
不平衡回归中的自适应加权采样的稀有值预测
2023-09-20 11:25付光辉李珍珍
计算机仿真 2023年8期
黄 牛,付光辉,李珍珍,寇 颖
(昆明理工大学理学院,云南 昆明 650500)
1 引言
在不平衡回归问题中,预测稀有值特别困难,主要有以下三个方面的问题。第一,样本点分布不均衡。第二,用户的目标是对稀有值进行预测。如果使用传统的方法(如最小二乘回归)对稀有值预测,预测模型误差大,从而预测结果极不准确。第三,标准的预测误差指标(如MAE)不足以衡量模型的性能。Torgo[7]提出用连续的相关函数将目标变量的原始域映射为连续的关联尺度,并根据相关性函数确定样本采样的数目,结合传统的经典算法,提出了SMOTE.R算法,增加了稀有样本数目,解决了样本点分布不均衡的问题。Torgo和Ribeiro[8]提出了一种评价模型性能优劣的方法,该方法更关注预测罕见情况的性能,解决了模型性能评价问题。Ribeiro[9]通过改进的箱线图来自动获取控制点,采用Hermite插值方法对控制点分三段插值,以此获得稀有值的相关函数。该方法避免稀有值真实情况的丢失,从而对稀有值的预测更加准确。然而,以上方法没有考虑到以下两个问题:第一,在不平衡回归学习很多领域内,不同的稀有值其相关性应该有所区别,而不应该将所有稀有值的相关性都取为“1”。第二,Torgo、Ribeiro等人没有考虑稀有值的域偏好,在某些领域内,可能极低稀有值会比极高稀有值显得更重要,或极高稀有值会比极低稀有值显得更重要。应该根据域偏好来确定预测问题是更偏向于极高稀有值预测还是极低稀有值预测,故相关函数图像可能会有左偏或者右偏的情况,而Torgo考虑的是更特殊的情形。
针对Torgo等人在不平衡回归任务中存在的一些问题。本文提出一种结合领域知识的自适应加权采样方法,该方法主要有两个优势:第一,本文提出的相关函数不仅反映目标变量的稀缺性程度,还由此确定了稀有值采样的权重,从而确定了稀有样本生成的个数,解决数据不平衡的问题。第二,解决了领域内稀有值的域偏好问题,是偏好极低稀有值预测还是偏好极高稀有值预测。自适应加权采样方法不仅提高了稀有值的预测精度,还更加符合现实领域的实际情况。
2 相关工作
2.1 SMOTE算法
Chawla[10]提出了SMOTE算法,SMOTE是一种用于解决类不平衡分类问题的重采样方法。在使用几种分类算法的几个现实世界问题上表明了这种方法与其它重采样技术相比的优势。为了使算法适应目标不平衡回归任务,需要处理它的三个关键组成部分:①怎样定义“异常”和“正常”样本;②如何创建新的合成样本(即过采样);③怎样确定新合成样本的目标变量值。对于第一个问题,使用相关函数获取数据集相关性,根据用户域偏好确定阈值,目标变量相关性大于阈值被确定为稀有值,小于阈值的被确定为普通值。关于第二个问题,本文认为越是稀有的点将越重要,相关性也将越高,即过采样生成的样本也越多。最后,第三个问题是确定生成的观测值的目标变量值。本文使用单个随机样本与它的一个k近邻样本二者的目标变量值的加权平均,其权值是由被采样点和它的一个k近邻点与生成样本之间的距离的反函数计算得到的。
2.2 支持向量机回归理论
Smola等[11-14]在支持向量机回归上做了很多的研究,传统的回归模型通常基于输出模型f(x)与真实输出y之间的差别来计算损失,当且仅当二者完全相同时,损失才为0。支持向量回归能假设容忍f(x)与y之间最多有误差ε,当二者之间的误差大于ε时,才计算损失。
正如图1所示,以f(x)为中心,建立一个宽度为2ε的间隔,如果训练样本落入到间隔内,则被认为是预测正确的。

图1 SVR
于是SVR问题就可形式化为
(1)
其中,C是正则化常数。lε是所示的ε-不敏感损失函数
(2)
回归问题的本质是找到一个模型,能够最佳程度拟合数据点。用线性回归作为对比,线性回归的拟合方式是:让数据点到预测的直线相应的MSE值最小。但是对于SVM来说,回归思路不同。需要找一个间隔值,在这个间隔内,能包含样本数据点越多越好。在间隔范围内的数据点越多,就代表预测效果越好。选择间隔中间的直线作为回归结果,用它来预测未知点对应的y值。用SVM解决分类和回归问题时,方法上截然不同。解决分类问题要求间隔内的样本点越少越好,特别是硬间隔的时候,一个样本点都不允许存在,而接近回归问题时,希望间隔范围内的数据样本有越多越好。
3 改进的算法
3.1 相关函数
Torgo在类似的背景下提出相关性的概念。它们将目标值转换为相关性的尺度,以此获得稀有值的重要性。为了在这样的条件下获得相关函数,需要一种自动方法来确定哪些目标变量值具有最小和最大的相关性(重要性)。鉴于分布中稀有值被认为是最重要的,为准确预测,这些值应该具有最大的相关性。相反,最常见的值应该具有最小的相关性。相关性是通过“目标变量”来确定,建议使用相关函数φ(Y),它将目标变量的原始域映射为连续的关联尺度。在回归中,考虑到目标变量的定义域是无限的,用“0”表示完全不相关的值,用“1”表示最大相关值。对用户来说,以分析的方式指定这样的函数并不总是那么容易。不过,对于某些应用程序,可以提出一个合理的自动生成的相关函数。实际上,在这些领域中,相关性与目标变量的稀缺性和极端性有关。箱形图提供了有关极端值的关键信息。所有高于第三四分位数或者低于第一四分位数的值,标记为稀有值。这些值对应高(低)稀有值。对于目标变量,可能有两种类型的稀有值,同时存在极低和极高稀有值,或者只有高(低)稀有值。那么在定义相关函数要考虑以下两个问题:①应该正确识别稀有值,给极低稀有值和极高稀有值赋予更高的相关性。②要符合现实领域的不平衡回归问题的实际情况。在此背景下,提出了如下函数
(3)
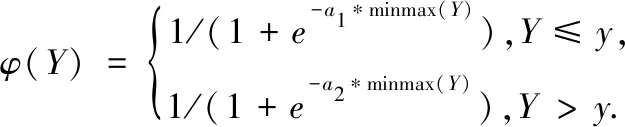
(4)
式中Y为目标变量,y为用户在该领域的领域偏好,a1和a2均为参数。
以美国波士顿房价为例,从图2中可以看出低房价和高房价都有着较大的相关性,并且相关性函数左偏,意味着高房价比低房价更为“异常”,对国家经济和社会影响更大。从图中显示a1比a2稍大,函数左偏,故低房价获得更低的相关性。如果参数a1比a2偏小,那将忽视了低房价的“异常”而可能导致决策者做出经济误判,因此需要提高a1的大小来正确识别“异常值”。同理,如果相关函数右偏,则需提高a2的大小。a1与a2通常与域偏好有关。

图2 波士顿房价相关函数

图3 新数据集生成框架
3.2 算法步骤
本文的算法是对普通值进行欠采样,对用户感兴趣的值(稀有值)进行过采样,从而得到一个新的训练集,其训练数据值的分布更加均衡。
1)算法1:获取稀有值
输入:数据集D,相关性程度w,中位数median(y),相关性程度的阈值tE
输出:极低稀有值rareL,极高稀有值rareH,普通值comvalue
步骤1:将数据集D中的每个数据〈x,y〉通过相关函数得到其相关性程度w。
步骤2:对于数据集D中的每个数据〈x,y〉,如果其w大于阈值tE并且目标变量Y大于median(y),则为极高稀有值rareH。
步骤3:对于数据集D中的每个数据〈x,y〉,如果其w大于阈值tE并且目标变量Y小于median(y),则为极低稀有值rareL。
步骤4:普通值comvalue=D areH∪rareL
2)算法2:过采样、欠采样、混合采样
输入:rareH,rareL,comvalue,w,m(与不平衡比有关的参数),ε(参数)
输出:欠采样个数n1
步骤1:依据相关性程度,将rareH和rareL中的每一个数据集分到三个区间,相关性在[tE,tE+ε)上,生成样本个数为m,相关性在[tE+ε,tE+2ε)上,生成样本个数为2m,相关性在[tE+2ε,1]上,生成样本个数为3m。
步骤2:(欠采样过程)comvalue中的每一个数据集获取其单个数据相关性w(k),comvalue数据集中的相关性w(k)越大,越应被保留,得到欠采样个数n1。
步骤3:对步骤1和步骤2操作可得到过采样的样本个数和混合采样的样本个数。
3)算法2:样本合成
输入:rareH、rareL
输出:NewrareH,NewrareL
步骤1:从rareH中随机选取一个样本点xHi,然后选取xHi的k近邻xHik,通过SMOTE合成新的样本xHX=xHi+random(0,1)|xHik-xHi|,计算xHi与xHX的欧式距离dH1=dist(xHi,xHX),计算xHik与xHX的欧式距离dH2=dist(xHik,xHX),目标变量HYi=(dH2yHi+dH1yHik)/(dH1+dH2)。
步骤2:从rareL中随机选取一个样本xLj,并且选取xLj的k近邻xLjk,通过SMOTE合成新的样本xLX=xLj+random(0,1)|xLjk-xLj|,计算xLj与xLX的欧式距离dL1=dist(xLj,xLX),计算xLjk与xLX的欧式距离dL2=dist(xLjk,xLX),目标变量LYi=(dL2yLj+dL1yLjk)/(dL1+dL2)。
步骤3:根据每个样本合成的数目,重复步骤1和步骤2,最终得到NewrareH、NewrareL。
3.3 评价指标

(5)

(6)

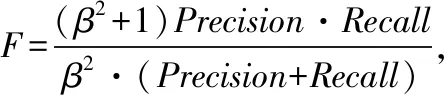
4 应用试验
4.1 数据集
本文的实验目的是测试提出的采样方法在预测连续目标变量的罕见方面的有效性。为此选择了8个回归数据集,这些数据集可以在UCI上获得。表1显示了这些数据集的主要特征。从表1中的数据可以看出,平均14.75%的可用样例是稀有值。

表1 数据集特征
4.2 试验结果与分析
通过构建SVR模型比较过采样、欠采样、混合采样三种方法预测连续目标变量稀有值回归的性能。实验基于R平台,实验结果经100次重复试验获得。表2、表3分别列出三种采样方法在8个数据集上的recall和precision,图4展现了三种采样方法在8个数据集上的F值。试验结果表明:过采样、欠采样、混合采样在所有数据集上其F值分别提高7.3%、1.8%、8.4%。可以看出欠采样提升不明显,而且在某些数据集上,其F值甚至有下降的趋势,这就说明单纯地删除普通值样本达不到准确预测稀有值的目的。而在过采样和混合采样中,过采样的precision提升效果更佳,混合采样的recall提升更加明显。因此,在处理不平衡回归问题时,无法判断何种采样方法处理不平衡问题更优,应根据具体的数据特性和需求选取合适的方法。此外,考虑到参数a1和a2会影响回归的性能。本文选取Boston房价为例,图5是在a2=6.1的条件下探究a1对F值的影响。从图中可以看出,a1在某一范围内其F值会趋于稳定。图6是在a1=8.1的条件下探究a2对F值的影响。从图中可以看出,随着a2的变化,F值波动较大,F值是先增大而后减小。但从提升回归效果上看,在过采样、混合采样中,不同参数的选取其性能提升的幅度趋于稳定,由此说明了自适应加权采样对稀有值准确预测提升效果明显。

表3 不同采样的pre

图4 过采样、欠采样、混合采样的F值

图5 参数a2=6.1 图6参数a1=8.1
5 结语
本文的主要贡献是:将抽样方法成功地应用于这类回归任务。并且考虑了每个稀有值样本的重要性,从而为稀有值数据点训练出更好的模型,体现了自适应加权采样在不平衡回归任务中的优越性。本文针对一系列不同的问题进行了大量的实验,突出了其优势。但是也存在一些问题需要讨论和进一步研究。第一,自适应加权方法在处理不平衡回归问题时表现出良好的优势,然而现实中数据的表现形式多种多样,在面临不同类型不平衡数据时,如何利用该技术来提升学习算法性能仍需深入研究。第二,能否把一些经典的采样方法应用于不平衡回归领域。因此,后续工作任务需要在此基础上进行更深层次的研究。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化·高一版(2021年2期)2021-03-19
河北理科教学研究(2020年2期)2020-09-11
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
