
基于跨尺度图对比学习的人体骨架动作识别方法
2023-05-13 11:39张雪莲徐增敏陈家昆王露露
燕山大学学报 2023年2期
张雪莲,徐增敏,3,∗,陈家昆,王露露
(1.桂林电子科技大学 数学与计算科学学院,广西 桂林 541004;2.桂林电子科技大学 广西高校数据分析与计算重点实验室,广西 桂林 541004;3.桂林安维科技有限公司,广西 桂林 541010)
0 引言
人体动作识别是目前计算机视觉领域非常热门的研究方向,它主要从视频片段中分辨不同类的动作,然后对视频的多帧图像进行处理,并利用全连接层来获得最终的分类结果[1]。作为该领域的研究热点,动作识别在视频监控、人体交互、视频理解等领域[2-3]发挥重要作用。
在过去的工作中,许多基于RGB 视频的动作识别技术已经取得了显著成果,但在提取RGB 视频数据时,其易受到遮挡、环境变化与阴影干扰,导致深度图中颜色和纹理特征容易缺失,且处理起来相对耗时。另一种模态数据,人体骨架数据集,利用骨骼关节点的三维坐标来表示人体,实现了一种更加轻量级的表示方法,且骨架数据对于视角变换、人物外貌以及环境变化具有较强的鲁棒性。因此,近年来,基于骨架数据的人体动作识别方法得到了广泛关注,Yan 等人[4]提出一种时空图卷积网络模型(ST-GCN),更好地表述了人体骨骼关节之间的依赖关系;Lei 等人[5]提出了一种双流自适应图卷积网络(2S-AGCN),更加合理地构建了邻接矩阵策略,增强了网络对空间特征的抽取能力;Liu 等人[6]提出了一种多尺度时空聚合方案(MS-G3D),有效地解决有偏加权问题。以上构建的模型虽然取得了较好的识别效果,但都属于全监督学习框架,需要依赖大量人工标注数据,而标注数据是繁琐且昂贵的。
针对以上问题,自监督学习被广泛应用,其无需标注训练样本,可以通过数据增强方法低成本扩充数据集,凭借这一优势,越来越多的研究人员将目光投入到自监督模型构建中。其中,Lin 等人[7]提出一种基于骨架的自监督动作识别方法,可以使编码器学习更多的鉴别特性,解决从单个重建任务中学习骨架表示的过拟合问题;Zheng 等人[8]通过结合编码器,解码器和生成式对抗网络,重新构建了被掩码的3D 骨架序列;Yang 等人[9]设计了一种骨骼云着色技术,将从未标记的骨架序列中学习到的特征表示用于骨架动作识别的自监督表示方法中。然而,以上基于骨架数据的自监督模型,利用对比学习方法进行建模,没有考虑骨架数据是一种离散数据结构,需要进行图结构学习,且利用数据增强获取正样本的想法过于单一,较少将跨尺度信息联合方法应用到自监督模型中,难以克服单一尺度特征信息不足的缺陷,不利于模型聚类效果。
鉴于此,本文提出基于图对比学习与跨尺度一致性知识挖掘的自监督动作识别方法。所提方法首先结合多种数据增强理论,以获得无标签骨架序列的不同视图,并对不同视图进行编码,建立图对比学习网络;其次将原始骨架序列转化为多尺度骨架图序列,结合跨尺度一致性知识挖掘模块,构建基于骨架的跨尺度图对比学习网络;最后将多尺度骨架图序列输入到所构建的网络模型中,通过个体多尺度映射间的协同关联模式,实现单尺度内关联及多尺度间语义协同交互。
基于以上所述,本文所作贡献可简述如下:
1)为解决传统方法在扩增骨架数据过程中,存在泛化性不足和传递性不强的问题,融合图数据增强思想,建立图对比自监督动作识别网络。
2)引入多尺度图来建模三维骨骼特征表示,聚集骨骼关节点的关键相关特征,结合跨尺度一致性知识挖掘方法,实现多尺度信息间的交互。
3)结合图对比自监督动作识别网络和跨尺度一致性知识挖掘方法,提出一种新的模型框架,并基于线性评估协议对模型效果进行评估。
1 相关工作
1.1 基于骨架的监督动作识别方法
基于骨架的监督动作识别方法旨在从一系列时间连续及有标签的人体骨架序列中识别正在执行的动作[10]。早期人体骨架动作识别算法大多是基于手工特征。近年来,随着机器学习与深度学习的发展,人们将其与骨架序列联系起来,提出许多基于循环神经网络[11-12]的方法,虽然有效地利用了骨架序列的时序信息,但考虑到循环神经网络存在梯度消失等问题,研究者们逐渐将目光转移到卷积神经网络[13-14]上,其可以从不同时间区间内提取到骨架特征的特定局部模式,然而鉴于该网络需要将骨架序列转换成特定的RGB 图像形式,不利于骨架数据的特征表达,人们又提出了图卷积神经网络[4,15],通过建模骨架数据的自身图结构,进而实现基于骨骼点的动作识别任务。本文受前人启发,采用基于图卷积网络方法,将STGCN[4]作为提取骨架特征的主要组成网络。
1.2 基于自监督对比学习的动作识别方法
对比学习方法着重于学习同类实例之间的共同之处,区分非同类之间的不同之处[16]。最近,研究人员提出许多基于生成实例的自监督对比学习方法[17-20]。其中,MoCo[17]模型建立一个动态字典,用动量对比的学习方法做自监督的表征学习任务,SimCLR[18]模型通过去除存储库(memory bank),简化了MoCo[17]模型提出的自监督对比学习算法,SimSiam[19]模型通过最大化同一样本不同视图间的相似度,来解决自监督对比学习中出现崩溃解(collapsing solutions)的问题。与本文相似的工作CoCLR[20]模型是基于RGB 视频数据与光流数据进行的跨模态自监督行为识别,相对骨架数据,提取RGB 视频数据与光流数据需要较长的时间,往往导致其复杂度过高。
1.3 基于骨架的自监督动作识别方法
自监督学习是指从大规模未标记数据中学习自身语义信息,为模型及算法提供监督信息。研究人员探索各种模型构建策略,如拼图[21-22]、着色[23]、预测和修复掩码词[24-26]等。相比图像和RGB 视频,基于骨架数据的用于人体动作识别的自监督学习仍然是一个较新的、值得被关注的问题。其中,MS2L[7]模型提出一种基于骨架序列表示的多任务自监督学习方法,可以同时解决多个辅助任务,例如运动预测和骨架拼图等,ASCAL[27]模型利用未标记骨架序列的不同扩增视图,以自监督对比学习的方式来学习动作表示,AimCLR[28]模型探索极端数据增强带来的不同运动模式,缓解正样本选取的不合理性。以上工作积极探索基于3D 骨骼的自监督学习方法,并从无标记骨架数据中学习到有效的动作表示。
1.4 多尺度骨架图
文献[29-30]通过构建不同骨架视图,例如:关节、运动、骨骼等,利用不同视图间的特征相似性,学习丰富的内部监督信息,并将其作为描述身体结构和运动的判别特征。然而,在建立不同骨架视图过程中,往往只从骨架的单一尺度空间中提取这些特征,这将限制从不同身体分区中捕获高层结构信息的能力。例如CrosSCLR[31]模型是基于骨架的跨视图对比学习,DMGNN[32]模型从单一空间尺度和拓扑结构的骨架中提取特征,PoseGait[33]模型将人体关节运动轨迹和预定义的姿态描述符编码为特征向量。本文是在SMSGE[34]模型的启发下,充分挖掘了身体组成部分中潜在的结构特征,利用一种跨尺度一致性知识挖掘的方法来表达不同层次的骨架结构信息,并结合协同训练,构建跨尺度图对比学习网络模型。
2 跨尺度图对比学习
虽然3D 骨架数据在动作识别领域起着至关重要的作用,但在自监督骨架表示方面尚未得到长足发展。数据增强作为对比学习的先决条件,影响着网络模型的最终拟合效果,如何构建适合骨架数据的扩增方法成为本章的研究重点。骨架图是由一系列的骨骼关节点相连组成,通过改变骨架图结构,可以更好地学习骨架的高级语义信息,且包含骨架信息的多尺度图较易获取。因此,本章利用图对比学习方法与多尺度特征间的语义相关性,结合协同训练,构建基于骨架动作表示的跨尺度图对比学习框架。本文主要包括两个关键模块:1)SGCLR:一个用于单尺度自监督学习表示的图对比学习框架(Graph Contrastive Learning for Skeleton-based action Representation,SGCLR);2)CrosScale-SGCLR:该算法将一个尺度的特征信息传递给另一个尺度,通过引入互补的伪标签约束,促进多尺度特征间的信息共享(Cross-Scale Graph Contrastive Learning framework for Skeletonbased action Representation,CrosScale-SGCLR)。
2.1 SGCLR 算法
给定一个包含l帧连续的3D 骨架序列X=(X1,…,Xl),其中Xi∈RW×J×D,W为人的总数,J为骨骼关节点数,D为位置向量维度(Xi的位置向量维度为3)。训练集包含了从多个视图和多个人中采集的B种不同动作的骨架序列。每个骨架序列Xi对应一个标签yi,其中yi∈表示第i种动作类别,c表示动作类别的总个数,每次输入网络中的样本数据批量大小(batch size)为N。不同于SkeletonCLR[31]模型利用对比学习建模的方法,本节方法虽然同样使用了该方法的基本组成框架来构建网络模型,但在此基础上融合了图对比学习方法,在数据扩增上进行了相应改进,使得同一样本扩增后得到的两个实例具有不同的邻接矩阵。
2.1.1 图对比学习
本文在GraphCL[35]与SimGRACE[36]模型的启发下,为解决传统基于对比学习的动作识别算法在扩增骨架数据过程中,存在泛化性不足和传递性不强的问题,融合图数据增强思想,提出一种基于图对比学习的人体骨架动作识别算法。该算法基于人体骨架数据自身的图结构关系,分别在双路径中处理输入骨架序列,即原路径与图对比路径,两条路径使用相同的自编码图卷积神经网络,将人体骨架数据的不同数据增强得到的实例作为正样本,将存储库中的其他人体骨架序列视为负样本。在每次训练过程中,构成负样本的张量坚持先进先出原则,不断更新存储库中的批量嵌入信息,并利用图对比损失函数训练模型参数,以拉近正样本的距离,远离负样本的距离。SGCLR 的总体架构如图1所示。

图1 单尺度SGCLR 的算法结构图Fig.1 Architecture of single-scale SGCLR
2.1.2 算法的实现
2.1.1 节介绍了本节中所提方法的原理和结构,主要步骤如下所示:
1)获取3D 骨架序列X,该张量维度为[N,D,l,J,W],为避免数据冗余和降低计算复杂度,在人体骨架数据集中,统一将骨架序列的连续帧数l取为50,批量大小N=128,位置向量维度D=3,骨骼关节点数J=25,人的总数W=2。
2)利用数据增强模块τ和τ+mask_edg来获取不同实例Q与K,使其作为正样本集,主要步骤如下所示:
① 在步骤1)获得无标签骨架数据的基础上,分别在原路径与图对比路经上引入剪切(shear)与时序裁剪(temporal crop)的数据增强方法,以得到不同视图Q和,具体方法概述如下。
剪切:剪切变换是通过构建相应的仿射矩阵,使人体关节的三维坐标形状呈任意角度倾斜。仿射矩阵的公式为
时序裁剪是在时间维度上的数据增强,它将一些帧对称地填充到序列中,然后随机地将其裁剪到原始长度。填充长度定义为l/r,r为填充比(取值为正整数)。
② 接下来对视图进行随机边裁剪(mask_edg),得到不同的图表示向量K。具体思想:利用随机掩码[0~ξ],去掉关节点间的连接边,形成新的骨架图结构。
3)将不同实例Q与K分别嵌入到编码器fθ和中,得到编码特征h与,其中θ与为两个编码器所需参数,遵循动量更新:(1-α)θ,α为动量系数,SGCLR 使用ST-GCN[4]作为编码器网络。
4)将得到的编码特征h与分别输入到投影层g和中,获得较低维空间向量:z=g(h),,其中。投影层是由一个全连接(FC)层与线性(ReLU)层组成。
6)在图对比学习过程中,当一个骨架序列以不同实例输入到两条不同的路径中时,其输出的特征是相似的,本文将InfoNCE 损失函数作为图对比学习的损失函数,公式如下:
式中,Mi∈M为存储库中的负样本集,t是超参数,z·表示两个向量的点积,其结果表明两个实例间的相似程度,其中z与已被归一化。
在图对比损失LSGCLR的约束下,对自监督网络模型进行训练,以区分训练集中的每个样本实例,最后通过线性评估方法验证该模型的有效性。SGCLR 方法的伪代码如算法1所示。

2.2 CrosScale-SGCLR 算法
鉴于人体的运动主要是通过骨骼围绕各个关节进行旋转而实现,可以根据骨骼关节点的分布,将人体分割成粗细粒度不同的功能部件[34]。本文将人体关节点作为基本构件,将空间上相邻的关节点进行组合,形成不同尺度的骨架图,并基于各尺度间具有语义信息互补的特性,提出跨尺度一致性知识挖掘方法,利用一个尺度图中特征信息的相似性,来促进另一个尺度图中相似特征进行有效聚类。相比于CrosSCLR[31]方法,本文在不使用骨架视图(motion,bone)的情况下,通过构建多尺度骨架图来实现不同尺度间的信息融合,也可以很好地学习到不同图结构丰富的内部监督信息。
2.2.1 构建多尺度图
如图2所示,首先,给定一个包含l帧的骨架序列X,将其称为关节点尺度(即身体关节作为节点),记作Θ1。其次,构建粗粒度比例图,将运动者的骨架结构分为10 个部分(包括躯干、头、右臂上、右臂下、左臂上、左臂下、右腿上、右腿下、左腿上和左腿下)和5 个部分(包括躯干、右上肢、左上肢、右下肢和左下肢),并将每部分所包含的骨骼关节点进行位置坐标平均,合并为新的骨骼关节点,将其命名为粗关节点尺度(即身体部分作为关节节点),记作Θ2和Θ3。最后,基于以上操作,得到不同尺度的骨架图Θm(Vm,εm)(m∈{1,2,3}),其中{1,2,…,nm})表示不同骨架尺度图对应的关节点集合,表示不同骨架尺度图边结构关系集合,nm是第m个尺度图Θm的关节点数。鉴于骨架的多尺度数据是由合并关节点所组成,导致图结构发生改变,不能直接输入到上文所建立的SGCLR 模块中,为此,本文将针对不同尺度骨架图构建相应图结构,并将其命名为multi-scale SGCLR(SGCLR(25),SGCLR(10),SGCLR(5))。在之后的实验中,将选取关节点数为25 和10 的多尺度骨架图Θ1与Θ2作为主要研究对象。
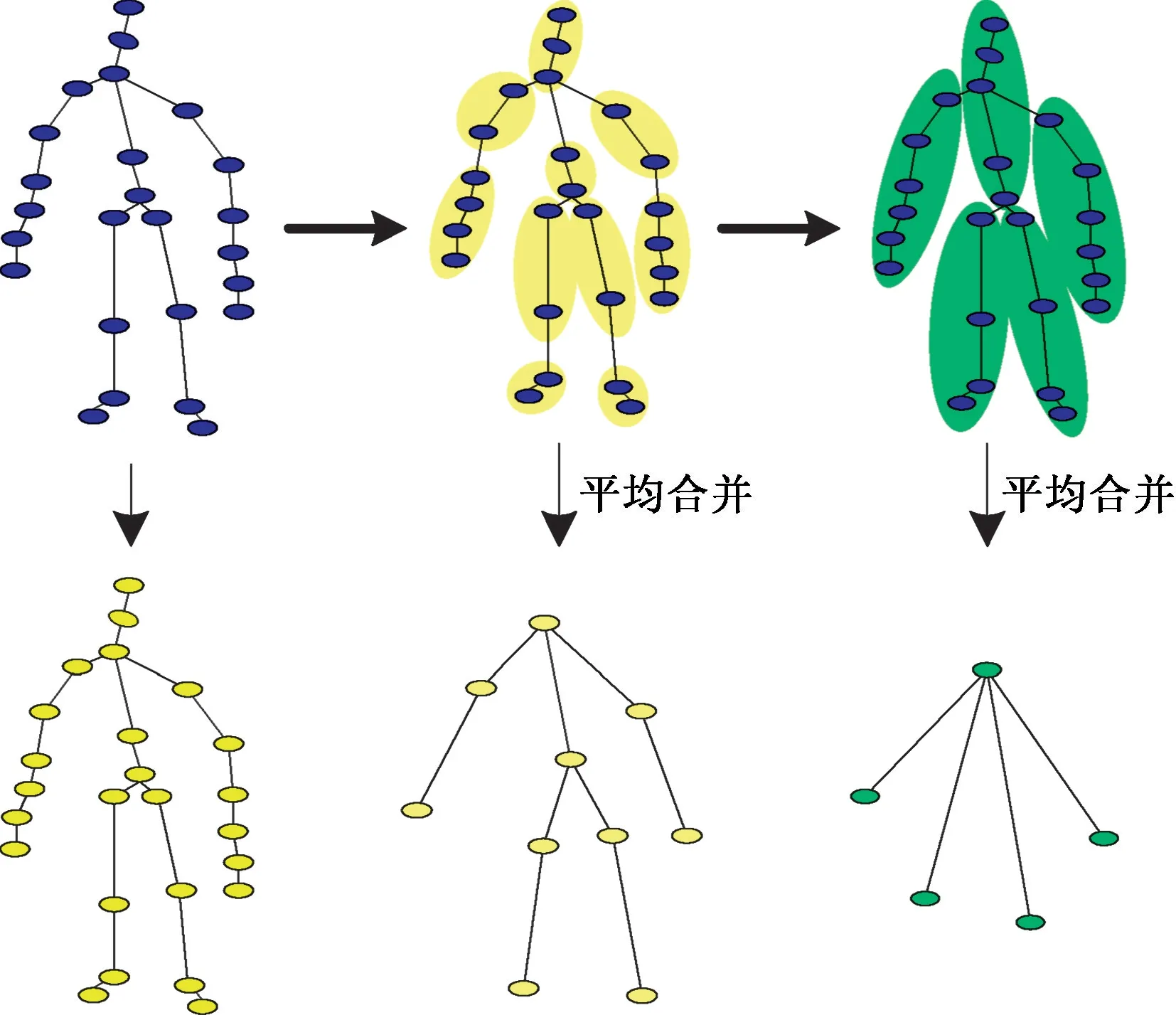
图2 多尺度骨架结构图Fig.2 Multi-scale skeleton structure
2.2.2 跨尺度图对比学习网络
本节为了可以从骨架数据的不同尺度图中获取语义互补信息,协助网络从相似的负样本中挖掘出更多的正样本,拟结合多尺度骨架图数据,提出跨尺度图对比学习网络,该网络模型不仅可以从互补尺度图中挖掘出高置信度的正样本,而且使嵌入的上下文在多个尺度图中保持一致。具体模型框架如图3所示。

图3 跨尺度CrosScale-SGCLR 的算法结构图Fig.3 Architecture of cross-scale CrosScale-SGCLR
作为前一种方法的扩展,在图对比学习网络训练结束后,再进行跨尺度图对比学习,以获得更强的学习表征能力,避免网络从头开始训练时的错误分类。具体来看,给定一个骨架序列X,需要得到两种不同的尺度图,在本文中Θ1和Θ2分别是由25 个和10 个骨骼关节点组成的不同尺度骨架图,分别表示对应尺度下的骨架序列,CrosScale-SGCLR 表示学习的目的是学习具有较好泛化性的,其中是Θ1和Θ2的特征表示,可以有效地执行各种下游任务。其主要思想与SGCLR 方法不同之处在于需要重新构建的正样本集和负样本集,即在Θ1尺度中很难发现的正样本,可以在Θ2中发现。将多尺度数据Θm(Vm,εm)(m∈ {1,2})输入到multi-scale SGCLR网络中,通过两个不同图结构的SGCLR 模块获得图编码特征zΘm,以及相应的存储库,随着训练的进行,逐渐增强模型的表示学习能力。
最后利用对比损失函数进行参数更新,主要介绍尺度Θ1(V1,ε1)与Θ2(V2,ε2)之间的损失函数公式,具体如下:
其中,t是超参数,为存储库中的负样本集,分子包含1+k个正样本,分母包含1+k个正样本和N-k个负样本在内的共N+1 个样本,k是相似样本特征嵌入的索引,由topk(·)函数进行选取,实验中k值取为1。
同样地,在Θ1尺度特征空间中相似的实例也可以作为伪标签,帮助Θ2尺度下的网络进行更好地表征学习。其损失函数如下:
其参数意义与公式(3)相同,两个网络互相为对方采样正样本,以增强网络模型性能并获得更好聚类效果。
将公式(3)与公式(4)联立求和并取平均,即得到CrosScale-SGCLR 方法的总损失函数,具体操作如下:
多尺度损失函数LCrosScale-SGCLR与单尺度损失函数LSGCLR相比,拉近了更多的高置信度正样本,使特征空间中同类样本特征更加容易聚合。
3 实验
3.1 实验数据集
NTU RGB+D 60[37]由56 880 个动作序列组成,是目前基于骨架动作识别研究中应用最广泛的数据集。该数据集由3 个Microsoft Kinect v2 摄像头从不同的视角捕获,动作样本由40 名演员执行,包含60 种动作分类,其中40 类为日常行为动作,9 类为与健康相关的动作,11 类为双人交互动作。本文采用该数据集的两种评价基准:1)Cross-Subject(xsub)基准,即训练数据来自20 名演员,测试数据来自其他20 名演员;2)Cross-View(xview)基准,其中训练数据来自摄像机视图2 和3,测试数据来自摄像机视图1。
NTU RGB+D 120[38]为NTU RGB+D 60 数据集的扩展,该数据集包含来自106 个演员执行的120种动作,相机的摆放位置由17 个增加到32 个,动作骨架序列总数扩充到114 480。同样,本文采用该数据集的两种评价基准:Cross-Subject(xsub)和Cross-Setup(xset)。在xsub 基准中,身份标识为1、2、4、5、8、9、13、14、15、16、17、18、19、25、27、28、31、34、35、38 等演员所做出的动作用作训练,其余的用于测试。在xset 基准中,训练数据和验证数据分别由身份标识数字的奇偶进行确定。
3.2 实验设置
本文实验所用的硬件平台包括运行内存128 GB 的4 块TITAN XP 显卡,软件平台包括Python 3.6 和PyTorch 1.2.0 框架。使用的参数配置与文献[31]保持一致,编码器fθ和主要使用STGCN[4]网络,隐藏层维度为256,特征维度为128,fθ采用随机梯度下降法更新参数,采用动量更新,动量系数α取值为0.999,剪切常数β取值为0.5,填充率r取值为6,超参数τ取值为0.07,ξ取值为2,随机边裁剪的个数范围在[0,2]之间,训练过程中,将批量大小设为128,存储库中负样本个数M= 32 768,迭代次数设置为250,权重系数为0.000 1,每个模型均运行300 epochs,其学习率初值为0.1,在训练了250 epochs 之后变为0.01,线性评估均运行100 epochs,其学习率初值为0.3,在评估了80 epochs 之后变为0.03。
3.3 实验结果分析
本文的图对比学习网络基于SkeletonCLR[31]模型,在该网络模型的对比路径上加入了图增强方法,并使用ST-GCN[4]模型作为主干网络,在每个编码器后附加一个投影层以产生固定大小为128 维的特征向量。在计算对比损失之前,对嵌入图进行归一化处理。由于随机边裁剪的范围在[0,2]之间,当选到0 条边裁剪时,其精度将会与原模型保持一致。
3.3.1 定量结果分析
如表1所示,将本文方法与其他基于骨架数据的自监督学习方面的工作进行了比较,主要对比了LongT GAN[8]、MS2L[7]、P&C[39]、AS-CAL[27]与SkeletonCLR[31],SGCLR 在NTU RGB+D 60 数据集上的xsub 与xview 两个评价基准上的精度分别是71.5%和76.5%。相比于SkeletonCLR[31],分别提升了3.2%与0.1%的精度,且CrosView-SGCLR 在跨视图(joint+motion)上取得了70.4%与77.9%的精度。除此之外,本文基于图对比学习网络和不同尺度特征间的互补性,构建了跨尺度(joint25+joint10)协同训练网络模型,即CrosScale-SGCLR,其精度分别达到了70.3%和75.2%。

表1 NTU RGB+D 60 数据集上的实验精度对比Tab.1 Comparison of accuracy on NTU RGB+D 60 dataset %
为了更好证明本文所提方法的有效性,同样在NTU RGB+D 120 数据集上也做了相应的比较。如表2所示,SGCLR 网络模型在NTU RGB+D 120数据集的xsub 和xset 上分别达到了57.6%和54.6%的精度。CrosView-SGCLR 在跨视图(joint+motion)上取得了60.1%与62.2%的精度,在跨尺度图(joint25+joint10)上取得59.0%与63.6%的精度。结果表明随机边裁剪的图增强方法对人体骨架的图结构搭建起到促进作用,该方法在xset评价基准上性能改善较为明显;跨尺度图对比学习网络,在不使用骨架视图(motion,bone)情况下,利用多尺度间的协同训练方法,也可以达到较好的识别效果。
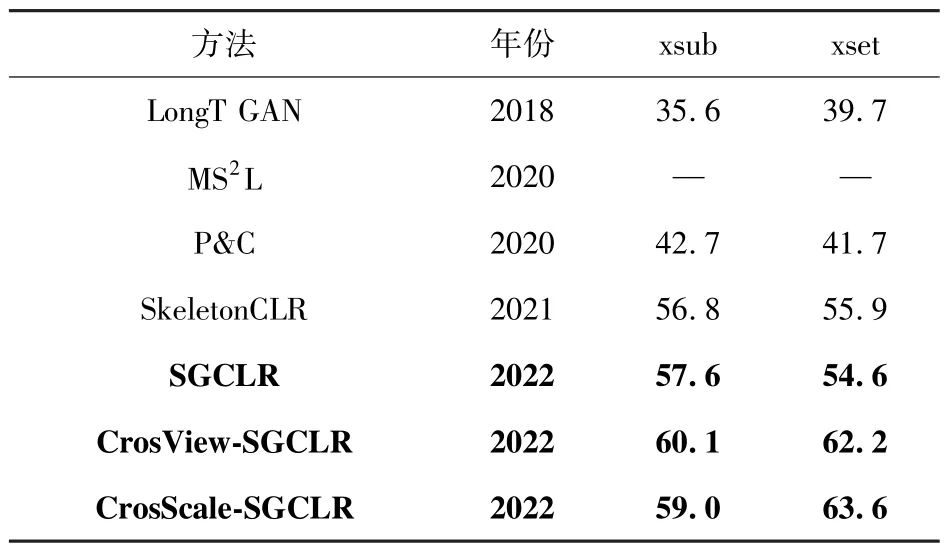
表2 NTU RGB+D 120 数据集上的实验精度对比Tab.2 Comparison of accuracy on NTU RGB+D 120 dataset %
3.3.2 定性结果分析
本文利用t-SNE[40]降维算法,可视化预训练了300 epochs 后的SkeletonCLR[31]、SGCLR、CrosView-SGCLR 和CrosScale-SGCLR 的嵌入分布。如图4所示,从NTU RGB+D 60 的xsub 数据集中选取10类样本进行嵌入比较,可以得出与表1 相似的结论。与SkeletonCLR[31]相比,本文所提方法可以更加紧凑的聚合相同类别的嵌入特征,分离不同类别的嵌入特征,具有更好的识别能力。

图5 t-SNE 可视化不同模型嵌入特征的结果对比图Fig.5 Comparison of the results of the t-SNE visualization of different model embedding features
3.3.3 结果分析
通过上述实验,可以得出以下结论:利用骨架数据间存在的紧密关联,融合图对比学习思想,改变原有模型的数据增强方法,不仅可以增强同一骨架序列不同视图间的语义相关性表达,而且可以学习到骨架图的高级语义信息;利用跨尺度一致性知识挖掘方法,从未标记骨架序列中获得人员动作识别的有效表示,为不同数据尺度中传递特定行为语义,捕捉更丰富的尺度信息,弥补单一尺度特征难以准确表达复杂的人体动作。两个模型各有优势,同时也具有极强的互补关系,这也再次证明了本文所构建模型的有效性。
3.4 消融实验结果分析
本节所有实验均在NTU RGB+D 数据集上进行,该数据集可以分为以下四个基准,分别是xsub60、xview60、xsub120 和xset120,测试实验遵循线性评估协议,在消融实验参数选取上参考模型AimCLR[28]与SkeletonCLR[31]。
3.4.1 验证原数据增强τ 有效性
数据增强可以学习到相同实例不同的表示状态,对图对比学习方法起着至关重要的作用。本文利用剪切与时序裁剪的方法对骨架数据进行扩增,通过改变参数β与r的值,在模型SGCLR 上进行相应实验,结果如表3所示,在四种基准数据集中,当β=0.5,r= 8 时,测试结果的平均精度达到了最大值,由此说明数据增强τ的有效性以及不同数据增强强度对图对比学习方法的影响程度。由于本文模型构建基于SkeletonCLR[31],因此在参数选取上应与其保持一致,选取β=0.5,r=6。

表3 不同参数β 与r 对网络性能的影响Tab.3 The impact of different parameters β and r on network performance%
3.4.2 验证所提数据增强mask_edg 有效性
由于超参数ξ决定了边裁剪的数量范围,影响着骨架图结构表示学习。为了验证边裁剪数据增强方法的有效性,本文做了相应的消融实验。如表4所示,将ξ分别取值为2、3、4、5、10 和15。可以看出,当ξ=2 时,模型的平均精度达到了最大值。然而,较大的ξ会降低所构建模型的性能,因为裁剪较多的边会导致邻接矩阵变成稀疏矩阵,不利于图结构的特征表达,致使自监督网络模型的错误分类。

表4 不同参数ξ 对网络性能的影响Tab.4 The impact of different parameters ξ on network performance %
3.4.3 验证所提图对比学习有效性
为了验证自监督模型在加入图对比学习(GCL)方法时,识别效果会有不同程度的提升。本文选用SGCL(单尺度)以及CrosScale-SGCLR(跨尺度)为基准模型,对比了加入GCL 和去除GCL 的网络模型识别效果,将其记作SGCLR†与CrosScale-SGCLR†。如表5所示,分别在NTU RGB+D 60 与NTU RGB+D 120 两个数据集上进行验证,得到相应结论:加入图数据增强方法之后,可以学习到骨架序列潜在的高级语义信息,增强同一样本不同视图的语义相关性表达,所以在不同基准下测试该模型,总体上加入了图对比学习要优于没加图对比学习的识别效果。

表5 模型SGCLR 和CrosScale-SGCLR 消融实验测试结果Tab.5 Ablation experimental test results on the model SGCLR and CrosScale-SGCLR%
4 结论
本文提出一种用于人体骨架动作识别的跨尺度图对比学习网络模型,通过聚合相关骨骼关节点,结合跨尺度感知一致性,构建出多个尺度的骨架图,摆脱了传统方法在扩增骨架数据过程中,存在泛化性不足和传递性不强的问题,增强了高级语义信息的表达,提高了最近邻挖掘策略,使学习过程更加合理。为了验证该方法的有效性,分别在公开的人体骨架动作识别数据集NTU RGB+D 60 和NTU RGB+D 120 上进行了大量实验,结果表明,本文所提方法的识别效果均比文中所涉及的其他方法有一定的提高。在以后的工作中,将继续研究基于多尺度骨架图序列的自监督动作识别方法,以实现利用更加轻量的网络模型达到更高的识别精度这一目标。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
中国新技术新产品(2020年5期)2020-05-06
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
中国煤层气(2014年3期)2014-08-07
