
基于过采样和代价敏感技术的软件缺陷预测
2023-06-23 09:34王文彪张春英马英硕
华北理工大学学报(自然科学版) 2023年3期
王文彪,张春英,马英硕
(1. 华北理工大学 理学院,河北 唐山 063210;2. 河北省数据科学与应用重点实验室,河北 唐山 063210;3. 唐山市工程计算重点实验室,河北 唐山 063210)
人工智能时代背景下,对于软件行业来说软件缺陷预测是验证软件质量的一个有效途径[1]。基于机器学习的软件缺陷预测是一个二分类问题,是对软件“有缺陷”与“无缺陷”的判定[2]。同时,机器学习方法是利用历史软件缺陷数据进行一次性建模[3]。与传统的人工测试方法相比,在软件行业中利用机器学习方法测试软件是否有缺陷,不仅提高了效率,还节省了不少的人力和财力[4]。在这种高效率的驱动下,软件缺陷技术得到了很大的发展。然而,软件每天都在产生大量的数据。面对与日俱增的“新数据”,传统的机器学习方法需要重新进行多次建模,即使在耗费时间的情况下也难以保证较好的效果。因此,有研究者提出了增量式机器学习,以解决现有软件缺陷预测中存在的问题[5]。
集成式增量学习注重对海量数据的全面的学习。例如典型的Learning++算法[6-10],这种算法的主要思想是在保留所有数据的前提下基于基模型对数据进行训练,由于Learning++算法保留了“之前数据”与“新增数据”,而“新增数据”与“之前数据”存在类不平衡问题,这种算法未对数据的不平衡进行处理,只是对基模型的简单集成,因此直接影响到了分类器的分类效果。
针对上述问题,提出了类不平衡的缓解方法SCS算法(Class Imbalance Mitigation Algorithms),以时间序列为前提获取软件数据流,将过采样技术与代价敏感技术相结合,以此提升预测模型对潜在缺陷数据的搜索范围。通过实验比较,表明该方法可有效提升算法的分类精度,在召回率指标上表现优异。
1相关工作
1.1 代价敏感方法
代价敏感学习是通过给不同类型的样本赋予不同的权值,使其能够进行机器学习[11-19]。在常规的学习任务中,样本的权重基本相同,但在一些特殊的任务中,也可以对样本赋予不同的权重。对风险控制和入侵检测来说,这2种类型的数据都存在着严重的不均衡性,比如风险控制模式[20],算法重点放在坏人的分类上,增加坏人的查全率,但是也可能把好用户分类为坏用户,降低坏用户分类的查准率。
在软件故障的历史资料中[21],只有少量的故障数据和大量的无故障数据,即存在着严重的不平衡。对不均衡的数据直接训练,得出的预测结果会对大部分的小类别数据产生较大的偏差,导致预测效果不佳。由于分类误差在实际中的影响很难估计,故采用成本敏感技术来减轻这种不均衡[22]。
代价敏感性技术是由于算法对目标项的错误分类成本不同而导致的[23]。基于最大类的算法和基于成本敏感性技术的分类误差成本,通过调整2种分类结果的不同权值,实现了少类和多类的均衡。表1所示为软件缺陷预测问题的代价矩阵。
表1中的C(x1,x2)为代价因子表达式,x通过符号“1”,“0”表示,“1”表示软件模块有缺陷,“0”表示软件模块无缺陷。当x1=x2时,代价表达式α为0,即预测结果正确;当x1≠x2时,说明预测结果错误,文献[24]最早提出在软件缺陷预测中不同的分类错误造成的代价是不同的,当把缺陷模块预测为无缺陷时,则此缺陷在软件中一直存在,使得软件不可靠;当把无缺陷模块预测为有缺陷,会导致无用测试,浪费资源,但不会有致命的损失,所以有代价表达式C(1,0)>C(0,1)C(1,0)>C(0,1)。当α= 1 时,表示错误分类的代价相等,当α> 1时,表示将有缺陷模块预测为无缺陷的代价要高。其中C(1,0)表示将有缺陷模块预测为无缺陷,C(0,1)表示将无缺陷模块预测为有缺陷。
当分类器错分时,设代价函数:F(x)=P{(x,1)}*C(0,1)+P{(x,0)}*C(1,0)其中代价函数F(x)表示对软件模块x进行缺陷预测的期望代价,对于模块x,最小化F(x)等同于选择最优的缺陷预测分类结果,P{(x,i)}表示把模块x预测为i类的概率;C(x1,x2)表示代价矩阵中对应模块的代价因子表达式。
1.2 SMOTE过采样技术
SMOTE算法的思想是合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本[25]。图1所示为SMOTE过采样示意图。

图1 SMOTE采样示意图
对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
根据样本不平衡比例,设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。对于每一个随机选出的近邻xn,分别与原样本,按照如下的公式构建新的样本。
xnew=x+rand(0,1)×(xn-x)
(1)
2类不平衡的缓解方法
类不平衡缓解算法SCS(Class Imbalance Mitigation Algorithms)以时间序列为前提获取软件数据流,融合过采样与代价敏感技术,构建代价敏感与过采样的增量模型,提升预测模型对潜在缺陷数据的搜索范围。
2.1 算法框架与实现
软件数据窗口通过设定的过采样技术缓解软件数据窗口中的类不平衡问题,最终得到用于训练基分类器的软件数据窗口。SCS算法通过对软件数据进行采样后训练基分类器加入集成模型之后完成对集成模型的更新。SCS算法框架流程如图2所示。

图2 算法流程图
(1)软件数据:软件数据以数据流的形式到达,设置存储空间保留数据流,并统计数据流数量,当存储空间到达阈值M时完成其中一个数据块的构建。
(2)代价敏感权重设置:普通基分类器对于数据分布不平衡的情况没有较好的处理效果,所以SCS算法中通过设置敏感代价因子,将不同类型的样本数据赋予不同的权重,重点关注分类错误但损失大的样本,来减缓权重的递减速度,从而达到更好的分类效果。
(3)进行采样:因为软件数据流具有随机性与不平衡性,因此基于时间序列构建的数据块中正类样例和负类样例的占比严重失衡,为缓解不平衡数据集给分类模型带来的困扰,SCS算法中引入Smote过采样使得正类样例与负类样例占比相等。对于少数类的每一个样本x计算其与少数类样本集中其他所有样本的欧式距离,并随机选出近邻xn,与原样本构建新的样本。
(4)训练基分类器加入集成模型:数据块随着数据流的不断产生而持续增加,利用采样后的数据块直接训练基模型,若基分类器的数量小于集成模型中的基分类器数量阈值M时,训练结束的基分类器可直接加入集成模型中。
(5)完成集成模型更新:当集成模型中基分类器个数等于阈值M时,每当有最新的基分类器加入,则删除最原始的基分类器,保证集成模型中的基分类器数量始终等于阈值M,完成更新。
(6)若存在数据流持续流入则重复操作,否则输出集成模型。
2.2 代价因子与采样比例设定
在解决数据类不平衡问题上,从算法层面提出了代价敏感。在软件缺陷预测中,将有缺陷数据误判为无缺陷数据需要付出更大代价。因此,通过设置代价敏感因子对软件数据集做平衡处理,在模型学习阶段,选择代价因子进行实验,并采用十折交叉验证方法对测试集进行验证,得出最优的软件缺陷类不平衡采样比例。通过代价敏感方法对数据集的不平衡处理可有效提升模型性能。
代价因子的取值与采样比例的确定决定着模型的预测性能,为保证取值的科学有效性,分别设置代价因子α的取值实验以及采样比例的实验。由于缺陷预测的准确率可直观展示分类器的预测性能,因此选择准确率作为参数确定的标准。
实验1给出实验中代价因子α的选择过程。在采用SCS算法构建预测模型时,代价因子α≥1。当α=1时,表示错误分类的代价相等;当α>1时,表示将有缺陷模块预测为无缺陷的代价要高。为了得到准确率较高的代价因子α,分段设置不同的α参数,通过对比实验,发现当α=30的时候,其获得的准确率数值相对较高,所以选取α=30作为最终代价敏感因子。表2中所示为不同代价因子取值时所获得的准确率数值。
同代价因子α的选择过程一样,在选择采样比例的时候也是通过对比实验进行,发现当采样比例1:1时,其准确率数值相对较高。实验2给出不同采样比例下,分类模型的准确率,具体详细结果见表2所示。

表2 参数确定实验
3实验结果与分析
3.1 实验环境与评价指标
3.1.1实验环境
操作系统:Windons10;显卡:GTX1060-4G;CPU:intel i7 9700r;内存:12G;硬盘:256G SSD;编译环境:PyCharm2021.1.1;Python库:Anaconda、Sklearn。
3.1.2评价指标
利用混淆矩阵对软件缺陷预测中的评价指标进行定义,混淆矩阵如表3所示。

表3 混淆矩阵
(1)预测率PD(Probability of detection)
(2)
预测率PD和召回率的计算方式相同,它在一定程度上反应了寻找缺陷模块的整体情况,当PD值越大时表现为预测模型发现缺陷模块的能力越强;当PD值越小时表现为预测模型发现缺陷模块的能力越弱。
(2)误报率PF(Probability of alarm)
(3)
误报率PF为把软件中无缺陷模块预测为缺陷模块的数量占整体缺陷模块个数的比例。当误报率PF值越大时表现为错将无缺陷模块预测为缺陷模块的概率越大,但在一定条件下可牺牲一定的误报率保证预测率。
(3)AUC(Area under the curve)
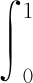
(4)
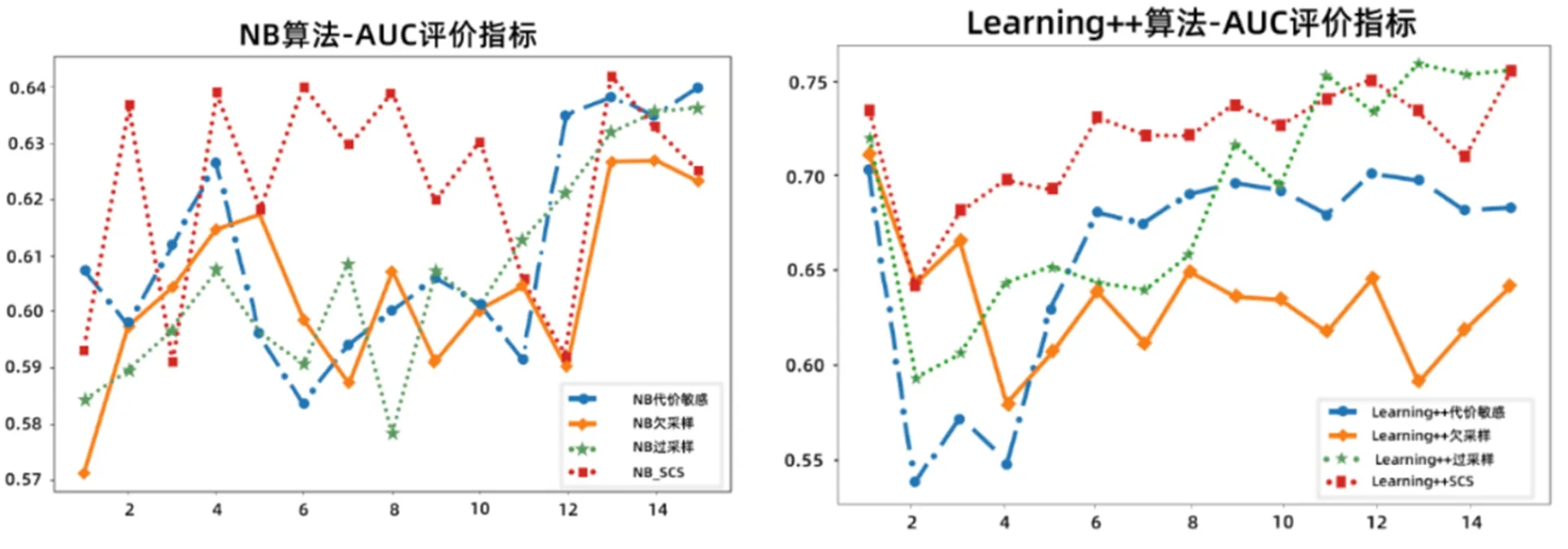
AUC的值是ROC(Receive operating characteristic)曲线下的面积。ROC是描述PD、PF的一种曲线,ROC以PF作为坐标系横轴、PD作为坐标轴纵轴。以AUC的取值范围0 3.2.1数据集 NASA数据集是美国航空航天局公开的数据集,在软件领域具有很强的权威性。采用NASA公开数据集中的7组数据集进行实验,保证了实验的有效性与可用性。同时也有利于其他研究人员对软件缺陷实验进行参考和实验对比。表4所示为实验的NASA数据集。 表4 实验数据集 3.2.2验证SCS算法有效性设计 利用多组实验验证SCS算法对不平衡软件数据流的分类有效性。第一组为利用随机过采样算法与SCS算法对软件数据流的分类比较;第二组为利用欠采样算法与SCS算法对软件数据流的分类比较;第三组为利用代价敏感算法与SCS算法对软件数据流的分类比较。在实验中采用的模型分别为传统静态机器学习算法朴素贝叶斯、动态增量学习Learning++。为了提高实验数据的可靠性,共进行5次实验对多个数据集进行了测试 ,并取得了各种算法在这些数据集上的平均性能和每种算法的分类结果平均值。 实验采用的模型分别为传统静态机器学习算法朴素贝叶斯和动态增量学习Learning++,其中每组模型分别用代价敏感、欠采样、过采样和SCS算法对软件数据流进行分类比较。图3所示为不同算法在指标PD上的实验结果。 图3 PD实验结果图 从静态的错误预报与动态的递进式(NB与Learning++)的角度看,SCS与上述2类方法有不同程度的改进。在NB方法中,SCS算法随着PD值随着数据量的增多而升高,从0.65升至0.98,平均值在0.9左右。NB过采样方法均值在0.85左右;NB欠采样方法均值在0.80左右;NB代价敏感方法均值在0.70左右。在Learning++方法中,SCS算法的PD值在0.53左右,Learning++过采样方法均值在0.43左右;Learning++欠采样方法均值在0.50左右;NB代价敏感方法均值在0.48左右。 总体而言,在NB算法下SCS方法的准确率高出其它三种方法10%-20%;在Learning++方法中SCS方法的准确率高出其它3种方法5%-10%; 图4所示为不同算法在指标PF上的实验结果。 图4 PF实验结果图 从静态软件缺陷预测和动态增量学习的比较角度来看(NB和Learning++算法),可以看出SCS算法相对于这2种算法来说有一定的提升,并且2种算法的表现结果相似。对于NB算法而言,在4种不同方法中,SCS方法表现最好PF值在0.175左右,其次是代价敏感方法PF值在0.24左右,欠采样表现最差PF值在0.325左右。对于Learning++算法而言,SCS方法、代价敏感方法和过采样方法随着数据量的增多PF值稳定在0.15左右,欠采样方法的PF值在0.20左右。 总体来看,这2种算法对于采样后的扰动反应较为稳定。因此,可以看出SCS算法相对于欠采样、随机过采样和代价敏感方法来说,在指标PF上的表现有所提升,并且优于这些方法。其PF值低于其它方法5%-15%左右。 图5所示为不同算法在指标AUC的实验结果。 图5 AUC实验结果图 从静态软件缺陷预测与动态增量学习的缺陷预测比较中(NB、Learning++)角度来看,SCS算法对这2个算法的提升是显然的,2种算法的表现结果相似。对于NB算法而言,SCS算法对其有提升效果但其表现并不稳定,平均值大约在0.63-0.64之间。对于Learning++算法而言,Learning++算法结合SCS算法依然表现出良好的结果,平均值大约在0.73左右。但总体而言,两种算法对于采样后的扰动后表现稳定。 (1)针对类不平衡对软件缺陷预测增量模型中基分类器分类效果不明显问题,提出了SCS算法可有效缓解类不平衡问题,进而提升分类算法的精度。 (2)以PD、PF、AUC作为评价指标,SCS算法的准确率优于传统机器学习算法10%-20%,优于动态增量学习算法5%-10%;SCS算法的误报率低于其它学习算法5%-15%左右;SCS的AUC值对这2个算法的表现结果相似,稳定在在0.63-0.73左右。3.2 实验设计

3.3 实验结果与分析


4结论
猜你喜欢
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
成都信息工程大学学报(2018年3期)2018-08-29
电子测试(2018年1期)2018-04-18
海峡姐妹(2017年12期)2018-01-31
作文与考试·初中版(2017年12期)2017-04-19
电子元器件与信息技术(2017年4期)2017-03-08
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中学生(2015年12期)2015-03-01
电测与仪表(2014年15期)2014-04-04
