
基于卷积神经网络的内窥镜图像分类
2023-09-13 12:58项诗雨魏利胜
安徽工程大学学报 2023年3期
项诗雨,魏利胜
(安徽工程大学 电气工程学院,安徽 芜湖 241000)
近年来,我国结直肠癌发病率与死亡率都呈现增长趋势。据2018年中国癌症统计报告显示,我国结直肠癌新发病例37.6万例,死亡病例19.1万例,结直肠癌严重危害并影响着我国公民健康[1]。溃疡性结肠炎与息肉被认为是导致结肠癌的高危因素之一[2]。无线胶囊内窥镜是检查肠道的常用工具,每次检查会产生数以万计的图像。肠道疾病的诊断需要医生高强度地分辨大量视频帧,即使是经验丰富的医生也会因为疲劳导致漏检误检,因此借助计算机诊断系统来降低误诊率是非常有必要的[3]。
随着深度学习的发展,很多基于深度学习的肠胃病变分类方法被提出来。阿依木克地斯等[4]将肠镜图像输入卷积神经网络(CNN),采用端到端的训练方式,最高达到95.27%的息肉分类准确率;Zeng等[5]将Xception、ResNet和DenseNet三个预训练模型融合对溃疡性直肠炎图像进行分类,实现了97.93%的分类准确率;Alaskar等[6]使用GoogLeNet和AlexNet模型在ImageNet数据集上进行预训练,使用网络参数的最佳组合高精度地分类出溃疡。这些方法可以有效地分类内窥镜图像。然而,为了更高效地提取图像特征,研究人员试图将注意力机制与卷积神经网络结合起来。注意力机制模型被广泛应用于各种深度学习任务,如分割、分类等领域。它可以快速扫描图像,类似于人眼观察物体的方式,捕获需要锁定的区域。目前已经开发出具有不同结构和特征的注意力机制,将其应用于图像处理任务中并取得了优异的结果[7-9]。巩稼民等[10]对残差网络ResNet进行改进并嵌入注意力机制SE模块实现慢性萎缩性胃炎的分类;Cao等[11]将通道注意机制集成到残差网络ResNet中以提取图像特征,然后采用基于改进的SVM(支持向量机)分类器进行息肉图像的分类,达到了98.4%的分类准确率。
本文在以上研究的基础上,结合数据增强和迁移学习策略提出一种基于ConvNeXt网络模型的分类方法,并在该模型中引入注意力机制CA(CoordAttention),同时使用Polyloss损失函数优化模型,实现小样本下的溃疡和息肉内窥镜图像的精确分类。
1 改进ConvNeXt模型的内窥镜图像分类
为了提高内窥镜图像分类准确率,采用了一种微调ConvNeXt模型的算法,具体流程如图1所示。由图1可知,改进ConvNeXt模型图像分类主要工作为:首先需对内窥镜图像进行预处理操作,包括调整数据集图像分辨率大小和修复图像的光斑;其次内窥镜图像进行数据扩增,包括内窥镜图像水平垂直翻转;然后结合迁移学习在引入注意力机制CA的ConvNeXt模型上进行训练,并在验证集上对模型的性能进行评估;最后,通过预测脚本对输入的图像进行分类。

图1 基于改进ConvNeXt模型的图像分类流程图
1.1 图像预处理
首先,裁剪数据集图像。由于内窥镜图像的周围存在黑框,这一部分没有包含图像的特性,并且会影响光斑修复操作的结果,所以将其统一裁剪掉。
其次,修复数据集图像光斑。针对内窥镜采集照片时会受到光照的影响产生光斑,从而影响网络的注意力导致误检的问题,提出一种光斑修复算法,先对内窥镜图像的光斑部分进行检测并生成mask掩膜,然后去除光斑并用周围的像素值代替。具体算法步骤:①图像阈值分割生成mask掩膜,本文使用的阈值范围是200~255;②使用opencv自带的图像修复函数INPAINT_TELEA实现图像的修复,其中INPAINT_TELEA函数会对位于点附近、边界法线附近和边界轮廓上的像素赋予更多权重,一个像素完成修复以后,它将使用快速行进的方法移动到下一个最近的像素进行修复。
最后,调整数据集图像的分辨率。由于数据集中图片的分辨率不一致,对模型的训练有一定的影响。因此,为了保持网络输入的一致性,将内窥镜图像的分辨率统一调整为224×224像素。通过上述图像预处理方法后的图像与原始图像之间的比较如图2所示。从图2图像预处理前后的对比可以看出,使用所提出的预处理方法对内窥镜图像进行预处理后,图像的光斑被消除,图像的病变更加明显,提高了后续网络模型学习数据集的效率,并在一定程度上提高了算法的鲁棒性。
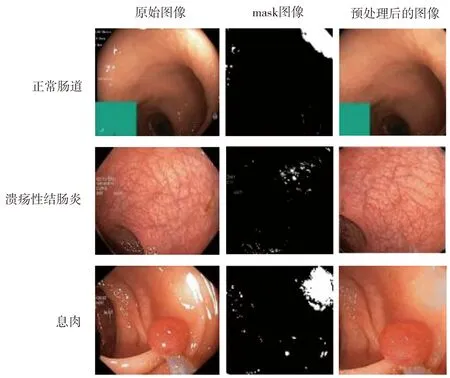
图2 图像预处理
1.2 图像增强
在深度学习中,相同训练条件下,大的样本量更有利于模型的训练。由于本文所使用数据集比较小,为了防止过拟合,使用了一种数据增强方法。该方法随机采用水平翻转、垂直翻转以及水平垂直翻转相结合这3种数据增强策略,保证扩增图像真实性的同时提高模型的泛化性能和鲁棒性。数据增强效果图如图3所示。
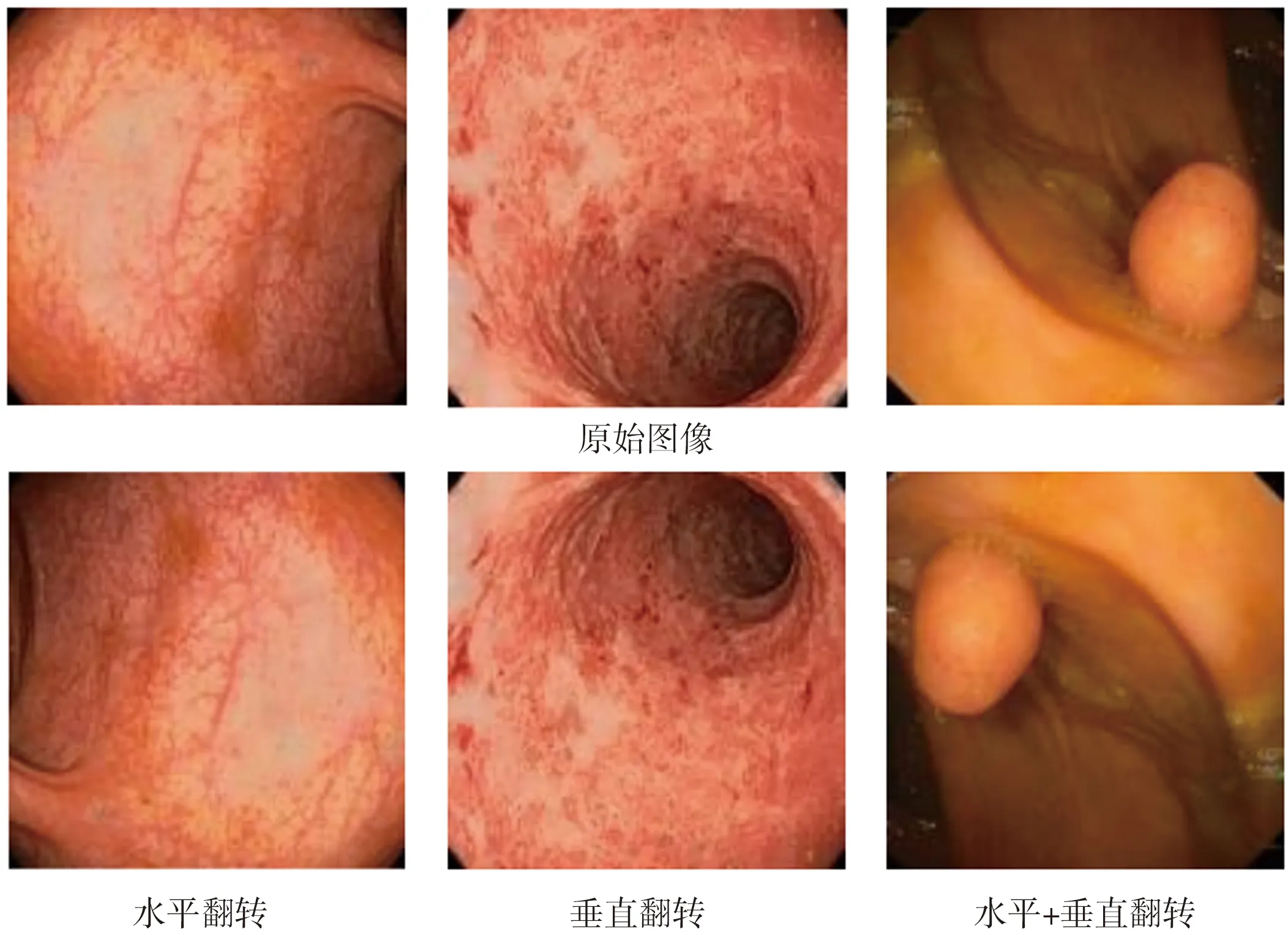
图3 数据增强
1.3 改进的ConvNeXt模型
(1)预训练模型。采用ConvNeXt纯卷积神经网络作为预训练模型,ConvNeXt从ResNet出发,依次从宏观设计、深度可分离卷积、逆瓶颈层、大卷积核、细节设计这5个角度依次借鉴Swin Transformer思想,然后在ImageNet上进行训练和评估,最终得到ConvNeXt的核心结构[12]。ConvNeXt有5个版本:ConvNeXt-T、ConvNeXt-S、ConvNeXt-B、ConvNeXt-L、ConvNeXtXL。本文将选择ConvNeXt-T作为预训练模型,ConvNeXt-T结构图如图4所示。
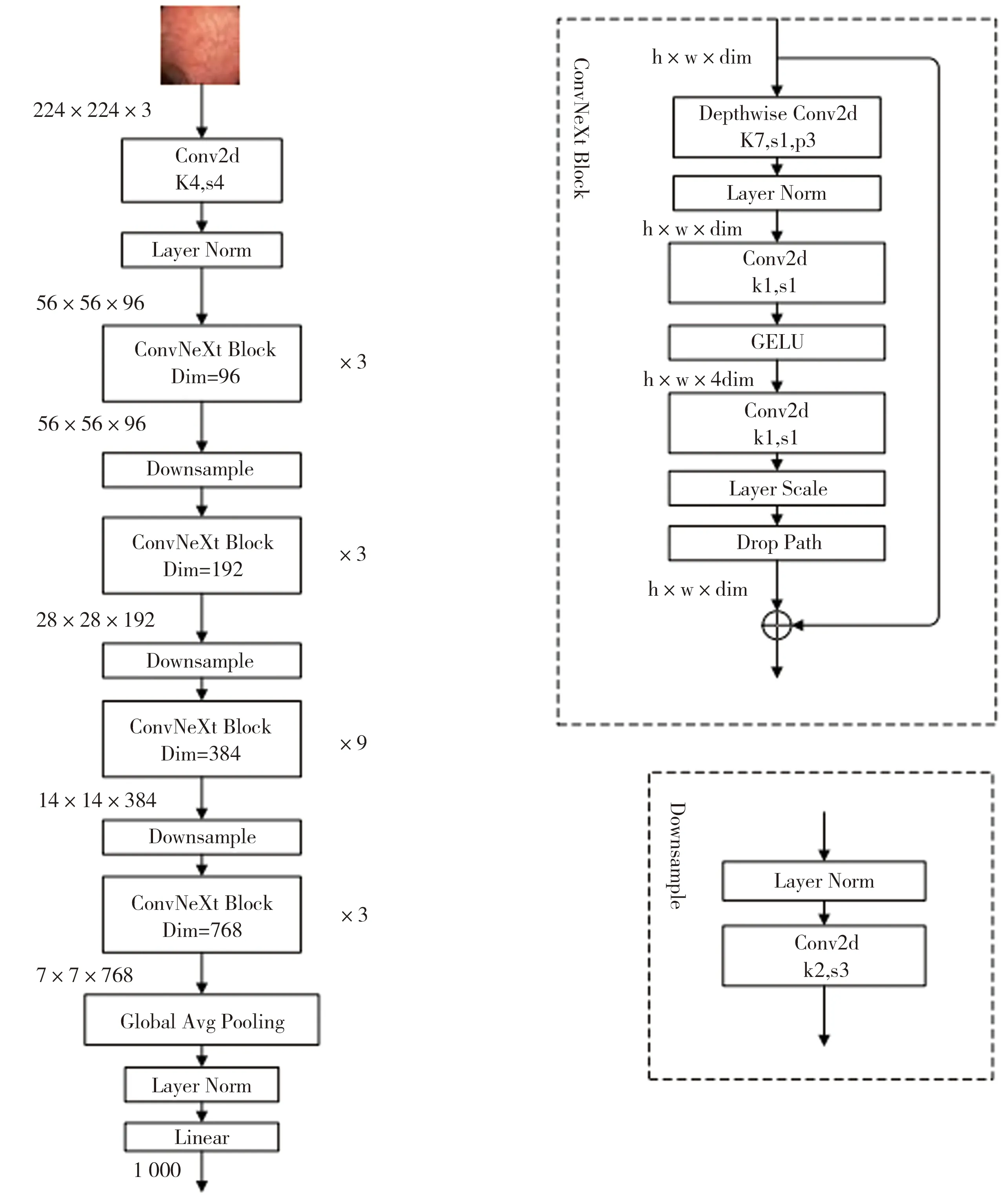
图4 ConvNeXt-T模型结构图
(2)改进的模型。虽然CNN可以获得内窥镜图像的特征信息,但无法提取一些关键信息。传统的注意力机制有SENet、CBAM等,其中SENet主要关注通道上的信息而忽略了位置信息;CBAM将通道注意力机制和空间注意力机制进行结合,现有实验表明,其性能优于SENet[13],但是CBAM对病变的关注不如CA注意力机制,CA不仅捕获跨通道的信息,还能捕获方向感知和位置敏感信息,这有助于模型更准确地定位和识别感兴趣的对象,从而实现更高的分类准确率。因此,本文在ConvNeXt网络结构中添加了CA[14]注意力机制。注意力机制模块作为一个即插即用的模块,可以集成在任何特征图后面,但是由于CA模块的权值具有随机初始化的特点,如果加在网络的主干部分会破坏网络主干部分的权值,并且网络所使用的预训练权重会失去作用,所以改进的模型将CA模块添加到ConvNeXt的非主干部分。将ConvNeXt网络的最后一个ConvNeXt Block作为输入特征输入CA模块,CA模块得到的输出结果输入到ConvNeXt网络的全局池化层进行后续的分类。CA集成到ConvNeXt网络中的结构如图5所示。其中,C代表通道数;H代表高度;W代表宽度;r是用于控制块大小的缩减率。图5中CA模块首先对输入特征沿着水平和垂直方向进行1维平均全局池化,然后拼接起来进行卷积;其次,经过BN+非线性激活函数后,将特征图分割开来分别进行卷积,同时关注水平和垂直方向,然后进入Sigmoid函数;最后得到的两个注意力图就能够很好地反映出感兴趣的对象是否存在于相应的行和列中,能够准确地定位出目标对象的位置。

图5 CA集成到ConvNeXt网络中的结构图
(3)迁移学习。由于医学图像数据集较小,训练深度学习模型比较困难并且训练后模型的泛化能力较弱,因此使用迁移学习的方法。迁移学习首先是在存在大量数据的源域(通常是ImageNet数据集)上进行训练得到预训练权重,然后通过在相关但不同的目标域上训练并且微调预训练权重来实现的。本文使用ConvNeXt-T网络在ImageNet-1k数据集上的预训练权重。首先,由于添加了注意力机制,网络最后3层(Global Avg Pooling,Layer Norm,Linear)的预训练权重失去作用,因此要将其删除。其次,由于ImageNet-1k数据集有1 000个类别,本文使用的内窥镜数据集只有3个类别,所以需要删除最后一个全连接层,取而代之的是适合内窥镜图像分类的全连接层。最后,训练网络所有的权重。微调后网络最后几层如图6所示。

图6 微调后的网络最后几层结构图
(4)损失函数。为了进一步优化模型,将Polyloss损失函数应用在所提出的模型中。Polyloss是一种将分类损失函数加入泰勒展开式的损失函数。Polyloss损失函数由标准交叉熵损失函数修改而来。交叉熵损失函数如式(1)所示:
lossce=-ylogy′-(1-y)log(1-y′),
(1)
式中,y是标签,y′是预测值。
交叉熵损失函数的泰勒展开式如式(2)所示。
(2)
式中,Pt表示目标标签预测的概率。
Polyloss损失函数仅仅修改了交叉熵损失中的第一个多项式系数,如式(3)所示:
(3)
式中,ε1是交叉熵损失中的第一个多项式系数,为了达到最佳效果,需要针对不同的任务和数据调整这个值,最佳值可以通过超参数调整找到。所提模型通过实验选择最优ε1=1。
1.4 评价指标
本文选用准确度、精度、召回率和F1分数4个指标来评估和分析内窥镜图像分类性能,其中,准确性(Accuracy)表示模型预测所有样本中被正确分类样本所占比例;精度(Precision)是指模型预测的所有Positive中预测正确的比例;召回率(Recall)表示所有真实Positive中预测正确的比例;F1分数表示精确率和召回率的调和平均数。各指标计算式如式(4)~(7)所示:
(4)
(5)
(6)
(7)
式中,TP表示被模型预测为正类的正样本;TN表示被模型预测为负类的负样本;FP表示被模型预测为正类的负样本;FN表示被模型预测为负类的正样本。
2 实验验证
为验证基于改进ConvNeXt模型图像分类算法的可行性和有效性,使用Pytorch深度学习框架,采用的硬件配置为Windows 11操作系统,AMD R7 CPU,GTX3060显卡,6G显存。首先利用Hyper Kvasir数据集对所提方法进行了训练和验证,并利用收敛速度较快的AdamW优化器对模型进行了优化。模型训练迭代次数设置为50,批量大小设置为4,AdamW优化器的初始学习速率设置为0.000 5,weight_decay设置为0.005。
本文使用的数据集是公开的Hyper Kvasir数据集中的部分图像,包含1 500张图像,其中正常肠道、息肉、溃疡性结肠炎各500张。此数据集较小,这对于模型的训练更具有挑战性。其中20%作为验证集,80%作为训练集。为了防止过拟合,对训练集使用数据增强的方法扩增为正常肠道、息肉、溃疡性结肠炎图像各600张,共1 800张,用来训练模型。
使用Cross Entropy loss、Focal loss以及Polyloss损失函数分别训练所提出的模型,损失函数曲线如图7所示。从图7可以看出,Polyloss损失函数大概在迭代41次左右趋于稳定,Cross Entropy loss损失函数以及Focal loss损失函数在迭代45次左右趋于稳定。并且,相对于Cross Entropyloss以及Focal loss损失函数,Polyloss损失函数在训练时损失变化更加稳定,鲁棒性更强。

图7 不同损失函数的损失曲线
为了进一步验证改进后模型的优越性,在相同训练条件下,使用ConvNeXt原模型、添加注意力机制CBAM的模型,以及添加CA注意力机制的模型进行对比实验,其结果如表1所示。由表1可以看出,添加CA注意力机制的模型的准确率比原模型准确率高1.6%,比添加注意力机制CBAM的准确率高1.0%,并且使用本文模型在验证集上能够准确识别正常肠道,没有把病变检测为正常的现象,不会导致漏检,具有一定的临床应用潜力。3个模型的Grad-CAM[15]可视化如图8所示。由图8可以看出原始ConvNeXt模型以及添加CBAM注意力机制模型的特征图略显粗糙,专注于更多不相关的区域。相比之下,改进后的模型可以更准确地聚焦病变在内窥镜图像中的位置,在遇到大面积的溃疡性结肠炎时,也能相对准确的关注所有病变区域。

表1 添加不同注意力机制后的比较

图8 Grad-CAM可视化
为了测试该模型的分类性能,将经典网络模型ResNet34、MobileNetV3、EfficientNetV2与改进后的模型进行了实验分析。在相同条件下进行训练,实验结果如表2所示。由表2可以看出,改进后的模型相对于ResNet34、MobileNetV3、EfficientNetV2准确率分别提升1.6%、5.6%、4.5%,从每种病变的Precision、Recall以及F1-Score指标来看,改进的模型基本优于其他模型,说明改进后模型在内窥镜图像分类上的优越性。
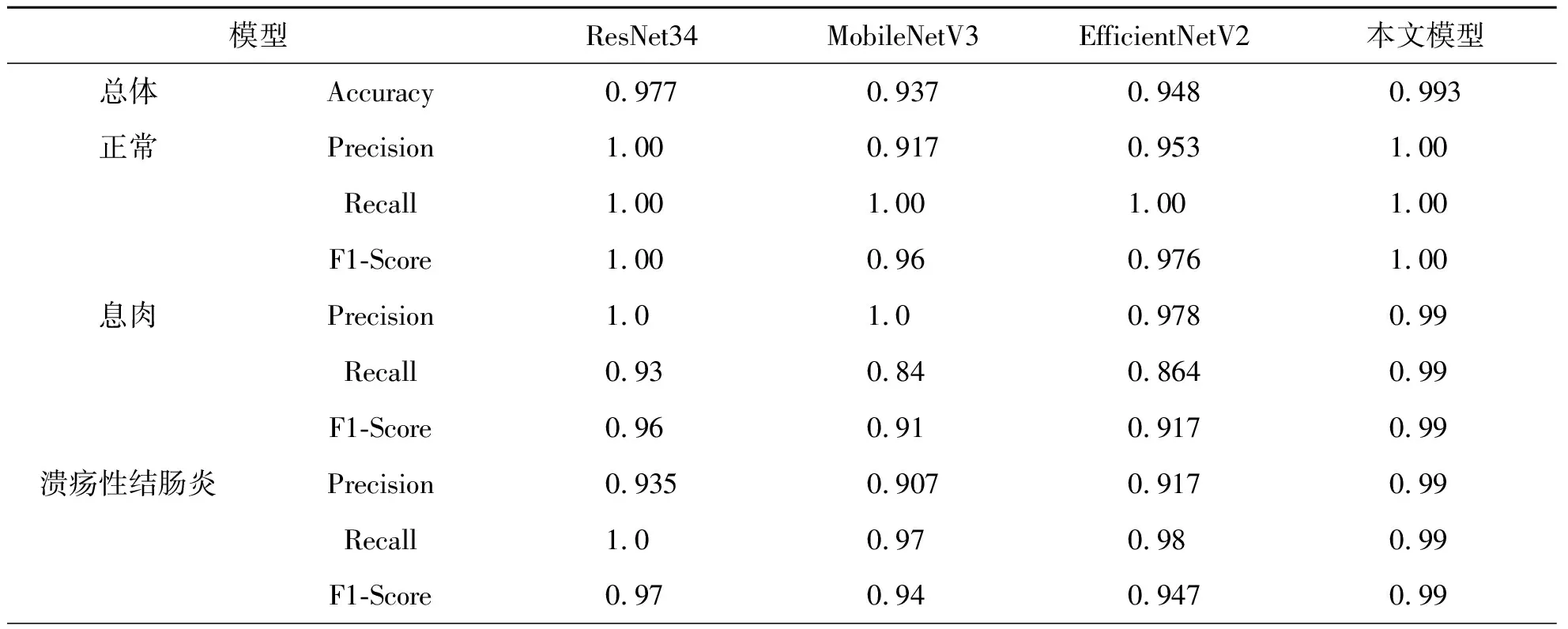
表2 与经典深度学习模型对比试验
为了进一步证明该模型的普遍适用性,将该方法应用于另一个内窥镜图像分类数据集Kvasir。该数据集有8个类别,每个类别1 000张图片共8 000张,其中80%作为训练集20%作为验证集。使用各类评估指标的宏平均作为总数据集的评价指标。并且与其他文献中内窥镜图像分类的深度学习模型进行了比较,结果如表3所示。在表3中,使用了与文献中其他比较算法相同的数据集,不难看出,该方法在4个常用评价指标中取得了最佳效果。其中,本方法的准确率相对于文献[16]~[18]分别提升3.5%、0.9%、3.7%。验证了该方法的有效性和可行性,并表明改进方法在内窥镜图像分类领域具有良好的前景。

表3 与其他现有方法对比试验
3 结论
本文研究了一种结合注意力机制的卷积神经网络的内窥镜图像分类方法,通过选择ConvNeXt模型作为预训练模型,结合迁移学习微调网络模型结构,并添加注意力机制构成一种端到端的分类模型,同时在数据预处理阶段探讨一种光斑修复方法对内窥镜图像高光部分进行修复。实验结果表明,改进后模型的分类性能有明显提高,为溃疡性结肠炎以及息肉的诊断提供了帮助。但是所提模型只对病变进行分类,没有实现病变精准定位,如何实现内窥镜息肉以及溃疡位置的精准定位将是接下来的重点研究工作。
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
现代仪器与医疗(2021年6期)2022-01-18
现代仪器与医疗(2021年4期)2021-11-05
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
