
基于YOLOv5+DeepSORT检测数据的车头时距混合分布模型研究
2023-08-12 03:47丁正道吴红兰孙有朝
测控技术 2023年7期
丁正道, 吴红兰, 孙有朝
(南京航空航天大学 民航学院,江苏 南京 211106)
车头时距是指在同向行驶的一列车队中,两辆连续行驶的车辆的车头驶过某一点的时间间隔。车辆的到达被视为一个随机事件序列,因此车头时距是一个随机变量,研究该变量的分布规律对于交通安全研究、通行能力分析、道路服务水平、优化道路设计和管理等具有重要意义[1]。
由于交通流的到达具有某种程度的随机性,采用单一的标准统计模型很难描述这种随机性的统计规律。严颖等[2]基于高斯混合模型将车头时距分为饱和状态和非饱和状态,但只考虑了饱和状态交通流的车头时距分布,未对自由流状态的车头时距进行研究。陶鹏飞等[3]将车辆的行驶状态分为跟驰和自由流2种状态,提出车头时距的混合分布模型。王福建等[4]在陶鹏飞的研究基础上,引入强弱跟驰状态,结合自由流状态的负指数分布模型,构建三元混合分布模型,但对于描述自由流状态的负指数分布模型,较小的车头时距出现的概率较大,这与实际情况不符。
此外,对于车头时距研究的数据采集方式,以往多采用实地采集并填调查表格的方法,这种方法耗费大量人力和时间,且采集车头时距精确度较低。随着智能交通采集技术的发展,车头时距采集的方式逐渐增多。章庆等[5]提出一种基于雷达数据的饱和车头时距检测方法,此种方法需要在道路上搭建微波发射设备,但对于多车道的检测需要布置多个雷达设备,且雷达在恶劣天气检测效果差。王殿海等[6]采用基于自动车牌识别数据对不同车型的车头时距进行检测,采用不同数量单一模型的高斯混合模型对采集的数据进行拟合,最后使用AIC准则对最优单一模型数量进行判断,计算过程复杂,且仅采用过车视频结合人工调查的方式模拟车牌数据采集,未进行车头时距自动采集的实践。严颖等[2]虽然采用交叉口电子警察的号牌识别数据进行采集,但仅限于在有专业交通电子设备的路段进行采集,不具有便捷性,而且自动车牌识别数据的时间戳仅精确到秒,采样精度低。
为实现车头时距样本的自动化采集并提高车头时距模型的准确性,采用YOLOv5+DeepSORT算法对车头时距样本进行自动精确采集,并提出一种车头时距混合模型。首先,分别训练用于车辆目标检测的YOLOv5检测器模型和DeepSORT算法中用于描述车辆外观特征的ReID模型,接着将过车视频每一帧输入到训练好的YOLOv5模型和DeepSORT算法便可实现对车辆的实时检测跟踪。在此基础上,抽取过车视频第一帧为基准图,在基准图中框选检测区域和设置检测线,通过检测车辆是否触碰到检测线来对车头时距样本进行自动采集;针对强跟驰、弱跟驰和自由流三种驾驶行为特性,构建双高斯-移位负指数混合模型;根据自动采集的样本,采用最大期望(Expectation Maximization,EM)算法拟合出双高斯-移位负指数混合模型,最后采用K-S(Kolmogorov-Smirnov)检验对拟合结果进行拟合优度检验,并与三元混合分布、二元混合分布和威布尔分布模型的拟合效果进行对比。
1 车头时距采集算法
1.1 YOLOv5车辆检测模型
YOLOv5是一个单阶段探测器和基于区域的目标检测网络模型,由3个主要组件构成:BackBone、Neck和Head[7],因其高检测准确性和实时性而在各个领域被广泛研究与应用。YOLOv5的官方模型中有YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x等多个版本,性能和特点如表1所示。
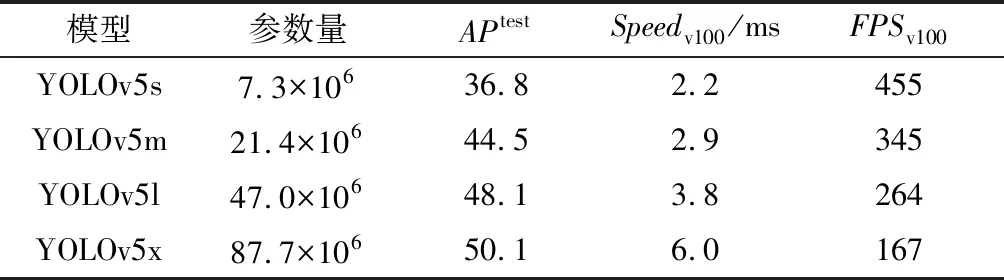
表1 YOLOv5的官方模型的性能及特点
表1中,YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x的模型参数量依次增大,其相应的检测精度也随着提升。然而随之模型变大,检测速度也有所降低,可以看到YOLOv5s检测速度为2.2 ms,而YOLOv5x的检测速度是其将近3倍。而在车头时距样本采集时,在满足检测实时性的情况下,模型的检测速度越高,则代表其每秒处理的帧数越多,从而其采集车头时距样本的准确度也越高。
此外,在实际的采集车头时距样本中,为避免因传输过车视频环节带来的时间延迟导致样本采集的实时性降低,从而降低了车头时距自动采集在智能交通中的实时性应用价值的问题,应采用路侧边缘端处理,较大参数量的模型对边缘端设备的性能有很高的要求,设备采购成本将会极大地增加。
因此,选择小参数量的YOLOv5s模型无疑是降低车头时距采集成本,提高车头时距采集准确度和实时性的较好选择。故本文选用YOLOv5s模型检测车辆,关于YOLOv5s模型的车辆检测精确度问题,将在下文的测试结果中表明其是否满足采集需求。
1.1.1 数据集
本文所采用训练YOLOv5模型的数据集是从网络上的过车视频中截取,图像中车辆全为朝向镜头行驶方向,共300张,其中包括单目标图像、多目标图像和目标重叠等图像,图1为数据集中车辆检测的主要场景,展现了数据集中几种较为典型的检测场景。

图1 数据集中车辆检测的主要场景
因为用来训练模型的数据较少,为了提升模型泛化性并避免过度拟合,所以对数据集进行数据增强处理以扩充数据集[8],数据增强的部分图片如图2所示。

图2 数据增强的部分图片
每张图像都有2个增强版本,因此最终数据集图像数量比原始图像数量增加了2倍。
利用makesense.ai标注软件对所用数据集图片进行标注,转化为训练所用的txt格式,并将数据集以8:1:1的比例分为训练集、验证集和测试集。
1.1.2 模型改进
(1) 采用CIoU损失函数。
交并比(IoU)是一种评价目标检测器性能的指标,是由预测框与目标框间交集和并集的比值计算,其考虑的是预测框和目标框重叠面积。
(1)
式中:A为预测框;B为目标框。
然而,IoU没有引入目标框与预测框中心的之间的距离信息和边界框宽高比的尺度信息,这使得目标物体的预测框无法准确贴合目标。但在采集车头时距样本时,检测框是否贴合目标的真实轮廓和是否稳定决定着检测框能否代表车辆的准确位置,这直接影响着样本的采集精度。而LossCIoU作为改进模型的边界框损失函数,考虑了边框中心距离和边框宽高比的尺度信息,使网络在训练时可以保证预测框快速收敛,并能够得到更高的回归定位精度。CIoU计算公式为
(2)
式中:b和bgt分别为预测边框和真实边框的中心点;ρ(b,bgt)为两框中心点间距离;c为预测框与目标框的最小外接矩形的对角线距离;α和v由式(3)、式(4)计算。
(3)
(4)
式中:h和hgt分别为预测框与目标框的高度;w和wgt分别为预测框与目标框的宽度。LossCIoU计算公式为
LossCIoU=1-CIoU
(5)
(2) 采用DIoU-NMS。
在传统的NMS中,IoU常用于提取置信度高的目标检测框,而抑制置信度低的误检框。其操作方法是,选取得分最高的检测框M,将与M的IoU大于NMS阈值的其他检测框的置信度置为0,从而剔除了冗余检测框。然而在面对车辆重叠场景的时候,两辆车很接近,由于两车辆检测框的IoU值较大,经过传统的NMS处理后,有可能只剩下一个检测框,导致与实际情况不符。对于传统NMS在重叠遮挡情况中经常产生错误抑制,DIoU-NMS引入了检测框之间的中心距离作为额外的检测准则。DIoU-NMS的得分Score更新公式定义如下。
(6)
式中:si为类别得分值;M为得分最高的检测框;Bi为其他检测框;ε为NMS阈值。对于两物体检测框IoU较大的情况,DIoU-NMS将考虑两个框之间的中心距离大小,若它们之间的中心距离较大时,将同时保留这两个物体的检测框,从而有效提高检测精度。因此,本文选用DIoU-NMS替代NMS。
1.1.3 实验设置
YOLOv5s模型实验配置如表2所示。

表2 YOLOv5s模型实验配置
训练参数设置为:输入图像尺寸为640像素×640像素;训练过程中,初始学习率为0.01,终止学习率为0.2;动量参数设为0.937;衰减系数为0.0005;Batch-size为8;训练轮数为200 epoches。
1.1.4 YOLOv5训练结果
本文采用YOLOv5官方给出的预训练网络模型YOLOv5s进行迁移学习,经200 epoches迭代训练后,选取得到的最优模型对测试集进行测试。测试结果如表3所示。

表3 原YOLOv5s模型和本文改进模型经测试的结果对比
经过训练后的本文模型精准率达到了95.5%,召回率为96.9%,平均精度AP(0.5)达到98.1%,满足后期检测需求,选取该模型用于车头时距检测。
1.2 DeepSORT多目标跟踪算法
在对车头时距样本进行采集时,需要跟踪每一辆驶入检测区域的车辆。DeepSORT算法可对检测到的每辆车进行轨迹跟踪,并为其分配特定的ID号。DeepSORT算法带有深度关联特征[9],在SORT算法的基础上,添加了一个CNN模型[10]。这个CNN模型被称为重识别ReID模型,用来提取由检测器界定目标部分的图像的特征,利用深度学习算法以减少大量ID切换。
1.2.1 跟踪处理和状态估计
DeepSORT 利用目标检测器的结果初始化跟踪器,每个跟踪器都设置有一个计数器,该计数器在卡尔曼滤波预测期间递增,并在轨迹与测量关联匹配时重置为0。跟踪器在预定的最大时间内没有关联匹配到合适的检测结果,则认为该目标已离开场景,将其从轨迹集中删除。对于无法从现有轨迹集中关联匹配的每个检测目标,都会分配跟踪器,若这些跟踪器在前3帧都能有预测结果匹配检测结果,则认为出现了新的轨迹;若前3帧内无法成功关联轨迹,则删除跟踪器。
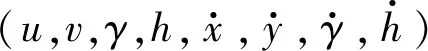
1.2.2 分配问题
DeepSORT通过匈牙利算法匹配预测框和跟踪框,并在此过程中结合运动信息和外观特征两项指标。对于运动信息,算法使用马氏距离度量卡尔曼滤波器的预测结果和检测器结果的匹配程度,马氏距离的计算公式为
d(1)(i,j)=(dj-yi)TSi-1(dj-yi)
(7)

(8)
然后指定一个阈值,比较d(2)(i,j)与阈值的大小来判断关联与否。此时,就可以使用马氏距离提供关于物体短期运动的位置信息预测;使用余弦距离提供的外观特征信息来对长期遮挡后的目标进行ID恢复。最后使用加权和将这两个指标进行结合。
ci,j=λd(1)(i,j)+(1-λ)d(2)(i,j)
(9)
1.2.3 ReID模型训练
DeepSORT算法使用一个残差卷积神经网络作为ReID模型以提取目标的外观特征。原始算法是对行人进行检测跟踪,其输入图像均被缩放为128像素×64像素大小[9],为使ReID模型适用于车辆特征的提取,将ReID模型的输入图像大小设置为128像素×128像素[11],该ReID模型如表4所示。
训练ReID模型的数据集来自VeRi数据集[12],其由20台摄像机拍摄完成,包含超过50000张776辆车的图像。模型结构采用上述调整后的CNN模型选取VeRi数据集中常见车型的100辆车的图片为训练数据集,并且提取每辆车的第一个图片为测试集。经200 epoches训练后得到的ReID模型,测试结果的Top-1准确率为80%。采用过车视频对模型进行检测,无明显ID跳变和漏检。
2 样本数据采集
采用基于YOLOv5+DeepSORT的方法对车头时距样本进行采集,图3为车头时距样本数据的采集流程。
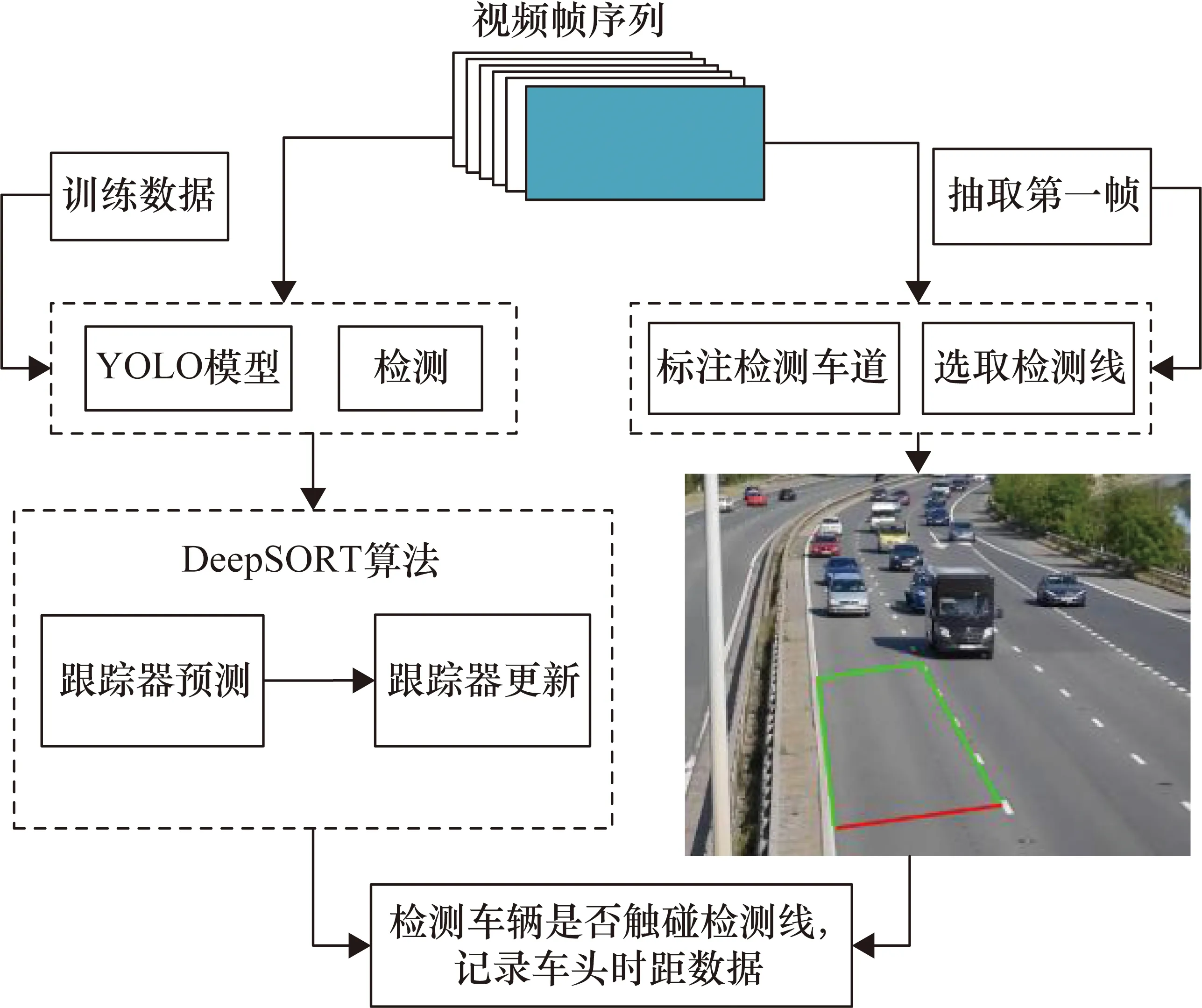
图3 采集车头时距样本数据的方法流程
2.1 过车视频拍摄与样本采集
摄像机在拍摄过车视频时应避免较大的抖动,防止因抖动导致检测线标定位置相对于路面移动导致车头时距检测出现误差。
抽取过车视频第一帧图像作为基准并标定检测区域,如图4所示,在要检测的车道上沿车道线选取合适的四边形检测区域,以四边形底边为车头时距检测线,当有车辆越过该线时,记录此车与前车之间的车头时距。

图4 提取出过车视频的第一帧为基准并标定检测区域
采集单个车头时距样本的具体流程如下:
① 通过YOLOv5和DeepSORT算法检测和跟踪每辆车,并取每辆车的检测边框底边中心点作为此辆车的位置。
② 当前帧中,通过判断车辆边框底边中心点相对于检测区域四条边的位置关系,判断此车辆是否在该检测区域内,并依此计算当前帧中四边形检测区域内所有车辆,将车辆编号计入数组Car_Array=[C1,C2,…,Ci,…,Cn]。
③ 若接下来的某帧中,其上一帧的Car_Array内Ci不在当前帧的Car_Array中,则代表前车越过车头时距检测线,并记当前此帧序号第k1帧。
④ 同理,当相邻的下一次车辆越过车头时距检测线时,记此帧序号第k2帧。
⑤ 计算得到车头时距为
t=(k2-k1)×tframe
(10)
式中:tframe为相邻两帧之间的时间间隔;若视频帧率为30 f/s,则tframe=1/30 s。
此外,通过车辆计数的方法也可对车头时距样本进行自动采集,采集流程与上述使用车辆编号的方法类似,通过对比前后两帧检测区域内车辆的数量是否减少来确定前车是否驶过检测线,从而确定驶过时刻。但若在同一帧中,前车越过检测线驶出检测区域,后边一辆车正好越过检测区域四边形的顶边进入检测区域,此种情况无法判断是否有车辆驶离检测区域,则会带来样本漏采的情况。
2.2 样本采集可靠性分析
在对车头时距样本进行采集时,误差可能来自以下几个方面。
(1) YOLOv5检测车辆时,目标车辆检测的位置误差。
① 检测框上代表车辆的像素点选取不当。
② 检测边框无法贴合实际车辆轮廓。
(2) 多目标跟踪准确度(Multiple Object Tracking Accuracy,MOTA)[13]。
① YOLOv5检测时漏检和误检车辆。
② DeepSORT算法跟踪车辆时目标ID跳变。
(3) 其他情况:摄像机拍摄时的抖动、视频帧率大小情况等。
采集误差来源的第(1)条,YOLOv5模型检测车辆位置的误差来自两个方面。
一是选取YOLOv5目标检测框上的像素点无法准确代表车辆在地平面上的位置而带来系统误差。车头时距视频监控视角如图5所示。
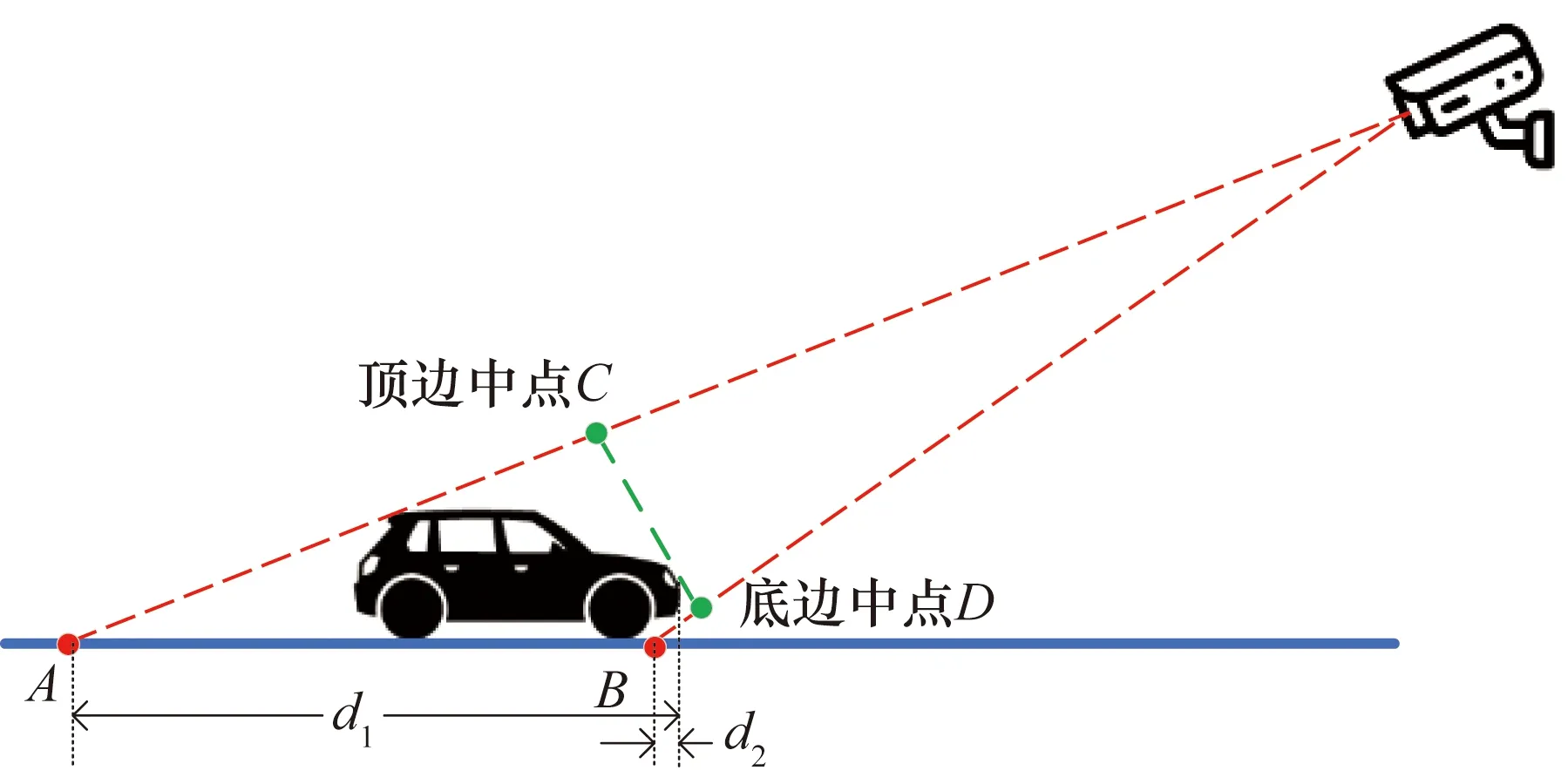
图5 代表目标车辆位置的检测框上像素点
由投影几何学知识可知,若选择检测边框顶边中点C用以采集样本(如图6(a)所示),边框顶边中点C在地面的投影距离车辆车头真实位置的长度为d1,位置误差较大。采集样本的过程中,当车头驶过检测区域很大一段距离时,才记录当前车辆的驶离时间。而且对于不同车高的车辆,即便是处于同一位置,其投影点位置也会有所不同,会导致车辆位置检测误差和不稳定。本文选择车辆检测边框的底边中点D来代表车辆车头位置(如图6(b)所示),其在地平面上的投影点B相比于其他投影点要更接近于车头的实际位置,车辆底盘高度带来的位置检测误差为d2,且不同车辆的底盘高度差别并不是很大,这也提高了YOLOv5车辆位置检测的稳定性。所以选择目标检测边框的底边中点代表每一辆车的位置更符合实际情况,提高了车辆位置检测的可靠性。

图6 车辆监控视角摄影示意图
二是检测边框的跳动,检测边框无法贴合实际车辆轮廓,导致车辆的检测位置不定带来的不定误差。通过测量车辆实际边框底边中点相对于YOLOv5检测边框的底边中点的距离d,然后对该距离进行归一化处理以衡量车辆位置因检测边框的跳动带来的检测误差(err):
(11)
式中:Ddiagonal为当前帧中实际车辆检测边框的对角线长度。
样本采集误差来源第(2)条中,由于YOLOv5在检测目标时出现车辆漏检和误检的情况,与DeepSORT算法跟踪目标时出现车辆ID跳变的情况将直接影响车头时距样本采集的准确性。为综合考虑漏检、误检和ID跳变所带来的误差影响,采用MOTA指标综合评价本文算法的有效性,MOTA被定义为
(12)
式中:t为帧序列数;FN为车辆漏检数;FP为车辆误检数;IDSW为目标ID跳变数;GTt为当前帧中总目标数量。
采用过车视频对采集算法进行测试。在过车视频中,实际过车数量为248辆,实测车头时距平均值为2.66 s;随机抽取过车中的50辆车,再抽取每一个车辆的任意2帧图片进行位置误差计算,最后计算得到平均位置检测误差;选取检测区域内车辆的。本文方法检测结果及其对比如表5所示。
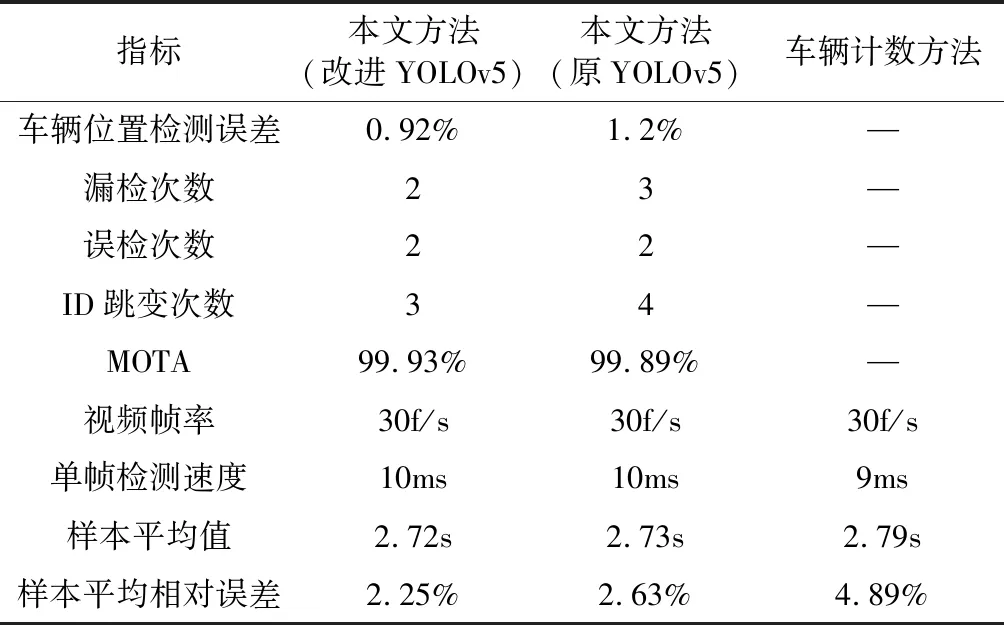
表5 本文采集方法与其他采集方法的检测结果
由表5可知,采用车辆计数的方法采集车头时距获得的车头时距误差较大为4.89%。使用改进YOLOv5s模型作为检测器的方法的车辆位置检测平均误差为0.92%,使用原YOLOv5s模型的采集方法的检测位置平均误差为1.2%,这表明本文方法中YOLOv5检测车辆位置具有较高的可靠性,且前者相比于后者的位置检测更加准确。此外改进后模型的漏检次数为2次,ID跳变3次,均小于使用原始YOLOv5s模型的采集方法。本文算法对检测区域内的MOTA指标为99.93%,表明此算法可有效满足车头时距样本采集的需求。
两者采集的车头时距样本平均值相当,分别为2.72 s和2.73 s,样本平均相对误差分别为2.25%和2.63%,车头时距样本采集误差在5%以内即可接受[14],所以,虽然本文方法在车头时距样本采集时有漏检、车辆ID跳变、检测位置误差、视频帧率等原因存在,但其平均相对误差仍在可接受范围之内,所以本文方法满足车头时距样本采集精确度的需求。过车视频的帧率为30 f/s,而本文算法的单帧检测速度为10 ms左右,满足车头时距实时性采集需求。
3 车头时距分布模型构建
对于正常行驶在道路上的车辆,在对车头时距的概率分布进行研究时,分为跟驰状态和自由流状态,两者的概率分布性质不同。
跟驰状态主要出现在交通流的密度较大时,车队中任意一辆车的车速受前车的制约,与前车保持紧随。但前后车之间保持一个安全距离,以留给后车足够的反应时间来面对前车的突发制动。由于车队具有制约性、延迟性和传递性,所有这个安全距离是波动的。不同的驾驶员对安全距离的心理阈值不同,基于此类情况将跟驰行为分为谨慎型和激进型,故跟驰所保持的车头时距概率分布情况亦有所不同。王福建[4]和Taieb-Maimon[15]等对激进型和谨慎型两种驾驶行为的车头时距进行了研究,表明其概率分布呈现以均值为中心的左右对称的情况,并成功用高斯混合模型对跟驰状态的车头时距做出通过显著性水平为0.05假设检验的拟合。
自由流状态出现在交通流密度较小时,驾驶员能够根据自己的驾驶风格、道路和车辆条件进行驾驶,基本不受道路上其他车辆的影响,并保持期望车速行驶。而在关于混合驾驶行为的车头时距研究中,大多采用负指数分布来表示自由流交通的车头时距分布特性,但这导致较小的车头时距出现的概率较大,与实际情况不符。因此,对于车头时距概率分布特性的描述很难用单一的标准分布模型来描述,故本文采用高斯混合模型结合移位负指数模型来描述路段车头时距分布特性。本文车头时距概率分布模型如式(13)所示。
f(t)=w1f1j+w2f2j+w3f3j
(13)
式中:f(t)为车头时距t的概率混合分布模型函数;w1、w2、w3分别为两种跟驰状态和自由流状态的样本数据占总数据的比例,并且w1+w2+w3=1;f1j、f2j和f3j的表达式为
(14)
(15)
(16)
式中:j=1,2,3,…,N,N为样本总量;μ1、μ2分别为两种跟驰状态模型的均值;σ1、σ2为两种跟驰状态模型的标准差,表示两种状态下车头时距t相对于均值的离散程度;λ为自由流状态下车辆到达率;τ为移位参数,取车头时距t数据中最小的值min(t)。
4 模型参数估计算法
本文采用EM算法来对模型的参数进行估计。EM算法是一种迭代算法,用于含有隐变量的概率模型参数极大似然估计。算法步骤为:
输入:检测到车头时距(t1,t2,…,tN),本文模型f(t)。
输出:本文模型参数θ=(σ1,σ2,μ1,μ2,λ,w1,w2,w3)。
① 初始化模型参数的值进行迭代。
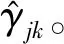
(17)
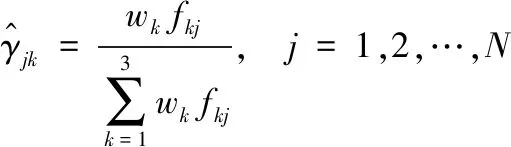
(18)
③ M步:计算下一轮迭代的模型参数。
(19)
(20)
(21)
(22)
④ 重复第②步和第③步,直至各参数收敛在给定范围内波动停止迭代。
5 实例应用
5.1 样本数据采集
过车视频拍摄地点位于宁宣高速路段,时间为傍晚高峰时刻。视频拍摄完成后,采用YOLOv5 + DeepSORT算法对过车视频中车头时距样本进行采集。
对比分析基于ALPR采集方式[6]和本文采集方式因数据采样所产生的误差,如表6所示。
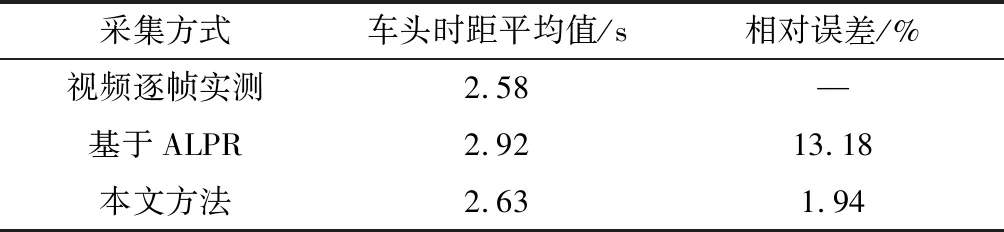
表6 不同车头时距样本采集方式与人工实测数据之间的平均相对误差
表6中,车头时距样本的实测平均值为2.58 s,基于ALPR和本文方法的样本平均值分别为2.92 s和2.63 s,两种采样方法相对与实测平均值的相对误差分别为13.18%和1.94%。由于数据误差在5%以内才可接受[14],基于ALPR的车头时距采集方式误差较大,采用本文YOLOv5+DeepSORT识别方法采集的车头时距样本满足实际的数据输入准确性要求。
5.2 模型估计结果与分析
利用YOLOv5+DeepSORT检测过车视频中车头时距数据,按照统计检验方法对获取的数据进行本文模型的拟合,应用EM算法进行参数估计,本文模型及对比模型的参数估计结果如表7所示。

表7 本文模型及对比模型的参数估计结果
各模型拟合效果对比如图7所示,可以看出威布尔分布和二元混合分布模型对样本数据的拟合效果较差,而本文模型和三元混合分布模型两者的拟合曲线与样本数据最为接近,可以明显看出后两者的双峰特征,代表强跟驰和弱跟驰两种跟驰状态的车头时距密度分布状况。但本文模型由于引入移位负指数模型来描述自由流状态的车头时距分布,所以在较小车头时距处的概率密度分布更贴合实际样本数据。

图7 各模型拟合效果对比
拟合结果采用K-S检验[16]进行评估,原假设H0为总体样本数据符合相应的模型分布,显著性水平选取0.05,计算样本数据与本文模型和对比模型的累计分布曲线之间相应的最大垂直差D值,然后与K-S检验临界值表中的显著性水平为0.05的临界值D0进行比较,若D>D0则拒绝原假设,否则接受原假设。本文模型与对比模型的K-S检验结果如表8所示,表中p值是对原假设成立的评价,代表模型在显著水平为0.05情况下的非拒绝率。如果p值较小,则对原假设有效性产生怀疑;若p值越大,则越能接受该模型[17]。
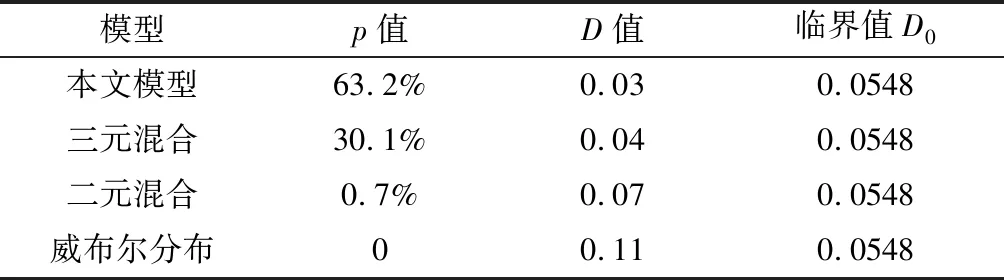
表8 显著水平0.05情况下的K-S检验结果
在表8中,临界值D0为0.0548,本文模型、三元混合分布、二元混合分布和威布尔分布模型的最大垂直差的D值分别为0.03、0.04、0.07和0.11。所以仅本文模型和三元混合模型的D值小于临界值D0,接受原假设H0,即采集的车头时距数据样本符合本文模型和三元混合模型在显著水平为0.05下的概率密度分布。但本文模型的非拒绝率p值为63.2%,要远远大于三元混合模型的非拒绝率p值30.1%,所以相比于三元混合模型,本文所建立的概率分布模型更好地拟合了实测的样本数据。
6 结束语
采用YOLOv5+DeepSORT的方法对车头时距数据进行自动化采集,此方法对车辆的位置检测可靠,满足车头时距采集的准确度需求和实时性要求,并避免了样本漏检的情况,解决了人工采集方法工作量大、耗时长和基于ALPR车牌数据采集的不准确的问题。此算法可以部署在边缘端智能化交通检测器上对道路上的车头时距进行实时采集,并通过通信技术将数据上传至数据库,可为智能化道路交通参数采集提供一种方法。此外,本文在三元混合分布模型的基础上对车头时距概率分布模型进行改进,引入移位负指数分布模型来描述自由流状态车头时距的概率密度分布。结果表明该模型具有更好地拟合效果,可以更好的体现车头时距在各种交通流状态下的变化特性,可将此模型进一步应用到交通安全研究、通行能力分析、道路服务水平、优化道路设计和管理等方面。
进行车头时距采集的环境是在天气晴朗的白天。在未来的研究中,可考虑加入雨天和黑夜等复杂交通场景下的车头时距样本采集,提高该车头时距采集方法的通用性。
猜你喜欢
人类工效学(2021年5期)2022-01-15
军事文摘(2020年24期)2020-02-06
绥化学院学报(2019年10期)2019-10-12
摄影之友(影像视觉)(2018年1期)2018-03-22
心理科学进展(2018年8期)2018-02-21
摄影之友(影像视觉)(2017年11期)2017-11-27
中国老区建设(2016年4期)2017-01-15
中国照明(2016年6期)2016-06-15
发明与创新(2015年25期)2015-02-27
心理科学进展(2015年5期)2015-02-26
