
基于BOA-LSTM模型的土壤湿度预测
2023-06-23 09:34肖天云张子晨魏佳妹刘凤春韩阳
华北理工大学学报(自然科学版) 2023年3期
肖天云,张子晨,魏佳妹,刘凤春,韩阳
(1. 华北理工大学 唐山市工程计算重点实验室,河北 唐山 063210;2. 华北理工大学 学科建设处,河北 唐山 063210;3. 华北理工大学 理学院,河北 唐山 063210)
随着时代进步与科技发展,人们的生活水平不断提高,对保护生态文明和自然环境的重要性的认识日益提高。草原作为世界上分布最广的重要陆地植被类型之一,在维护生物多样性、涵养水土、净化空气、固碳、调节水土流失和沙尘暴等方面具有重要的生态功能。中国的草原面积约为3.55亿 hm2,是世界草原总面积的6%~8%,居世界第二。草原作为自然环境的重要组成部分,其沙漠化和板结化现象所造成的土壤干旱化、盐渍化和水土流失等情况,对维护生态平衡与多样性产生严重影响。在现实情况中,常将土壤湿度作为草原沙漠化和板结化程度判定的重要指标,因此,对草原环境的土壤湿度进行回归分析以及预测,对保护和改善草原生态环境有着重大意义[1]。该项研究选取锡林郭勒草原作为研究对象,对气象条件、植被系数和土壤湿度数据集进行预处理,对数据进行缺失值处理、重复值处理以及使用主成分分析(PCA)方法进行数据降维。
该项研究选取长短期记忆网络(Long Short-Term Memory,LSTM)构建土壤湿度的预测模型,长短期记忆网络基于循环神经网络(Recurrent Neural Network,RNN)所提出,广泛应用在时间序列类型数据的回归分析和预测上[2]。目前,国内外对LSTM模型的研究与运用处在前中期阶段,LSTM模型还具有很大的发展空间和庞大的应用场景,应用LSTM模型解决实际问题对其发展有着十分重要的影响[3]。为了证明LSTM模型的可行性和分析结果的直观性,分别选取岭回归(Ridge Regression,RR)算法、支持向量机(Support Vector Machine,SVM)算法、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法[4]作为对比实验。对训练后的模型进行评估和测试,选取平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)、差异解释得分(EV)和判定系数(R2)对各个算法模型的应用效果进行比较。
LSTM模型内部有着众多超参数及参数空间,超参数的选取和模型优化过程是LSTM算法构建回归模型中的重要一环,直接影响模型实际效果和预测结果,因此需要选取合适的参数优化算法对LSTM模型进行改进。该项研究选取贝叶斯优化算法(Bayesian Optimization Algorithm,BOA)进行超参数调优,BOA是一种基于贝叶斯定理来寻找目标函数极值的方法,在迭代过程中,根据之前观测到的历史数据进行下一次优化,直到达到最大的迭代次数。相比于网格搜索和随机搜索等优化算法,BOA的迭代次数较少并且迭代过程中会考虑之前的参数信息,效率有着较大提升,同时在非凸问题下仍具有稳健性。BOA通过多次迭代计算得到一组或者多组超参数,回带到LSTM模型中后与调参前的LSTM模型算法进行对比实验,比较得到BOA对LSTM模型效果的提升情况。最后根据锡林郭勒草原的历史数据,运用BOA优化后的LSTM模型,对未来的土壤湿度情况完成预测。
1长短期记忆网络模型
随着深度学习和人工智能的发展,对神经网络的研究日益加深,如今已经设计出循环神经网络(RNN)、深度神经网络(DNN)、卷积神经网络(CNN)、生成对抗网络(GAN)等不同神经网络类别,长短期记忆网络(LSTM)则属于其中的RNN类型。满足按照时间顺序、逻辑顺序或者其他顺序排布的数据称作序列类型,例如股票价格是按照时间的推移而变化,自然语言的表达需要依靠字词按照逻辑顺序排布。RNN的特点为输入是序列类型的数据,并在序列的前进方向进行循环递归,RNN的内部结构如图1所示,其中X、S、O分别为输入层、隐藏层和输出层的值,U、V、M为权重矩阵[5]。

图1 RNN结构模型
RNN模型中隐藏层的值St不只取决于当前时刻输入层值Xt的大小,还取决于上个时刻的隐藏值St-1的大小。以下为RNN的计算公式,其中f、g为激活函数,b、c是偏差变量。
St=f(UXt+WSt-1+b)
(1)
Ot=g(VSt+c)
(2)
RNN模型中的每层隐藏单元只执行一个简单的tanh或者Relu操作,激活函数tanh的取值范围是(-1,1),控制RNN模型记住信息多少或忘记信息多少。而在传统RNN中,如果模型层次太深会造成梯度消失或者梯度爆炸情况的产生,当最后时刻的梯度大小几乎为0或非常大的时候,启用激活函数Relu将梯度置于0或者1。但是这种方法会使得RNN中较远时间外的梯度消失了,从而无法进行长期依赖。
对传统RNN模型进行改进后得到的LSTM模型,由当前时刻的输入Xt、细胞状态Ct、隐层状态ht、遗忘门、记忆门和输出门组成,其内部结构如图2所示。LSTM模型可以总结为,对细胞状态Ct的信息进行遗忘和记忆新的信息,对后续时刻的计算舍弃无效信息,传递有效信息,并在每个时间步长时输出隐层状态ht,遗忘、记忆和输出的信息由通过上个时刻的隐层状态ht-1和当前输入的Xt计算出来的遗忘门、记忆门和输出门控制。通过更新记忆细胞和遗忘门控制记忆或遗忘信息,使得当前记忆单元对上一个记忆单元的偏导数为常数,能够很好地解决无法长期依赖的问题。

图2 LSTM结构模型
2超参数优化算法
机器学习算法在构建回归模型或分类模型的时候,需要考虑对其超参数进行优化以提高模型的精度。常见的超参数优化方法例如网格搜索法、随机搜索法、穷举搜索法,实际效果并不理想,无法同时保证搜索效率和模型精度达到预计情况。在非凸问题下,随机搜索法和网格搜索法常面临着搜索到的超参数只是局部最优的情况。为避免以上情况的发生,选取贝叶斯优化算法(BOA)作为全局优化算法,对该研究的LSTM模型进行超参数搜索。
2.1 贝叶斯优化原理
贝叶斯优化算法(BOA),主要针对目标函数未知或者计算目标函数的时间成本过大的情况,只需确定输入和输出,无需知道算法结构内幕模型和数学性质的黑盒优化问题,如图3所示为黑盒优化模型[6]。

图3 黑盒优化模型
相比于网格搜索法、随机搜索法,基于贝叶斯定理构建的BOA在寻找目标函数最大值或最小值的时候,每次迭代过程中都会根据之前的搜索结果来进行下一次搜索,而不是在搜索区间内进行穷举运算,对每种超参数组合进行计算与比较对应的目标函数结果。这种方法大大提升了搜索效率,且避免了局部最优情况的发生,以下为贝叶斯定理的公式形式[7]。
(3)
2.2 贝叶斯优化步骤
贝叶斯优化算法经过多次迭代,根据先验函数与采集函数搜索最佳的超参数组合,贝叶斯优化的流程如图4所示。
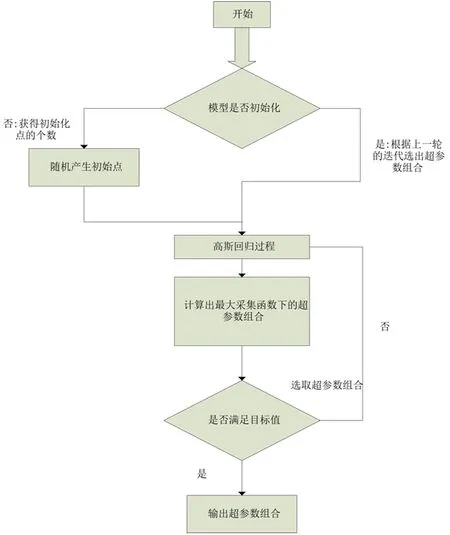
图4 贝叶斯优化算法的流程图
贝叶斯的优化步骤大概分为以下几步:
(1)最大化采集函数,得到下个输入点;
(2)计算目标函数值;
(3)整合数据并且更新先验函数与观测模型;
(4)重复上述步骤至迭代完全结束。
对于超参数调优过程来说,选取LSTM模型的units、epochs、batch_size和validation_split参数作为超参数搜索对象,选取均方误差作为目标函数,通过多次迭代计算得到的最优结果如表1所示。

表1 BOA对于LSTM模型确定的超参数空间
3锡林郭勒草原土壤湿度数据集的回归分析
该项目选择锡林郭勒草原作为研究对象,通过阅读文献和查阅统计年鉴,收集2012~2021年内的气候数据以及土壤湿度数据作为原始数据。选取岭回归(RR)算法、支持向量机(SVM)算法、梯度提升决策树(GBDT)算法进行对比实验,选用平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)、差异解释得分(EV)和判定系数(R2)作为评价指标分析各个模型之间效果差异[8]。
3.1 数据预处理
研究所收集到的数据集中包含土壤蒸发量、植被系数、径流量、平均气温等15种特征,由于历史原因,需要对数据集进行重复值处理、异常值处理和缺失值处理的操作,提高数据的可信度和真实性。
在获取数据的过程中,可能出现收集到重复数据的情况,重复数据的存在会使回归模型的预测结果出现偏差。因此,使用Python软件中的duplicate函数对数据进行判定,若不同样本之间的特征值全部相同,则判定样本为重复样本并将其删除。
由于缺失值的存在会对回归模型的构建产生影响,显著降低模型预测的准确程度,应对数据集中的缺失值进行相关处理。该研究对缺失值的处理方法主要包括以下几种:
(1)均值插补:用该类数据的均值替换缺失值。
(2)直接删除:对于样本数量较多的数据集,对其中的部分缺失值采用直接删除的方法进行处理。
由于数据集中各个特征的单位和数量级并不相同,为了构建回归模型,需要将各个特征数据进行标准化。该项研究采用Min-Max标准化的方法,对原始数据进行线性变化,映射到[0,1]区间上,便于回归模型的建立与分析。Min-Max标准化可用公式(4)表达:
(4)
该项研究使用主成分分析(PCA)方法对原始数据进行降维处理,将数据集中的15维特征降至10维。通过PCA降维方法,最大程度保留了大部分信息,消除了原始数据之间相互影响的因素。以下为PCA降维的主要步骤:
(1)输入原始数据到PCA降维模型中;
(2)通过线性变化将数据集映射到新的坐标系;
(3)计算各成分的方差,按照方差大小选取最大的前10项。
3.2 评价指标
选用平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)、差异解释得分(EV)和判定系数(R2)作为评价指标估计各个模型的性能。评价指标的计算公式表示为:
(5)
(6)
(7)
(8)
(9)
MAE是指模型预测值f(x)与真实值y之间绝对误差的平均值,能够直观的展示出模型预测的准确程度,其值越大,模型预测的误差越大;RMSE是指预测值与真实值的平方误差和样本数量n之间的平方根,对异常值更为敏感,能够更好地说明模型预测的误差大小;MAPE常用于衡量模型的预测准确性,MAPE的值越小,说明模型拥有更好的精确度;EV常用于判断模型偏差程度,当预测值与真实值相同时,EV等于1,当EV越小时,模型的预测偏差越大;判定系数又称拟合优度、绝对系数,当R2越接近1的时候,该模型的拟合程度越高。
3.3 土壤湿度的预测分析
将经过预处理后得到的数据输入到算法模型中,构建回归分析模型对历史数据进行拟合,如图5所示分别为RR、SVM、GBDT和LSTM算法模型的拟合效果图。
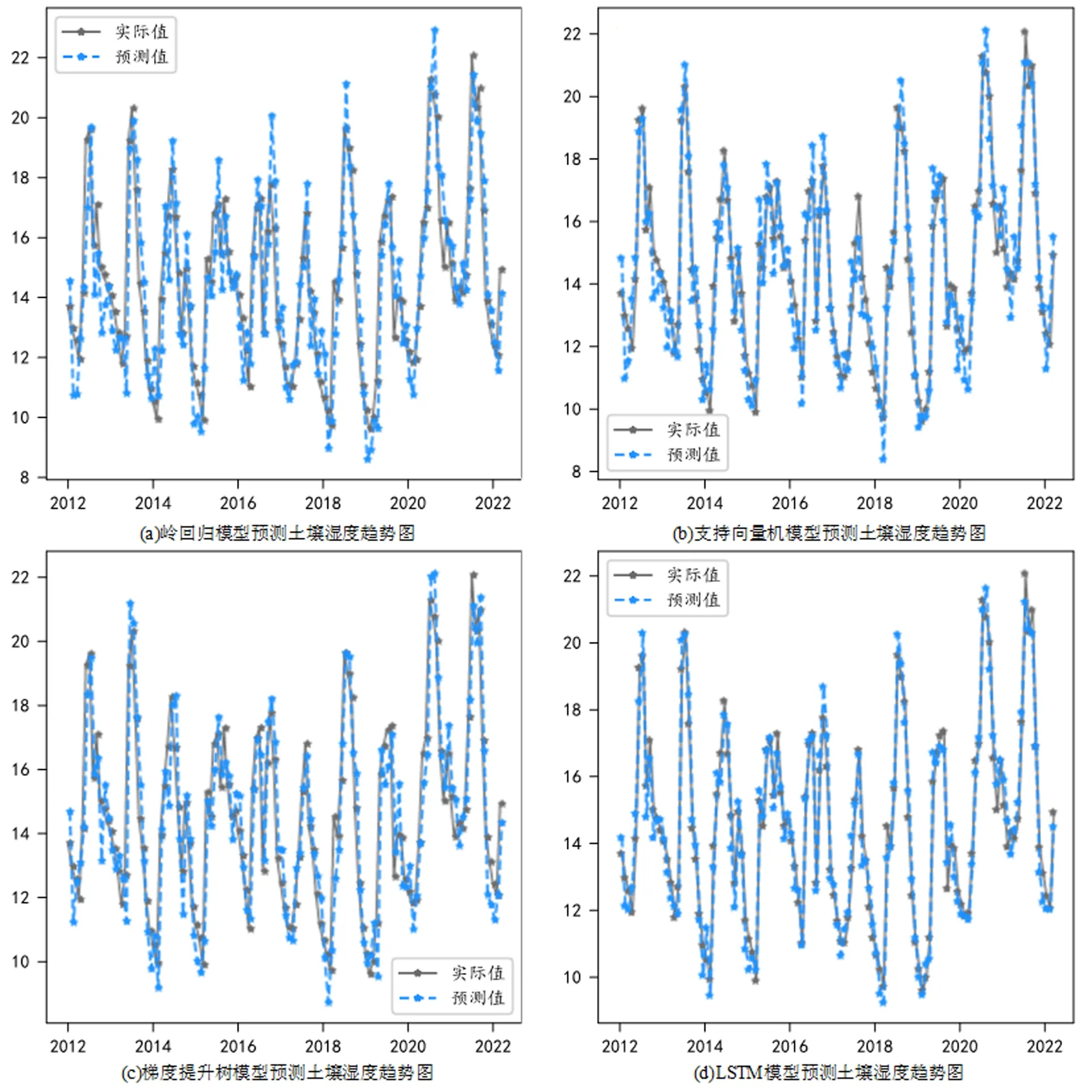
图5 历史土壤湿度数据拟合效果对比
通过图5分析得到,岭回归模型的拟合效果较差,拟合数据在某些时刻产生较大的波动,LSTM模型和GBDT模型的拟合效果较为良好,拟合程度较高[9]。为了进一步得到模型效果的具体数据,采用统计指标MAE、RMSE、MAPE、EV和R2对拟合效果进行评估分析,表2为不同算法模型的指标分析结果。

表2 模型统计指标结果分析
通过分析表2得到,RR和SVM模型的效果较差,而GBDT和LSTM模型由于在训练模型的过程中会对误差进行多次迭代,因此模型的拟合程度较高[10]。以上算法中LSTM模型的效果最为优异。
对算法进行超参数调优能够大大提升模型的性能与效果[11],因此选用贝叶斯优化算法对LSTM模型进行超参数优化,构建BOA-LSTM回归分析模型与LSTM模型进行对比实验,其中拟合效果如图6所示,算法模型效果对比如图7所示。
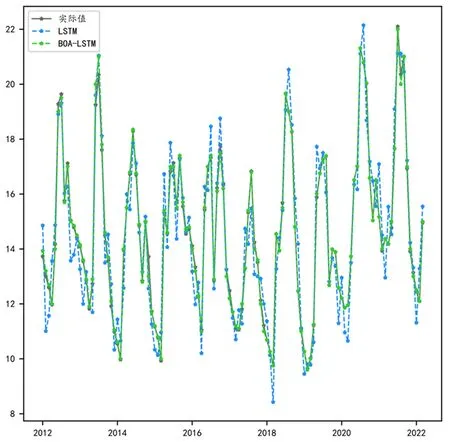
图6 BOA-LSTM模型与LSTM模型的拟合数据对比
由图6可以得到,经过贝叶斯优化后的LSTM模型的拟合效果得到明显提升,从图上可以看出BOA-LSTM已经有着相当优异的拟合结果。
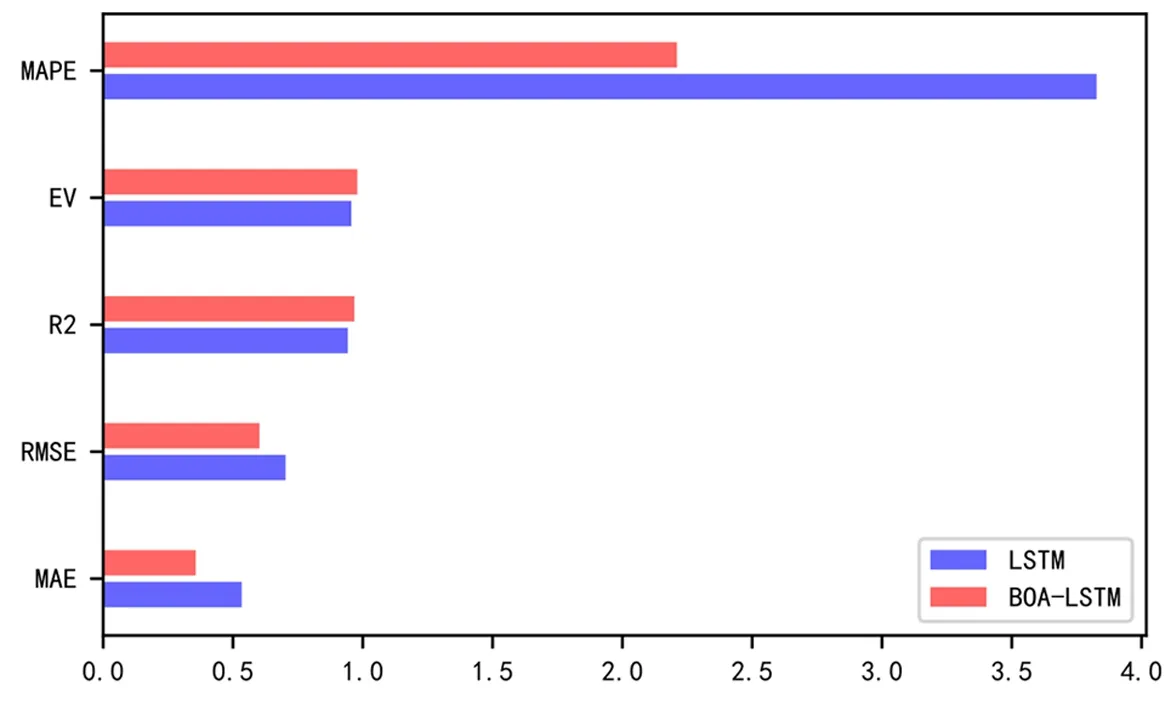
图7 BOA-LSTM模型与LSTM模型的统计指标对比
由图7所得,BOA-LSTM模型的各项指标均优于优化前的LSTM模型,其中MAPE达到2.3492,MAE达到0.3078,优化算法提高了模型效果且拟合误差有着明显改善。
由于BOA-LSTM模型的性能优于其他对比算法,且适合处理时间序列数据和预测未来数据,因此导入历史数据构建基于BOA-LSTM算法的土壤湿度预测模型,对锡林郭勒草原上2022、2023年的土壤湿度进行预测。图8为BOA-LSTM模型对锡林郭勒草原上的土壤湿度预测图,其中实线代表2012至2021年的土壤湿度数据,虚线代表BOA-LSTM模型预测的结果。

图8 BOA-LSTM模型预测未来土壤湿度
4结论
(1)通过进行对比实验的方法,比较岭回归(RR)、支持向量机(SVM)、梯度提升树(GBDT)和LSTM模型在锡林郭勒草原土壤湿度数据集的回归分析中的性能,分析得到LSTM模型在平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)、差异解释得分(EV)和判定系数(R2)统计指标上分别为0.533 6,0.702 7,3.826 9,0.956 1,0.942 2,相比于其他算法平均提高27.03%,19.35%,20.47%,3.39%,5.08%。选取贝叶斯优化算法对LSTM模型进行超参数优化,并与优化前的模型进行对比,分析得到贝叶斯算法优化后的LSTM模型在以上指标上分别为0.356 4,0.602 1,0.967 6,0.979 1,2.211 2,各项指标分别提高33.21%,14.33%,42.25%,2.39%,2.69%。
(2)BOA-LSTM模型效果较好,与锡林郭勒草原土壤湿度数据拟合程度高,对预测锡林郭勒草原土壤湿度数据有着一定参考价值。随着机器学习和神经网络算法的发展,研究与应用LSTM模型对指导现实发展有着重要意义,BOA-LSTM模型将会应用在更多领域,如癌症患者数据分析、房产价格预测等。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
天津农林科技(2020年3期)2020-08-13
今日中国·法文版(2020年7期)2020-07-04
电子制作(2019年15期)2019-08-27
中国特种设备安全(2019年1期)2019-03-13
数理化解题研究(2017年4期)2017-05-04
铁道通信信号(2016年6期)2016-06-01
山东青年(2016年2期)2016-02-28
高原山地气象研究(2016年4期)2016-02-28
高原山地气象研究(2016年4期)2016-02-28
