
韩国汉语学习者写作质量评估研究
2023-06-15 20:18王淑华朱伊苓
现代语文 2023年3期
关键词:质量评估
王淑华 朱伊苓


摘 要:以99篇韩国汉语学习者的新HSK5看图写作文本为研究对象,从词汇和语法两个维度,设立7个特征项、33个区别性指标,考察不同指标与写作文本质量的相关性。研究显示,词汇维度、语法维度均有多个指标与看图写作文本质量强相关或中度相关。使用语法维度指标建立的方程解释力优于词汇维度建立的方程;结合词汇和语法维度建立的方程虽然解释力更强,但使用的预测变量较多,操作难度增加。
关键词:韩国汉语学习者;看图写作;质量评估;词汇维度;语法维度;预测方程
在第二语言能力评估中,听和读的评估可以通过选择、判断、填空等客观性试题来进行,但说和写的评估一般只能通过主观性试题来完成。因此,近些年来,关于口语和写作能力的评估在第二語言能力评估研究中逐渐成为热点话题[1]-[5]。由于评估者个人的兴趣、情绪、意志以及光环效应、位置效应等,均会引起评分误差,学界虽然尽力使用各种手段来提高评分者信度,如规定标准化评分细则、对评分员进行岗前培训、配备评分仲裁等,但人工评估的客观性和准确性仍一直饱受争议,因此,学界在多年前就开始了对机器自动评估的探索[6]-[8]。机器自动评估技术的发展,主要是依赖于口语测试、写作测试中各项区别性特征的正确选择和不同特征的权重设置[9]-[12]。这些探索为汉语二语能力评估研究作出了很大贡献,但仍有一些问题值得继续深入探讨。
就汉语写作质量评估来说,前人多单独考察词汇维度或语法维度对写作质量的影响,综合考察两个维度的研究较少;同时,前人考察的文本或来自于老HSK,或是自建语料库,对新HSK的写作文本关注不够。实际上,不同长度、任务的写作文本,其质量评估因素也有一定差异。有鉴于此,本文拟从词汇和语法两个维度出发,对韩国汉语学习者的写作质量进行综合考察,以期能为汉语作为第二语言的写作教学和质量评估工作提供参考。
一、研究问题和语料选取
本文以韩国汉语学习者的新HSK5看图写作文本为研究对象,在Read的词汇丰富性框架[11]和Wolfe- Quintero等学者的CAF框架[13]指导下,从词汇和语法两个维度,考察不同区别性指标与写作质量的相关性,并结合词汇和语法维度的指标,建立看图写作自动评分方程。
(一)研究问题
本文所探讨的问题主要包括三个方面:
1.词汇维度和语法维度的不同区别性指标,与看图写作文本质量的相关性如何?
2.词汇和语法维度具体有哪些区别性指标,它们以何种方式预测看图写作文本的质量?
3.影响新HSK5看图写作文本质量和影响汉语其他类型写作任务质量的因素有何不同?
(二)语料选取
为了较为全面地考察学习者的写作质量,我们首先选择了3幅在场景、人物、行为等方面具有较大差异的图片作为考察范围,其整卷编号分别为H51445、H51552、H51560。然后再依据成绩,将文本分为高(24—30分)、中(18—23分)、低(12—17)三个组别。需要说明的是,由于得分低于11分的作文错误较多,研究价值较低,因此,未纳入本文的研究范围。最后,每组选定33篇、一共99篇文本作为本文的具体考察对象。3幅图片分别如图1、图2、图3所示:
二、词汇、语法维度的区别性指标
与写作质量的相关性
一般认为,写作质量评估主要涉及语言表现和内容质量两个方面。考虑到内容质量方面的标准较难实现客观化且不易操作,在二语写作中尤其是篇幅较短的情况下,考察点大多集中在学生是否能使用规范的目的语,而立意构思和谋篇布局更多是母语写作中的考察点[14]。也有学者将汉字正确性作为一个独立维度,考虑到机考在不断普及且在汉字正确方面的表现优于纸笔考,故本文未将汉字正确性作为独立指标。因此,本文仅从词汇和语法两个维度来考察其区别性指标与写作文本质量之间的相关性。
(一)词汇维度区别性指标与写作质量的相关性
Read的词汇丰富性框架包括5个特征:词汇多样性、词汇复杂性、词频概貌、词汇错误和词汇密度,其中,词汇密度不太适合考察写作质量,故本文不把这一指标列入考察范围。本文中的词汇多样性包括实词数(总词数减去副词、介词、连词、助词、叹词、拟声词后的数量)、词种数、自然文本长度TTR(Type-Token Ratio)、控制文本长度TTR等4个指标①。词汇复杂性包括复杂词数和占比、复杂词种数和占比等4个指标,这里的复杂词语是指新HSK词汇大纲5级词语以外的词语,即6级词和超纲词。词频概貌包括常用词数和占比、次常用词数和占比、非常用词数和占比等6个指标,这里的常用词是指新HSK词汇大纲中的1—2级词,次常用词是指大纲中的3—4级词,非常用词是指大纲中的5—6级词和超纲词。词汇错误包括词语混用数和占比、生造词数和占比等4个指标。
1.词汇多样性与写作质量的相关性
我们对韩国汉语学习者看图写作文本的词汇多样性进行了归纳、统计,具体如表1所示:
从表1可以看出,从低分组到中分组,实词数和词种数分别增加了340个和246个,增幅分别为33.1%和25.1%;从中分组到高分组,实词数和词种数分别增加了83个和159个,增幅分别为6.1%和13.0%。低分组到中分组的增幅明显高于中分组到高分组的增幅。从低分组到高分组,实词数、词种数、控制文本长度TTR均与文本成绩成正比,但自然文本长度TTR呈“U”型,中分组最低,低分组略高于高分组。
我们使用spss25.0来计算看图写作文本质量与以上4个指标之间的Spearman相关系数。其中,|0.8|≤r<|1.0|为非常强的相关,|0.6|≤r<|0.8|为强相关,|0.4|≤r<|0.6|为中度相关,|0.2|≤r<|0.4|为弱相关,r<|0.2|为不相关。统计结果显示,看图写作文本质量与词种数(r=0.619,p<0.01)强相关,与实词数(r=0.499,p<0.01)中度相关,与控制文本长度TTR(r=0.394,p<0.01)弱相关,与自然文本长度TTR(r=-0.061,p=0.546>0.05)不相关。词汇多样性主要反映了词汇使用的广度,词种数越多,词汇量越大;实词数越多,文本信息越丰富。
2.词汇复杂性与写作质量的相关性
我们对韩国汉语学习者看图写作文本的词汇复杂性进行了归纳、统计,具体如表2所示:
从表2可以看出,复杂词数、复杂词占比、复杂词种数、复杂词种占比等4个指标,均与文本成绩成正比。低分组复杂词数和复杂词种数之间的差别远高于中分组和高分组的对应差别,这主要是因为低分组的学习者词汇量较小,同一个词常常多次使用造成的。从低分组到高分组,复杂词数、词种数均有较大幅度的增长,其中,低分组到中分组的增幅分别为70.8%、129.2%,中分组到高分组的增幅分别为58.5%、53.9%。
进一步的统计显示,看图写作文本质量与复杂词数(r=.574,p<.01)、复杂词种数(r=.571,p<.01)为中度相关,与复杂词占比(r=.278,p<.01)和复杂词种占比(r=.356,p<.01)为弱相关。这说明,随着学习者汉语水平的提高,词汇量也逐渐增大,他们对复杂词的使用也越发娴熟。
3.词频概貌与写作质量的相关性
我们对韩国汉语学习者看图写作文本的词频概貌进行了归纳、统计,具体如表3所示:
一般来说,写作水平从低到高,常用词的使用应该呈递减状态,次常用词、非常用词的使用呈递增状态。但从表3可以看出,不同组别的词频概貌呈现出比较复杂的情况。在常用词的使用方面,中分组的常用词总数和占比均为最高,但低分组比例和中分组差别不大;次常用词的数量虽然从低分组到高分组逐渐递增,但其占比呈U型;非常用词的使用和文本质量呈正比,从低分组到高分组逐渐递增。从总体上来说,低分组和中分组的词频概貌较为接近,中分组和高分组之间的差距远大于它与低分组的差距。
进一步的统计显示,次常用词数(r=.547,p<.01)和非常用词数(r=.574,p<.01),均与文本质量中度相关;常用词数(r=.265,p<.01)、常用词占比(r=-.277,p<.01)、次常用词占比(r=.211,p<.05)和非常用词占比(r=.285,p<.01),均与文本质量弱相关。这说明,尽量使用更多的次常用词和非常用词,有助于提升写作文本的质量。
4.词汇错误与写作质量的相关性
我们对韩国汉语学习者看图写作文本中的词汇错误进行了归纳、统计,具体如表4所示:
从表4可以看出,就不同组别来说,低分组最明显的错误是生造词,而中分组和高分组最明显的错误是词语混用。就词语混用来说,从低分组到中分组,数量有一定增加;但从中分组到高分组,降幅明显。就生造词来说,其数量和占比均与文本质量高低呈反比关系,从低分组到中分组再到高分组,降幅明显。
进一步的统计发现,生造词数(r=-.544,p<.01)和生造词占比(r=-.584,p<.01)与文本质量中度负相关,混用数(r=-.282,p<.01)和混用占比(r=-.371,p<.01)与文本质量弱负相关。这说明,生造词的错误会随着写作水平的提高而逐渐减少,但词语混用是写作中一个需要长期关注的问题,易混淆词语的辨析在相当长的时间内都会是教学的重点与难点。
(二)语法维度区别性特征与写作质量的相关性
Wolfe-Quintero等学者的CAF框架包括文本复杂性(Complexity)、准确性(Accuracy)和流利性(Fluency)三个指标。本文中的句法复杂性包括复句数量和占比、特殊句式数量和占比、平均句长、T单位平均小句数等6个指标。其中,特殊句式包括“把”字句、被动句、双宾句、连动句、比较句、兼语句、“是……的”强调句、“得”字句、存现句、主谓谓语句等10种,同一小句出现两种句式特征则统计两次。特殊句式占比的计算方法是特殊句式数除以所有小句数。平均句长是指文章总字数除以小句数。T单位的计算采用安福勇的方法[3],单句算作一个T单位;联合复句分句间没有主从关系,地位平等,因此,各算一个T单位;偏正复句有一个分句承担主要信息,另一个分句为补充,所以算一个T单位。T单位平均小句数的计算方法是小句总数除以T单位总数。准确性包括虚词错误数、有误特殊句式数、有误句子数、有误句子占比等4个指标。流利性包括总句数、总字数四次方根[15]、T单位平均长度(总字数除以T单位的个数)、无误T单位(没有任何词汇或语法方面错误)个数和占比等5个指标①。
1.句法复杂性与写作质量的相关性
我们对韩国汉语学习者看图写作文本的句法复杂性进行了归纳、统计,具体如表5所示:
从表5可以看出,句法复杂性特征下的6个指标,均与文本质量呈正比关系。从低分组到中分组,复句和特殊句式数量增幅分别为51.9%、147.8%,平均句长增幅为33.6%,T单位平均分句数增幅为12.0%。从中分组到高分组,复句和特殊句式数量增幅分别为25.3%、29.8%,平均句长增幅为25.6%,T单位平均分句数增幅为3.5%。可见,低分组和中分组之间的差距要大于中分组和高分组之间的差距。
进一步的统计表明,特殊句式数量(r=.603,p<.01)和文本质量强相关,复句数量(r=.538,p<.01)、平均句长(r=.590,p<.01)、复句占比(r=.485,p<.01)、特殊句式占比(r=.471,p<.05),均与文本质量中度相关;T单位平均分句数(r=.294,p<.01)与文本质量弱相关。这说明,在写作中增加句子长度、较多使用特殊句式和复句,有助于提升文本质量。
2.句法准确性与写作质量的相关性
句法准确性这一特征,这里主要是通过句法错误来描述。也就是说,错误越少,准确性越高,文本质量相应也越高。我们对韩国学习者看图写作文本中的句法错误进行了归纳、统计,具体如表6所示:
从表6可以看出,除了有误特殊句式数这一指标是中分组数值最高外,其余3個指标即虚词错误数、有误句子结构数、有误句子结构占比,均与文本质量呈反比关系。相对而言,中分组在句法准确性方面的表现更接近于低分组,从低分组到中分组的变化幅度远远小于从中分组到高分组的变化幅度。
进一步的统计表明,句法准确性特征下有误句子结构的占比(r=-.444,p<.01)和文本质量中度负相关,虚词错误(r=-.201,p<.05)、有误句子结构的数量(r=-.320,p<.01)和文本质量是弱负相关,有误特殊句式数(r=-.161,p>.05)和文本质量无关。可见,相对而言,评分者对虚词和特殊句式使用错误的容忍度,要高于普通句子发生错误的容忍度。
3.句子流利性与写作质量的相关性
我们对韩国汉语学习者看图写作文本的句子流利性进行了归纳、统计,具体如表7所示:
从表7可以看出,除了总句数这一指标呈抛物线形态(高分组最低、中分组最高)外,其他各项指标均与文本质量呈正比关系。进一步的统计表明,句子流利性特征中与看图文本质量达到强相关的指标有总字数四次方根(r=.664,p<.01)、无误T单位个数(r=.643,p<.01)和无误T单位个数占比(r=.679,p<.01),平均T单位长度与文本质量中度相关(r=.447,p<.01),总句数(r=-.0.043,p>0.05)和文本质量不相关。也就是说,对学习者而言,文章篇幅长一些,多用长句,句子结构正确,有利于取得更好的成绩。
三、不同维度下看图写作文本质量的
评估方程
为了进一步了解词汇维度和语法维度下不同区别性指标对新HSK5看图写作文本质量的影响,我们在回归分析的基础上,分别从词汇维度、语法维度、词汇和语法相结合的维度,建立了3个看图写作文本质量的评估方程。
(一)词汇维度下看图写作文本质量的评估方程
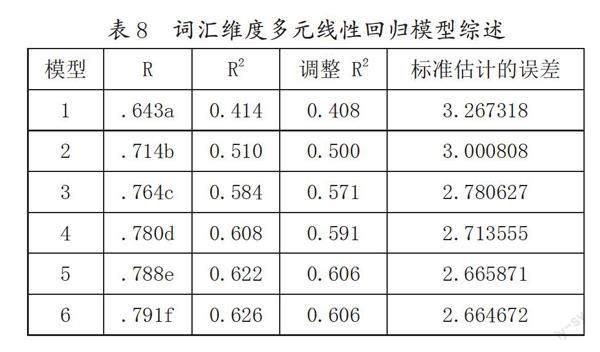
我们将词汇丰富性框架中的4个特征、20个区别性指标设为参数项,进行回归分析,并建立模型。具体数据如表8所示:
在表8中,a.预测变量:(常量),词种数;b.预测变量:(常量),词种数,生造词占比;c.预测变量:(常量),词种数,生造词占比,次常用词数;d.预测变量:(常量),词种数,生造词占比,次常用词数,复杂词数;e.预测变量:(常量),词种数,生造词占比,次常用词数,复杂词数,常用词数;f.预测变量:(常量),生造词占比,次常用词数,复杂词数,常用词数。统计显示,在多元线性回归分析中,生造词占比、次常用词数、复杂词数和常用词数4个参项进入回归模型,联合复相关系数为R=0.791,四者联合的R2决定系数为0.626,即可以联合解释作文成绩62.6%的方差,模型对数据的拟合情况较好。
我们又进行了自变量回归系数的显著性t检验,具体数据如表9所示:
从表9可以看出,生造词占比、次常用词数、复杂词数和常用词数均为有效预测参项,可以据此建立方程:
写作成绩=11.266+0.111×常用词数+0.339×复杂词数+0.342×次常用词数-38.633×生造词占比
以上四者的标准化回归系数由大到小为:0.355>|-0.345|>0.334>0.314,即次常用词数>生造词占比>复杂词数>常用词数。这说明,次常用词数对写作成绩的影响最大,其次是生造词占比和复杂词数,常用词数影响最小。
(二)语法维度下看图写作文本质量的评估方程
考虑到无误T单位的确定同时也涉及词汇错误的指标,为了使语法维度建立的预测方程指标更为纯粹,我们将这两个指标予以剔除。然后,将剩下的13个指标设为参项进行回归分析,并建立模型。具体数据如表10所示:
在表10中,a.预测变量:(常量),总字数四次方根;b.预测变量:(常量),总字数四次根,特殊句式占比;c.预测变量:(常量),总字数四次方根,特殊句式占比,总句数;d.预测变量:(常量),总字数四次方根,特殊句式占比,总句数,有误句子数。统计显示,总字数四次根、特殊句式占比、总句数、有误句子数4个参项进入回归模型,联合复相关系数为0.670,即可以联合解释作文成绩67%的方差,模型拟合情况较好。
我们又进行了自变量回歸系数的显著性t检验,具体数据如表11所示:
从表11可以看出,总字数四次方根、特殊句式占比、总句数、有误句子数等均为有效预测参项,可以据此建立方程:
写作成绩=-22.218+14.506×总字数四次方根+7.248×特殊句式占比-0.549×总句数-0.455×有误句子数
四者的标准化回归系数由大到小依次为:0.757>0.251>|-0.229|>|-0.129|,即总字数四次方根>特殊句式占比>总句数>有误句子数。这说明,总字数四次方根对写作成绩的影响最大,其次是特殊句式占比和总句数,有误句子数影响最小。
(三)结合词汇和语法维度建立的看图写作文本质量评估方程
按照上述程序,我们将词汇和语法维度下的33个指标设为参数项,进行回归分析并建立模型,得出方程如下:
写作成绩=-16.635+11.441×总字数四次方根+3.221×特殊句式占比+0.222×次常用词数-27.654×生造词占比-0.696×虚词错误数+4.944×复句占比-0.443×有误句子数-复句数×0.862
这个方程结合了词汇和语法两个维度,一共有8个指标项进入了回归模型。其中,词汇维度有3个区别性指标,语法维度有5个区别性指标。这几个指标与前文仅仅依据词汇维度和语法维度进入模型的指标略有不同,主要是因为词汇维度和语法维度中有些指标之间互相关联。这8个指标项的联合复相关系数为0.768,即可以解释作文成绩76.8%的方差。这一方程的解释力要优于单用词汇维度或语法维度建立的方程,但是由于进入模型的指标项较多,进行评估时相应地需要进行更多的前期准备。
需要指出的是,除了词汇和语法维度的指标外,写作文本的内容质量、上下文的连贯性和逻辑性、标点符号的使用等其他因素,也会对写作文本的质量产生一定影响。
四、讨论与建议
本文的研究语料来自新HSK5看图写作文本,在写作任务、文本长度和具体要求等方面,和汉语作为第二语言的其他写作任务体现出一定的差异。下面,我们就以本文的研究结果为基础,结合其他学者的相关研究,探讨影响写作文本质量评估的指标和不同方程对写作文本质量的解释度问题,并针对韩国汉语学习者的写作,提出一些切实可行的建议。
(一)影响写作文本质量评估的指标
通过上文的分析,可以发现,在词汇维度的4个特征18个指标中,有17个指标与看图写作成绩呈现出强弱不同的相关性。相关系数较高的6个指标项分别是:词种数、生造词占比、非常用词数、次常用词数、复杂词数和生造词数。结合王艺璇的相关研究[11],我们发现,写作文本体裁、题材、长度和任务不同,影响写作质量的词汇因素也有一定差异。
就词汇多样性特征而言,两项研究中,写作成绩与各因素的相关性序列趋势基本相同,词种数是与写作文本相关性最高的指标,实词数/词数居于第二位,自然文本长度TTR与文本质量不相关。
就词汇复杂性特征而言,在王文中,复杂词种数和占比均优于复杂词数和占比的相关性;我们统计的结果是,复杂词和词种数量与写作质量的相关性均优于复杂词和词种的占比,这应该与看图写作文本普遍较短有关。
就词频概貌特征而言,表面上看两个统计相关性指标有较大不同。王文的统计结果显示,无论是词形数还是词种数,均是最常用词与写作文本的相关性最高,为负相关,最常用词用得越多,文本质量越低。本文的统计结果是,次常用词数和非常用词数相关性最高,为正相关,这两类词用得越多,文本质量越高。这个结论,一方面,反映了硬币的正反两面,在文本中,常用词使用越多,相对而言,次常用词和非常用词则使用越少;另一方面,也与两篇论文的词频等级分类标准不同有较大关系,新HSK词表不仅数量较少,而且难度较低,它的次常用词、非常用词有较多属于王文中的最常用词、常用词或次常用词等级。
就词汇错误特征而言,王文发现,词汇错误占比与写作成绩的相关性高于词汇错误数量,但未讨论每种错误与写作成绩的相关性;我们发现,词汇错误中,生造词占比、生造词数与写作质量相关性最高。此外,王文统计的指标相关系数明显高于我们的统计结果,这可能与其样本量更大、文本更长有一定的关系。
在语法维度的3个特征15个指标中,有13个指标与写作文本质量呈现出强弱不同的相关性。强相关因素有4个,分别是无误T单位占比、总字数四次方根、无误T单位个数、特殊句式数量。其中,有3个指标都居于流利性特征之下,并且2个指标均与无误T单位有关,这说明能够正确地输出T单位是写作水平较高的主要标志。考虑到T单位测量框架内的指标实际上是兼顾了复杂性和正确性的复合型指标,因此,它和写作质量相关性比较强是可以预见的结果。特殊句式数量指标为本文首次单独设立,它和写作文本质量也是强相关的关系。吴继峰等学者曾以语言特征和内容质量为测量维度,对韩语母语者汉语二语写作质量进行了评估研究,该研究显示,语法正确性和句法复杂性均与写作成绩相关,相关系数分别为0.439和0.415[5]。我们的研究结果和吴继峰等学者的研究结果大体一致。
(二)不同方程对写作文本质量的解释度
如前所述,我们分别从词汇维度、语法维度、词汇和语法相结合的维度出发,构建了三个质量评估方程,以预测看图写作文本的质量。通过对这三个方程以及与其他学者所建立的方程的比较,我们得出三点结论:
第一,就单个维度来说,语法维度的方程优于词汇维度的方程。词汇维度使用4个预测指标,可以解释写作成绩总变异的62.6%;语法维度同样使用4个指标,却可以解释写作成绩总变异的67%。这是因为词汇和语法常常界限模糊,难以截然分开。如HSK语法大纲中的部分条目其实就是属于词汇范围的;同时,由于一个句子是由多个词语按照特定的规则组合生成的,所以语法维度中的无误T单位这一指标,实际上同时反映了学习者正确选用词语和组合词语的能力。语法维度主要是综合能力的考察,因此,根据其区别性指标建立的方程自然要优于词汇维度建立的方程。
第二,在可操作性和使用便利度方面,三个方程体现出一定的差异性。结合词汇和语法维度所建立的方程,虽然解释力明显高于仅仅依据词汇或语法单一维度建立的方程,但后两者使用的指标数量较少,相对来说,具有更强的可操作性。在计算机自动评分时,可以根据实际情况的需要,在评分的有效性和操作的便利性之间进行权衡。
第三,本研究根据词汇维度建立的方程解释力,跟王艺璇构建的方程有较大差别[11]。王文认为,词种数、词汇错误比重、常用词数三者联合的R2,可以解释作文成绩92.8%的方差。我们对此持怀疑态度,因为即使一篇作文在这3个指标上表现良好,但如果偏离主题或逻辑性不强,也很难得到高分。决定写作质量的除了词汇方面的指标之外,还有语法表现、内容质量和标点符号的使用等因素。虽然我们与吴继峰等学者的考察对象不同[5]、[12],具体指标设置和计算方法也有一定差异,但在研究结果方面,表现出较强的一致性。
(三)面向韩国汉语学习者的写作建议
从上文的分析可以看出,低分组的学习者由于词汇量有限,导致写作中出现词种总数较少而生造詞较多的现象,生造词和句子结构杂糅是造成作文得分较低的主要原因。因此,学习者除了努力扩大词汇量、提升正确运用词汇的能力以外,还需要将句子写长,并有意识地使用特殊句式,提高语法的复杂度。
中分组的学习者文章篇幅基本达标,有明确的使用复杂词和特殊句式的意识,但语法错误较多,这是被高分组拉开差距的主要原因。这一水平的学习者,应该有意识地加强复杂词语和特殊句式的使用,并通过多种途径提高正确率,尽量减少语法错误。
高分组的学习者在词汇使用的广度和深度方面表现良好,会使用多种类型的复句,特殊句式使用的准确率也较高,其错误主要集中在词语混用方面。这说明对学习者而言,掌握了基本的语法规则以后,词汇学习仍然任重道远。
(本文在撰写时曾得到汉考国际教育科技[北京]有限公司的数据支持,谨致谢忱!)
参考文献:
[1]翟艳.汉语口语成绩测试评估标准[J].华文教学与研究, 2012,(1).
[2]Jiang,Wenying.Measurements of development in L2 written production:The case of L2 Chinese[J].Applied Linguistics,2013,(1).
[3]安福勇.不同水平CSL学习者作文流畅性、句法复杂度和准确性分析——一项基于T单位测量法的研究[J].语言教学与研究,2015,(3).
[4]金檀,刘力,郭凯.口语测试评分标准研究与实践三十年[J].现代外语,2016,(6).
[5]吴继峰,周蔚,卢达威.韩语母语者汉语二语写作质量评估研究——以语言特征和内容质量为测量维度[J].世界汉语教学,2019,(1).
[6]李亚男.汉语作为第二语言测试的作文自动评分研究[D].北京:北京语言大学硕士学位论文,2006.
[7]梁茂成.中国学生英语作文自动评分模型的构建[D].南京:南京大学博士学位论文,2005.
[8]徐昌火,陈东,吴倩,谢沚蓝.汉语作为第二语言作文自动评分研究初探[J].国际汉语教学研究,2015,(1).
[9]王佶旻.三类口语考试题型的评分研究[J].世界汉语教学,2002,(4).
[10]陈默,李侑璟.韩语母语者汉语口语复杂度研究[J].语言文字应用,2016,(4).
[11]王艺璇.汉语二语者词汇丰富性与写作成绩的相关性——兼论测量写作质量的多元线性回归模型及方程[J].语言文字应用,2017,(2).
[12]吴继峰.韩语母语者汉语书面语句法复杂性测量指标及与写作质量关系研究[J].语言科学,2018,(5).
[13]Wolfe-Quintero,K.,Inagaki,S.& Kim,H.-Y.Second language development in Writing:Measures of fluency, accuracy and complexity[M].Honolulu:University of Hawai‘i Press,1998.
[14]陈贤纯.对外汉语教学写作课初探[J].语言教学与研究,2003,(5).
[15]陈东.基于文本特征提取的汉语L2作文电子评分系统初探[D].南京:南京大学硕士学位论文,2013.
A Study on the Quality Assessment of the Korean Chinese-Learners Writing
——A Discussion Based on the Writing Texts of Picture-Reading-and-Writing in New HSK5
Wang Shuhua1,Zhu Yiling2
(1.College of Liberal Arts, Shanghai University, Shanghai 200444;
2.English Teaching and Research Group, Seven-Color Flower Elementary School, Shanghai 200020, China)
Abstract:This paper takes Korean Chinese-learners 99 writing texts of Picture-Reading-and-Writing in new HSK5 as the research object. It sets up 7 characteristic items and 33 distinguishing indicators from the two dimensions to examine the correlations between these indicators and the quality of the writing texts. The study show that multiple indicators of both the vocabulary dimension and the grammar dimension are strongly or moderately related to the quality of the writing texts. The explanatory power of the equation established using the grammar dimension indicators is better than that of the equation established using the vocabulary dimension indicators. Although the equations built combining the vocabulary and grammatical dimensions have stronger explanatory power, more predictive variables are used and thus the difficulty of operation is increased.
Key words:Korean Chinese-learners;Picture-Reading-and-Writing;quality assessment;vocabulary dimension;grammar dimension;prediction equation
基金项目:国家社会科学基金项目“英语和汉语作为外语的综合性写作测评研究”(17BYY108)
作者簡介:1.王淑华,女,上海大学文学院副教授,文学博士;
2.朱伊苓,女,上海七色花小学英语教研组小教二级,教育学硕士。
①Read采用TTR来计算词汇多样性,计算方法是文本中词种数与总词数之比。一个词在文本中出现多次仅计为1个词种,但每次出现均计入词数。为了减少文本长度的影响,同时考虑到99篇文本中字数最少的1篇为33字,因此,我们将33字设为控制文本长度,其他篇目均从第二个任意标点符号开始截取33个字作为控制文本,这部分文本中的词种数和总词数的比例即为控制文本TTR。
①陈东指出,短文长度、短文长度的四次方根和词类型的数目,是测量语言流利性的3种最普遍的指标;但他采用回归模型实验后发现,短文长度的四次方根的指标的预测结果优于其他两项[15]。因此,本文也采用了文本总字数四次方根这个指标。
猜你喜欢
价值工程(2017年20期)2017-07-10
现代电子技术(2017年13期)2017-07-08
山东工业技术(2017年12期)2017-07-06
青年时代(2017年17期)2017-07-03
科学与财富(2017年13期)2017-05-31
大学教育(2017年4期)2017-04-13
计算机应用(2016年12期)2017-01-13
中国市场(2016年5期)2016-03-07
世界教育信息(2015年22期)2016-01-06
高教探索(2015年10期)2015-10-29
