤
基于模型的协同过滤推荐主要通过训练数学模型的方式挖掘用户和项目之间的特征和潜在联系,模拟用户的评分行为,从而得到未交互项目的评分并作为推荐依据。模型通常为聚类模型、矩阵分解模型、贝叶斯模型等,其中基于矩阵分解的推荐应用较为广泛[4-6]。
聚类算法是经典的无监督机器学习算法,原理是寻找一种划分,使得类内距离小,并尽可能地相似,同时类间距离尽可能大,以保证差异和区分度。算法过程是先随机指定若干个聚类中心,然后依据对象的欧式距离聚成若干簇,并重新计算每簇对象的均值,将其作为新的聚类中心,不断重复以上步骤,直至聚类中心稳定下来。聚类是相对直接的方法,对象可以是用户、项目,也可以是二者联合,最后还需在聚类结果的基础上进行推荐对象的选择。
矩阵分解是推荐系统协同过滤方法中最常用的模型之一,原理是从“用户一项目”评分矩阵中学习用户潜在信息和项目潜在信息,进而预测未评分部分的分值。目标函数一般形式如下:
贝叶斯模型用于解决分类问题,属于有监督的机器学习,原理是基于条件概率和贝叶斯定理,用决策树表示用户和项目间的概率关系。
2.3推荐过程
协同过滤的推荐过程主要分为三个步骤:第一步,根据定义的度量和已知数据,形成“用户一项目”评分矩阵;第二步,通过协同过滤算法预测未评分数据,补全“用户一项目”评分矩阵:第三步,根据评分做出项目推荐。基于内存的协同过滤可解释性强,易于操作实现,但缺少提取特征的方法,无法得到推荐对象和被推荐对象的潜在信息。相比之下,基于模型的协同过滤可以同时得到这些潜在信息,但解释性相对较弱,也难以处理大规模的推荐。除了这两类推荐方法,还有融合多种方法扬长避短的混合推荐,其克服了普通方法的缺点,但过程较为复杂,难以用显式的数学模型表示。
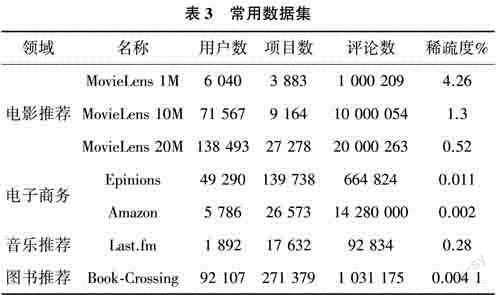
推荐系统常用的数据集涵盖电影、电商、音乐、图书等领域,其中MovieLens是电影评分数据,分为3种大小的数据集,包含用户个人信息和电影信息:Epinions包含商品和匿名用户信息,商品至少被评价过一次;Amazon包含商品数量、价格,用户浏览记录、购买情况等信息;Last. fm是音乐播放数据,包含最受欢迎的歌手列表和播放量;Book-Crossing是图书评分数据。具体规模和稀疏度如表3所列。
3面临的数据稀疏问题
协同过滤的推荐方法仅需依据用户对项目的评分数据,以挖掘用户偏好,其解释性强,操作简便,能够很大程度上解决推荐问题。然而现实场景中,用户和项目并不是固定不变的,各大平台为占领市场份额,会花费大量资金和精力在用户拉新和产品上新上。当有新用户或新项目出现时,数据库中没有相关的历史数据,无从判断用户的偏好,也没法预估项目的交互情况,进而使推荐系统难以做出合理的推荐,这种问题称为冷启动。
另外,当项目数量远大于用户数量时,有大部分的项目未经交互和评价,导致“用户一项目”评分矩阵严重稀疏,为提取用户和项目的潜在特征带来挑战。在信息飞涨的时代,以电子商务为例,随着达人直播带货、短视频引流等新形式的出现,规模不断扩大,用户信息、商家信息、项目信息、交互信息急剧增长,用户间共同评分的项目数量相对不足。在时间分秒游走的同时,指尖滑动产生的数据激增,导致用户与项目间的评分矩阵变得愈发稀疏,推荐效果差强人意。因此,协同过滤的推荐方法面临严峻的数据稀疏问题。
融合多种技术的混合推荐方法虽然可以利用辅助信息(如社交信息)在一定程度上缓解冷启动和数据稀疏问题,但辅助信息形式多样,普适性较差。另外,相似度计算在协同过滤推荐方法中尤为关键,易受数据稀疏的影响,直接影响推荐效果。大多数相似度为两个用户之间的相似性关系赋予相等的值,这意味着和用户之间的相似性。这样刻画的相似度无法区分两个具有不同评级配置文件的用户,即二者交集占各自体量比重差距较大的用户。
4解决方法与对策
为解决冷启动和数据稀疏问题,协同过滤推荐方法有三条路径可以尝试。
(1)补全评分数据。针对多数场景,“用户一评分”矩阵极度稀疏的困境,可以应用数学模型和算法预测缺失值。例如矩阵分解技术,常用于基于模型的协同过滤,核心是将“用户一项目”评分矩阵分解成两个低秩矩阵,一个代表用户潜在信息,另一个代表项目潜在信息,然后根据分解后的两个矩阵乘积做预测。另外,可以将传统协同过滤算法和深度学习的神经网络算法进行结合,以计算分析用户和项目之间隐含的复杂非线性关系。深度学习能够通过训练集学习较为复杂的内在联系,深层次地挖掘推荐对象的特征,并模拟用户评分过程,从而进行更为准确的预测。
(2)添加辅助信息。为提高推荐效果,可以考虑除评分矩阵以外的数据,如用户的详细信息、社交信息、商品的详细信息等。当有新用户日寸,根据性别、年龄等基本信息聚类,将所属聚类的评分平均值作为新用户的评分数据。另外,好友之间兴趣偏好相似的概率较高,来自好友的推荐更精准,也更易获得信任,所以社交关系可以有效辅助推荐效果的提升。
(3)迁移知识学习。由于实际场景有生态化发展的趋势,通常涉及不同领域。例如,美团外卖和本地生活、美团电商等打通,虽然美团电商起步较晚,但用户基数大,可以根据外卖数据和线下团购数据推荐线上商品,这里外卖和本地生活是源域,电商是目标域。因此,可以将多个源域的知识迁移到目标域,以取得更好的效果,解决数据稀疏的问题。
另外,相似度矩阵通常潜藏用户之间的关系,在特征挖掘和兴趣发现中十分关键。为避免对称相似度在一些场景中的局限性和矛盾,可以使用不对称相似度,通过用户之间共同评分项目占各自评分项目的比例将原有计算结果标准化。非对称的用户相似度计算方法,可以区分每一用户对其相似用户的影响和相似用户对该用户的影响。
5未来的研究方向
近年来,推荐系统的深度研究和广泛应用为用户带来了便捷,为企业带来了收益,为行业带来了进步。虽然基于协同过滤的推荐技术已取得不错的效果,但随着其他技术的研究和发展,以及用户体验需求的上升,未来仍有许多方面值得研究。其一,将知识图谱、图神经网络等深度学习技术与推荐系统结合,以符合用户的个性化追求。其二,增强推荐模式的动态性和交互性。在实际生活中,用户的偏好和兴趣会随外部环境改变,如果能考虑环境因素提供实时动态推荐,并给予用户反馈优化的机会,推荐算法会更加精准和智能。其三,数据安全与隐私保护。挖掘用户特征时会用到多维度的信息,用户希望得到准确推荐的同时并不愿意公開隐私。一般通过数据模糊和扭曲来保护隐私,但会降低推荐准确性。因此,兼顾效果和隐私的方法会是众望所归。
6结束语
通过对基于协同过滤的推荐算法的研究,整理常用相似度和数据集,分析基于内存和模型的推荐方法及过程,易见用户或项目间的相似性度量尤为重要,且协同过滤推荐面临着严重的数据稀疏问题和冷启动问题。目前的工作主要是通过模型和深度学习算法补全评分数据,添加社交关系等辅助信息,迁移学习其他领域的知识到目标领域,定义非对称的相似性度量等提升推荐效果。未来可以在多技术结合、增强推荐的动态性和交互性、兼顾效果和隐私保护方面进行更深入的研究。
猜你喜欢
计算机应用(2016年12期)2017-01-13
中国新通信(2016年22期)2017-01-13
计算技术与自动化(2016年4期)2017-01-11
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
电脑知识与技术(2016年25期)2016-11-16
