
基于深度学习的短临降水预报综述*
2023-10-24 02:52马志峰
计算机工程与科学 2023年10期
马志峰,张 浩,刘 劼
(1.哈尔滨工业大学计算机科学与技术学院,黑龙江 哈尔滨150001;2.哈尔滨工业大学(深圳)国际人工智能研究院,广东 深圳 518055)
1 引言
短临降水预报一般指预测局部地区未来0~2 h的降水[1-3],是天气预报领域最重要的任务之一[4,5],其不仅要求预报的准确性和及时性,还要求预测的精细程度,即期望获取到准确、及时和高分辨率的预测结果[6]。短临降水预报的应用无处不在,极大地影响着人类的生产和生活,如航空业需要根据气象服务信息来判断是否允许航班起飞[7,8];农业从业者需要知道未来几小时内的降水信息来确定收割农作物的最佳时机[9];海洋管理机构依赖气象预警服务及时通知出海捕捞的渔船避险等[10]。另外,还期望其在发生概率很小但危害很大的极端天气事件(如暴雨和特大暴雨等)上表现良好,以保护人民的生命和财产安全[11]。由于短临降水预报的重要性,其在气象和计算机研究领域受到越来越多的关注[5,12]。
传统的预报方式主要基于数值天气预报NWP(Numerical Weather Prediction)[13]。数值天气预报是在给定初始条件和边界条件下,通过时间积分求解描述大气运动的物理方程来预测未来时刻的大气状态[14]。其主要以雷达、卫星、地面和高空观测数据以及地形数据作为输入,输出在不同高度场下未来时刻的各种气象要素(如温度、湿度、风速和降水等)的值。根据当地的气候特点,世界上许多先进的气象服务中心已经逐步建立了自己的数值预报模式,如中国的GRAPES(Global/Regional Assimilation and PrEdiction System)[15]和美国的WRF(Weather Research and Forecasting)[16]。然而,NWP通常受初始条件场的影响较大,需要一个积分周期来启动推演过程,这导致其在0~2 h的前置时间内预报不佳[17,18]。此外,NWP的计算成本高昂,导致其不能提供小尺度的预测[19]。因而,基于雷达的预报成为了其替代方案。光流法[20]通过获取雷达回波图的光流场来推断降雨区域的运动。相比于NWP,光流法的计算效率较高,预测图像较为清晰,这使得其成为了在极短时间内预测时使用的主流模型。然而,当应用于短期预测时,光流法预测精度较低(预测图畸变效应明显),无法满足实际应用的需求[21]。
近年来,随着计算机硬件(如GPU、TPU)性能的大幅提升[22],深度学习技术蓬勃发展,在各领域的应用效果优于传统方法[23,24]的。大多数研究工作将短临降水预报视为雷达序列预测任务,而雷达序列预测属于视频预测(或时空序列预测,图像序列预测)的子任务[25],因此,用于视频预测的模型一般都适用于雷达序列预测任务,只是由于降水云团存在膨胀、消散、变形等更为复杂的运动变换,雷达序列预测任务比一般的图像序列预测问题更具挑战性[26,27]。有些模型[28,29]只在雷达回波数据集上进行了实验,有些模型[30,31]在其它的视频数据集上进行了实验,有些模型兼顾了两者[32,33],这些模型都是本文介绍的重点,在模型部分本文将重点介绍这些和短临降水预报和视频预测相关的模型。目前主流的视频预测模型可以分为2类[27]:确定性模型和随机生成模型。确定性模型主要有以UNet[34]为代表的卷积神经网络CNN(Convolutional Neural Network)、以ConvLSTM[35]为代表的循环神经网络RNN(Recurrent Neural Network)以及两者的混合模型。随机生成模型主要有生成对抗网络GAN(Generative Adversarial Network)[36]、变分自编码器VAE(Variational Auto-Encoder)[37]以及两者的混合模型[38]。
由于短临降水预测是一个跨学科的科研问题,涉及到多个学科的交叉和融合[39],如:气象学、地理学、计算机视觉和人工智能等,关于该领域的研究知识分散在各个学科相关的会议和期刊文献上。本文重点整理了近年来在计算机视觉、人工智能、地理以及数据挖掘等领域的国际顶级会议(如 CVPR (IEEE/CVF Computer Vision and Pattern Recognition Conference)、AAAI(AAAI Conference on Artificial Intelligence)、NeurIPS(Conference on Neural Information Processing Systems)、ICML(International Conference on Machine Learning)等)与学术期刊(如 TGRS(IEEE Transactions on Geoscience and Remote Sensing)、Nature、TPAMI(IEEE Transactions on Pattern Analysis and Machine Intelligence)等)上发表的与视频预测和短临降水预测相关的论文并进行了归纳和分析。据我们所知,目前国内只有一篇关于深度学习在短临降水预报中应用的中文综述文献[40]。然而,这综述文献只是简单地介绍了年份久远的RNN模型,且没有介绍相关的数据集、度量和损失函数。总之,其没有完整地介绍短临降水预测任务中各个方面的问题,不能起到综述应有的作用。目前国际上有几篇关于视频预测的英文综述文献[41-43],其中文献[42]最具代表性。该文献主要介绍了视频预测、人体姿势识别和视频语义分割等视频相关的问题,但其并不是专门针对短临预测这个子问题的综述。本文是专门针对短临降水预测任务的综述,详细介绍了短临预测任务中的各种模型、损失、度量和数据集等,还分析和总结了在科学研究过程中遇到的其它的比较隐蔽的科学问题。
本文的组织结构如图1所示。具体来说,本文第1节讲述了短临天气预测的意义、相关的研究背景、与其他综述文献的区别以及本文的价值所在;第2节给出了短临天气预测问题的定义;第3节介绍了相关的模型分类以及一些隐蔽的科学研究问题;第4节归纳了开源的数据集及其下载方式;第5节详细分析了度量和评价指标的优缺点;第6节介绍与模型训练相关的损失函数;第7节展望了短临降水预测未来的研究方向;最后,第8节对全文的工作进行了总结。

Figure 1 Organization of this paper
2 问题定义


Figure 2 An example of precipitation nowcasting
(1)
3 模型方法
虽然关于短临降水预测的模型众多,但目前并没有一个详细且完整的总结。本节将全面、具体地介绍相关的模型,并讨论其优缺点。
目前主流的视频预测模型可以分为2类:确定性模型和随机生成模型。确定性视频生成方法为观察到的帧只生成一种可能的未来。相比之下,随机视频生成方法专注于建模未来的不确定性并生成不同可能的未来帧。另外,本文还对这2类模型中相似的模型进行了总结和重新分类。
3.1 确定性模型
确定性模型主要有以UNet[34]为代表的卷积神经网络CNN、以ConvLSTM[35]为代表的循环神经网络RNN以及两者的混合模型。本文在表1和表2中分别总结了基于CNN和RNN的模型。
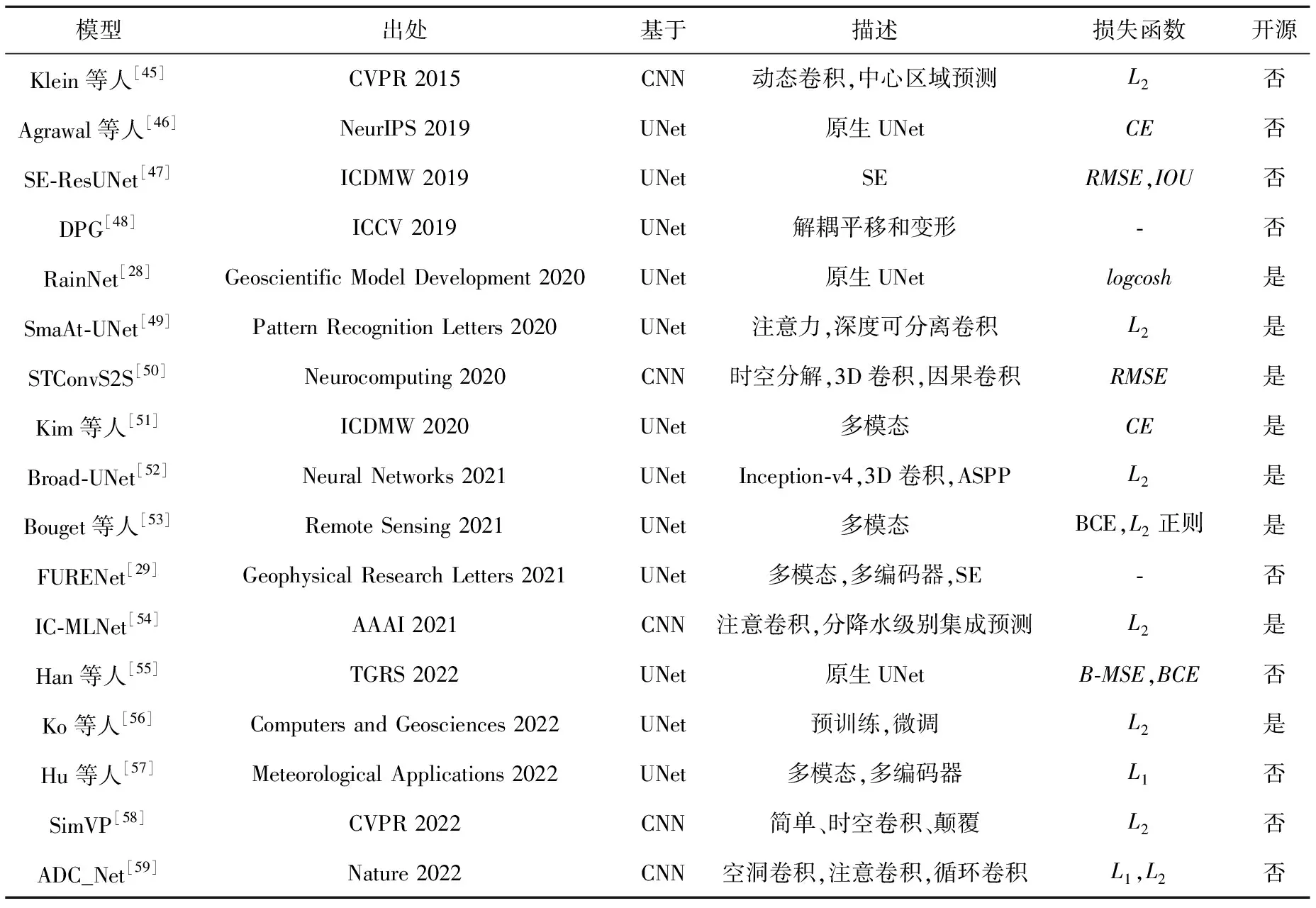
Table 1 Deterministic models based on CNN

Table 2 Deterministic models based on RNN
3.1.1 卷积神经网络
UNet[34]最早应用于医疗图像分割任务,其结构和用于图像分类的卷积神经网络类似,主要由卷积层和池化层构成镜像金字塔结构来保持输出和输入分辨率的一致,并且使用跳跃连接来组合同尺度下编码器的低级细节特征和解码器的高级语义特征。
鉴于UNet结构简单、计算需求小、易于部署、且不会像其它卷积神经网络一样带来分辨率的损失,有许多研究工作将其拓展到短临天气预测领域。RainNet[28]将UNet的分类头替换为预测头,用于德国全境的雷达拼图预测任务。SE-ResUNet[47]将SE(Squeeze and Excitation)[75]模块整合到UNet中,且已被集成到北京市海淀区气象局的气象预报服务中。SmaAt-UNet[49]引入注意力机制[76]到UNet中,并使用深度可分离卷积[77]来减少参数量和运算量。Agrawal等人[46]将降雨分为3个类别(轻微降雨、小雨和中雨),然后使用UNet预测美国大陆的降水。Broad-UNet[52]使用卫星图像而不是常规的雷达图像,其还在UNet的基础上引入了多尺度分解卷积[78,79]和空间金字塔池模块[80]来预测荷兰境内的降水。Han等人[55]将UNet用于中国北方区域的对流降水预报。Ko等人[56]采用预训练和微调的方式训练UNet,并将其用于韩国境内的降水估计。ADC_Net[59]融合空洞卷积、注意力卷积及循环卷积构建了一个类似UNet镜像金字塔结构的雷达回波外推模型。
基于UNet的模型通常用前面时刻的多帧去预测下一帧(如图3a所示),然后递归地预测后面的帧以学习序列中的时间趋势,也有一些研究工作(STConvS2S[50])尝试使用3D卷积来捕捉帧之间的时间依赖。然而,卷积是为了提取图像中的空间特征和捕获局部空间依赖而设计的,其在捕获时间变化方面存在天然的劣势[32]。在如此困难的时空序列预测任务下,只使用卷积无法应对复杂的非线性时空变换[81]。

Figure 3 Model structure of UNet,UNet+RNN,MS-RNN
图3中白色框表示编码器,灰色框表示解码器,黑色框表示瓶颈层。
3.1.2 递归神经网络
与卷积适合提取空间特征相反,基于马尔科夫假设的RNN在处理时序数据上有着优异的表现[42]。直觉上结合CNN和RNN可能适合处理短临天气预测这样一个时空序列任务,然而简单地拼接2个模型并不可行,原因是时空是交织在一起的,不是割裂的。ConvLSTM[35]的提出奠定了RNN模型在短临降水预测领域的统治地位。ConvLSTM将LSTM[82]的输入到状态和状态到状态转换中的全连接(1×1卷积)替换为卷积(3×3卷积或者更大)来同时捕获时空运动趋势。ConvLSTM模型的核心是同LSTM一样的记忆忘记机制[83,84],即记住并忘记过去以应对未来的不确定性。
ConvLSTM存在的问题是会产生模糊的预测图像,并且这种趋势随着预报时间的推移愈发地明显(如图2所示)[33]。从模型结构层面来说原因有2点:ConvLSTM模型过于简单和性能不够强大。从损失函数层面来说,MSE(Mean Square Error)或者MAE(Mean Absolute Error)损失总是带来未来状态的平均,使得ConvLSTM难以应对未来的不确定性[42]。本文将在第3.2节和第6节讨论关于损失函数的改进,本节主要讨论关于RNN模型结构的改进。
在自然语言处理NLP(Natural Language Processing)领域中,Seq2Seq[85]结构在机器翻译和文本预测任务上表现优异。随着ConvLSTM的提出,图像预测和文本预测任务之间的差异不再明显,许多模型将Seq2Seq结构迁移到视频预测领域。原始的Seq2Seq架构如图4所示,其中白色框表示编码器,灰色框表示解码器,EOS(End of Sequence)代表序列结束,此时的输入是零张量。从图4可知,原始的Seq2Seq通过自回归来完成逐步的预测,左边是编码器,用于编码观测到的帧序列;右边是解码器,用于解码编码器最后一个时刻的隐状态。训练期间解码器的输入可以使用真实帧也可以使用预测帧,但通常采用计划采样策略(Scheduled Sampling)[86]来弥补训练和测试阶段解码器输入的不一致。ConvLSTM的不同变体使用了不同的Seq2Seq结构,接下来本文将结合模型设计来详细介绍这些架构的不同。
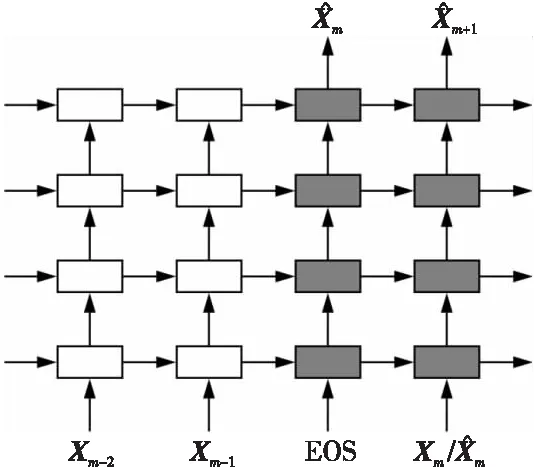
Figure 4 Model structure of Seq2Seq
ConvLSTM采用的模型结构如图5a所示,其中白色框表示编码器,灰色框表示解码器。相较于原始的Seq2Seq结构,其解码器没有输入(输入全为0的张量),只有沿着时间轴传播的记忆(Hidden State and Cell State)。为了进一步提升ConvLSTM的性能来缓解模糊问题,许多研究工作改进了ConvLSTM的基本单元,并使用不同的Seq2Seq结构。

Figure 5 Model structures of ConvLSTM and TrajGRU
TrajGRU[62]认为跨时间轴的卷积连接是随位置不变的(Location-invariant),而自然界的运动或变换(如旋转)一般是随位置变化的(Location-variant),这不利于学习像素之间的时空关联。为了解决此问题,TrajGRU将光流法引入ConvGRU的状态到状态转换中(原来是卷积)。相比于ConvLSTM,其结构略有不同(如图5b所示)。TrajGRU调转了解码器的预测方向,并在此基础上引入多尺度结构,使得编解码器的层处于同一特征级别上。TrajGRU的编码器和解码器的每一层的尺度是一致的,越是底层尺度越小。为了方便与ConvLSTM进行对比,本文没有在图5b中体现这点。
像其它深度神经网络一样,ConvLSTM也是通过叠加更多的层来获取更高的性能。然而,这种结构中只有输出(隐含状态)自下而上传递,层与层之间的记忆单元在时域上是相互独立的。在这种情况下,底层将完全忽略顶层在之前的时间步骤中记住的内容。为了克服这一缺点,Wang等人[33]提出了PredRNN,它允许不同层之间的记忆跨层交互。国家气象中心已将其作为短临降水预报的基础模型。相比于ConvLSTM,PredRNN增加了网络的宽度,增加了约1倍的参数量,带来了更好的性能。PredRNN的模型结构如图6a所示,其中沿着之字形路径传播的信息流是用于层间记忆交互的时空记忆(Spatiotemporal Memory)。原始的Seq2Seq的编码器并不会输出预测值,因为输入帧的下一时刻的预测值并不是想要预测的。然而,PredRNN的编码器输出了这些帧,并且在损失函数中做出了相应的惩罚,这导致网络的前几层成为编码器,而后几层成为解码器。在时空序列预测这样一个自监督任务背景下,这种做法惩罚了更多的帧,有益于模型学习更多的运动趋势(几乎整个序列的运动)。
PredRNN++[31]重新整理了PredRNN中的张量流来增强模型的短期趋势建模能力,并在第1层和第2层之间加入了梯度高速公路GHU(Gradient Highway Unit)来增强模型的长期趋势建模能力。本质上,GHU是一个GRU层。相比于PredRNN,PredRNN++通过增加网络深度来捕获更多的时空上下文信息。
受传统时间序列经典模型ARIMA(Auto-Regressive Integrated Moving Average )[87]的启发,MIM[27]通过多次差分将非平稳过程转换为平稳过程[88],其在PredRNN的基础上引入了2个记忆模块(Non-stationary Memory and Stationary Memory)来建模时空动力学中的非平稳和近似平稳特性。另外,其还引入了沿着对角路径传播的张量流,用于差分同一层相邻2帧之间的隐状态(如图6b所示)。此外,还可以替换PredRNN为PredRNN++构建MIM*模型。然而相对于PredRNN,MIM增加了网络的宽度,增加了大约2倍的参数量,这可能是模型性能提升的根本原因。
E3D-LSTM[65]将PredRNN中的2D卷积替换为3D卷积来使记忆单元更好地存储短期特征,并引入门控自我注意模块来回忆长期历史上下文信息。不同于PredRNN使用单帧预测单帧的方式来进行一步预测,E3D-LSTM采用类似UNet的方式使用多帧预测一帧来进行一步预测。相比于PredRNN,E3D-LSTM使用了3D卷积,这将引入巨大的参数量和显存占用量。
PredRNN和MIM的模型结构如图6所示,其中白色框表示编码器,灰色框表示解码器。
和PredRNN引入沿着层和时间轴传递的时空记忆不同,SA-ConvLSTM[67]在ConvLSTM的基础上引入了沿着时间轴传递的自我注意记忆SAM(Self-Attention Memory)。SA-ConvLSTM中的隐状态(Hidden State)和SAM一样都采用了自我注意机制来捕获全局空间依赖和长程时间依赖,并且2个注意力模块共享了查询部分(Query)。SA-ConvLSTM使用了深度可分离卷积来降低由自我注意力带来的额外的参数量和巨大的显存占用量。尽管SA-ConvLSTM的参数量少于PredRNN的,性能优于MIM*的,但在实际应用中,一般的显卡无法承受其巨大的显存占用量,导致其只能用于图像尺寸较小的数据集。
MotionRNN[26]认为物理世界的运动可以分解为瞬时变化和运动趋势,而后者可以看作是以前运动的积累。MotionRNN在MIM(也可使用前面介绍的其他模型)的层之间加入 MotionGRU来同时捕捉瞬态变化(Transient Memory)和运动趋势(Trend Memory),MotionGRU的核心思想是动量衰减策略(常用于梯度下降算法)[89],用于学习瞬时变化并累积运动趋势。相对于MIM,MotionRNN本质上是增加了网络的深度。尽管其使用编解码压缩了参数量,但这也导致其性能和MIM的相当。另外,由于引入光流法的缘故,MotionRNN的训练和TrajGRU一样较为缓慢。
卷积递归混合模型如图3b所示,这类模型只在瓶颈层使用LSTM或者ConvLSTM,它们既具有UNet简单轻便的多尺度空间结构,又兼备LSTM的时间建模能力。它们通常作为GAN的生成器或者VAE的主干结构。使用此类结构的模型有:FSTN[90]、BP-Net[91]、BCnet[92]、HAF-SVG[93]、Chen等人提出的模型[94]和TsGAN[95]等。
3.2 随机生成模型
生成模型主要用于应对未来的不确定性,它们生成多种可行的预测,而不是单一的结果。随机生成模型主要有生成对抗网络GAN[36]和变分自编码器VAE[37]以及两者的混合模型,表3给出了随机生成模型的总结。

Table 3 Random generation models
3.2.1 生成对抗神经网络
由于像素空间的高维性,从原始像素值中提取一个鲁棒的表示是一项非常复杂的任务[42]。连续帧之间的逐像素变化导致在长期水平上的预测误差呈指数增长,MSE这类像素级预测损失通过模糊预测来适应视频固有的不确定性。另外,天然的视频是服从多峰分布的,而MSE损失函数假定数据服从高斯分布[21]。最小化MSE将倾向于获取多个结果的平均,使得预测结果丢失了大部分的高频细节,这与人类的直观视觉感受相违背。
为了克服这些局限性,许多研究工作将生成对抗训练引入到视频预测任务中。GAN是受博弈论[107]的启发而提出的,通过学习数据的概率分布使其很容易地从学习到的分布中生成新的未出现过的样本。GAN是由2个相互竞争的学习系统组成的,分别称为生成器和判别器。它们被联合训练成一个极大极小博弈游戏,以生成与真实数据相似的假样本。生成器产生新的样本试图欺骗判别器,而判别器则试图区分出由生成器生成的样本。
在原始的GAN中,生成器从随机噪声中采样新数据,而在短临降水预测任务中,GAN的生成器一般从前面介绍的CNN或者RNN模型的预测中采样。GA-ConvGRU[21](如图7所示)是最为简单的生成模型,其使用前面介绍的RNN模型作为生成器,并使用一个二分类判别器来辨别真实雷达图和预测图来对抗重建损失(MSE)导致的模糊。Mathieu等人[96]提出了3种不同但互补的学习策略(多尺度结构、对抗训练和图像梯度差分损失函数GDL(Gradient Difference Loss))来对抗模糊。与Mathieu等人提出的学习策略类似,MCNet[97]引入了多尺度、对抗训练和GDL损失,但其分解了运动和内容。Ravuri等人[1]认为产生模糊的降水预测的原因是缺乏约束,其使用2个判别器分别用于甄别生成的帧在时间和空间维度上是否相似。BCnet[92]分为正向预测模块和反向预测模块(作为额外的约束)。正向预测模块使用当前序列预测未来序列,反向预测模块使用正向模块的输出再去预测当前序列。当正向预测模糊时,反向预测会放大误差,导致出现更模糊的序列。这使得正向预测模块朝着减少运动混淆的方向进行优化,缩小了解空间的大小。FSTN[90]使用CNN与ConvLSTM的组合作为生成器,能同时进行视频外推和视频插值。Znet[99]使用类似计划采样的思想训练GAN,这在一定程度上缓解了预测的模糊性。其使用了2个生成器,一个完全使用预测帧作为输入,一个完全使用真实帧作为输入。TsGAN[95]使用2个阶段来训练GAN,其中第1个阶段用于生成预测图像,并引入2个判别器分别用于判别单幅雷达图像和整个序列的真假;第2个阶段再次引入GAN来丰富对抗过程,进一步改善了模糊性的问题。Kim等人[22]提出了一种基于条件生成对抗网络的雷达降雨预报方法,适用于10 min~4 h的短期天气预报。Luo等人[24]将UNet多帧预测一帧再循环预测的思想融入到RNN中,作为GAN的生成器,之后用RNN逐步迭代预测的思想构建了多尺度GAN,证实了GAN的正则化损失项能减缓雷达回波图预测的模糊。

Figure 7 Model structure of GA-ConvGRU
尽管关于GAN的模型很多,然而对抗训练是不稳定的。如果没有明确的潜在变量解释,GAN很容易崩溃[108,109],这时生成器将无法覆盖可能的预测空间,陷入单一模式。此外,GAN经常难以平衡对抗损失和重建损失,从而得到模糊的预测[110]。
3.2.2 变分自编码器
除了对抗性训练之外,一些研究工作还通过编码和重构输入的方式来建模未来的不确定性。这些模型基于变分自编码器VAE[37],致力于从潜在表示构成的先验知识中估计出潜在的分布,以生成新的样本。
Babaeizadeh等人[102]首次将潜在变量纳入确定性的CNDA[60]架构中,提出了SV2P模型。SV2P使用整个输入视频序列来近似后验分布。Denton等人[103]将确定性模型与随机潜变量相结合,提出了SVG网络。与SV2P采用固定的高斯分布作为先验不同,SVG(如图8所示)采用可学习的高斯分布作为先验。SVG是从一个随时间变化的后验分布中采样的。随机模型通常使用自回归的方式根据模型生成的帧去预测下一帧。与自回归模型的交错过程相反,状态空间模型将帧生成与动力学模型分开了。Franceschi等人[105]提出了一种用于视频生成的状态空间模型SRVP,其使用确定的状态转换表示帧之间的残余变化。通过这种方式,时空动力学是用独立于先前生成的帧的潜在状态变量来建模的。尽管独立的潜在状态在计算上很有吸引力,但它们无法对视频的运动历史进行建模。SLAMP[106]假设内容和运动历史都被编码在随机潜在变量中,并以一种确定性的方式将它们分别解码为内容和运动的预测。HAF-SVG[93]放松了SVG中近似后验变量的所有维度都是相互独立的假设,将近似后验变量分解为多组,并假设组内独立、组外相关。

Figure 8 Model structure of SVG
3.2.3 生成对抗和变分混合模型
尽管基于变分推理的模型能够产生各种貌似合理的结果,但与最先进的基于GAN的模型相比,VAE的预测不够真实,质量较低[42]。为了充分利用两者的优势,一些研究人员将对抗训练与变分推理进行了结合。Lee等人[104]提出了SAVP模型,首次将潜在变量模型与GAN相结合,以增加视频预测中的可变性,同时保持真实性。BP-Net[91]提出了一个具有挑战性的新问题,涉及2个层面的不确定性:噪声输入的感知不确定性和时空建模中的动态不确定性。BP-Net使用序列重要性采样SIS(Sequential Importance Sampling)[111]解决输入的随机性问题,使用VAE和GAN解决输出的随机性问题。
3.3 其它模型分类
3.3.1 多尺度模型
在前面介绍的RNN模型中,PredRNN[33]、PredRNN++[31]、MIM[27]、SA-ConvLSTM[67]和MotionRNN[26]等通过将模型变得更宽和更深来提升模型性能和缓解模糊性,然而这种做法带来了参数量和显存占用量的增加[112]。在计算资源受限的情况下,这些模型只能用于低分辨率的任务。实际上在计算机视觉CV(Computer Vision)领域,除了深度(Depth)[113]和宽度(Width)[114]外,还有2个维度可以提高性能,即基数(Cardinality)[115]和尺度(Scale)[116]。基数通过对卷积进行分组来减少参数的数量,然后通过增加组的数量来提高性能,同时确保与原始卷积相同的参数量。不幸的是,基数也会加重显存占用量。在视觉任务中,获取多尺度表示要求特征提取器使用大范围的感受野来描述不同尺度的对象,这可以通过叠加卷积层、使用更大的卷积核或使用池化(下采样)来实现。其中,池化是最有效的方式。具体来说,前两者分别增加了网络的深度和宽度,而后者只是增加了一些没有参数的层,并允许模型在低分辨率(低开销)下运行。
在视频预测领域,UNet模型本身就是多尺度的镜像金字塔结构,在GAN和VAE中通常使用UNet和ConvLSTM联合的多尺度结构,此外,CNDA[60]、SV2P[102]、SNA[61]和MS-RNN[112]将这种金字塔结构迁移到RNN模型中(如图3c所示)。其中CNDA、SV2P和SNA只能使用多尺度的ConvLSTM结构;而MS-RNN是通用的架构,能兼容很多RNN模型,通过替换基础RNN模型可以得到多个多尺度模型,如MS-ConvLSTM、MS-TrajGRU、MS-PredRNN、MS-PredRNN++、MS-MIM和MS-MotionRNN等。相比于基础RNN模型,MS-RNN性能更强,显存占用量更少。UNet、UNet和ConvLSTM的组合,以MS-RNN这3种多尺度结构的对比如图3所示。
短临降水预测通常需要高分辨率和小尺度的预测图像,这样就能精确地确定降水的具体位置。目前来说,用于训练模型的显卡的显存是固定的,显存占用量更小的模型允许显存承受更高分辨率的图像输入,这对短临降水预测模型的落地应用具有重要意义。除了使用多尺度结构外,另一个降低显存占用量的方法是使用块(Patch),即将图像进行切块。该做法将切分的块在通道维度拼接起来作为模型的输入,再将模型的输出还原到原始图像分辨率。ConvLSTM[35]最早使用了这种做法,主要是受限于当时落后的训练设备。TrajGRU[62]设计了新的多尺度结构来进一步降低显存占用量。PredRNN[33]、MIM[27]和MotionRNN[26]等模型都延续了ConvLSTM的做法。然而,使用Patch将带来模型性能的显著下降,并且可能会引发预测图像的栅格效应[42]。关于显存占用量和模型性能的平衡,有待未来进一步探究。
3.3.2 时空上下文模型
在时空序列预测任务中,时间和空间2个维度你中有我,我中有你,交织在一起。一些模型像多尺度模型一样关心空间上下文信息,另一些模型考虑如何获取到更丰富的时间上下文信息。
CLCRN[95]基于地理位置特征的平滑性假设,提出使用局部条件卷积来捕捉和模拟在整个地球球面上的局部气象流模式。ContextVP[64]不依赖于深度网络、多尺度架构、解耦、光流和对抗训练来缓解模糊性,而是使用完全上下文的结构来捕捉每个像素所有相关的时空上下文信息,并使用混合单元聚合这些信息。和SA-ConvLSTM[77]采用自我注意记忆模块来记忆全局长期时间上下文信息不同,E3D-LSTM[65]和MAU[71]选择软注意力机制来记忆历史帧的时间上下文信息。HPRNN[4]在编码器和解码器之间引入了一个长期记忆模块来帮助长期天气预测。LMC[72]将长期运动上下文存储起来,并通过序列匹配机制回忆出已学习到的长期上下文信息。
3.3.3 解耦模型
视频中的复杂运动是由多个因素相互作用并纠缠在一起形成的。解耦或者叫做解纠缠的方法将高维视频分解为低维数据,使得模型更容易学习潜在的时空动力学。这类模型有很多,如:PhyDNet[68]解耦了已知和未知物理知识,MIM[27]解耦了平稳和非平稳过程,MotionRNN[26]解耦了短期和长期趋势,Znet[99]和PredRNN V2[32]解耦了时间和时空记忆,MCNet[97]和MoCoGAN[98]解耦了运动和内容,DPG[48]解耦了平移和变形,Jin等人[100]通过小波变换解耦了时间和空间,STRPM[101]解耦了时间和空间,FDNet[7]解耦了光流场运动与形态变形等等。然而,尽管从原理上的解释是合理的,但有些模型引入了额外的编解码器或者生成判别器,带来了参数量的增加,这可能是性能提升的根本原因,但在损失函数中加入新的正则约束项,将会缩小解空间的大小,这种做法应该能起一定的作用。
3.3.4 多模态模型
不同于视频预测任务只有单一的视频帧输入,短临天气预测可以有多种模态的数据输入。气象数据可通过卫星、雷达、地面观测站、高空探测站获取,有时也可采用数值天气预报模式NWP的预测值作为输入源。此外,卫星具有不同的遥感通道,这些通道数据代表的含义不同;雷达使用不同的仰角将得到不同高度的反射率回波图;地面和高空观测将获取到风速、风向、压力、湿度及降水等多种气象要素数据。总之,气象数据源众多,推动了多模态降水预测模型的发展。
Tran等人[8,17]使用从不同高度采集的雷达反射率数据来学习垂直维度上的气象时空动力学。Wu等人[117]融合了卫星、地面观测站和地形数据来预测中国大陆的日降水量。Ivashkin等人[118]提出了一种融合雷达和卫星数据的算法。Bouget等人[53]使用雷达数据和NWP预测出的风要素预报降水。Franch等人[119]将地形数据作为输入。FURENet[29]引入了2个额外的极化雷达变量数据。MetNet[69]融合了卫星、雷达和地形数据,其性能优于数值天气预测。MetNet-2尝试使用所有可用的数据源(地面观测、高空观测、雷达和卫星等),能够提供长达12 h前置时间的大规模降水预报,该模型比目前在美国大陆运行的最先进的基于物理的模型HRRR和HREF的性能更高。此外,MetNet-2还尝试结合物理模型来进行更准确的降水预测。前面的这些工作都是以UNet或者ConvLSTM为基础的模型,而FourCastNet[120]与这些模型不同,采用了最新的神经网络架构ViT[121]进行多模态降水预测。FourCastNet认为降水数据较为稀疏,呈现出长尾分布特征,不容易被学习,因此其使用其它相对连续且容易被预测的气象要素(如风速、压力、温度等)去预测降水。FourCastNet采用先预测1帧再预测2帧的逐步预训练的方式来同时进行其它气象要素的预测,然后再使用同一个模型去预测降水。然而,FourCastNet的训练过程极其复杂,并且需要时间跨度较长的数据集来学习潜在的全球气候变化。虽然FourCastNet可能不适用于短期降水预测,但FourCastNet的出现至少证明了ViT也可作为基础模型用于时空序列预测任务。
总之,这些多模态工作在数据融合方面做出了一定的尝试。然而这些多模态数据通常具有一定的观测误差,它们的时间或空间分辨率也不同,需要插值对齐,这都带来了额外的误差。这些误差的存在可能会影响到多模态模型的性能。
3.3.5 迁移学习模型
迁移学习涉及到的面较广,具有不同的实现形式,如预训练+微调[122]、知识蒸馏[123]、元学习[124]和小样本学习[125]等。这些实现形式都是将已习得的强大技能迁移到相关的问题,以帮助目标数据的学习。
使用预训练+微调的方式在CV和NLP领域很常见。这些模型先在相关的大规模数据集进行预训练,然后在目标数据集上微调网络权重。使用这种知识迁移方式能获得更高的模型性能,并且有时可以节省在目标任务上的训练时间。假设已经有了一个在雨量充沛、运动丰富的雷达数据集上训练好的模型,那么可以通过微调的方式快速地将模型部署到新建的只具有较少历史雷达数据的雷达站点上。然而,不同的地区可能有其独特的气候特征,并不是所有预训练模型的知识都可以直接应用到目标任务中。知识蒸馏探索从预训练模型中提取那些可转移的表示。例如,当需要训练一个干旱地区的降水预报模型时,有可能会利用从其他雨量充沛的地区学习到的天气变化规律,但不同的气候条件会导致不同的降水规律,这时就需要蒸馏出有用的知识并在目标域上进行调整。
Han等人[126]首先在北京地区收集的大量雷达数据上进行预训练,然后分别建立了基于微调和基于最大均值差异最小化方法MMD(Maximum Mean Discrepancy)[127]的迁移学习模型来将学习到的知识迁移到与北京降水特征不同的广州地区。Yao等人[38]设计了一个可转移存储器TMU(Transferable Memory Unit),使得目标模型能够自适应地从大量源模型中学习。TMU与微调不同,其证明了从单个或多个源雷达站点训练的RNN模型中蒸馏出知识的迁移学习方式要优于微调,甚至可以从多个其它的视频运动数据集(如数字运动数据集Moving MNIST[128]和人体运动数据集KTH[129]、Human3.6M[130]等)蒸馏获取有用的知识来帮助提升模型在降水预测任务上的性能。
将源域的时空动力学作为先验知识能帮助学习和理解目标域的分布。然而,当目标域数据足够充沛时,这种知识迁移方式的作用可能就会下降[38]。
3.4 小节
本节介绍了多种短临降水预测模型,它们的优缺点如表4所示。

Table 4 Advantages and disadvantages of different precipitation nowcasting models
4 数据集
本节主要介绍不同国家和地区的多个开源雷达数据集,并讨论了它们的优缺点。表5总结了这些数据集。
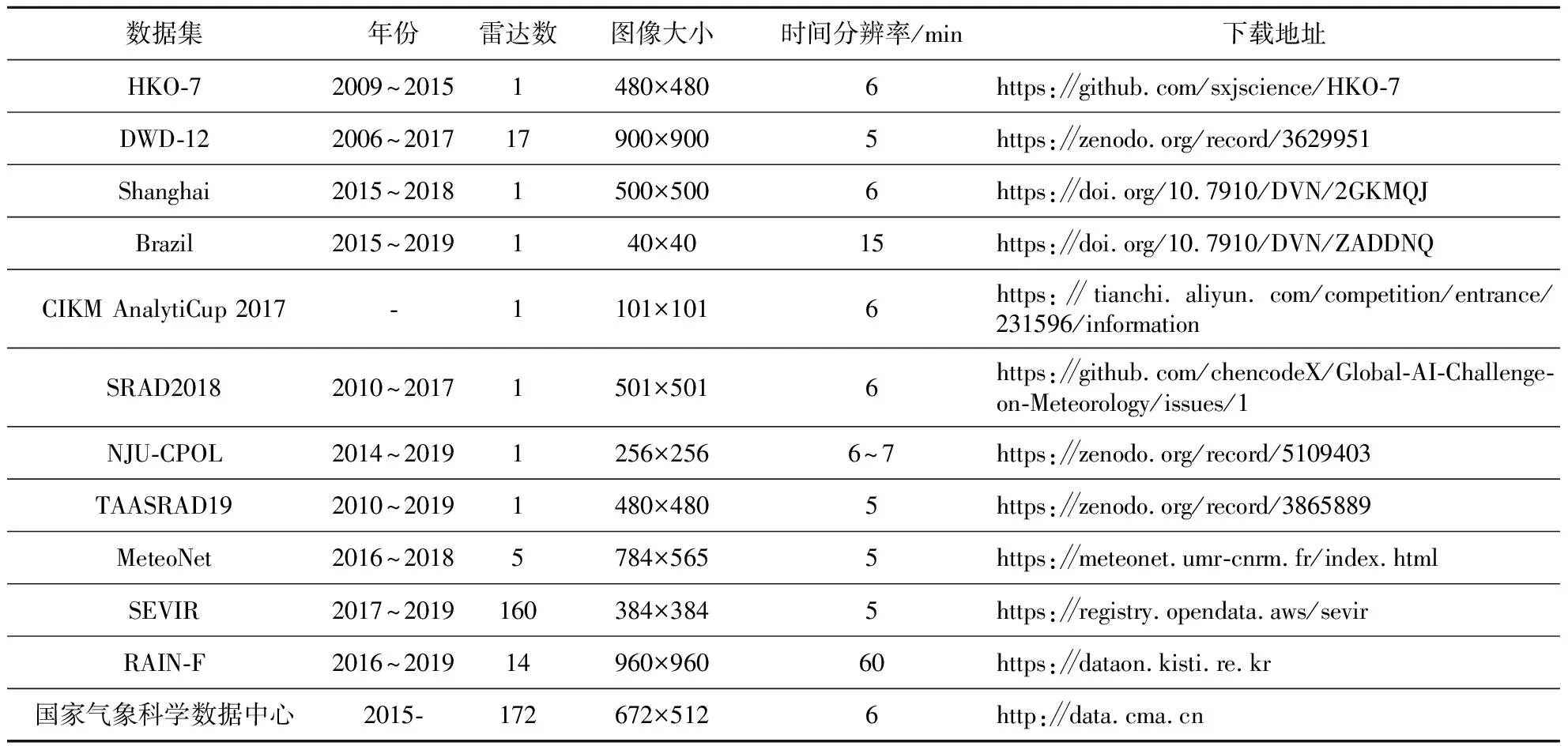
Table 5 Existing open radar datasets
4.1 先验知识
在气象研究中,通常涉及到4个概念以及它们之间的相互转换关系。反射率因子Z与空间单位体积的雨滴大小和数量有关,其单位为mm6/m3。雷达回波强度dBZ代表相对于Z的分贝,通常其值在0~70。RGB或者灰度雷达图像的像素用P表示,其值在0~255。降雨量用R表示,其单位为mm/h。
Z、dBZ和P的计算方式如式(2)~式(4)所示:
Z=(a×Rb)
(2)
dBZ=10lg(Z)
(3)

(4)
其中,a和b由当地的气候类型确定[131]。总之,通过这些公式就可以完成四者之间的相互转换。
4.2 HKO-7
HKO-7数据集是与TrajGRU模型一起发表的,数据来源于香港天文台,涵盖2009至2015年共7年的数据。雷达图像由单部雷达从2 km高度采集,雷达覆盖512×512 km2的区域,采集图像的时间和空间分辨率分别为6 min和480×480像素。TrajGRU使用该数据集时对数据进行了去噪处理,而且只取用下雨天的数据(共有993 d)。笔者认为去噪过程繁琐,且去除异常值后图像会出现空洞(像素为0),也是一个异常值。另外,使用没有降雨或者降雨小的数据进行训练时,梯度不会更新或者更新慢,并不会影响到整体模型的训练。因此,如果想要尽快使用该数据集进行训练,建议直接使用原始数据集。香港地区的Z-R关系[131]为Z=58.53×R1.056。
4.3 DWD-12
DWD-12数据集[28]是由德国气象局采集制作的,包含2006至2017年共12年的数据。图像由17部雷达拼接而成,图像大小为900×900像素,覆盖了900×900 km2的区域,数据集的时间分辨率 (时间间隔)为5 min。该数据集分辨率高、年份多、云层运动丰富(德国属温带海洋性气候,常年多雨),实属可贵。德国地区的Z-R关系(通过查阅德国气象台官方网站获取到)为Z=256×R1.42。
4.4 Shanghai
Shanghai[136]雷达回波数据集使用来自上海浦东的双极化多普勒气象雷达(WSR-88D)的组合反射率数据。该数据集包含2015年10月至2018年7月每6 min采集一次的气象数据,共有170 000幅回波图。回波图已进行去噪、去缺失预处理。
4.5 Brazil
Brazil数据集[137]采集自巴西圣保罗州,由单部雷达采集完成,涵盖2015~2019年共5年的数据。数据集中雷达图大小为40×40像素,覆盖240 km2的区域,其时间分辨率为15 min。该数据集并不是一个标准的雷达数据集,原因是尺寸太小,时间跨度太长,这不利于模型捕捉复杂的运动趋势,增加了预测的难度,但其可作为一个快速实验数据集来验证模型性能。该地区的Z-R关系为Z=300×R1.4。
4.6 CIKM AnalytiCup 2017
在2017年,深圳市气象局和阿里巴巴合办了CIKM AnalytiCup 2017气象竞赛,并发布了一个雷达数据集。竞赛发布的雷达图的尺寸为101×101像素,覆盖101×101 km2范围,雷达图的时间分辨率为6 min。由于该竞赛传播范围较广、影响较大,Github上已有大量的模型和数据预处理代码可供借鉴。
4.7 SRAD2018
SRAD2018数据集同样以竞赛的方式发布,该数据集由深圳市气象局和香港天文台携手制作,使用的是从2010年至2017年的每年3月15日至7月15日的数据,其中每幅雷达图的大小为501×501像素,占地500×500 km2,数据集的时间分辨率为6 min。
4.8 NJU-CPOL
NJU-CPOL数据集[29]由南京大学制作,收集了2014~2019年的数据,涵盖了268个降水事件。数据采集自3 km高度,覆盖256×256 km2的区域。数据集的空间分辨率为1 km,时间分辨率为6~7 min。
4.9 TAASRAD19
TAASRAD19数据集[138]采集自意大利阿尔卑斯山附近的地区,涵盖2010~2019年共19年的数据。数据由单部雷达每5 min采集一次,图像大小为480×480像素,覆盖240 km2的区域。由于该数据集数据规模过大,如果全部使用会导致模型训练时间过长,建议使用部分年份数据进行训练。
4.10 MeteoNet
MeteoNet[132]是一个多模态数据集,包含地面观测站、卫星、雷达、地形和数值天气预报数据。MeteoNet由法国气象局制作,完整的数据涵盖法国西北部和东南部2个地理区域。本文主要介绍其在Kaggle竞赛上提供的雷达数据(西北部)。数据集的时间间隔为5 min,包含从2016~2018年的数据。雷达图由5部雷达拼接而成,原始图像大小为784×565像素,涵盖550 km2的区域。总的来说,该数据集数据规模适中,且数据采集地法国也属温带海洋性气候,降雨丰富,是一个理想的雷达数据集。法国地区的Z-R关系为Z=200×R1.6。
4.11 SEVIR
SEVIR[133]是一个时空对齐的多模态数据集,包含超过10 000个天气事件,每个事件由覆盖384×384 km2的图像序列组成,跨越4 h的时间。SEVIR由麻省理工学院收集制作,其中的降水风暴事件发生在美国大陆,每5 min收集一次。具体来说,其包含5种模态的数据:GOES-16卫星的3个通道数据、NEXRAD雷达降水事件以及GOES-16卫星收集的闪电事件。SEVIR将多种天气传感模态数据组合并对齐到一个单一的数据集中,供气象学家、数据科学家和其他研究人员免费使用。这将有利于天气传感、短期预测和其他相关应用研究。
4.12 RAIN-F
RAIN-F[134]也是一个时空对齐的多模态数据集,由26 280幅图像组成,包含9个与降水变量相关的不同大气状态变量(如温度、湿度、风向和风速等),覆盖韩国大陆大部分区域。RAIN-F的时间分辨率为1 h,数据来源包括雷达、卫星和地面观测站。之后的数据集RAIN-F+[141]在RAIN-F的基础上增加了地球静止卫星Himawari-8的数据,并去掉了缺失值较多的压力要素数据。韩国地区的Z-R关系为Z=200×R1.6。该数据集时间间隔较长,预测难度较大。
4.13 国家气象科学数据中心
国家气象科学数据中心官方网站公开了自2015年9月29日以来全国172个雷达站点每6 min 的基本反射率和组合反射率图像数据。
5 度量和评价指标
对模型预测出的雷达回波图进行质量评估是必要的,需要评估图像是否清晰,对小雨或者大雨的预测是否准确等。但是,单个度量指标不可能覆盖到方方面面,一般使用多个指标来衡量模型的预测能力。
5.1 降雨指标
如果模型的训练使用的是像素P或者雷达回波强度dBZ,那么首先需要使用式(2)~式(4)将真实或者预测图像中的像素值P或雷达回波强度dBZ转换为降雨值R。给定降雨阈值τ,如果R≥τ,那么赋值为1;反之,赋值为0。然后计算出TP(prediction=1,truth=1)、FN(prediction=0,truth=1),FP(prediction=1,truth=0)和TN(prediction=0,truth=0)。最后,就可以计算4个常见的临近降水预报统计量:命中率POD(Probability of Detection)[35]、空报率FAR(False Alarm Rate)[139]、临界成功指数CSI(Critical Success Index)[140]和Heidke技巧评分HSS(Heidke Skill Score)。
命中率POD表示预测的真正有降水区域占实际降水区域的比重。POD值在0~1,其中POD=1时表示预测效果最好,POD=0时最差。POD的计算如式(5)所示:
(5)
空报率FAR表示在预测有降水但实际没有降水的区域占预报有降水区域的比重。FAR值在0~1,其中FAR=1时表示预测效果最差,FAR=0时最好。FAR的计算如式(6)所示:
(6)
临界成功指数CSI表示正确预测降水区域占实际或预测有降水的区域总数的比例。CSI值在0~1,其中CSI=1时表示预测效果最好,CSI=0时最差。CSI计算如式(7)所示:
(7)
Heidke技巧评分HSS表示去除随机事件的影响后的预报准确率。HSS的值为-∞~1,完美的预测应该是HSS=1。HSS的计算如式(8)所示:
HSS=
(8)
5.2 常见指标
由于计算简单快捷,在气象预测中经常使用概率统计误差指标MAE、MSE和RMSE(Root Mean Squared Error)来衡量降水预测的准确性,其计算分别如式(9)~式(11)所示;
(9)
(10)
(11)
其中,X和Y分别表示预测和真实雷达图像,m×n为图像的大小。这些指标都是越小越好,为0时表明预测图像和真实图像最相似。
5.3 计算机视觉指标
常用的计算机视觉指标有PSNR(Peak Signal to Noise Ratio)和SSIM(Structure Similarity)[141]。峰值信噪比PSNR是峰值信号的能量与噪声的平均能量之比,表示的时候通常取10倍的lg变成分贝(dB)。由于MSE为真实图像与含噪图像之差的能量均值,而两者的差即为噪声,因此PSNR也可以叫做峰值信号能量与MSE之比。其计算如式(12)所示:
(12)
其中,MAX2表示最大像素值的平方。PSNR最小为 0,最大为正无穷。PSNR越大表明2幅图像之间的差异越小。但是,这种基于MSE的评价指标并不能很好地按人眼的视觉感受来衡量2幅图像的相似度,经常出现评价结果与人的主观感受不一致的情况。
与MSE和PSNR衡量绝对误差不同,SSIM基于人眼能提取图像中的结构化信息假设,相比传统方式更符合人眼视觉感知。SSIM主要考量图像的3个关键特征:亮度、对比度和结构。其使用均值作为亮度估计,标准差作为对比度估计,协方差作为结构相似程度的度量。其计算如式(13)所示:
(13)
其中,μx和μy分别代表真实图像和预测图像的均值,σx和σy分别代表真实图像和预测图像的方差,σxy是真实图像和预测图像的协方差,c1和c2是常数。SSIM的值在-1~1。当SSIM=1时表示2幅图像最相似。在MSE和PSNR相同的情况下,SSIM指标更大的预测图像更锐利、更清晰。然而PSNR和SSIM都只适合画面复杂度低或完全对齐的图像,当图像较为复杂或者发生错位时,其评价将不再准确。
6 损失函数
损失函数的设计和选择至关重要。MSE损失函数(L2)在回归任务中占据统治地位,其处处可导,而且梯度值是动态变化的,使模型能够快速地收敛,然而平方项会放大离群点的损失,那么MSE会以牺牲其它样本的误差为代价,朝着减小离群点误差的方向更新,这就会降低模型的整体性能。相比之下,MAE损失(L1)在处理离群点时更柔和,但其存在一个严重的问题:更新的梯度始终相同,即使对于一个很小的损失值,也会产生较大的梯度,这显然不利于模型学习。通常会使用MSE和MAE的组合来一起优化模型。
通常情况下,随着降雨级别的增加,小雨、中雨、大雨和暴雨发生的次数越来越少,即降雨数据整体呈现出长尾分布的特征。如果使用常规的MSE或者MAE损失,那么它们对大雨和小雨的惩罚是相同的,这可能导致模型会忽略那些发生概率很小但危害很大的暴雨事件。Shi等人[62]提出了对不同雨量级别加权的损失函数B-MAE(Balanced Mean Absolute Error)和B-MSE(Balanced Mean Squared Error),其计算分别如式(14)和式(15)所示:
(14)
(15)
其中,Wi,j为每个像素的权重,大雨的权重更大。相比于使用MSE或者MAE损失,使用B-MSE或者B-MAE作为损失函数会使模型在度量较大雨量的指标如CSI-30、HSS-30上表现得更好,但会降低模型对小雨的预测性能。Cao等人[142]提出了一种组合了加权和不加权的损失函数,尝试解决B-MSE或者B-MAE忽略小雨这一缺陷。该损失函数强制每一种降雨级别的像素的总权重为1,以达到既关注大雨又关注小雨的目的。
使用MSE或者MAE作为损失函数进行训练带来的另一个缺陷是预测图像会模糊,并且随着外推步数的增加,预测图像的模糊效应愈发明显。原因是MSE损失的结构设计决定了其假定图像中高频细节特征是噪声,最小化MSE误差,将使得其仅仅通过平均图像像素值就可以得到全局最优的结果,因此无法重建出清晰锐利的图像。一些研究工作尝试在MSE损失的基础上引入正则项来缓解预测的模糊性。
Tran等人[143]引入结构相似度指标SSIM惩罚预测来获取更符合人类视觉的图像(此外还有表2中的一些参考文献)。Song等人[47]引入IOU(Intersection over Union)[144]来重点关注降雨区域,其在气象上等同于CSI,需要指定某个降雨阈值来计算,等同于关注某个级别的降雨。IOU的计算如式(16)所示:
(16)
多个文献(如表2和表3所示)引入基于梯度的锐度损失GDL来锐化图像预测。其计算如式(17)所示:
|Yi,j-Yi-1,j‖α+‖Xi,j-1-
Xi,j|-|Yi,j-1-Yi,j‖α)
(17)
其中,α是一个大于或等于1的整数。总之,使用正则化手段在一定程度上缓解了模糊问题。然而,如何平衡常规的损失函数和正则项之间的权重是一个棘手的问题,需要进行大量的实验来选择合适的权重,这增加了模型训练的难度。
MSE损失函数假定数据服从高斯分布,导致其无法处理多峰分布数据,并且给预测带来了模糊性。为了克服这些局限性,许多研究工作将生成对抗训练(损失)引入到视频预测任务中。GAN[36]是由2个相互竞争的学习系统组成的,分别称为生成器(G)和判别器(D)。通过玩极小极大的游戏,就可以训练这2个系统。生成器旨在生成与目标分布中的样本尽可能相似的样本;而判别器则负责将生成的样本与目标分布中的样本区分开来。经过良好的训练,生成器可以模拟目标分布。换句话说,生成器产生的样本可以近似地认为是来自目标分布的样本。GAN的损失函数如式(18)所示:
Ez~p(z)[log(1-D(G(z)))]
(18)
其中,E(·)表示期望,q(x)表示真实数据的分布,p(z)表示随机噪声的分布。尽管GAN能生成更清晰、真实的样本,但训练GAN需要达到纳什均衡,而只有在损失函数是凸函数的情况下才能保证梯度下降算法实现纳什均衡[145]。另外,交替训练生成器和判别器将导致训练不稳定和梯度消失等问题[146]。
除了GAN,大量的研究工作还使用变分自编码器VAE[37]来建模未来的不确定性和生成不同可能的未来帧。VAE是一种基于贝叶斯变分推理技术的自编码器。VAE认为普通自编码器的隐空间没有被很好地组织,不够规则,其在训练过程中引入显式的正则项,以避免模型过度拟合。该正则化项用于惩罚隐空间的分布与标准高斯之间的KL(Kulback-Leibler) 散度(相当于引入了随机噪声)[147],其计算如式(9)所示:
(19)
其中,P(x)和Q(x)为2个概率分布。VAE增加了预测的多样性,但难以评估,需要多次运行才能获得令人满意的结果[27]。
7 展望
视频预测是一个像素级别的时序预测任务。相比于计算机视觉领域中的其他任务(如:视频分类、视频语义分割),视频预测更加复杂。基于雷达回波图的短临降水预测任务属于视频预测的一种,然而,由于云团的膨胀、消散和变形,它比一般的视频预测问题更具挑战性。尽管目前已有许多研究工作取得了不错的成果,但模糊问题依然没有完全解决。因此,如何更有效地应对复杂的非线性时空变换是未来研究的重点。此外,在短临降水预测领域还存在一些其它的问题亟待解决。接下来本文将从多个方面讨论未来值得进一步探究的科研问题。
(1)数据和算力是开展深度学习研究的基础,只有具备充足的数据和强大的算力支持才有可能开展进一步的模型、算法研究。算力可以通过租赁、购买的方式获取,而数据是无价的。目前,关于降水的开放雷达数据集也不是很多,多模态的数据集就更加稀少了。这些珍贵的数据能使科研工作者快速开展研究,而不必在繁琐的数据收集和预处理过程中耗费大量时间[148]。因此,如能贡献降水相关的数据集也是一项有意义的工作。
(2)目前关于多模态的降水模型较少。一是因为多模态数据难以获取,二是因为时空分辨率需要对齐。尽管这些因素严重阻碍了多模态模型的发展,但多模态模型同时考虑了多种输入源,更符合自然界中人类通过多种感官认知事物的规律。在其他研究领域,多模态模型是一个研究热点方向,如使用图像、文本和声音进行视频分类。但是,在短临降水预测领域仍需进一步探索。
(3)尽管目前短临降水预测领域的模型众多,且能够得到一些令人满意的结果,但这些模型(RNN、GAN和VAE)都存在各自的缺点。当参数量足够大、超参数设置和训练方式足够合理时,这些模型的性能会趋于饱和。即模型自身的架构存在瓶颈,这可以通过组合或者集成预测来解决。然而,使用旧的架构组合仍不能从根本上解决预测模糊的问题。最近,ViT[121]的提出似乎指明了未来研究的方向。其首次将NLP中最为经典的Transfomer[76]结构迁移到视觉领域,并逐步在图像分类[149]、语义分割[150]、目标检测[151]、视频分类[152,153]和视频分割[154,155]等各个子任务下取得了与传统模型相媲美甚至更好的结果。鉴于视频预测任务的困难性,目前只有少数工作探索了ViT在天气预测或视频预测领域的应用,如FourCastNet[120]和MaskViT[156]。此外,Rainformer[157]和Earthformer[158]等模型已经尝试将完全基于注意力的Transfomer架构应用到短临降水预测领域。因此,基于注意力的模型或者与之前模型的组合将指引短临降水预测领域未来的发展方向。
(4)训练资源受限是视频预测领域一个棘手的问题。加宽或加深模型来提升模型性能以减缓模糊性的方法所占用的显存总归要达到显卡所能承受的最大值。引入多尺度结构是一个解决办法,但这只是减缓了模型达到显存瓶颈的速度。此外,还可以使用分布式数据并行技术,如PyTorch的DDP(Distributed Data Parallel )[159],将批数据(Batches)分散到多个显卡上。然而,RNN模型占用的显存量越来越大,40 GB显存甚至不能维持批大小 (Batch Size)为1时RNN模型的训练。分布式模型并行技术将模型的各个部分(如层)分散到不同的训练设备上,似乎是大模型最终的归宿,但其复杂的工程实现对于非计算机专业的科研工作者可能不太友好。切块(Patch)的使用的确缓解了训练RNN时资源受限的问题,但其作用机理不明确,缺点很多。在视觉任务中使用Self Attention将带来巨大的显存占用量,随着图像分辨率的增加,显存占用量将呈平方级别增长。Patch的使用是能将Transfomer架构迁移到视觉领域的根本原因,ViT利用Patch大大降低了训练的空间复杂度。此外,MAE[160]还通过完成类似BERT[161]一样的完型填空(填块)任务来迫使模型学习生成新的样本。总之,Patch能降低显存占用量,并且可能成为时空序列预测的新范式。
(5)MSE损失函数总是导致未来状态的平均,很难处理未来的不确定性,GAN和VAE通过更改模型设计并在损失函数中加入正则项来约束求解方式,此外一些模型还在损失函数中引入额外的正则项,如SSIM和GDL等。这也给我们一些启发:正则项限制了神经网络求解空间的大小,使模型更容易得到近似解。总之,未来是否有更好的重建损失函数代替MSE以及是否有更强有力的正则约束是一个值得探讨的问题。
(6)作为迁移学习的一种形式,预训练+微调的方式在NLP任务中广泛应用,一些基于Transfomer的大模型,如BERT和GPT[162-164],采用预训练的方式从大规模的文本数据中学习先验知识,然后再在下游任务上微调,它们似乎统一了NLP领域内几乎所有的任务。在CV领域,ViT及MAE的提出,使得CV和NLP模型之间的距离不再遥远,预训练和大模型可能是未来CV模型的趋势。此外,视频预测领域的经典Seq2Seq架构也是从NLP领域迁移过来的,而目前NLP领域主流的模型并不是基于RNN的模型,而是基于更先进的Transfomer的模型。鉴于文本生成和视频预测这2个任务的相似性,未来基于Transfomer变体的大模型可能是视频预测领域的新宠儿。
8 结束语
本文主要从短临降水预测问题中存在的模糊问题出发,详细阐述了不同的模型从不同的角度增强模型预测能力的方案。为了建模未来的不确定性,这些研究工作从模型架构、训练方式、损失函数等不同方面对算法进行了改进。此外,本文还以图像和表格的形式对方法和数据集进行了比较总结,以便读者能直观地明白底层的细节。最后,本文为未来的研究方向和开放问题提供了一定的见解。总之,关于短临降水预测的研究未来的发展空间还很大,需要气象和计算机相关的科研人员共同探索。本文的目的是希望能对相关领域的研究人员和工程技术人员提供一些有益的帮助。
猜你喜欢
黑龙江气象(2021年2期)2021-11-05
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
小学生学习指导(低年级)(2018年12期)2018-12-29
家教世界(2018年16期)2018-06-20
北京航空航天大学学报(2018年1期)2018-04-20
成都信息工程大学学报(2016年6期)2016-06-01
火控雷达技术(2016年3期)2016-02-06
百科探秘·航空航天(2015年4期)2015-11-07
