
基于深度学习的水表示数检测与识别
2023-05-29 09:24孙跃文李修治鲍喜荣
电子技术与软件工程 2023年7期
孙跃文 李修治 鲍喜荣
(东北大学 计算机科学与工程学院 辽宁省沈阳市 110169)
机械水表字轮区域的信息识别主要可分为字轮区域文本检测和文本识别两个任务。文本检测指在水表图片中消除背景干扰准确定位字轮框;文本识别指将文本行旋转矫正并识别出文本字符。现有的水表图像识别方法一般采用特征提取的方式进行字轮框的检测定位,然后采用模板匹配、特征分类等方法对文本行进行文本识别。现有方法对背景简单呈水平排列的检测场景具备一定的适用性,但也易受环境干扰出现较大面积的背景残留,影响后续的文本识别工作。
深度学习的文本检测算法主要分为基于回归的文本检测算法和基于分割的文本检测算法两类。基于回归的文本检测算法是直接面对整张图像进行预测,可以提取到更深层次的特征信息,在检测速度上存在较大优势,但是这类方法由于预设了文本框形状,所以无法对弯曲文本和不规则文本进行检测。基于分割的文本检测算法对图像的像素进行分类判别像素点是否属于文本目标,计算出文本概率图后通过复杂的后处理操作得到文本框,此类算法解决了弯曲文本和不规则文本的检测问题,但是复杂的后处理操作也大大的增加了计算开销。
水表字轮区域的形状一般为矩形,不存在弯曲文本和不规则文本的情况,这一特点降低了识别的难度。然而自然场景下采集的水表图像存在其特殊性,往往背景复杂、旋转角度不一。综上,本文使用轻量化的YOLOv5 模型完成水表字轮区的文本检测,结合YOLOv5 可以同时完成目标检测与分类的优势,改变了常规的目标检测策略,提出了一种基于角点定位的检测方法。文本识别模型采用CRNN+CTC 的网络结构,可以处理检测到的文本行,完成文本识别任务。
1 基于深度学习的水表示数检测与识别模型
本文所提出的水表示数检测与识别模型包括字轮检测和文本识别两个部分。首先采用合适的目标检测模型对字轮区域进行定位,将字轮图像进行裁剪,经过旋转校正后作为文本识别模型的输入进行文本识别,最终输出水表示数,整个过程如图1。

图1:模型整体流程
1.1 基于YOLOv5的水表字轮检测模型
1.1.1 YOLOv5 网络结构
YOLO(You Only Look Once)[1]是一种基于深度卷积神经网络的目标检测模型,模型的优点是拥有更快的检测速度,并且降低了背景误检率,YOLOv5 常用的模型结构有s,m,l,x 四种,本文使用的是YOLOv5s(下文统一简称“YOLOv5”)。
YOLOv5[2-3]的输入端采用马赛克数据增强将四张图进行随机拼接。同时,输入端采用了自适应缩放,可以将输入图像统一到网络需要的尺寸。并且自适应锚框计算可以在预设的锚框基础上输出预测框并与真实框对比,计算差值再反向迭代更新网络参数。如图2 所示。

图2:Mosaic 数据增强
YOLOv5 的损失函数由三部分组成,分别是分类损失(Classes loss),置信度损失(Objectness loss)以及定位损失(Location loss),如公式(1)。
式中λ1,λ2,λ3为平衡系数。
1.1.2 字轮框直接定位算法
直接定位是直接将水表字轮框作为目标进行检测,由于在自然场景下拍摄的图像存在较大的旋转角度,模型检测的区域往往有较大面积的背景残留。对文本识别模型造成干扰,导致文本识别准确率大大降低。如图3所示。

图3:直接定位检测结果
1.1.3 改进的YOLOv5 目标检测模型
结合YOLO 算法在多类别检测时准确效果优于单类别这一特点,设计将定位字轮框转变为定位矩形框角点,并将以顺时针顺序将左上、右上、右下、左下角点分别设置为类别0、1、2、3,对这四个类别进行检测和模型训练。如图4 所示。

图4:检测字轮框角点
对于能够检测出全部角点的情况可以直接计算中心点坐标,用于字轮框的定位与裁剪。对于只能检测出三个角点的情况,可以根据三点坐标计算出第四个角点的坐标。
式中Point0[x]表示类别“0”的x 轴坐标。
对于只检测出两个点的情况,一般是图片表面存在水雾或污点,可以根据缺失点的类别分情况对原始图片进行旋转,再次进行检测得到最终结果。首先在检测出的两点中确定一个点为中心点,以x 轴正方向为起始方向,另一点以逆时针作为基本旋转方向,实际情况中旋转角度范围为[-90°,90°]。
当“0”点和“1”点已知时,分为图5 所示两种情况。
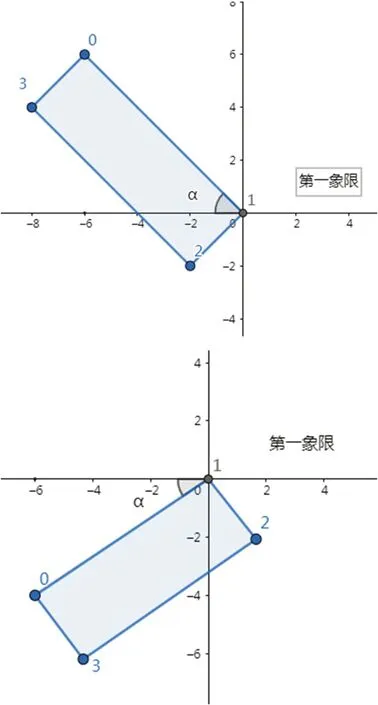
图5:角点的旋转情况
将“1”点作为中心点,坐标设为(xo,yo),“0”点坐标设为(xr,yr),根据公式(4)计算逆时针旋转角度。对于另外三种情况,分别以2 点、1 点和0 点作为中心点,分析过程相同。对于检测出0 个或1 个角点的情况,此类图像存在较大面积“灰雾”或字轮框被严重遮挡。
1.2 基于CRNN的文本识别模型
1.2.1 CRNN 网络结构
CRNN 是一种集特征提取、序列建模和转录于一体的神经网络结构[4],包括卷积层(Convolutional Layers)、循环层(Recurrent Layers)、转录层(Transcription Layer)。
卷积层CNN 用于提取特征图、输出特征序列。首先将输入水表图像转变为灰度图并缩放处理,将所有图像缩放到固定高度,本文选择默认高度32。缩放后图像的宽度可以是任意值,文中选取宽度为100。接着卷积层进行一系列卷积、最大池化、批量归一化操作,最后得到512 个特征图,高度变为原来的1/32,宽度变为原来的1/4,输出特征图像尺寸为(512,1,25)。
循环层由一个深度双向LSTM[5]循环神经网络构成,为特征序列X=x1,…,xT中的每一特征向量xt预测其标签分布yt。将两个相向的LSTM 组合成一个双向长期短记忆网络(Bi-LSTM),同时将多个双向LSTM 堆叠形成深度双向LSTM 网络。在 LSTM 中一个时间序列就传入一个特征向量进行分类,本文中卷积层每张图像会生成25 个特征向量,即时间序列长度T 为25。每输入一个特征向量xt进入循环从都会输出其标签分布yt,所以循环层的输出为25 个长度为字符类别数的向量yt构成的概率矩阵。
转录层使用了联结时间分类器(CTC)将Bi-LSTM生成的特征序列标签分布重新整合转换成标签序列进行输出。
2 实验过程
2.1 YOLOv5模型
2.1.1 数据集
本文研究所用到的数据集来源于中国计算机学会所创办的CCF 大数据与计算智能大赛,共计1500 张水表图像。
数据集标签按照[index, cx, cy, w, h]的格式进行标注。其中index 为类别索引,下标从0 开始,每个水表图像的字轮区均有4 个角点,共4 种类别。
2.1.2 数据扩充
为了提高模型的文本检测效果,对训练集进一步扩充以增加不同情况的图像数据。选择角度旋转作为数据扩充方法。设旋转角度为[5, 30, 60, 90],同时改变labels 中的标注的数据集坐标信息,经过角度旋转后训练集扩增了5 倍,共计5000 张图像,按照4:1 的比例划分为训练集与验证集。如图6 所示。

图6:数据扩充——图像旋转
2.1.3 模型训练
YOLOv5 模型训练样本的batch_size 设置为4,训练迭代次数epoch 设定为100。YOLOv5 采用warm-up的方式调整学习率,初始学习率设置为0.001。模型训练过程中损失值变化曲线如图7 所示。

图7:YOLOv5 模型的损失曲线
由图7 可知,随着训练迭代次数增加,各类损失函数均在训练的过程中不断减小并最终收敛到较小的值,虽然验证集的损失曲线幅度波动较大,但随着迭代次数增加最终也趋于收敛,说明YOLOv5 模型在训练集和验证集中的检测效果趋于稳定。
2.2 CRNN模型
2.2.1 数据集
对原始数据集经过裁剪、透射变换后,获得一套具有1500 张字轮区域图像的数据集。同时在训练集中增加著名的SCUT-WMN 的数据集[6]中的简单样本进行扩容,增加训练集至2000 张图像,其中每张图像包含5个字符。如图8 所示。

图8:文本识别模型数据集
对于半字符的情况,使用大写英文字母表示。投入CRNN 网络中进行识别后再转换为两个半字符中数字较大的输出。
2.2.2 模型训练
在训练过程,设置最大迭代次数max_epoch 为200,初始学习率为1.0,在第50 个和80 个epoch 训练时降低学习率,训练样本的batch_size 设置为16。
由图9 可知,随着训练迭代次数增加,损失曲线呈下降趋势,在第120 个step 时CRNN 模型的损失值已收敛到0.005 左右,表明模型趋于稳定。

图9:CRNN 模型的训练损失曲线
3 实验结果及分析
3.1 评价指标
常用的目标检测评价指标包括平均召回率(mean Recalls)、平均准确率(mean Precision)以及均值平均精度(mAP),这三个评价标准建立在TP、FP、FN,TN 上。TP 表示正类数据被模型预测为正类的数量,TN 表示负类数据被模型预测为负类的数量,FP 表示负类数据被模型预测为正类的数量,FN 表示正类数据被模型预测为负类的数量。
召回率(Recalls)表示正类数据判定为正类的数量占实际该类全部数量的比例,见公式(5)。
准确率(Precision)表示正类数据判定为正类的数量占模型预测为正类的数量的比例,见公式(6)。
均值平均精度则建立在准确率和召回率上,见公式(7)。
其中p 表示准确率,r 表示召回率,平均精度p(r)表示当前的P-R 曲线。
3.2 YOLOv5算法实验结果
将未进行数据扩充训练的YOLOv5 模型记作YOLOv5 ①,经过数据扩充后重新训练的YOLOv5 模型记作YOLOv5 ②,现将两个模型的检测结果进行对比。
如图10 所示, 经过100 个epoch 迭代后,YOLOv5 ②的准确率和召回率变化曲线的波动幅度均小于YOLOv5 ①。随着迭代次数增加,准确率和召回率呈上升趋势,且YOLOv ②数值始终大于YOLOv5 ②,变化曲线更快趋于收敛,说明数据集扩充后训练得到的YOLOv5 模型训练效果更好。
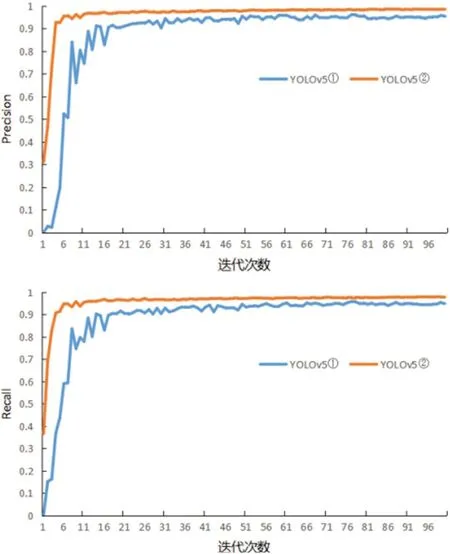
图10:准确率(上)与召回率(下)变化曲线
通过表1 可知,训练100 个epoch 后,YOLOv5 ②的平均精度优于YOLOv5 ①,“0”、“1”、“2”、“3”四个类别的AP0.5 分别比YOLOv5 ①高3%、3%、3.1%、1.8%,均值平均精度比YOLOv5 ①高2.7%,说明经过数据集扩充后,指标mAP0.5 得到较大提升,模型预测定位更加准确。
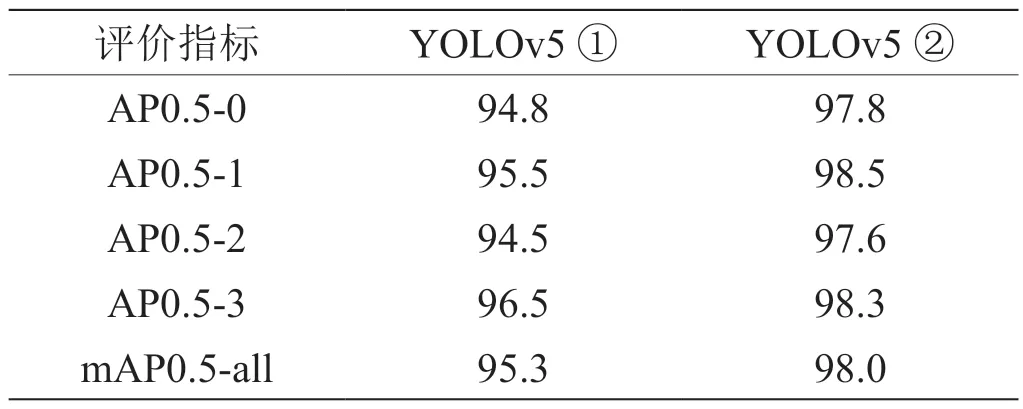
表1:mAP0.5 结果对比
在测试集上检测模型性能,对于测试集中只能检测出0 个、1 个或2 个角点的图像将按照1.1.3 的方法进行图像旋转后再次进行检测,检测结果如表2 所示。

表2:测试集检测结果
对于检测到3 个和4 个角点的图像可认为模型检测正确,正确率为97.4%;其他情况则需要按照1.1.3 方法图像旋转校正后进行二次检测。经过二次检测后,各个角点类别的检测准确率均有所提升,检测正确率由97.4%提高到99.0%,检测精度提高了1.6%。
将测试集水表图像字轮区域裁剪并进行透射变换后生成文本框切片,输入CRNN 网络进行文本识别。在500 张图像共计2500 个字符中,2462 个字符正确识别,38 个字符未正确识别,单字符识别准确率达到98.48%,共计26 张图像未正确识别,完整字轮区文本行识别准确率达到94.80%,基本实现了对机械式水表图像的检测识别。
4 结束语
本文提出了基于YOLOv5 与CRNN 模型的水表读数识别算法,设计了一种字轮区角点定位方法,获取角点位置后即可裁剪出字轮区域,同时采用图像旋转扩充数据集提高模型鲁棒性,改进的文本检测模型的准确率、召回率和mAP 值分别达到98.50%、97.68%和98.00%,各项指标均得到明显提升,克服了自然场景下水表图像识别难题。文本识别模型中添加SCUT-WMN数据集进行训练后,在测试集上单字符识别准确率未98.48%,文本行识别准确率达到94.80%,满足水表读数检测识别需求。
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
供水技术(2020年6期)2020-03-17
E动时尚·科学工程技术(2019年9期)2019-09-10
中国交通信息化(2018年5期)2018-08-21
电子科技(2016年12期)2016-12-26
系统工程与电子技术(2016年4期)2016-08-24
城市地理(2015年18期)2015-08-15
电子设计工程(2014年17期)2014-02-27
