
基于LSTM算法的大坝坝体渗透压力预测
2023-09-08 12:45姚志武侯丽娜文茂华
水利建设与管理 2023年8期
姚志武 侯丽娜 文茂华
(1.长江勘测规划设计研究有限责任公司,湖北 武汉 430010;2.长江空间信息技术工程有限公司(武汉),湖北 武汉 430010)
目前,在渗压拟合方面应用较多的是集成时间序列(ITS)模型,逐步回归分析法作为ITS中的代表性方法在渗压分析预报方面取得了不错的成绩[2]。BP神经网络在大坝渗流安全监测数据的分析和处理中得到了广泛的应用,对非线性问题的高仿真性能、适应性及拟合精度优于逐步回归方法,但泛化能力弱、易陷入局部极小点等缺陷问题是近年研究的重点之一[3]。
鉴于标准BP算法存在的缺陷,为了提高坝体渗流压力的预测效果,本文利用混凝土坝实时监测数据建立基于LSTM算法的渗压预测模型,以渗透压力作为研究指标进行示例预测,并与传统BP神经网络方法进行对比,搭建高精度渗压预测模型,为水库安全运行管理及大坝渗透压力控制提供科学依据[4]。
1 基于LSTM的神经网络
1.1 循环神经网络简介
循环神经网络(Recurrent Neural Network,RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络[5]。RNN由具有时间序列建模特点的神经元构成,包括输入层、隐藏层和输出层,并通过层之间的神经元建立权连接。循环神经网络在数据传递上具有额外的权重,表示关于此神经元之前输入对当前神经元影响的程度。在每个神经元更新时,会把先前的值与其他权重一起输入到激活函数中。所以此刻的状态不仅包含了新的输入数据,还包含了之前输入数据的历史影响,因此具有一定的预测能力[6]。RNN展开后由多个相同的单元连续连接,是一个自我不断循环的结构,见图1。随着输入信息的不断增加,自我循环结构中的上一状态传递给自我作为输入,一起作为新的输入信息进行当前批次的训练和学习,一直到训练结束,最终达到信息预测的效果。

图1 RNN基本结构
然而,在RNN的训练过程中,先前数据中的信息对后续数据的影响逐渐减少,信息的保存率较低,难以控制对先前数据中信息的利用程度。长短时记忆网络(Long Short-Term Memory,LSTM)是RNN的一种特殊网络,是在计算机内存单元设计灵感下诞生的[7]。通过在算法中加入判断先前数据信息是否有用的门单元,能够有效解决长序依赖问题。因此,可以利用长短时记忆网络来创建大型的循环神经网络,用于解决机器学习中比较复杂的序列问题,并且长时期记忆网络对序列问题的处理具有很高的效率[8]。
1.2 LSTM算法原理
LSTM是一种特殊的RNN,两者的区别在于普通的RNN单个循环结构内部只有一个状态,而LSTM的单个循环结构(又称为细胞)内部有四个状态。相比于RNN,LSTM循环结构之间保持一个持久的单元状态不断传递下去,用于决定哪些信息要遗忘或者继续传递下去[9]。LSTM网络的结构相比普通的RNN结构来说较为复杂(见图2),采用LSTM层替代传统的隐藏层,并且拥有三个门:输入门、遗忘门和输出门。其中遗忘门的存在使得LSTM能够删除和遗忘部分信息,从而解决了RNN存在的长期依赖问题[10]。LSTM的具体实现过程如下:

图2 LSTM网络结构
a.计算遗忘门的输出值:
模式预报结果的检验是按照《环境空气质量标准》(GB 3095—2012)中的标准及算法进行的。使用了2016年7月1日~2017年10月31日模式预报数据和环保总站发布的污染物浓度监测数据2015年1月1日~2017年10月31日进行对比分析,使用了相关系数、均方根误差来检验模式预报结果。
ft=σ(wf·[ht-1,xt]+bf)
b.计算输入门的值:
it=σ(wi·[ht-1,xt]+bi)
C′t=tanh(wC·[ht-1,xt]+bC)
c.更新细胞状态:
Ct=ft⊙Ct-1+it⊙Ct
d.计算输出门的值:
ot=σ(wo·[ht-1,xt]+bo)
ht=ot⊙tanh(Ct)
式中:wf,wi,wC,wo分别为遗忘门、输入门、细胞状态和输出门的权重矩阵;bf,bi,bC,bo分别为遗忘门、输入门、细胞状态和输出门的偏置项;ft,it,Ct,ot分别为t时刻的遗忘门、输入门、细胞状态和输出门;C′t为记忆单元的输入状态;ht为t时刻的隐藏层输出;σ为sigmoid函数;xt为t时刻的输入;tanh为双曲正切函数;⊙表示矩阵元素相乘[11]。
2 模型建立与应用
本文以湖北省恩施市境内马尾沟流域的青龙水电站为研究对象。水电站坝高139.7m,坝址以上集雨面积为226km2,水库正常蓄水位735m,库容2939万m3。大坝基础廊道共埋设了9支渗压计(P-1~P-9),其中P-1、P-4、P-7位于帷幕前,其他测点位于帷幕后,布置见图3。
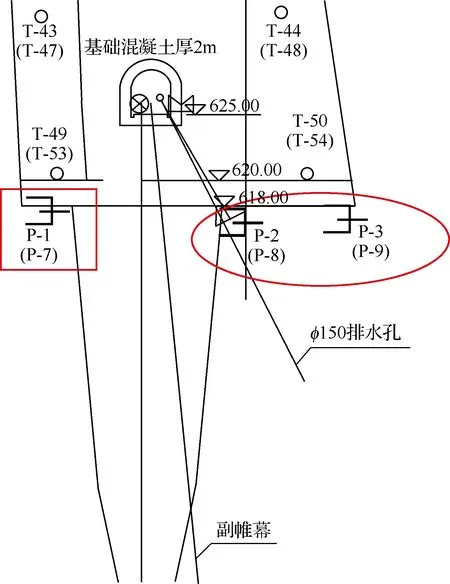
图3 渗压计布置
2.1 数据准备与预处理
本文选取渗压计P-1(2017年12月1日至2022年2月25日)进行分析计算。上述自动化监测时间序列里共有监测数据1522组,将其中80%的数据作为训练及拟合样本,20%的数据作为测试样本。本文对获取到的自动化监测数据进行数据标准化操作,从而避免由奇异样本数据导致的训练时间成本增加,进而提升模型训练的收敛速度。本文采用Sklearn库自带的MinMaxScaler方法进行标准化操作,对原始数据进行线性变换,从而使最后的数据落在0至1之间。
2.2 模型搭建与实现
本文实验所使用的的计算机物理环境如下:CPU为AMD Ryzen 7 4800H 2.90GHz,运行内存为40GB;软件环境如下:操作系统为64位的win10系统,Python版本为3.7,IDE工具为PyCharm,神经网络基于Keras框架搭建。
LSTM神经网络涉及的参数较多,选取合适的参数对获得良好的预测精度和提升训练速度均有着较大影响[12]。LSTM模型的结构主要分输入层、隐藏层、输出层三个部分,隐藏层数较多的LSTM参数更加复杂,容易增加训练难度,考虑到本文中所使用的样本量较少,所有模型均在单隐藏层LSTM神经网络下构建。参考相关文献,无论是从提升LSTM神经网络性能还是时间效率上来讲,合理选择时间步长和隐藏层神经元的个数至关重要[13]。本文主要探讨时间步长、隐藏层神经元个数对模型训练的影响。
2.3 模型建立
基于LSTM大坝坝体渗透压力的预测模型包括5个模块:数据获取、数据预处理、模型构建、训练与优化、模型预测。模型通过数据库获取渗压计历史监测数据,数据间隔为一天,并通过一定步长的时间序列数据预测后一天的渗透压力值;考虑到自动化监测设备存在数据采集异常等情况,将时间序列数据中的异常值、缺失值等进行补全;通过经验法和逐步试错法确定最优的时间步长和隐藏层神经元个数;最后,对模型进行训练、验证和测试,并预测大坝坝体渗透压力值。具体的LSTM预测模型结构见图4。
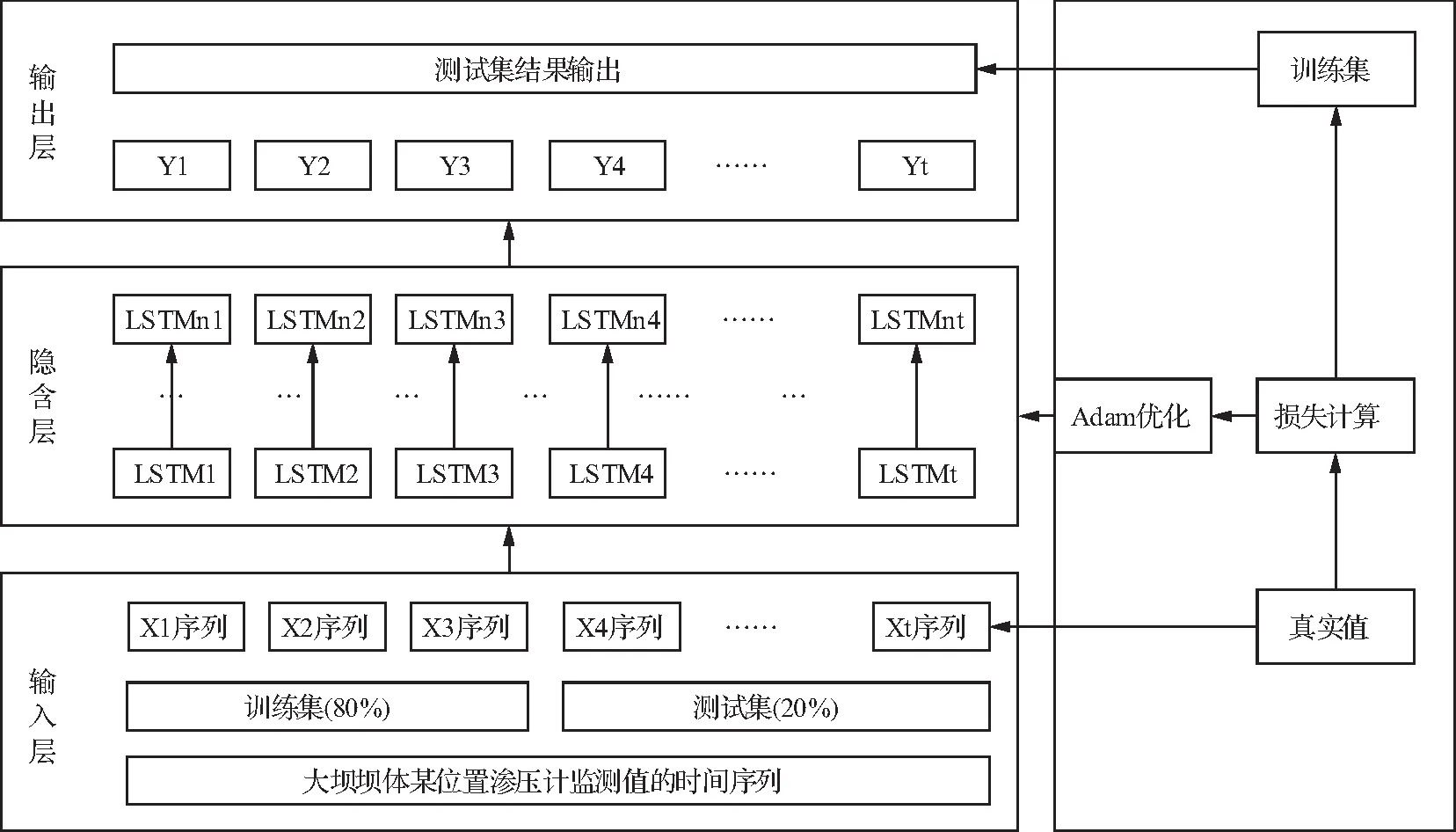
图4 LSTM预测模型结构
2.4 模型评价方法
为了提高大坝坝体渗压预测模型的预测精度,需要根据预测结果比较参数的变化对结果的影响。在深度学习领域,常用的模型评估方法有准确率、覆盖率、MAE、RMSE、R2等[14]。准确率和覆盖率多用在分类问题上,MAE、RMSE、R2多用于回归预测问题。
其中,MAE为平均绝对误差,用来度量预测误差的真实情况,为绝对误差的均值。
RMSE为均方根误差,度量预测值和真实值之间的偏差,是预测值与真实值的差的平方和与样本量比值的平方根。
R2为确定系数,用来度量未来的样本是否可能通过模型被很好地预测,值越接近1表示回归分析中自变量对因变量的解释越好,即预测效果越好。
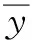
3 结果对比与分析
3.1 主要参数分析
3.1.1 时间步长
本实验数据是每日一条的大坝渗压监测数据,结合实际情况分析,选取时间步长分别为6d、8d、10d、15d、20d进行模型训练,并在验证集上计算各步长下的性能。时间步长是LSTM神经网络中引入时序概念的决定性参数,步长过短可能导致历史信息不足而降低训练性能,步长过长可能增加训练时间且降低训练性能。根据如图5和图6所示的实验结果发现,随着时间步长的增加,RMSE存在明显的先降后升趋势,即时间步长为10d能够达到更好的预测效果,本文中将选取时间步长为10d作为模型参数。
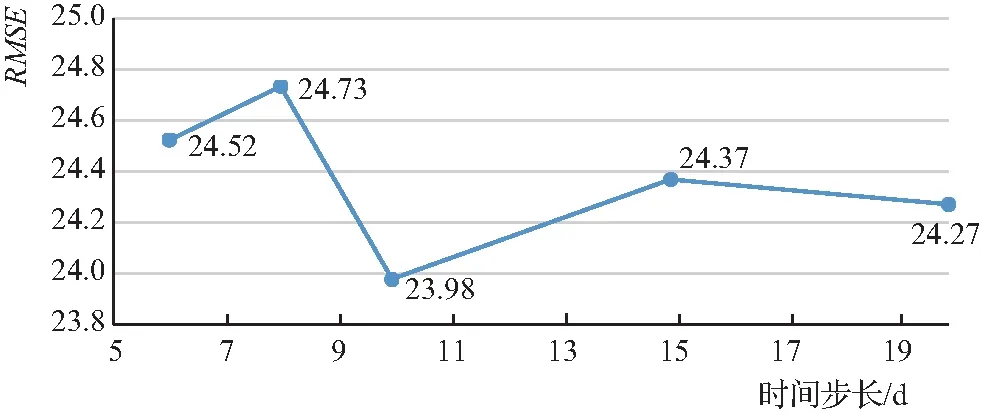
图5 时间步长对LSTM模型性能的影响

图6 隐藏层神经元个数对LSTM模型性能的影响
3.1.2 隐藏层神经元个数
理论上来讲,神经元个数过多容易陷入过拟合,而数量较少则无法很好地进行模型训练。本文选取隐藏层神经元个数为50、100、150、200、250进行模型训练,并在验证集上计算各隐藏层神经元个数下的性能。根据如图6所示的实验结果发现,随着隐藏层神经元数量的增加,RMSE会明显地降低,但数量大于200后,模型性能差别并没有显著变化,本文中将选取隐藏层神经元个数为200作为模型参数。
综上所述,最终选取时间步长为10d,隐藏层神经元个数为200作为最后的参数训练LSTM模型,并调节正则化、dropout等参数防止过拟合,最终LSTM神经网络的RMSE为23.98(实验数据值域为781.81~1100.23kPa,预测波动范围为2%~3%),R2为0.94,整体拟合效果较好。
3.2 模型对比分析
为进行对比分析,本文同时使用BP神经网络[15]、LSTM模型对样本数据进行拟合预测(BP神经网络采用MLP模型,同样采用经验法和逐步试错法确定最优参数,其中预测窗口步长为10d,隐藏层神经元个数为200)。表1为验证集中部分样本大坝坝体渗压实际值和预测值的比较,图7为验证集中所有样本实际值和预测值的对比。
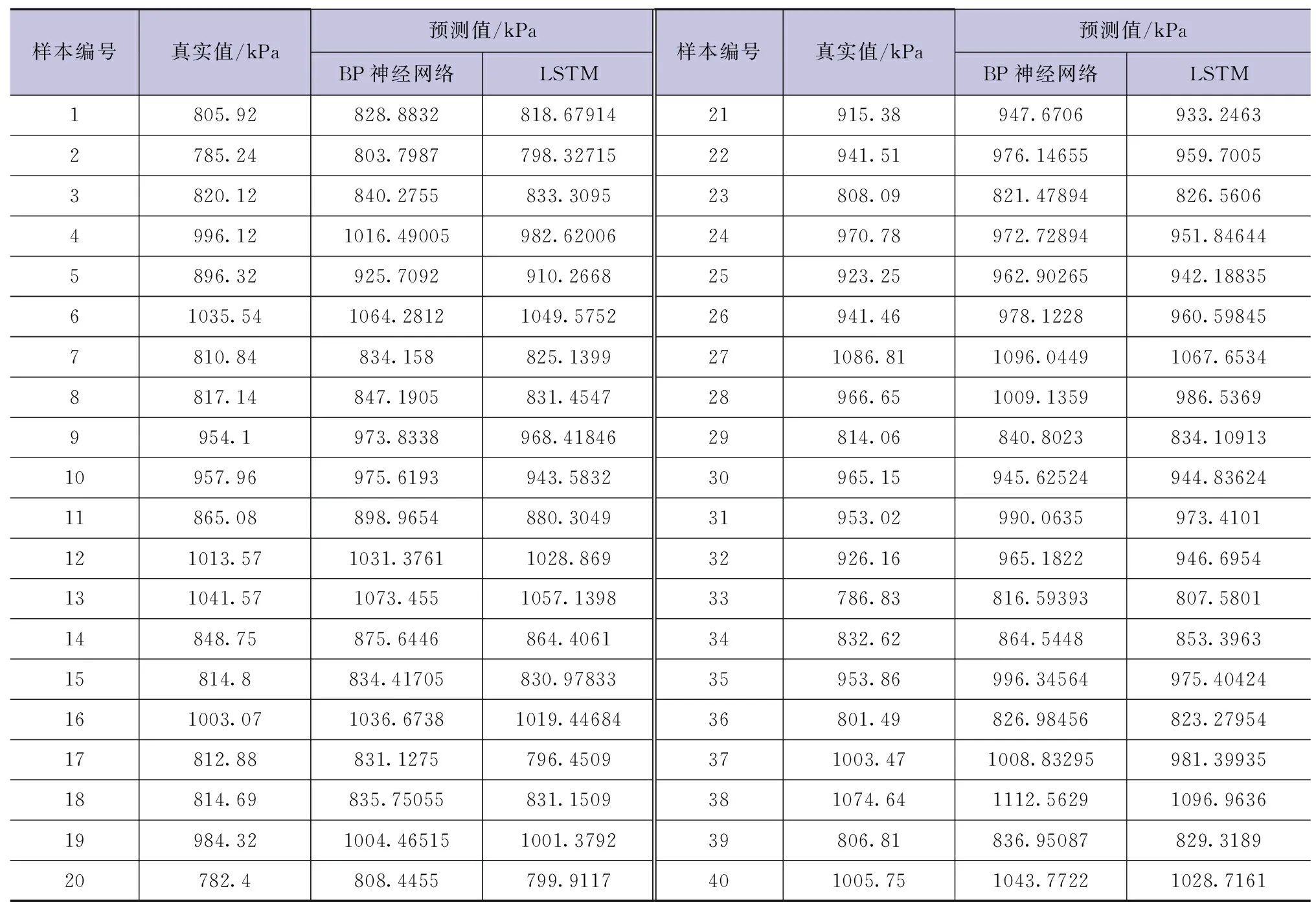
表1 部分预测坝体渗压值和实际值数据
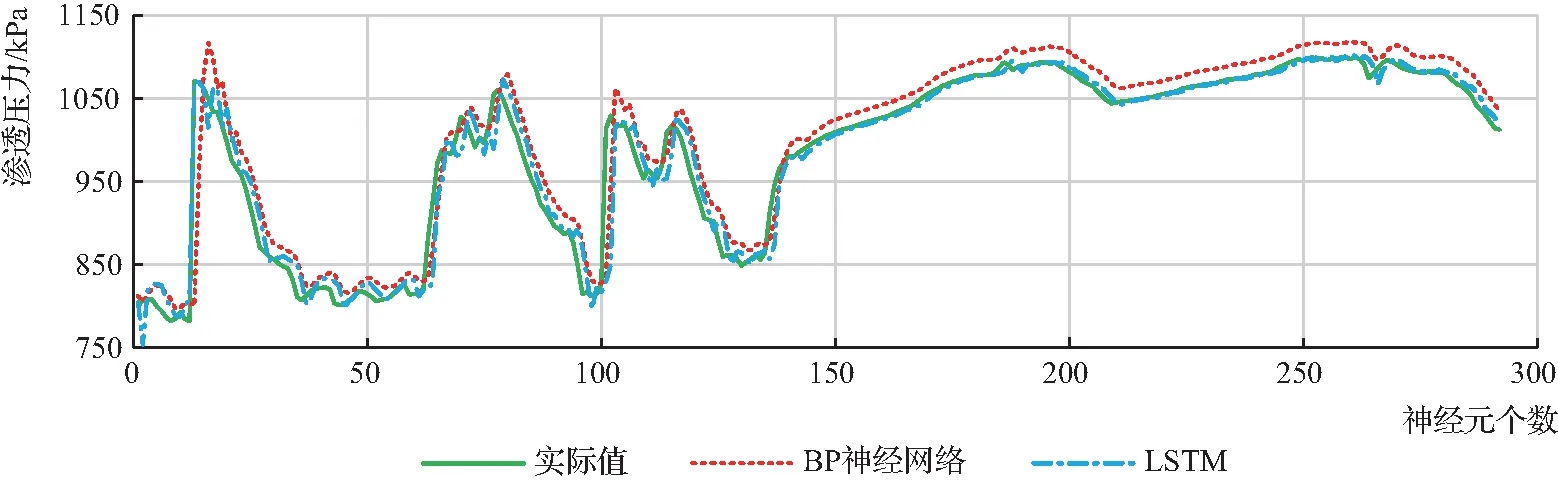
图7 实际值与预测值(BP神经网络和LSTM模型)对比
表1和图7的数据对比显示:LSTM模型的预测值与实际值相比波动微弱,且总体趋势更接近实际值。由表2可以看出:BP神经网络和LSTM模型的R2都在0.9以上,表明两种模型对测点渗压的拟合度均较高,其拟合曲线与实际动态基本贴合(见图7),LSTM模型相较BP神经网络的平均绝对误差和均方根误差均更小。综合对比,LSTM作为深度学习网络,相较传统机器学习方法的BP神经网络能更好地进行本文所研究大坝的渗压预测。
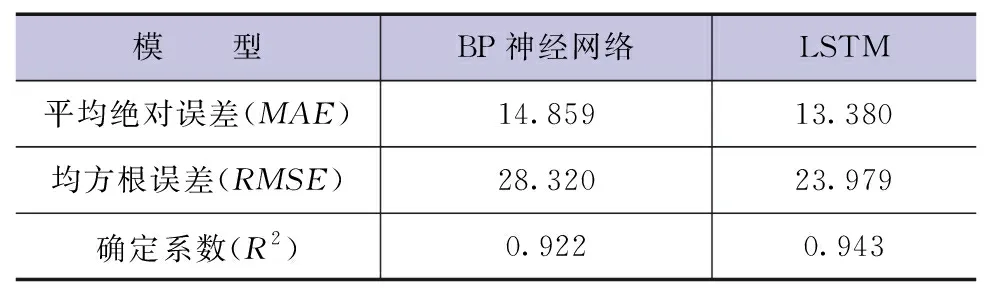
表2 模型评价对比
4 结 论
本文基于青龙水电站大坝坝体的渗压自动化监测数据,构建了LSTM神经网络模型,探究了时间步长、隐藏层神经元个数对模型训练性能的影响,并与传统BP神经网络模型进行对比分析,得出如下结论:
a.LSTM神经网络在不同时间步长和隐藏层神经元个数下均有较好预测效果,本文中的实验数据模型时间步长为10d,隐藏层神经元个数为200时,整体拟合效果较好。
b.LSTM模型能够准确反映大坝坝体渗压系统的不确定性非线性关系,与传统BP神经网络对比分析表明,LSTM模型拟合曲线R2达到0.943,拟合水平显著,性能优越。
c.本文中搭建的LSTM神经网络预测模型,时间步长为10d的能达到较好的预测结果,均方根误差(RMSE)为23.98,预测波动范围为2%~3%,能够初步判定大坝工作状态是否存在安全隐患,为水库安全运行管理及大坝渗透压力控制提供科学依据,满足水电站日常管理需求,具有很好的工程应用价值。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
建材发展导向(2021年19期)2021-12-06
小学生学习指导(低年级)(2021年9期)2021-10-14
黑龙江水利科技(2020年8期)2021-01-21
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
中国工程咨询(2017年9期)2017-01-31
河北科技大学学报(2015年5期)2015-03-11
电测与仪表(2014年2期)2014-04-04
