
基于GPU的卫星通信基带处理高吞吐率并行算法*
2023-10-24 02:52李荣春王庆林梅松竹
计算机工程与科学 2023年10期
李荣春,周 鑫,王庆林,梅松竹
(国防科技大学计算机学院并行与分布处理国防重点实验室,湖南 长沙 410073)
1 引言
近年来,随着近地卫星数量越来越多,卫星通信也越来越被广泛应用于航海、军事、应急通信,甚至是手机通信中。卫星通信因为其全覆盖、高稳定性和高鲁棒性,更加被人们所接受。卫星数字传输信号的处理通常由数字信号处理器DSP(Digital Signal Processor)或者现场可编程逻辑门阵列FPGA(Field Programmable Gate Array)完成。近年来,GPU(Graphics Processing Unit)凭借其强大的高速并行计算能力和丰富便捷的编程接口等优势逐渐开始在数字信号处理领域扮演十分重要的角色。在卫星高速数字传输的应用场景下,要对接收到的信号进行解调、同步和译码等一系列计算,为了实现高速传输的目的,应最大程度降低处理设备的计算时延,提高信号处理的吞吐率。利用GPU的并行多线程的计算能力,能够实现卫星信号多路、多帧的并行处理,还能利用多线程运算对信号处理算法进行并行优化,降低处理时延。与专用元器件和FPGA相比,基于GPU的数字传输信号处理器开发周期短,能够适配的信号制式类型完全由软件来定义,还可以根据需求灵活调整配置,从而达到最佳性能,具有较好的应用前景。
利用GPU进行基带处理并行算法的设计有以下难点。首先,GPU是批处理模式,利用多个并行计算单元对大批量数据进行并行计算,而通信协议中基带处理算法的延迟要求在毫秒级,速率要求极高,这就对GPU并行算法的延迟和吞吐率提出了一定的要求;其次,很多基带处理算法是按照位运算进行设计的,数据序列之间存在一定的数据依赖性,如果采用GPU进行并行计算,需要重新设计并行算法,打破数据序列之间的依赖关系,从而可以将这些数据分布到多个计算单元上实现并行计算,这对并行算法的改造提出了一定的挑战;最后,多个基带算法之间需要低延迟的快速切换,这对算法群之间的缓冲区设计提出了更高的要求。
本文针对上述3个难点,提出了基于GPU的卫星通信基带处理高吞吐率并行算法,通过巧妙的并行算法设计,打破数据序列的顺序依赖关系,并通过性能优化、缓存区优化,解决吞吐率与延迟问题,有效支持卫星通信协议在GPU上的高速执行。
2 卫星通信基带链路
卫星通信下行链路主要对卫星信号进行解析,其基带算法负责对数字传输信号进行处理,并将其还原成发送端原始数据。本文优化的基带链路是全球导航卫星系统GNSS(Global Navigation Satellite System)的卫星通信下行链路[1]。卫星通信下行链路主要包括重采样、匹配滤波、解相位模糊、帧同步和解扰等过程,解调后的数据还需要进行判决和译码,最后得到原始数据。解调包括BPSK/QPSK/8PSK/16QAM这4种星座映射模式。译码过程包括了基于国际空间数据系统咨询委员会CCSDS(Consultative Committee for Space Data Systems)标准的低密度奇偶校验LDPC(Low Density Parity Check)码、里德-所罗门RS(Reed-Solomon)码、卷积码以及RS码+卷积码级联码。
3 相关工作
近年来,基于GPU的无线通信并行算法引起学术界和产业界越来越多的重视。大多数工作聚焦于单个无线通信算法的GPU加速,如基于GPU的同步算法[2]、Viterbi算法[3]、解调算法[4]、LDPC算法[5-8]、极化码[9]、信道估计算法[10]、MIMO-OFDM(Multiple-Input Multiple-Output,Orthogonal Frequency Division Multiplexing)检测器[11]等。
目前很多研究人员开始研究基于GPU的完整的通信链路,如WiMAX[12]和WiFi[13]。近些年,随着卫星通信的兴起,越来越多的研究人员开始聚焦基于GPU的卫星通信基带并行算法研究[14-20],如基于直接位置估计DPE(Direct Position Estimation)的全球导航卫星系统(GNSS)GPU接收机[14]、全球导航卫星系统反射测量GNSS-R(Global Navigation Satellite System-Reflectometry)GPU接收机[15]、基于多GPU负载均衡的GNSS接收机[16,17]、基于GPU的GNSS多径并行仿真器[18]、基于MPI+CUDA的遥感卫星数据处理通用系统[19]和基于GPU的信号相关器的GNSS接收机。以上大多数研究都是针对接收机链路中的部分算法进行并行优化,本文基于GPU实现GNSS卫星通信基带接收机完整下行链路算法群。
4 基于GPU的卫星通信基带并行算法
4.1 基于GPU卫星通信基带信号处理框架
基于GPU基带信号处理框架主要面向NVIDIA系列GPU,使用CUDA C/C++开发,采用了B/S架构,便于远程监控处理程序运行状态。如图1所示,该框架的功能模块可分为解调模块、译码模块和辅助模块,其中每个模块又根据各自特点分成多个子模块。解调模块负责完成接收到的下变频后的数字传输信号重采样、匹配滤波、帧同步、解扰、判决等译码之前的所有步骤。经过解调判决的数据继续留存在GPU内存中参与后续的译码运算。译码模块根据事先设置好的译码参数,对解调后的程序进行译码。图1中,r表示译码码率,Lk表示信息位长度。辅助模块包括了参数配置、文件读写、状态显示和日志输出等子模块,负责配合处理程序完成处理任务。解调模块和译码模块既可联合使用,又可独立运行,程序的运行次序和功能均可以根据参数来确定。

Figure 1 Framework of baseband signal processing for satellite communication based on GPU
卫星基带信号处理包含了复杂的控制逻辑、密集的浮点计算和频繁的不规则访存,为了提高处理速度,框架通过结合算法的计算规律和访存特性,设计并实现了基于GPU的高速并行解调算法和并行译码算法。设计的并行位同步算法和并行滤波算法,对原有串行算法进行了粗粒度和细粒度的并行优化,在低误码率损失的情况下实现了BPSK/QPSK/8PSK/16QAM的高速解调。该加速器还实现了基于CCSDS标准的LDPC码、RS码、卷积码以及RS码+卷积码级联码的并行译码。其中,LDPC码采用了MSA(Min-Sum Algorithm)译码算法,RS码采用了BMA(Berlekamp-Massey Algorithm)译码算法,卷积码采用了Viterbi译码算法。在实现MSA并行译码算法的过程中,使用了两段式求解最小值的并行算法,提高了译码速率。在实现BMA并行译码算法的过程中,对Chien搜索算法进行了并行优化,大幅提高了寻找错误位置的速度。Viterbi译码算法实现了并行butterfly算法来计算路径度量值,并且使用截断-重叠译码的方式实现了卷积码多码块并行译码。如图2所示,该解调器的解调、帧同步和译码等计算过程均在GPU上实现,CPU仅负责控制计算流程和数据文件读写操作,该方案有效避免了CPU和GPU通信带来的开销。

Figure 2 Division of CPU and GPU computing tasks
CPU和GPU的任务分工如图2所示。框架输入是参数文件和对应的数据文件,数据文件先由CPU从磁盘读入主机内存,同时CPU会根据参数文件中的配置参数进行一系列的初始化操作,然后将主机内存中的数据分批次传入GPU内存。当数据传入GPU内存时,即开启GPU的工作周期。首先由解调模块的GPU核函数依次对传入信号的正交分量I路数据和Q路数据进行处理运算。当解调模块各个步骤结束之后,由帧同步子模块将处理结果排列成固定帧长的连续码字,并送入译码模块进行译码。译码模块按照参数文件中的配置开始并行译码。译码结束后,译码结果被传入CPU内存,最终由CPU将结果写入磁盘。
4.2 基于GPU的并行解调算法
解调模块支持对BPSK、QPSK、8PSK、16QAM这4类调制方式的并行解调。信号在解调的重采样过程中使用了Gardner位同步算法来确定最佳采样时刻。FPGA和DSP在处理信号时可以将信号按照连续序列依次处理,通过高速计算单元和并行计算逻辑来加快处理速度。GPU处理信号数据的时候通常需要一次性将大量的数据传入GPU内存,经过计算后再将结果传回CPU内存。这样避免了CPU-GPU的频繁通信造成的处理时延。GPU还能够利用丰富的并行计算资源一次性计算多组结果,实现更高的处理吞吐率。由于GPU内存有限,这时候的信号数据往往是被截断的、不连续的。在位同步的计算过程中,接收载波的时钟相位不断变化,数字控制振荡器NCO(Numerically Controlled Oscillator)环路生成的采样间隔也在不断校准,这样累计校准的算法使得位同步的计算成为一个基于时间序列的算法。对于t时刻的时钟误差只能从起始时刻t0一步一步校准得到,而无法从任意中间时刻的采样点开始计算,这给位同步计算的并行化带来了极大的挑战,使得GPU丰富的内存资源和计算资源没有了用武之地。然而对于单路信号而言,位同步计算的并行化还是可以针对重采样过程中拉格朗日插值和采样间隔的计算这2个环节进一步优化,以实现更低的计算时延。
重采样后的信号要经过匹配滤波来获取更好的解调效果。匹配滤波本质上就是对采样结果进行线性卷积运算。虽然线性卷积依然是基于时间序列的算法,但是已经有方法能够通过循环卷积来代替线性卷积,将计算的时间范围缩小到固定的多个时间段中。利用重叠相加法或重叠保留法可以将连续的线性卷积运算转换成分段的循环卷积运算。这样的转换已被证明对结果的精度和误差不会带来任何损失,转换最大的好处是使滤波运算摆脱了时间序列的束缚,能够对多段数据同时计算卷积,充分利用了GPU的计算资源。本文基于GPU平台设计并实现了重叠保留法的并行卷积算法,实现了高速滤波运算。
在使用GPU处理信号数据的时候通常是将信号数据文件读取到GPU内存中,在一般情况下,数据文件的大小能达到数GB。由于GPU的内存是有限的,这些数据难以一次读入GPU内存,只能分批次读入GPU内存。分批读入会造成截断,为了避免截断造成的数据丢失或者误码,需要针对GPU处理流程设计一定的重叠区域和对齐功能。重叠区域保证了数据的连续性,例如在进行Gardner位同步计算时,计算一个插值结果常常需要用到连续4个时刻的采样值,如果这4个时刻的采样值恰好被分到了不同的批次读入,会造成数据计算错误。因此,需要设置一定的重叠区域,以避免程序设计导致的误码现象。此外,在进行帧同步的时候,如果解调结果不是帧长的整数倍,对这些多出帧长整数倍的部分需要进行相应处理,以避免丢帧。综上所述,针对GPU的解调需要专门设计一种缓冲对齐机制,以保证数据的连续性和解调的正确性。本节将主要介绍上述专门为GPU设计的并行解调算法和相应的处理技术。
4.2.1 并行位同步算法
Gardner位同步单元的计算过程可以由NCO环路、插值滤波器和定时误差检测器组成。为了确保能够在最大值处采样,Gardner位同步算法通过内插的方法计算出采样值,同时用NCO环路生成采样间隔。采用内插方法计算得到采样值后,对应的采样时刻也需要重新计算。这个采样时刻与输入信号采样周期Ts的整数倍相差小数间隔μ。
图3所示的算法是Gardner位同步算法的主要过程。其中,x(t)为输入信号,经过周期为Ts的固定时钟采样后,得到x(mTs),m=1,2,…表示离散序列编号;插值滤波器、环路滤波器、定时误差检测器和数控振荡器组成了一个NCO环路,NCO环路的作用是生成采样间隔。插值滤波器通过插值运算得到k时刻的结果y(kTi),其中Ti为输出信号的采样周期;τ(n)为计算得到的定时误差;e(n)经过环路滤波后的校准误差;mk为NCO得到的采样步长;μk为根据k时刻插值结果计算得到的小数间隔。NCO寄存器的初始值R(0)=1,NCO寄存器深度为1,相邻2个周期的NCO寄存器的值如式(1)所示:

Figure 3 Synchronization algorithm
R(k+1)←[R(k)-wc]mod 1
(1)
其中wc是控制步长。当NCO寄存器的值过零点时,寄存器的值模1,即得到下一个符号周期NCO寄存器的值。当NCO寄存器过零点时,就是对输入信号进行重采样的位置,该位置相对于输入信号的时钟周期的整数倍多出的部分即为重采样的小数间隔μ。
根据几何关系,2次重采样的间隔可以由式(2)得出:
l=R(k)/wc
(2)
该采样间隔也可由式(3)表示:
l=sTs+μ
(3)
其中,s是采样间隔的整数部分,下一次采样则从k+s处开始计算。
采样过程中(k-1)Ts,kTs,(k+1)Ts,(k+2)Ts时刻的信号值将被作为参数进行内插运算,采样时刻相对于采样周期整数倍的小数间隔μ也将作为内插运算的参数。
本文采用了立方插值函数作为拉格朗日插值函数。立方插值滤波器的插值多项式如式(4)~式(7)所示:
(4)
(5)
(6)
(7)
其中,μ是内插点的时间偏移,C-2、C-1、C0、C1是立方插值滤波器的系数。当计算得到C=[C-2(k),C-1(k),C0(k),C1(k)]后,即由式(8)可得内插值:
y(k)=Cx
(8)
其中,x为(k-1)Ts、kTs、(k+1)Ts、(k+2)Ts时刻的信号的采样值。
在GPU计算过程中,更新NCO寄存器值、计算小数间隔都可以由一个线程完成,当进行拉格朗日插值时,则可以由多个线程同时参与计算。
并行计算内插值的过程可以分为2步。第1步是通过插值多项式的系数矩阵与内插点小数偏移μ的幂次向量的乘积。第2步是插值系数向量和信号向量的乘积。即4×4的矩阵与长度为4的μ的幂次向量的乘积,即[1,μ,μ2,μ3],以及2个长度为4的向量的乘积。可以使用4个线程分别计算4个插值系数,并且分别计算系数与信号值的乘积,经过2次归约运算后即可得到内插值。
根据Gardner算法,在得到连续3次的内插采样值后,即可进行一次时钟误差的检测和校正。在计算内插值的时候,可以申请更多的线程参与运算,从而一次得到多个内插采样值。假设同时计算的内插值数量为I,则申请4I个线程同时计算上述乘积运算。
每当计算得到2个内插结果后,都要对时钟相位进行校正,也就是计算更新NCO控制步长wc的值。对于不同的解调方式,校正方法有所区别。对于QPSK来说,时钟相位误差由式(9)确定:
e=sign(yI(k-2))-sign(yI(k))*yI(k-1)+
sign(yQ(k-2))-sign(yQ(k))*yQ(k-1)
(9)
其中,yI和yQ为I、Q路分别计算得到的内插值。除了计算时钟相位误差之外,在得到插值结果后,还要计算相应的载波相位误差。在更新相位误差后,NCO控制步长wc和载波相位θ都发生了变化,新的插值结果需要用新的控制步长和载波相位进行后续的计算。因此,不能一次计算过多的内插值,假设校准间隔为M,当M=1时,每计算得到2个内插结果校正一次相位误差;当M≥2时,就需要考虑未及时检测更新相位误差带来的影响。
在并行计算插值结果时,需要先由主线程计算得到M次插值对应的NCO寄存器值和小数间隔。对于k时刻的一次插值来说,下一次插值对应的时刻由式(10)计算得到:
R(k+s)=R(k)-s×wc
(10)
为了实现并行计算,需要一次计算多次采样的NCO寄存器的值,通过事先迭代计算多次得到寄存器结果R1,R2,…,RM、时钟偏移μ1,μ2,…,μM及对应的采样时刻k1,k2,…,kM。通过4M个线程将对应M个时刻的4M个对应的信号采样值提取出来,利用提前计算好的参数实现并行内插运算。
并行插值运算减少了条件判断,有利于降低GPU运算延迟。当M≥2时,需要考虑边界判断带来的结果误差。如果k1到kM中的某一个时刻ki所需要的4个采样值没有在这一轮读入GPU内存,则会造成结果错误。解决办法是:在插值计算结束后设置同步栅栏来判断所需采样值是否超过信号读取范围,如果超过范围则舍弃相应的插值结果,仅保留所需采样值处于本轮信号值读取范围的插值结果;对于超过范围的结果,记录最后一个超过读取范围的采样时刻偏移和NCO寄存器等各个寄存器状态,在下一轮读取信号值时,通过重叠读取和更新寄存器状态的方式来继续计算重采样内插值。
校准间隔可以根据信号情况进行动态调整,当M较大时,可以提高解调速率,但是误码性能也会相应地受到影响。实际测试过程中发现,当M≥64后会出现误码增多的情况。
4.2.2 并行滤波
滤波运算实质上就是将滤波器的时域信号值与输入信号进行线性卷积。线性卷积的操作十分适合如FPGA这样串行计算效率较高的设备。对于GPU而言,如果按照线性卷积中的时间序列逐步计算卷积,则无法发挥GPU的资源优势。通过对输入信号进行一系列的分段和重叠等预处理操作,可以用多个循环卷积计算结果的拼接来得到和一段线性卷积计算相同的结果。这样十分有利于发挥GPU的线程资源和计算资源优势,达到更快的处理速率。
替代的方法主要有重叠相加法和重叠保留法。这2种方法的步骤十分类似,本文采用了重叠保留法。对于重叠保留法而言,需要先对输入信号进行分段,在分段的时候对每一段的头部重叠填充前一个分段的数值,在计算卷积之后,再将每一段结果的头部删去,最后把各个分段的结果拼接起来,就得到最终结果。
基于GPU的并行卷积运算步骤如下所示:
(1)将滤波器时域信号值存入GPU内存,并进行FFT(Fast Fourier Transform)卷积。
(2)对接收信号值进行分段,接收信号的分段长度为Ls,分段长度由事先设定的FFT长度确定。设FFT长度为N,N≪Ls,滤波器长度为D,则将信号分为长度为L的段,其中L的计算如式(11)所示:
L=N-D+1
(11)
总共分段数BS=Ls/L。至少需要申请BS×N长度的GPU内存,为每一段信号申请长度为N的GPU内存,将长度为L的数值填入L段的后部。
(3)将每一分段的最后一段长度为D-1的数值存入后一个分段。对于第1个分段填充值需要区分是否是第1轮读取的数据,如果是第1轮读取的数据,则填充零;如果是中间轮读取的数据,则需要在上一轮计算时将最后D-1长度数据保存起来,以给下一轮填充使用。
(4)对填充好的BS个分段数据进行批量并行FFT运算。
(5)将FFT运算的结果与之前计算滤波器的FFT结果相乘。
(6)对相乘结果进行并行IFFT(Inverse Fast Fourier Transform)计算。
(7)对每个分段进行内存移动操作,只取每个分段的后L个数据,舍弃前D-1个数据。
(8)对计算结果进行拼接调整并且作最后抽样。
图4展示了通过分段卷积进行滤波运算的流程。在GPU执行上述步骤时,可以最大程度调用计算资源,实现并行FFT、并行IFFT和并行乘法操作,在整个过程中有大量内存移动操作,所以需要注意线程同步问题,在实现的过程中通过合理调整计算和访存顺序,将对同一个内存区域的读写操作步骤分隔开,避免了写后读冲突。

Figure 4 Filtering algorithm
4.2.3 多级缓冲区对齐技术
针对基于GPU数字信号处理的特点,在充分确保处理结果的连续性和正确性的基础上,最大程度实现运算的并行度,需要对数据处理的各个节点,特别是处理边界部分进行专门的优化。设置缓冲区能够减少不必要的访存操作,降低处理时延。与此同时,对于大规模并行处理操作,计算单元支持的最大长度往往是固定的,而输入数据的长度无法事先确定,需要对这些超过计算单元支持的最大长度的部分进行相应的处理。本文通过软件编程设置专门的缓冲区和对齐单元,解决访存时延和并行计算的边界问题。
在整个解调周期中共设置了4级缓冲区,如图5所示,每个缓冲区的功能如下:

Figure 5 Design of CPU-GPU heterogeneous buffer
第1级缓冲区Buf1位于CPU内存,用于保存读入的信号数据;
第2级缓冲区Buf2位于GPU内存,用于保存超过FFT长度整数倍的重采样结果;
第3级缓冲区Buf3位于GPU内存,用于保存超过帧长整数倍的解调结果;
第4级缓冲区Buf4位于CPU内存,用于保存译码结果。
当处理程序将数据文件读入CPU内存后,将信号数据存入Buf1中,分多轮读入GPU内存,减少磁盘到CPU内存的访存时延,同时节省GPU内存。
当重采样结束后,为了保证输入滤波器的数据长度是并行卷积分段长度的整数倍,设置对齐单元,将多出的部分存入Buf2。在下一轮重采样结果进入对齐单元时,将Buf2中保存的数据放在新数据的头部,同时将尾部多余的部分放入Buf2。对齐方式通过截取帧长整数倍来完成。
当解调结束之后帧同步之前,将多出帧长整数倍的部分存入Buf3。在帧同步开始时,首先将Buf3中上一轮解调结果放入新解调结果的头部。在帧同步结束后,将多出帧长整数倍的部分存入Buf3。
当译码结束后,处理结果会由GPU内存存入CPU内存,这时首先将结果存入Buf4,当处理过若干轮次后,再将结果由Buf4存入结果数据文件。
4.3 基于GPU的并行帧同步算法
并行帧同步的任务是找到帧同步头的位置,并将同步后的数据放入连续的内存空间中以备译码或者直接存入文件。一些译码算法属于软判决译码算法,即需要对解调后的结果计算LLR(Log Likelihood Ratio)值,然后进行译码运算,本文中的LDPC译码算法采用的就是软判决译码算法。另一些译码算法属于硬判决译码算法,即在译码之前需要对解调后的信号值进行硬判决,将浮点数值转换成0或者1的二进制数值。本文根据译码算法的需求,分别实现了用于软判决译码的帧同步算法和用于硬判决译码的并行帧同步算法。基于软判决译码的帧同步算法可以根据信号的浮点值计算帧同步结果,保留信号值的原始精度,给译码器提供更精确的输入值。基于硬判决译码的帧同步算法根据信号的二进制数值计算帧同步结果,占用内存更小,速度更快。
基于GPU的帧同步算法采用了argmax算法,设帧同步头长度为H,码字长度为E,组成的帧长度F=H+E,计算每个偏移位置q的分数,如式(12)所示:
(12)
其中,si是帧同步序列,yi是帧同步信号序列。在计算出每个偏移位置的分数后,选出得分最高或者最低的偏移位置,如式(13)所示:
m=arg max{Sq|0≤q≤F-1}
(13)
对于硬判决结果的帧同步,匹配函数如式(14)所示:
f(s,y)=s·sign(y)
(14)
对于软判决结果的帧同步,匹配函数如式(15)所示:
(15)
4.3.1 并行滑块分区搜索帧同步算法
在利用argmax算法寻找帧同步头的过程中,需要有一个移动的长度为S的滑块,这个滑块滑到哪里,就要计算出这个范围内的信号与帧同步头之间的分值,最终根据分值的高低来确定帧同步头的位置。
并行帧同步采用并行滑块的方式搜索帧同步头。假设输入信号长度为Linput,信号的每一个位置都设置一个相应的分值SLinput。通过申请P个线程来计算每个位置的分值,相当于建立了P个滑块,每个线程维护一个滑块游标,当滑块滑动时,从当前位置开始,取长度为S的信号计算与帧同步头的分数。计算完毕当前位置的分值后,滑块的游标长度增加P,即跳转到下一个位置计算相关分值,由此往复直到信号末尾。
当计算得到每个位置的分数后,需要通过比较得到的相关分值确定帧同步头的位置。并行帧同步算法采用了分区计算最终偏移的方法。将所有位置的分数分成Z个区段,每个区段的长度为Lblock,即帧同步头加码字的长度。由于一个帧长范围内最多可能有一个帧同步头,通过寻找最小值的方法找到帧同步头的偏移。在比较相关分数的时候,由Z个线程分别寻找本区段长度为Lblock的相关分数最小值对应的偏移量。计算偏移的过程由Z个线程并行完成,其中Z≥Linput/Lblock。
算法1是并行帧同步算法的伪代码。其中,r表示信号数据向量,asm表示帧同步头向量,Lasm表示帧同步头长度,S表示每次参与计算的数据长度,SLinput表示分数向量,C为经过帧同步的数据序列。
算法1并行帧同步算法
输入:r,asm,Lasm,S,Linput。
输出:C。
1.tx←threadIdx.x;
2.fork=tx→Linput-1paralleldo
3.fori=0→Lasm-1do
4.s=asm[i]⊕r[k+i];
5.s′=(1-asm[i])⊕r[k+i];
6.endfor
7.SLinput[k]=max(s,s′);
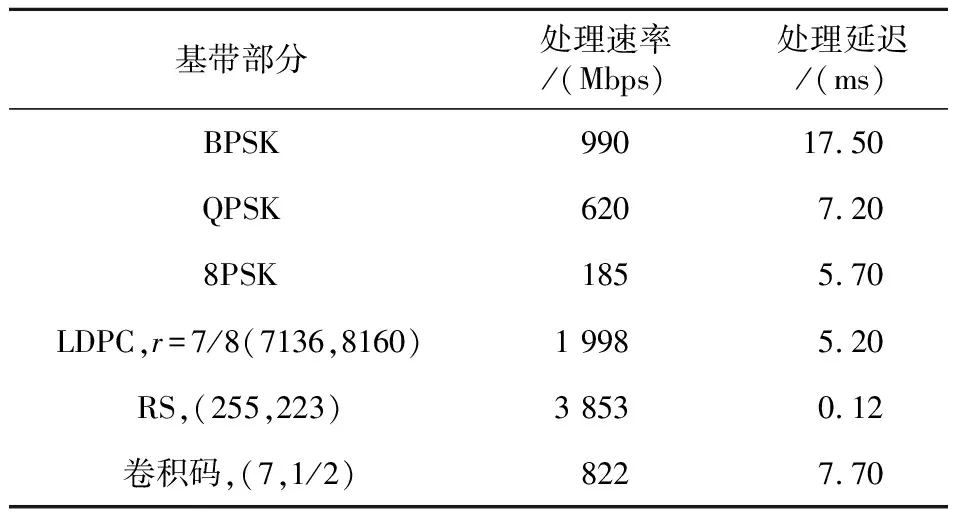
8.PLinput[k]=s 9.endfor 10.count←Linput/S; 11.MAX←-1; 12.iftx 13.fori=0→S-1paralleldo 14.ifSLinput[tx×S+i] 15.MAX←SLinput[tx×S+i]; 16.H[tx]←tx×S+i; 17.endif 18.endfor 19.endif 20.fork=tx→Linput-1paralleldo 21.fid←k/S; 22.bid←kmodS; 23.ifPLinput[k]==0then 24.C[k]=r[H[fid]+bid]; 25.else 26.C[k]=1-r[H[fid]+bid]; 27.endfor 4.3.2 相位模糊识别同步算法 在MPSK进行解调的时候,容易发生相位模糊。如果输入信号存在相位模糊,在帧同步的时候就无法得到正确的相关分值,也就无法实现帧同步。为了解决相位模糊的问题,本文在帧同步的过程中为输入信号增加了一个相位向量,并且在计算相关分值的时候同时计算同相情况下的分值和反相情况下的分值,如果反向分值小于同相分值,则将反向分值保存到分值向量中,同时在相位向量中记录分数向量对应的相位。这样在计算分值的时候就能够确定是否发生了相位模糊的情况。在帧同步的最后一步通过偏移量排列帧数据的时候,根据相位向量所记录的相位情况对帧数据的相位进行修正,最终得到原始相位的帧同步结果。 本文基于CCSDS推荐的编码方案设计了相应的GPU并行译码算法。在处理程序进行初始化的时候,就已经事先根据参数的配置为相应的译码器申请好了相应的内存资源和计算资源,当完成帧同步运算后,进入译码器的数据就是一帧帧已编码的码字,这些码字数据以LLR浮点数值或者二进制字符存入GPU的连续内存中,可以批量送入译码器进行译码运算。在CCSDS推荐的几种码字类型中,LDPC码和RS码属于线性分组码,即所有的码字可以按照码长分块,在译码的时候也是以码块作为基本的译码单元。而卷积码不属于线性分组码,对卷积码译码时没有固定的码长。LDPC码和RS码在译码时需要对译码算法进行并行优化,保证单个码字的计算时延达到最小,再利用GPU多线程的优势增加译码的吞吐率从而实现高速并行译码。对于卷积码来说,在不改变译码算法的情况下,多线程并行带来的速度增益并不明显。即使如此,本文采用重叠-截断译码算法,通过基于序列串行译码的算法并行化,实现了基于GPU的高速并行译码。 4.4.1 LDPC译码 LDPC译码算法的复杂度主要取决于在进行LDPC编码时采用的校验矩阵。CCSDS推荐的LDPC编码算法可以分为2类:AR4JA和C2。校验矩阵都是由基本矩阵组成的,图6和图7中的小方格就是基本矩阵通过不同步数的循环移位得到的结果。AR4JA类型的基本矩阵每一列只有一个非零值,这类LDPC码在利用MSA算法译码的时候可以以基本矩阵的维度为基本并行维度实现并行译码。对于C2类型的校验矩阵,其基本矩阵每一列有2个非零值,而且这2个非零值的距离不固定,因此无法以基本矩阵的维度作为并行维度。通过观察可以发现,C2类型的校验矩阵2个非零值之间的距离有最小值,只要译码的时候并行维度小于这个最小值,就可以保证在译码时更新每个VN(Variable Node)节点的度量值时不发生冲突。例如,对于7/8码率的C2类型的LDPC码,基本矩阵的维度是511×511,2个非零值之间距离的最小值大于64且小于128,因此可以选择64作为译码的并行维度。基于GPU的LDPC算法在以前的工作中已有阐述[5],在此不做赘述。 Figure 6 AR4JA check matrix Figure 7 C2 check matrix 4.4.2 RS译码 CCSDS推荐的RS码标准根据其纠错性能分为(255,223)和(255,239)2种。RS码的运算主要是伽罗华域中的运算,所有的数据都是用8位数表示,所以刚好对应GPU中的一个char类型的字母。RS码的主要译码步骤可以分为以下几步: (1)由接收到的R(x)求得伴随式。 (2)利用BMA算法得错误位置多项式。 (3)利用Chien搜索算法求出错误位置多项式的根,并通过根的倒数确定错误位置。 (4)由错误位置多项式求得错误值,从而得到错误图样。 (5)R(X)-E(X)=C(X),完成纠错过程。 在GPU实现并行RS译码的过程中,对求伴随式、BMA算法和Chien搜索算法进行了并行优化。假设RS码的纠错能力为t,不难发现,对于求解伴随式、BMA算法和Chien搜索算法来说,都依次计算2t个相关的结果,因此译码过程对于每个RS码字申请了2t个线程,这样计算2t次的值只需要在一个周期内就能给出结果。在多码字并行方面,通过调用多组2t线程实现更大程度的并行,每个线程块至少能够支持16个码字的并行译码。 4.4.3 卷积码 卷积码译码就是根据接收序列来预测可能的发送序列。对于卷积解码来说,就是要通过维护每条译码路径的路径度量值,最终选择最有可能正确的路径,最后通过回溯操作获取译码结果。 本文在实现卷积码译码时采用了如图8所示的Viterbi译码算法。Viterbi译码算法在计算分支路径度量值时采用了Butterfly算法,Butterfly算法的优化是本文进行并行加速的重点。 Figure 8 Viterbi decoding algorithm 并行Butterfly算法利用了以下几个特点: (1)译码过程中一共64种状态,状态State(n),其中n=1,2,… 64。当1≤n≤32时,在使用Butterfly算法更新对应的分支度量值BMn的过程中,需要依赖状态State(n+32)的分支度量值BMn+32。同理,State(n+32)的分支度量值BMn+32的更新也依赖State(n)的分支度量值BMn。 (2)对于状态State(n),当1≤n≤32时,BMn的更新与BMp(1≤p≤32,p≠n)没有依赖关系。同样,对于状态State(n),当33≤n≤64时,BMn的更新与BMp(33≤p≤64,p≠n)没有依赖关系。 (3)采用32个线程并行计算Butterfly中的分支度量值,实现算法并行。 (4)通过4倍循环展开的方法,减少循环次数。 由于卷积码基于输入信号的序列进行译码,无法直接进行分段译码。已经有方法证明可以通过重叠-截断的方式进行并行分段译码,只需要在每个分段的头部与前一个分段的最后部分有12 bit的重叠,最后将分段译码的结果进行拼接,即可得到正确的译码序列。 对于每个分段使用32个线程实现并行译码,以32个线程为1个线程组,通过申请多个32线程组,可以实现更多分段的Viterbi译码。分段的数量可以由用户根据GPU支持的最大线程数和内存资源自行设定。 本文在基于图灵架构的NVIDIA®GeForce®RTXTM2080Ti上实现了卫星基带处理算法,该GPU拥有4 352个CUDA核心、68个多处理器和11 GB的GDDR6内存。CPU为Intel®CoreTMi7-8700K。CUDA版本为10.2。实验调制数据为递增码00 01..FF,数据大小采用4字节浮点数,采样速率为40 MHz,符号速率为5 Mbps,帧同步头为4字节1ACFFC1D。 表1展示了不同部分的处理速率和处理延迟。从图1可以看到,LDPC译码速度达到1 998 Mbps,RS译码器达到3 853 Mbps,Viterbi译码器达到822 Mbps。 Table 1 Delay of different parts of baseband 表2展示了不同的解调参数和译码参数下基带的处理速度。 Table 2 Comparison of processing rates under different demodulation and decoding parameters 目前还没有基于GPU的卫星通信基带的相关工作。本文比较了基于GPU的LDPC译码器的实现性能。表3是本文实现的LDPC译码器和其他LDPC译码器的性能比较。由表3可知,本文提出的译码器实现了1.998 Gbps的吞吐率,超过了其他相关工作[5-8]的。为了体现不同GPU平台比较的公平性,本文利用“利用率参数=吞吐率/峰值性能”来衡量加速器的性能。从表3可以看出,本文针对GPU峰值性能的利用率也是最高的。 Table 3 Performance comparison of different GPU-based decoders 本文提出了一种基于GPU的卫星通信基带算法群,实现了重采样、匹配滤波、解相位模糊、帧同步、解扰、LDPC码、RS码和卷积码等并行算法,最终实现的下行链路基带处理速率在170 Mbps~978 Mbps,有效提升了卫星通信信号处理速度。4.4 基于GPU的并行译码算法



5 实验及结果分析
5.1 实验设置

5.2 实验结果

6 结束语
猜你喜欢
现代计算机(2021年36期)2021-03-14环球市场(2017年36期)2017-03-09新闻传播(2016年3期)2016-07-12遥测遥控(2015年2期)2015-04-23数字通信世界(2015年5期)2015-04-04集美大学学报(自然科学版)(2015年4期)2015-02-28石家庄理工职业学院学术研究(2014年4期)2014-04-27电视技术(2014年19期)2014-03-11华东理工大学学报(自然科学版)(2014年3期)2014-02-27计算机工程与科学(2013年2期)2013-06-07
