
基于DN-LSSVM模型的危险气体定量识别
2023-05-29 09:24朱泽昊田兵樊小鹏曾敏杨志
电子技术与软件工程 2023年7期
朱泽昊 田兵 樊小鹏 曾敏 杨志*
(1.薄膜与微细技术教育部重点实验室 上海交通大学 上海市 200240)(2.南方电网数字电网研究院有限公司 广东省广州市 510700)
在煤矿开采业、石油生产和天然气传输业中,常常伴随着大量的易燃易爆和有毒气体产生,诸如甲烷(CH4)、一氧化碳(CO)和氢气(H2)等。准确可靠地检测CH4、CO 和H2以及预测它们的混合气体的种类和浓度,对开采工作人员的安全健康、避免事故的发生以及环境保护有着重要的研究价值[1]。目前,电子鼻系统已被广泛应用于混合气体的分类识别和浓度预测领域,但是仍面临一些挑战。比如电子鼻传感器获取的参数信号中存在来自温湿度干扰和测量误差等方面的复杂噪声干扰,在分类识别时要求分类算法能够处理多个输入和输出的模式识别算法,并且能够甄别数据中的复杂关系[2]。如刘伟玲等人[3]采用结合主成分分析(PCA)的支持向量机(SVM)和反向传播神经网络(BPNN)对甲硫醚、乙酸乙酯及其混合物进行分类识别,其识别精度分别达到92%和94%。
混合气体浓度预测的主要挑战之一是不同浓度和比例的混合气体在一起产生的复杂性,导致传感器响应信号和单一气体组分浓度之间的关系往往是非线性关系,难以直观地建立起相互之间的对应关系[4]。最小二乘支持向量机(LSSVM)在SVM 的数学框架上结合了最小二乘优化技术,拥有很强的非线性拟合能力,在气体的浓度预测中显示出较高的精度。如Khalaf W 等人[5]通过建立LSSVM 模型来精确预测不同挥发性有机化合物的浓度。Huang L X 等人[6]用电子鼻系统鉴定蜂蜜的植物来源,实验结果表明LSSVM 在蜂蜜质量预测方面具有高性能。Zhang W L 等人[7]用多层感知机(MLP)和LSSVM 等多种算法对四种空气污染物(C6H6、NO2、SO2、SO2和NO2的混合物)进行分析,结果表明LSSVM 获得了最高的预测精度。
本文针对CH4、CO 和H2三种单一气体组分及其二元混合物的分类识别及浓度预测问题,设计了可以实现高精度识别和预测的电子鼻系统,通过时域特征提取来降低响应信号受到的噪声干扰。本文提出基于DN 算法的气体分类模型,解决传统机器学习算法在小样本数据集下识别准确率低的问题。针对混合气体浓度预测的难点,采用先分类再预测的“双步策略”,结合DN 算法对气体分类识别的结果建立LSSVM 模型。在小样本数据集的训练情况下,DN-LSSVM 模型将进一步提升电子鼻的浓度预测性能。
1 实验装置设计及样本采集流程
1.1 电子鼻系统设计
本文设计的电子鼻系统主要由三个部分组成:气体传感器阵列、硬件电路以及软件系统。为了实现针对三种待测目标气体(CH4、CO 和H2)的检测,购买了6 个商用气体传感器用来组成气体传感器阵列:TGS2600、TGS2612、TGS2619、TGS813、MQ-8 和MQ-9B。电子鼻硬件电路包括了信号调理及采集电路模块、通讯传输电路模块、电源电压转换模块以及蓝牙信号发射器等辅助配件。软件系统主要实现了传感器阵列响应波形的可视化、多信道的数据实时存储及分析等功能。
1.2 实验装置及流程
在密闭的气体腔室中放入电子鼻系统后,采用气体质量流量控制器(MFC)调节通入腔室的待测气体和空气的流速和比率,从而配置出不同浓度的待测气体。同时在电脑上通过蓝牙信号接收每个气体传感器的实时响应值。在完成一次数据采集后,通入纯净空气直到气体腔室内部所有气体传感器恢复到无响应状态,以便于进行下一次采样。整个实验装置的设置和实验流程如图1所示。对于某个单种气体,从5ppm 开始,以5ppm 作为浓度间隔,然后增加到50ppm,每个浓度测试两次,共获得20 组与浓度相对应的电子鼻响应数据。对于混合气体中的每种气体,分别从5ppm 和10ppm 开始,以10ppm 作为浓度间隔相互混合,各类别混合气体经测试,可以得到150 组与浓度对应的电子鼻响应数据。
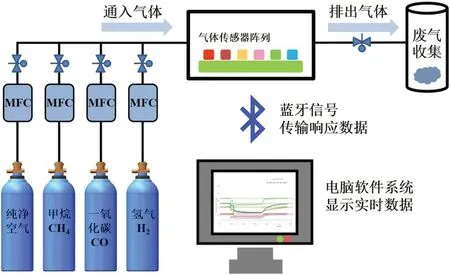
图1:气体采集实验的流程步骤
2 混合气体的分类识别和浓度预测
2.1 特征提取
由于传感器自身的漂移和实验环境中存在的噪声干扰,直接使用原始响应数据难以达到较好的效果,因此需要进行特征提取。时域特征提取是指直接从传感器的原始响应中提取稳态响应和瞬态响应等信息。本文采用分式差分法作为时域特征提取,如式(1)所示:
其中,Rair表示传感器在空气中的基线电阻值,Rgas表示传感器在待测气体响应中的稳定电阻值,F为所提取的时域特征。
2.2 基于DN算法的气体分类识别
传统的气体分类识别算法往往需要建立高复杂度的模型以适应复杂的气体特征空间,从而导致其泛化性能降低,容易出现过拟合问题。DN 算法主要由树突模块和线性模块组成[8]。树突模块的计算仅包含矩阵乘法和Hadamard 乘积,其计算复杂度显著低于非线性函数,计算公式如下:
其中Al-1和Al分别是模块的输入和输出。X表示原始输入数据,Wl,l-1是从第l-1 个模块到第l个模块的权重矩阵,L表示模块的数量,°表示Hadamard 乘积。DN 的总体架构如图2 所示。
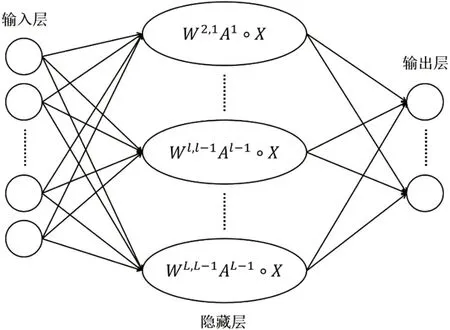
图2:DN 模型的结构图
2.3 基于LSSVM模型的气体浓度预测
LSSVM 通过求解线性方程组更适合处理高维空间问题,不仅表现出卓越的泛化能力,而且解决问题的速度也更快[9]。假设给定训练数据集i为训练数据集的样本个数,xi为一组1×n维的向量,yi为函数y=f(x)的对应输出,则LSSVM 回归的初始优化问题为:
其中,w 为一组权值向量,b为阈值,ei为误差,γ为正则化参数, 为原空间向高维空间对应的非线性映射。由于w 可能具有无限维数,一般无法直接进行求解,而是需要采用拉格朗日乘子法来求解上式。引入拉格朗日函数为:
其中,非负辅助变量 称为拉格朗日乘子。构造核函数:
分别对式(4)中的w,b,,ei求偏导数并令其为0,结合核函数可得到下列线性方程组:
其中,为训练样本的目标值所构成的一组向量,矩阵Ω 的第(i,j)个元素为,I 为维度合适的单位矩阵。求解式(6)的线性方程组得到a和b的表达式为:
根据式(7)求出的a和b构造LSSVM 的解析函数表达式为:
3 实验结果分析
3.1 数据预处理
PCA 是一种常用的降维算法,可以减少高维数据中的冗余信息[10]。为了保留气体响应信号中最重要的特征,本文对经过时域特征提取的传感器信号数据进行PCA降维处理,其对应的三维空间分布如图3 所示。将PCA降维后的结果作为分类模型的输入,可以降低计算的复杂性,并起到防止过度拟合的作用。
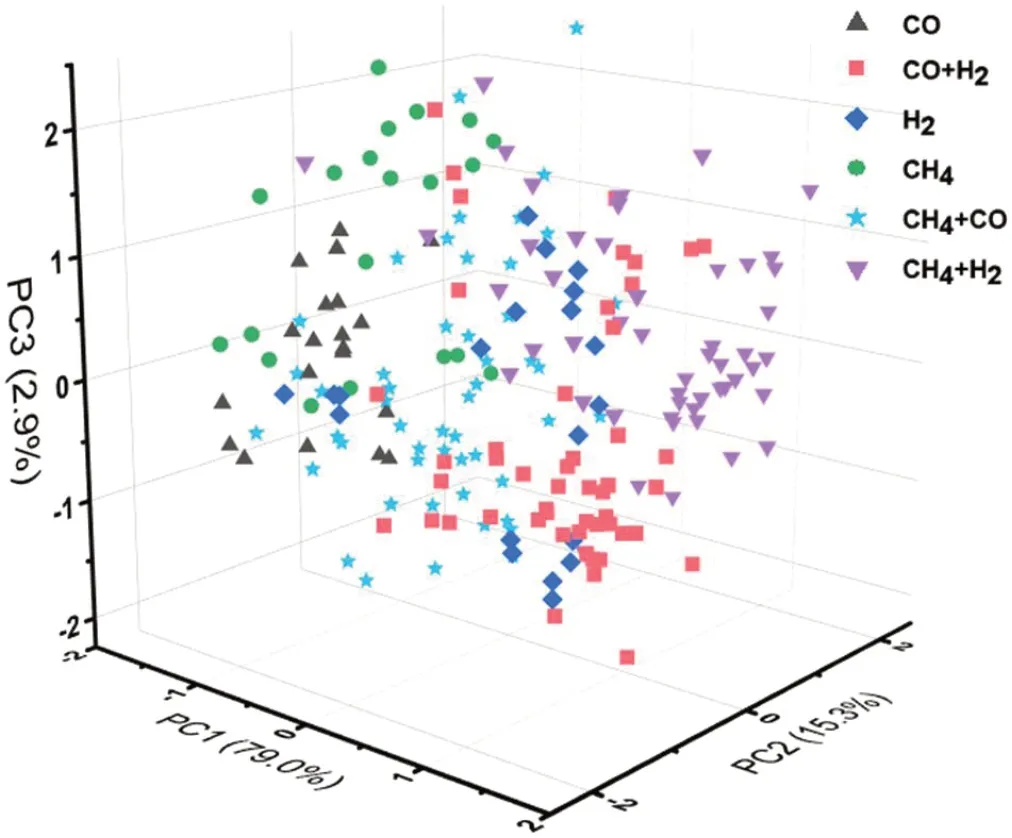
图3:混合气体样本在三维空间上的分布图
3.2 气体分类识别结果
为了验证DN 算法的效果,本文使用四种传统机器学习算法(随机森林(RF)、随机梯度下降(SGD)、SVM 和MLP)与DN 算法进行了比较。不同算法的分类性能对比结果如图4 所示。
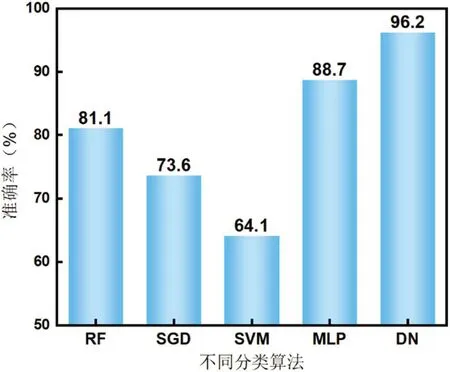
图4:不同分类算法的识别准确率对比图
从图4 中可以看出,基于DN 算法的分类模型的识别准确率达到96.2%,远优于四种传统的机器学习算法。
3.3 气体浓度预测结果
针对气体的浓度预测,本文先利用DN 算法对样本进行分类识别,然后再针对每个分类结果建立LSSVM模型进行气体浓度的精确预测。LSSVM 模型和DNLSSVM 模型对CH4、CO 和H2的浓度预测结果如图5所示。
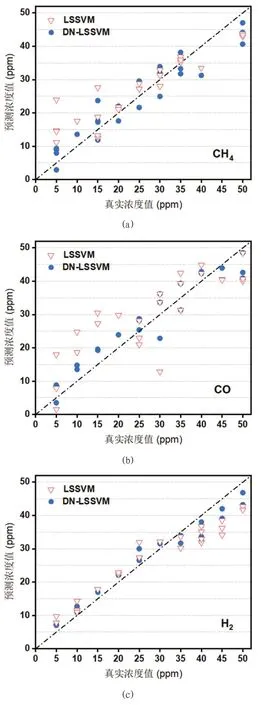
图5:CH4、CO 和H2 的浓度预测结果对比
从图5 中可以看出,DN-LSSVM 模型的预测值相比于LSSVM 模型的预测值,更加接近中间的真实浓度直线。进一步地分析了两种模型预测结果的决定系数(R2)、均方根误差(RMSE)以及平均绝对误差(MAE)作为模型的评价指标,其具体值如表1 所示。

表1:不同气体的浓度预测评价指标
从表1 中可以看出,相较于LSSVM 模型,DNLSSVM 提高了模型对于混合气体组分浓度预测的准确性,其对CH4、CO 和H2浓度预测的R2分别提升到了0.909、0.896 和0.937。
4 结语
本文完成了电子鼻系统的软硬件设计,可以实现针对CH4、CO 和H2的分类定性识别与浓度定量预测。首先采用时域特征提取降低了响应信号受环境噪声干扰的影响,基于DN 算法的分类定性识别模型对单一气体组分及其二元混合物共6 种气体类别的识别准确率达到了96.2%,远优于作为对比的四种传统机器学习算法(RF、SGD、SVM 和MLP)。在针对混合气体的浓度定量预测中,与传统的直接建立预测模型相比,结合DN 算法先对混合气体组分进行定性识别,再建立LSSVM 模型进行浓度预测,DN-LSSVM 模型有效地提升了混合气体的浓度定量预测性能。实验结果表明,本文设计的电子鼻系统可以实现对CH4、CO 和H2三种气体的高精度定性识别与浓度定量预测,为煤矿开采、石油生产和天然气传输等应用场景中易燃易爆危险气体的高精度在线气体传感提供技术支持。
猜你喜欢
吉林电力(2022年2期)2022-11-10
数学物理学报(2021年5期)2021-11-19
数学物理学报(2020年4期)2020-09-07
中医眼耳鼻喉杂志(2019年3期)2019-04-13
小哥白尼(趣味科学)(2018年11期)2018-12-18
中学化学(2017年5期)2017-07-07
百科探秘·航空航天(2016年6期)2016-12-01
中国塑料(2016年8期)2016-06-27
焊接(2015年8期)2015-07-18
食品工业科技(2014年15期)2014-03-11
