
加权概率区间值犹豫模糊集及决策应用∗
2023-10-10 07:21朱国成胡伟张娟
新疆大学学报(自然科学版)(中英文) 2023年5期
朱国成,胡伟,张娟
(1.广东创新科技职业学院通识教育学院,广东 东莞 523960;2.广州科技贸易职业学院经济管理学院,广东 广州 511442)
0 引言
在不确定信息环境下的多属性群决策问题中,决策者在使用精确数据信息描述自己认知心理时,不能完整、客观与全面地反映决策对象的真实情况,因此,相较于具体数值构成的经典集合,模糊集能够更好地处理多属性群决策问题[1].由于人们掌握知识水平的局限性以及表达信息方式的多样性,于是学者们给出了模糊集的各种拓展形式,如: 语言术语集[2]、区间模糊集[3]、直觉模糊集[4]、区间直觉模糊集[5]等经典模糊集.但经典模糊集中仅使用一个隶属度值来刻画决策信息,不能很好地解决人们对同一问题见解多样性导致的模糊性问题[6].为此,Torra[7]给出了模糊集的另一种拓展形式,即犹豫模糊集.犹豫模糊集中的单位元称之为犹豫模糊元,其是由若干个不同的隶属度值构成的集合.随后许多学者相继研究了犹豫模糊集的相似度[8]、熵[9]、相关系数[10]、包含度[11]、α-截集[12]等.文献[13-15]还分别研究了犹豫模糊集在聚类分析、多属性决策以及数学表达式检索结果相关排序问题中的应用等.随着犹豫模糊集在群决策问题中的深入应用,其自身存在的局限性开始凸显: 在犹豫模糊集中默认所有的隶属度值出现的概率相等,没有考虑决策者对于各个隶属度值的偏好问题,因而容易损失决策信息.为了有效弥补这一不足,Zhang 等[16]给出了概率犹豫模糊集的概念(不同的隶属度值发生的可能性用概率表示).由于在概率犹豫模糊环境下的群决策案例中,不同的决策者喜欢使用不同类型的隶属度值参与测评,继而Pang 等[17]定义了概率语言术语集,He 等[18]定义了概率区间值犹豫模糊集(Probabilistic Interval Valued Hesitant Fuzzy Set,PIVHFS).
针对概率区间值犹豫模糊集多属性群决策问题的研究,王金凤等[19]建立了基于关联系数的概率区间值犹豫模糊集群决策模型; 陈惠琴等[20]给出了满足封闭性的概率区间值运算公式,并提出了概率区间值犹豫模糊集的加权平均算子与加权几何算子; 周小领等[21]提出了一系列概率区间犹豫模糊信息集成算子; 朱国成[22]将决策专家的权重注入概率区间值犹豫模糊集中,定义了加权概率区间值犹豫模糊集(Weighted Probabilistic Interval Valued Hesitant Fuzzy Set,WPIVHFS),并在WPIVHFS 刻画决策信息的基础上建立多属性群决策模型.
目前,关于概率区间值犹豫模糊集多属性群决策问题的研究皆在概率区间犹豫模糊情境下来建立决策算法,实现对概率区间值犹豫模糊集的应用目的.同时在对方案排序时,一般做法是直接对决策专家组给出的方案评审信息进行集结以获取各方案的综合属性值,并根据各方案的综合属性值大小达到排序方案目的.由于上述研究中不但在原始的评审信息中没有考虑决策专家的重要性,而且也没有兼顾决策专家组内部成员之间给予方案的评价信息差异程度值,因而容易造成与实际情况不符的排序结果.
鉴于以上分析,本文针对WPIVHFS 多属性群决策问题,首先,给出了区间值隶属度的中位数、区间值隶属度的清晰度定义,并采用四维点坐标来刻画WPIVHFS,从维度的角度出发来研究WPIVHFS.其次,在采取四维点坐标刻画WPIVHFS 的基础上,建立了计算加权概率区间值犹豫模糊元(Weighted Probabilistic Interval Valued Hesitant Fuzzy Element,WPIVHFE)的外部固定函数值模型与内部稳定函数值模型、2 个WPIVHFE 的大小比较规则以及距离测度模型.再次,考虑方案的外部固定函数值(评审专家组给予该方案的评分值)与内部稳定函数值(评审专家组成员之间关于方案的评价信息差异程度值) 来计算方案的综合属性值.最后,通过一个数值算例来分析文中理论与方法的可行性.
1 预备知识

则PIVHFE h1(p1)与h2(p2)的大小比较规则为:
(i)若△(h1(p1))>△(h2(p2)),则有h1(p1)>h2(p2);
(ii)若△(h1(p1))=△(h2(p2)),则分三种情况:
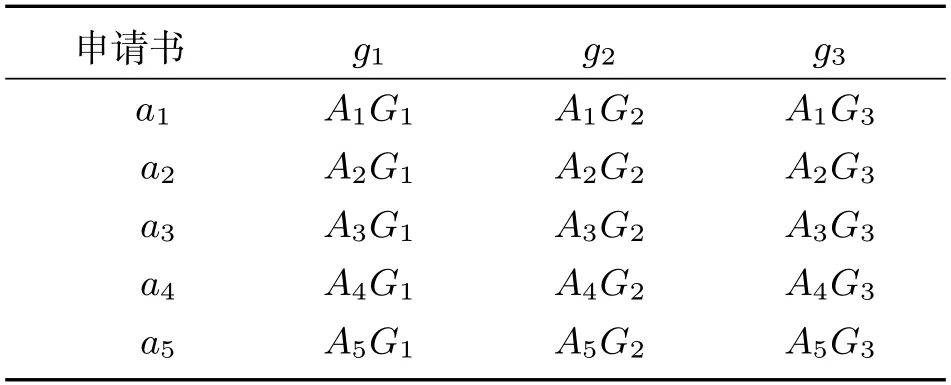
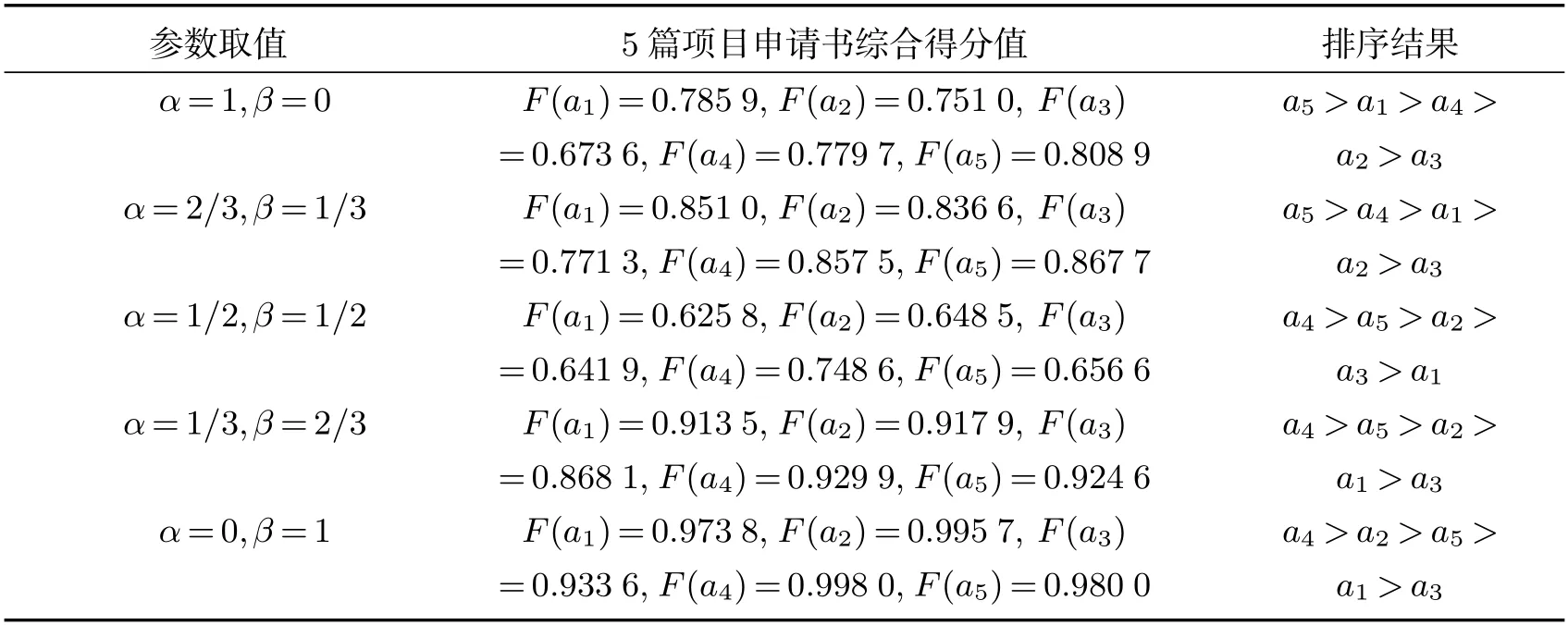
(a) 当∇(h1(p1))>∇(h2(p2))时,有h1(p1) (b) 当∇(h1(p1))<∇(h2(p2))时,有h1(p1)>h2(p2); (c) 当∇(h1(p1))=∇(h2(p2))时,有h1(p1)=h2(p2). 定义4[23]对于任意2 个元素数目相等的PHFE h1(p1)与h2(p2),二者距离测度d 需要满足以下3 个公理性条件: (i)非负性,d(h1(p1),h2(p2))≥0; (ii)可交换性,d(h1(p1),h2(p2))=d(h2(p2),h1(p1)); (iii)反身性,d(h1(p1),h2(p2))=0h1(p1)=h2(p2). 在建立模型来解决方案排序问题的过程中,计算属性权重是一个不可或缺的重要步骤.计算属性权重比较成熟的方法有熵值法、离差最大化方法、线性规划法等.其中,熵值法确定属性权重的核心思想是根据所有方案在各属性上的评价信息差异程度来计算各属性的权重.本文利用熵值法来计算属性权重,有别于前人的计算思路,这里不仅考虑所有方案在各个属性上的评价信息差异程度,而且还兼顾所有方案在各个属性上的决策专家内部评价信息差异程度. 根据方案在各个属性上评价信息的差异程度计算出的外部权重用ω1j(j ∈{1,2,···,J})表示,根据方案在各个属性上决策专家内部评价信息的差异程度计算出的内部权重用ω2j(j ∈{1,2,···,J})表示,属性的综合权重用ωj(j ∈{1,2,···,J})表示.具体计算过程如下: 步骤1 计算属性的外部权重ω1j、内部权重ω2j以及综合权重ωj(j ∈{1,2,···,J}). 步骤2 由式(1)、式(2) 分别计算各方案在所有属性上的外部固定函数值ϕ((pij)) 与内部稳定函数值φ((pij))(i=1,2,···,I;j=1,2,···,J). 步骤3 计算各方案的综合属性值F(ai),其中 在式(4)中,参数α,β ∈[0,1]且α+β=1,式(4)表达的含义为: 决策者可以依据方案在属性上的外部固定函数值与内部稳定函数值来计算方案的综合属性值,式(4)通过对参数α,β 灵活选取,可以从不同角度观察方案的排序结果. 步骤4 根据方案的综合属性值F(ai)进行排序,F(ai)值大者其对应的方案ai为优. 步骤5 结束. 某校科技处收到关于教育教学内容方面的5 篇项目申请书,按照学校教学科研工作安排,准备择优选取2项作为立项项目.科技处邀请3 位评审专家对5 篇项目申请书进行评审,从申请书中阐述方法的可行性(g1)、理论研究系统性(g2)以及创新性(g3)等3 个维度进行评审,3 位评审专家表示为zt(t=1,2,3),其权重依次为0.25、0.35、0.4.5 篇论文标记为ai(i=1,2,3,4,5),3 个评审维度的外部权重(ω1j)、内部权重(ω2j)、综合权重(ωj)均未知(j=1,2,3),3 位评审专家给出的原始评审数据信息见表1.其中: 表1 5 篇项目申请书的评审信息表 A1G1={[0.62,0.72]|z1,[0.65,0.78]|z2,z3},A2G1={[0.84,0.96]|z1,z2,z3}, A1G2={[0.74,0.88]|z1,[0.68,0.84]|z2,[0.62,0.78]|z3}, A1G3={[0.82,0.94]|z1,z2,z3},A2G2={[0.68,0.76]|z1,z2,[0.72,0.82]|z3}, A2G3={[0.72,0.78]|z1,[0.66,0.76]|z2,[0.64,0.72]|z3}, A3G1={[0.71,0.79]|z1,[0.67,0.75]|z2,z3},A3G2={[0.86,0.96]|z1,z2,z3}, A3G3={[0.71,0.77]|z1,[0.73,0.79]|z2,[0.65,0.71]|z3}, A4G1={[0.61,0.67]|z1,[0.63,0.71]|z2,[0.65,0.75]|z3}, A4G2={[0.68,0.76]|z1,z2,z3},A4G3={[0.8,0.94]|z1,z2,z3}, A5G1={[0.71,0.77]|z1,z2,[0.73,0.79]|z3},A5G3={[0.78,0.82]|z1,z2,z3}. A5G2={[0.64,0.76]|z1,z2,[0.68,0.78]|z3}. 应用本文方法对以上5 篇项目申请书进行量化分析并排序.在建立决策模型之前,可以先将表1 中的原始评审信息转换为PIVHFS 决策信息,再将评审专家权重注入PIVHFS 决策信息中,以此构建WPIVHFS 决策信息,最后用四维点坐标描述决策信息,如表2 所示. 表2 平面向量评审信息表 其中: a1g1={(0.67,0.861 1,0.333 3,0.25),(0.72,0.822 8,0.666 7,0.75)}, a1g2={(0.81,0.913 6,0.333 3,0.25),(0.76,0.809 5,0.333 3,0.35),(0.70,0.794 9,0.333 3,0.40)}, a1g3={(0.88,0.872 3,1.00,1.00)},a2g1={(0.90,0.875 0,1.00,1.00)}, a2g2={(0.72,0.894 7,0.666 7,0.60),(0.77,0.878 0,0.333 3,0.40)}, a2g3={(0.75,0.923 1,0.333 3,0.25),(0.71,0.868 4,0.333 3,0.35),(0.68,0.888 9,0.333 3,0.4)}, a3g1={(0.75,0.898 7,0.333 3,0.25),(0.71,0.893 3,0.666 7,0.75)}, a3g2={(0.91,0.895 8,1.00,1.00)},a4g2={(0.72,0.894 7,1.00,1.00)}, a3g3={(0.74,0.922 1,0.333 3,0.25),(0.76,0.924 1,0.333 3,0.35),(0.68,0.915 5,0.333 3,0.40)}, a4g3={(0.93,0.898 0,1.00,1.00)},a5g3={(0.80,0.951 2,1.00,1.00)}, a4g1={(0.64,0.910 4,0.333 3,0.25),(0.67,0.887 3,0.333 3,0.35),(0.70,0.866 7,0.333 3,0.40)}, a5g1={(0.74,0.922 1,0.666 7,0.65),(0.76,0.924 1,0.333 3,0.35)}, a5g2={(0.70,0.824 1,0.666 7,0.60),(0.73,0.871 8,0.333 3,0.40)}. 步骤1 用本文方法计算评审维度的外部权重(ω1j)、内部权重(ω2j)与综合权重(ωj)(j=1,2,3)分别为: ω11=0.238,ω12=0.325,ω13=0.435; ω21=0.314,ω22=0.335,ω23=0.349 9; ω1=0.441 9,ω2=0.058 1,ω3=0.5. 步骤2 由式(1)、式(2)分别计算5 篇项目申请书在3 个评审维度上的外部固定函数值与内部稳定函数值. 步骤3 利用式(4)计算5 篇项目申请书的综合评审结果数值F(a1),5 篇项目申请书的排序结果见表3. 表3 参数取不同值时的排序结果 由表3 的排序结果可知,若全部采用项目申请书的外部固定函数值进行排序,则应当选取第5 篇与第1 篇作为立项项目.若全部采用项目申请书的内部稳定函数值进行排序,则应当选取第4 篇与第2 篇作为立项项目.考虑到项目申请书的内部稳定函数值只能反映该项目的评审专家意见统一程度,不能说明该项目申请书内容的质量高低,故全部采用项目申请书的内部稳定函数值进行排序不可行(若评审专家组认为5 篇项目申请书的质量几乎无差别,此时可以从评审专家组关于项目申请书的内部固定函数值的角度出发进行排序,也可以选取参数取值为α=0,β=1).第4 篇项目申请书与第1 篇项目申请书关于评审专家组的内部成员之间的评分差异值比较敏感,敏感值介于0 至1/3 之间.故选取第5 篇、第1 篇作为立项项目或者第5 篇、第4 篇作为立项项目,需要决策者根据实际情况(是否关注评审专家组的内部意见统一程度)来最终确定. 为了在原始的PIVHFS 决策信息中体现决策专家的重要性,本文给予每个区间隶属度值赋予了决策专家权重,进而定义了WPIVHFS,并在四维点坐标基础上建立了WPIVHFS 新的测度范式,通过在具体决策案例中的应用可知: 将决策专家的权重注入PIVHFS 中是必要的; 采用四维点坐标来刻画WPIVHFS,并在此基础上建立的决策模型不但可以达到排序方案目的,而且可以从多个角度来观察各方案的排序结果,为精准地确定最优方案提供了一种有效路径; 相较于在PIVHFS 情境下建立的决策算法,在四维点坐标条件下建立的决策算法操作方便、计算量小,能够快速取得方案的排序结果. 接下来的工作是进一步开展WPIVHFS 的集成算子和加权概率犹豫模糊语言术语集的研究,从而进一步深入开展基于加权概率犹豫模糊集多属性群决策方法研究,并应用于解决实际决策问题,进一步为多属性群决策的理论与方法提供新思路与新路径.2 WPIVHFS 定义与测度范式




3 建立多属性决策模型

3.1 计算属性权重

3.2 决策过程
4 数值算例

5 结论
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
数学大世界(2021年4期)2021-03-30
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
当代陕西(2017年12期)2018-01-19
派出所工作(2017年10期)2017-05-30
电测与仪表(2016年23期)2016-04-12
中国畜牧业(2016年6期)2016-02-17
佳木斯大学学报(自然科学版)(2014年4期)2014-07-09
河北大学学报(自然科学版)(2013年5期)2013-03-01
