
基于深度学习的果蔬识别与定位软件系统研究与实现
2023-06-07 05:47杜兴
电子制作 2023年9期
杜兴
(贵州电子信息职业技术学院,贵州凯里,556000)
0 引言
在生产生活中,存在着农民通过观察统计果实数量和位置以方便估计产量和收益多少情况、同时还有果蔬加工厂通过大量劳动力进行手工分拣现象等,这些方式都存在着大量重复式机械劳动等相似共同特征。
为了解决生产生活中低效率的现象,本系统设计出了一款能够利用手机拍照上传含有果蔬的图片,经过算法识别与定位后统计出果蔬的类别、位置及数量等信息的果蔬识别与定位APP。
1 系统整体设计
系统前端使用以Vue.js 语言开发的uniapp 跨平台前端框架,该框架只需提供一款程序而可以同时开发出安卓、iOS、微信小程序等多平台的快速前端开发工具,简称一端开发,多端编译。前端部分使用基于uniapp 风格的HTML、CSS 和Vue 等作为前端开发语言,同时借鉴uniapp 官方社区的前端模板构建整个APP 页面[1]。
系统后端使用基于Python 语言的Django 的Web 框架作为果蔬识别与定位软件数据增删改查的后端部分。其中,Django 的Web 框架是一个基础的Web 框架,而本系统使用的是基于Django 再次开发封装的Django rest framework 的Web 框架[2],该框架对数据库的增删改查有着极其简明的操作逻辑。其中,MySQL作为数据的存储工具。
系统的算法核心使用基于SSD 目标检测与识别的神经网络对果蔬图片进行识别与定位,从而获取图片中的果蔬位置、类别及数量等信息。
果蔬识别与定位APP 系统是采用前后端分离的设计模式进行开发,包含APP 前端页面、数据增删改查的后端以及识别与定位的算法核心。系统的整体实现构架如图1 所示。

图1 系统整体构架图
果蔬识别与定位软件系统由图中的三个模块组成,前端APP 通过点击对应按钮调用手机端摄像头拍摄或上传含有果蔬的图片信息,当后端检测到数据库中的字段信息发生变化时,调用识别与定位的算法核心对图片信息进行处理,将检测后图片、位置和类别信息结果存储到数据库中的对应字段类型中,最后在前端页面点击识别按钮获取识别与定位后的结果并在前端页面显示。其中,拍照上传图片的方式是HTTP 中的put 请求方式,获取识别结果是get 请求方式,因此本系统的后端只有常见增删改查中的改查功能。此外,本系统没有设计用户注册登录功能,故在后端数据库中表的字段数量只有一个。
2 前端设计
果蔬识别与定位的APP 的前端设计理念是功能实现和操作简约。
在编程语言方面选择目前较为流行的基于Vue.js 开发的前端多平台应用框架,该框架主要的特点是只需使用一套代码就能实现不同平台的设计开发,并且开发流程和模式与常见的网页设计高度相似,可以无学习成本的进行果蔬识别与定位的APP 开发。
在功能核心设计方面,由于本识别与定位系统是采用前后端分离[3]的设计模式,同时在进行前后端设计采用restful[4]风格的设计模式故在前端只需要向后端提供对应的请求接口以及请求方式,并且前后端数据是以JSON 数据类型进行传输。按照此种设计,就完成前端核心功能。在上传图片和识别定位按钮分别对应PUT 和GET 请求,该部分的功能对应图3 中的功能实现部分,由于设计采用restful风格,故请求地址相同,方式不同,如图2 所示(以本机IP 为例)。
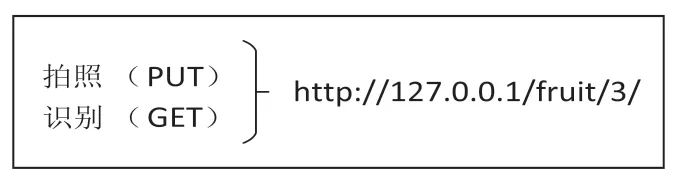
图2 请求接口和方式图

图3 果蔬与识别定位软件界面图
在界面展示方面,前端页面主要突出简洁够用的原则,既能确保核心功能的完成和实现,也要突出界面操作简单。果蔬识别与定位的APP,如图3 所示。软件界面的注意事项主要包含软件产品优缺点和使用说明,软件的功能部分是上传图片和识别定位的核心功能,软件的操作流程界面主要包含软件的操作流程,由以上的三个模块共同组成果蔬识别定位软件的前端界面。
在图3 所示的功能部分中,点击拍照按钮提交图片的数据是以base64 进行编码,封装到JSON[5]类型的数据中,向后端进行提交。
3 后端设计
果蔬识别与定位的APP 的后端设计理念是采用基于Python 语言的Django 的web 框架进行后端设计,为了方便快速后端系统采用的是基于Django 框架的再封装的Django Rest Framework 简称(DRF)进行主要后端主要设计框架。同时结合数据库MySQL、图像处理库pillow 以及base64 解码库等进行辅助设计。
在图3 所示的功能部分中,拍照和上传按钮分别对应后端PUT 和GET 请求,且请求路径相同和数据库中的字段也相同。具体做法如下,当点击拍照按钮,前端将图片的base64 数据提交给后台,并修改名为base64 对应的数据内容,其他数据内容不做修改,请求方式为PUT。当点击识别按钮,后端部分先进行图片解码操作,之后通过识别与定位算法计算出果蔬所在位置和类别信息,并保存在名为result 对应的数据内容,其他数据类型不变,并将数据以JSON 数据类型返回给前端页面进行渲染,且请求方式为GET。其中,数据库信息如图4 所示。

图4 数据库字段
后端部分的DRF 框架如图5 所示,使用基于DRF 框架进行快速搭建[6]。数据库API 负责数据的增删改查,序列化器Serializers 负责前后端数据的交互,结合参数校验数据接口Validators 和权限校验Permissions 组成三级接口视图集,同时Routers 完成自动路由注册以及包含异常处理和规范接口等功能。使用极少的程序代码,从而注重项目的流程设计,完成复杂的后端逻辑设计。

图5 后端DRF 设计流程图
4 算法设计
果蔬识别与定位使用基于深度学习的SSD 目标检测与识别的神经网络作为识别核心。以本系统为例,能够定位出果蔬在图片中的位置、果蔬的类别以及数量信息,如图6 所示,其界面是图3 的功能部分的界面图。

图6 识别与定位效果图
在本系统中,数据集分为苹果、橘子和香蕉三个类别,样本总数量为300。使用基于labelme[7]数据标注软件对数据集进行标注,数据的标注格式VOC2007,之后送入到神经网络中性学习训练。样本数据如图7 所示。

图7 部分样本数据图
在算法结构中,SSD 是one-stage 的端到端目标检测识别网络[8],网络结构图如图8 所示。以本系统为例,该目标检测识别网络的特征提取网络(backbone)是基于牛津大学团队设计VGG16 卷积神经网络。通过对6 种不同尺度的特征图进行融合,可以实现不同尺寸目标的检测与识别,即浅层特征图用于检测小目标、深层特征图用于检测大目标。此外,网络结构的特征图采用锚点(anchor)机制,每个特征图上的每个锚点生成4 或6 个目标的先验框,考虑到特征图的通道数,6 种不同尺度的特征图总共生成8732 个先验框。生成的8732 个先验框的分类运算量,在一定程度上,相当于输入一张图片生成8732 个图片,然后再对生成的图片做分类,这样就会导致运算复杂度成倍增长。因此,需要对先验框做数量上的减法处理,具体做法如下,采取非极大值抑制的方法减少先验框与之重合度比较高的框,从而减少分类运算量。SSD 网络的损失函数是由均方误差和交叉熵损失的线性组合,从而对目标进行位置定位和类别分类。
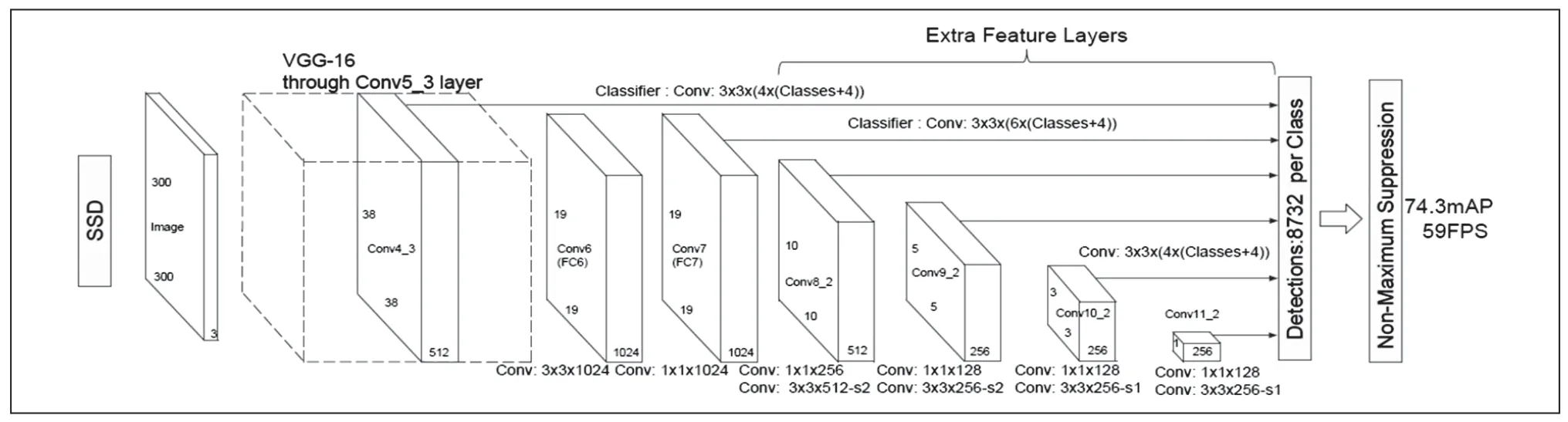
图8 SSD 网络结构图
在网络的输入中,训练和预测时的图像预处理的重要步骤之一是统一将图片尺寸放缩到300×300。将图像放缩到固定尺寸时会损失图像的部分信息,若图像尺寸越大这种情况会明显。为了不损失图像信息,本文在采取在原图周围padding 的方式进行放缩图像做法,这样做的优点是不破坏原图的图像信息在图像补一个固定像素值的点(本例补黑色像素值的点),而图像以直接缩放的方法则会破坏原图目标结构和目标信息。图像放缩效果图,如图9 所示。

图9 图像放缩效果图
在网络结构模型中,SSD 网络是以VGG16 的6 层特征图作融合,共产生8732 个先验框。以图8 所示的Conv4_3 layer 为例,其他特征图做法与之类似。
以输入图像尺寸为300*300*3 和VGG16 卷积和池化的操作为例,SSD 网络生成的第一个特征图是Conv4_3 layer,该层特征图的尺寸为38*38,且通道数为512。该层特征图每个锚点产生4 个先验框,而该层先验框的尺寸以21*21 作为基准大小,比例分别为1:1、1:0.5、1:2、1:(21*45)0.5,产生4 个不同尺寸的比例,按照此种方法产生5776 个先验框。不同的是,另外5 个特征图上的每个锚点会产生4 或者6 个不等的先验框,以此种方法为例,剩下5 个特征图分别产生2116、600、150、36、4 个先验框。这些先验框的总数量为8732。这些先验框是以输入图像为基准,采取提取不同尺度特征图的方法,从而检测出图像中不同尺寸的目标区域。
由于输入一张图片产生出8732 个先验框,若不经过减少先验框数量的处理会产生大量数值运算,会增加网络模型训练和预测的时间。SSD 网络模型在产生8732 个框为基础,经过非极大值抑制处理[9],减少先验框的数量,降低网络模型的运算量。非极大值的主要作用是在不同数量先验框的情况下,寻找局部的最大值,从而确定最终的先验框,从而降低总先验框的数量。具体流程如图10 所示。

图10 非极大值算法流程图
SSD 是端到端检测与识别的神经网络模型,目标区域的定位和目标区域的分类是网络模型的任务。因此,损失函数与网络模型的任务相对应。损失函数公式,如图11 所示。损失函数由两部分组成,分别是均方误差损失函数(定位损失)和交叉熵损失函数(类别损失)。图像中目标区域的位置坐标信息与均方误差损失函数输出值是连续的相对应。图像中目标区域的类别信息与交叉熵损失函数的输出值是离散的相对应。不同的损失函数负责目标检测与识别的不同任务。

图11 损失函数公式图
SSD 网络模型训练步骤如下:(1)数据清洗和数据标注(VOC2007 格式);(2)安装和配置硬件环境;(3)创建训练工程项目;(4)读取数据并数据预处理;(5)搭建网络模型;(6)设置训练参数;(7)观察损失函数训练曲线图(调优网络模型);(8)保存网络模型的结构和参数(用于预测)。SSD 网络模型的训练损失曲线图如图12 所示,训练迭代次数是50 次。

图12 损失函数训练曲线图1
由于,网络模型训练对硬件配置较高,训练环境硬件配置为:CPU 为I712 代处理器,显卡为RTX3070TI 显存为8G,运存为32G。以此硬件环境为例,每秒能够预测38 张左右,以本机调用摄像头为例,如图13 所示。

图13 实时检测与识别效果图
5 其他部分
在完成整个果蔬识别与定位部署之前,需要将系统的前端打包至安卓端,系统的后端和识别检测部署在云端。以腾讯云和阿里云等服务器的中低端的配置水平,在部署和调试过程中发现,硬件水平虽然能够完成的基础功能,但是所耗时间较多,造成软件的操作体验不好。因此,本系统使用内网穿透技术[11],实现内网与外网的互相访问,将后端和识别检测部分部署在本地电脑,以增强软件使用体验。本系统使用的是神卓互联内网穿透工具,可以使用极少的成本实现前端与后端的数据交互以及目标的检测与识别,解决了以外网为主要使用场景的手机端访问内网的难题。
由于本系统是由APP 前端、基于Python 语言DRF 的web 后端,以及识别与定位算法端的三个核心部分。果蔬识别与定位系统是前后端分离开发的设计模式,前端与后端的交互数据类型是JSON。由于,本系统的三个核心模块分别单独进行设计和开发,因此,后端系统和识别与定位算法系统需要进行数据耦合。如图4 所示,具体做法如下,采取设置数据库中is_delete 的不同标志的为状态,来检测和判断APP 前端页面提交的功能需求。基于此种方法实现果蔬识别定位系统的三个核心模块的数据交互。
6 实验环境
本系统使用的主要环境名及版本号如表1 所示,其中系统硬件环境配置在第5 部分已说明,在此不再赘述。
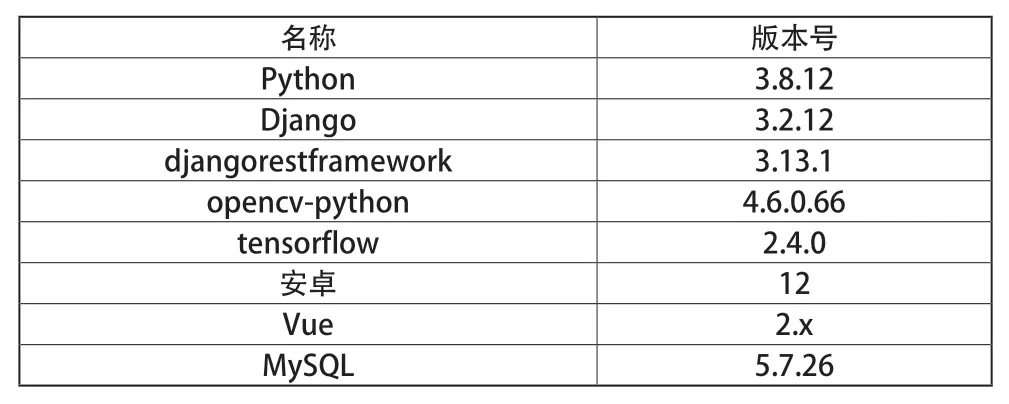
表1 解释器及框架版本号
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
成都信息工程大学学报(2019年3期)2019-09-25
童话世界(2019年26期)2019-09-24
今日农业(2019年15期)2019-01-03
启蒙(3-7岁)(2018年8期)2018-08-13
基层中医药(2018年2期)2018-05-31
自动化学报(2017年5期)2017-05-14
童话世界(2016年8期)2016-06-02
探测与控制学报(2015年4期)2015-12-15
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
