
基于ResNet18网络的油茶果壳籽分选研究
2023-10-25 10:35王焱清孙记委段宇飞
湖北工业大学学报 2023年5期
董 庚, 王焱清,2, 孙记委,2, 段宇飞,2
(1 湖北工业大学农机工程研究设计院, 湖北 武汉 430068; 2 湖北省农机装备智能化工程技术研究中心, 湖北 武汉 430068)
油茶属于山茶科植物,与油棕、油橄榄、椰子并称为世界四大木本食用油料作物,其中富含多种不饱和脂肪酸,有着“东方橄榄油”的称号[1-2]。近年来在我国脱贫政策的扶持下,油茶的产量会进一步提高,随着产量的提高,油茶的产业化发展也迫在眉睫。油茶的产业化过程中,油茶果的采摘、破壳、分选和榨油环节是重中之重,会直接影响茶油的品质[3-5]。较高的分选准确率可以减少分选时间,提高分选效率进而增加农户的经济效益,对于推动油茶果产业化有着重要意义。
近年来,卷积神经网络在农业当中有着广泛应用[6-8],谢为俊等[9]将卷积神经网络应用于油茶籽完整性识别当中,通过对卷积神经网络的改进从而进一步提高了分辨的准确率,最终优化后的准确率达到了98.05%,训练时间为0.58 h,能够很好地满足油茶籽在线实时分选的要求。赵洋等[10]以ResNet18模型为基础,将里面的残差卷积改为空洞卷积用于对花卉的识别,改进后的模型识别精度达到了97.78%,对花卉分类有一定的可行性。张怡等[11]将ResNet卷积神经网络应用于绿茶种类的识别当中,很好地区别了8种常见的绿茶,最终的识别准确率达到了90.99%,为茶叶种类识别提供了一种快捷高效的新方法。
经典的卷积神经网络模型有很多,比如AlexNet[12],VGGNet[13]以及ResNet[14-16]等。本文研究方向是基于ResNet18模型探索与油茶果的分选是否能够很好地结合,在原有的模型基础上优化模型,提高分选的准确率与效率,提升油茶果分选的经济效益。
1 材料与方法
1.1 油茶果分选机结构
油茶果分选机主要是由传动系统、样本采集系统、控制系统和喷吹系统组成。油茶果分选机先经滤网筛选出合适的样本,其样本由上料口均匀掉落在下方的托盘当中,电动机带动链条负责传动,使托盘均速地传动到工业相机的下方,相机将托盘内的信息拍照上传并进行壳籽信息的判断,确定所在位置,当油茶果果壳的托盘经过喷吹装置时传感器会将位置信息传送给PLC控制器。当PLC控制器确定果壳达到预定位置并获得果壳的判定信号后,会打开对应电磁阀控制气体将果壳吹出,而茶籽则自由掉落在下方的收集装置里为后续工序做准备。具体流程与油茶果分选机结构如图1图2所示。
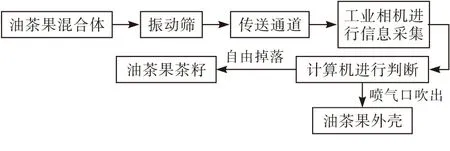
图1 油茶果分选机流程
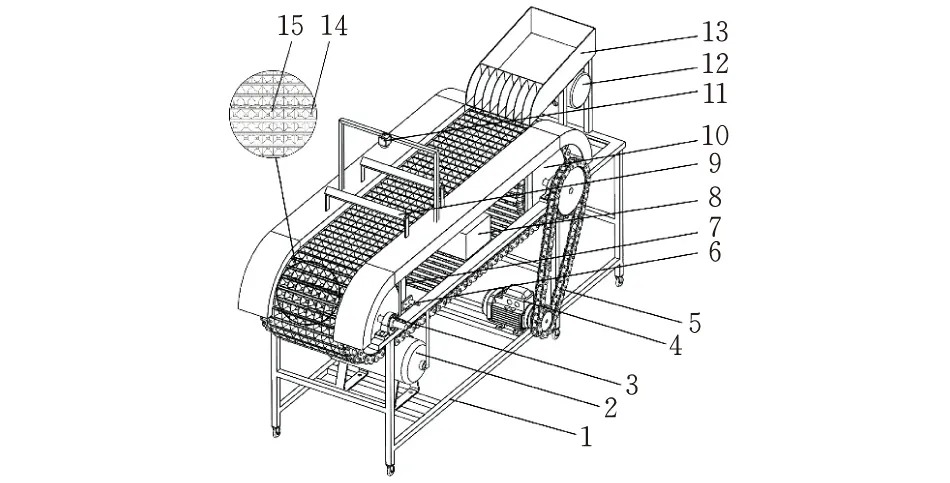
1-机架; 2-空气压缩机; 3-轴承座; 4-调速电机; 5-链传动1;6-霍尔传感器; 7-气阀; 8-控制单元; 9-条形光源; 10-链传动2; 11-工业相机; 12-振动器; 13-进料仓; 14-喷嘴; 15-阵列方槽
1.2 实验样本的采取与处理
本文采用的油茶果样本为油茶果分选机与配套的工业相机对样本图像进行采集,采集后的整幅样本图像(1280像素×1024像素)如图3所示。
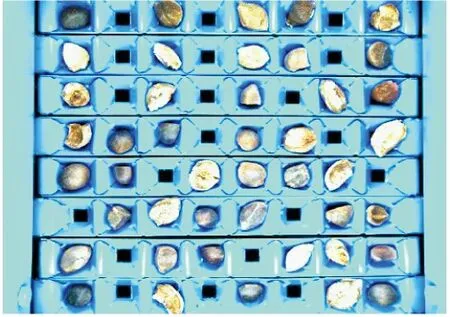
图3 采集的样本图像
油茶果分选机的托盘将整幅样本图片分为均匀的64份,果壳与茶籽的混合体由上料口自然掉落,随机分布在托盘中,以确保样本的随机性。将采集的图像由matlab软件将其均匀裁剪,每张图片获得64张独立的样本图像(128像素×128像素),独立的样本图像由油茶果,果壳与空格三部分组成,其中果壳的情况较为复杂,将其分为内壳和外壳做具体的区分,以达到更好的分选效果。具体图像如图4所示。

图4 剪切后的四类样本图像
从图4可以看出,经摊晒破壳后的油茶果外壳与茶籽在颜色和大小方面具有部分类似的特征,较难区分,影响分选的准确率。油茶果分选机共采集整幅样本图像26张,裁剪为1664张独立样本图像,其中内壳外壳样本数量与其他样本相比数量较少,取全部的230张外壳和234张内壳,与部分的250张空格和250张茶籽作为后续建模数据。考虑到数据较少会影响后续模型的训练,将其旋转90°,180°与270°,并增加图片亮度与降低图片噪声,扩充至5784张数据图像,其中的70%用作训练集, 20%用作验证集,另外的10%用来做测试集使用。
1.3 ResNet算法研究
卷积神经网络在图片分类中具有出色的表现,但是仍然具有一定的局限性。一般情况下网络的准确度是随着网络深度同步增加的,但是现实情况是当深度增加到一个临界值后网络的准确度会降低,这就是卷积神经网络中的梯度消失现象[17]。其原因是网络深度增加过多以后造成从后向前传播的梯度变得过小,从而使权重不再更新。除此之外,随着网络深度的增加,参数量也会变得更大,导致模型的优化变得更加困难,出现训练误差更大的问题。为了解决上述问题,He 等[14]提出了残差神经网络为基础的ResNet模型,其主要思想是在输入通道和输出通道之前使用跳过连接增加通道之间的联系,进而避免信息缺失的出现。在训练过程中学习上一环节的输出残差,而不是将所有内容一并学习,从而减少工作量,节约时间和运行内存,降低模型的学习难度。残差单元如图5所示。
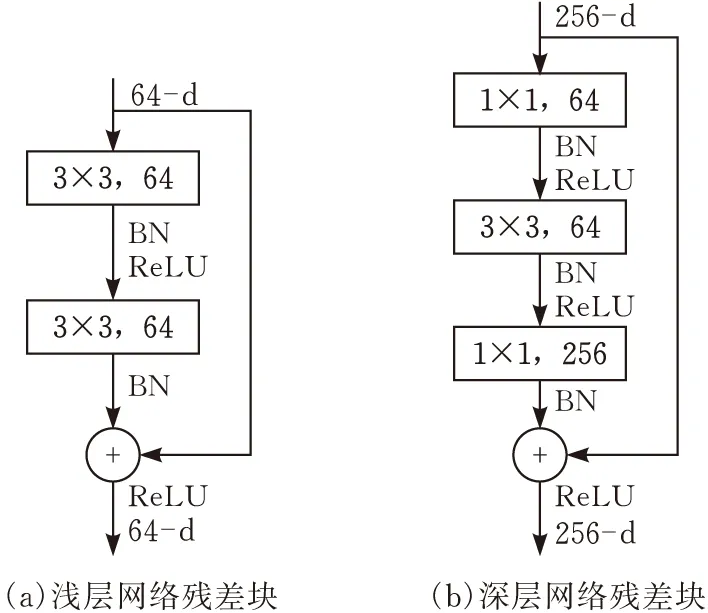
图5 残差块结构
图5为ResNet中经常使用的两种残差块,其中(a)多用于浅层神经网络,(b)多用于深层神经网络,图5a输入数据经两条曲线在相交点通过卷积操作进行相加,然后由激活函数进行激活输出,相比图5a而言,图5b则在主线当中多了一个升维和降维的过程,其主要目的是节省参数,深层网络使用得越多就可以节省越多的参数,加快ResNet的运算速度,提升效率。
ResNet模型有着不同的网络层数, 常用的有ResNet18、ResNet34和ResNet50,如果目标较为复杂的情况下还可以提升模型层数如ResNet101和ResNet152。本文选用ResNet18模型为研究的主要模型,并针对不同的超参数进行优化,ResNet18模型参数设置详见表1。

表1 ResNet18参数设置
2 结果与分析
2.1 运行平台
本文实验搭建的训练环境为Win11操作系统,使用CPU进行模型训练,在intel(R) Core(TM) i7-11800H处理器中运行,Python 版本为3.9.7,Pytorch 版本为 1.11.0。
2.2 批量尺寸对模型的影响
批量尺寸(batch_size)指的是训练过程中每批运行使用图像的数量,是深度学习的重要参数。合适的批量尺寸能够提高模型测试集的准确率,对模型训练速度的提升也有较大的影响。为方便二进制的计算,习惯上选择为2的次幂。本文以批量尺寸(16、32、64、128)做为研究基础,探究不同因素对模型具体的影响。数据如图6所示。
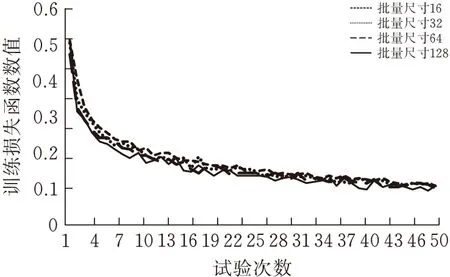
(a)训练集损失函数数值

(b)验证集准确率
由图6可得,批量尺寸的大小与训练集损失函数成正比,与验证集准确率成反比,且越大的批量尺寸验证集准确率折线浮动越大,花费的时间也越多,过大的批量尺寸也会产生较大的内存消耗,不利于长时间运行,因此选用32作为ResNet18的批量尺寸。
2.3 学习率对模型性能的影响
学习率(Learning rate) 是深度学习中重要的超参数,其作用是决定目标函数是否能够收敛到局部最小值以及收敛到最小值的时间。一个合适的学习率可以更快达到loss的最小值,可以保证收敛的loss值是神经网络的全局最优解。结合文献[18]以及实验经验,本文以学习率分别为0.1、0.01、0.001、0.0001和0.00001,在其他不变的情况下进行实验,得到的数据如图7所示。
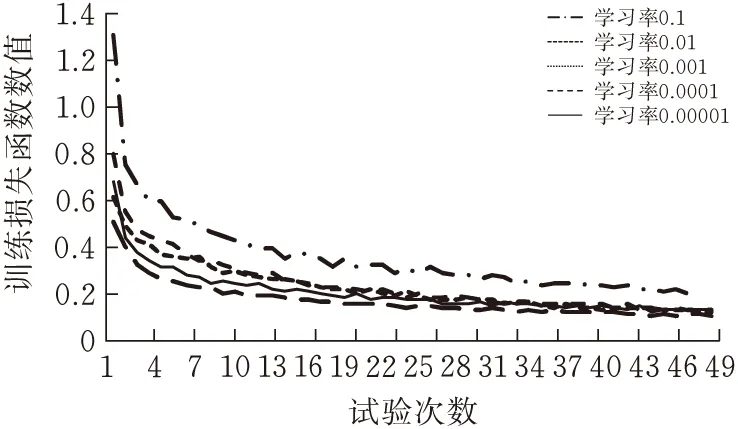
(a)训练集损失函数数值
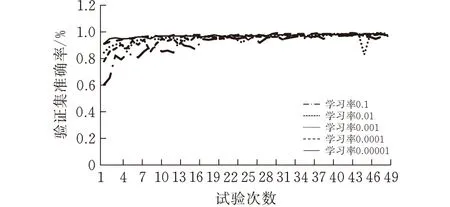
(b)验证集准确率
从实验数据中可以得出结论,随着学习率的减小,模型的损失函数数值变低的同时验证集准确率也在不断地提高,但是过小的学习率会减慢模型损失函数变化的速度,增加网络收敛的复杂度,并导致模型被困在局部最小值。在学习率达到0.00001的时候训练损失函数并没有进一步下降而是反向增加,故将最终的学习率定为0.0001。
2.4 激活函数对模型的影响
激活函数是ResNet18中极其重要的概念,其激活函数的意义是判定神经元的输出,具有非线性的特征。将非线性的因素引入神经元中,可以提升神经网络对模型的表达能力,并且具有线性模型所不具备的解决问题的能力。每个激活函数的表达式不同,起到的作用也各不相同[19],本文选取了Relu、LeakyReLU和Sigmoid三种激活函数进行了对比,具体实验数据如图8所示。

(a)训练集损失函数数值
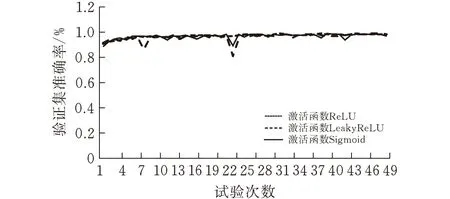
(b)验证集准确率
图中可以看出虽然使用的不同的激活函数,但是对模型都有积极的作用,整体相差较小, LeakyReLU激活函数在损失函数方面整体与其他两种函数相比略大且折线浮动略高,同时在验证集准确率方面也不占优势。Sigmoid激活函数在损失函数上与Relu激活函数相差较小,但是准确率浮动较大。因此在ResNet18中使用Relu函数作为激活函数。
2.5 优化器对模型的影响
优化器的选择关系到ResNet模型能否快速收敛并取得较高的准确率和召回率,不同的优化器对网速的损失函数与测试集准确率也有着不同的影响,本文选用Adam、SGD、和Adamax三种优化器进行对比,对比数据如图9所示。
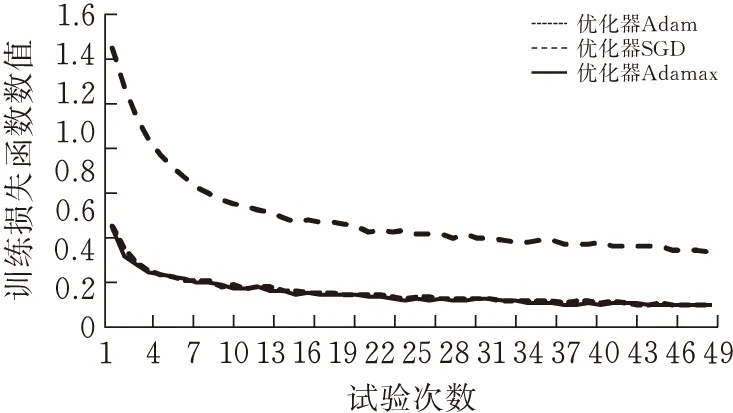
(a)训练集损失函数数值
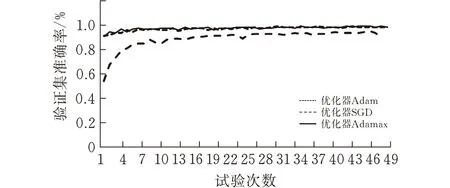
(b)验证集准确率
图中能够得出结果,优化器SGD与其他两者相比在损失函数和准确率上不具有优势,而Adamax作为Adam的优化,在Adam的基础上增加了一个学习率上限的概念,具有一定的稳定性,折线幅度较低。所以选择Adamax作为ResNet18的优化器。
2.6 优化后的ResNet18模型
基于前面实验部分得到的各部分数据进行模型优化,得到改进后的ResNet18模型进行对比,数据如图10所示。

(a)训练集损失函数数值
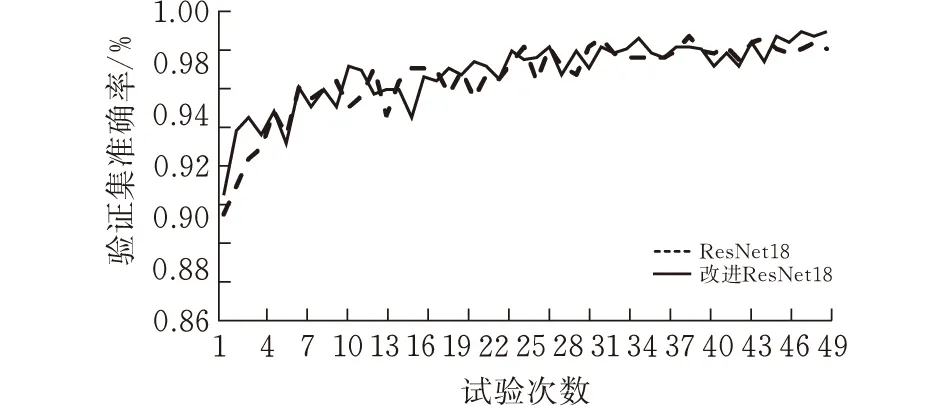
(b)验证集准确率
由图10中得出结论,训练损失函数方面改进后的ResNet18模型与改进前相比有明显的降低,模型更加稳定,验证集准确率也得到了一定的提升,其初始准确率高于未改进的模型且整体曲线的波动相比较少,验证集平均准确率更是由之前的97.03%,提升为当前的97.21%整体样本的准确率有了小幅度提升。将改进前的模型与改进后的模型使用预留的578张测试集图片进行测试,结果如表2所示。

表2 模型测试集准确率
测试结果证明, 改进后的ResNet18测试集在油茶果的分选上准确率提升,有效的降低了外壳的错误率,在整体的平均准确率有了小幅度的提升,能够满足油茶果分选的实际需求。
3 结论
1)在其他相同的条件下,采用较大的批量尺寸可以很好地提升模型的损失函数。但是较大的批量尺寸会增长模型的运行速度,提高运算时间,而且过大的批量尺寸也会使模型的验证集准确率进一步波动。
2)学习率的降低可以使模型更快收敛,但是过低的学习率也会减少验证集准确率,从而使模型效果变差。最终表明,选用0.0001的学习率最适合油茶果的分选。
3)激活函数和优化器的作用同样重要,不同的选择有着不同的影响,最终选择Relu激活函数和Adamax优化器。
4)优化后的模型在准确率方面得到了一定的提高,实际测试平均准确率由之前的97.25%提升为选择的97.75%,提升幅度不大但是证明了研究方向是正确的。下一步可以进一步改进模型,得到更好的模型效果。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
科学家(2021年24期)2021-04-25
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
现代园艺(2017年21期)2018-01-03
现代园艺(2017年21期)2018-01-03
中国西部(2017年4期)2017-04-26
湖南农业(2017年1期)2017-03-20
阜阳职业技术学院学报(2015年4期)2015-05-17
